Si estás comparando herramientas de scraping web en 2026, lo último que necesitas es un ensayo filosófico. Lo que quieres es una lista corta fiable, una forma rápida de distinguir las herramientas pensadas para usuarios de negocio de las pilas técnicas pesadas, y pruebas reales suficientes para no equivocarte en la compra. Esa es la finalidad de esta página.
La respuesta rápida
Si solo necesitas la lógica de decisión, quédate con esto:
- Elige un raspador web IA si quieres ir de un sitio web a una hoja de cálculo lo más rápido posible y con la mínima configuración.
- Elige una herramienta de scraping sin código si necesitas más control sobre las tareas, la programación o las ejecuciones en la nube sin escribir código.
- Elige una plataforma API si tu equipo necesita renderizado, rotación de proxies, gestión antibots o integración dentro de un producto interno.
- Elige una biblioteca de código abierto si quieres control total y puedes asumir el mantenimiento, los selectores, la infraestructura y los fallos.
Este artículo cubre las 20 herramientas, pero la lógica de recomendación es deliberadamente sencilla: empieza por la herramienta más ligera que pueda gestionar tu flujo de trabajo de forma fiable, y baja de nivel solo cuando el mantenimiento, los bloqueos o la escala te obliguen.
Tabla comparativa rápida: las mejores herramientas de scraping web en 2026
Los precios y modelos de plan que aparecen abajo se verificaron en las páginas oficiales de producto o precios el 8 de mayo de 2026. Cuando los proveedores facturan por uso o manejan presupuestos empresariales personalizados, describo el modelo de precios en lugar de inventar un precio de lista universal.
| Herramienta | Tipo | Ideal para | Por qué entró en la lista de 2026 | Modelo de precios (revisado en mayo de 2026) |
|---|---|---|---|---|
| Thunderbit | Raspador Web IA | Ventas, operaciones, ecommerce, bienes raíces | La forma más rápida para usuarios sin código; sugerencia de campos con IA, subpáginas, exportaciones, flujo de trabajo en navegador + nube | Plan gratis, planes de pago, precios personalizados para empresas |
| Browse AI | Raspador Web IA | Usuarios de negocio que supervisan sitios web | Robots sin código muy sólidos, supervisión y resultados tipo hoja de cálculo/API | Plan gratis, planes de pago, nivel premium gestionado |
| Bardeen | Automatización con IA + scraping | Operaciones de ingresos y flujos de trabajo en navegador | Mejor cuando el scraping es solo un paso dentro de un flujo de automatización más amplio | Plan gratis y planes de pago |
