
Antes yo pensaba que “recopilación de datos” era tirarse horas copiando y pegando filas de una web a una hoja de cálculo, para después darte cuenta de que te faltaba la mitad de los teléfonos y, por un despiste, habías pegado un meme de gato en la columna de precios. En 2026, ese flujo de trabajo ya suena a otra época. Hoy la categoría abarca desde AI web scrapers y la infraestructura de proxies y APIs, hasta equipos de scraping gestionado y enormes redes humanas de investigación y anotación.
Y eso importa porque las empresas siguen necesitando datos más frescos, más limpios y más fiables de los que sus equipos internos pueden reunir a mano. Los equipos de ventas quieren listas de leads que no se queden obsoletas al instante. Los equipos de ecommerce quieren seguimiento de productos, precios e inventario. Los equipos de investigación e IA buscan formas escalables de recopilar datos públicos de la web, feedback humano, datos de entrenamiento y conjuntos estructurados sin tener que montar cada canal desde cero.
Esta guía está pensada para una decisión práctica: ¿qué empresa de recopilación de datos encaja con tu flujo de trabajo, el nivel técnico de tu equipo y tu escala en 2026?
Por qué las empresas necesitan servicios de recopilación de datos en 2026
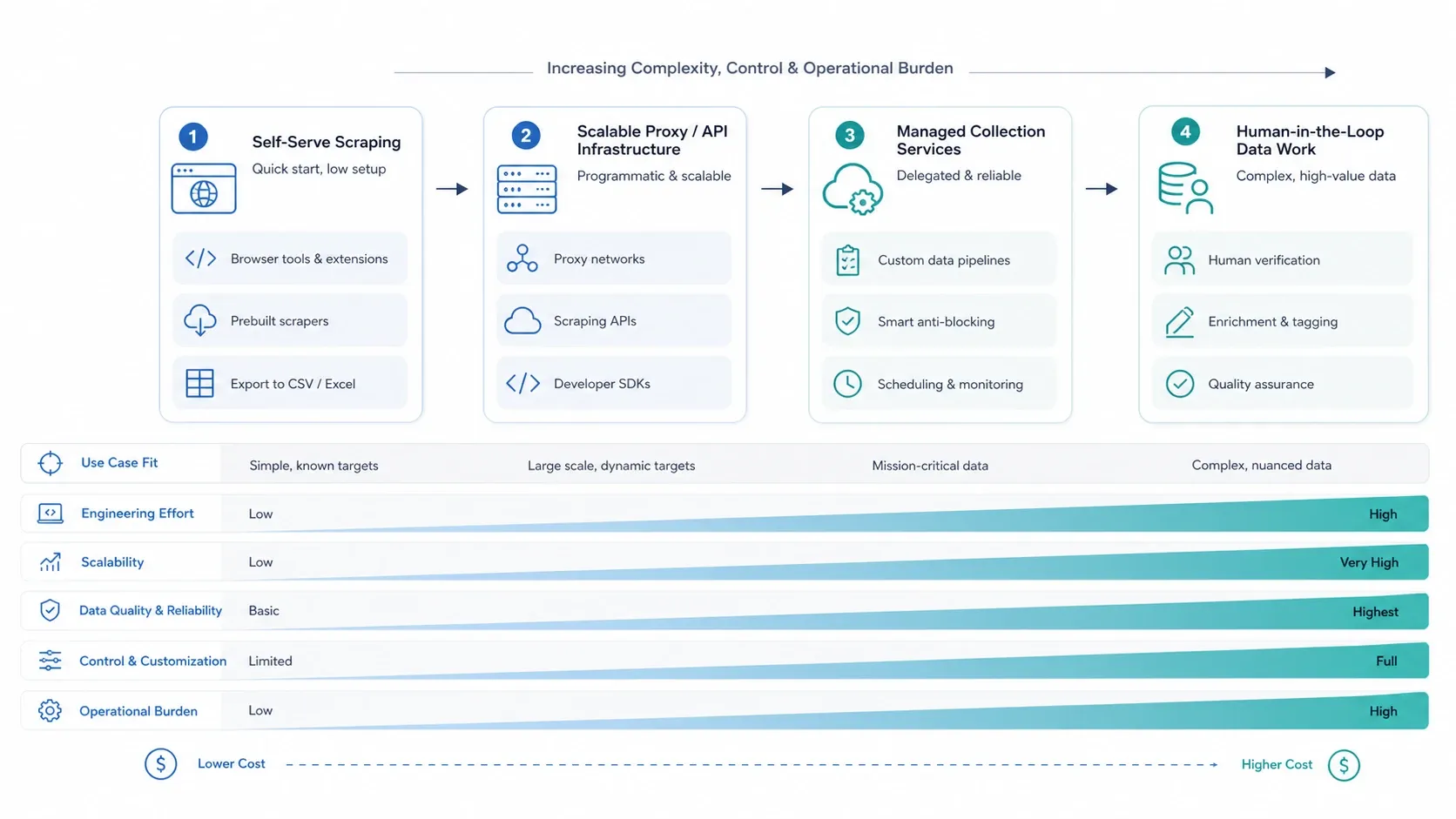
