
Si alguna vez has intentado extraer datos de un sitio web que carga contenido a medida que haces scroll, oculta precios detrás de un inicio de sesión o parece cambiar su diseño cada dos semanas, sabes que el reto es real. Los scrapers estáticos ya no son suficientes. De hecho, más del ya dependen del web scraping para obtener datos alternativos, y el automatizan el seguimiento de precios de la competencia. Pero aquí está la clave: gran parte de esos datos vive en sitios dinámicos, cargados por JavaScript y ocultos detrás de interacciones del usuario. Ahí es donde entran la automatización de navegadores sin interfaz y herramientas como Puppeteer.
Como alguien que ha pasado años creando herramientas de automatización e IA —y, sí, extrayendo bastantes datos de sitios web para equipos de ventas y operaciones—, he visto de primera mano cómo Puppeteer puede desbloquear datos que los scrapers tradicionales no detectan. Pero también he visto cómo la carga de programación puede ser un obstáculo para los usuarios de negocio. Así que en esta guía te mostraré exactamente qué es un puppeteer scraper, cómo usarlo para puppeteer web scraping y cuándo quizá te convenga optar por algo todavía más simple, como , nuestro web scraper sin código y con IA.
¿Qué es Puppeteer Scraper? Una visión rápida
 Empecemos por lo básico. es una biblioteca open source de Node.js creada por Google que te permite controlar un navegador Chrome o Chromium sin interfaz usando JavaScript. Dicho de forma simple: es como tener un robot que puede abrir páginas web, hacer clic en botones, rellenar formularios, hacer scroll y, lo más importante, extraer datos, todo sin mostrar nada en tu pantalla.
Empecemos por lo básico. es una biblioteca open source de Node.js creada por Google que te permite controlar un navegador Chrome o Chromium sin interfaz usando JavaScript. Dicho de forma simple: es como tener un robot que puede abrir páginas web, hacer clic en botones, rellenar formularios, hacer scroll y, lo más importante, extraer datos, todo sin mostrar nada en tu pantalla.
¿Qué hace especial a Puppeteer?
- Puede renderizar contenido dinámico: es decir, espera a que JavaScript cargue, igual que un usuario real.
- Puede simular acciones de usuario: hacer clic, escribir, desplazarse e incluso manejar ventanas emergentes.
- Es perfecto para extraer datos de sitios donde la información solo aparece tras una interacción, como listados de e-commerce, feeds sociales o paneles de control.
¿Cómo se compara con otras herramientas?
- Selenium: el veterano de la automatización de navegadores. Funciona con muchos navegadores y lenguajes, pero es más pesado y algo más clásico. Es excelente para pruebas multiplataforma, pero Puppeteer es más ágil para proyectos con Chrome y Node.js.
- Thunderbit: aquí es donde me entusiasmo. Thunderbit es un web scraper sin código y con IA que funciona dentro de tu navegador. En lugar de escribir scripts, solo haces clic en “AI Suggest Fields” y dejas que la IA decida qué extraer. Es ideal para usuarios de negocio que quieren resultados sin código (hablo más de esto luego).
En resumen: Puppeteer = control máximo (si programas). Thunderbit = comodidad máxima (si no quieres programar).
Por qué el web scraping con Puppeteer importa para los usuarios de negocio
Seamos claros: el web scraping ya no es solo para hackers o científicos de datos. Equipos de ventas, operaciones, marketing e incluso de bienes raíces están usando datos web para ganar ventaja. Y con tanta información crítica para el negocio bloqueada detrás de sitios dinámicos, Puppeteer suele ser la clave para desbloquearla.
Estos son algunos casos de uso reales:
| Caso de uso | Quién se beneficia | Impacto / ROI |
|---|---|---|
| Generación de leads | Ventas, desarrollo de negocio | Automatiza la creación de listas de prospectos; ahorra más de 8 horas/semana por representante (caso de estudio) |
| Seguimiento de precios | E-commerce, operaciones de producto | Seguimiento de la competencia en tiempo real; una empresa ahorró 3,8 millones de dólares al año (fuente) |
| Investigación de mercado | Marketing, estrategia, finanzas | El 67% de los asesores de inversión usa datos extraídos de la web; en algunos casos, el ROI llega hasta el 890% (fuente) |
| Agregación inmobiliaria | Agentes, analistas | Extrae más de 50 páginas de propiedades en minutos, no en horas (fuente) |
| Seguimiento de cumplimiento | Operaciones, legal | Automatiza la supervisión; una aseguradora evitó 50 millones de dólares en sanciones (fuente) |
Y no olvidemos que dedica una cuarta parte de su semana a tareas repetitivas como la recopilación de datos. Automatizar esto con web scraping no es solo una comodidad: es una ventaja competitiva.