| Diffbot | Plataforma de extracción con IA | Empresas y equipos de datos | La mejor opción cuando quieres extracción con IA y flujos de datos estructurados a gran escala | Precios de tipo empresarial |
| Instant Data Scraper | Raspador ligero para navegador | Usuarios ocasionales y capturas rápidas de tablas | Sigue siendo una de las formas más sencillas de llevar rápidamente una lista o tabla visible a CSV | Gratis |
| Octoparse | Raspador sin código | Analistas y equipos de operaciones con tareas recurrentes más grandes | Constructor visual maduro con extracción en la nube, anti-bloqueo y plantillas | Plan gratis, desde $69/mes, precio personalizado para empresas |
| ParseHub | Raspador low-code | Analistas que necesitan lógica y control de escritorio | Lógica de proyecto flexible y navegación anidada, con una curva de aprendizaje más pronunciada que las herramientas IA más nuevas | Plan gratis y planes de pago |
| Web Scraper | Raspador sin código | Principiantes y trabajos ligeros en la nube | Buen punto de entrada si te gusta el scraping basado en sitemap y la configuración centrada en el navegador | Extensión gratis, planes de nube de pago |
| Data Miner | Raspador para navegador | Investigadores y operadores de crecimiento | Sigue siendo útil para extracciones rápidas basadas en recetas dentro del navegador | Plan gratis y planes de pago |
| Apify | Plataforma API + Actor | Equipos técnicos y operadores híbridos | Excelente ecosistema de Actors más runtime personalizado cuando superas las extensiones de navegador | Plan gratis, desde $29/mes más uso, niveles de pago superiores |
| ScrapingBee | API de scraping | Desarrolladores que extraen sitios con mucho JS | Buena opción cuando quieres renderizado y gestión de proxies sin construir tú mismo la capa de navegador | Prueba gratis y planes de pago |
| ScraperAPI | API de scraping | Desarrolladores que escalan solicitudes rápido | API sencilla, créditos de prueba, productos estructurados y menos carga de infraestructura | Prueba de 7 días con 5.000 créditos, desde $49/mes |
| Bright Data | API empresarial + plataforma de proxies | Programas de gran volumen y alta exigencia de cumplimiento | La pila de recopilación de datos más amplia cuando el desbloqueo, los proxies y la adquisición gestionada importan más que la simplicidad | Precios por uso y por producto |
| Oxylabs | API empresarial + plataforma de proxies | Equipos que compran scraping como infraestructura | Muy sólido para recopilación a gran escala, especialmente para precios, SEO e investigación de mercado | La API de Web Scraper parte de $49/mes; los precios de proxy más amplios varían |
