Stell dir vor: Es ist 2025, du schlürfst gemütlich deinen Morgenkaffee und willst endlich wissen, ob Walmart den Preis für den 65-Zoll-Fernseher gesenkt hat, den du schon ewig beobachtest – oder du betreibst ein E-Commerce-Business und musst Preise, Lagerbestände und Kundenbewertungen bei Walmart in Echtzeit im Blick behalten. Jeden Tag manuell alle Produkte auf der Walmart-Seite checken? Das wäre ein Fulltime-Job – und ehrlich gesagt, kein besonders spaßiger. Mit ein bisschen Python-Skills und 웹 스크래퍼 kannst du dir diese Fleißarbeit aber komplett sparen und wertvolle Daten automatisch abgreifen.
Ich habe über Jahre hinweg Automatisierungs- und KI-Tools für Unternehmen gebaut. Walmart scraping ist dabei so eine Art „Geheimwaffe“, mit der du stundenlange Recherche auf ein paar Zeilen Code runterbrichst – und ich zeige dir Schritt für Schritt, wie das geht. In diesem Guide erfährst du, was Walmart scraping eigentlich ist, warum es 2025 für Unternehmen so wertvoll ist und wie du mit Python einen zuverlässigen Walmart scraper baust – inklusive echtem Code und praktischen Tipps. Also schnapp dir deinen Kaffee (oder deinen liebsten Debugging-Snack) und los geht’s.
Was ist Walmart scraping? Die Basics für 2025
Kurz gesagt: Walmart scraping heißt, Produkt-, Preis- und Bewertungsdaten automatisiert von der Walmart-Website zu ziehen – meistens mit einem Skript, das wie ein ultraschneller Webbrowser arbeitet. Statt Infos mühsam per Hand zu kopieren, schreibst du ein Python-Skript, das Walmart-Seiten abruft, gezielt die gewünschten Daten rausfiltert und sie für deine Analyse speichert.
Warum Python? Python ist das Schweizer Taschenmesser für 웹 스크래퍼: super verständlich, mit genialen Bibliotheken (wie Requests, BeautifulSoup und pandas) und einer riesigen Community, die ständig Tipps und Code teilt. Egal ob du solo unterwegs bist oder im Team – mit Python ist Walmart scraping auch für Nicht-Entwickler easy machbar.
Wichtig: Es gibt einen Unterschied zwischen Scraping für den Eigenbedarf (z. B. Preisbeobachtung für ein paar Produkte) und für Unternehmen (z. B. Überwachung von Tausenden SKUs für Marktanalysen). Im Business-Kontext wird’s schnell komplexer – vor allem, weil Walmart 2025 keine öffentliche Produkt-API anbietet ().
Warum Walmart scrapen? Echter Mehrwert für Unternehmen
Walmart ist längst nicht mehr nur Amerikas größter Einzelhändler – online ist das Unternehmen ein echter Riese: Über , fast 18 % des Gesamtumsatzes kommen aus dem E-Commerce (). Das heißt: Unmengen an Produkten, Preisen, Bewertungen und Trends – ein Paradies für Datenanalysen.
Warum also Walmart scrapen? Hier die wichtigsten Business-Use-Cases:
- Preisüberwachung & Wettbewerbsanalyse: Preise, Aktionen und Sortimentsänderungen bei Walmart in Echtzeit verfolgen, um die eigene Preis- und Produktstrategie zu optimieren ().
- Produktrecherche & Markttrends: Sortiment, Spezifikationen und Kategorietrends analysieren, um Lücken oder neue Chancen zu erkennen ().
- Lagerbestands-Tracking: Verfügbarkeit von Produkten überwachen, um die Lieferkette zu optimieren oder von Engpässen bei Wettbewerbern zu profitieren ().
- Kundenbewertungen & Sentiment-Analyse: Bewertungen sammeln und auswerten, um Produkte gezielt zu verbessern oder Schwachstellen zu identifizieren ().
- Marketing & Content-Optimierung: Bestseller-Produkte, deren Präsentation und Conversion-starke Inhalte analysieren ().
- Händler- & Anbieteranalyse: Erfolgreiche Drittanbieter oder unerlaubte Listings identifizieren ().