Empezar: configurar tu Puppeteer scraper
¿Listo para ponerte manos a la obra? Así puedes hacer que Puppeteer funcione en menos de 10 minutos (suponiendo que te sientas cómodo con un poco de JavaScript):
1. Instala Node.js
Puppeteer funciona sobre Node.js. Descarga la última versión LTS desde .
2. Crea una nueva carpeta de proyecto
Abre tu terminal y ejecuta:
1mkdir puppeteer-scraper-demo
2cd puppeteer-scraper-demo
3npm init -y3. Instala Puppeteer
1npm install puppeteerEsto también descargará una versión compatible de Chromium (unos 100 MB).
4. Crea tu primer script
Crea un archivo llamado scrape.js:
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
6 const title = await page.title();
7 console.log('Título de la página:', title);
8 await browser.close();
9})();Ejecuta esto con:
1node scrape.jsSi ves “Título de la página: Example Domain”, ¡felicidades! Acabas de automatizar Chrome.
Crear tu primer script de web scraping con Puppeteer
Vamos a lo práctico. Supongamos que quieres extraer citas de (un sitio de demostración para scrapers).
Paso 1: navega a la página
1await page.goto('http://quotes.toscrape.com', { waitUntil: 'networkidle0' });Paso 2: extrae los datos
1const quotes = await page.evaluate(() => {
2 return Array.from(document.querySelectorAll('.quote')).map(node => ({
3 text: node.querySelector('.text')?.innerText.trim(),
4 author: node.querySelector('.author')?.innerText.trim(),
5 tags: Array.from(node.querySelectorAll('.tag')).map(tag => tag.innerText.trim())
6 }));
7});
8console.log(quotes);Paso 3: gestiona la paginación
1let hasNext = true;
2let allQuotes = [];
3while (hasNext) {
4 // Extrae las citas como arriba
5 const quotes = await page.evaluate(/* ... */);
6 allQuotes.push(...quotes);
7 const nextButton = await page.$('li.next > a');
8 if (nextButton) {
9 await Promise.all([
10 page.click('li.next > a'),
11 page.waitForNavigation({ waitUntil: 'networkidle0' })
12 ]);
13 } else {
14 hasNext = false;
15 }
16}Paso 4: guarda en JSON
1const fs = require('fs');
2fs.writeFileSync('quotes.json', JSON.stringify(allQuotes, null, 2));Y listo: un Puppeteer scraper básico que navega, extrae, pagina y guarda datos.
Técnicas avanzadas de puppeteer scraper: manejar contenido dinámico
La mayoría de los sitios reales no son tan simples como una lista estática. Así puedes afrontar lo más complicado:
1. Esperar elementos dinámicos
1await page.waitForSelector('.product-list-item');Esto asegura que el contenido que quieres ya se haya cargado antes de intentar extraerlo.
2. Simular acciones de usuario
- Hacer clic en un botón:
await page.click('#load-more'); - Escribir en un campo:
await page.type('#search', 'laptop'); - Hacer scroll en carga infinita:
1// Nota: page.waitForTimeout se eliminó en Puppeteer v22. Usa una promesa normal en su lugar. 2const sleep = (ms) => new Promise(r => setTimeout(r, ms)); 3let previousHeight = await page.evaluate('document.body.scrollHeight'); 4while (true) { 5 await page.evaluate('window.scrollTo(0, document.body.scrollHeight)'); 6 await sleep(1500); 7 const newHeight = await page.evaluate('document.body.scrollHeight'); 8 if (newHeight === previousHeight) break; 9 previousHeight = newHeight; 10}
1**3. Gestionar inicios de sesión**
2```javascript
3await page.goto('https://exampleshop.com/login');
4await page.type('#login-username', 'myusername');
5await page.type('#login-password', 'mypassword');
6await page.click('#login-button');
7await page.waitForNavigation({ waitUntil: 'networkidle0' });4. Trabajar con datos cargados por AJAX A veces los datos no están en el DOM, sino que provienen de una llamada API. Puedes interceptar respuestas de red con:
1page.on('response', async response => {
2 if (response.url().includes('/api/products')) {
3 const data = await response.json();
4 // Procesar datos
5 }
6});Ejemplo real: extraer datos de productos de un sitio de e-commerce
Vamos a unirlo todo. Imagina que quieres extraer nombres de productos, precios e imágenes de un sitio de e-commerce (de demostración) después de iniciar sesión.