| Zyte | API + stack anti-bot | Equipos de desarrollo y datos | Buena opción si quieres extracción API-first con potentes primitivas de navegador, rotación y anti-detección | Prueba con $5 de crédito gratis, compromisos por uso |
| Selenium | Automatización de navegador de código abierto | Automatización estilo QA y flujos de interacción complejos | Sigue siendo útil cuando la fidelidad de la interacción del usuario importa más que el rendimiento del scraper | Gratis y de código abierto |
| BeautifulSoup4 | Analizador de código abierto | Principiantes y análisis ligero | Funciona mejor como analizador dentro de una pila sencilla, no como plataforma completa de scraping | Gratis y de código abierto |
| Scrapy | Framework de rastreo de código abierto | Rastreadores personalizados de producción | El mejor equilibrio entre potencia y madurez si quieres encargarte tú mismo de la canalización | Gratis y de código abierto |
| Puppeteer | Automatización de navegador de código abierto | Scraping con Node y scripts de navegador | Ideal si tu equipo ya se siente cómodo trabajando en el ecosistema de Chrome/Node | Gratis y de código abierto |
| Playwright | Automatización de navegador de código abierto | Automatización moderna mult navegador | Suele ser la opción más limpia para la automatización moderna del navegador, con gran ergonomía para desarrolladores | Gratis y de código abierto |
Cómo evalué estas herramientas
Apliqué cuatro filtros:
- Tiempo hasta el primer scraping exitoso
Si un usuario no técnico no puede obtener datos útiles rápido, eso cuenta. - Carga de mantenimiento
Una configuración rápida pierde sentido si el flujo se rompe cada vez que un sitio cambia. - Techo de escala
Hay herramientas perfectas para 50 páginas a la semana y pésimas para 5 millones de solicitudes al mes. - Encaje en el flujo de trabajo
La mejor herramienta para un equipo de operaciones de ingresos casi nunca es la mejor para un equipo de plataforma de datos.
El resultado no es un ranking universal. Es una guía de decisión para elegir primero la categoría correcta y después el producto adecuado dentro de esa categoría.
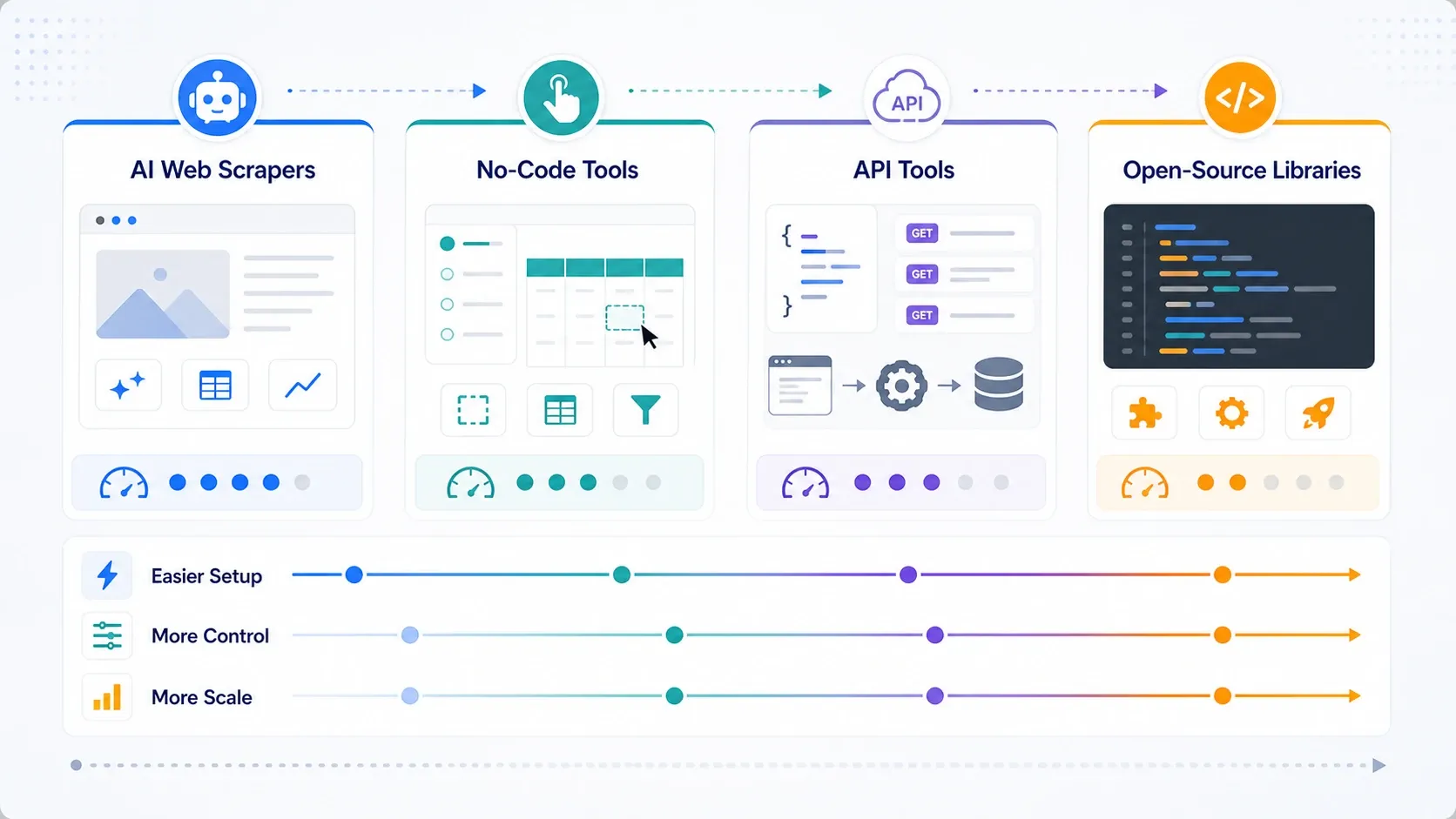
¿Qué tipo de herramienta de scraping web necesitas en realidad?
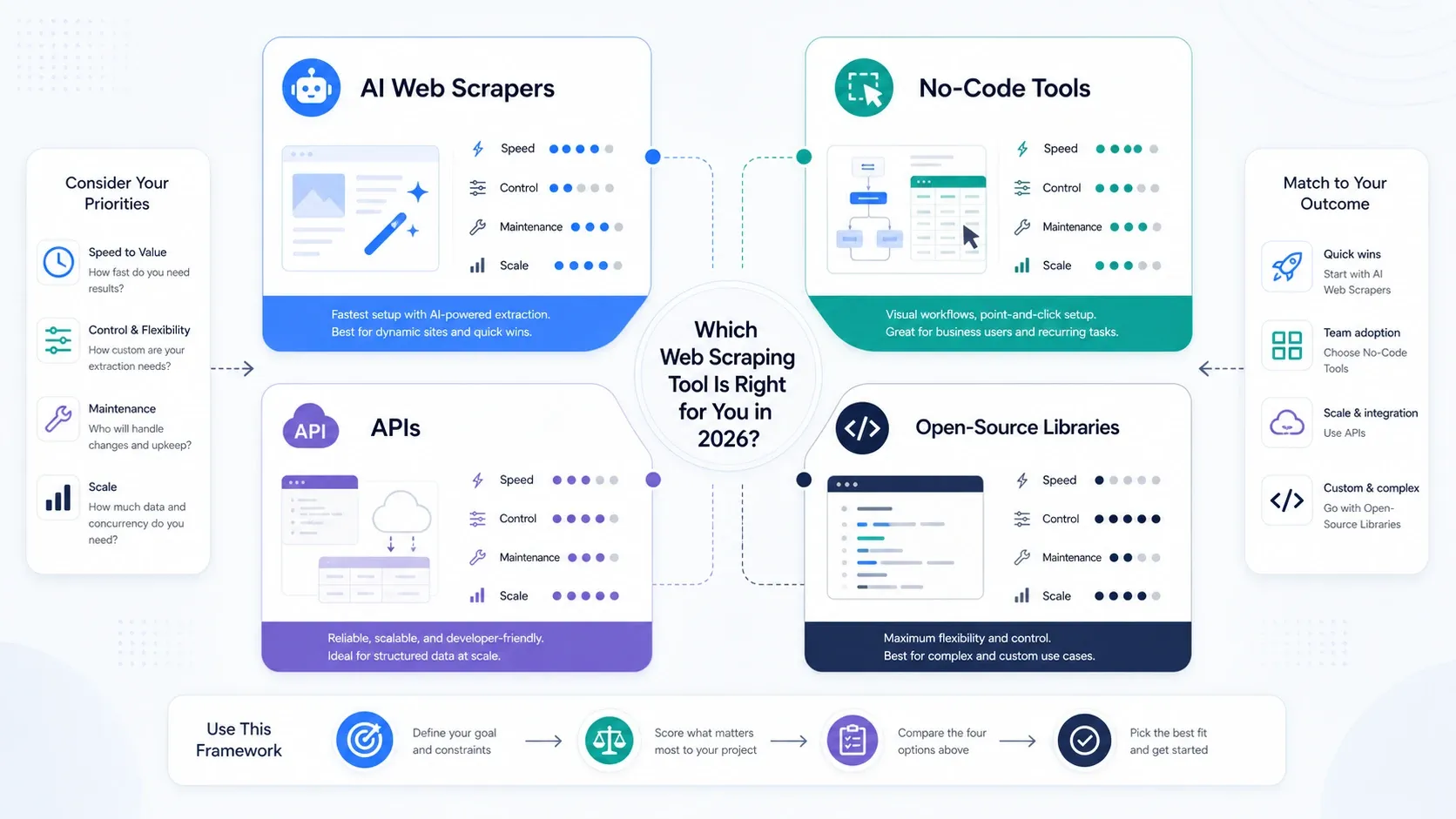
- Elige raspadores web IA si tu prioridad es la velocidad.
- Elige herramientas sin código si necesitas paginación, programación y control repetible de tareas.
- Elige APIs y plataformas de scraping si el renderizado, la rotación y la capacidad de desbloqueo ya son el cuello de botella.
- Elige bibliotecas de código abierto si tu equipo valora más el control que la comodidad y puede mantener la pila internamente.
