Lass die Szene mal kurz lebendig werden: Es ist Montag, 8:30 Uhr, und du sitzt vor einer Tabelle und ziehst per Copy-and-paste Firmennamen, E-Mail-Adressen und Telefonnummern von einem Dutzend verschiedener Websites zusammen. Damit bist du nicht allein – tatsächlich verbringen über nur damit, Daten von einem Ort zum anderen zu schieben. Ich kenne das aus eigener Erfahrung nur zu gut, und ehrlich gesagt ist das nicht gerade der motivierendste Wochenstart. Für Vertriebsteams ist es sogar noch heftiger: , und mehr als 20 % sagen, dass das ihr größtes CRM-Problem ist.
Unsere Welt läuft auf Daten – nur war die Art, wie wir sie sammeln, lange Zeit wie aus dem letzten Jahrhundert. Dank moderner Data-Extraction-Tools wie Web-Scrapern und KI-gestützten Lösungen befreien wir uns endlich aus der Tyrannei endloser Copy-and-paste-Arbeit. In diesem Leitfaden zeige ich dir, was Data Extraction wirklich bedeutet, warum sie so wichtig ist und wie du damit aus stundenlanger Fleißarbeit in wenigen Minuten verwertbare Erkenntnisse machst. Egal ob Sales, E-Commerce oder Operations: Hier geht es darum, smarter zu arbeiten, nicht härter.
Data Extraction verständlich erklärt: Was ist das und warum ist es wichtig?
Reden wir Klartext. Data Extraction bedeutet ganz einfach, nützliche Informationen aus vielen Quellen zusammenzutragen und sie in einer übersichtlichen Liste zu ordnen. Stell dir vor, du pflückst Äpfel aus verschiedenen Obstgärten und legst die besten in deinen Korb – genau so funktioniert Data Extraction im Kern.
Formal ist es der Prozess, Daten aus unterschiedlichen Quellen abzurufen oder herauszuziehen und sie in ein nutzbares Format für Analyse, Reporting oder Speicherung zu überführen (). Ziel ist es, verstreute Informationen aus Datensilos herauszuholen und an einem Ort zu bündeln, an dem man wirklich damit arbeiten kann.
Wo findet Data Extraction statt?
- Websites: Öffentliche Verzeichnisse, Produktlisten oder Bewertungsportale.
- Datenbanken & Tabellen: Dein CRM, ERP oder die endlose Excel-Datei.
- Dokumente & PDFs: Rechnungen, Berichte oder Verträge.
- APIs und Logs: Für technisch versiertere Teams sind das echte Goldgruben für Betriebsdaten.
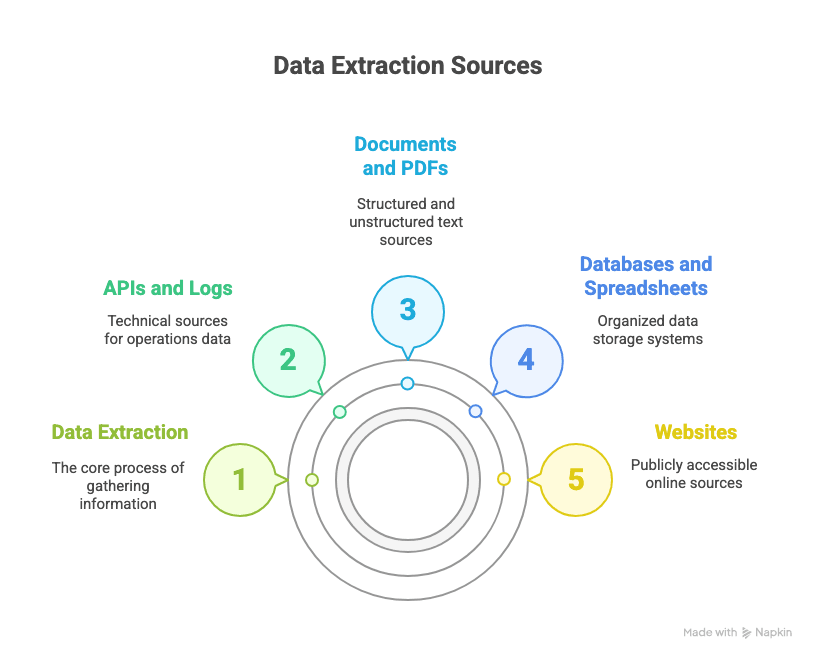
Ob strukturiert (wie saubere Zeilen in einer Datenbank) oder unstrukturiert (wie ein wildes Durcheinander aus Social-Media-Posts): Data Extraction ist der erste Schritt, um daraus Sinn zu machen. Im Grunde ist es „Copy-and-paste auf Steroiden“ – schneller, genauer und deutlich weniger seelenraubend.
