El mundo digital no para de moverse, y la web va a la par. Después de años metido en SaaS y automatización, he visto una verdad clara: muchas veces, avanzar más rápido significa aprender de lo que ya está hecho. Ya sea para analizar a la competencia, lanzar un producto nuevo o simplemente guardar una copia de tu propio sitio, la habilidad de clonar cualquier sitio web—capturando su contenido, estructura o incluso funcionalidades—puede ser un empujón enorme para cualquier equipo de negocio. Y gracias a herramientas con IA como , lo que antes era cosa de programadores ahora está al alcance de cualquiera que use un navegador.
Pero vamos al grano: clonar un sitio web no es tan fácil como darle a “Guardar como” y listo. Los sitios modernos son dinámicos, interactivos y a veces más escurridizos que un calamar. En esta guía te cuento qué significa realmente “clonar cualquier sitio web”, por qué es útil para los negocios, los retos que implica y—lo más importante—cómo hacerlo de forma segura, eficiente y legal usando herramientas avanzadas como Thunderbit.
¿Qué implica realmente clonar cualquier sitio web?
Vamos a lo básico. Cuando hablamos de “clonar un sitio web”, puede significar varias cosas:
- Clonar el diseño: Hacer un sitio que se vea y funcione igual que el original.
- Clonar el contenido: Copiar textos, imágenes, información de productos y otros datos visibles.
- Clonar la funcionalidad: Replicar funciones como buscadores, formularios o elementos interactivos.
Para la mayoría de los equipos de negocio, el verdadero valor está en copiar el contenido y los datos visibles—lo que se puede ver y analizar, no necesariamente el código interno o la lógica propietaria. Es como sacar una foto de la parte pública de un sitio y convertirla en datos estructurados para análisis, prototipos o archivo.
Y antes de que lo preguntes: clonar no es robar ni plagiar. De hecho, la mayoría de los usos son totalmente legales—como investigación de mercado, prototipado rápido o crear un respaldo offline por temas legales. El objetivo es ahorrar tiempo y conseguir información aprovechando lo que ya funciona, no reinventar la rueda ni meterse en líos de derechos.
¿Por qué clonar cualquier sitio web? Casos de uso clave para empresas
Te sorprendería saber cuántos equipos dependen de la clonación de sitios web en su día a día. Aquí tienes algunos de los casos de uso más comunes:
| Caso de uso | Descripción y beneficio para el negocio |
|---|---|
| Monitoreo de precios de la competencia | Extrae páginas de productos de la competencia para seguir precios y stock. Permite precios dinámicos—un minorista en Reino Unido logró un aumento del 4% en ventas. |
| Generación de leads y enriquecimiento de CRM | Clona directorios o páginas de LinkedIn para recopilar prospectos. Automatizar esto puede ahorrar hasta un 80% del tiempo. |
| Reutilización de contenido | Duplica FAQs, blogs o reseñas para curar información o adaptarla a tu audiencia. |
| Prototipado y diseño rápido | Clona el front-end de sitios existentes para acelerar nuevos proyectos—prototipa en días en vez de semanas. |
| Respaldo y archivo | Crea copias completas de sitios web para cumplimiento o registro. |
Y esto es solo el principio. Investigadores pueden clonar páginas de redes sociales para analizar tendencias, especialistas SEO pueden copiar estructuras de sitios para análisis offline, y casi dependen de datos extraídos de la web. El retorno de inversión viene de la velocidad y el conocimiento—en vez de recopilar datos manualmente o rehacer diseños, lo tienes todo en un solo paso.
Los retos de clonar cualquier sitio web: mucho más que copiar y pegar
Si clonar un sitio fuera tan fácil como “Copiar > Pegar”, cualquiera lo haría. Pero si alguna vez lo intentaste, sabes que la cosa es más complicada.
Por qué copiar a mano no basta
- Contenido dinámico: Muchos sitios cargan datos con JavaScript, así que un simple “Guardar página como” puede dejarte solo con la estructura—sin imágenes ni datos en vivo, solo una página rota ().
- APIs y scripts: Parte del contenido se obtiene de APIs después de cargar la página. Copiar el HTML no basta.
- Requiere inicio de sesión: Si la información está tras un login, necesitas una herramienta que funcione con sesiones autenticadas.
- Medidas anti-scraping: Algunos sitios usan CAPTCHAs, límites de velocidad o detección de bots para bloquear la automatización.
- Límites legales y éticos: Que puedas copiar algo no significa que debas hacerlo. El copyright y los términos de uso importan—y mucho.
En resumen, clonar un sitio web implica superar retos técnicos y respetar límites éticos. No se trata solo de obtener los datos, sino de hacerlo bien—y de forma responsable.