Si tu equipo todavía está decidiendo si el scraping debe vivir en operaciones o en ingeniería, empieza con una herramienta IA o sin código. Aprenderás qué importa de verdad ejecutando trabajos reales, en lugar de sobredimensionar la pila desde el principio.
Mejores raspadores web IA para equipos de negocio
Son las herramientas que revisaría primero si el objetivo es obtener datos listos para hoja de cálculo con la menor configuración posible.
1. Thunderbit
Thunderbit es la opción más directa de esta lista si tu equipo quiere datos estructurados sin lidiar con selectores, scripts de navegador ni infraestructura de scraping. El flujo de trabajo se basa en sugerencias de campos con IA, enriquecimiento de subpáginas y exportación directa a las herramientas que ya usa el equipo.
- Ideal para: ventas, operaciones, ecommerce, inmobiliaria y otros equipos que trabajan mucho en el navegador.
- Por qué destaca: reduce el tiempo de configuración mejor que cualquier otra opción para usuarios sin código.
- A tener en cuenta: si necesitas lógica de rastreo muy personalizada o control de ingeniería muy especializado, en algún momento tendrás que bajar de nivel.
- Modelo de precios: plan gratuito, planes de autoservicio de pago y precios para empresas.
Si quieres ver el flujo real antes de seguir comparando, este recorrido es el mejor punto de partida:
2. Browse AI
Browse AI sigue siendo una gran opción para usuarios de negocio que quieren configuración de apuntar y hacer clic junto con supervisión recurrente. Su modelo de robot resulta especialmente útil cuando el scraping y la detección de cambios importan por igual.
- Ideal para: monitorizar páginas de precios, páginas de competidores y extracción repetible de listas.
- Por qué destaca: incorporación pulida, robots preconstruidos y un camino claro del sitio web a la hoja de cálculo o a la salida tipo API.
- A tener en cuenta: los trabajos complejos y de alto volumen pueden volverse caros o incómodos operativamente con más rapidez que en las pilas API-first.
- Modelo de precios: plan gratis, planes de pago, nivel premium/gestionado.
3. Bardeen
Bardeen gana enteros cuando el scraping es solo una acción dentro de un flujo de automatización más amplio. Si estás moviendo datos a un CRM, hojas de cálculo o flujos outbound, su enfoque en automatización pesa más que la profundidad pura de scraping.
- Ideal para: operaciones de ingresos, flujos de leads y automatización nativa del navegador.
- Por qué destaca: su historia de automatización de flujos es más completa que la de las herramientas de extracción puras.
- A tener en cuenta: no es la mejor alternativa cuando el scraping en sí es complejo y crítico para el negocio.
- Modelo de precios: plan gratis y planes de pago.
