
“Puedes tener datos sin información, pero no puedes tener información sin datos.” —
Las estimaciones más recientes dicen que ya hay más de de sitios web en internet, y que cada día se publican cerca de 2 millones de entradas nuevas. En este mar de datos hay insights súper valiosos para tomar mejores decisiones, pero aquí viene el “pero”: alrededor del es información no estructurada, o sea, necesita un procesamiento extra para volverse realmente útil. Y justo ahí es donde brillan las herramientas de web scraping: hoy son casi obligatorias para cualquiera que quiera sacarle jugo a los datos online.
Si estás arrancando en el web scraping, cosas como y pueden sonar a “uff, qué pereza”. Pero en plena era de la IA, esas barreras ya no pesan tanto. Ahora, un raspador web ia te deja empezar sin tener que ser técnico ni saberte mil detalles. En la práctica, puedes recopilar y procesar datos rápido, sin ponerte a programar.
Las mejores herramientas y software de web scraping
- si quieres un Raspador Web IA fácil de usar y con resultados top
- para monitoreo en tiempo real y extracción masiva
- para automatización sin código con un montón de integraciones
- para web scraping visual más “pro”
- para scraping potente sin código, evitando bloqueos de IP y detección de bots
- para una API avanzada de extracción con IA y knowledge graphs
Prueba a usar IA para web scraping
Pruébalo: puedes hacer clic, explorar y ejecutar el flujo mientras lo ves.
¿Cómo funciona el web scraping?
El web scraping es, básicamente, sacar datos de sitios web. Tú le das a una herramienta unas instrucciones y ella se encarga de traerte texto, imágenes o lo que necesites a una tabla desde una página. Esto sirve para mil cosas: desde vigilar precios en e-commerce hasta juntar datos para investigación o, simplemente, montarte una hoja bien armada en Excel o Google Sheets.
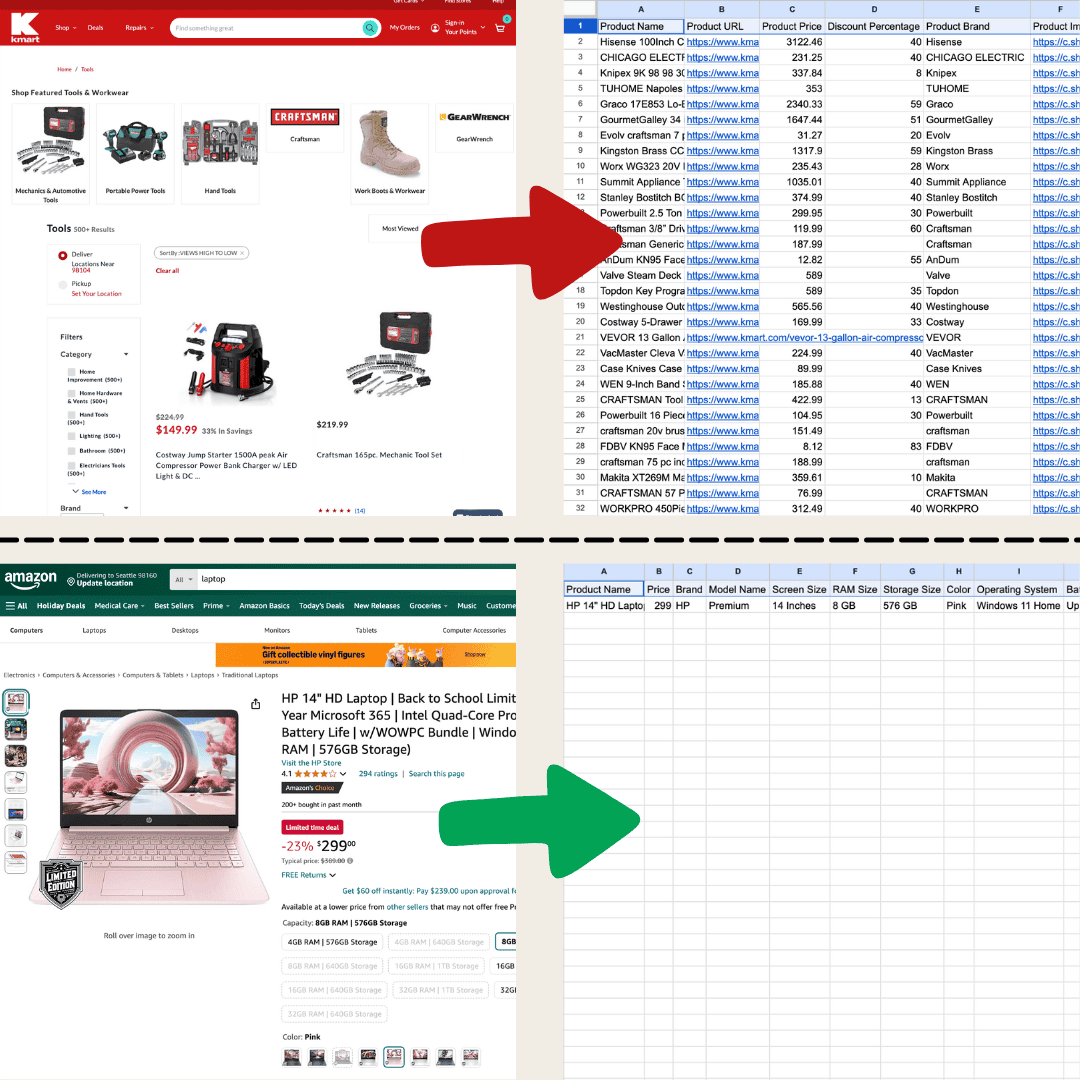 Lo hice con Thunderbit usando el Raspador Web IA.