Warum Data Extraction für moderne Unternehmen wichtig ist
Seien wir ehrlich: Zeit ist Geld. Jede Stunde, die dein Team mit Datenchaos verbringt, ist eine Stunde, die nicht für Vertrieb, Strategie oder Kundenservice zur Verfügung steht. Tatsächlich kosten . Eine Billion – mit „B“. Autsch.
Aber es geht nicht nur darum, Zeit zu sparen, sondern auch darum, neue Chancen zu erschließen. So schafft automatisierte Data Extraction echten Mehrwert:
| Anwendungsfall | Wer profitiert | Wie das aussieht |
|---|---|---|
| Lead-Generierung | Vertriebsteams | Kontaktinformationen aus Verzeichnissen, LinkedIn oder Unternehmenswebsites in eine sofort nutzbare Liste ziehen |
| Preis- & Lagerüberwachung | E-Commerce-Teams | Konkurrenzpreise oder Lagerbestände über Hunderte von SKUs hinweg beobachten – keine manuellen Checks mehr |
| Marktforschung | Analysten/Marketing | Bewertungen, Social Posts oder Produktspezifikationen für Wettbewerbsanalysen bündeln |
| Lieferantenmanagement | Einkauf | Lieferantenkataloge und Preisaktualisierungen automatisch verfolgen |
| Datenanreicherung | Alle | Zusätzliche Informationen wie E-Mails, Telefonnummern oder Adressen ergänzen, um CRM oder Datenbank aufzuwerten |
Und vergiss die Genauigkeit nicht: Manuelle Dateneingabe hat eine Fehlerquote von rund . Das klingt erst mal wenig – aber auf große Mengen hochgerechnet ruft dein Vertrieb plötzlich die falschen Nummern an, oder dein Preis-Dashboard liegt um Hunderte Dollar daneben.
Automatisierte Data-Extraction-Tools sparen nicht nur Zeit, sondern helfen auch, teure Fehler zu vermeiden und bessere Entscheidungen schneller zu treffen. Kein Wunder, dass fast .
Die realen Herausforderungen bei Data Extraction
Wenn Data Extraction so großartig ist – warum macht es dann nicht einfach jeder? Nun, die alten Methoden waren… sagen wir mal: eher eine Geduldsprobe.
Das ging früher oft schief:
- Manuelles Copy-and-paste ist langsam und fehleranfällig. Selbst die sorgfältigste Person macht nach der 50. Zeile Fehler. Und mal ehrlich: Niemand träumt davon, seine Karriere als Copy-Paste-Ninja zu verbringen.
- Skripte brechen ständig. Technikaffine Menschen schreiben zwar eigene Web-Scraping-Skripte, aber Websites ändern gern ihr Layout. Eine kleine Änderung, und dein Skript ist hinüber ().
- Jede Website ist anders. Was auf einer Seite funktioniert, klappt auf der nächsten vielleicht gar nicht. Manche haben komplizierte Pagination, andere verstecken Daten hinter Buttons oder Logins.
- Anti-Bot-Sperren. Websites setzen CAPTCHAs, IP-Sperren und andere Tricks ein, um Scraper fernzuhalten ().
- Rechtliche und Compliance-Fragen. Nicht jede Website möchte, dass du ihre Daten abgreifst, und Datenschutzgesetze wie die DSGVO verlangen sauberes Vorgehen.
Und vielleicht die größte Hürde? Die Kommunikationslücke zwischen nicht-technischen Anwendern und technischen Teams. Ich habe erlebt, wie Sales Manager einem Entwickler erklären, was sie brauchen, und am Ende kommt ein Skript heraus, das fast funktioniert – bis zum nächsten Website-Update.
So funktioniert Data Extraction: von manuell zu automatisiert
Wie zieht man Daten eigentlich heraus? Ob per Hand oder mit modernster KI – die Schritte sind erstaunlich ähnlich:
- Datenquelle identifizieren. Wo liegen die Informationen? (Website, PDF, Datenbank usw.)
