
Google procesa más de —algunas estimaciones lo sitúan más cerca de —y esa cifra no deja de crecer. Todos esos datos de búsqueda son una mina de oro para equipos de SEO, operaciones de ventas, analistas de ecommerce y, cada vez más, agentes de IA que necesitan evidencia web en tiempo real. ¿El problema? Elegir una SERP API en 2026 se parece menos a escoger una herramienta y más a descifrar un laberinto de páginas de precios, sistemas de créditos y vagas promesas sobre "JSON estructurado".
He pasado las últimas semanas investigando a fondo ocho proveedores de SERP API: probando tiempos de respuesta, normalizando precios entre modelos de facturación confusos y comprobando qué funciones de la SERP analiza realmente cada uno en campos estructurados. El objetivo: darte una comparación honesta, de manzanas con manzanas, que no vas a encontrar en otro sitio. Vamos a cubrir velocidad, coste real a escala, cobertura de análisis, preparación para agentes de IA y fiabilidad en producción. Si te ha frustrado eso de "estás comparando páginas de precios, no el gasto real" (una cita real de un que encontré), esto es para ti.
Por qué necesitas una SERP API en 2026 (y por qué elegir una es difícil)
Una SERP API es un servicio alojado que envía una consulta de búsqueda a un motor de búsqueda y devuelve la página de resultados en un formato legible por máquina, normalmente JSON. En lugar de montar tu propia rotación de proxies, gestión de CAPTCHA, renderizado del navegador y parsers, llamas a un endpoint y recibes datos estructurados. Concepto simple, mercado complicado.
Los casos de uso han ido mucho más allá del seguimiento de posiciones:
- Los equipos de SEO necesitan rankings, propiedad de snippets, preguntas de People Also Ask y visibilidad de la competencia.
- Los equipos de ventas y GTM usan las SERP para descubrir empresas, páginas de reseñas, directorios y señales de compra.
- Los equipos de ecommerce monitorizan Google Shopping, anuncios de pago y precios de la competencia.
- Los desarrolladores de IA alimentan datos de SERP en agentes LLM, pipelines RAG y herramientas de flujo de trabajo como n8n y LangChain.
Se proyecta que el alcance los , creciendo a una tasa anual compuesta de alrededor del 13,78 %. Las SERP API son una parte importante de ese pastel.
Aquí está la frustración principal: todos los proveedores dicen ofrecer "JSON estructurado", pero los elementos de la SERP que realmente analizan —PAA, paneles de conocimiento, paquetes locales, anuncios de shopping, fragmentos destacados— varían muchísimo entre unos y otros. Los precios también son un lío. Algunos cobran por búsqueda, otros por crédito, otros por resultado, y algunos aplican tarifas distintas según el nivel de velocidad o la geolocalización. Un usuario de Reddit lo resumió bien: "SerpApi cobra por búsqueda exitosa, ScraperAPI lo empaqueta todo en créditos, y Serperdev parece barato hasta que conviertes los créditos a tu carga de trabajo real".
Este artículo cubre los huecos que no pude encontrar en ningún otro sitio: una matriz de análisis que muestra lo que devuelve realmente cada API, precios normalizados a 1.000/10.000/100.000 consultas, compatibilidad con agentes de IA y datos de preparación para producción.
Cómo probamos: criterios para elegir la mejor SERP API
Evalué cada proveedor en ocho dimensiones que se corresponden directamente con lo que de verdad importa a los usuarios de producción. La mayoría de los artículos de la competencia cubren dos o tres de estas de forma superficial. Yo quería las ocho, con pruebas.
Velocidad y tiempo de respuesta. Tomé como referencia benchmarks de terceros —en particular la — y la documentación de los proveedores. La velocidad importa cuando estás creando paneles en tiempo real o agentes de IA que llaman herramientas y no pueden esperar 30 segundos por una respuesta.
Precios a escala (1.000, 10.000, 100.000 consultas). Normalicé el precio de cada proveedor a coste por cada 1.000 consultas exitosas. Es la única forma de comparar de manera justa modelos basados en créditos, suscripción y pago por uso.
Funciones de SERP analizadas (más allá de los resultados orgánicos). Revisé documentación y respuestas de ejemplo para verificar qué elementos de la SERP devuelve cada API como campos estructurados, no solo HTML en bruto.
Disponibilidad de plan gratuito y pago por uso. Importa poder empezar con poco compromiso. Si no puedes probar un proveedor con tu carga de trabajo real antes de comprometer cientos de dólares, es una señal de alerta.
Integración con IA y automatización. En 2026, más equipos necesitan que las SERP API alimenten agentes de IA que paneles. La estabilidad del esquema, la salida limpia y la conversión a Markdown son importantes para el consumo posterior por parte de LLM.
Compatibilidad con varios motores. La mayoría de los artículos se centran exclusivamente en Google. Revisé qué proveedores admiten Bing, Yandex, DuckDuckGo, Baidu y otros.
Límites de tasa y preparación para producción. Ningún artículo de la competencia compara sistemáticamente límites de tasa, políticas de reintento o SLA. Y aun así, los equipos que escalan a miles de consultas al día necesitan esa información.
Facilidad para desarrolladores. Calidad de la documentación, disponibilidad de SDK y tiempo hasta el primer resultado.
1. Thunderbit
adopta un enfoque fundamentalmente distinto al de las SERP API tradicionales. En lugar de ofrecer endpoints fijos que analizan elementos predeterminados de la SERP, la Extract API de Thunderbit te permite definir tu propio JSON Schema, y la IA extrae exactamente los campos que especifiques de cualquier página de resultados de búsqueda. Su Distill API convierte cualquier URL en Markdown limpio, listo para LLM.