Lo hice con Thunderbit usando el Raspador Web IA.
Hay varias maneras de hacerlo. En lo más básico, podrías copiar y pegar a mano, pero eso se vuelve imposible cuando el volumen crece. Por eso, casi todo el mundo termina usando uno de estos tres caminos: raspadores tradicionales, Raspador Web IA o código a medida.
Los raspadores tradicionales funcionan definiendo reglas súper específicas sobre qué capturar según la estructura de la página. Por ejemplo, puedes decirle que tome nombres de productos o precios desde ciertas etiquetas HTML. Van genial en sitios que cambian poco, porque cualquier ajuste de diseño normalmente te obliga a retocar el raspador.
 Aprender a usar un raspador tradicional toma su tiempo, y seguramente necesites decenas de clics para dejarlo bien configurado.
Aprender a usar un raspador tradicional toma su tiempo, y seguramente necesites decenas de clics para dejarlo bien configurado.
Los Raspador Web IA se entienden así: ChatGPT “se lee” el sitio completo y extrae el contenido según lo que tú necesitas. Encima, puede extraer, traducir y resumir al mismo tiempo. Gracias al procesamiento de lenguaje natural, analiza y entiende el layout del sitio, así que suele adaptarse mejor cuando hay cambios. Si el sitio reordena secciones, un Raspador Web IA puede ajustarse sin que tengas que reconfigurarlo todo desde cero. Por eso son perfectos para sitios “puñeteros” o con estructuras complejas.
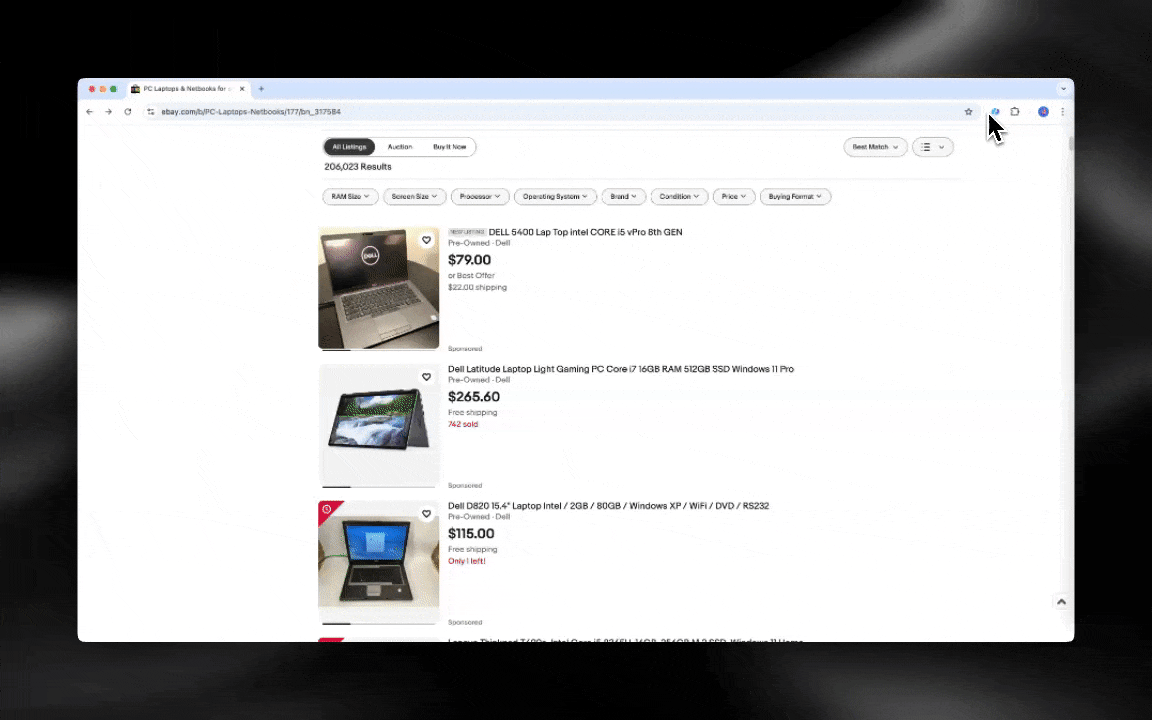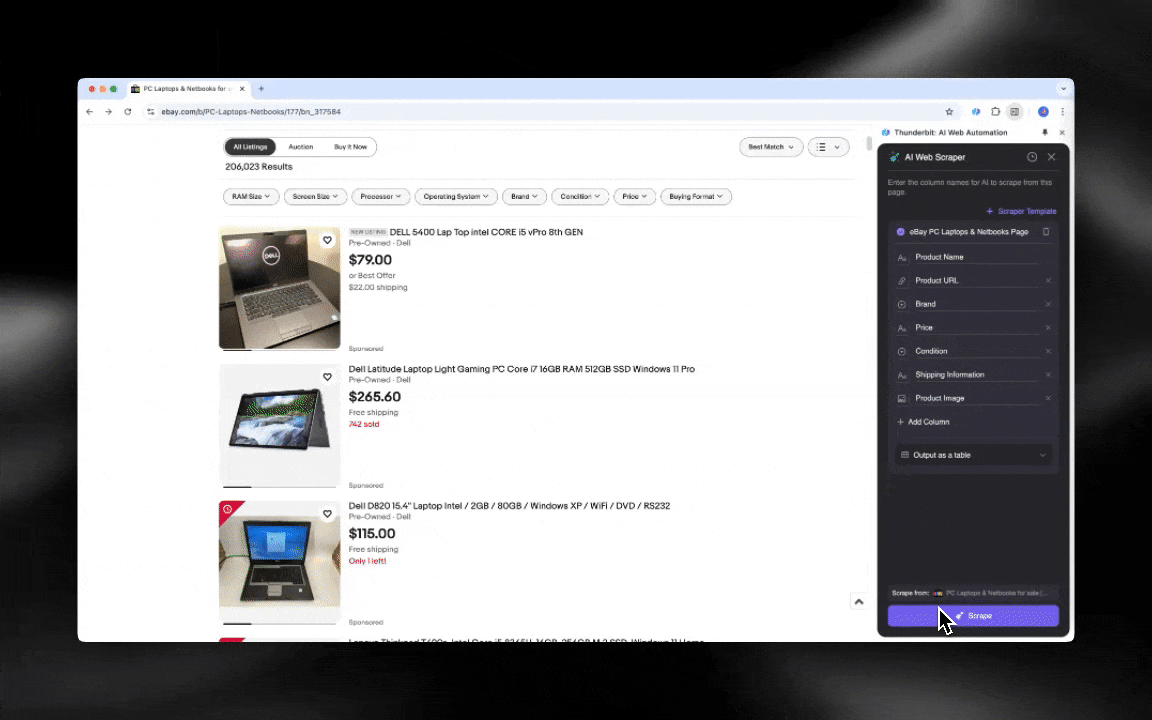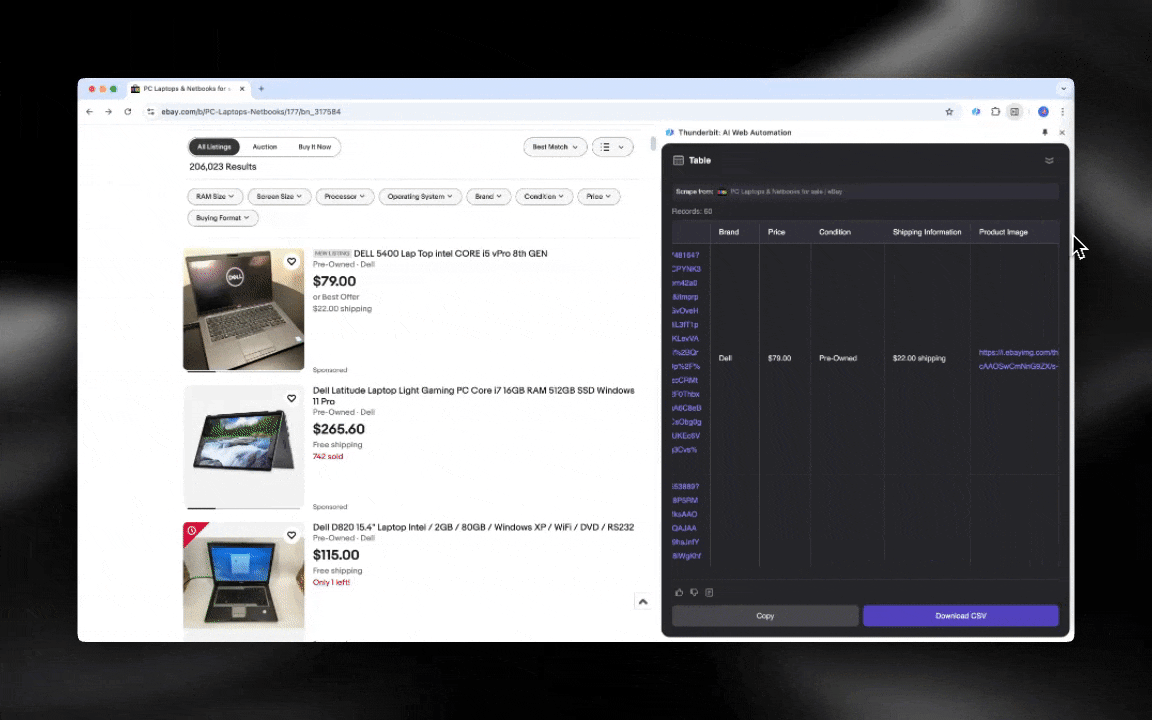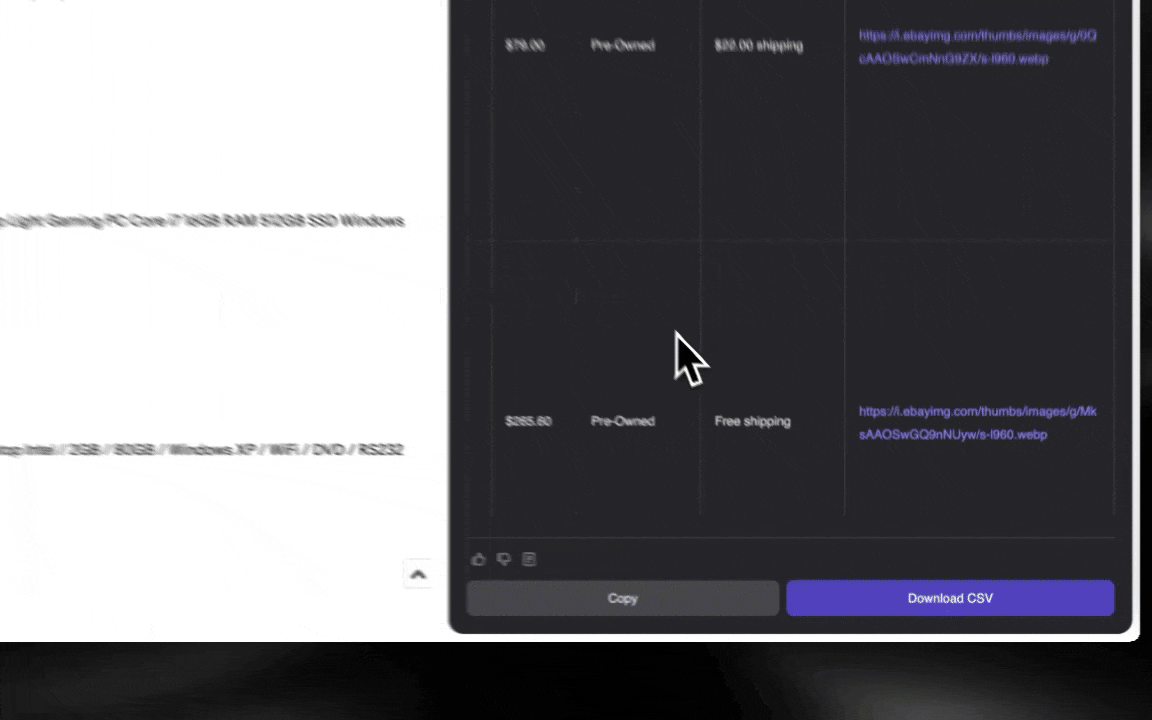 Con un Raspador Web IA es facilísimo empezar y sacar datos detallados en pocos clics.
Con un Raspador Web IA es facilísimo empezar y sacar datos detallados en pocos clics.
¿Cuál deberías elegir? Depende. Si te manejas bien con código o necesitas recolectar volúmenes enormes en un sitio súper popular, los raspadores tradicionales pueden ser muy eficientes. Pero si eres nuevo en web scraping o quieres algo que aguante mejor las actualizaciones del sitio, normalmente un Raspador Web IA es la mejor jugada. Mira la tabla para ver escenarios más concretos.
