
Αν έχεις προσπαθήσει ποτέ να τραβήξεις δεδομένα από έναν ιστότοπο που φορτώνει περιεχόμενο όσο κάνεις scroll, κρύβει τιμές πίσω από login ή φαίνεται να αλλάζει διάταξη κάθε λίγο και λιγάκι, ξέρεις πόσο δύσκολο είναι. Οι στατικοί scrapers απλώς δεν φτάνουν πια. Μάλιστα, πάνω από το βασίζονται πλέον στο web scraping για εναλλακτικά δεδομένα, ενώ το αυτοματοποιεί την παρακολούθηση τιμών ανταγωνιστών. Όμως εδώ είναι το ζουμί: μεγάλο μέρος αυτών των δεδομένων βρίσκεται σε δυναμικούς ιστότοπους, φορτώνεται με JavaScript και κρύβεται πίσω από αλληλεπιδράσεις του χρήστη. Εκεί μπαίνει ο αυτοματισμός headless browser — και εργαλεία όπως το Puppeteer.
Ως κάποιος που έχει περάσει χρόνια χτίζοντας εργαλεία αυτοματοποίησης και AI (και, ναι, κάνοντας το δίκαιο μερίδιό μου σε scraping ιστότοπων για ομάδες πωλήσεων και operations), έχω δει από πρώτο χέρι πώς το Puppeteer μπορεί να ξεκλειδώσει δεδομένα που οι παραδοσιακοί scrapers χάνουν. Έχω δει όμως και πώς το επιπλέον coding μπορεί να γίνει dealbreaker για επιχειρηματικούς χρήστες. Γι’ αυτό σε αυτόν τον οδηγό θα δεις ακριβώς τι είναι το Puppeteer scraper, πώς να το χρησιμοποιήσεις για web scraping και πότε ίσως αξίζει να στραφείς σε κάτι ακόμη πιο απλό — όπως το , το AI-powered, no-code web scraper μας.
Τι είναι το Puppeteer Scraper; Μια γρήγορη επισκόπηση
 Ας ξεκινήσουμε από τα βασικά. Το είναι μια open-source βιβλιοθήκη Node.js από την Google που σου επιτρέπει να ελέγχεις έναν headless Chrome ή Chromium browser με JavaScript. Με απλά λόγια: είναι σαν να έχεις ένα ρομπότ που μπορεί να ανοίγει ιστοσελίδες, να κάνει κλικ σε κουμπιά, να συμπληρώνει φόρμες, να κάνει scroll και — το σημαντικότερο — να εξάγει δεδομένα, όλα χωρίς να εμφανίζει τίποτα στην οθόνη σου.
Ας ξεκινήσουμε από τα βασικά. Το είναι μια open-source βιβλιοθήκη Node.js από την Google που σου επιτρέπει να ελέγχεις έναν headless Chrome ή Chromium browser με JavaScript. Με απλά λόγια: είναι σαν να έχεις ένα ρομπότ που μπορεί να ανοίγει ιστοσελίδες, να κάνει κλικ σε κουμπιά, να συμπληρώνει φόρμες, να κάνει scroll και — το σημαντικότερο — να εξάγει δεδομένα, όλα χωρίς να εμφανίζει τίποτα στην οθόνη σου.
Τι κάνει το Puppeteer ξεχωριστό;
- Μπορεί να αποδίδει δυναμικό περιεχόμενο — δηλαδή περιμένει να φορτώσει το JavaScript, όπως ακριβώς ένας πραγματικός χρήστης.
- Μπορεί να προσομοιώνει ενέργειες χρήστη: κλικ, πληκτρολόγηση, scroll και ακόμη και χειρισμό pop-ups.
- Είναι ιδανικό για scraping ιστότοπων όπου τα δεδομένα εμφανίζονται μόνο μετά από αλληλεπίδραση, όπως λίστες e-commerce, social feeds ή dashboards.
Πώς συγκρίνεται με άλλα εργαλεία;
- Selenium: Ο παλιός «κλασικός» του browser automation. Υποστηρίζει πολλούς browsers και γλώσσες, αλλά είναι πιο βαρύ και λίγο πιο παλιομοδίτικο. Εξαιρετικό για cross-browser testing, όμως το Puppeteer είναι πιο γρήγορο για έργα σε Chrome/Node.js.