- Daten extrahieren (scrapen). Die relevanten Inhalte herausholen – per Copy-and-paste, Skript oder Tool.
- Daten bereinigen und strukturieren. Tippfehler korrigieren, Formate vereinheitlichen, Dubletten entfernen.
- Daten exportieren oder speichern. Dort ablegen, wo sie nützlich sind – in Excel, Google Sheets, einer Datenbank oder wo auch immer du sie brauchst.
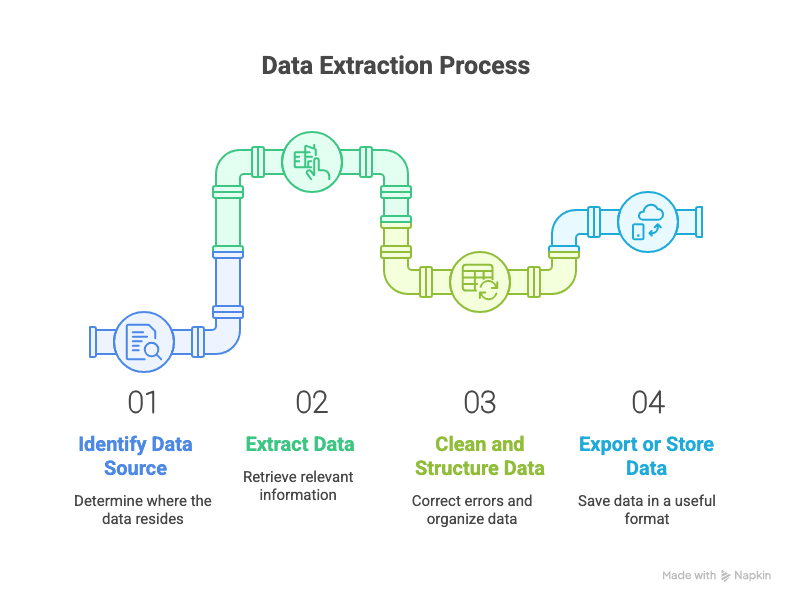
Vergleichen wir die gängigsten Ansätze:
| Ansatz | Vorteile | Nachteile |
|---|---|---|
| Manuelles Copy-and-paste | Jeder kann es | Langsam, fehleranfällig, nicht skalierbar |
| Code-basierte Scraper | Flexibel, leistungsstark | Erfordert Programmierung, bricht leicht, hoher Wartungsaufwand |
| No-Code-/KI-Web-Scraper | Schnell, benutzerfreundlich, anpassungsfähig | Für Sonderfälle manchmal weniger flexibel |
Moderne Tools, besonders KI-gestützte, haben diesen Prozess in eine automatisierte Pipeline verwandelt. Du sagst dem Tool, was du brauchst – den Rest erledigt es. Ganz ohne Programmierung.
Data-Extraction-Tools im Überblick: Web-Scraper, APIs und mehr
Es gibt eine ganze Reihe an Data-Extraction-Tools, aber die meisten fallen in einige Hauptkategorien:
- Web-Scraping-Tools: Der Standard für Business-Anwender. Sie ziehen Daten direkt von Websites – quasi Browser-Erweiterungen oder Cloud-Apps mit Turbo.
- APIs und Integrationen: Wenn eine Website eine API anbietet, nutze sie! APIs sind sauber, strukturiert und brechen seltener.
- Batch-Verarbeitung & ETL-Tools: Für große Datenmengen zwischen Datenbanken oder Dateien – häufiger im IT- und Analytics-Umfeld.
- RPA (Robotic Process Automation): Bots, die menschliche Klicks und Tastatureingaben nachahmen. Gut für Legacy-Systeme, aber manchmal etwas zickig.
- Manuelle Tools: Excel-Webimport, Google-Sheets-Funktionen oder Browser-Add-ons. Gut für kleine Aufgaben, aber nicht für Skalierung gebaut.
Web-Scraper-Tools: Data Extraction für alle zugänglich machen
Web-Scraper sind für die meisten Business-Anwender die erste Wahl. Sie automatisieren das Sammeln von Daten von Websites und machen aus Stunden des Klickens in Minuten verwertbare Ergebnisse.
Klassische Web-Scraper verlangen meist, dass du Felder per Point-and-Click auswählst oder Regeln definierst, was extrahiert werden soll. Ändert sich die Website, fängst du praktisch wieder von vorne an.
