
Si alguna vez has intentado sacar datos de una página web que solo muestra contenido cuando haces scroll, esconde los precios tras un login o cambia de diseño cada dos por tres, sabes que esto no es nada sencillo. Los raspadores web estáticos ya se quedan cortos. De hecho, más del ya dependen del web scraping para conseguir datos alternativos, y el automatizan el monitoreo de precios de la competencia. Pero aquí está el truco: la mayoría de esos datos están en webs dinámicas, cargadas con JavaScript y escondidas tras interacciones de usuario. Ahí es donde la automatización con navegadores sin cabeza y herramientas como Puppeteer marcan la diferencia.
Como alguien que lleva años creando soluciones de automatización e IA (y sí, también raspando webs para equipos de ventas y operaciones), he comprobado cómo Puppeteer te abre puertas a datos que los raspadores tradicionales ni huelen. Pero también he visto que programar puede ser un muro para muchos usuarios de negocio. Por eso, en esta guía te cuento qué es un Puppeteer scraper, cómo usarlo para web scraping y cuándo te conviene algo aún más fácil, como , nuestro raspador web IA sin código.
¿Qué es Puppeteer Scraper? Un vistazo rápido
 Vamos a lo básico. es una librería open-source de Node.js creada por Google que te deja controlar un navegador Chrome o Chromium sin cabeza usando JavaScript. O sea, es como tener un robot que puede abrir webs, hacer clics, rellenar formularios, hacer scroll y, lo más importante, extraer datos, todo sin que veas nada en pantalla.
Vamos a lo básico. es una librería open-source de Node.js creada por Google que te deja controlar un navegador Chrome o Chromium sin cabeza usando JavaScript. O sea, es como tener un robot que puede abrir webs, hacer clics, rellenar formularios, hacer scroll y, lo más importante, extraer datos, todo sin que veas nada en pantalla.
¿Por qué mola Puppeteer?
- Puede renderizar contenido dinámico—espera a que el JavaScript cargue, igual que haría una persona.
- Puede simular acciones de usuario: clics, escribir, hacer scroll e incluso manejar pop-ups.
- Es ideal para sacar datos de sitios donde la info aparece tras interactuar, como listados de e-commerce, feeds sociales o paneles de control.
¿Cómo se compara con otras herramientas?
- Selenium: El clásico de la automatización de navegadores. Va bien con muchos navegadores y lenguajes, pero es más pesado y algo viejuno. Perfecto para pruebas cruzadas, pero Puppeteer es más ágil si trabajas con Chrome/Node.js.
- Thunderbit: Aquí me emociono. Thunderbit es un raspador web sin código, potenciado por IA, que funciona directo en tu navegador. En vez de programar, solo haces clic en “Sugerir campos con IA” y la IA detecta qué extraer. Es perfecto para usuarios de negocio que quieren resultados sin programar (más adelante te cuento más).
En resumen: Puppeteer = control total (si sabes programar). Thunderbit = máxima comodidad (si no quieres programar).
¿Por qué el Web Scraping con Puppeteer es clave para los usuarios de negocio?
Seamos sinceros: el web scraping ya no es solo cosa de hackers o científicos de datos. Equipos de ventas, operaciones, marketing e incluso inmobiliarias usan datos web para sacar ventaja. Y con tanta información clave bloqueada en webs dinámicas, Puppeteer suele ser la llave para acceder a ella.
Aquí tienes algunos ejemplos reales:
| Caso de uso | ¿Quién se beneficia? | Impacto / ROI |
|---|---|---|
| Generación de leads | Ventas, Desarrollo de Negocio | Automatiza la creación de listas de prospectos; ahorra más de 8 horas/semana por comercial (caso de estudio) |
| Monitoreo de precios | E-commerce, Operaciones Producto | Seguimiento en tiempo real de la competencia; una empresa ahorró $3.8M/año (fuente) |
| Investigación de mercado | Marketing, Estrategia, Finanzas | 67% de los asesores de inversión usan datos extraídos; hasta 890% de ROI en algunos casos (fuente) |
| Agregación inmobiliaria | Agentes, Analistas | Extrae más de 50 páginas de propiedades en minutos, no horas (fuente) |
| Seguimiento de cumplimiento | Operaciones, Legal | Automatiza el monitoreo; una aseguradora evitó $50M en sanciones (fuente) |
Y ojo: gastan una cuarta parte de su semana en tareas repetitivas como recopilar datos. Automatizar esto con web scraping no es solo un plus—es una ventaja competitiva.
