Daten sind ein Schatz, der selbst dann noch Wert hat, wenn die Systeme, die sie erzeugt haben, längst Geschichte sind.
- , Informatiker und Erfinder des World Wide Web
Täglich verarbeitet Google Suchanfragen – das sind nicht nur Antworten auf Alltagsfragen, sondern auch eine riesige Quelle für Markttrends, Wettbewerbsanalysen und wertvolle Kundendaten. Egal ob du im Vertrieb, als -Spezialist oder im Marketing unterwegs bist: Wer diese Daten clever nutzt, kann daraus echte Wettbewerbsvorteile ziehen.
Du kopierst noch immer Daten per Hand aus den Suchergebnissen? Das geht heute viel smarter.
In diesem Artikel erfährst du, was die Google-Suchergebnisseite (SERP) eigentlich ist, welche spannenden Infos sie bereithält und wie du mit einem Google-Serp-Scraper – zum Beispiel dem besonders einfach zu bedienenden No-Code-Tool – gezielt Daten extrahieren kannst. Wir zeigen dir drei verschiedene Wege.
Was ist die Google-Suchergebnisseite (SERP)?
Die (Search Engine Results Page) ist die Seite, die du nach einer Suchanfrage bei Suchmaschinen wie , oder angezeigt bekommst. Sie ist das Tor zu allen Webseiten und der erste Schritt, bevor du auf ein Ergebnis klickst.