| Escenario | Mejor opción |
|---|---|
| Scraping ligero en páginas como directorios, tiendas online o cualquier sitio con listados | Raspador Web IA |
| La página tiene menos de 200 filas y crear un raspador tradicional llevaría demasiado tiempo | Raspador Web IA |
| Necesitas un formato específico para subir los datos a otra herramienta (por ejemplo, contactos para HubSpot) | Raspador Web IA |
| Sitios muy usados a gran escala, como decenas de miles de páginas de productos de Amazon o listados de Zillow | Raspador Web tradicional |
Las mejores herramientas y software de web scraping: resumen rápido
| Herramienta | Precio | Funciones clave | Pros | Contras |
|---|---|---|---|---|
| Thunderbit | Desde $9/mes, con plan gratis | Raspador Web IA, detecta y da formato automáticamente, soporta varios formatos, exportación en un clic, interfaz sencilla. | Sin código, soporte con IA, integraciones con apps como Google Sheets | El scraping a gran escala puede ser más lento, algunas funciones avanzadas cuestan más |
| Browse AI | Desde $48.75/mes, con plan gratis | Interfaz sin código, monitoreo en tiempo real, extracción masiva, integración de flujos. | Fácil de usar, integra con Google Sheets y Zapier | Páginas complejas requieren más configuración, el scraping masivo puede generar timeouts |
| Bardeen AI | Desde $60/mes, con plan gratis | Automatización sin código, integra con 130+ apps, MagicBox convierte tareas en flujos. | Muchísimas integraciones, escalable para empresas | Curva de aprendizaje para nuevos usuarios, configuración inicial lenta |
| Web Scraper | Gratis en local, $50/mes en la nube | Creación visual de tareas, soporta sitios dinámicos (AJAX/JavaScript), scraping en la nube. | Funciona bien en sitios dinámicos | Para configurarlo “bien” suele requerir conocimientos técnicos |