Primeros pasos: Cómo configurar tu Puppeteer Scraper
¿Listo para ponerte manos a la obra? Así puedes tener Puppeteer funcionando en menos de 10 minutos (si tienes algo de experiencia con JavaScript):
1. Instala Node.js
Puppeteer va sobre Node.js. Descarga la última versión LTS en .
2. Crea una carpeta para tu proyecto
Abre la terminal y escribe:
1mkdir puppeteer-scraper-demo
2cd puppeteer-scraper-demo
3npm init -y3. Instala Puppeteer
1npm install puppeteerEsto también bajará una versión de Chromium (unos 100MB).
4. Crea tu primer script
Haz un archivo llamado scrape.js:
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
6 const title = await page.title();
7 console.log('Page title:', title);
8 await browser.close();
9})();Ejecuta el script con:
1node scrape.jsSi ves “Page title: Example Domain”, ¡lo lograste! Chrome automatizado.
Construyendo tu primer script de Web Scraping con Puppeteer
Vamos a lo práctico. Imagina que quieres extraer frases de (un sitio de pruebas para raspadores).
Paso 1: Ve a la página
1await page.goto('http://quotes.toscrape.com', { waitUntil: 'networkidle0' });Paso 2: Extrae los datos
1const quotes = await page.evaluate(() => {
2 return Array.from(document.querySelectorAll('.quote')).map(node => ({
3 text: node.querySelector('.text')?.innerText.trim(),
4 author: node.querySelector('.author')?.innerText.trim(),
5 tags: Array.from(node.querySelectorAll('.tag')).map(tag => tag.innerText.trim())
6 }));
7});
8console.log(quotes);Paso 3: Gestiona la paginación
1let hasNext = true;
2let allQuotes = [];
3while (hasNext) {
4 // Extrae las frases como antes
5 const quotes = await page.evaluate(/* ... */);
6 allQuotes.push(...quotes);
7 const nextButton = await page.$('li.next > a');
8 if (nextButton) {
9 await Promise.all([
10 page.click('li.next > a'),
11 page.waitForNavigation({ waitUntil: 'networkidle0' })
12 ]);
13 } else {
14 hasNext = false;
15 }
16}Paso 4: Guarda en JSON
1const fs = require('fs');
2fs.writeFileSync('quotes.json', JSON.stringify(allQuotes, null, 2));¡Y ya tienes un Puppeteer scraper básico que navega, extrae, pagina y guarda los datos!
Técnicas avanzadas con Puppeteer Scraper: Cómo manejar contenido dinámico
La mayoría de webs reales no son tan sencillas como una lista estática. Así puedes enfrentarte a los retos más comunes:
1. Esperar a que carguen elementos dinámicos
1await page.waitForSelector('.product-list-item');Esto asegura que el contenido que buscas ya está cargado antes de intentar extraerlo.
2. Simular acciones de usuario
- Clic en un botón:
await page.click('#load-more'); - Escribir en un campo:
await page.type('#search', 'laptop'); - Scroll infinito:
1let previousHeight = await page.evaluate('document.body.scrollHeight'); 2while (true) { 3 await page.evaluate('window.scrollTo(0, document.body.scrollHeight)'); 4 await page.waitForTimeout(1500); 5 const newHeight = await page.evaluate('document.body.scrollHeight'); 6 if (newHeight === previousHeight) break; 7 previousHeight = newHeight; 8}
3. Gestionar inicios de sesión
1await page.goto('https://exampleshop.com/login');
2await page.type('#login-username', 'myusername');
3await page.type('#login-password', 'mypassword');
4await page.click('#login-button');
5await page.waitForNavigation({ waitUntil: 'networkidle0' });4. Trabajar con datos cargados por AJAX A veces los datos no están en el DOM, sino que llegan por una llamada a la API. Puedes interceptar las respuestas así:
1page.on('response', async response => {
2 if (response.url().includes('/api/products')) {
3 const data = await response.json();
4 // Procesa los datos
5 }
6});Ejemplo real: Extrayendo datos de productos de un e-commerce
Vamos a juntar todo. Imagina que quieres sacar nombres, precios e imágenes de productos de un e-commerce (de prueba) tras iniciar sesión.