Eso significa que Thunderbit funciona en Google, Bing, Yandex, DuckDuckGo o cualquier otro motor de búsqueda: la IA lee la página desde cero cada vez en lugar de depender de selectores codificados. Los diseños de las SERP cambian constantemente. No tienes que esperar a que un proveedor actualice un parser.
Funciones clave
- Extract API: Define un JSON Schema personalizado (resultados orgánicos, preguntas de PAA, empresas del paquete local, productos de shopping, lo que necesites) y recibe exactamente esos campos como datos estructurados.
- Distill API: Convierte cualquier página de SERP en Markdown limpio, ideal para pipelines RAG y resumir con LLM.
- Multi-motor por diseño: Funciona en cualquier página de búsqueda accesible, no solo en Google.
- Procesamiento por lotes: Gestiona varias URLs en paralelo.
- Gestión anti-bot integrada: Incluye resolución de CAPTCHA, renderizado JS y rotación de proxies.
- Límites de tasa por nivel: Free (10 req/min, 2 concurrentes), Pro (100 req/min, 10 concurrentes), Enterprise (1.000 req/min, 50 concurrentes).
Precios
Modelo basado en créditos. Distill cuesta 1 crédito por página; Extract cuesta 20 créditos por página. Hay créditos gratuitos para pruebas. Usando la matemática del plan anual, el coste marginal de Distill puede llegar a ser tan bajo como ~0,80 USD por cada 1.000 páginas, mientras que Extract ronda ~16 USD por cada 1.000 páginas al uso máximo. La propuesta de valor de Extract es que obtienes exactamente el esquema que necesita tu sistema downstream, sin posprocesado.
Consulta para ver los paquetes actuales.
Ideal para
Flujos de trabajo con agentes de IA, pipelines RAG, scraping multi-motor, equipos que necesitan un esquema flexible en lugar de una salida fija y cualquiera que esté cansado de esperar a que un proveedor añada soporte para una nueva función de la SERP.
2. SerpApi
es el veterano del sector: opera desde 2016 y ofrece la gama más amplia de endpoints específicos de Google. Cubre Google Search, Maps, Shopping, Scholar, News, Jobs, Trends, Images, Videos y más.
Funciones clave
- Endpoints dedicados para distintos productos de Google con geolocalización madura, hasta nivel de ciudad.
- Analiza PAA, paneles de conocimiento, paquete local, anuncios, resultados de shopping, fragmentos destacados, cajas de respuesta y búsquedas relacionadas como campos estructurados.
- Documentación bien mantenida y bibliotecas cliente en varios idiomas.
Precios
. Plan Starter: 25 USD/mes por 1.000 búsquedas (efectivamente 25 USD por 1.000). Plan Popular: 130 USD/mes por 15.000 búsquedas (~8,67 USD por 1.000). Big Data: 2.750 USD/mes por 500.000 búsquedas (~5,50 USD por 1.000). No hay una opción simple de pago por uso: funciona con paquetes de suscripción.
Velocidad y fiabilidad
El benchmark de HasData informa de ~5,49 segundos de tiempo medio de respuesta: no es el más rápido, pero sí estable. SerpApi anuncia un SLA de disponibilidad del 99,95 % en los planes de pago, y los límites de solicitudes concurrentes varían según el plan.
Ideal para
Equipos que necesitan la cobertura más amplia de productos de Google (Maps, Scholar, Shopping, Jobs) con alta precisión y esquemas estables. Proyectos enterprise con presupuesto para precios premium.
3. Serper
apuesta por velocidad y coste. Es un proveedor más reciente centrado en scraping rápido de SERP de Google a un precio extremadamente competitivo, y se ha vuelto popular en las comunidades de n8n y LangChain por sus integraciones con agentes de IA.
Funciones clave
- Salida JSON limpia para Google Search, News, Scholar, Images, Shopping, Videos, Places, Patents y Autocomplete.
- Configuración mínima: puedes empezar a extraer resultados en menos de un minuto.
- Lo bastante sencillo como para que los frameworks de agentes de IA lo integren de forma nativa.
Precios
2.500 consultas gratis al registrarte. El precio de entrada ronda 0,001 USD por búsqueda, bajando a ~0,00075 USD con gran volumen. Amigable con el pago por uso. Una salvedad: pedir más de 10 resultados por consulta puede costar 2 créditos (verifica el comportamiento actual en tu panel).
Velocidad y fiabilidad
Está entre los más rápidos en los benchmarks: HasData informa de unos 2,87 segundos de media. El soporte es solo por email y el equipo mantiene un perfil público relativamente bajo, lo que deja a algunos usuarios con dudas. A concurrencias muy altas, algunos revisores señalan problemas de fiabilidad. Para la mayoría de las cargas, eso sí, es sólido.
Ideal para
Proyectos con presupuesto ajustado, startups e integraciones de agentes de IA que necesitan datos rápidos y baratos de SERP de Google. Seguimiento de rankings de gran volumen donde el coste por consulta es la principal restricción.
4. Scrapingdog
lleva más de 5 años en el mercado y aparece de forma consistente como el más rápido en benchmarks de terceros. HasData lo midió en con una tasa de éxito del 100 %.
Funciones clave
- La Google SERP API devuelve resultados orgánicos, PAA, fragmentos destacados, anuncios y resultados locales como JSON estructurado.
- Disponibles tanto HTML en bruto como JSON analizado.
- Documentación en varios idiomas con fragmentos de código para la mayoría de lenguajes de programación: empezar lleva minutos, no horas.
- Soporte 24/7.
Precios
. Los planes de pago empiezan alrededor de 40 USD/mes. El precio por llamada arranca en ~0,001 USD y baja drásticamente con alto volumen; algunas comparativas citan tarifas tan bajas como 0,000058 USD en los niveles más altos.