| Octoparse | Desde $119/mes, con plan gratis | Scraping sin código, autodetección de elementos, scraping en la nube con tareas programadas, biblioteca de plantillas. | Muy potente en sitios dinámicos, maneja restricciones | Sitios complejos requieren aprendizaje |
| Diffbot | Desde $299/mes | API de extracción, API sin reglas, NLP para texto no estructurado, knowledge graph amplio. | Extracción con IA muy sólida, integración por API, scraping a gran escala | Curva de aprendizaje para no técnicos, tiempo de configuración |
El mejor web scraper en la era de la IA
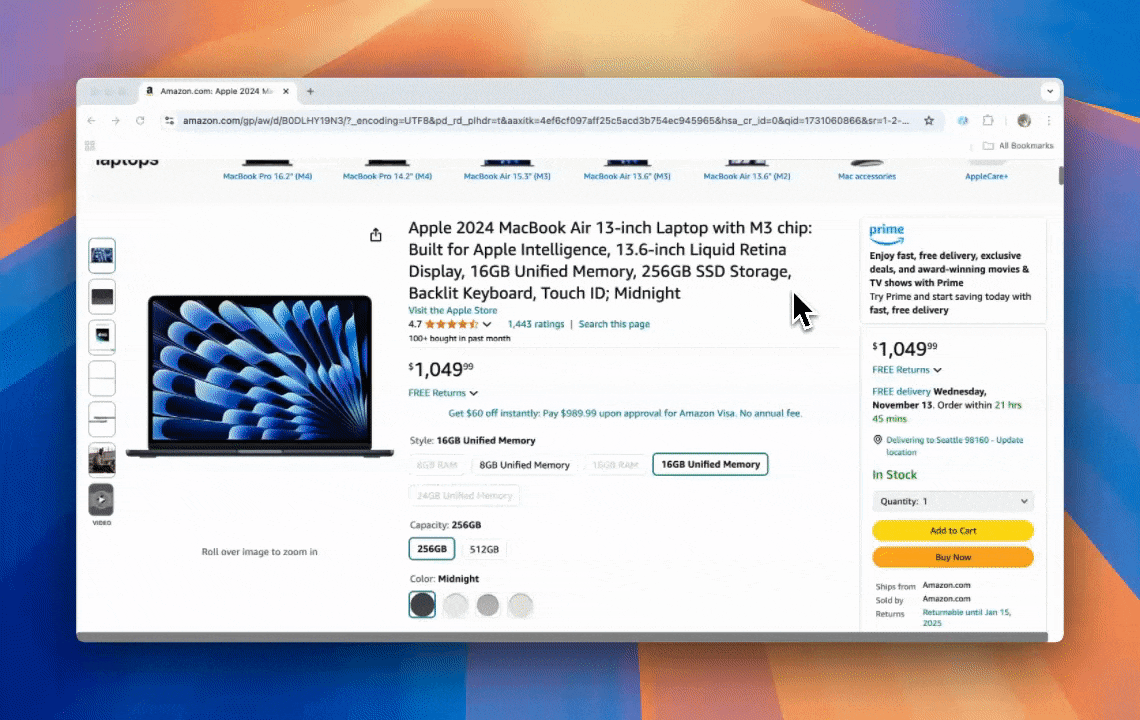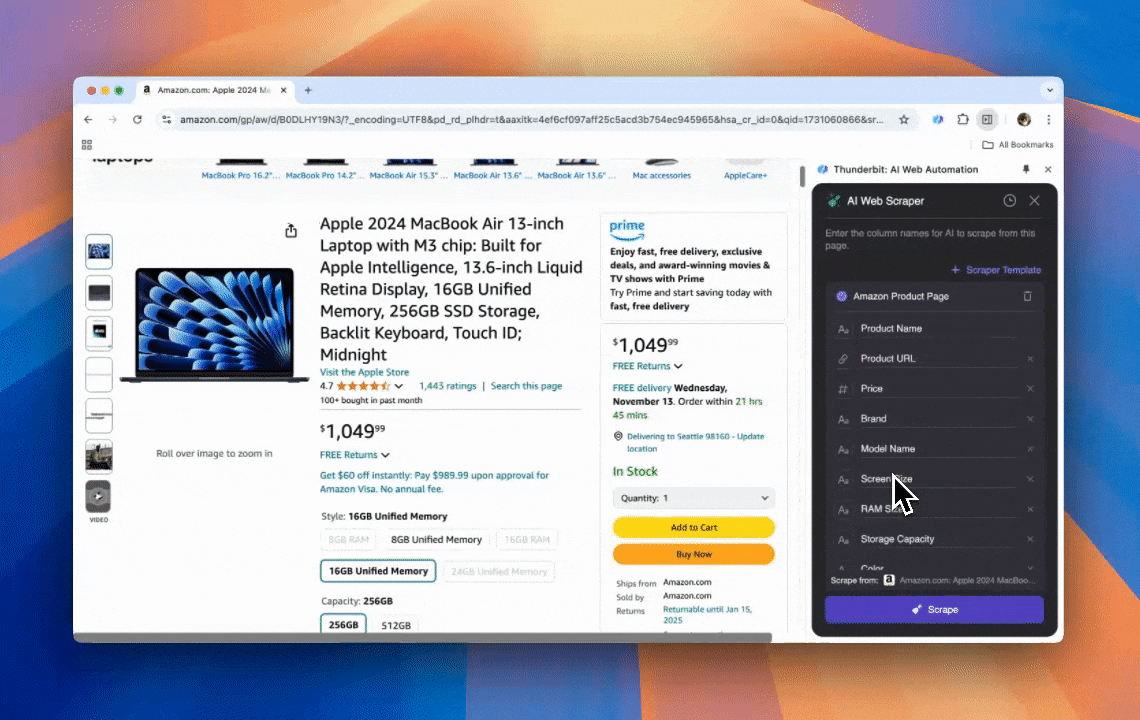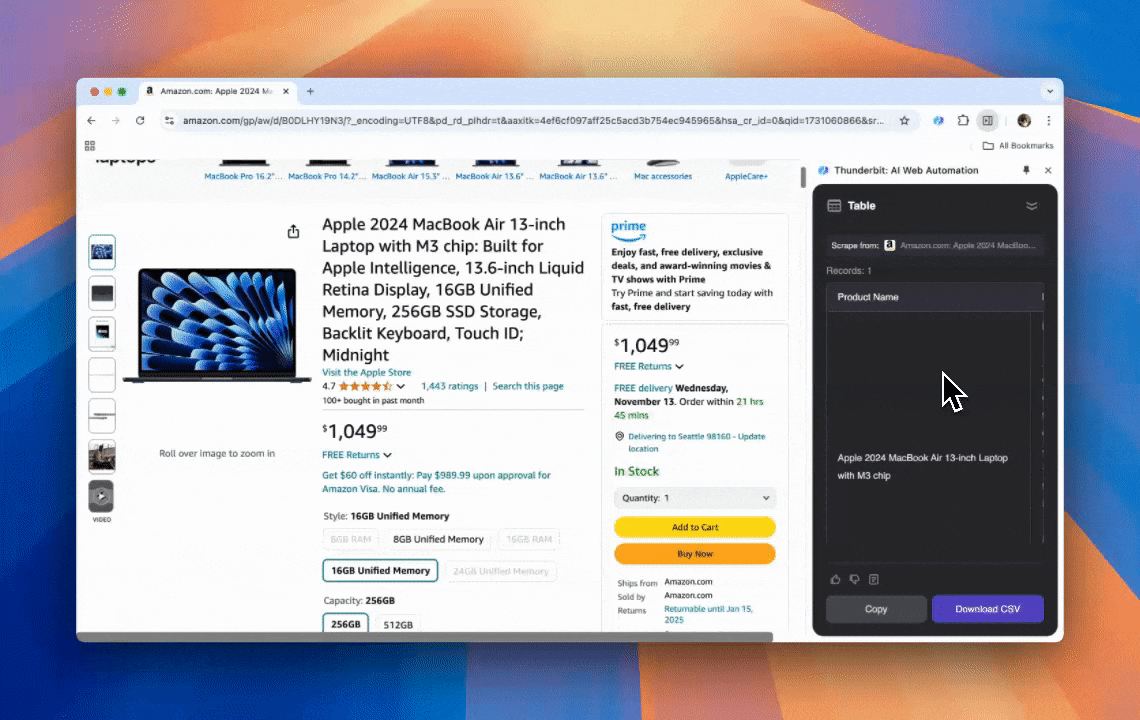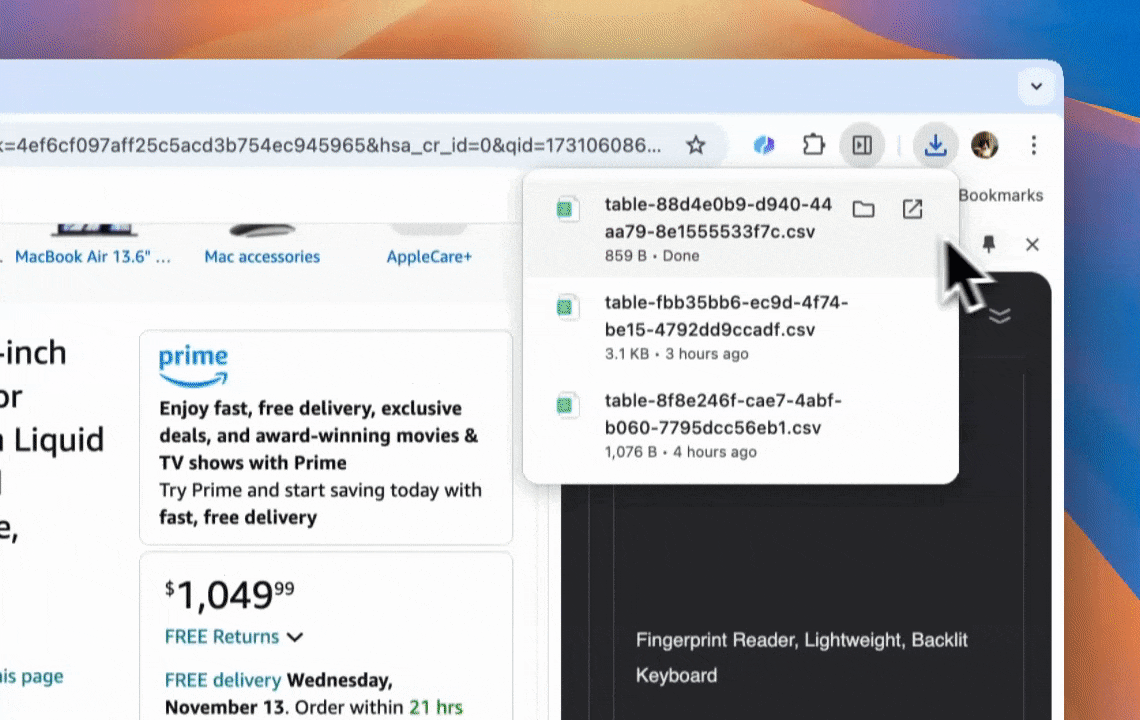
Thunderbit es una herramienta potente y muy fácil de usar para automatización web con IA, pensada para que cualquiera (incluso sin programar) pueda extraer y ordenar datos sin líos. Con su , el de Thunderbit hace que el scraping sea mucho más llevadero: puedes sacar datos rápido sin “pelearte” con los elementos de la página ni tener que crear raspadores distintos para cada diseño.
