YouTube tiene más de y . También es una de las plataformas más difíciles de extraer sin chocar con una pared de CAPTCHAs, errores 429 o bloqueos directos de IP.
Si alguna vez intentaste extraer datos de canales, comentarios o transcripciones a cualquier escala, ya conoces la frustración. Sacas unos cientos de resultados y, de pronto, YouTube te cierra la puerta. He dedicado mucho tiempo a evaluar cómo resisten distintos enfoques de scraping frente a las defensas anti-bot, que no paran de evolucionar, de YouTube, y la diferencia entre las herramientas que funcionan con fiabilidad y las que se bloquean en minutos es enorme.
Esta guía cubre los 6 mejores raspadores de YouTube para 2026: herramientas pensadas de verdad para soportar la hostilidad de YouTube sin freír tu IP ni tu flujo de trabajo. Tanto si eres un especialista en marketing que sigue canales de la competencia, un equipo de ventas que busca contactos de creadores o un desarrollador que está montando una canalización de datos, aquí hay una opción que encaja.
Qué bloquea realmente YouTube en 2026 (y por qué fallan la mayoría de los raspadores)
Las defensas anti-bot de YouTube no son una sola barrera: son un sistema por capas. Entender a qué te enfrentas es el primer paso para no acabar bloqueado.
Esto es lo que hace YouTube en 2026 para detectar y cortar el acceso automatizado:

- Comprobaciones de reputación y velocidad de IP: las solicitudes repetidas desde IPs de centros de datos, VPN o proxies compartidos se marcan enseguida. Verás errores 403, límites de 429 o pantallas de "inicia sesión para confirmar que no eres un bot".
- Fingerprinting del navegador y de JavaScript: YouTube comprueba si el cliente se comporta como un navegador real, ejecutando scripts, renderizando elementos y manteniendo el estado esperado. Los navegadores headless y los clientes HTTP puros suelen fallar estas comprobaciones sin avisar (simplemente obtienes datos vacíos o incompletos).
- Confianza en cookies y sesiones: si tus solicitudes no vienen de una sesión de navegador reconocida y de larga duración, YouTube sube el nivel de verificación. Las sesiones con inicio de sesión e historial de navegación reciben más confianza que las nuevas y anónimas.
- Análisis de comportamiento: intervalos de solicitud uniformes, desplazamiento demasiado rápido o patrones de página repetidos activan limitaciones. YouTube busca una navegación que ningún humano haría.
- Puertas CAPTCHA: cuando el riesgo es alto, YouTube obliga a pasar una verificación humana, especialmente en resultados de búsqueda y secciones de comentarios.
- Aplicación de cuotas de API: la API oficial de YouTube Data aplica cuotas diarias por proyecto (10.000 unidades/día por defecto), y los flujos de trabajo intensivos en búsquedas las agotan en minutos.
La experiencia típica es esta: empiezas a extraer datos, consigues unos cuantos cientos de resultados y luego te topas con un Error 429, una pared CAPTCHA o datos degradados sin aviso. Los raspadores en la nube que operan desde IPs de centros de datos son especialmente vulnerables.
This paragraph contains content that cannot be parsed and has been skipped.
La conclusión es simple: las herramientas que trabajan dentro de una sesión real de navegador (como Thunderbit) esquivan de forma natural muchas de estas comprobaciones porque la solicitud se ve idéntica a la de una persona navegando por YouTube. Los raspadores solo en la nube necesitan rotación de proxies, resolución de CAPTCHA y un ritmo cuidadoso para sobrevivir.
API de YouTube vs. los mejores raspadores de YouTube: un marco práctico de decisión
La API de YouTube Data v3 es la forma "oficial" de acceder programáticamente a los datos de YouTube. Es fiable para metadatos básicos y de poco volumen, pero su modelo de cuotas la vuelve poco práctica para la mayoría de los flujos reales de inteligencia competitiva e investigación.