1const puppeteer = require('puppeteer');
2const fs = require('fs');
3(async () => {
4 const browser = await puppeteer.launch({ headless: true });
5 const page = await browser.newPage();
6 // Paso 1: inicia sesión
7 await page.goto('https://exampleshop.com/login');
8 await page.type('#login-username', 'myusername');
9 await page.type('#login-password', 'mypassword');
10 await page.click('#login-button');
11 await page.waitForNavigation({ waitUntil: 'networkidle0' });
12 // Paso 2: ve a la página de categoría
13 await page.goto('https://exampleshop.com/category/laptops', { waitUntil: 'networkidle0' });
14 // Paso 3: extrae los productos
15 const products = await page.evaluate(() => {
16 return Array.from(document.querySelectorAll('.product-item')).map(item => ({
17 name: item.querySelector('.product-title')?.innerText.trim() || '',
18 price: item.querySelector('.product-price')?.innerText.trim() || '',
19 image: item.querySelector('img.product-image')?.src || ''
20 }));
21 });
22 // Paso 4: guarda en JSON
23 fs.writeFileSync('products.json', JSON.stringify(products, null, 2));
24 await browser.close();
25})();Este script inicia sesión, navega, extrae y guarda todo automáticamente. Para necesidades más avanzadas, puedes añadir bucles de paginación o incluso entrar en cada producto para obtener más detalles.
Thunderbit: hacer que Puppeteer Scraper sea más simple con IA
Ahora bien, si has llegado hasta aquí y estás pensando: “Esto está muy bien, pero no quiero escribir código cada vez que necesito un nuevo conjunto de datos”, no estás solo. Precisamente por eso creamos .
¿Qué hace diferente a Thunderbit?
- No requiere código: solo instala la , abre la página que quieres extraer y haz clic en “AI Suggest Fields”.
- Detección de campos impulsada por IA: Thunderbit lee la página y sugiere las mejores columnas para extraer, como “Nombre del producto”, “Precio”, “Imagen”, etc.
- Maneja contenido dinámico: ¿scroll infinito, ventanas emergentes y subpáginas? La IA de Thunderbit puede encargarse, seguir la paginación o incluso visitar la página de detalles de cada producto para enriquecer tus datos.
- Exportación instantánea: envía tus datos directamente a Excel, Google Sheets, Notion o Airtable con un solo clic. Sin coste adicional por exportaciones.
- Plantillas para sitios populares: ¿necesitas extraer Amazon, Zillow o LinkedIn? Thunderbit tiene plantillas instantáneas, sin configuración.
- Extracción en la nube o en el navegador: para trabajos grandes, Thunderbit puede extraer hasta 50 páginas a la vez en la nube.
He visto usuarios pasar de “Ojalá pudiera conseguir estos datos” a “Aquí tienes mi hoja de cálculo” en menos de cinco minutos. Y lo mejor es que ya no tienes que preocuparte por scripts que se rompen cuando cambia el sitio web: la IA de Thunderbit se adapta sobre la marcha.
Puppeteer vs. Thunderbit: cómo elegir la herramienta de web scraping adecuada
Entonces, ¿cuál deberías usar? Así es como lo resumo para los equipos:
| Factor | Puppeteer (con código) | Thunderbit (sin código, con IA) |
|---|---|---|
| Facilidad de uso | Requiere JavaScript y conocimientos de DOM | Interfaz de apuntar y hacer clic; la IA sugiere campos |
| Velocidad de configuración | Horas o días para tareas complejas | Minutos: instalar y empezar |
| Control/Flexibilidad | Máximo: programa cualquier lógica personalizada e intégrala con otro código | Alto para casos estándar; menos adecuado para flujos de trabajo muy personalizados |
| Contenido dinámico | Programación manual para esperas, clics y scrolls | La IA integrada maneja automáticamente contenido dinámico, paginación y subpáginas |
| Mantenimiento | Tú eres responsable de los scripts: actualízalos cuando cambien los sitios | La IA se adapta a los cambios de diseño; menos mantenimiento para el usuario |
| Exportación de datos | Debes escribir tu propia lógica de exportación | Exportación con un clic a Excel, Sheets, Notion, Airtable, CSV, JSON |
| Ideal para | Desarrolladores, extracciones muy personalizadas o a gran escala | Usuarios de negocio, proyectos rápidos, equipos no técnicos |
| Coste | Gratis (salvo tu tiempo y cualquier infraestructura) | Hay plan gratuito; planes de pago por créditos (consulta Thunderbit Pricing) |
En resumen:
- Usa Puppeteer si necesitas control total, cuentas con recursos de programación o quieres integrar la extracción en una app más grande.