Comparativa de soluciones para clonar sitios web: de lo manual a la IA
Hablemos de herramientas. Hay varias formas de clonar un sitio web, cada una con sus ventajas y desventajas:
| Método | Facilidad de uso | Precisión | Contenido dinámico | Opciones de exportación | Cumplimiento legal | Mantenimiento |
|---|---|---|---|---|---|---|
| Copia/descarga manual | Moderada | Baja | Mala | HTML/CSS/JS | Depende del usuario | Alto (se rompe fácil) |
| Raspado web tradicional | Baja | Alta* | Buena* | CSV/Excel/JSON | Depende del usuario | Alto (frágil) |
| Herramientas con IA (Thunderbit) | Muy alta | Alta | Excelente | Excel/Sheets/Notion | Fácil de usar | Bajo |
*Si sabes lo que haces y lo configuras bien.
Copia/descarga manual
Herramientas como HTTrack o el “Guardar como” del navegador pueden servir para sitios estáticos simples, pero son y fallan con contenido dinámico. Suele haber imágenes que no cargan, estilos rotos y carpetas llenas de archivos que no sabes ni para qué sirven.
Raspado web tradicional
Incluye escribir scripts (Python, BeautifulSoup, etc.) o usar scrapers visuales donde seleccionas lo que quieres extraer. Son potentes, pero . El mantenimiento es un dolor—si el sitio cambia, tu scraper deja de funcionar.
Herramientas con IA (Thunderbit)
Aquí es donde la cosa se pone buena. usa IA para “entender” la página, así que no tienes que definir cada detalle. Solo haz clic en “AI Suggest Fields”, deja que detecte los datos automáticamente y listo. Gestiona contenido dinámico, navegación por varias páginas y exporta directo a Excel, Google Sheets, Airtable o Notion. Además, está pensado para gente sin conocimientos técnicos—no necesitas programar.
Si quieres ver más sobre extensiones de Chrome para web scraper, revisa .
Paso a paso: cómo clonar cualquier sitio web con Thunderbit
¿Listo para ponerte manos a la obra? Así clono yo cualquier sitio web con Thunderbit, paso a paso.
Paso 1: Instala y configura Thunderbit
Primero, entra en la y crea una cuenta gratuita. Luego instala la . Es tan fácil como instalar cualquier otra extensión—solo un par de clics.
Una vez instalada, verás el icono de Thunderbit en la barra de Chrome. Haz clic, inicia sesión y ya puedes empezar tu primer proyecto. Consejo: fija el icono para tenerlo siempre a mano. Si vas a extraer datos de un sitio que requiere login, asegúrate de estar conectado antes de empezar—Thunderbit funciona con tu sesión actual del navegador.
Paso 2: Usa la IA para identificar y estructurar los datos
Navega al sitio que quieres clonar (por ejemplo, la página de productos de un competidor). Abre el panel lateral de Thunderbit y crea un nuevo proyecto de extracción. Aquí viene la magia: haz clic en “AI Suggest Columns” (a veces llamado “AI Suggest Fields”) y la IA de Thunderbit analizará la página, proponiendo automáticamente campos de datos—como nombre del producto, precio, URL de imagen, valoración y más.
Puedes revisar, ajustar o añadir columnas según lo que necesites. ¿Quieres capturar un campo extra, como “Disponibilidad” o “SKU”? Solo agrégalo y la IA intentará rellenarlo. No necesitas saber HTML—la IA hace el trabajo duro.
Paso 3: Extrae y exporta los datos del sitio web
Cuando tengas las columnas listas, pulsa “Scrape” (o “Start”). Thunderbit extraerá todos los datos de los campos seleccionados, fila por fila. Si la página tiene varios elementos (como una lista de productos), los capturará todos.
¿Y si hay paginación o scroll infinito? Thunderbit gestiona la mayoría de los casos automáticamente—si hay un botón “Siguiente” o carga por scroll, seguirá avanzando. Para casos muy complejos, puedes desplazarte manualmente o usar ajustes avanzados, pero para la mayoría de sitios de negocio, funciona sin problemas.
Al terminar, verás tus datos en una tabla ordenada. Exportar es facilísimo: envíalos directamente a Excel, Google Sheets, Airtable o Notion. Olvídate de pelear con CSV—obtienes datos estructurados, listos para usar.
Para más detalles, revisa .
Potencia tu clon: extracción de subpáginas para copias completas
Aquí es donde Thunderbit realmente brilla: la extracción de subpáginas. Muchos sitios muestran resúmenes en la página principal (como nombres y precios), pero los detalles importantes—descripciones, especificaciones, reseñas—están en subpáginas individuales.