Das Besondere an der SERP: Sie basiert auf aktuellen Live-Daten. Änderungen am Algorithmus, neue SERP-Features, Keyword-Trends oder aktualisierte Webseiteninhalte wirken sich direkt auf die Suchergebnisse aus. Außerdem personalisieren Suchmaschinen die Resultate – je nach Suchverlauf und Standort. Das heißt: Selbst zur gleichen Zeit sehen verschiedene Nutzer unterschiedliche SERPs. Gerade für Nicht-Techniker ist es deshalb oft gar nicht so einfach, diese unstrukturierten Daten effizient zu extrahieren.
Da Google über Marktanteil bei Suchmaschinen hat, ist es für Unternehmen besonders wichtig, die Struktur der Google-SERPs zu verstehen und gezielt zu nutzen.
Welche Daten enthält die Google-SERP?
Aufbau der Google-SERP
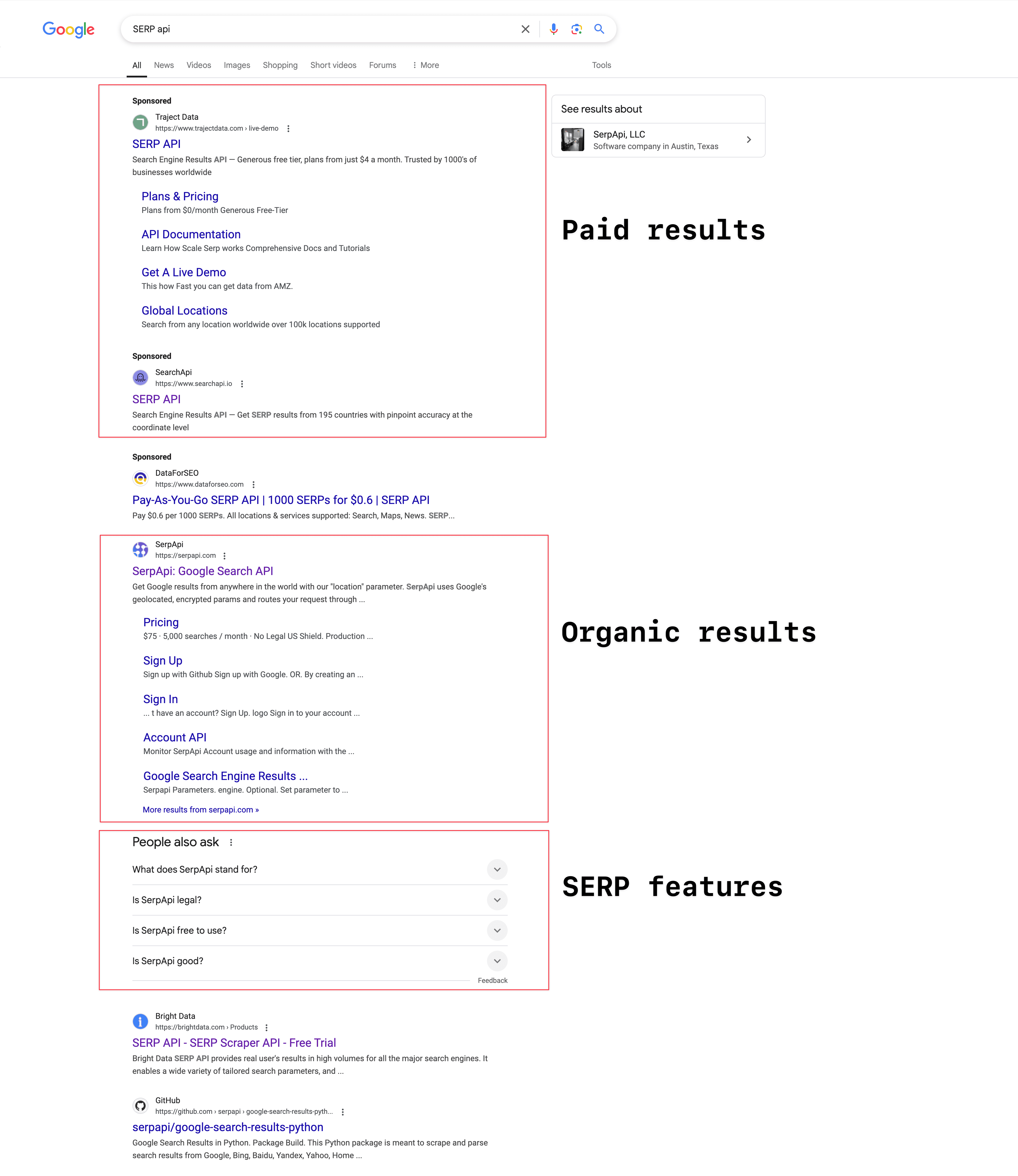
Je nach Suchanfrage kann die SERP unterschiedlich aussehen. Im Großen und Ganzen besteht sie aus drei Hauptbereichen:
-
Bezahlte Ergebnisse: Diese Treffer sind mit „Anzeige“ oder „Gesponsert“ markiert. Unternehmen zahlen dafür, um ganz oben oder unten in den Suchergebnissen zu erscheinen. Ob Anzeigen angezeigt werden, hängt von der Suchanfrage ab. 2023 hat Google laut mit Werbung 264,59 Milliarden US-Dollar umgesetzt.
-
Organische Ergebnisse: Diese unbezahlten Treffer werden nach Relevanz und Ranking sortiert. Sie bestehen aus Titel, Meta-Beschreibung und URL.