4. Diffbot
Diffbot va dirigido a equipos que necesitan extracción con IA a escala empresarial, no a quienes buscan la ruta más económica o más rápida. Tiene sentido cuando la calidad de los datos estructurados y la ingesta a gran escala pesan más que el control manual.
- Ideal para: equipos de datos empresariales, inteligencia de contenido y grandes programas de extracción.
- Por qué destaca: extracción estilo visión por computador y fuerte orientación a la salida estructurada.
- A tener en cuenta: para equipos pequeños resulta excesivo, y puede ser incómodo si tu caso de uso es ligero.
- Modelo de precios: planes empresariales y proceso comercial personalizado.
5. Instant Data Scraper
Instant Data Scraper sigue mereciendo un puesto porque hay muchas situaciones en las que solo necesitas exportar ahora mismo la tabla, el directorio o la lista que ves en pantalla. No es una plataforma, pero en muchos casos cumple de sobra.
- Ideal para: extracción puntual, listas rápidas de leads, directorios sencillos y tablas visibles.
- Por qué destaca: fricción casi nula para las páginas adecuadas.
- A tener en cuenta: automatización limitada, poca profundidad y encaje débil para flujos avanzados.
- Modelo de precios: gratis.
Mejores herramientas de scraping web sin código para trabajos repetibles
Cuando el trabajo va más allá del scraping ocasional, los constructores visuales y la ejecución en la nube empiezan a importar.
6. Octoparse
Octoparse sigue siendo una de las plataformas sin código más robustas si necesitas ejecuciones en la nube, cobertura de plantillas y una gestión de tareas más sofisticada que la que ofrece una extensión de navegador.
- Ideal para: analistas, equipos de precios y operadores que ejecutan trabajos recurrentes de recopilación.
- Por qué destaca: constructor de tareas maduro, extracción en la nube, funciones anti-bloqueo y gran ecosistema de plantillas.
- A tener en cuenta: es más potente que las herramientas de navegador con IA, pero eso también implica más sobrecarga de configuración.
- Modelo de precios: plan gratis, desde $69/mes, precio personalizado para empresas.
7. ParseHub
ParseHub sigue siendo una opción válida para usuarios que quieren más control que un raspador IA pero no quieren construir una base de código. Premia la paciencia, no la velocidad.
- Ideal para: analistas y operadores con curiosidad técnica que toleren una curva de aprendizaje más alta.
- Por qué destaca: lógica de navegación flexible y más control que las herramientas ligeras de navegador.
- A tener en cuenta: la experiencia de producto se siente más pesada que la de las opciones más recientes, sobre todo para equipos de negocio que necesitan moverse rápido.
- Modelo de precios: plan gratis y planes de pago.
8. Web Scraper
Web Scraper sigue siendo un punto de entrada razonable si te gusta el modelo de sitemap y quieres algo que empiece en el navegador y luego crezca hacia la programación en la nube.
- Ideal para: principiantes, proyectos personales y trabajos pequeños y repetibles.
- Por qué destaca: flujo de trabajo de sitemap accesible y adopción fácil desde el navegador.
- A tener en cuenta: se queda corto cuando necesitas una lógica de extracción más adaptable.
- Modelo de precios: extensión gratis para navegador y planes de nube de pago.
9. Data Miner
Data Miner se entiende mejor como una utilidad de extracción rápida que como una plataforma completa de scraping. Aun así, se gana su puesto porque el trabajo basado en recetas es útil para muchas tareas de investigación y prospección.
- Ideal para: investigadores, equipos de crecimiento y exportaciones rápidas desde el navegador.
- Por qué destaca: modelo de recetas, baja fricción y exportación sencilla.
- A tener en cuenta: no es la herramienta para scraping serio a escala de plataforma.
- Modelo de precios: plan gratis y planes de pago.
Mejores plataformas API cuando la escala y los bloqueos son el verdadero problema
Esta es la capa en la que los equipos de ingeniería dejan de preguntarse "¿cómo extraigo esta página?" y empiezan a pensar en "¿cómo hago que esto funcione de forma fiable a gran volumen?".
10. Apify
Apify es la plataforma más flexible de este grupo si quieres tanto un marketplace de scrapers reutilizables como un entorno para ejecutar tu propio código. Conecta mejor que la mayoría la exploración sin código y la ejecución para desarrolladores.
- Ideal para: equipos híbridos, scraping guiado por desarrolladores y flujos de automatización reutilizables.
- Por qué destaca: el ecosistema de Actors junto con el runtime personalizado le dan un alcance poco habitual.