La función de subpáginas de Thunderbit te permite ir más allá. Actívala y la IA seguirá los enlaces desde la página principal a cada página de detalle, capturando la información extra y fusionándola en tu conjunto de datos principal. Por ejemplo, si clonas la categoría “chaquetas de invierno” de una tienda online, Thunderbit puede entrar en cada producto y extraer materiales, disponibilidad, opiniones de clientes y más—logrando una copia completa y estructurada de todo el catálogo.
Esto ahorra muchísimo tiempo a los equipos de negocio. Ya sea para crear una lista de leads, archivar una base de conocimiento o analizar un catálogo completo, la extracción de subpáginas asegura que no te pierdas nada.
Para ver un ejemplo real, consulta .
Cumplimiento legal: cómo clonar cualquier sitio web de forma segura
Vamos con el tema delicado: ¿Es legal clonar cualquier sitio web?
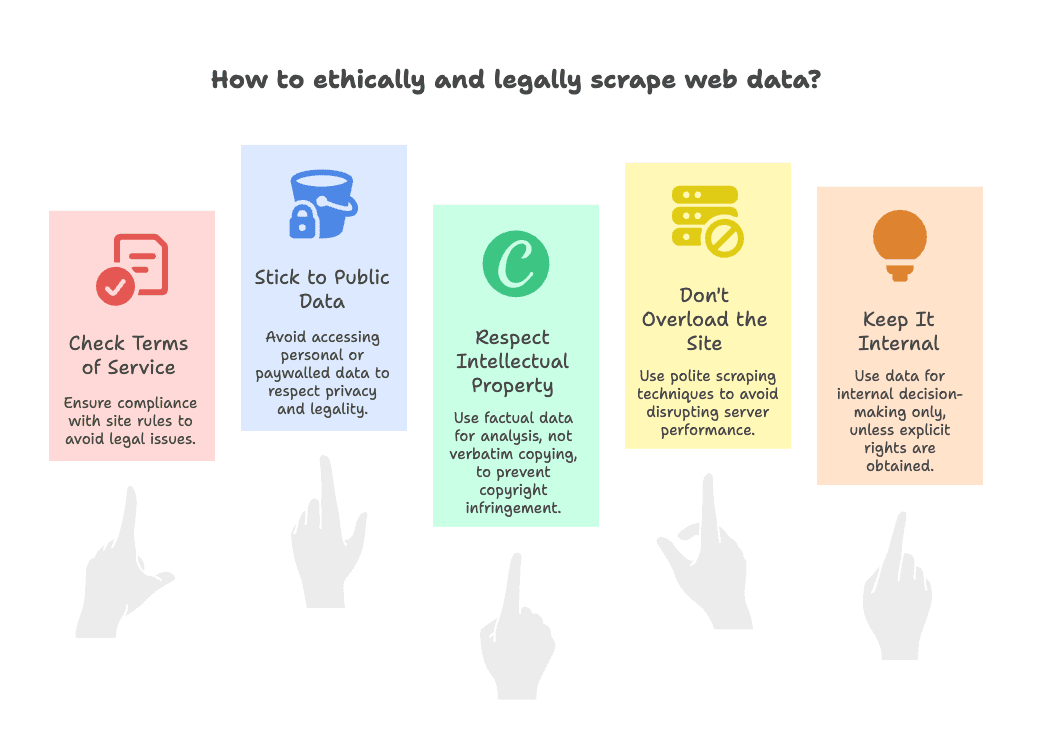
La respuesta corta: normalmente sí, siempre que sigas unas reglas básicas. Aquí tienes mi checklist de cumplimiento:
- Revisa los Términos de Servicio: Algunos sitios prohíben explícitamente el scraping. Si es así, actúa con cautela—usa los datos solo internamente, no los publiques ().
- Limítate a datos públicos: Extrae solo lo que sea visible sin iniciar sesión. Evita datos personales, emails o información tras muros de pago ().
- Respeta la propiedad intelectual: Los datos fácticos (precios, nombres de productos) suelen estar permitidos. Copiar contenido creativo tal cual (como blogs o imágenes) puede ser un problema de copyright—úsalo para análisis, no para crear un sitio clonado ().
- No sobrecargues el sitio: Haz scraping de forma responsable—no envíes miles de peticiones en segundos. Thunderbit limita la velocidad automáticamente, pero siempre sé considerado ().
- Uso interno: A menos que tengas derechos explícitos, utiliza los datos clonados solo para decisiones internas, no para redistribución pública.
Thunderbit facilita el cumplimiento permitiendo exportar datos directamente a plataformas seguras como Google Sheets o Airtable, manteniendo la información gestionada y compartida solo dentro de tu organización. Para más consejos legales, revisa .