Funciones clave
- Flexibilidad impulsada por IA: el Raspador Web IA de Thunderbit detecta y formatea datos automáticamente, sin necesidad de selectores CSS.
- La experiencia de scraping más simple: solo haces clic en “AI suggest column” y luego en “Scrape” en la página que quieras extraer. Ya está.
- Compatibilidad con distintos formatos de datos: Thunderbit puede extraer URLs, imágenes y mostrar los datos capturados en varios formatos.
- Procesamiento automático de datos: la IA puede reformatear al vuelo, incluyendo resumir, categorizar y traducir al formato requerido.
- Exportación fácil: exporta a Google Sheets, Airtable o Notion con un clic.
- Interfaz amigable: diseño intuitivo para usuarios de cualquier nivel.
Precios
Thunderbit tiene planes por niveles desde $9 al mes por 5.000 créditos, hasta $199 por 240.000 créditos. Además, con el plan anual recibes todos los créditos por adelantado.
Pros:
- La IA hace más fácil tanto la extracción como el procesamiento.
- Sin código, accesible para cualquier nivel.
- Ideal para scraping ligero (directorios, tiendas online, etc.).
- Integraciones sólidas para exportar directo a apps populares.
Contras:
- El scraping a gran escala puede tardar un poco para asegurar precisión.
- Algunas funciones avanzadas requieren suscripción de pago.
¿Quieres más información? Empieza por , o mira con Thunderbit.
El mejor web scraper para monitoreo de datos y extracción masiva
Browse AI
Browse AI es una herramienta de scraping sin código bastante sólida, hecha para extraer y monitorear datos sin escribir ni una línea. Tiene algunas funciones de IA, aunque no llega al nivel de un scraping 100% basado en IA. Aun así, para la mayoría de usuarios, te deja arrancar sin complicarte.
Funciones clave
- Interfaz sin código: permite crear flujos personalizados a punta de clics.
- Monitoreo en tiempo real: usa bots para detectar cambios en páginas y entregar información actualizada.
- Extracción masiva: puede manejar hasta 50.000 registros en una sola ejecución.
- Integración de flujos: conecta varios bots para procesos más complejos.
Precios
Desde $48.75 al mes, incluyendo 2.000 créditos. También hay un plan gratuito con 50 créditos mensuales para probar funciones básicas.
Pros:
- Integraciones con Google Sheets y Zapier.
- Bots preconfigurados para tareas comunes.
Contras:
- En páginas complejas puede necesitar ajustes extra.
- La velocidad en scraping masivo varía y a veces provoca timeouts.
El mejor web scraper para integrar flujos de trabajo
Bardeen AI
Bardeen AI es una herramienta de automatización sin código pensada para optimizar flujos conectando distintas apps. Usa IA para crear automatizaciones personalizadas, aunque no tiene la misma capacidad de adaptación que un Raspador Web IA completo.
Funciones clave
- Automatización sin código: montas flujos con clics.
- MagicBox: describes la tarea en lenguaje natural y Bardeen AI la convierte en un flujo.
- Amplias integraciones: más de 130 apps, incluyendo Google Sheets, Slack y LinkedIn.
Precios
Desde $60 al mes, con 1.500 créditos (aprox. 1.500 filas). El plan gratuito ofrece 100 créditos al mes para probar lo básico.
Pros:
- Muchísimas integraciones para necesidades variadas.
- Flexible y escalable para empresas de cualquier tamaño.
Contras:
- Los nuevos usuarios pueden necesitar tiempo para agarrarle el truco.
- La configuración inicial puede llevar bastante tiempo.