Velocidad y fiabilidad
Las cifras de velocidad son realmente impresionantes. Si tu flujo de trabajo es sensible a la latencia y haces extracción de SERP de Google con esquema fijo y gran volumen, Scrapingdog es difícil de superar en tiempo bruto de respuesta.
Ideal para
Herramientas SEO de gran volumen y trackers de rankings que necesitan baja latencia y bajo coste. Equipos que construyen sistemas de producción donde cada milisegundo del tiempo de respuesta de la API importa.
5. DataForSEO
no es solo una SERP API: es toda una suite de APIs diseñada para empresas que construyen productos SEO. Cubre SERP, palabras clave, backlinks, datos de negocio, Google Ads, Trends y más.
Funciones clave
- Análisis de funciones de SERP extremadamente completo: orgánicos, pagados, paquete local, knowledge graph, PAA, fragmentos destacados, shopping, imágenes, vídeos, noticias destacadas y más.
- Dos modos: Live (sincrónico) para paneles en tiempo real y Standard (asíncrono) para flujos por lotes en los que encolas tareas y recuperas resultados más tarde.
- Multi-motor: Google, Bing, Yahoo, Baidu, Naver, Seznam y otros.
Precios
Modelo de pago por uso, pero el coste varía según endpoint, motor, dispositivo, prioridad y modo. El precio de SERP suele oscilar entre ~0,0006 USD y 0,002 USD por tarea para Google orgánico, según el modo estándar frente a live y los ajustes de prioridad. La documentación es densa: prepárate para dedicar tiempo a la calculadora de precios. .
Velocidad y fiabilidad
El modo asíncrono estándar puede ser más lento (~10 segundos) porque las tareas se encolan. Los modos live y de alta velocidad cuestan más, pero son adecuados para paneles en tiempo real. Largo historial, estabilidad probada y soporte enterprise disponible.
Ideal para
Empresas SaaS que construyen plataformas SEO, paneles de seguimiento de rankings y herramientas de investigación de palabras clave. Equipos cómodos con documentación compleja e infraestructura de nivel enterprise.
6. Bright Data
es el gigante enterprise. Su SERP API es solo uno de muchos productos: proxies, datasets, Web Unlocker y herramientas de scraping. Su propuesta de valor es escala, fiabilidad e infraestructura.
Funciones clave
- Endpoints dedicados para Google Maps, Shopping y búsqueda general, además de soporte multi-motor mediante infraestructura de proxies que cubre Bing, Yahoo, Yandex y DuckDuckGo.
- Afirma una tasa de éxito del 100 % con tecnología de desbloqueo integrada.
- Donde Bright Data realmente destaca: geolocalización, concurrencia y desbloqueo a escala enterprise.
Precios
Orientado a enterprise. Los precios públicos muestran opciones de pago por uso y suscripción, y muchas comparativas citan compromisos iniciales de alrededor de 499 USD/mes. El coste por llamada empieza en ~0,005 USD, pero baja con el volumen. . Créditos de prueba disponibles (valor de 5 USD).
Velocidad y fiabilidad
Los benchmarks suelen mostrar entre 2 y 5,58 segundos. El motivo para comprar Bright Data no es la latencia mediana bruta, sino el SLA enterprise, el soporte dedicado y una infraestructura capaz de manejar millones de solicitudes concurrentes sin degradación. La recomienda aumentar gradualmente.
Ideal para
Equipos enterprise que recopilan millones de SERP al mes. Organizaciones que necesitan datos de Google Maps o negocios locales a escala. Equipos que ya usan los productos proxy de Bright Data.
7. ScraperAPI
es una API generalista de web scraping que también ofrece endpoints estructurados de Google SERP. Es la opción "una herramienta para todo": fácil de integrar, con un pool de proxies de más de 40 millones de IP.
Funciones clave
- Endpoints de datos estructurados para Google Search, Shopping, News y Jobs.
- Antibloqueo y resolución de CAPTCHA basados en machine learning, con renderizado JavaScript incluido sin coste adicional.
- Soporte de geotargeting para resultados localizados.
Precios
Prueba gratuita de 7 días con 5.000 créditos. Los planes de pago empiezan en ~49 USD/mes. La pega: las llamadas a SERP pueden consumir créditos distintos a las solicitudes de scraping normales, así que normaliza siempre por consultas SERP exitosas reales entregadas. .
Velocidad y fiabilidad
Aquí va la parte honesta: el benchmark de HasData informa de ~33,66 segundos de media para consultas SERP. Es bastante más lento que las SERP API dedicadas. Alta tasa de éxito (99,9 %), pero la latencia lo hace menos adecuado para aplicaciones en tiempo real. Mejor para procesamiento por lotes.
Ideal para
Equipos que necesitan una solución general de web scraping con SERP como complemento. Proyectos en los que la velocidad importa menos que la fiabilidad y la facilidad de configuración. Desarrolladores que ya usan ScraperAPI para otras tareas de scraping y quieren consolidar proveedores.
8. Apify
no es una SERP API pura. Es una plataforma de scraping y automatización construida en torno a "Actors", scripts reutilizables para tareas como scraping de Google Search, extracción de Maps y automatización de flujos de trabajo. Piensa en ello como un marketplace donde eliges —o construyes— el scraper que encaja exactamente con lo que necesitas.
Funciones clave
- Marketplace de preconstruidos con distinta cobertura de funciones.
- Muy personalizable: crea flujos de scraping a medida, encadena actors y programa ejecuciones.
- Devuelve JSON; flexibilidad para analizar funciones específicas de la SERP mediante la configuración del actor.
- Muy útil para combinar extracción de SERP con otras tareas de scraping y automatización.