- Thunderbit: Εδώ είναι που ενθουσιάζομαι. Το Thunderbit είναι ένα no-code, AI-powered web scraper που λειτουργεί μέσα στον browser σου. Αντί να γράφεις scripts, απλώς κάνεις κλικ στο “AI Suggest Fields” και αφήνεις την AI να καταλάβει τι πρέπει να εξαχθεί. Είναι ιδανικό για επιχειρηματικούς χρήστες που θέλουν αποτελέσματα χωρίς κώδικα (περισσότερα γι’ αυτό παρακάτω).
Με λίγα λόγια: Puppeteer = μέγιστος έλεγχος (αν γράφεις κώδικα). Thunderbit = μέγιστη ευκολία (αν δεν θέλεις να γράφεις κώδικα).
Γιατί το Puppeteer Web Scraping έχει σημασία για επιχειρηματικούς χρήστες
Ας το πούμε ξεκάθαρα: το web scraping δεν είναι πια μόνο για hackers ή data scientists. Ομάδες πωλήσεων, operations, marketing, ακόμη και real estate αξιοποιούν δεδομένα από το web για να αποκτήσουν πλεονέκτημα. Και με τόσες κρίσιμες επιχειρηματικές πληροφορίες κλειδωμένες πίσω από δυναμικούς ιστότοπους, το Puppeteer είναι συχνά το κλειδί για να τις ξεκλειδώσεις.
Ορίστε μερικές πραγματικές χρήσεις:
| Περίπτωση χρήσης | Ποιοι ωφελούνται | Επίδραση / ROI |
|---|---|---|
| Δημιουργία leads | Πωλήσεις, Biz Dev | Αυτοματοποιεί τη δημιουργία λιστών υποψήφιων πελατών· εξοικονομεί 8+ ώρες/εβδομάδα ανά εκπρόσωπο (case study) |
| Παρακολούθηση τιμών | E-commerce, Product Ops | Παρακολούθηση ανταγωνιστών σε πραγματικό χρόνο· μία επιχείρηση εξοικονόμησε 3,8 εκατ. δολάρια/έτος (source) |
| Έρευνα αγοράς | Marketing, Strategy, Finance | Το 67% των επενδυτικών συμβούλων χρησιμοποιεί δεδομένα από web scraping· σε ορισμένες περιπτώσεις ROI έως 890% (source) |
| Συγκέντρωση real estate | Μεσίτες, αναλυτές | Scrape 50+ σελίδες ακινήτων σε λίγα λεπτά, όχι σε ώρες (source) |
| Παρακολούθηση συμμόρφωσης | Operations, Νομικό | Αυτοματοποιεί την παρακολούθηση· μία ασφαλιστική απέφυγε πρόστιμα 50 εκατ. δολαρίων (source) |
Και ας μην ξεχνάμε: πάνω από το ξοδεύει το ένα τέταρτο της εβδομάδας του σε επαναλαμβανόμενες εργασίες όπως η συλλογή δεδομένων. Η αυτοματοποίηση αυτού μέσω web scraping δεν είναι απλώς ευχάριστη — είναι ανταγωνιστικό πλεονέκτημα.
Ξεκινώντας: Ρύθμιση του Puppeteer Scraper σου
Έτοιμος/η να σηκώσεις μανίκια; Δες πώς να βάλεις μπρος το Puppeteer σε κάτω από 10 λεπτά, αν νιώθεις άνετα με λίγο JavaScript:
1. Εγκατέστησε το Node.js
Το Puppeteer τρέχει πάνω στο Node.js. Κατέβασε την τελευταία έκδοση LTS από το .
2. Δημιούργησε έναν νέο φάκελο έργου
Άνοιξε το terminal και εκτέλεσε:
1mkdir puppeteer-scraper-demo
2cd puppeteer-scraper-demo
3npm init -y3. Εγκατέστησε το Puppeteer
1npm install puppeteerΑυτό θα κατεβάσει επίσης μια συμβατή έκδοση του Chromium (περίπου 100MB).
4. Δημιούργησε το πρώτο σου script
Φτιάξε ένα αρχείο με όνομα scrape.js:
1const puppeteer = require('puppeteer');
2(async () => {
3 const browser = await puppeteer.launch();
4 const page = await browser.newPage();
5 await page.goto('https://example.com', { waitUntil: 'domcontentloaded' });
6 const title = await page.title();
7 console.log('Page title:', title);
8 await browser.close();
9})();Τρέξ’ το με:
1node scrape.jsΑν δεις “Page title: Example Domain”, συγχαρητήρια — μόλις αυτοματοποίησες το Chrome!