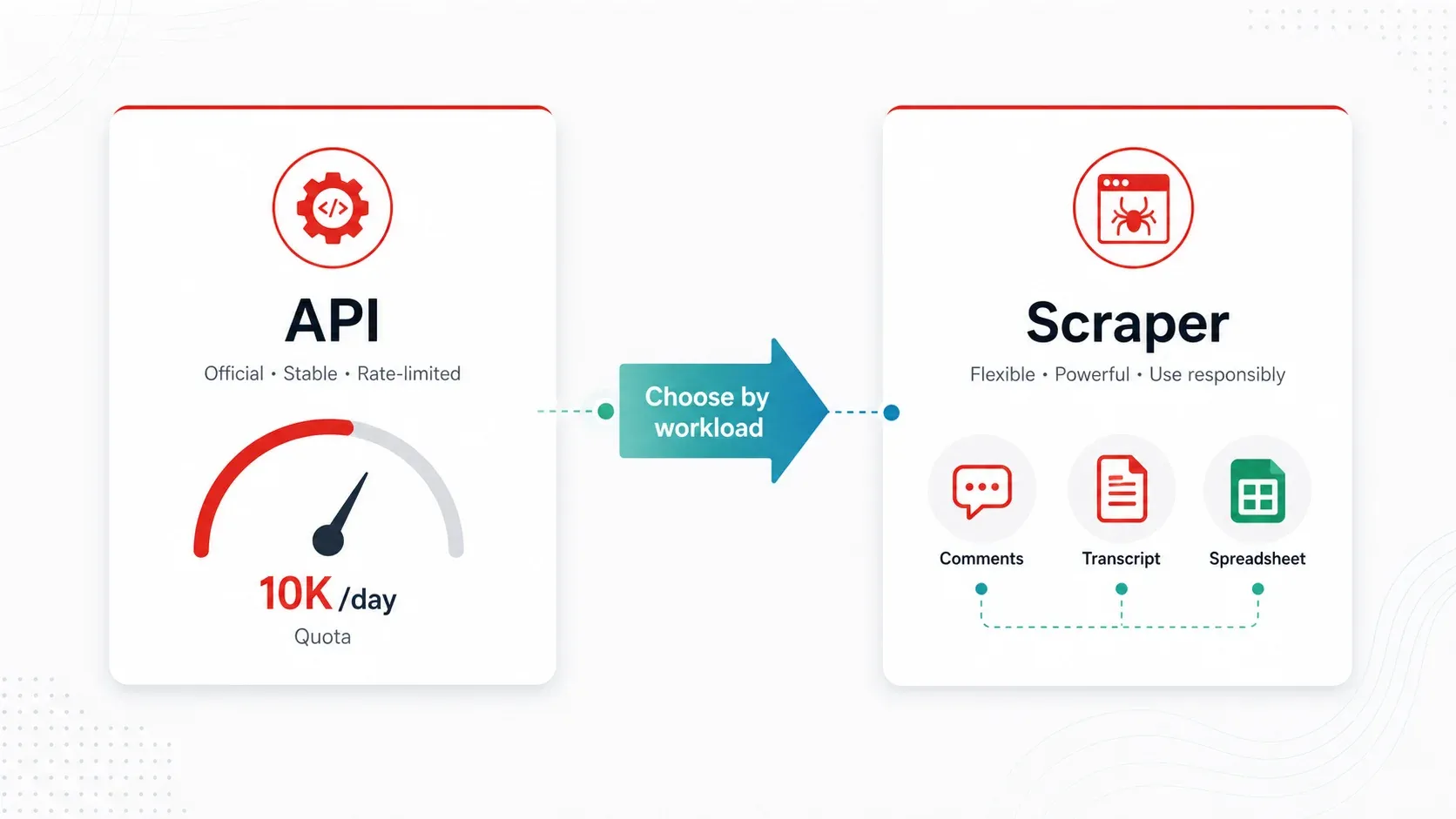
Aquí está la matemática. Cada proyecto de la API recibe . Costes clave de los endpoints:
search.list= 100 unidades por página (máximo 50 resultados por página)videos.list= 1 unidad por llamada (hasta 50 IDs de video por llamada)commentThreads.list= 1 unidad por llamada (hasta 100 hilos por llamada)
Así que, si haces 100 búsquedas por palabra clave al día, habrás gastado toda tu cuota diaria antes de enriquecer un solo video. Un flujo centrado en comentarios es más barato por llamada, pero la paginación real, los comentarios desactivados y la expansión de respuestas consumen capacidad rápidamente.
Cuándo la API es suficiente:
- Necesitas menos de 100 videos al día y solo metadatos públicos (título, vistas, likes, duración)
- Un desarrollador puede configurar OAuth y gestionar la cuota
Cuándo conviene un raspador:
- Necesitas comentarios a escala (la API funciona, pero la fricción de cuota es real)
- Necesitas transcripciones/subtítulos como texto (la API no expone fácilmente el texto de subtítulos para uso masivo)
- Estás monitorizando más de 100 canales con regularidad (la cuota escala, la programación es manual)
- Necesitas datos enriquecidos o etiquetados (categorización, traducción o detección de campos con IA)
- Eres un usuario no técnico que solo quiere una hoja de cálculo
La API tampoco expone todo lo que verías en la web: los datos de la estantería de Shorts, los correos públicos de las descripciones de canales, las publicaciones de la comunidad y algunos metadatos de canal solo son accesibles extrayendo las páginas reales de YouTube.
Para la mayoría de usuarios de negocio que hacen investigación competitiva, búsqueda de creadores o estrategia de contenido, una herramienta de scraping resulta más práctica que la API.