Precios
Plan gratuito con créditos mensuales de la plataforma (valor aproximado de 5 USD, unas 1.400 resultados). Los planes de pago empiezan en ~49 USD/mes. El coste a nivel de actor varía: algunos cobran por resultado, otros por unidad de cómputo. Las comparativas de terceros suelen situar Apify en torno a 0,003 USD por búsqueda a pequeña escala. .
Velocidad y fiabilidad
HasData informa de ~8,2 segundos de media. La arquitectura basada en actors añade sobrecarga frente a endpoints SERP dedicados. Mejor para flujos programados o por lotes que para consultas en tiempo real.
Ideal para
Equipos que necesitan flujos personalizados de scraping + automatización más allá de los datos SERP. Proyectos que combinan extracción de SERP con otras tareas de web scraping. Desarrolladores que quieren la máxima flexibilidad frente a endpoints preconstruidos.
Matriz de análisis de funciones SERP: lo que realmente devuelve cada API
Esta es la comparativa que no pude encontrar en ningún otro sitio. Todos los proveedores dicen ofrecer "JSON estructurado", pero los elementos de la SERP que analizan como campos de primera clase varían muchísimo. Revisé la documentación y las respuestas de ejemplo de cada uno.
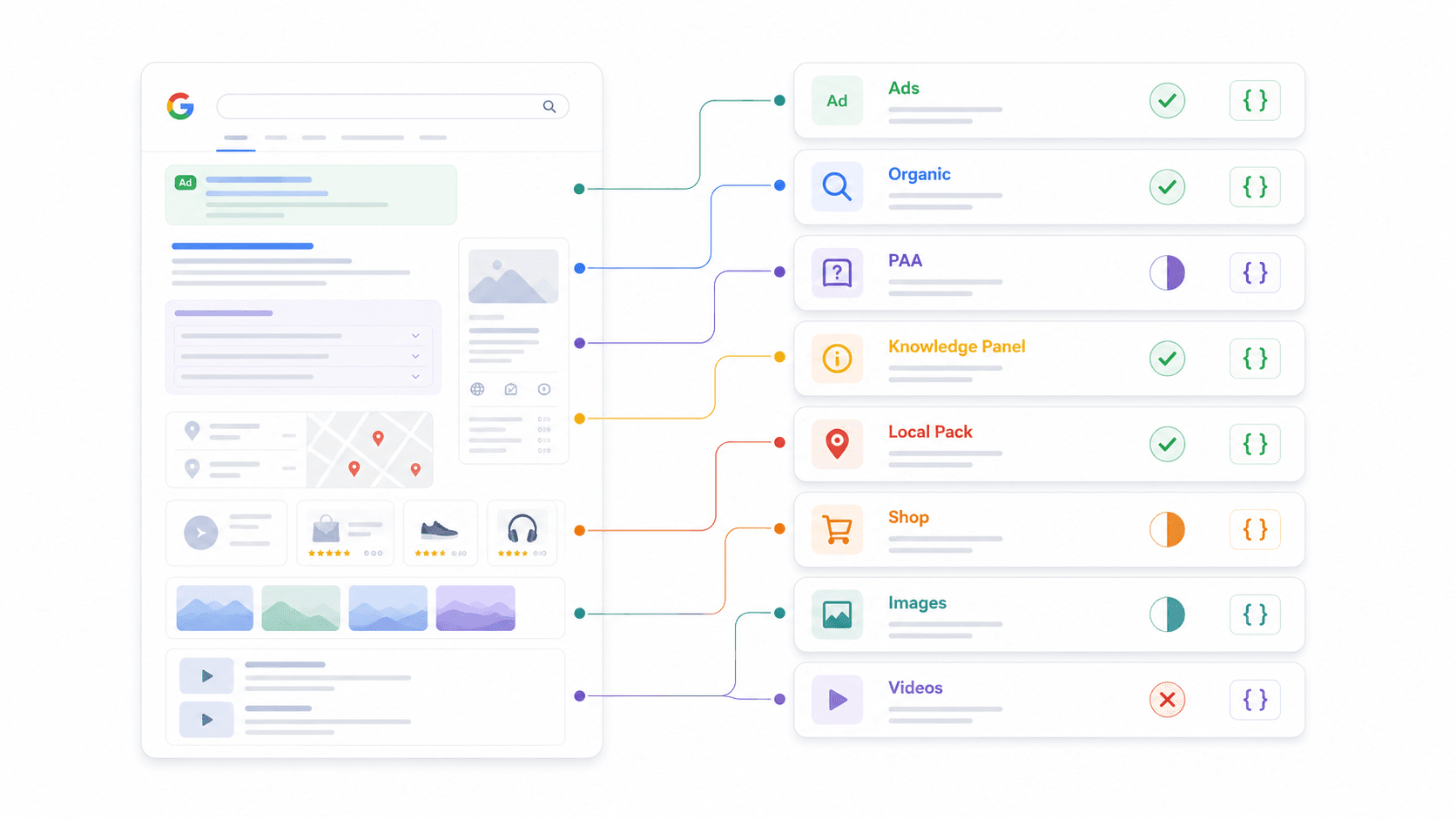
| Función de SERP | Thunderbit | SerpApi | Serper | Scrapingdog | DataForSEO | Bright Data | ScraperAPI | Apify |
|---|---|---|---|---|---|---|---|---|
| Resultados orgánicos | Esquema personalizado | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ | Depende del actor |
| People Also Ask | Esquema personalizado | ✅ | ✅ | ✅ | ✅ | Parcial | Parcial | Depende del actor |
| Panel de conocimiento | Esquema personalizado | ✅ | Parcial | Parcial | ✅ | Parcial | Parcial | Depende del actor |
| Paquete local / Maps | Esquema personalizado | ✅ | ✅ | Parcial | ✅ | ✅ | Parcial | Depende del actor |
| Resultados de shopping | Esquema personalizado | ✅ | ✅ | Parcial | ✅ | ✅ | ✅ | Depende del actor |
| Fragmentos destacados | Esquema personalizado | ✅ | Parcial | ✅ | ✅ | Parcial | Parcial | Depende del actor |
| Anuncios (arriba/abajo) | Esquema personalizado | ✅ | Parcial | ✅ | ✅ | Parcial | Parcial | Depende del actor |
| Paquete de imágenes | Esquema personalizado | ✅ | ✅ | ✅ | ✅ | Parcial | Parcial | Depende del actor |
| Resultados de vídeo | Esquema personalizado | ✅ | ✅ | Parcial | ✅ | Parcial | Parcial | Depende del actor |
Qué significa "Esquema personalizado" en Thunderbit: En lugar de predefinir qué funciones de la SERP analiza, defines tu propio JSON Schema para extraer exactamente los campos que necesitas. ¿Quieres preguntas de PAA más resúmenes de respuesta más señales de intención comercial? Define ese esquema y la IA te lo entrega. Esta flexibilidad es la razón por la que Thunderbit funciona en cualquier motor de búsqueda, no solo en Google.