KI-gestützte Web-Scraper wie Thunderbit gehen einen Schritt weiter. Du beschreibst einfach, was du willst – „Gib mir alle Produktnamen und Preise auf dieser Seite“ – und die KI macht den Rest. Kein Kampf mehr mit HTML oder XPath.
Wichtige Funktionen, auf die du achten solltest:
- Einfache Einrichtung (ohne Code)
- Scraping von Unterseiten und Pagination
- Mehrere Exportoptionen (Excel, Google Sheets, Notion usw.)
- Anpassungsfähigkeit an verschiedene Website-Layouts
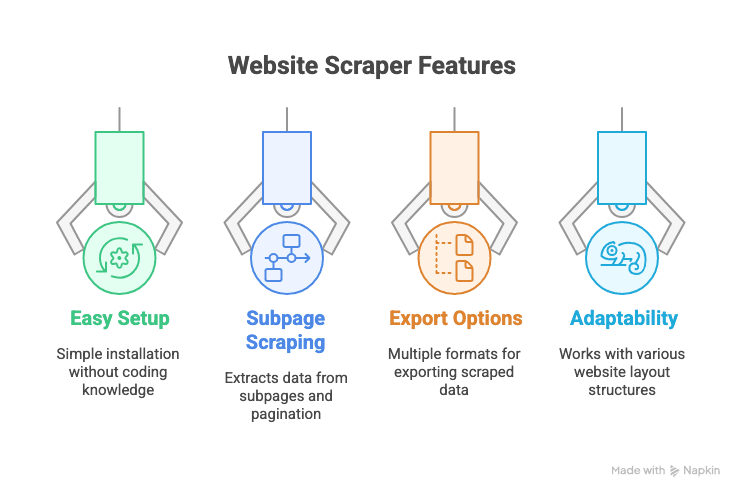
Thunderbit: KI-gestützte Data Extraction für alle
Als jemand, der jahrelang SaaS- und Automatisierungstools entwickelt hat, habe ich aus erster Hand gesehen, wo die meisten Data-Extraction-Tools scheitern: Sie sind entweder zu technisch, zu starr oder zu langsam, um sich an echte Geschäftsanforderungen anzupassen.
Deshalb haben wir gebaut – einen KI-basierten Web-Scraper, der speziell für nicht-technische Business-Anwender entwickelt wurde. Unser Ziel? Data Extraction so einfach machen wie Essen zu bestellen.
Das zeichnet Thunderbit aus:
- AI Suggest Fields: Einfach auf „AI Suggest Fields“ klicken, und Thunderbit liest die Website, schlägt die relevantesten Spalten vor und erstellt sogar eigene Prompts für jedes Feld. Kein Rätselraten mehr, welcher Selektor verwendet werden muss.
- Unterseiten-Scraping: Brauchst du Details von jeder Produkt- oder Profilseite? Thunderbit besucht jede Unterseite und ergänzt deine Tabelle automatisch.
- Pagination-Unterstützung: Egal ob „Weiter“-Button oder endloses Scrollen – Thunderbit kommt damit klar, sodass du alle Daten bekommst und nicht nur die erste Seite.
- Einfacher Export: Sende deine Daten direkt an Excel, Google Sheets, Notion oder Airtable. Oder lade sie als CSV oder JSON herunter – passend zu deinem Workflow.
- No-Code und benutzerfreundlich: Wenn du einen Browser bedienen kannst, kannst du auch Thunderbit nutzen. Technisches Vorwissen ist nicht nötig.
- Scraping in der Cloud oder im Browser: Wähle, was am besten zu deinem Bedarf passt – Thunderbit kann für mehr Geschwindigkeit in der Cloud laufen oder im Browser für Websites, die Logins erfordern.
Und ja, wir haben dafür gesorgt, dass es bezahlbar bleibt. Im kostenlosen Tarif kannst du bis zu 6 Seiten scrapen, und die kostenpflichtigen Pläne starten bei nur 15 $ pro Monat für 500 Credits. Für die meisten kleinen Teams reicht das völlig aus, um loszulegen.
Neugierig? Lade die Chrome-Erweiterung von Thunderbit herunter und probiere sie selbst aus.
Thunderbit in der Praxis: Anwendungsbeispiele aus dem Alltag
Werden wir konkret. So nutzen Teams Thunderbit jeden Tag:
Vertrieb: Leads in Minuten erfassen
Stell dir vor, du bist im Vertrieb und sollst aus einem Branchenverzeichnis eine Liste potenzieller Kunden erstellen. Statt stundenlang Namen, E-Mail-Adressen und Telefonnummern zu kopieren, machst du Folgendes:
- Öffne das Verzeichnis in Chrome.