Δημιουργώντας το πρώτο σου Puppeteer Web Scraping Script
Ας το κάνουμε πρακτικό. Υποθέτουμε ότι θέλεις να κάνεις scrape αποσπάσματα από το (έναν demo ιστότοπο για scrapers).
Βήμα 1: Πήγαινε στη σελίδα
1await page.goto('http://quotes.toscrape.com', { waitUntil: 'networkidle0' });Βήμα 2: Εξαγωγή δεδομένων
1const quotes = await page.evaluate(() => {
2 return Array.from(document.querySelectorAll('.quote')).map(node => ({
3 text: node.querySelector('.text')?.innerText.trim(),
4 author: node.querySelector('.author')?.innerText.trim(),
5 tags: Array.from(node.querySelectorAll('.tag')).map(tag => tag.innerText.trim())
6 }));
7});
8console.log(quotes);Βήμα 3: Διαχείριση σελιδοποίησης
1let hasNext = true;
2let allQuotes = [];
3while (hasNext) {
4 // Εξαγωγή αποσπασμάτων όπως παραπάνω
5 const quotes = await page.evaluate(/* ... */);
6 allQuotes.push(...quotes);
7 const nextButton = await page.$('li.next > a');
8 if (nextButton) {
9 await Promise.all([
10 page.click('li.next > a'),
11 page.waitForNavigation({ waitUntil: 'networkidle0' })
12 ]);
13 } else {
14 hasNext = false;
15 }
16}Βήμα 4: Αποθήκευση σε JSON
1const fs = require('fs');
2fs.writeFileSync('quotes.json', JSON.stringify(allQuotes, null, 2));Και να το — ένα βασικό Puppeteer scraper που πλοηγείται, εξάγει, κάνει σελιδοποίηση και αποθηκεύει δεδομένα.
Προηγμένες τεχνικές Puppeteer Scraper: Χειρισμός δυναμικού περιεχομένου
Οι περισσότεροι πραγματικοί ιστότοποι δεν είναι τόσο απλοί όσο μια στατική λίστα. Δες πώς να αντιμετωπίσεις τα δύσκολα:
1. Αναμονή για δυναμικά στοιχεία
1await page.waitForSelector('.product-list-item');Αυτό διασφαλίζει ότι το περιεχόμενο που θέλεις έχει φορτώσει πριν προσπαθήσεις να το τραβήξεις.
2. Προσομοίωση ενεργειών χρήστη
- Κάνε κλικ σε κουμπί:
await page.click('#load-more'); - Πληκτρολόγησε σε πεδίο:
await page.type('#search', 'laptop'); - Κάνε scroll για infinite scroll:
1let previousHeight = await page.evaluate('document.body.scrollHeight'); 2while (true) { 3 await page.evaluate('window.scrollTo(0, document.body.scrollHeight)'); 4 await page.waitForTimeout(1500); 5 const newHeight = await page.evaluate('document.body.scrollHeight'); 6 if (newHeight === previousHeight) break; 7 previousHeight = newHeight; 8}
3. Χειρισμός logins
1await page.goto('https://exampleshop.com/login');
2await page.type('#login-username', 'myusername');
3await page.type('#login-password', 'mypassword');
4await page.click('#login-button');
5await page.waitForNavigation({ waitUntil: 'networkidle0' });4. Διαχείριση δεδομένων που φορτώνονται μέσω AJAX Μερικές φορές τα δεδομένα δεν βρίσκονται στο DOM αλλά έρχονται από κλήση API. Μπορείς να παγιδεύσεις network responses με:
1page.on('response', async response => {
2 if (response.url().includes('/api/products')) {
3 const data = await response.json();
4 // Επεξεργασία δεδομένων
5 }
6});Πραγματικό παράδειγμα: Scraping δεδομένων προϊόντων από e-commerce site
Ας τα συνδυάσουμε όλα. Φαντάσου ότι θέλεις να κάνεις scrape ονόματα προϊόντων, τιμές και εικόνες από έναν (demo) ιστότοπο e-commerce αφού συνδεθείς.