Cómo elegimos los 6 mejores raspadores de YouTube
Todas las herramientas de esta lista se evaluaron con los mismos criterios, ponderados según lo que de verdad importa cuando YouTube intenta bloquearte activamente:
| Criterio | Por qué importa |
|---|---|
| Fiabilidad anti-baneo | El principal dolor de los usuarios: limitación de tasa y bloqueos de IP a escala |
| Coste por 1.000 resultados | Un precio normalizado permite comparar herramientas en igualdad de condiciones |
| Tipos de datos compatibles | Metadatos, comentarios, transcripciones, Shorts, miniaturas: varía mucho según la herramienta |
| Capacidad de escala | ¿Puede manejar más de 100 canales o más de 10K videos sin romperse? |
| Facilidad de configuración | Quien usa un scraper por primera vez necesita opciones prácticas y sin código |
| Formatos de exportación | CSV, JSON, Google Sheets, Airtable: distintos flujos necesitan distintos resultados |
| Carga de mantenimiento | YouTube cambia y rompe herramientas; ¿quién lo arregla? |
Todas las herramientas se evaluaron según los patrones actuales de bloqueo de YouTube que los usuarios encuentran en 2026.
1. Thunderbit
es una extensión de Chrome impulsada por IA que convierte páginas de YouTube en datos estructurados en apenas dos clics. En lugar de ejecutarse desde un servidor en la nube (que YouTube detecta fácilmente), Thunderbit trabaja dentro de tu propia sesión del navegador; así, para YouTube, parece que estás navegando con normalidad.
El flujo central para YouTube: instala la , entra en un canal de YouTube, una página de resultados de búsqueda o una página de video, y haz clic en "AI Suggest Fields". La IA lee la página y propone columnas: título del video, URL, vistas, fecha de subida, descripción, URL de la miniatura, texto del comentario, autor, likes y más. Revisas, haces clic en "Scrape" y exportas directamente a Google Sheets, Excel, Airtable, Notion, CSV o JSON. Sin código, sin selectores, sin claves API.
Funciones clave para extraer datos de YouTube:
- Detección de campos con IA: la IA de Thunderbit lee la página de YouTube en la que estés y sugiere columnas relevantes automáticamente. No hace falta mapear manualmente selectores CSS ni XPath.
- Scraping de subpáginas: extrae la lista de videos de un canal y luego entra en cada página de video para enriquecerla con comentarios, descripciones, etiquetas y transcripciones (si son visibles).
- Scraping programado: configura tareas recurrentes para monitorizar canales semanalmente sin intervención manual.
- Modo navegador: se ejecuta en tu sesión autenticada del navegador, reduciendo la huella de "IP de centro de datos en la nube" que activa la mayoría de bloqueos de YouTube.
- Exportación gratuita: los datos van a Google Sheets, Excel, Airtable o Notion sin una barrera de pago para exportar.
Enfoque anti-baneo: scraping basado en navegador con la sesión autenticada del propio usuario. YouTube ve un navegador real, cookies reales e historial real de sesión. Para tareas de alto volumen, lotes pequeños programados reducen aún más el riesgo.
Precio: plan gratuito (6 páginas), impulso de prueba (10 páginas). Los planes de pago se basan en créditos. Consulta para ver las cifras actuales.
Ideal para: especialistas en marketing, equipos de ventas, estrategas de contenido y usuarios de operaciones que quieren investigación rápida de canales, búsquedas y comentarios sin configuración técnica.
Cómo extraer datos de YouTube con Thunderbit (paso a paso)
- Instala la .
- Navega a una página de canal de YouTube, resultados de búsqueda, una lista de reproducción o una página de video.
- Haz clic en "AI Suggest Fields": la IA lee la página y propone columnas (título, URL, vistas, fecha, descripción, miniatura, etc.).
- Revisa y ajusta los campos sugeridos si hace falta.
- Haz clic en "Scrape": los datos se extraen en una tabla estructurada.
- Exporta a Google Sheets, Excel, Airtable, Notion, CSV o JSON.
Para una extracción más profunda (por ejemplo, obtener comentarios de cada video de un canal), usa el scraping de subpáginas: primero extrae la lista de videos y luego deja que Thunderbit visite cada página de video y extraiga comentarios, descripciones o la disponibilidad de transcripciones.
Todo el proceso tarda menos de dos minutos para una tarea típica de investigación de un canal. Sin claves API, sin configuración de proxies, sin código.
2. Apify
Apify es una plataforma de scraping basada en la nube con "Actors" de YouTube ya preparados: raspadores especializados para videos, comentarios, canales, Shorts y transcripciones. Está pensada para desarrolladores que quieren construir canalizaciones de datos automatizadas en lugar de hacer investigaciones puntuales.
El ecosistema de YouTube de Apify incluye Actors separados para distintas tareas. Un Actor bien mantenido llamado "YouTube Scraper — Videos, Comments & Transcripts" acepta canales, listas de reproducción, búsquedas y URLs directas de video. Admite filtrado de Shorts, scraping de comentarios y transcripciones con marcas de tiempo.