La recopilación manual sigue fallando en los mismos puntos de siempre: demasiado trabajo repetitivo, demasiadas pestañas abiertas, demasiada limpieza y demasiada fragilidad cuando cambia la fuente. La diferencia en 2026 es que más equipos ya esperan que la automatización se encargue por defecto de la extracción inicial, el enriquecimiento, la programación y la exportación.
Por eso los servicios de recopilación de datos se han dividido en varias capas. Algunas herramientas ayudan a usuarios no técnicos a extraer datos de sitios web con una configuración mínima. Otras se centran en redes de proxies, automatización de navegador e infraestructura de desbloqueo para equipos de ingeniería. Otras venden servicios totalmente gestionados o recopilación y anotación realizadas por personas. Elegir bien ya no va tanto de encontrar el proveedor “más grande”, sino de ajustar la herramienta al trabajo.
Si tu equipo solo necesita extraer anuncios, contactos o páginas de producto rápido, un scraper con IA puede ahorrarte horas desde el primer día. Si necesitas pipelines resistentes para objetivos de alto volumen o con protección, tiene más sentido apostar por proveedores de infraestructura. Si tu problema está relacionado con encuestas, etiquetado, evaluación o juicio humano matizado, las plataformas de investigación y anotación con crowdsourcing suelen ser la mejor opción.
Si quieres una visión rápida de por qué unas operaciones de datos más sólidas son importantes antes de hacer tu lista corta de proveedores, este breve video de contexto del mercado es una buena introducción.