- Klicke in Thunderbit auf „AI Suggest Fields“.
- Prüfe die vorgeschlagenen Spalten (Name, E-Mail, Telefon, Firma).
- Klicke auf „Scrape“.
- Exportiere die Ergebnisse in Google Sheets und starte deine Ansprache.
Ein Nutzer sagte uns: „Ich habe in weniger als 10 Minuten eine Liste mit 200 Leads erstellt. Früher hat mich das einen halben Tag gekostet!“
E-Commerce: Konkurrenzpreise überwachen
E-Commerce-Manager müssen die Preise der Wettbewerber im Blick behalten. Mit Thunderbit kannst du:
- Die Produktseite des Konkurrenten öffnen.
- Eine Vorlage verwenden oder die KI Felder vorschlagen lassen (Produktname, Preis, Verfügbarkeit).
- Ein geplantes Scraping einrichten, das die Preise täglich prüft.
- Benachrichtigungen erhalten, wenn sich Preise ändern – keine manuellen Kontrollen mehr.
Operations: Lieferantenkataloge im Blick behalten
Operationsteams müssen Lieferantenkataloge oft aktuell halten. Mit Thunderbit ist das ganz einfach:
- Produktlisten von Lieferanten-Websites scrapen.
- Die Daten in Airtable oder Notion für die Bestandsverfolgung exportieren.
- Regelmäßige Updates planen, damit du immer mit den neuesten Informationen arbeitest.
Wichtige Funktionen, auf die du bei Data-Extraction-Tools achten solltest
Nicht jedes Data-Extraction-Tool ist gleich. Darauf würde ich achten:
- Benutzerfreundlichkeit: Können auch nicht-technische Nutzer schnell loslegen?
- Unterstützung mehrerer Datenquellen: Websites, PDFs, Bilder, APIs usw.
- Strukturierte Daten-Ausgabe: Saubere Tabellen statt chaotischer Textwüsten.
- Automatisierung & Planung: Einmal einrichten und vergessen – das Tool läuft auf Autopilot.
- Integration mit Business-Tools: Export nach Excel, Google Sheets, Notion, Airtable oder ins CRM.
- Skalierbarkeit: Verarbeitet das Tool Tausende Datensätze oder nur ein paar wenige?
- Genauigkeit & Zuverlässigkeit: Erkennt es Fehler und passt sich Änderungen an?
- Unterseiten- & Pagination-Scraping: Keine versteckten Details mehr verpassen.
- KI-Unterstützung: Das Tool sollte dir helfen – nicht umgekehrt.
Und unterschätze nicht den Wert von gutem Support und solider Dokumentation – wenn es hakt, willst du schnelle Hilfe.
Best Practices für effektive Data Extraction und Analyse
Das richtige Tool ist nur die halbe Miete. So holst du das Maximum aus deiner Data-Extraction-Strategie heraus:
- Daten prüfen und bereinigen: Immer auf Fehler, Dubletten und Formatprobleme achten. Schlechte Daten rein, schlechte Daten raus.
- Für die Analyse strukturieren: Klare Überschriften und einheitliche Formate verwenden. Denk schon daran, wie du die Daten später nutzen wirst.
- Wiederkehrende Aufgaben automatisieren: Regelmäßige Scrapes einplanen, damit deine Daten immer aktuell sind.
- Rechtliche und datenschutzrechtliche Grenzen respektieren: Vor dem Scraping immer die Website-AGB und Datenschutzregeln prüfen.
- Tools aktuell halten: Websites ändern sich – deine Tools müssen mithalten.
- Daten sichern und backuppen: Lass deine hart erarbeiteten Erkenntnisse nicht durch einen Festplattencrash verschwinden.