1const puppeteer = require('puppeteer');
2const fs = require('fs');
3(async () => {
4 const browser = await puppeteer.launch({ headless: true });
5 const page = await browser.newPage();
6 // Βήμα 1: Σύνδεση
7 await page.goto('https://exampleshop.com/login');
8 await page.type('#login-username', 'myusername');
9 await page.type('#login-password', 'mypassword');
10 await page.click('#login-button');
11 await page.waitForNavigation({ waitUntil: 'networkidle0' });
12 // Βήμα 2: Μετάβαση στη σελίδα κατηγορίας
13 await page.goto('https://exampleshop.com/category/laptops', { waitUntil: 'networkidle0' });
14 // Βήμα 3: Εξαγωγή προϊόντων
15 const products = await page.evaluate(() => {
16 return Array.from(document.querySelectorAll('.product-item')).map(item => ({
17 name: item.querySelector('.product-title')?.innerText.trim() || '',
18 price: item.querySelector('.product-price')?.innerText.trim() || '',
19 image: item.querySelector('img.product-image')?.src || ''
20 }));
21 });
22 // Βήμα 4: Αποθήκευση σε JSON
23 fs.writeFileSync('products.json', JSON.stringify(products, null, 2));
24 await browser.close();
25})();Αυτό το script κάνει login, πλοηγείται, κάνει scrape και αποθηκεύει — όλα αυτόματα. Για πιο προχωρημένες ανάγκες, μπορείς να προσθέσεις loops για σελιδοποίηση ή ακόμη και να μπαίνεις σε κάθε προϊόν για περισσότερες λεπτομέρειες.
Thunderbit: Κάνοντας το Puppeteer Scraper απλούστερο με AI
Τώρα, αν έφτασες μέχρι εδώ και σκέφτεσαι: «Αυτό είναι ωραίο, αλλά δεν θέλω να γράφω κώδικα κάθε φορά που χρειάζομαι ένα νέο dataset», δεν είσαι μόνος/η. Ακριβώς γι’ αυτό δημιουργήσαμε το .
Τι κάνει το Thunderbit διαφορετικό;
- Δεν απαιτείται κώδικας: Απλώς εγκατέστησε το , άνοιξε τη σελίδα που θέλεις να κάνεις scrape και πάτησε “AI Suggest Fields”.
- Ανίχνευση πεδίων με AI: Το Thunderbit διαβάζει τη σελίδα και προτείνει τις καλύτερες στήλες για εξαγωγή — όπως “Product Name”, “Price”, “Image” κ.λπ.
- Χειρίζεται δυναμικό περιεχόμενο: Infinite scroll, pop-ups και υποσελίδες; Η AI του Thunderbit τα διαχειρίζεται, κάνοντας κλικ στη σελιδοποίηση ή ακόμα και επισκεπτόμενη τη σελίδα λεπτομερειών κάθε προϊόντος για να εμπλουτίσει τα δεδομένα σου.
- Άμεση εξαγωγή: Στείλε τα δεδομένα σου κατευθείαν σε Excel, Google Sheets, Notion ή Airtable με ένα κλικ. Χωρίς επιπλέον χρέωση για εξαγωγές.
- Πρότυπα για δημοφιλείς ιστότοπους: Θέλεις να κάνεις scrape Amazon, Zillow ή LinkedIn; Το Thunderbit έχει έτοιμα πρότυπα — χωρίς καμία ρύθμιση.
- Scraping στο cloud ή στον browser: Για μεγάλα tasks, το Thunderbit μπορεί να κάνει scrape έως και 50 σελίδες ταυτόχρονα στο cloud.
Έχω δει χρήστες να περνούν από το «Μακάρι να μπορούσα να πάρω αυτά τα δεδομένα» στο «Να το spreadsheet μου» μέσα σε λιγότερο από πέντε λεπτά. Και το καλύτερο; Δεν χρειάζεται πια να ανησυχείς ότι τα scripts θα σπάσουν όταν αλλάξει ο ιστότοπος — η AI του Thunderbit προσαρμόζεται επιτόπου.