Por qué esto importa para tu flujo de trabajo: Si necesitas datos de PAA para estrategia de contenidos, verifica que tu proveedor realmente los analice. Si haces seguimiento de anuncios de shopping para ecommerce, confirma que existan campos estructurados de shopping. No asumas que "JSON estructurado" significa cobertura completa.
Coste real a escala: comparación de precio por consulta
Los precios publicados en las webs no cuentan toda la historia. Lo normalicé todo a coste por cada 1.000 consultas exitosas en tres niveles de volumen.
| Proveedor | Coste por 1.000 consultas | Coste por 10.000 consultas | Coste por 100.000 consultas | ¿Pago por uso? | Plan gratuito |
|---|---|---|---|---|---|
| Thunderbit (Distill) | ~0,80–3,20 USD | ~8–32 USD | ~80–320 USD | Paquete de créditos | Créditos gratis |
| Thunderbit (Extract) | ~16–64 USD | ~160–640 USD | ~1.600–6.400 USD | Paquete de créditos | Créditos gratis |
| SerpApi | 25 USD (Starter) | ~87 USD (Popular) | ~550 USD (Big Data) | No (suscripción) | 250/mes |
| Serper | ~1 USD | ~10 USD | ~75–100 USD | Sí | 2.500 consultas |
| Scrapingdog | ~1 USD | ~10 USD o menos | Puede caer muy por debajo de 10 USD | Plan/créditos | 1.000 créditos |
| DataForSEO | ~0,60–2 USD | ~6–20 USD | ~60–200 USD | Sí | Créditos de prueba |
| Bright Data | ~0,50–5+ USD | Depende de la oferta | Mejor a volumen enterprise | Sí/plan | Créditos de prueba (5 USD) |
| ScraperAPI | Depende de créditos | Depende de créditos | Depende de créditos | Plan/créditos | 5.000 créditos de prueba |
| Apify | ~3 USD (pequeña escala) | Depende del actor | Depende del actor | Créditos de la plataforma | Créditos mensuales gratis |
Costes ocultos a vigilar:
- El posible cobro de 2 créditos de Serper por más de 10 resultados por consulta.
- Las diferencias de precio de DataForSEO entre los modos estándar y live/de alta prioridad.
- Los multiplicadores de créditos de ScraperAPI para SERP frente a scraping normal.
- Los compromisos mínimos empresariales de Bright Data.
Valor en cada nivel:
- Proyectos secundarios (50 USD/mes): Serper o Scrapingdog para JSON fijo de SERP de Google.
- Equipos en crecimiento (10.000–50.000 consultas/mes): Serper, Scrapingdog o DataForSEO según la profundidad del análisis.
- Enterprise (100.000+ consultas/mes): DataForSEO, Bright Data o SerpApi Big Data.
- Extracción AI-first: Thunderbit, porque el esquema encaja con las expectativas del agente downstream sin posprocesado.
La mejor SERP API para agentes de IA y flujos LLM en 2026
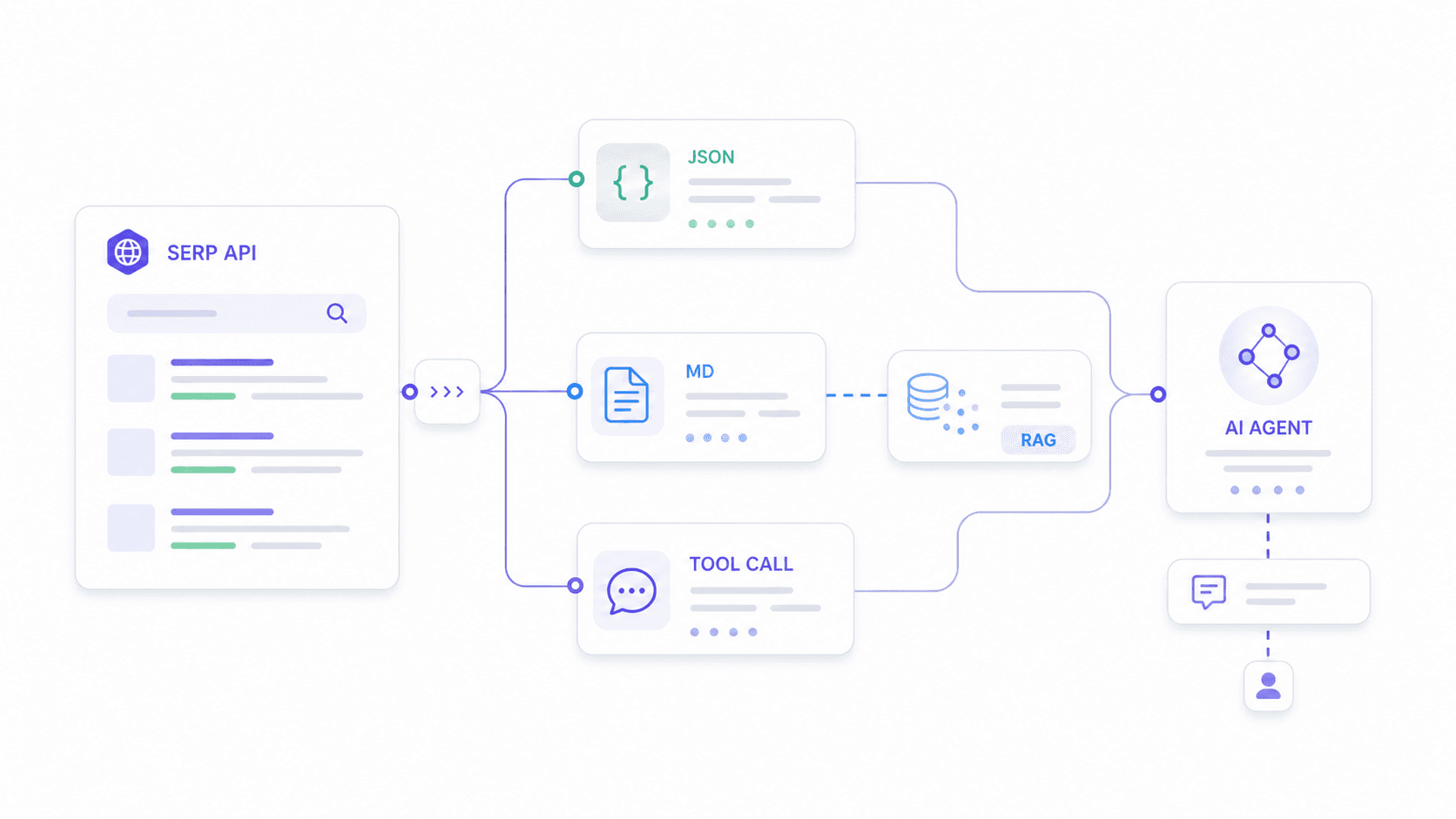