Cómo seleccionamos los mejores servicios de recopilación de datos
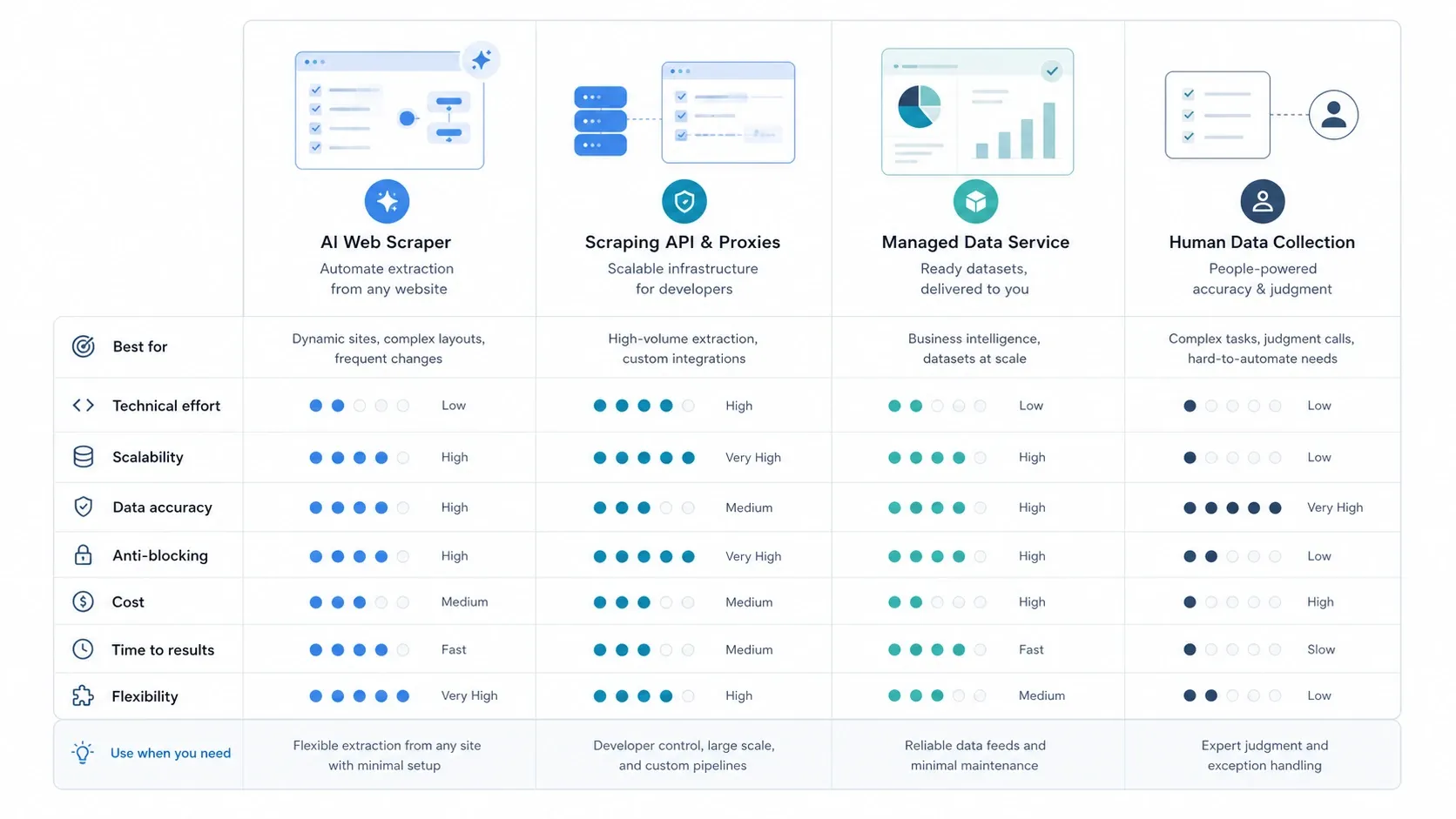
No faltan empresas de recopilación de datos, pero no todas resuelven el mismo problema. Para esta actualización, me centré en varios criterios prácticos:
- Funciones y capacidades: ¿El servicio puede trabajar con páginas web públicas, exportaciones estructuradas, páginas dinámicas, programación, APIs o tareas con intervención humana?
- Facilidad de uso: ¿Es accesible para usuarios de negocio o está pensado sobre todo para desarrolladores y equipos de datos?
- Escalabilidad: ¿Puede cubrir desde una prospección ligera hasta pipelines de nivel empresarial y trabajos recurrentes de recopilación?
- Modelo de precios: ¿Tiene plan gratuito, suscripción, pago por uso, pago por tarea o precio bajo presupuesto?
- Reputación y posicionamiento: ¿El posicionamiento actual del producto sigue coincidiendo con lo que realmente necesitan los compradores en 2026?
- Capacidades de IA: ¿Usa IA de forma relevante para extracción, análisis, enriquecimiento o evaluación, o sigue siendo sobre todo automatización tradicional de flujos?
También depuré cifras desfasadas y marcas antiguas. Cuando los precios o capacidades exactos no estaban claramente respaldados por páginas oficiales actuales, orienté la comparación hacia el modelo de precios y el caso de uso ideal, en lugar de fingir que números antiguos seguían siendo precisos.