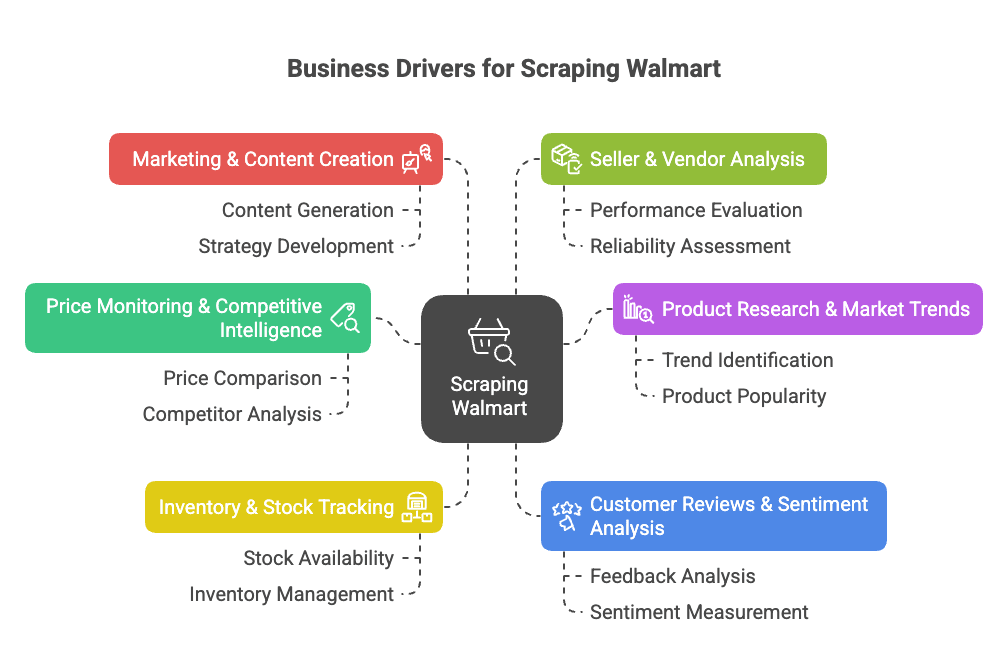
Hier eine kompakte Übersicht zu Anwendungsfällen, Zielgruppen und Mehrwert:
| Anwendungsfall | Wer profitiert | Nutzen & ROI |
|---|---|---|
| Preisüberwachung | Preis- & Vertriebsteams | Echtzeit-Wettbewerbspreise, dynamische Preisgestaltung, Margensicherung |
| Sortiments- & Kataloganalyse | Produktmanagement, Einkauf | Lücken erkennen, neue Produkte launchen, Katalog optimieren |
| Lagerbestands-Tracking | Operations & Supply Chain | Bessere Prognosen, Engpässe vermeiden, Distribution optimieren |
| Kundenbewertungen & Sentiment | Produktentwicklung, Kundenerlebnis | Datenbasierte Produktverbesserung, höhere Zufriedenheit |
| Markttrends & Analysen | Strategie & Marktforschung | Trends erkennen, strategische Entscheidungen, neue Segmente frühzeitig erschließen |
| Content- & Preisstrategie | Marketing & E-Commerce | Preisstrategie verfeinern, von Top-Content lernen |
| Händlerüberwachung | Vertrieb & Partnerschaften | Partner finden, Marke schützen, unerlaubte Händler erkennen |
Das Fazit: Walmart scraping spart Zeit, steigert Umsätze und verschafft dir einen echten Datenvorsprung. Statt jeden Morgen 50 Seiten manuell zu prüfen, kann dein Skript in wenigen Minuten Tausende Listings abgreifen ().
Walmart scraping ist ein echter Gamechanger für E-Commerce, Vertrieb und Marktforschung. Mit den richtigen Tools automatisierst du die Datensammlung und kannst dich auf die Analyse konzentrieren – statt auf Fleißarbeit.