1const puppeteer = require('puppeteer');
2const fs = require('fs');
3(async () => {
4 const browser = await puppeteer.launch({ headless: true });
5 const page = await browser.newPage();
6 // Paso 1: Inicia sesión
7 await page.goto('https://exampleshop.com/login');
8 await page.type('#login-username', 'myusername');
9 await page.type('#login-password', 'mypassword');
10 await page.click('#login-button');
11 await page.waitForNavigation({ waitUntil: 'networkidle0' });
12 // Paso 2: Ve a la categoría
13 await page.goto('https://exampleshop.com/category/laptops', { waitUntil: 'networkidle0' });
14 // Paso 3: Extrae los productos
15 const products = await page.evaluate(() => {
16 return Array.from(document.querySelectorAll('.product-item')).map(item => ({
17 name: item.querySelector('.product-title')?.innerText.trim() || '',
18 price: item.querySelector('.product-price')?.innerText.trim() || '',
19 image: item.querySelector('img.product-image')?.src || ''
20 }));
21 });
22 // Paso 4: Guarda en JSON
23 fs.writeFileSync('products.json', JSON.stringify(products, null, 2));
24 await browser.close();
25})();Este script inicia sesión, navega, extrae y guarda los datos automáticamente. Si necesitas más, puedes añadir bucles para paginación o entrar en cada producto para más detalles.
Thunderbit: Haciendo Puppeteer Scraper más sencillo con IA
Si has llegado hasta aquí y piensas: “Genial, pero no quiero programar cada vez que necesito un nuevo dataset”, no eres el único. Por eso creamos .
¿Por qué Thunderbit es diferente?
- Sin código: Solo instala la , abre la página que quieres extraer y haz clic en “Sugerir campos con IA”.
- Detección inteligente de campos: Thunderbit analiza la página y sugiere las mejores columnas para extraer—como “Nombre del producto”, “Precio”, “Imagen”, etc.
- Gestiona contenido dinámico: ¿Scroll infinito, pop-ups, subpáginas? La IA de Thunderbit lo gestiona, navegando por la paginación o entrando en cada producto para enriquecer tus datos.
- Exportación instantánea: Manda tus datos directo a Excel, Google Sheets, Notion o Airtable con un solo clic. Sin costes extra por exportar.
- Plantillas para sitios populares: ¿Necesitas extraer datos de Amazon, Zillow o LinkedIn? Thunderbit tiene plantillas listas para usar—sin configurar nada.
- Raspado en la nube o en el navegador: Si tienes mucho volumen, Thunderbit puede extraer hasta 50 páginas a la vez en la nube.
He visto usuarios pasar de “Ojalá pudiera conseguir estos datos” a “Aquí tienes mi hoja de cálculo” en menos de cinco minutos. ¿Lo mejor? No tienes que preocuparte por scripts que se rompen cuando la web cambia—la IA de Thunderbit se adapta sola.
Puppeteer vs. Thunderbit: ¿Qué herramienta de Web Scraping elegir?
Entonces, ¿cuál te conviene? Así se lo explico a los equipos:
| Factor | Puppeteer (con código) | Thunderbit (Sin código, IA) |
|---|---|---|
| Facilidad de uso | Requiere conocimientos de JavaScript y DOM | Punto y clic, la IA sugiere los campos |
| Velocidad de inicio | Horas o días para tareas complejas | Minutos—solo instala y empieza |
| Control/Flexibilidad | Máximo: puedes programar cualquier lógica personalizada | Alto para casos estándar; menos adecuado para flujos muy personalizados |
| Contenido dinámico | Programación manual para esperas, clics, scrolls | La IA gestiona automáticamente contenido dinámico, paginación y subpáginas |
| Mantenimiento | Tú mantienes los scripts—hay que actualizarlos si la web cambia | La IA se adapta a los cambios de diseño; menos mantenimiento para el usuario |
| Exportación de datos | Debes programar la lógica de exportación | Exportación con un clic a Excel, Sheets, Notion, Airtable, CSV, JSON |
| Ideal para | Desarrolladores, extracciones personalizadas o a gran escala | Usuarios de negocio, proyectos rápidos, equipos sin perfil técnico |
| Coste | Gratis (salvo tu tiempo y la infraestructura) | Hay plan gratuito; los planes de pago son por créditos (ver Precios de Thunderbit) |
En resumen:
- Usa Puppeteer si necesitas control total, tienes recursos de programación o quieres integrar el scraping en una app más grande.