Funciones clave:
- Actors separados para videos, comentarios, canales, Shorts y transcripciones
- Acepta términos de búsqueda, URLs de canales e IDs de listas de reproducción como entrada
- Programación en la nube e integraciones con webhooks
- Exportación a JSON, CSV, Excel o envío a bases de datos vía API
- Control de tasa a nivel de Actor y rotación de proxies
Enfoque anti-baneo: ritmo específico por Actor, infraestructura de proxies de Apify y acceso a la API interna de YouTube (Innertube) cuando corresponde. Cada Actor implementa su propia lógica de reintentos y límite de tasa.
Precio: el Actor citado de YouTube Scraper indica aproximadamente 15 USD por 1.000 videos, 8 USD por 1.000 comentarios y 5 USD por transcripción. Los planes de la plataforma empiezan en 49 USD/mes.
Desventajas: los costes de uso escalan rápido en trabajos grandes. La interfaz está orientada a desarrolladores; los usuarios no técnicos pueden encontrarla compleja. Los esquemas de salida varían entre Actors, así que a menudo hay que limpiar datos. La calidad de los Actors difiere en el marketplace.
Ideal para: desarrolladores que crean canalizaciones automatizadas, equipos que necesitan extracción programada hacia APIs o bases de datos y equipos de marketing ops que ejecutan flujos recurrentes de sentimiento en comentarios.
3. Bright Data
Bright Data es una plataforma empresarial de infraestructura de datos con la red de proxies residenciales más grande del sector y raspadores de YouTube dedicados. Si necesitas extraer YouTube a escala masiva y en varias geografías, esta es la artillería pesada.
Bright Data ofrece varios raspadores de YouTube (perfiles de canal, videos, comentarios) además de conjuntos de datos de YouTube listos para usar que puedes comprar. Su servicio de scraping gestionado significa que ellos construyen y mantienen el raspador por ti.
Funciones clave:
- Más de 150M de IPs residenciales en 195 países
- Raspadores específicos de YouTube para canales, videos y comentarios
- Renderizado completo del navegador y resolución de CAPTCHA
- Scraping geolocalizado (compara resultados de YouTube entre países)
- Opción de servicio gestionado (ellos se encargan del mantenimiento)
- Procesamiento por lotes de hasta 5K URLs por solicitud
Enfoque anti-baneo: enorme pool de proxies residenciales, rotación automática de IP, emulación de fingerprint del navegador y resolución integrada de CAPTCHA. Es la infraestructura anti-bloqueo más sólida de la lista.
Precio: prueba gratuita (1K solicitudes durante una semana), pago por uso a 3,50 USD por 1K registros, plan Scale a 499 USD/mes con 384.000 registros incluidos y 2,30 USD por cada 1K adicional.
Desventajas: excesivo para proyectos pequeños. El precio es complejo (ancho de banda + solicitudes + IPs pueden provocar un "golpe de factura" si no se fijan límites). La plataforma requiere más configuración que una extensión de Chrome.
Ideal para: grandes corporaciones, agencias que monitorizan cientos de canales y equipos que necesitan datos de YouTube específicos por geografía a escala empresarial.
4. Octoparse
Octoparse es una herramienta de scraping de escritorio y en la nube con una interfaz visual de apuntar y hacer clic. Construyes flujos de extracción de YouTube haciendo clic en elementos de la página: no hace falta código, pero ofrece más personalización que una extensión simple.
Octoparse tiene plantillas de YouTube ya preparadas, incluida una plantilla de YouTube Comments & Replies Scraper actualizada en abril de 2026. Extrae nombres de usuario, texto del comentario, likes, hora de publicación y hilos de respuestas desde URLs de video.
Funciones clave:
- Creador visual de flujos sin código: haz clic en elementos para definir la lógica de scraping
- Plantillas de YouTube ya preparadas para comentarios, resultados de búsqueda y metadatos de video
- Programación en la nube con rotación automática de proxies
- Exportación a Excel, CSV, JSON y conexiones a bases de datos
- Rotación de IP integrada y anti-detección en los planes en la nube
Enfoque anti-baneo: ejecución en la nube con rotación de IP integrada y medidas anti-detección. Las plantillas gestionan el scroll infinito y la carga dinámica en páginas comunes de YouTube.
Precio: la plantilla de comentarios de YouTube aparece a 0,20 USD por 1.000 líneas. Los planes de la plataforma empiezan en alrededor de 75 USD/mes (Standard, facturado anualmente) con servidores en la nube, programación y opciones de proxy.