Walmart scraping mit Python: Was du brauchst
Bevor du loslegst, richte deine Python-Umgebung ein. Das brauchst du:
- Python 3.9+ (empfohlen: 3.11 oder 3.12 für 2025)
- Requests: Zum Abrufen von Webseiten
- BeautifulSoup (bs4): Zum Parsen von HTML
- pandas: Für Datenorganisation und Export
- json: Für die Arbeit mit JSON-Daten (integriert)
- Einen Webbrowser mit Entwicklertools: Um die Seitenstruktur zu analysieren (F12 ist dein Freund)
- pip: Zum Installieren von Python-Paketen
Schnellinstallation:
1pip install requests beautifulsoup4 pandasOptional: Für ein sauberes Projekt empfiehlt sich eine virtuelle Umgebung:
1python3 -m venv walmart-scraper
2source walmart-scraper/bin/activate # Mac/Linux
3# oder
4walmart-scraper\\Scripts\\activate.bat # WindowsTeste dein Setup mit:
1import requests, bs4, pandas
2print("Libraries loaded successfully!")Wenn diese Meldung kommt, bist du startklar.
Schritt 1: Dein Python Walmart scraper – das Grundgerüst
So startest du:
- Projektordner anlegen (z. B.
walmart_scraper/). - Code-Editor öffnen (VSCode, PyCharm oder Notepad++ – alles erlaubt).
- Neues Skript anlegen (z. B.
walmart_scraper.py).
Ein Start-Template:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4import jsonJetzt bist du bereit, Walmart-Produktseiten abzurufen.
Schritt 2: Walmart-Produktseiten mit Python abrufen
Um Walmart zu scrapen, musst du das HTML einer Produktseite laden. Aber Achtung: Walmart blockt Bots ziemlich konsequent. Ein einfaches requests.get(url) führt meist direkt zu einer „Robot or human?“-Abfrage.
Der Trick: Verhalte dich wie ein echter Browser. Das heißt, du setzt Header wie User-Agent und Accept-Language, um Chrome oder Firefox zu imitieren.
So geht’s:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9"
4}
5response = requests.get(url, headers=headers)
6html = response.textTipp: Nutze requests.Session(), um Cookies zu speichern und noch menschlicher zu wirken:
1session = requests.Session()
2session.headers.update(headers)
3session.get("<https://www.walmart.com/>") # Homepage aufrufen, um Cookies zu setzen
4response = session.get(product_url)Checke immer response.status_code (sollte 200 sein). Bei seltsamen Seiten oder CAPTCHAs: Tempo drosseln, IP wechseln oder eine Pause einlegen. Walmart meint es ernst mit Bot-Schutz ().
So umgehst du Walmarts Anti-Bot-Maßnahmen
Walmart setzt Tools wie Akamai und PerimeterX ein, um Bots anhand von IP, Headern, Cookies und sogar TLS-Fingerprints zu erkennen. So bleibst du unauffällig:
- Immer realistische Header setzen (siehe oben).
- Anfragen drosseln – 3–6 Sekunden zwischen den Seiten warten.
- Zufällige Pausen einbauen, damit dein Verhalten nicht maschinell wirkt.
- Proxies rotieren, wenn du viele Seiten scrapen willst (mehr dazu später).
- Bei CAPTCHAs: Pause machen – nicht mit Gewalt durchdrücken.
Wer es ganz professionell will, kann mit Bibliotheken wie curl_cffi Python-Anfragen noch browserähnlicher machen (). Für die meisten Fälle reichen aber Header und Geduld.
Schritt 3: Walmart-Produktdaten mit BeautifulSoup extrahieren
Jetzt wird’s spannend: Die gewünschten Daten rausziehen. Walmart nutzt Next.js, daher sind die Produktinfos meist als großes JSON im <script id="__NEXT_DATA__">-Tag eingebettet.
So kommst du dran:
1from bs4 import BeautifulSoup
2import json
3soup = BeautifulSoup(html, "html.parser")
4script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
5if script_tag:
6 json_text = script_tag.string
7 data = json.loads(json_text)Jetzt hast du ein Python-Dictionary mit allen Produktinfos. Für eine typische Produktseite findest du die Details hier:
1product_data = data["props"]["pageProps"]["initialData"]["data"]["product"]Dann extrahierst du die gewünschten Felder:
1name = product_data.get("name")
2price_info = product_data.get("price", {})
3current_price = price_info.get("price")
4currency = price_info.get("currency")
5rating_info = product_data.get("rating", {})
6average_rating = rating_info.get("averageRating")
7review_count = rating_info.get("numberOfReviews")
8description = product_data.get("shortDescription") or product_data.get("description")Warum das JSON nutzen? Es ist strukturiert, stabil und weniger fehleranfällig, falls Walmart das HTML ändert. Außerdem bekommst du oft mehr Infos als auf der Seite sichtbar sind ().