- Usa Thunderbit si buscas resultados rápidos, no quieres programar o necesitas empoderar a compañeros sin perfil técnico.
La verdad, he visto equipos usar ambos: Thunderbit para resultados rápidos y prototipos, Puppeteer para integraciones profundas o casos muy específicos.
Checklist paso a paso: Cómo ejecutar un proyecto de Web Scraping con Puppeteer
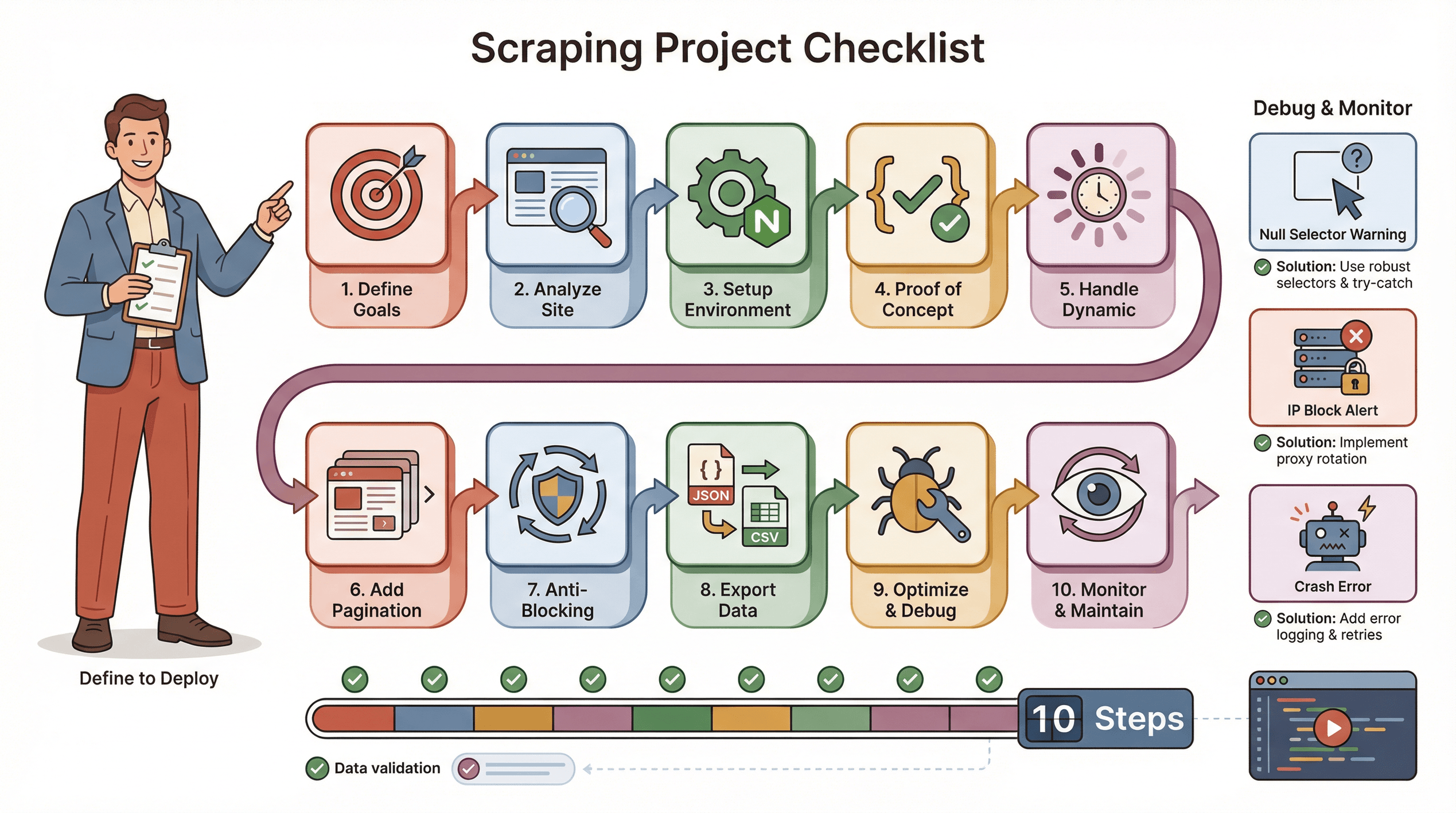 Aquí tienes mi checklist para que tu proyecto de scraping con Puppeteer vaya sobre ruedas:
Aquí tienes mi checklist para que tu proyecto de scraping con Puppeteer vaya sobre ruedas:
- Define tus objetivos: ¿Qué datos necesitas? ¿Dónde están?