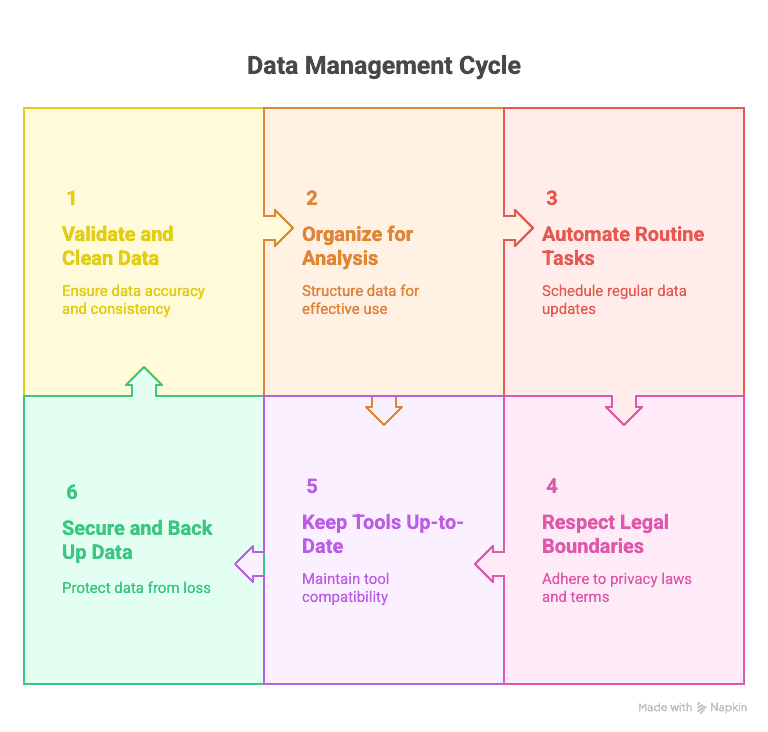
Eine kurze Checkliste nach jedem Scrape: Stichproben prüfen, Dubletten entfernen, in dein Analysetool laden und eine Erinnerung für das nächste Update setzen.
Das volle Potenzial von Data Extraction für dein Unternehmen freisetzen
Fassen wir zusammen. Data Extraction ist nicht nur ein Buzzword – sie ist ein praktisches, transformierendes Werkzeug für alle, die mit Informationen arbeiten. Egal, ob du Leads verfolgst, Preise beobachtest oder einfach nur Ordnung in deine Daten bringen willst: Das richtige Tool verwandelt stundenlange Plackerei in Minuten voller Erkenntnisse.
Und meine persönliche Sicht darauf: Die Zukunft gehört vertikalen KI-Agenten – Tools, die sich präzise auf konkrete Geschäftsprobleme konzentrieren, statt nur allgemeine Chatbots zu sein. Warum? Weil Unternehmen Zuverlässigkeit, Wiederholbarkeit und skalierbare Ergebnisse brauchen. Allgemeine KI-Agenten sind großartig für Brainstorming oder Fragen und Antworten, aber wenn es um die Automatisierung wiederkehrender, geschäftskritischer Prozesse geht, brauchst du ein Tool, das genau für diese Aufgabe gebaut wurde.
Genau das entwickeln wir bei . Unsere Mission ist es, Data Extraction für alle zugänglich zu machen – ohne Code, ohne Kopfschmerzen, einfach mit Ergebnissen. Wenn du bereit bist, manuelle Dateneingabe hinter dir zu lassen, probiere Thunderbit aus und erlebe, wie viel mehr du schaffen kannst.
Willst du noch tiefer einsteigen? Dann schau dir auch unsere anderen Leitfäden im an, zum Beispiel und .
Arbeite smarter, nicht härter. Die Erkenntnisse sind da draußen – jetzt hast du die Mittel, sie dir zu holen.
P.S. Wenn du dich jemals dabei ertappst, vom Copy-and-paste von Daten zu träumen, ist es wahrscheinlich Zeit zu automatisieren. Oder einfach mal Urlaub zu machen. So oder so: Thunderbit steht dir zur Seite.
FAQ
1. Was ist Thunderbit?
Thunderbit ist eine KI-gestützte Chrome-Erweiterung, mit der jeder Daten von Websites extrahieren kann – ganz ohne Programmierung. Ideal für Sales-, Marketing-, E-Commerce- und Operations-Teams.
2. Worin unterscheidet es sich von klassischen Scrapern?
- KI erkennt Felder automatisch
- Unterstützt Unterseiten und Pagination
- Keine Einrichtung und kein Code nötig
- Export nach Sheets, Excel, Notion usw.
3. Kann es Logins, PDFs oder dynamische Seiten verarbeiten?
Ja.
- Browser-Modus: Für Logins, PDFs und interaktive Seiten
- Cloud-Modus: Schnelles Scraping öffentlicher Websites
Außerdem unterstützt es Textzusammenfassung und Übersetzung.