Dynamische Inhalte und JSON-Daten
Manche Infos wie Bewertungen oder Lagerstatus werden per JavaScript oder API nachgeladen. Meist enthält das initiale JSON aber schon alles Wichtige. Falls nicht, kannst du im Browser-Netzwerk-Tab die API-Endpunkte von Walmart finden und diese gezielt ansprechen.
Für die meisten Produktdaten ist das __NEXT_DATA__-JSON aber die beste Quelle.
Schritt 4: Walmart-Daten speichern und exportieren
Hast du die Daten, speicher sie am besten strukturiert – z. B. als CSV, Excel oder JSON. Mit pandas geht das so:
1import pandas as pd
2product_record = {
3 "Produktname": name,
4 "Preis (USD)": current_price,
5 "Bewertung": average_rating,
6 "Anzahl Bewertungen": review_count,
7 "Beschreibung": description
8}
9df = pd.DataFrame([product_record])
10df.to_csv("walmart_products.csv", index=False)Bei mehreren Produkten einfach alle Datensätze in eine Liste sammeln und am Ende das DataFrame erstellen.
Für Excel: df.to_excel("walmart_products.xlsx", index=False) (ggf. openpyxl installieren). Für JSON: df.to_json("walmart_products.json", orient="records", indent=2).
Tipp: Kontrolliere deine Exporte immer stichprobenartig. Nichts ist ärgerlicher, als 1.000 Preise zu scrapen und dann festzustellen, dass alle Felder leer sind, weil Walmart einen Schlüssel geändert hat.
Schritt 5: Deinen Walmart scraper skalieren
Du willst mehr? So scrapest du mehrere Produktseiten:
1product_urls = [
2 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
3 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
4 # ...weitere URLs
5]
6all_records = []
7for url in product_urls:
8 resp = session.get(url)
9 # ...wie oben parsen und extrahieren...
10 all_records.append(product_record)
11 time.sleep(random.uniform(3, 6)) # Höflich bleiben!Falls du keine URL-Liste hast, kannst du auch von einer Suchergebnisseite starten, Produktlinks extrahieren und dann jede Seite scrapen ().
Achtung: Wer hunderte oder tausende Seiten schnell abruft, riskiert eine IP-Sperre. Hier kommen Proxies ins Spiel.
Proxies und Scraper-APIs für Walmart nutzen
Proxies ermöglichen es, deine IP-Adresse zu wechseln, sodass Walmart dich schwerer blockieren kann. Du kannst z. B. Residential Proxies kaufen oder Proxy-Pools nutzen. So funktioniert’s mit requests:
1proxies = {
2 "http": "<http://your.proxy.address>:port",
3 "https": "<https://your.proxy.address>:port"
4}
5response = session.get(url, proxies=proxies)Für große Scraping-Projekte empfiehlt sich eine Scraper API – diese Services übernehmen Proxies, CAPTCHAs und sogar JavaScript-Rendering für dich. Du schickst nur die Walmart-URL und bekommst die Daten zurück (oft schon als JSON).
Hier ein Vergleich:
| Ansatz | Vorteile | Nachteile | Ideal für |
|---|---|---|---|
| Eigenes Python + Proxies | Volle Kontrolle, günstig bei kleinen Projekten | Wartung, Proxy-Kosten, Blockierungsrisiko | Entwickler, individuelle Anforderungen |
| Drittanbieter Scraper API | Einfach, Anti-Bot inklusive, gut skalierbar | Kosten bei großem Volumen, weniger Flexibilität, Abhängigkeit | Business-User, große Projekte, schnelle Ergebnisse |
Wer nicht programmieren möchte oder schnell Ergebnisse braucht, kann Tools wie die nutzen – alles mit wenigen Klicks, ohne Code, Proxies oder Kopfschmerzen. (Mehr dazu gleich.)
Typische Herausforderungen beim Walmart scraping (und wie du sie löst)
Walmart scraping ist kein Selbstläufer. Hier die häufigsten Stolpersteine – und wie du sie meisterst:
- Strenge Anti-Bot-Maßnahmen: Walmart prüft IP, Header, Cookies, TLS-Fingerprints und JavaScript. Lösung: Realistische Header, Sessions, Pausen und Proxy-Rotation ().