Puppeteer vs. Thunderbit: Πώς να επιλέξεις το σωστό εργαλείο web scraping
Λοιπόν, ποιο να χρησιμοποιήσεις; Να πώς το βάζω κάτω για ομάδες:
| Παράγοντας | Puppeteer (Κώδικας) | Thunderbit (No-Code, AI) |
|---|---|---|
| Ευκολία χρήσης | Απαιτεί γνώση JavaScript και DOM | Point-and-click, η AI προτείνει πεδία |
| Ταχύτητα ρύθμισης | Από ώρες έως μέρες για σύνθετες εργασίες | Λεπτά — απλώς εγκατάσταση και ξεκίνα |
| Έλεγχος / ευελιξία | Μέγιστος: γράφεις όποια προσαρμοσμένη λογική θέλεις, το συνδέεις με άλλο κώδικα | Υψηλός για τυπικές περιπτώσεις· λιγότερο κατάλληλο για πολύ εξειδικευμένα workflows |
| Δυναμικό περιεχόμενο | Χειροκίνητα scripts για waits, clicks, scrolls | Η ενσωματωμένη AI χειρίζεται αυτόματα δυναμικό περιεχόμενο, σελιδοποίηση και υποσελίδες |
| Συντήρηση | Εσύ διαχειρίζεσαι τα scripts — τα ενημερώνεις όταν αλλάζουν οι ιστότοποι | Η AI προσαρμόζεται σε αλλαγές διάταξης· λιγότερη συντήρηση για τον χρήστη |
| Εξαγωγή δεδομένων | Γράφεις μόνος/η σου τη λογική εξαγωγής | Με ένα κλικ σε Excel, Sheets, Notion, Airtable, CSV, JSON |
| Ιδανικό για | Developers, ιδιαίτερα προσαρμοσμένα ή μεγάλης κλίμακας scrapes | Επιχειρηματικούς χρήστες, projects με γρήγορο turnaround, μη τεχνικές ομάδες |
| Κόστος | Δωρεάν (εκτός από τον χρόνο σου και τυχόν υποδομή) | Διαθέσιμο δωρεάν επίπεδο· επί πληρωμή πλάνα με credits (δες Thunderbit Pricing) |
Συμπέρασμα:
- Χρησιμοποίησε Puppeteer αν χρειάζεσαι πλήρη έλεγχο, έχεις πόρους για coding ή θέλεις να ενσωματώσεις το scraping σε μια μεγαλύτερη εφαρμογή.
- Χρησιμοποίησε Thunderbit αν θέλεις αποτελέσματα γρήγορα, δεν θέλεις να γράφεις κώδικα ή θέλεις να δώσεις δυνατότητες σε μη τεχνικούς συναδέλφους.