- A tener en cuenta: cuando pasas a lo personalizado, vuelves al terreno de ingeniería y la ventaja de simplicidad se diluye.
- Modelo de precios: plan gratis, desde $29/mes más uso, niveles de mayor consumo y empresa.
11. ScrapingBee
ScrapingBee es una buena opción cuando lo que necesitas es: "dame una página renderizada y encárgate de la infraestructura por mí". Encaja bien con destinos cargados de JavaScript.
- Ideal para: desarrolladores que extraen sitios dinámicos con poca tolerancia al trabajo de infraestructura.
- Por qué destaca: API sencilla que cubre renderizado, proxies y automatización del navegador.
- A tener en cuenta: es un servicio de infraestructura — tú sigues encargándote del parsing, la lógica de reintentos y la calidad de datos aguas abajo.
- Modelo de precios: prueba y planes de pago.
12. ScraperAPI
ScraperAPI sigue siendo una de las formas más fáciles de delegar la gestión de proxies y las tasas de éxito de las solicitudes cuando quieres escalar rápido.
- Ideal para: desarrolladores que necesitan pasar de prototipo a volumen con rapidez.
- Por qué destaca: API directa, créditos de prueba, productos estructurados y niveles de escalado.
- A tener en cuenta: como todos los productos API-first, no elimina la necesidad de criterio de ingeniería en torno al parsing y la validación de datos.
- Modelo de precios: prueba de 7 días con 5.000 créditos, desde $49/mes.
13. Bright Data
Bright Data es la opción de peso pesado cuando la capacidad de desbloqueo, el inventario de proxies y la adquisición gestionada importan más que la simplicidad de la herramienta.
- Ideal para: programas empresariales, recopilación a gran escala con exigencias de cumplimiento y adquisición de datos gestionada.
- Por qué destaca: amplitud de productos de proxies, scraping, navegador y datasets.
- A tener en cuenta: caro y fácil de sobredimensionar si tu flujo principal sigue siendo relativamente simple.
- Modelo de precios: precios por uso y por producto para APIs, proxies y servicios gestionados.
14. Oxylabs
Oxylabs sigue siendo una gran opción para equipos que compran scraping como infraestructura, no como una herramienta de navegador. Resulta especialmente relevante cuando la fiabilidad y la madurez de adquisición son prioritarias.
- Ideal para: recopilación empresarial, supervisión de precios, supervisión SEO e investigación de mercado.
- Por qué destaca: infraestructura robusta, profundidad de proxies y proceso de compra empresarial más claro.
- A tener en cuenta: no es la mejor opción si tu equipo quiere un flujo de autoservicio informal.
- Modelo de precios: la API de Web Scraper parte de $49/mes; otros productos varían según unidad y uso.
15. Zyte
Zyte merece una consideración seria por parte de equipos de desarrollo y datos que quieren anti-detección, acciones de navegador, renderizado JavaScript e IPs rotatorias detrás de una sola propuesta API-first.
- Ideal para: equipos técnicos que construyen sistemas de extracción repetibles.
- Por qué destaca: acciones de navegador, renderizado JS, rotación de IPs y postura antibots en una sola pila.
- A tener en cuenta: mejor para equipos con responsabilidad de ingeniería que para operadores no técnicos.
- Modelo de precios: prueba con $5 de crédito gratis y compromisos mensuales por uso.
Mejores bibliotecas de código abierto para desarrolladores que quieren control total
Si quieres ser dueño de la pila de scraping de principio a fin, estos son los componentes más útiles en 2026.
16. Selenium
Selenium sigue siendo útil cuando necesitas fidelidad de interacción estilo QA, flujos de automatización heredados o un control muy explícito del recorrido del usuario.
- Ideal para: automatización con muchas interacciones, solapamiento con QA y sitios donde el comportamiento del navegador importa más que el rendimiento de rastreo.
- Por qué destaca: ecosistema maduro y amplio soporte de navegadores.
- A tener en cuenta: es más pesado y lento que herramientas de navegador más nuevas para muchas cargas de trabajo de scraping.
- Modelo de precios: gratis y de código abierto.
17. BeautifulSoup4

BeautifulSoup no es una plataforma completa de scraping, pero sigue siendo una de las formas más sencillas de analizar HTML desordenado en flujos ligeros.
- Ideal para: principiantes, scripts rápidos y tareas centradas en el parser.
- Por qué destaca: API sencilla y baja carga cognitiva.
- A tener en cuenta: combínalo con herramientas de requests, navegador o rastreo; por sí solo, es un parser.
- Modelo de precios: gratis y de código abierto.