- CAPTCHAs: Bei CAPTCHAs: Pause machen und später erneut versuchen. Bei häufigen Problemen ggf. CAPTCHA-Lösungsdienste nutzen – das erhöht aber Kosten und Komplexität ().
- Seitenstruktur-Änderungen: Walmart aktualisiert die Website regelmäßig. Bei Fehlern: JSON-Struktur neu analysieren und Code anpassen. Modularer Code hilft.
- Paginierung & Unterseiten: Bei großen Datenmengen musst du Paginierung berücksichtigen. Nutze Schleifen mit Abbruchbedingungen und prüfe, ob das Ende erreicht ist ().
- Datenmenge & Rate Limits: Bei sehr großen Scrapes Anfragen stapeln und Zwischenergebnisse speichern. Lade nicht 100.000 Produkte auf einmal in den Speicher.
- Rechtliche & ethische Fragen: Nur öffentliche Daten scrapen, Walmarts Nutzungsbedingungen beachten und Server nicht überlasten. Bei kommerzieller Nutzung rechtliche Prüfung vornehmen.
Wann lohnt sich ein Managed Tool? Wenn du mehr Zeit mit CAPTCHAs als mit Datenanalyse verbringst, ist ein Tool wie Thunderbit oder eine Scraper API sinnvoll. Für Nicht-Entwickler sind No-Code-Lösungen oft die beste Wahl ().
Walmart scraping mit Python: Kompletter Beispielcode
Hier ein vollständiges, kommentiertes Python-Skript zum Scrapen von Walmart-Produktseiten:
1import requests
2from bs4 import BeautifulSoup
3import json
4import pandas as pd
5import time
6import random
7# Session und Header einrichten
8session = requests.Session()
9session.headers.update({
10 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
11 "Accept-Language": "en-US,en;q=0.9"
12})
13# Homepage besuchen, um Cookies zu setzen
14session.get("<https://www.walmart.com/>")
15# Liste der Produkt-URLs
16product_urls = [
17 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
18 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
19 # Weitere URLs nach Bedarf
20]
21all_products = []
22for url in product_urls:
23 try:
24 response = session.get(url)
25 except Exception as e:
26 print(f"Request error for \{url\}: \{e\}")
27 continue
28 if response.status_code != 200:
29 print(f"Failed to fetch \{url\} (status \{response.status_code\})")
30 continue
31 soup = BeautifulSoup(response.text, "html.parser")
32 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
33 if not script_tag:
34 print(f"No data script found for \{url\} - possibly blocked or changed page format.")
35 continue
36 try:
37 data = json.loads(script_tag.string)
38 except json.JSONDecodeError as e:
39 print(f"JSON parse error for \{url\}: \{e\}")
40 continue
41 try:
42 product_info = data["props"]["pageProps"]["initialData"]["data"]["product"]
43 except KeyError:
44 print(f"Product data not found in JSON for \{url\}.")
45 continue
46 name = product_info.get("name")
47 brand = product_info.get("brand", {}).get("name") or product_info.get("brand", "")
48 price_obj = product_info.get("price", {})
49 price = price_obj.get("price")
50 currency = price_obj.get("currency")
51 orig_price = price_obj.get("priceStrikethrough") or price_obj.get("price_strikethrough")
52 rating_obj = product_info.get("rating", {})
53 avg_rating = rating_obj.get("averageRating")
54 review_count = rating_obj.get("numberOfReviews")
55 desc = product_info.get("description") or product_info.get("shortDescription") or ""
56 product_record = {
57 "URL": url,
58 "Name": name,
59 "Marke": brand,
60 "Preis": price,
61 "Währung": currency,
62 "Originalpreis": orig_price,
63 "Durchschnittsbewertung": avg_rating,
64 "Anzahl Bewertungen": review_count,
65 "Beschreibung": desc
66 }
67 all_products.append(product_record)
68 # Zufällige Pause zur Tarnung
69 time.sleep(random.uniform(3.0, 6.0))
70df = pd.DataFrame(all_products)
71print(df.head(5))
72df.to_csv("walmart_scrape_output.csv", index=False)Anpassungen:
- Füge weitere URLs zu
product_urlshinzu. - Extrahiere weitere Felder nach Bedarf.