- Usa Thunderbit si quieres resultados rápidos, no quieres programar o necesitas dar autonomía a compañeros no técnicos.
La verdad es que he visto equipos usar ambos: Thunderbit para victorias rápidas y prototipos, y Puppeteer para integraciones profundas o casos límite.
Lista de verificación paso a paso: ejecutar con éxito un proyecto de web scraping con Puppeteer
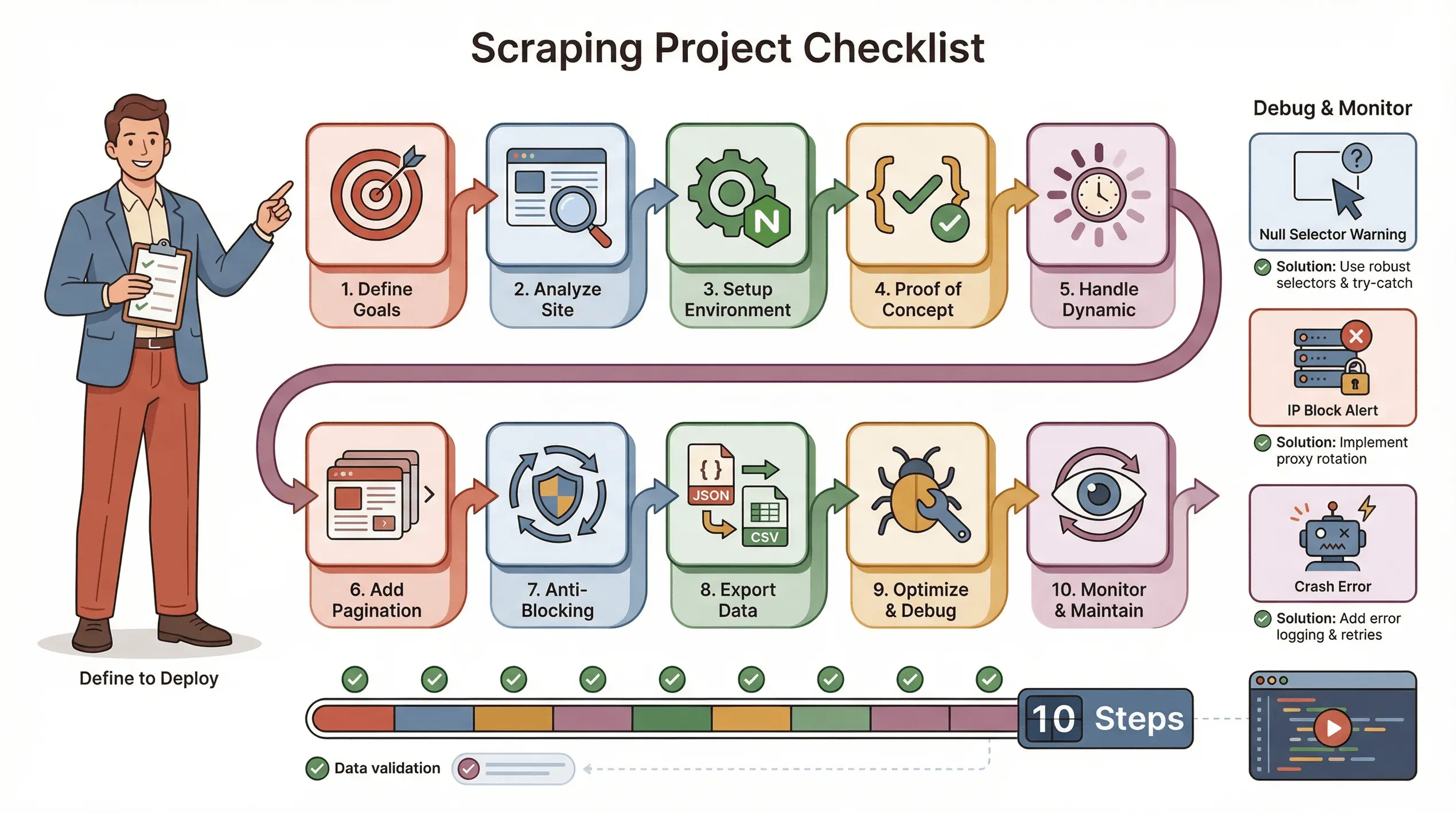 Esta es mi lista de verificación habitual para que un proyecto de scraping con Puppeteer salga bien:
Esta es mi lista de verificación habitual para que un proyecto de scraping con Puppeteer salga bien:
- Define tus objetivos: ¿Qué datos necesitas? ¿Dónde están?