Tabla comparativa rápida: las 15 mejores empresas de recopilación de datos
Antes de entrar en detalle, aquí tienes una vista lado a lado de los 15 mejores servicios de recopilación de datos en 2026.
| Servicio | Funciones clave | Tipos de datos compatibles | ¿AI Web Scraper? | Prueba / acceso gratuito | Modelo de precios | Ideal para |
|---|---|---|---|---|---|---|
| Thunderbit | Extensión de Chrome con IA, detección automática de campos, subpáginas, paginación, programación, exportación a Sheets y Excel | Páginas web, tablas, imágenes, emails, números de teléfono | Sí | Plan gratuito | Plan gratuito + planes de pago | Usuarios de negocio sin perfil técnico que quieren extraer datos web rápido y sin fricción |
| Bright Data | API de scraping web, infraestructura de proxies, datasets, herramientas de desbloqueo, controles de cumplimiento | Datos públicos de la web, ecommerce, redes sociales, búsqueda, APIs | Parcial | Prueba gratuita | Prueba gratuita + pago por uso / planes de escala | Equipos técnicos que ejecutan pipelines de recopilación a gran escala |
| Oxylabs | APIs de scraping, red de proxies, datasets listos, soporte de parsing | Datos de producto, búsqueda, viajes, empresas y marketplaces | Parcial | Prueba en productos seleccionados | Precio bajo presupuesto / ventas enterprise | Empresas que necesitan infraestructura de scraping fiable y de alto volumen |
| Octoparse | Scraper visual sin código, plantillas, programación en la nube, constructor de flujos | Sitios web, listas, tablas, datos estructurados de páginas | IA limitada | Plan gratuito | Plan gratuito + suscripción | Analistas y operadores que quieren control sin código |
| Zyte | Zyte API, extracción con IA, herramientas de smart proxy, enfoque en cumplimiento | Datos web dinámicos, extracción estructurada, objetivos basados en navegador | Sí | Prueba gratuita | Pago por uso | Equipos que buscan extracción de datos compatible y centrada en API |
| NetNut | Red de proxies, acceso a datos B2B, geolocalización, APIs de scraping | Datos empresariales y profesionales, recopilación respaldada por proxies | No | Prueba / demo | Precio bajo presupuesto | Enriquecimiento de datos B2B y flujos de inteligencia comercial |
| Decodo (antes Smartproxy) | APIs de scraping, productos de proxy, desbloqueador de sitios, planes self-service | Datos de búsqueda, compras, redes sociales y web general | No | Plan gratuito / prueba gratuita | Plan gratuito + suscripción | Equipos con presupuesto ajustado que aún necesitan infraestructura escalable |
| Infatica | Red de proxies, API de scraping, renderizado JS, soporte gestionado | Sitios web dinámicos, objetivos restringidos, páginas renderizadas en navegador | No | Prueba | Precio bajo presupuesto | Equipos técnicos que necesitan soporte flexible para scraping personalizado |
| DataHen | Web scraping gestionado, soporte ETL, entrega en formatos estructurados | Datos públicos de la web, proyectos de recopilación a medida | No | Consulta | Precio de servicio personalizado | Empresas que externalizan trabajos de recopilación de datos a medida |
| HabileData | Enriquecimiento de datos, anotación, procesamiento de documentos, operaciones externalizadas | Registros estructurados, documentos, imágenes, conjuntos de datos sectoriales | No | Consulta | Precio de servicio personalizado | Procesamiento de datos validado por humanos y trabajo de back office |
| Coresignal | Datasets públicos de la web, APIs, cobertura de empresas y fuerza laboral | Datos de empresas, empleados y mercado laboral | No | Acceso a muestras | Precio por contrato | Equipos que quieren datasets de inteligencia empresarial listos para usar |
| LXT | Recopilación humana global, anotación, RLHF, alcance multilingüe | Audio, texto, imagen y datasets de evaluación | No | Consulta empresarial | Precio enterprise personalizado | Equipos de IA que necesitan datos de entrenamiento humanos y multilingües |
| Appen | Recopilación gestionada de datos para IA, anotación, validación, evaluación | Voz, texto, imagen y datos de evaluación de modelos | No | Consulta empresarial | Precio enterprise personalizado | Empresas que ejecutan programas grandes y gestionados de datos para IA |
| Prolific | Participantes de investigación de alta calidad, preselección, servicios gestionados | Encuestas, estudios, evaluación humana, datos de feedback | No | Acceso self-service | Pago por uso | Equipos de investigación, UX y evaluación de IA que priorizan la calidad de los participantes |
| Amazon Mechanical Turk | Gran marketplace de tareas, herramientas para solicitantes, flujos de microtareas flexibles | Encuestas, etiquetado, reseñas, validación y tareas de captura de datos | No | Sin prueba gratuita | Pago por tarea + comisiones de la plataforma | Distribución de tareas humanas flexible y de bajo coste a gran escala |
Thunderbit: el AI Web Scraper más fácil para usuarios de negocio
Empecemos con mi favorito: Thunderbit. Thunderbit está pensado para personas que necesitan datos estructurados desde la web, pero no quieren pasarse la semana depurando selectores, automatizaciones de navegador o flujos de scraping frágiles. Convierte páginas en tablas en un par de clics y destaca especialmente para generación de leads, seguimiento de ecommerce, scraping de directorios y recopilación operativa recurrente.