18. Scrapy
Scrapy sigue siendo la respuesta cuando necesitas un framework de rastreo real en lugar de un puñado de scripts.
- Ideal para: rastreadores personalizados de producción y canalizaciones de datos de propiedad interna.
- Por qué destaca: alto rendimiento, pipelines, middleware y extensibilidad a largo plazo.
- A tener en cuenta: la sobrecarga de ingeniería es real, y los destinos con mucho JavaScript suelen requerir herramientas complementarias.
- Modelo de precios: gratis y de código abierto.
19. Puppeteer
Puppeteer sigue encajando bien en equipos centrados en Node que quieren control directo sobre Chromium y scripts de navegador.
- Ideal para: scraping con Node, capturas de pantalla y tareas de automatización del navegador.
- Por qué destaca: control directo y potente del comportamiento de Chromium.
- A tener en cuenta: alcance de navegadores más limitado que Playwright y alto consumo de recursos a escala.
- Modelo de precios: gratis y de código abierto.
20. Playwright
Playwright es la recomendación por defecto para la automatización moderna del navegador si tu equipo escribe código y quiere una abstracción más actual que Selenium.
- Ideal para: automatización moderna del navegador, sitios con mucho JavaScript y equipos que valoran la ergonomía para desarrolladores.
- Por qué destaca: modelo sólido multinavegador, comportamiento de espera fiable y APIs limpias.
- A tener en cuenta: la infraestructura del navegador, la concurrencia, el desplazamiento de selectores y la validación de datos siguen siendo responsabilidad tuya.
- Modelo de precios: gratis y de código abierto.
Mi lista corta por tipo de equipo
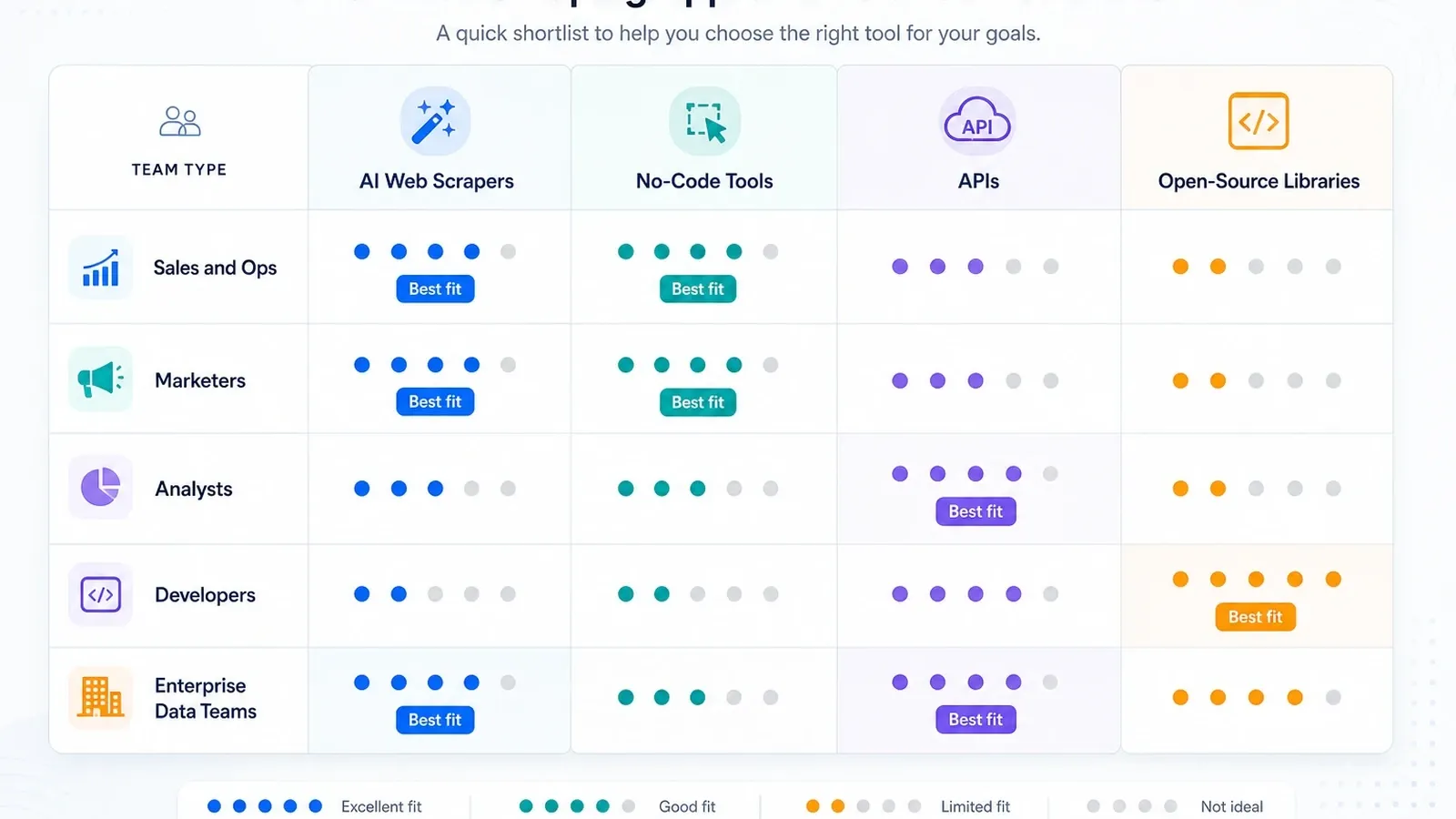
- Equipos de ventas y operaciones: empieza con Thunderbit y mira Browse AI si la supervisión importa más que el enriquecimiento de subpáginas.