Consejos avanzados: exprime Thunderbit al clonar sitios web
Cuando ya domines lo básico, aquí tienes algunos trucos para llevar la clonación de sitios al siguiente nivel:
- Gestiona sitios dinámicos e interactivos: Si el contenido aparece tras una acción (como “Ver todas las reseñas”), haz la acción tú mismo y luego ejecuta Thunderbit. La IA capturará lo que esté visible. Para scroll infinito, desplázate por partes o usa la paginación automática ().
- Prompts personalizados para la IA: Guía a la IA nombrando las columnas de forma específica—por ejemplo, “Autor (texto después de Por:)” o “Resumen de ventajas”. La IA de Thunderbit reconoce el contexto, así que nombres claros funcionan como mini-instrucciones ().
- IA para transformar datos: Usa la función de resumen de Thunderbit o conéctalo con herramientas como ChatGPT para analizar, categorizar o traducir datos al instante ().
- Programación para clones periódicos: Configura extracciones programadas para monitorizar sitios a lo largo del tiempo—ideal para seguir precios de la competencia o nuevas ofertas de empleo ().
- Extracción masiva de URLs: Proporciona a Thunderbit una lista de URLs y extraerá cada una automáticamente—perfecto si ya tienes los enlaces recopilados.
- Plantillas para sitios populares: Usa las plantillas instantáneas de Thunderbit para sitios como Amazon o Zillow y personalízalas según tus necesidades ().
- Gestiona casos complejos: Si te topas con CAPTCHAs o diseños extraños, prueba a ejecutar el scraper en dos fases o ajusta tus columnas. La IA de Thunderbit es robusta, pero nunca está de más revisar los resultados.
Para flujos de trabajo aún más avanzados, revisa .
Conclusión y puntos clave: clona cualquier sitio web con confianza
Clonar sitios web ya no es solo cosa de desarrolladores—es una técnica práctica y accesible que empodera a equipos de ventas, marketing y operaciones. Quédate con esto:
- Valor para el negocio: Clonar sitios web aporta verdadero retorno—ya sea superando a la competencia, ahorrando tiempo o tomando mejores decisiones ().
- Retos y soluciones: Los sitios modernos son complejos, pero herramientas avanzadas como Thunderbit hacen que clonar sea preciso, rápido y sencillo—hasta para usuarios sin experiencia técnica.
- Ventaja Thunderbit: Con funciones como “AI Suggest Columns” y extracción de subpáginas, Thunderbit convierte horas de trabajo manual en un proceso de dos clics.
- Cumplimiento ante todo: Clona siempre de forma responsable—limítate a datos públicos, respeta la PI y usa los datos para análisis o decisiones internas.
- Llega más lejos: Con consejos avanzados e integraciones, Thunderbit puede con los sitios y flujos de trabajo más exigentes.
Así que, la próxima vez que veas la página de productos de un competidor, un directorio de leads o una base de conocimiento que te gustaría analizar—recuerda que tienes las herramientas para clonar los datos de ese sitio con total confianza. Úsalas con responsabilidad y que tus proyectos impulsados por datos prosperen.
Preguntas frecuentes
1. ¿Es legal clonar cualquier sitio web para uso empresarial?
En general, sí—si te limitas a datos públicos, respetas la propiedad intelectual y usas los datos internamente. Revisa siempre los términos de uso del sitio y evita extraer datos personales o con copyright sin permiso. Más información en .
2. ¿Cuál es la diferencia entre clonar un sitio web y hacer scraping?
Clonar suele referirse a copiar el contenido, estructura o diseño de un sitio, mientras que el raspado web es el proceso de extraer datos específicos. Con herramientas como Thunderbit, la línea se difumina—puedes extraer y estructurar datos para “clonar” justo lo que necesitas.
3. ¿Thunderbit puede manejar contenido dinámico y subpáginas?
¡Sí! La IA de Thunderbit está diseñada para gestionar contenido dinámico (como datos cargados por JavaScript) y puede seguir enlaces para extraer subpáginas, fusionando toda la información en un solo conjunto de datos. Es una de las formas más sencillas de obtener una copia completa de un sitio web.
4. ¿Cómo exporto los datos clonados a Excel o Google Sheets?
Después de extraer datos con Thunderbit, puedes exportarlos directamente a Excel, Google Sheets, Airtable o Notion con solo un par de clics. No necesitas formatear nada a mano—los datos están listos para analizar o compartir.
5. ¿Consejos avanzados para clonar sitios web complejos?
Usa prompts personalizados para la IA para extraer campos precisos, programa extracciones regulares para monitorizar cambios y aprovecha las funciones de extracción masiva de URLs y plantillas de Thunderbit para mayor eficiencia. En sitios interactivos, realiza las acciones manualmente antes de extraer y revisa siempre tus datos para asegurar su calidad.