Este es el caso de uso que nadie más cubre bien. Encontré al menos tres en los que usuarios describen intentar integrar SERP APIs con flujos de n8n y agentes de IA, y uno afirmaba explícitamente que "no ha conseguido hacerlo funcionar correctamente con un agente de IA".
Los agentes de IA necesitan cosas distintas a los paneles de seguimiento de rankings. Necesitan:
- JSON con esquema estable que no rompa su lógica de análisis cuando un proveedor actualiza el formato de salida.
- Campos de salida personalizados que coincidan con lo que espera el modelo downstream, no un volcado genérico de todo.
- Markdown o texto limpios para pipelines de embeddings RAG.
- Latencia lo bastante baja para llamadas a herramientas en tiempo real.
Cómo encaja cada proveedor en una pila de agentes de IA
| Proveedor | Encaje con agentes de IA | Por qué |
|---|---|---|
| Thunderbit | Excelente | JSON Schema personalizado (Extract API) + Markdown para RAG (Distill API). El más flexible para extracción específica de agentes. |
| Serper | Muy bueno | JSON rápido y limpio, popular en comunidades n8n/LangChain. Sencillo y barato para llamadas básicas a herramientas de búsqueda. |
| SerpApi | Bueno | Esquema estable, documentación excelente. Funciona muy bien cuando los agentes necesitan verticales de Google (Maps, Scholar, Shopping). |
| DataForSEO | Bueno | Mejor cuando el agente forma parte de una pipeline SEO más grande. |
| Scrapingdog | Bueno | Rápido y barato; el esquema es estable para SERP de Google. |
| Bright Data | Bueno | Recopilación de datos frescos a escala enterprise en distintos motores y regiones. |
| ScraperAPI | Moderado | Mejor cuando el agente también necesita rastreo web general. |
| Apify | Moderado a bueno | Flexible pero más lento; mejor para flujos programados por lotes. |
Ejemplo práctico con Thunderbit: Imagina que tu agente de IA necesita analizar la intención de búsqueda para "mejor CRM para inmobiliarias". Defines un esquema que solicita resultados orgánicos (título, URL, fragmento, posición), preguntas de People Also Ask con resúmenes de respuesta y una clasificación de intención comercial. La Extract API de Thunderbit devuelve exactamente esa estructura: ni más ni menos. Tu agente no desperdicia tokens analizando campos irrelevantes ni limpiando artefactos HTML.
Para pipelines RAG, la Distill API de Thunderbit convierte la página de SERP en Markdown limpio, listo para embeddings. La mayoría de las SERP API dedicadas devuelven esquemas JSON fijos; el enfoque de Thunderbit permite a los desarrolladores adaptar la salida a lo que espere su modelo downstream.