-
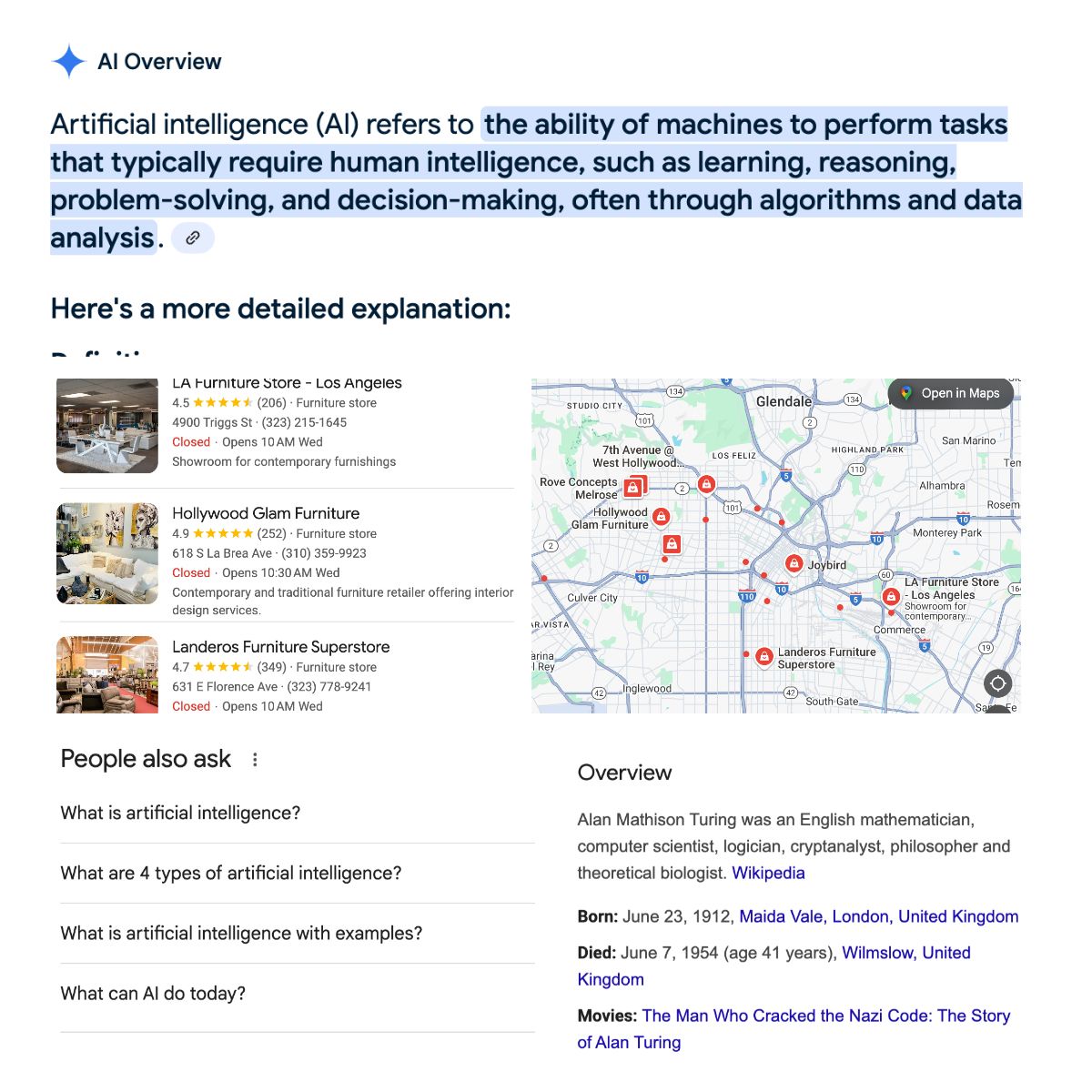
SERP-Features: Google erweitert die Suchergebnisse ständig um neue Funktionen, um die Nutzererfahrung zu verbessern. Dazu gehören hervorgehobene Snippets, KI-Überblicke, „Nutzer fragen auch“-Boxen (PAA), Knowledge Panels, lokale Ergebnisse, Videos, Bilder und Shopping-Angebote.