- Analiza el sitio: ¿Es dinámico? ¿Requiere inicio de sesión? ¿Tiene medidas anti-bot?
- Configura tu entorno: Node.js, Puppeteer y cualquier biblioteca auxiliar.
- Escribe una prueba de concepto: empieza con una sola página y ajusta bien los selectores.
- Maneja el contenido dinámico: usa
waitForSelectory simula clics o scrolls según sea necesario. - Añade paginación o bucles: extrae todas las páginas, no solo una.
- Implementa tácticas anti-bloqueo: aleatoriza los retrasos, configura un User-Agent real y usa proxies si hace falta.
- Exporta y valida los datos: guarda en JSON/CSV y comprueba que esté todo completo.
- Optimiza y gestiona errores: añade try/catch, registra el progreso y maneja con elegancia los datos faltantes.
- Supervisa y mantén: los sitios cambian; prepárate para actualizar tu script.
Consejos de solución de problemas:
- Si los selectores devuelven null, revisa el HTML y usa esperas.
- Si te bloquean, reduce la velocidad, rota IPs o usa plugins de stealth.
- Si tu script falla, comprueba si hay fugas de memoria o excepciones no controladas.
Conclusión y puntos clave
El web scraping se ha convertido en una habilidad imprescindible para los equipos orientados a datos. Puppeteer te da el poder de extraer datos incluso de los sitios más dinámicos y cargados de JavaScript, pero sí requiere cierta experiencia en programación y mantenimiento continuo. Para los usuarios de negocio que quieren saltarse el código e ir directos a los datos, Thunderbit ofrece una alternativa con IA, sin código, rápida, flexible y sorprendentemente sólida.
Esto es lo que te recomendaría:
- Si eres técnico y necesitas mucha personalización, empieza con Puppeteer.
- Si quieres velocidad, simplicidad y menos mantenimiento, prueba (la es un gran punto de partida).
- Para la mayoría de los equipos, una combinación de ambos cubrirá el 99% de tus necesidades de datos web.
¿Quieres ver más guías como esta? Consulta el para tutoriales, comparativas y lo último en web scraping impulsado por IA.
Preguntas frecuentes
1. ¿Qué es un Puppeteer scraper y por qué se usa para web scraping?
Puppeteer es una biblioteca de Node.js que te permite controlar un navegador Chrome sin interfaz con JavaScript. Se usa para web scraping porque puede cargar contenido dinámico, simular acciones de usuario y extraer datos de sitios que los scrapers tradicionales no pueden manejar.
2. ¿Cómo se compara Puppeteer con Selenium y Thunderbit?
Selenium funciona con múltiples navegadores y lenguajes, pero es más pesado. Puppeteer está optimizado para Chrome y Node.js, y es más rápido para muchas tareas de scraping. Thunderbit, en cambio, es una herramienta sin código y con IA que permite a usuarios no técnicos extraer datos con solo unos clics.
3. ¿Cuáles son los principales beneficios empresariales del web scraping con Puppeteer?
Automatizar la recopilación de datos ahorra tiempo, reduce errores y permite obtener insights en tiempo real para ventas, marketing, operaciones y más. Los casos de uso van desde la generación de leads hasta el seguimiento de precios y la investigación de mercado.
4. ¿Cuáles son los mayores desafíos al hacer scraping con Puppeteer?
Los principales desafíos son manejar contenido dinámico, evitar bloqueos anti-bot y mantener los scripts cuando cambian los sitios web. Tendrás que programar cómo gestionar esperas, simular interacciones y tratar errores.
5. ¿Cuándo debería usar Thunderbit en lugar de Puppeteer?
Usa Thunderbit si quieres evitar programar, necesitas resultados rápidos o quieres dar autonomía a compañeros no técnicos. Es ideal para tareas de scraping estándar, proyectos rápidos o cuando solo quieres exportar datos a Excel o Google Sheets con el mínimo esfuerzo.
¿Listo para probar una forma más inteligente de extraer datos? o profundiza con más guías en el . ¡Feliz scraping!
Más información