El mejor web scraper visual para usuarios con experiencia
Web Scraper
Sí, tal cual: la herramienta se llama "Web Scraper". Es una extensión muy popular para Chrome y Firefox que te deja extraer datos sin programar, con un enfoque visual para armar tareas de scraping. Eso sí: lo normal es que tengas que dedicarle unos días a ver y practicar con los tutoriales de arriba para dominarla bien. Si quieres algo más “tranqui” y directo, mejor vete por un Raspador Web IA.
Funciones clave
- Creación visual: configuras tareas haciendo clic en elementos de la web.
- Soporte para sitios dinámicos: maneja AJAX y JavaScript.
- Scraping en la nube: programa tareas con Web Scraper Cloud para ejecuciones periódicas.
Precios
Gratis para uso local; los planes de nube arrancan en $50/mes.
Pros:
- Va muy bien en sitios dinámicos.
- Gratis en local.
Contras:
- Para dejarlo “fino” suele requerir conocimientos técnicos.
- Los cambios en el sitio exigen pruebas y ajustes.
El mejor web scraper para evitar bloqueos de IP y detección de bots
Octoparse
Octoparse es un software versátil, más orientado a gente técnica que necesita recopilar y monitorear datos web específicos sin programar, sobre todo cuando el volumen es grande. No depende del navegador del usuario: usa servidores en la nube para hacer el scraping. Por eso puede ofrecer varios métodos para esquivar bloqueos de IP y ciertos sistemas anti-bot.
Funciones clave
- Uso sin código: crea tareas de scraping sin escribir código, apto para distintos niveles técnicos.
- Autodetección inteligente: identifica automáticamente datos y elementos extraíbles, acelerando la configuración.
- Scraping en la nube: scraping 24/7 con tareas programadas.
- Biblioteca amplia de plantillas: cientos de plantillas para sitios populares, para sacar datos rápido sin configuraciones complejas.
Precios
Desde $119 al mes, incluyendo 100 tareas. También hay un plan gratuito con 10 tareas al mes para probar.
Pros:
- Funciones potentes para sitios dinámicos y alta adaptabilidad.
- Soluciones para restricciones de scraping y contenido dinámico.
Contras:
- Estructuras complejas requieren más tiempo de configuración.
- Los nuevos usuarios necesitan tiempo para aprender buenas prácticas.
El mejor web scraper para una API avanzada de extracción con IA
Diffbot
Diffbot es una herramienta avanzada de extracción de datos web que usa IA para convertir contenido no estructurado en datos estructurados. Con APIs potentes y un knowledge graph, Diffbot ayuda a extraer, analizar y gestionar información de la web, útil para múltiples industrias y casos de uso.
Funciones clave
- API de extracción de datos: ofrece una API “sin reglas”; basta con pasar una URL para extraer automáticamente, sin definir reglas por sitio.
- API de procesamiento de lenguaje natural: extrae entidades, relaciones y sentimiento desde texto no estructurado, útil para construir knowledge graphs propios.
- Knowledge Graph: uno de los más grandes, conectando datos de entidades (personas y organizaciones) a gran escala.
Precios
Desde $299 al mes, incluyendo 250.000 créditos (aprox. 250.000 extracciones de páginas vía API).
Pros:
- Extracción “sin reglas” muy adaptable.
- Muchas opciones de integración por API.
- Soporta scraping a gran escala, ideal para empresas.
Contras:
- Para usuarios no técnicos, el arranque puede requerir aprendizaje.
- Para usarlo, necesitas programar llamadas a la API.
¿Para qué puedes usar los scrapers?
Si estás empezando con el web scraping, aquí van algunos casos de uso típicos para arrancar. Mucha gente usa scrapers para sacar listados de productos de Amazon, extraer datos inmobiliarios de Zillow o recopilar información de negocios desde Google Maps. Pero eso es solo el comienzo: con el de Thunderbit puedes recopilar datos de casi cualquier sitio web, simplificando tareas y ahorrándote tiempo en el día a día. Ya sea para investigación, seguimiento de precios o creación de bases de datos, el web scraping abre un montón de maneras de poner los datos de internet a trabajar para ti.
Preguntas frecuentes
-
¿Es legal el web scraping?
En general, el web scraping es legal, pero tienes que respetar los términos de servicio del sitio y el tipo de datos al que accedes. Revisa siempre las políticas aplicables y cumple con las normas legales.
-
¿Necesito saber programar para usar herramientas de web scraping?
La mayoría de las herramientas de esta lista no requieren programación. Aun así, en opciones como Octoparse y Web Scraper ayuda tener nociones básicas de estructuras web y una mentalidad más técnica para sacarles todo el provecho.
-
¿Hay herramientas gratuitas de web scraping?
Sí. Hay herramientas gratuitas como BeautifulSoup, Scrapy y Web Scraper, y varias plataformas también ofrecen planes gratis con funciones limitadas.
-
¿Cuáles son los retos más comunes del web scraping?
Entre los desafíos típicos están el contenido dinámico, los CAPTCHAs, el bloqueo de IP y estructuras HTML complejas. Con herramientas y técnicas avanzadas, estos problemas se pueden abordar de forma efectiva.
Más recursos:
-
Usa IA para trabajar sin esfuerzo.