Matriz de decisión por caso de uso: si necesitas X, usa Y
Los usuarios de foros siguen pidiendo recomendaciones concretas mapeadas a sus flujos de trabajo reales, no consejos genéricos de "depende". Así que monté esto.
| Tu caso de uso | Mejor opción | Segunda opción | Por qué |
|---|---|---|---|
| Seguimiento de rankings SEO (gran volumen) | DataForSEO | Scrapingdog | Endpoints nativos de SEO, precios por volumen, análisis completo |
| Google Maps / datos de negocios locales | SerpApi | Bright Data | Endpoint de Maps maduro; Bright Data encaja con scraping local a escala enterprise |
| Automatización con agentes de IA / n8n | Thunderbit | Serper | Esquema personalizado + Markdown para RAG; Serper es rápido y barato para llamadas simples |
| MVP con presupuesto limitado / proyecto secundario (<50 USD/mes) | Serper | Scrapingdog | Planes gratuitos generosos, pago por uso, configuración mínima |
| Multi-motor (Bing, Yandex, DuckDuckGo) | Thunderbit | DataForSEO | Thunderbit funciona en cualquier motor de búsqueda mediante extracción con IA; DataForSEO tiene endpoints multi-motor |
| Agregación de reseñas de Google | SerpApi | DataForSEO | Endpoints dedicados para análisis de reseñas |
| Ecommerce / monitorización de shopping | SerpApi | DataForSEO | Gran cobertura de Google Shopping y campos estructurados |
| Flujos de scraping personalizados | Apify | ScraperAPI | Flexibilidad de actors; ScraperAPI es fácil para scraping general + SERP |
Guía rápida por perfil:
- Equipo de SEO: empieza con DataForSEO si vas a construir paneles; usa SerpApi si la cobertura de verticales de Google y la documentación importan más que el precio.
- Equipo de ventas: usa Thunderbit cuando el flujo abarque SERP, páginas de directorios y enriquecimiento; usa Serper para consultas simples de descubrimiento de leads.
- Desarrollador de herramientas de IA: Thunderbit para esquemas personalizados/RAG, Serper para búsqueda rápida y barata, SerpApi para verticales de Google robustas.
- Emprendedor en solitario: empieza con los planes gratuitos de Serper, Scrapingdog, SerpApi y Thunderbit. Ejecuta las mismas 20 consultas parecidas a producción antes de comprometerte.
Comparativa de límites de tasa, fiabilidad y preparación para producción
Ojalá esta sección hubiera existido cuando evalué por primera vez proveedores para flujos de producción. Los equipos que escalan a miles de consultas al día necesitan límites de tasa previsibles, reintentos automáticos y garantías de disponibilidad, y ningún otro artículo comparativo los cubre de forma sistemática.
| Proveedor | Límite de tasa | Solicitudes concurrentes | Reintento ante fallo | SLA / disponibilidad |
|---|---|---|---|---|
| Thunderbit Free | 10 req/min | 2 | Integrado (anti-bot, CAPTCHA) | — |
| Thunderbit Pro | 100 req/min | 10 | Integrado | — |
| Thunderbit Enterprise | 1.000 req/min | 50 | Integrado | Términos personalizados |
| SerpApi | Según plan (búsquedas/hora) | Según plan | El proveedor gestiona proxies/CAPTCHA | SLA del 99,95 % |
| Serper | Según cuenta/plan | No publicado ampliamente | Se recomienda reintento manual en el cliente | Sin SLA público |
| Scrapingdog | Según plan | Consulta los términos del plan | El antibloqueo está gestionado | No siempre público |
| DataForSEO | Documentado por endpoint/modo | Varía según el modo | El modo asíncrono admite polling/reintento | Soporte enterprise |
| Bright Data | Documentado, aumenta gradualmente | Escala enterprise | Desbloqueo integrado | SLA enterprise |
| ScraperAPI | Concurrencia según plan | Depende de créditos | Gestiona reintentos/proxies | Opciones de soporte de pago |
| Apify | Depende de actor/memoria/cómputo | Límites de la plataforma | Configuración a nivel de actor | Fiabilidad de la plataforma |
Lista de comprobación para producción antes de comprometerte:
- Pregunta si el proveedor cobra por solicitudes fallidas o bloqueadas.
- Confirma la concurrencia exacta, las solicitudes por minuto y el comportamiento ante ráfagas.
- Comprueba si la geolocalización, móvil frente a escritorio y el renderizado JS cambian el consumo de créditos.
- Guarda respuestas JSON de ejemplo de 20–50 consultas reales y compara los nombres de campos entre días para verificar la estabilidad del esquema.
- Añade reintentos del lado del cliente y presupuestos de timeout si los datos SERP son críticos para la misión.
Resumen rápido: comparación de las 8 SERP API
| Proveedor | Velocidad media | Coste por 1.000 | Plan gratuito | Cobertura de análisis | Compatibilidad con IA | Multi-motor | Veredicto |
|---|---|---|---|---|---|---|---|
| Thunderbit | Media (extracción con IA) | Baja (Distill) a premium (Extract) | Sí | Personalizada (cualquier función) | Excelente | Excelente | La mejor para extracción SERP personalizada nativa de IA y RAG |
| SerpApi | ~5,5 s | Premium | 250/mes | Excelente (fija) | Bueno | Amplias verticales de Google | La mejor cobertura madura de Google |
| Serper | ~2–3 s | Muy baja | 2.500 consultas | Buena | Muy buena | Principalmente Google | La mejor API rápida y barata para IA/MVP |
| Scrapingdog | ~1,25 s | Muy baja a escala | 1.000 créditos | Buena | Buena | Verificar motores | La mejor combinación velocidad/coste |
| DataForSEO | Media-lenta (estándar) | Baja-moderada | Créditos de prueba | Excelente | Bueno | Excelente | La mejor infraestructura para plataforma SEO |
| Bright Data | ~2–5,5 s | Enterprise | Prueba (5 USD) | Buena (depende del producto) | Buena | Excelente | La mejor recopilación a escala enterprise |
| ScraperAPI | ~33 s | Depende de créditos | 5.000 de prueba | Moderada | Moderada | Endpoints de Google | La mejor si SERP es solo una parte del scraping más amplio |
| Apify | ~8 s | Depende del actor | Créditos mensuales | Depende del actor | Moderada–buena | Depende del actor | La mejor para flujos de automatización personalizados |
Cómo encaja Thunderbit en tu flujo de trabajo SERP
Un poco más de contexto sobre por qué nuestro equipo construyó la API de Thunderbit de la forma en que lo hicimos. El modelo tradicional de SERP API —endpoints fijos, campos de salida predeterminados, solo Google— funciona bien para un seguimiento de rankings sencillo. Pero en cuanto necesitas algo un poco distinto (respuestas de PAA con sentimiento, resultados de paquete local con número de reseñas o datos de shopping formateados para un esquema de base de datos concreto), te quedas atascado en el posprocesado o cambiando de proveedor.