Datenarten
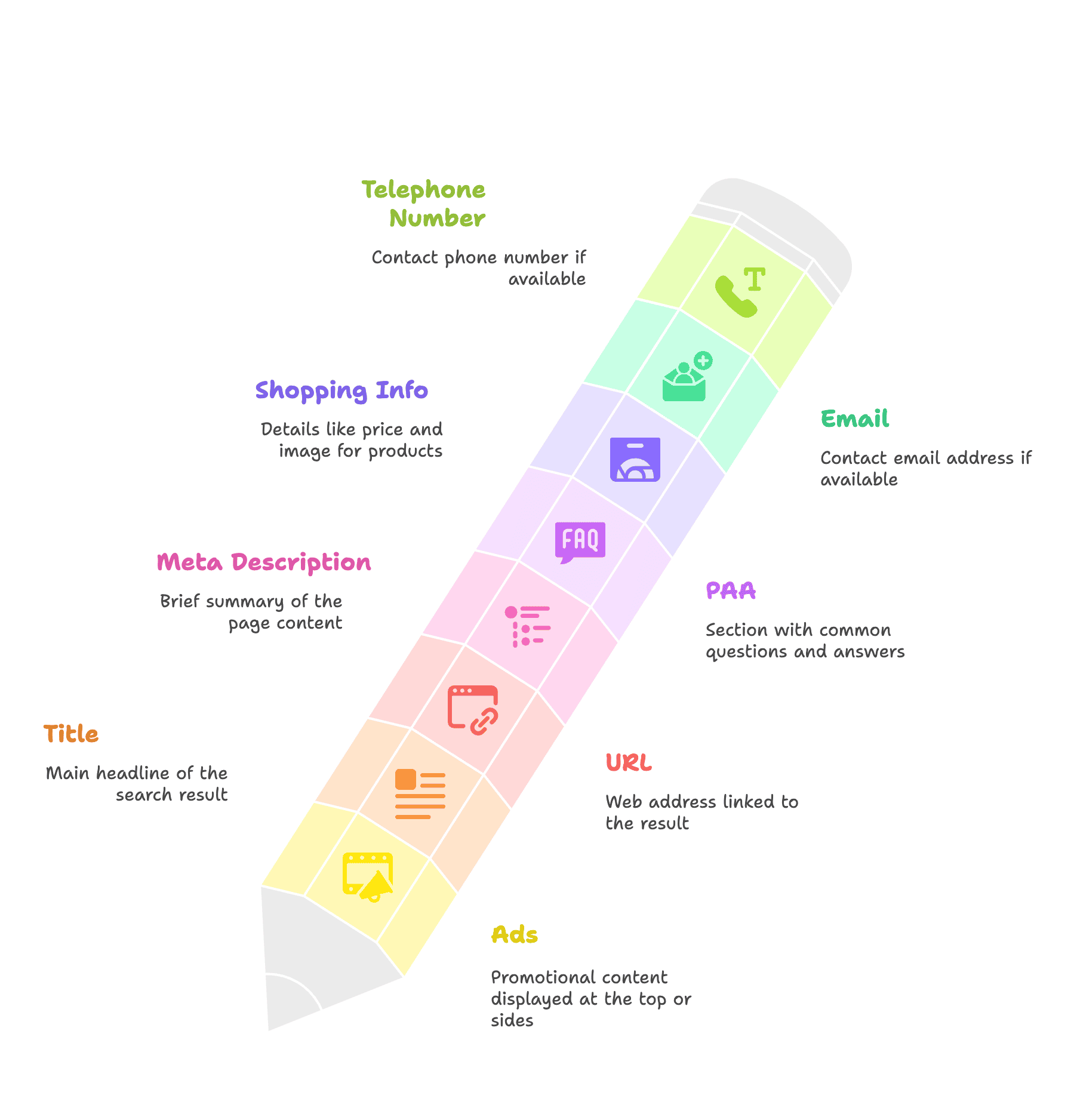
Wer die Struktur der SERP kennt, weiß, welche Infos sich gezielt herausziehen lassen – zum Beispiel:
- Anzeigen
- Titel
- URL
- Meta-Beschreibung
- PAA-Boxen
- Shopping-Infos: Preis, Bild
- E-Mail-Adressen
- Telefonnummern
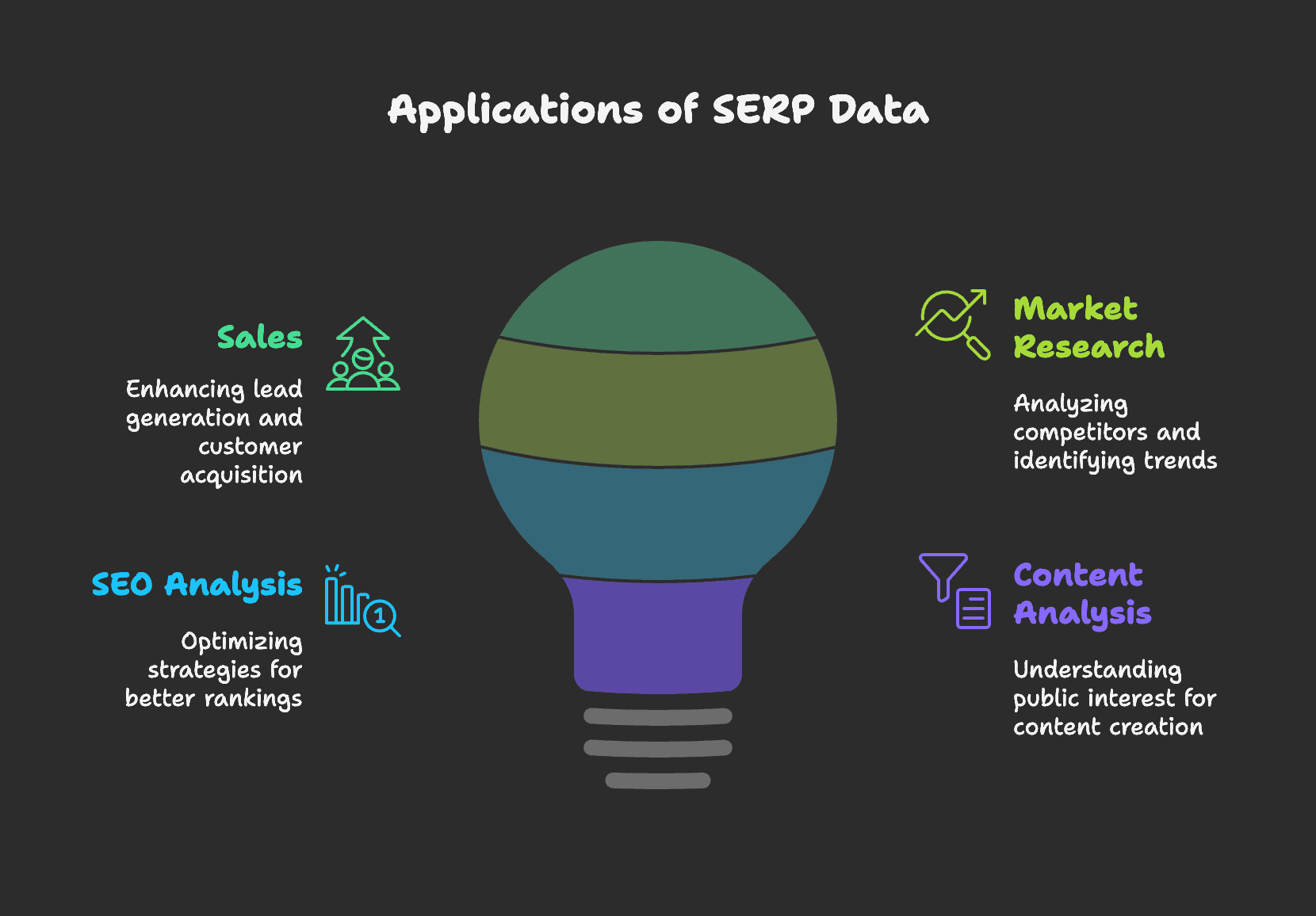
Was lässt sich mit SERP-Daten machen?
Vertrieb
Mit gezielten Suchanfragen können Vertriebsteams schnell neue Leads finden und Chancen entdecken, die andere übersehen. Google liefert dabei wertvolle Kontaktdaten potenzieller Kunden – zum Beispiel E-Mail-Adressen oder Telefonnummern aus sozialen Netzwerken. Wie du mit der SERP Leads auf Instagram findest, zeigen wir dir weiter unten Schritt für Schritt.