Lo que hace que Thunderbit destaque es su flujo de trabajo centrado en IA. Con AI Suggest Fields, entras en una página, le dices a Thunderbit qué extraer y obtienes al instante un esquema útil. Para usuarios de negocio, eso es un punto de partida mucho mejor que definir cada campo manualmente. También admite paginación, subpáginas, exportaciones y trabajos programados, así que sirve tanto para recopilaciones puntuales como para monitorización recurrente.
Funciones clave de Thunderbit
- Detección de campos con IA: Thunderbit sugiere el esquema de extracción para la página en vez de obligarte a definirlo todo desde cero.
- Flujo de trabajo con poca fricción: Está diseñado para usuarios de negocio, no solo para desarrolladores o especialistas en scraping.
- Scraping de subpáginas y paginación: Muy útil para catálogos de productos, directorios, listados inmobiliarios y páginas de reseñas.
- Enriquecimiento integrado: Puedes limpiar, clasificar, traducir o dar formato a los campos durante la extracción.
- Opciones de exportación flexibles: Exporta a Excel, Google Sheets, Airtable, Notion, CSV o JSON.
- Modo nube y modo navegador: Usa ejecución en la nube para escalar o el modo navegador para sitios con inicio de sesión y sesiones sensibles.
- Programación: Ejecuta trabajos recurrentes sin reconstruir el flujo cada vez.
- Plan gratuito: Una forma práctica de probar el flujo antes de pasar a uso de pago.
Thunderbit es ideal para equipos de ventas, ecommerce, operaciones e investigación que quieren resultados rápidos sin tener que convertir el mantenimiento del scraper en una tarea adicional.
Si quieres ver cómo se ve el flujo de trabajo con menos fricción de esta categoría, este tutorial oficial de inicio rápido es el ejemplo más claro del resumen.
¿Quieres ver Thunderbit en acción? Consulta el blog o el canal de YouTube.
Prueba gratis Thunderbit AI Web Scraper
Bright Data: scraper web e infraestructura de proxies de nivel empresarial
Si Thunderbit es el botón fácil, Bright Data es la capa de infraestructura. Bright Data está diseñado para organizaciones que necesitan recopilación a gran escala, cobertura de objetivos difíciles, herramientas de desbloqueo y varias formas de acceder a datos públicos de la web sin tener que montar todo internamente.
El flujo actual de producto y precios de Bright Data gira en torno a una Web Scraper API, con prueba gratuita, entrada por pago por uso, plan de escala y un nivel enterprise personalizado visibles en su página oficial de precios. Eso lo convierte en una gran opción para equipos técnicos que necesitan flexibilidad entre proxies, APIs, datasets y flujos sensibles al cumplimiento.
Oxylabs: potentes APIs de scraping y datasets para pipelines de datos
Oxylabs sigue siendo una de las opciones empresariales más seguras si tu prioridad es la fiabilidad, las APIs de scraping especializadas y la profundidad de infraestructura. Su línea de productos está pensada para casos de uso serios de recopilación, no para scraping ocasional de una sola vez.