- Analistas y equipos de investigación: Octoparse primero si los trabajos recurrentes son demasiado grandes para las extensiones de navegador.
- Equipos GTM con mucha automatización: Bardeen si el scraping es solo un paso dentro de un flujo más amplio.
- Equipos de desarrollo que construyen herramientas internas: Apify, Zyte, ScraperAPI o Playwright, según cuánto control de la pila quieras.
- Programas empresariales de datos: Bright Data, Oxylabs, Diffbot y Zyte son las conversaciones serias de infraestructura.
Cuándo bajar de nivel en la pila
Una regla sencilla:
- Quédate con las herramientas IA hasta que encuentres límites de repetibilidad o casos límite.
- Pasa a herramientas sin código cuando la programación, la paginación, el anti-bloqueo o las ejecuciones en la nube importen más que la simplicidad de un clic.
- Pasa a APIs cuando la tasa de desbloqueo, el renderizado JS y la concurrencia se conviertan en los cuellos de botella reales.
- Pasa a bibliotecas de código abierto cuando el coste de la abstracción del proveedor supere al de gestionar toda la pila.
La mayoría de los equipos baja de nivel antes de tiempo. Es uno de los errores más habituales que veo.
Conclusión final
Para la mayoría de los equipos no técnicos, la respuesta correcta en 2026 no es "el scraper más potente". Es la herramienta que lleva datos precisos al siguiente flujo de trabajo con el menor mantenimiento. Por eso las herramientas con IA siguen ganando entre los operadores, mientras que las APIs y las pilas de código abierto siguen siendo la mejor opción para equipos técnicos con necesidades claras de escala.
Si quieres el camino más corto de una página a una salida estructurada, empieza con Thunderbit. Si ya sabes que tu trabajo necesita infraestructura pesada, ve directamente a las capas de API y desarrolladores. Eso sí, no confundas complejidad con sofisticación.
Preguntas frecuentes
1. ¿Cuál es la mejor herramienta de scraping web para usuarios no técnicos en 2026?
Para la mayoría de los usuarios no técnicos, las herramientas con IA como Thunderbit y Browse AI ofrecen la ruta más rápida hacia datos útiles porque reducen el trabajo con selectores, la fricción de configuración y la carga de mantenimiento.
2. ¿Qué debo elegir si mis sitios tienen mucho JavaScript o bloquean solicitudes de forma agresiva?
Pásate a ScrapingBee, ScraperAPI, Zyte, Bright Data, Oxylabs, Playwright o Selenium, según prefieras un servicio gestionado o control directo de ingeniería.
3. ¿Siguen siendo relevantes las herramientas sin código ahora que los raspadores web IA son mejores?
Sí. Herramientas sin código como Octoparse y ParseHub siguen siendo importantes cuando necesitas un control más explícito de la lógica de tareas, la ejecución en la nube y la gestión repetible de trabajos.
4. ¿Qué herramientas tienen más sentido para equipos de ingeniería?
Apify, Zyte, ScraperAPI, Scrapy, Playwright, Puppeteer y Selenium son las opciones más naturales cuando los desarrolladores son dueños del flujo de trabajo.
5. ¿Cómo puedo hacer una lista corta rápidamente en lugar de investigar de más?
Primero elige el tipo de herramienta, no el proveedor. Decide si necesitas simplicidad con IA, control sin código, infraestructura API o propiedad de código abierto. Luego compara los productos dentro de esa capa.
Lecturas relacionadas