- Passe die Pausen an dein Risikoprofil an.
Fazit & wichtigste Erkenntnisse
Das hast du gelernt:
- Walmart scraping ist ein mächtiges Werkzeug, um Preis-, Produkt- und Bewertungsdaten zu gewinnen – unverzichtbar für Wettbewerbsanalysen, Preisgestaltung und Produktentwicklung 2025.
- Python ist das Tool der Wahl: Mit Requests, BeautifulSoup und pandas baust du auch ohne Profi-Kenntnisse einen robusten scraper.
- Anti-Bot-Schutz ist Realität: Browser-Header imitieren, Sessions nutzen, Pausen einbauen und Proxies rotieren, wenn du skalierst.
- Daten aus dem
__NEXT_DATA__-JSON extrahieren: Das ist stabiler und weniger fehleranfällig als HTML-Parsing. - Daten für die Analyse exportieren: Mit pandas als CSV, Excel oder JSON speichern.
- Skalieren mit Bedacht: Für große Projekte Proxies oder Scraper-APIs nutzen. Wer nicht programmieren will, kann mit dem Walmart (und viele andere Seiten) in wenigen Klicks auslesen – ohne Code. Export nach Excel, Google Sheets, Airtable oder Notion ist kostenlos möglich ().
Mein Tipp:
Starte klein – scrape erst ein Produkt, dann eine Handvoll. Prüfe die Daten auf Richtigkeit. Respektiere Walmarts Regeln und überlaste die Server nicht. Wenn dein Bedarf wächst, steig auf Managed Tools oder APIs um, um Zeit und Nerven zu sparen. Und falls du genug vom Debuggen hast: Mit Thunderbit scrapest du Walmart (und fast jede andere Seite) in zwei Klicks – KI übernimmt die Arbeit ().
Du willst tiefer einsteigen in 웹 스크래퍼, Datenautomatisierung oder KI-gestützte Produktivität? Weitere Anleitungen findest du im .
Viel Erfolg beim Scrapen – und mögen deine Daten immer aktuell, korrekt und frei von CAPTCHAs sein.
P.S.: Falls du nachts um 2 Uhr Walmart scrapest und dabei leise vor dich hin fluchst – keine Sorge, das kennt jeder Datenmensch. Debugging stärkt den Charakter!
FAQs
1. Ist es legal, Walmart-Daten mit Python zu scrapen?
Das Scrapen öffentlich zugänglicher Daten für private oder nicht-kommerzielle Zwecke ist meist erlaubt. Für geschäftliche Nutzung können aber rechtliche und ethische Fragen entstehen. Checke immer die Nutzungsbedingungen von Walmart und achte darauf, keine Server zu überlasten oder sensible Daten zu sammeln.
2. Welche Daten kann ich mit Python von Walmart extrahieren?
Du kannst Produktnamen, Preise, Markeninfos, Beschreibungen, Kundenbewertungen, Ratings, Lagerstatus und mehr extrahieren – vor allem, wenn du das strukturierte JSON im <script id="__NEXT_DATA__">-Tag ausliest.
3. Wie verhindere ich, dass ich beim Walmart scraping blockiert werde?
Nutze realistische Header, Sessions, zufällige Pausen (3–6 Sekunden), rotiere Proxies und vermeide zu viele Anfragen in kurzer Zeit. Für größere Projekte sind Scraper-APIs oder Tools wie Thunderbit sinnvoll, die Anti-Bot-Schutz automatisch übernehmen.
4. Kann ich hunderte oder tausende Walmart-Produkte scrapen?
Ja, aber du musst Proxies verwalten, Anfragen drosseln und ggf. eine Scraper-API nutzen. Walmart hat einen starken Bot-Schutz – ohne Vorbereitung drohen Blockaden oder CAPTCHAs.
5. Was ist der einfachste Weg, Walmart zu scrapen, wenn ich nicht programmieren kann?
Mit Tools wie der Thunderbit KI-Web-Scraper Chrome-Erweiterung kannst du Walmart-Produktseiten ohne eine Zeile Code scrapen. Das Tool übernimmt den Anti-Bot-Schutz, unterstützt den Export nach Excel, Notion und Sheets und ist ideal für Nicht-Entwickler oder Business-Teams, die schnell Einblicke brauchen.