Es especialmente fuerte para organizaciones que necesitan extracción fiable desde fuentes de búsqueda, ecommerce, viajes y marketplaces, además del soporte operativo para ejecutar esos pipelines a escala. Frente a herramientas self-service más simples, Oxylabs es más pesada en infraestructura y más orientada a ventas, precisamente por eso muchas empresas grandes la incluyen en su shortlist.
Octoparse: extracción de datos sin código para analistas y operadores
Octoparse sigue siendo uno de los scrapers visuales sin código más conocidos. Su propuesta es clara: te da un constructor de flujos, plantillas y programación en la nube sin que tengas que escribir código personalizado para tareas comunes de extracción.
La página oficial de precios actual de Octoparse sigue haciéndolo atractivo para equipos pequeños porque mantiene un plan gratuito y luego escala a suscripciones de pago para usos más serios. Es una buena opción para analistas, marketers y operadores que quieren más control manual que el que ofrecen las herramientas solo con IA, pero que aun así prefieren no construir todo desde código.
Zyte: recopilación de datos web con IA y enfoque centrado en API
Zyte sigue posicionándose alrededor de una extracción de datos web compatible y centrada en API. La empresa combina infraestructura de navegador y proxies con extracción mediante IA dentro de Zyte API, lo que resulta atractivo si prefieres una interfaz programática más limpia que ir uniendo varias herramientas sueltas.
Zyte es especialmente fuerte para equipos que valoran la extracción estructurada, los objetivos complejos y la postura legal o de gobernanza. Su precio actual sigue siendo por uso, lo cual encaja mejor con cargas de trabajo variables que con tarifas rígidas por puesto.
NetNut: datos B2B y recopilación respaldada por proxies
NetNut entra en la categoría de infraestructura, con un mensaje centrado en proxies de alta calidad, recopilación de datos web y casos de uso B2B. Es una opción práctica para inteligencia comercial, enriquecimiento y programas de recopilación que necesitan alta calidad de entrega más que una interfaz pensada para consumidores.
Si tu flujo depende de un acceso fiable a fuentes de datos empresariales y profesionales, NetNut tiene más sentido que las herramientas genéricas sin código. No es el punto de partida más fácil para usuarios no técnicos, pero puede ser una pieza sólida dentro de una pila de recopilación más amplia.
Decodo (antes Smartproxy): scraping escalable y herramientas de proxy
Smartproxy se ha rebautizado como Decodo, y su posicionamiento oficial actual apuesta por productos de scraping, proxies y acceso self-service. Eso importa porque las comparativas antiguas que siguen tratando Smartproxy como una marca independiente y actual ya se han quedado atrás.
Decodo sigue siendo atractivo para equipos pequeños que necesitan herramientas de desbloqueo, acceso a proxies y APIs de scraping sin saltar directamente a ciclos de venta empresariales pesados. Es una buena opción intermedia cuando ya has superado las herramientas de scraping ligeras, pero aún no estás listo para los proveedores de infraestructura más caros.
Infatica: API de scraping flexible y soporte de proxies
Infatica combina productos de proxy con una API de scraping y soporte para objetivos renderizados en navegador. Es mejor pensar en él como infraestructura flexible con soporte, no como una app de scraping pensada para principiantes.
Eso hace que Infatica resulte útil para equipos técnicos con sitios dinámicos, requisitos geográficos concretos o necesidades de recopilación personalizadas que no encajan bien en una plantilla de producto rígida.
DataHen: scraping web gestionado para trabajos empresariales a medida
DataHen sigue la vía del servicio gestionado. En lugar de pedirle a tu equipo que opere toda la pila, se posiciona alrededor de servicios personalizados de crawling y web scraping con entrega estructurada.
Es una opción potente cuando el problema real no es “¿cómo raspo esta página?” sino “¿cómo hago que un proveedor se encargue de este flujo de recopilación repetitivo y complicado de principio a fin?”.
HabileData: procesamiento y enriquecimiento de datos validados por humanos
HabileData va menos de glamour del scraping y más de operaciones de datos externalizadas. Su posicionamiento abarca servicios tipo BPO, enriquecimiento, procesamiento de documentos, anotación y trabajos de datos específicos por sector.