Marktforschung
Auch fürs Marketing sind SERP-Daten ein echter Gamechanger. Wer Wettbewerber-Anzeigen und Produktinfos extrahiert, kann deren Strategien analysieren und die eigenen Kampagnen gezielt verbessern.
Außerdem sind SERPs ein Frühwarnsystem für neue Trends. Wer die Entwicklung von Suchbegriffen beobachtet, erkennt frühzeitig neue Marktchancen. Steigt zum Beispiel das Suchvolumen für „nachhaltige Mode“, kann es für einen Modehändler sinnvoll sein, das Sortiment entsprechend anzupassen.
SEO-Analyse
Für SEO-Profis sind SERP-Daten das A und O. Durch die Analyse lassen sich Keyword-Strategien anpassen und Webseiten gezielt optimieren, um das Ranking zu verbessern.
Ein Beispiel: Wer die „Nutzer fragen auch“-Fragen (PAA) extrahiert und deren Entwicklung verfolgt, sieht, welche Themen die Zielgruppe wirklich interessieren – und kann die eigene Website darauf ausrichten.
Content-Analyse
Auch für Journalist:innen und Redaktionen sind Google News-Suchergebnisse eine wertvolle Quelle, um Trends zu erkennen und Themen mit hoher öffentlicher Relevanz zu identifizieren. Wie du mit einem Web-Scraper gezielt Artikel extrahierst, erfährst du in unserem Leitfaden.
Wie kann man die Google-Suchergebnisseite extrahieren?
Du weißt jetzt, wie wertvoll SERP-Daten sind – aber wie kommst du an sie ran?