La Extract API de Thunderbit invierte ese modelo. Tú le dices qué quieres mediante un JSON Schema, y la IA averigua cómo obtenerlo desde la página de búsqueda que le indiques. Google hoy, Bing mañana, un motor de búsqueda vertical de nicho la semana que viene: misma API, mismo enfoque.
La Distill API resuelve otro problema: transformar páginas SERP desordenadas en Markdown limpio que los LLM puedan consumir de verdad sin ahogarse con artefactos HTML, elementos de navegación y scripts de seguimiento. Si estás construyendo un pipeline RAG que necesita evidencia de búsqueda fresca, este es el camino más rápido de "SERP en vivo" a "contenido embebible".
Ambos endpoints incluyen gestión anti-bot, resolución de CAPTCHA y renderizado JS de serie. No pagas extra por eso: está incluido en el coste de créditos.
Pruébalo tú mismo: para extracción desde el navegador, o usa la API directamente para flujos programáticos. Nuestro tiene tutoriales si quieres verlo en acción antes de escribir código.
Una nota sobre la legalidad
Esto aparece en todas las FAQ, así que aquí va la versión corta: la legalidad del scraping de SERP depende de los hechos y de la jurisdicción. El caso estableció que extraer datos públicamente accesibles no es necesariamente un delito informático, pero no concede permiso general. Google por el scraping de SERP, lo que indica una presión comercial activa en torno al acceso.
Consejo práctico: usa las APIs de los proveedores según sus términos, evita recopilar datos personales salvo que sea necesario y pregunta a los proveedores cómo gestionan el cumplimiento. No asumas que el scraping de SERP está libre de riesgo.
Conclusión
No hay un solo proveedor que gane en todas las dimensiones: la elección correcta depende de tu caso de uso, presupuesto y stack técnico. Tras normalizar precios, probar la velocidad, mapear la cobertura de análisis y evaluar la preparación para agentes de IA, este es mi marco de decisión:
- ¿Necesitas flexibilidad + preparación para agentes de IA? → Thunderbit
- ¿Necesitas amplia cobertura de productos de Google? → SerpApi
- ¿Necesitas velocidad + el coste más bajo? → Serper o Scrapingdog
- ¿Vas a construir una plataforma SEO? → DataForSEO
- ¿Escala enterprise con SLA? → Bright Data o DataForSEO
- ¿Scraping general + SERP ocasional? → ScraperAPI o Apify
Empieza por los planes gratuitos. Ejecuta de 20 a 50 consultas reales que coincidan con tu carga de trabajo de producción. Compara las respuestas JSON. Revisa el coste real después de créditos y multiplicadores. Y luego comprométete.
Los precios cambian a menudo en este mercado: esta comparativa se normalizó a partir de las páginas públicas actuales en mayo de 2026. Si la lees meses después, vuelve a comprobar antes de comprar.
Para más información sobre enfoques de y cómo se comparan con los métodos tradicionales, hemos escrito mucho sobre el tema. Y si estás evaluando , la extensión de Chrome de Thunderbit también cubre esa parte.
Preguntas frecuentes
1. ¿Qué es una SERP API y quién necesita una?
Una SERP API es un servicio que envía consultas de búsqueda a motores como Google, Bing o Yandex y devuelve los resultados como datos estructurados, normalmente JSON. Los profesionales de SEO las usan para seguimiento de rankings, los equipos de ventas para descubrir leads, los equipos de ecommerce para monitorizar precios y los desarrolladores de IA para alimentar datos de búsqueda en vivo a agentes y pipelines RAG.
2. ¿Cuánto cuesta extraer 1.000 resultados de búsqueda de Google vía API?
Varía bastante: desde ~0,60 USD por 1.000 (DataForSEO en el nivel estándar) hasta ~25 USD por 1.000 (plan Starter de SerpApi). Los descuentos por volumen cambian muchísimo entre proveedores. Normaliza siempre a coste por cada 1.000 consultas exitosas en lugar de comparar el precio de portada.
3. ¿Puedo usar una SERP API con agentes de IA como LangChain o n8n?
Sí. Serper es popular en la comunidad de n8n para llamadas sencillas de búsqueda. Thunderbit es especialmente fuerte cuando tu agente necesita JSON Schema personalizado o Markdown para RAG. SerpApi funciona muy bien para agentes que necesitan datos verticales estables de Google (Maps, Scholar, Shopping).
4. ¿Qué SERP API tiene el mejor plan gratuito para probar?
Serper ofrece 2.500 consultas gratis al registrarte, lo más generoso en volumen puro. SerpApi da 250 al mes, Scrapingdog ofrece 1.000 créditos, ScraperAPI proporciona 5.000 créditos de prueba (7 días) y Thunderbit incluye créditos gratuitos para prototipado. Apify tiene créditos mensuales de plataforma por valor de unos 5 USD.
5. ¿Qué funciones SERP debería verificar que un proveedor analiza antes de comprar?
No des por hecho que "JSON estructurado" significa cobertura completa. Verifica si la API devuelve campos estructurados para: People Also Ask, Panel de conocimiento, Paquete local/Maps, resultados de Shopping, Fragmentos destacados, Anuncios (superiores e inferiores), Paquete de imágenes y Resultados de vídeo. Usa la matriz de análisis de este artículo como lista inicial y prueba con consultas reales antes de comprometerte con un plan.
Más información