Si tu cuello de botella está en la limpieza, la validación, el enriquecimiento o el procesamiento intensivo de documentos más que en la automatización del navegador en sí, HabileData es una comparación más relevante que los proveedores centrados primero en proxies.
Coresignal: datasets públicos de la web listos para usar
Coresignal es la apuesta por datasets dentro de este resumen. Su posicionamiento actual pone el foco en datos públicos de la web en tiempo real sobre empresas, empleados e inteligencia del mercado laboral, lo que lo hace útil cuando quieres datos empresariales aprovechables sin operar tu propio flujo de recopilación completo.
Eso es una decisión de compra distinta a la de las herramientas de scraping tradicionales. Coresignal encaja mejor cuando tu equipo valora más el tiempo hasta el análisis que la flexibilidad de extracción personalizada.
LXT: datos humanos para entrenamiento y evaluación de IA
LXT está diseñado para recopilación de datos para IA, anotación y flujos multilingües con intervención humana. Si tu caso de uso es entrenamiento de modelos, RLHF, evaluación o creación de datos humanos a gran escala, LXT entra de lleno en la conversación aunque no sea un scraper web en el sentido habitual.
Es una mejor opción para equipos de IA que necesitan operaciones de datos humanas especializadas que para equipos cuyo problema principal es extraer datos estructurados de sitios web.
Appen: recopilación gestionada de datos para IA a escala empresarial
Appen sigue siendo un nombre importante en la recopilación gestionada de datos para IA. Su posicionamiento actual se centra en datos de entrenamiento para IA, recopilación personalizada y programas gestionados a escala empresarial.
Si necesitas un socio para iniciativas grandes y complejas de datos para IA más que un producto self-service, Appen sigue siendo relevante. La desventaja es que implica un compromiso empresarial más pesado, no una solución rápida y lista para usar.
Prolific: participantes humanos de alta calidad para investigación y evaluación
Prolific es una de las mejores opciones para obtener input humano con nivel de investigación. Su página de precios destaca el acceso pay-as-you-go y la ausencia de cuota mensual de plataforma en el uso self-service, lo que encaja muy bien con investigación UX, estudios académicos y trabajos de evaluación de IA donde la calidad de los participantes importa.
Si el resultado depende de respuestas humanas creíbles y no solo del volumen de tareas, Prolific suele encajar mejor que los marketplaces de microtareas genéricas.
Si tu shortlist incluye recopilación de datos basada en participantes más que infraestructura de scraping, esta visión general de Prolific muestra cómo es la rama de la categoría orientada a investigación.
Amazon Mechanical Turk: distribución flexible y sensible al coste de tareas humanas
Amazon Mechanical Turk sigue siendo la opción de marketplace flexible para tareas humanas distribuidas. Continúa siendo útil para validación, revisión, etiquetado, encuestas y otros flujos de microtareas donde buscas amplio alcance y control de costes.
La contrapartida no ha cambiado demasiado: MTurk es flexible y económico, pero traslada más responsabilidad al solicitante en materia de control de calidad, diseño de tareas y filtrado. Suele ser aceptable para operadores con experiencia, pero no es la mejor elección cuando la calidad de las respuestas es la prioridad principal.

¿Qué servicio de recopilación de datos encaja con tu empresa?
Aquí va la versión corta de la lista:
- Usuarios no técnicos o equipos de negocio pequeños: Empieza con Thunderbit si quieres el camino más rápido de una página web a una hoja de cálculo.
- Recopilación técnica a escala empresarial: Bright Data u Oxylabs son opciones sólidas para pipelines resistentes y con mucha infraestructura.
- Constructores de flujos sin código: Octoparse sigue siendo una de las opciones más prácticas si quieres control visual.
- Scraping gestionado a medida: DataHen o Infatica tienen sentido cuando necesitas que un proveedor asuma buena parte de la carga operativa.
- Datos de empresas y de fuerza laboral: Coresignal y NetNut son útiles cuando el objetivo es inteligencia empresarial o enriquecimiento.
- Datos de entrenamiento y anotación para IA: LXT y Appen son mejores comparaciones que los proveedores de scraping si la necesidad real son datos generados por humanos.