Desventajas: las páginas complejas de YouTube (scroll infinito, comentarios cargados bajo demanda, pestañas de Shorts) pueden requerir ajustar tiempos de espera y comportamiento de desplazamiento. La extracción de transcripciones/subtítulos es más limitada que con yt-dlp o actores de transcripción dedicados. Curva de aprendizaje para flujos avanzados.
Ideal para: analistas de marketing e investigadores de negocio que prefieren herramientas visuales de flujo de trabajo, pero necesitan más personalización que una extensión de Chrome.
5. YT-DLP
YT-DLP (disponible en GitHub) es una herramienta de línea de comandos de código abierto que extrae metadatos de video, subtítulos, transcripciones y más desde YouTube (y más de 1.000 sitios adicionales). Es la navaja suiza para usuarios técnicos que quieren el máximo control y cero costes de suscripción.
Para trabajos de tipo scraping, yt-dlp puede extraer metadatos sin descargar los archivos de video usando banderas como --skip-download, --write-info-json, --dump-json y --flat-playlist. Distingue entre subtítulos generados automáticamente y subtítulos escritos por personas, una diferencia que la mayoría de las demás herramientas no detectan.
Funciones clave:
- Extrae metadatos de video (título, vistas, likes, fecha de subida, descripción, etiquetas) sin descargar el video
- Descarga listas de reproducción y canales completos en bloque
- Accede a subtítulos/transcripciones (generados automáticamente y escritos por humanos, por separado)
- Procesamiento por lotes con plantillas de salida personalizadas
- Soporte de cookies/autenticación para acceso basado en sesión
- Totalmente gratis, con una comunidad de código abierto activa
Enfoque anti-baneo: cookies del usuario para autenticación (--cookies-from-browser), ajustes configurables de limitación de velocidad y actualizaciones del extractor mantenidas por la comunidad que se adaptan a los cambios de YouTube.
Precio: gratis.
Desventajas: requiere soltura con la línea de comandos. No tiene interfaz visual. Se rompe cuando YouTube cambia (la comunidad lo corrige rápido, pero aun así tienes que actualizar y solucionar problemas). No incluye programación integrada ni exportación a hojas de cálculo: tú construyes tu propia canalización.
Ideal para: desarrolladores, científicos de datos y equipos técnicos que necesitan el máximo control sobre metadatos y extracción de transcripciones y no les molestan los comandos de terminal.
6. Phantombuster
Phantombuster es una plataforma de automatización en la nube con "Phantoms" específicos de YouTube, pensados más para marketing de crecimiento y generación de leads que para un puro almacenamiento de datos. Es la opción cuando tu objetivo es encontrar contactos de creadores y construir listas de prospección.
El YouTube Channel Video Extractor de Phantombuster extrae información del canal, listas de videos y correos públicos de las descripciones de los canales. Su documentación oficial sobre límites de tasa dice que YouTube Channel Video Extractor admite hasta 100 videos por ejecución y advierte que la actividad inusual aún puede activar restricciones de YouTube.
Funciones clave:
- Raspador de canales de YouTube (número de suscriptores, lista de videos, información del canal, correos públicos)
- Extracción de videos y comentarios para análisis de la competencia
- Integración con CRM y herramientas de prospección
- Programación y automatización de flujos de trabajo
- Prueba gratuita de 14 días, plan Start a 56 USD/mes (facturado anualmente, 20 h/mes de ejecución)
Enfoque anti-baneo: retrasos integrados entre acciones, sesiones de navegador Phantom y ejecución en la nube con automatización a ritmo controlado. Está diseñado para flujos de trabajo seguros y pausados, no para extracción masiva a alta velocidad.
Precio: plan Start a 56 USD/mes (anual), Grow a 128 USD/mes, Scale a 352 USD/mes. El coste por 1.000 resultados varía según el tiempo de ejecución, no por precio por registro.
Desventajas: más lento que las herramientas centradas en canalizaciones. El precio se basa en horas de ejecución y créditos, no en un coste limpio por fila. Soporte limitado para transcripciones/subtítulos. El límite de 100 videos por ejecución significa que los canales grandes requieren varias corridas.
Ideal para: especialistas en marketing de crecimiento que hacen investigación de influencers, equipos de ventas que extraen información de contacto de creadores y agencias que monitorizan la actividad de YouTube de la competencia.