Ειλικρινά, έχω δει ομάδες να χρησιμοποιούν και τα δύο: το Thunderbit για γρήγορες νίκες και prototyping, και το Puppeteer για βαθιές ενσωματώσεις ή edge cases.
Checklist βήμα προς βήμα: Πώς να τρέξεις ένα επιτυχημένο Puppeteer web scraping project
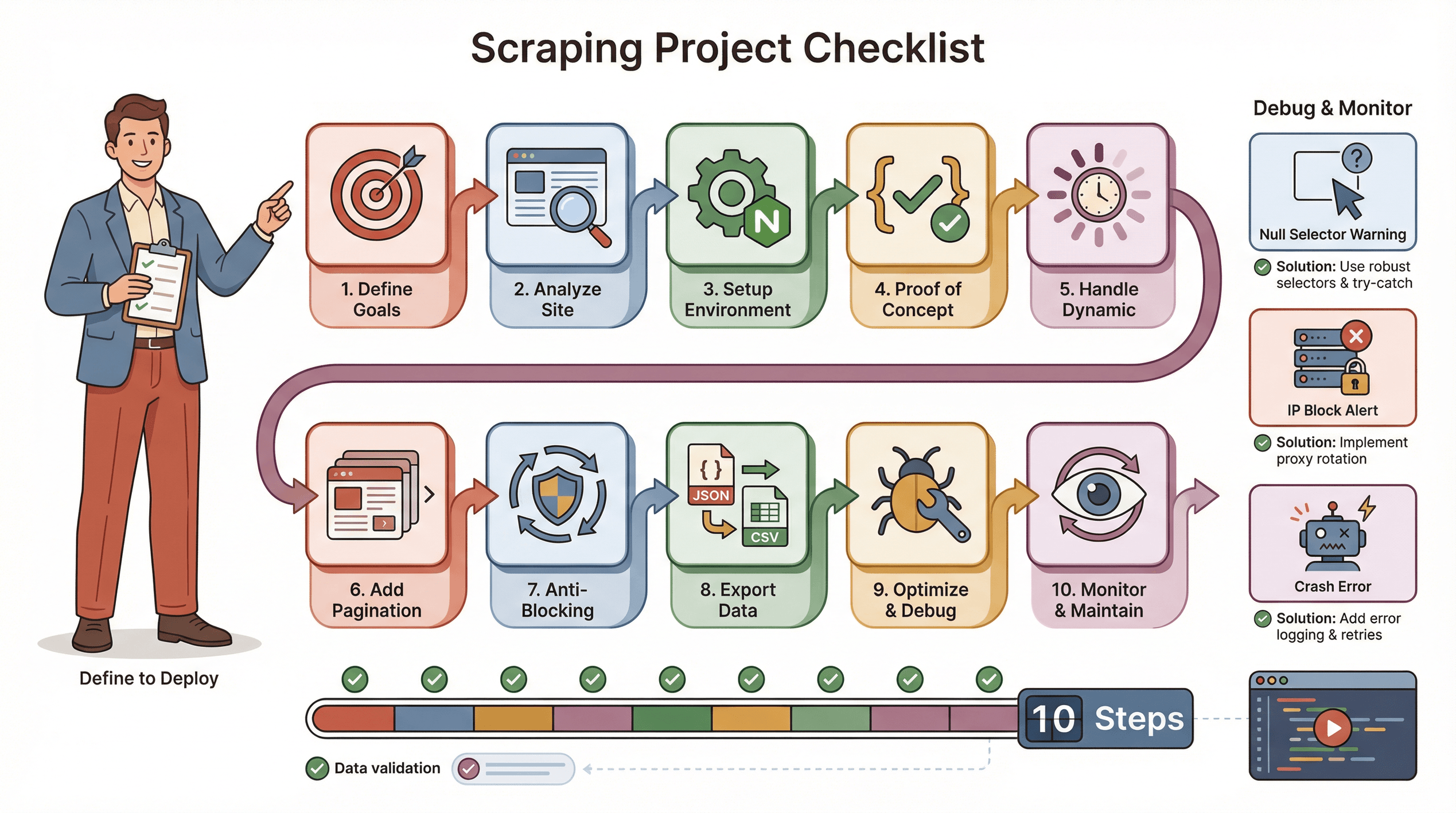 Ορίστε το checklist που χρησιμοποιώ για ένα ομαλό Puppeteer scraping project:
Ορίστε το checklist που χρησιμοποιώ για ένα ομαλό Puppeteer scraping project:
- Όρισε τους στόχους σου: Τι δεδομένα χρειάζεσαι; Πού βρίσκονται;
- Ανάλυσε τον ιστότοπο: Είναι δυναμικός; Χρειάζεται login; Υπάρχουν anti-bot μέτρα;
- Ρύθμισε το περιβάλλον σου: Node.js, Puppeteer και όποιες βοηθητικές βιβλιοθήκες χρειάζονται.
- Γράψε ένα proof-of-concept: Ξεκίνα με μία σελίδα, βρες σωστά τους selectors.
- Χειρίσου το δυναμικό περιεχόμενο: Χρησιμοποίησε
waitForSelector, προσομοίωσε κλικ/scroll όπου χρειάζεται. - Πρόσθεσε σελιδοποίηση ή βρόχους: Κάνε scrape όλες τις σελίδες, όχι μόνο μία.
- Εφάρμοσε τακτικές αποφυγής μπλοκαρίσματος: Τυχαίοι χρόνοι αναμονής, πραγματικό User-Agent, proxies αν χρειάζεται.
- Εξήγαγε και έλεγξε τα δεδομένα: Αποθήκευσέ τα σε JSON/CSV, έλεγξε αν είναι πλήρη.
- Βελτιστοποίησε και διαχείρισε σφάλματα: Πρόσθεσε try/catch, κατέγραψε την πρόοδο, χειρίσου ήρεμα τα ελλιπή δεδομένα.
- Παρακολούθησε και συντήρησε: Οι ιστότοποι αλλάζουν — να είσαι έτοιμος/η να ενημερώσεις το script σου.
Συμβουλές αντιμετώπισης προβλημάτων:
- Αν οι selectors επιστρέφουν null, ξαναέλεγξε το HTML και χρησιμοποίησε waits.
- Αν μπλοκάρεις, επιβράδυνε, κάνε rotation IPs ή χρησιμοποίησε stealth plugins.
- Αν το script σου κρασάρει, έλεγξε για memory leaks ή unhandled exceptions.