- Analiza el sitio: ¿Es dinámico? ¿Requiere login? ¿Tiene medidas anti-bots?
- Prepara el entorno: Node.js, Puppeteer y cualquier librería auxiliar.
- Haz una prueba de concepto: Empieza con una página, ajusta los selectores.
- Gestiona contenido dinámico: Usa
waitForSelector, simula clics/scrolls según sea necesario. - Añade paginación o bucles: Extrae todas las páginas, no solo una.
- Implementa tácticas anti-bloqueo: Aleatoriza los tiempos, usa un User-Agent real, proxies si hace falta.
- Exporta y valida los datos: Guarda en JSON/CSV, revisa que esté todo.
- Optimiza y gestiona errores: Añade try/catch, registra el progreso, gestiona datos faltantes.
- Monitorea y mantén: Las webs cambian—prepárate para actualizar tu script.
Tips para resolver problemas:
- Si los selectores devuelven null, revisa el HTML y usa esperas.
- Si te bloquean, baja la velocidad, rota IPs o usa plugins de camuflaje.
- Si el script falla, revisa fugas de memoria o excepciones no controladas.
Conclusión y puntos clave
El web scraping se ha vuelto esencial para los equipos que quieren ser data-driven. Puppeteer te da el poder de sacar información incluso de los sitios más dinámicos y llenos de JavaScript—pero necesitas saber programar y estar pendiente del mantenimiento. Para quienes quieren saltarse el código y obtener los datos directo, Thunderbit es una alternativa sin código, rápida, flexible y sorprendentemente potente.
Mi consejo:
- Si tienes perfil técnico y buscas personalización avanzada, empieza con Puppeteer.
- Si quieres rapidez, sencillez y menos líos de mantenimiento, prueba (la es ideal para empezar).
- Para la mayoría de equipos, combinar ambas cubre el 99% de las necesidades de datos web.
¿Quieres más guías como esta? Pásate por el para tutoriales, comparativas y lo último en web scraping con IA.
Preguntas frecuentes
1. ¿Qué es Puppeteer scraper y para qué se usa en web scraping?
Puppeteer es una librería de Node.js que permite controlar un navegador Chrome sin cabeza con JavaScript. Se usa para web scraping porque puede cargar contenido dinámico, simular acciones de usuario y extraer datos de sitios que los raspadores tradicionales no pueden manejar.
2. ¿Cómo se compara Puppeteer con Selenium y Thunderbit?
Selenium funciona con varios navegadores y lenguajes, pero es más pesado. Puppeteer está optimizado para Chrome/Node.js y es más rápido para muchas tareas de scraping. Thunderbit, en cambio, es una herramienta sin código, potenciada por IA, que permite a usuarios no técnicos extraer datos con solo unos clics.
3. ¿Cuáles son los principales beneficios de negocio del web scraping con Puppeteer?
Automatizar la recopilación de datos ahorra tiempo, reduce errores y permite obtener insights en tiempo real para ventas, marketing, operaciones y más. Los casos de uso van desde generación de leads hasta monitoreo de precios e investigación de mercado.
4. ¿Cuáles son los mayores retos al hacer scraping con Puppeteer?
Los principales retos son manejar contenido dinámico, evitar bloqueos anti-bots y mantener los scripts cuando las webs cambian. Hay que programar para gestionar esperas, simular interacciones y controlar errores.
5. ¿Cuándo debería usar Thunderbit en vez de Puppeteer?
Usa Thunderbit si quieres evitar programar, necesitas resultados rápidos o quieres que compañeros sin perfil técnico puedan extraer datos. Es ideal para tareas estándar, proyectos rápidos o cuando solo quieres exportar datos a Excel o Google Sheets sin complicaciones.
¿Listo para probar una forma más inteligente de extraer datos? o explora más guías en el . ¡Feliz scraping!
Más información