Todos los tipos de datos que puedes extraer de YouTube (matriz por herramienta)
Distintas herramientas admiten distintos tipos de datos de YouTube. Antes de comprometerte con una herramienta, necesitas saber exactamente qué vas a obtener. Aquí va el desglose:
| Tipo de dato | Thunderbit | Apify | Bright Data | Octoparse | YT-DLP | Phantombuster |
|---|---|---|---|---|---|---|
| Metadatos de video (título, vistas, likes, duración, fecha) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Comentarios (en bloque con autor, hora, likes) | ✅ | ✅ | ✅ | ✅ | ❌ | ⚠️ |
| Respuestas a comentarios | ⚠️ | ✅ | ✅ | ✅ | ❌ | ⚠️ |
| Transcripciones/subtítulos | ⚠️ (depende de la página) | ✅ | ⚠️ | ⚠️ | ✅ | ❌ |
| Subtítulos automáticos vs. manuales (distinguido) | ⚠️ | ✅ | ⚠️ | ❌ | ✅ | ❌ |
| Métricas de Shorts | ✅ | ✅ | ✅ | ⚠️ | ✅ | ⚠️ |
| Analítica de canal (suscriptores, vistas totales, fecha de alta) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Miniaturas/imágenes | ✅ | ✅ | ✅ | ✅ | ✅ | ❌ |
| Correos públicos de las descripciones de canal | ✅ (si son visibles) | Depende del Actor | ⚠️ | ⚠️ | ❌ | ✅ |
Datos más valiosos según el caso de uso de negocio:
- Comentarios → análisis de sentimiento, extracción de objeciones, quejas sobre competidores, investigación de audiencia
- Transcripciones → canalizaciones de LLM/RAG, análisis del mensaje de la competencia, reutilización de contenido
- Metadatos del canal → búsqueda de creadores, seguimiento de la competencia, prospección de ventas/influencers
- Metadatos de video → estrategia de contenido, análisis de títulos/miniaturas, cadencia de publicación, ideación SEO
- Correos públicos → contacto con creadores (úsalo con responsabilidad y cumpliendo las normas de correo electrónico y privacidad)
Mejores raspadores de YouTube comparados: tabla lado a lado
| Herramienta | Tipo | Enfoque anti-baneo | Coste/1K resultados | Ideal para | Configuración | Formatos de exportación | Escala |
|---|---|---|---|---|---|---|---|
| Thunderbit | Extensión de Chrome con IA | Sesión del navegador, detección de campos con IA | Plan gratuito (6 páginas); plan de pago basado en créditos | Investigación de canales/búsquedas sin código | Muy fácil | Sheets, Excel, Airtable, Notion, CSV/JSON | Pequeña-mediana, programada |
| Apify | Plataforma de actores en la nube | Ritmo específico por Actor, proxies, Innertube | ~5–15 USD/1K (varía según el Actor) | Canalizaciones para desarrolladores | Media | JSON, CSV, Excel, API, webhooks | Media-alta |
| Bright Data | Raspador/proxy empresarial | Más de 150M IPs residenciales, resolución de CAPTCHA | 3,50 USD/1K registros (pago por uso) | Extracción empresarial | Media-difícil | JSON, NDJSON, CSV, webhooks | Muy alta |
| Octoparse | Creador visual de flujos | Rotación de IP en la nube, anti-detección | ~0,20 USD/1K líneas (plantilla) + plan | Flujos visuales personalizados | Media | Excel, CSV, JSON, BD | Media |
| YT-DLP | CLI de código abierto | Cookies, ajustes de limitación, actualizaciones de la comunidad | Gratis | Extracción técnica de metadatos/transcripciones | Difícil (para no técnicos) | JSON, subtítulos, salida personalizada | Depende de la configuración del usuario |
| Phantombuster | Automatización de crecimiento en la nube | Retrasos integrados, sesiones con ritmo controlado | Basado en plan (56+ USD/mes); ~100 videos/ejecución | Generación de leads de creadores, flujos de crecimiento | Fácil-media | CSV/JSON/API/CRM | Media, a ritmo controlado |
Ganadores por categoría:
- Mejor para usuarios no técnicos: Thunderbit
- Mejor para canalizaciones de desarrollador: Apify
- Mejor para escala empresarial: Bright Data
- Mejor creador visual: Octoparse
- Mejor opción técnica gratuita: YT-DLP
- Mejor flujo de trabajo de marketing de crecimiento: Phantombuster
Raspadores de YouTube gratis vs. de pago: cuándo bastan las herramientas gratuitas
Las herramientas gratuitas funcionan cuando la tarea es concreta, poco frecuente y te sientes cómodo con el mantenimiento técnico. Aquí tienes cuándo quedarte en gratis y cuándo invertir:
| Escenario | Mejor opción gratuita | Cuándo pasar a una opción de pago | Por qué |
|---|---|---|---|
| Descarga puntual de una transcripción | YT-DLP | Necesitas 500+ videos o compañeros no técnicos | La configuración por CLI y la gestión de cookies añaden fricción |
| Revisión rápida de un canal de la competencia | Plan gratuito de Thunderbit (6 páginas) | Monitorización regular o más de 10 páginas | El scraping programado ahorra horas por semana |
| Construcción de un conjunto de datos para entrenamiento de LLM | YT-DLP + scripts personalizados | Necesitas filtrar subtítulos automáticos/manuales a escala | Los Actors dedicados de Apify gestionan casos extremos |
| Monitorización semanal de más de 10 canales | — | Inmediatamente | La programación y la reutilización de esquemas ahorran tiempo real |
| Equipo de marketing extrayendo leads de creadores | Prueba gratuita de Thunderbit | Más de 10 canales por semana | Escalar con créditos sale más barato que el tiempo de programar |
La verdad, sin adornos: herramientas gratuitas como YT-DLP son potentes, pero exigen mantenimiento técnico constante. Los cambios de diseño de YouTube, la caducidad de cookies, los ajustes de limitación y el formato de salida necesitan atención manual. Un script que se rompe cada dos semanas puede costar más horas de ingeniería que una suscripción de pago a un raspador.