- Investigación y evaluación con personas: Prolific es mejor para la calidad de los participantes; MTurk es mejor para una distribución flexible y de bajo coste de tareas.
- Infraestructura con presupuesto ajustado: Decodo es un buen punto intermedio entre herramientas simples de scraping y stacks enterprise caros.
La respuesta correcta suele ser una mezcla. Muchos equipos usan una herramienta para scraping con IA de bajo volumen, otra para objetivos que requieren mucha infraestructura y una plataforma aparte para evaluación o anotación humana.
Descargar la extensión de Chrome de Thunderbit
Conclusión: cómo elegir el socio adecuado para recopilación de datos en 2026
En 2026, la recopilación de datos ya no es una sola categoría con una única forma de compra. Algunos compradores necesitan extracción asistida por IA que puedan ejecutar por su cuenta. Otros necesitan infraestructura resistente de proxies y APIs. Otros necesitan recopilación totalmente gestionada. Y otros necesitan personas reales para investigación, anotación o evaluación.
Por eso el mejor proveedor depende menos de rankings genéricos y más de si encaja con tu flujo de trabajo. Si quieres la ruta más rápida hacia datos web útiles sin cargar con una configuración técnica pesada, Thunderbit es el punto de partida más sencillo de esta lista. Si tus problemas son más difíciles, más grandes o más dependientes de infraestructura, los proveedores enterprise y los servicios gestionados pasan a ser mucho más relevantes.
Para la mayoría de los equipos, la decisión inteligente es empezar con la herramienta más pequeña que realmente pueda resolver el trabajo y subir de nivel solo cuando la escala, la fiabilidad o la complejidad de los datos lo exijan.
Descarga el paquete visual actualizado
Prueba la recopilación de datos con IA con Thunderbit Get Started Free
Preguntas frecuentes
1. ¿Qué son los servicios de recopilación de datos y por qué los necesitan las empresas en 2026?
Los servicios de recopilación de datos ayudan a las empresas a reunir información estructurada desde sitios web, plataformas, documentos, APIs o participantes humanos sin depender del copiado y pegado manual. En 2026 son importantes porque los equipos necesitan datos más frescos, flujos de trabajo más rápidos y pipelines más fiables para ventas, ecommerce, investigación e IA.
2. ¿En qué se diferencia Thunderbit de otras herramientas de recopilación de datos?
Thunderbit está pensado para usuarios no técnicos que quieren pasar rápidamente de una página web a datos estructurados. Su extensión de Chrome con IA sugiere campos automáticamente, admite paginación y subpáginas, y exporta de forma limpia a hojas de cálculo y otras herramientas sin requerir una configuración pensada primero para desarrolladores.
3. ¿Qué debo tener en cuenta al elegir un servicio de recopilación de datos?
Fíjate en:
- Encaje con el flujo de trabajo: ¿Estás resolviendo scraping web, recopilación gestionada, enriquecimiento, investigación o generación de datos para IA?
- Facilidad de uso: ¿Puede tu equipo actual utilizarlo con eficacia?
- Escala y fiabilidad: ¿Seguirá funcionando cuando crezca el volumen o los objetivos sean más difíciles?
- Modelo de precios: ¿Plan gratuito, suscripción, pago por uso, pago por tarea o contrato personalizado?
- Carga operativa: ¿Quieres una herramienta self-service, una capa de infraestructura o un socio totalmente gestionado?
4. ¿Qué herramientas son mejores para proyectos a escala empresarial?
Bright Data y Oxylabs son opciones sólidas para recopilación web a escala empresarial cuando importan la infraestructura, la resiliencia y la entrega de grandes volúmenes. DataHen, Appen y otros proveedores gestionados cobran más relevancia cuando quieres que el proveedor asuma directamente más parte del flujo de trabajo.
5. ¿Puedo usar varias herramientas de recopilación de datos para distintas necesidades?
Claro que sí. Muchos equipos combinan herramientas: Thunderbit para scraping ligero con IA, Bright Data u Oxylabs para objetivos técnicos difíciles, Coresignal para datasets ya preparados, y Prolific o MTurk para investigación humana o tareas de etiquetado.