Συμπέρασμα και βασικά σημεία
Το web scraping έχει γίνει απαραίτητη δεξιότητα για ομάδες που δουλεύουν με δεδομένα. Το Puppeteer σου δίνει τη δυνατότητα να εξάγεις δεδομένα ακόμη και από τους πιο δυναμικούς ιστότοπους με έντονο JavaScript — αλλά απαιτεί κάποιες γνώσεις coding και συνεχή συντήρηση. Για επιχειρηματικούς χρήστες που θέλουν να παρακάμψουν τον κώδικα και να πάνε κατευθείαν στα δεδομένα, το Thunderbit προσφέρει μια AI-powered, no-code εναλλακτική που είναι γρήγορη, ευέλικτη και εκπληκτικά στιβαρή.
Αυτό που θα πρότεινα:
- Αν είσαι τεχνικός/ή και χρειάζεσαι βαθιά παραμετροποίηση, ξεκίνα με το Puppeteer.
- Αν θέλεις ταχύτητα, απλότητα και λιγότερη συντήρηση, δοκίμασε το (η είναι εξαιρετικό σημείο εκκίνησης).
- Για τις περισσότερες ομάδες, ένας συνδυασμός και των δύο καλύπτει το 99% των αναγκών σε web data.
Θέλεις να δεις περισσότερους οδηγούς σαν κι αυτόν; Δες το για tutorials, συγκρίσεις και τα πιο πρόσφατα νέα στο AI-powered web scraping.
Συχνές ερωτήσεις
1. Τι είναι το Puppeteer scraper και γιατί χρησιμοποιείται στο web scraping;
Το Puppeteer είναι μια βιβλιοθήκη Node.js που σου επιτρέπει να ελέγχεις έναν headless Chrome browser με JavaScript. Χρησιμοποιείται για web scraping επειδή μπορεί να φορτώνει δυναμικό περιεχόμενο, να προσομοιώνει ενέργειες χρήστη και να εξάγει δεδομένα από ιστότοπους που οι παραδοσιακοί scrapers δεν μπορούν να χειριστούν.
2. Πώς συγκρίνεται το Puppeteer με το Selenium και το Thunderbit;
Το Selenium λειτουργεί με πολλούς browsers και γλώσσες, αλλά είναι πιο βαρύ. Το Puppeteer είναι πιο «στριμωγμένο» για Chrome/Node.js και είναι πιο γρήγορο για πολλές εργασίες scraping. Το Thunderbit, από την άλλη, είναι ένα no-code, AI-powered εργαλείο που επιτρέπει σε μη τεχνικούς χρήστες να κάνουν scrape δεδομένα με λίγα μόνο κλικ.
3. Ποια είναι τα βασικά επιχειρηματικά οφέλη του Puppeteer web scraping;
Η αυτοματοποίηση της συλλογής δεδομένων εξοικονομεί χρόνο, μειώνει τα λάθη και επιτρέπει insights σε πραγματικό χρόνο για πωλήσεις, marketing, operations και πολλά άλλα. Οι χρήσεις κυμαίνονται από δημιουργία leads μέχρι παρακολούθηση τιμών και έρευνα αγοράς.
4. Ποιες είναι οι μεγαλύτερες προκλήσεις με το Puppeteer scraping;
Οι κύριες προκλήσεις είναι ο χειρισμός δυναμικού περιεχομένου, η αποφυγή anti-bot μπλοκαρισμάτων και η συντήρηση των scripts όταν αλλάζουν οι ιστότοποι. Θα χρειαστεί να γράψεις κώδικα για να διαχειρίζεσαι waits, να προσομοιώνεις αλληλεπιδράσεις και να χειρίζεσαι σφάλματα.
5. Πότε πρέπει να χρησιμοποιήσω το Thunderbit αντί για το Puppeteer;
Χρησιμοποίησε το Thunderbit αν θέλεις να αποφύγεις το coding, χρειάζεσαι γρήγορα αποτελέσματα ή θέλεις να δώσεις δυνατότητες σε μη τεχνικούς συναδέλφους. Είναι ιδανικό για τυπικές εργασίες scraping, projects με γρήγορο turnaround ή όταν θέλεις απλώς να εξάγεις δεδομένα σε Excel ή Google Sheets με ελάχιστο κόπο.
Έτοιμος/η να δοκιμάσεις έναν πιο έξυπνο τρόπο για scraping; ή προχώρησε πιο βαθιά με περισσότερους οδηγούς στο . Καλή επιτυχία στο scraping!
Μάθε περισσότερα