Las herramientas impulsadas por IA como Thunderbit vuelven a leer las páginas en cada ejecución y se adaptan automáticamente a los cambios de diseño. Ese coste oculto de mantenimiento es lo que justifica las herramientas de pago para la mayoría de los equipos de negocio.
Cómo se ve realmente un dato extraído de YouTube (muestras reales de salida)
Una de las mayores carencias en las reseñas de raspadores es que nadie te muestra lo que de verdad vas a obtener. Aquí tienes ejemplos realistas de salida extraída de YouTube:
Ejemplo 1: metadatos de canal
| channel_name | handle | subscribers | total_views | video_count | join_date | description_snippet | public_email |
|---|---|---|---|---|---|---|---|
| Ejemplo SaaS Tutorials | @examplesaas | 184K | 22.4M | 412 | 2018-06-14 | Tutoriales semanales de producto y guías de flujo de trabajo | partnerships@example.com |
| Data Ops Weekly | @dataopsweekly | 92K | 8.7M | 215 | 2020-01-03 | Demostraciones de analítica, automatización y flujos de trabajo con IA | No visible |
Ejemplo 2: exportación de comentarios
| video_url | timestamp | author | comment_text | likes | reply_count |
|---|---|---|---|---|---|
| youtube.com/watch?v=abc123 | 2026-04-18 | @workflowfan | Esto respondió la pregunta sobre precios mejor que la página del proveedor. | 28 | 3 |
| youtube.com/watch?v=abc123 | 2026-04-18 | @opslead | Me encantaría una continuación comparándolo con Apify. | 11 | 0 |
| youtube.com/watch?v=abc123 | 2026-04-19 | @examplesaas | Buen punto, eso es justo lo que estamos probando a continuación. | 4 | 0 |
Ejemplo 3: extracción de transcripción
100:00:00.000 - 00:00:04.200 Hoy estamos comparando seis flujos de trabajo de scraping de YouTube para especialistas en marketing.
200:00:04.200 - 00:00:09.800 La principal diferencia es si necesitas metadatos, comentarios o transcripciones.
300:00:09.800 - 00:00:15.300 Para usuarios no técnicos, un raspador basado en navegador suele ser más fácil de mantener.Problemas comunes de limpieza que debes esperar:
- Los conteos de vistas pueden incluir sufijos localizados (K, M) o etiquetas en otros idiomas
- Las fechas de subida a veces son relativas ("hace 3 años") en lugar de fechas ISO
- Los comentarios pueden estar ordenados por Destacados en vez de Más recientes por defecto
- Las respuestas ocultas y los comentarios cargados bajo demanda requieren desplazamiento o paginación
- Los campos de correo público pueden estar ocultos tras interacción o restricciones de cuenta
- Las transcripciones pueden no estar disponibles, ser generadas automáticamente o estar en un idioma inesperado
Para Thunderbit en concreto, el flujo de trabajo es: AI Suggest Fields → Scrape → Export to Google Sheets. La IA se encarga de detectar los campos, así que no necesitas definir manualmente cómo se ven "vistas" o "fecha de subida" en la página.
¿Es legal extraer datos de YouTube en 2026?
La versión corta: extraer datos públicos disponibles de YouTube suele tener menos riesgo que acceder a datos privados, pero no es un terreno libre de reglas.
Los de YouTube prohíben explícitamente el acceso automatizado salvo para motores de búsqueda públicos que sigan robots.txt o cuenten con permiso previo por escrito de YouTube. Sin embargo, la aplicación contra la investigación empresarial legítima es poco común: YouTube se centra sobre todo en abuso a gran escala, piratería de contenido y violaciones de privacidad.
El precedente legal en EE. UU. aporta algo de claridad. La decisión del Noveno Circuito concluyó que había cuestiones serias sobre si extraer datos disponibles públicamente viola la CFAA. La que extraer datos de sitios web públicos no es un delito. Pero los Términos de Servicio de la plataforma, los derechos de autor, la privacidad y las leyes anti-spam siguen aplicando.
Pautas prácticas:
- Recoge solo datos públicos que tu cuenta tenga permiso de ver
- No extraigas datos personales a una escala innecesaria
- No eludas controles de acceso ni muros de pago
- Respeta los derechos de autor: no republicar transcripciones o contenido de video en bloque
- Limita la tasa de los trabajos y evita sobrecargar los servidores de YouTube
- Para prospección, cumple con CAN-SPAM, GDPR y las normas locales
- Consulta a un profesional legal en casos de uso de alto riesgo
Las herramientas de esta lista incluyen limitación de tasa y ritmos respetuosos por diseño. Eso no es solo buena ética: es lo que hace que tu scraping siga funcionando a largo plazo.
¿Qué raspador de YouTube deberías elegir?
Aquí va la guía rápida de decisión:
- Thunderbit → La mejor opción para usuarios no técnicos que quieren extraer YouTube rápido y con resistencia a bloqueos en hojas de cálculo. Empieza aquí si eres marketer, comercial o estratega de contenido.
- Apify → La mejor para desarrolladores que construyen canalizaciones automatizadas con trabajos programados, webhooks y entrega por API.
- Bright Data → La mejor para extracción a escala empresarial y por geografías con infraestructura gestionada anti-bloqueo.
- Octoparse → La mejor para analistas que quieren creación visual de flujos con más personalización que una extensión de Chrome.
- YT-DLP → La mejor opción gratuita para usuarios técnicos que necesitan control máximo sobre metadatos y transcripciones.
- Phantombuster → La mejor para especialistas en marketing de crecimiento que hacen búsqueda de creadores y generación de leads basada en YouTube.
La clave para no ser bloqueado no es un truco secreto: es elegir una herramienta con detección inteligente incorporada. El scraping basado en sesión del navegador, la rotación de proxies, el ritmo controlado y los lotes pequeños programados reducen el riesgo. Lo que te bloquea es intentar forzar miles de solicitudes desde una sola IP en la nube.
Si quieres ver cómo es el scraping moderno de YouTube sin código, prueba el plan gratuito de . Dos clics para obtener datos estructurados. Y si tus necesidades son más técnicas o de escala empresarial, las otras herramientas de esta lista también te cubren. Para más información sobre enfoques de scraping web, consulta nuestras guías sobre y . También puedes ver tutoriales en el .
Preguntas frecuentes
¿Qué datos puedes extraer de un canal de YouTube?
Los datos públicos que se pueden extraer incluyen títulos de video, URLs, miniaturas, vistas, likes (cuando son visibles), fechas de subida, descripciones, duración, comentarios, respuestas, nombres/handles de comentaristas, likes en comentarios, transcripciones/subtítulos (generados automáticamente y escritos por personas), indicadores de Shorts, nombre del canal, handle, número de suscriptores, cantidad de videos, vistas totales, descripción, enlaces y correos públicos si son visibles en la página del canal.
¿Cuántos videos de YouTube puedo extraer al día sin que me bloqueen?
No existe un número universal. Las herramientas basadas en navegador como Thunderbit tienen menos riesgo para flujos de trabajo parecidos a los de un usuario porque operan dentro de una sesión real. El YouTube Channel Video Extractor de Phantombuster admite hasta 100 videos por ejecución. Las plataformas en la nube con rotación de proxies pueden manejar miles con el ritmo adecuado. Los scripts en bruto desde servidores en la nube sin limitación de tasa se bloquearán rápidamente. El enfoque más seguro es usar lotes pequeños y programados en lugar de una sola ejecución masiva.
¿Puedo extraer comentarios de YouTube para análisis de sentimiento?
Sí. Thunderbit, Apify, Bright Data y Octoparse admiten extracción masiva de comentarios con autor, marca de tiempo, likes y conteo de respuestas. Exporta a Google Sheets o CSV para analizarlos. El actor de YouTube de Apify admite explícitamente un máximo configurable de comentarios por video para este caso de uso.
¿Existe un raspador de YouTube gratuito que realmente funcione en 2026?
YT-DLP es la mejor opción gratuita para usuarios técnicos, especialmente para metadatos y transcripciones. Thunderbit ofrece un plan gratuito para usuarios no técnicos (6 páginas, con impulso de prueba hasta 10) que exporta directamente a Google Sheets. Ambos funcionan, pero YT-DLP requiere habilidades de línea de comandos mientras que Thunderbit solo necesita un navegador.
¿Cómo evitan los raspadores de YouTube ser bloqueados?
Las distintas herramientas usan enfoques diferentes: el scraping basado en sesión del navegador (Thunderbit) usa el contexto autenticado del navegador del usuario; la rotación de proxies residenciales (Bright Data, Apify) distribuye las solicitudes entre millones de IPs; la autenticación por cookies (YT-DLP) mantiene la confianza de la sesión; los retrasos y el ritmo integrados (Phantombuster) evitan la detección por comportamiento. El enfoque más fiable combina contexto real de navegador con un ritmo conservador y trabajos pequeños programados.
Más información