Manuelles Kopieren ist zwar möglich, aber bei größeren Datenmengen einfach nicht praktikabel. Dank moderner Technologien, vor allem KI, lassen sich heute große Datenmengen automatisiert mit Web-Scrapern erfassen. Hier ein Überblick über drei Methoden:
Mit Thunderbit KI-Web-Scraper
ist ein KI-Web-Scraper, der komplett ohne Programmierkenntnisse funktioniert. Du kannst entweder nutzen oder eigene Spalten definieren. Am Beispiel „Lead-Generierung“ zeigen wir dir Schritt für Schritt, wie du mit Thunderbit qualifizierte Kontakte findest:
-
Schritt 1: Thunderbit als Chrome-Erweiterung installieren und mit Google-Konto oder E-Mail anmelden.
-
Schritt 2: Suchanfrage eingeben.
Um die Ergebnisse gezielt einzugrenzen, helfen .
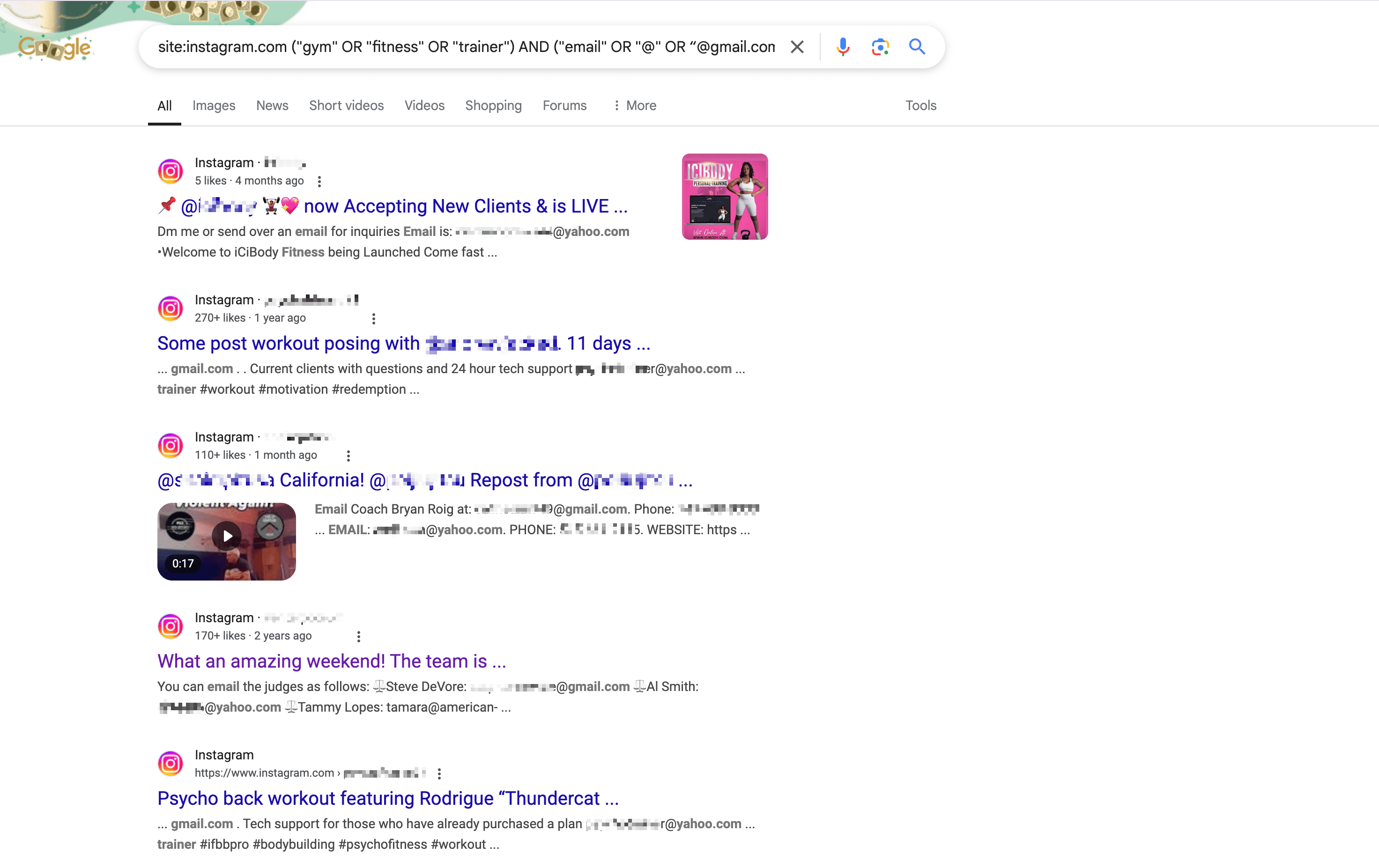
Beispiel für eine von generierte Suchanfrage, um E-Mails von Fitness-Accounts aus Los Angeles auf Instagram zu finden:
1site:instagram.com ("gym" OR "fitness" OR "trainer") AND ("email" OR "@" OR “@gmail.com“ or ”@yahoo.com“ ) AND ("Los Angeles" OR "LA" OR "California")Gib die Suchanfrage bei Google ein und drücke Enter – schon siehst du alle relevanten Ergebnisse.
-
Schritt 3: Thunderbit starten und Daten extrahieren
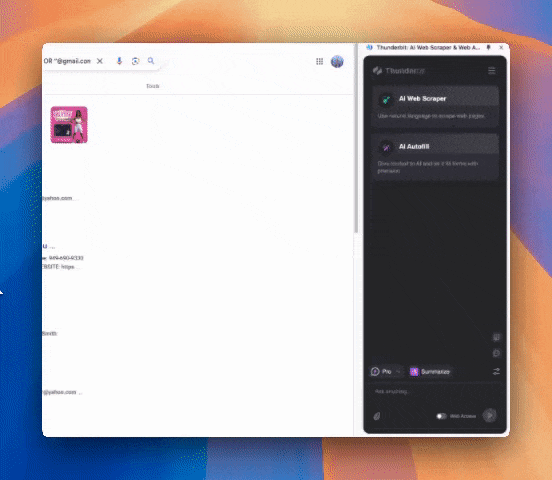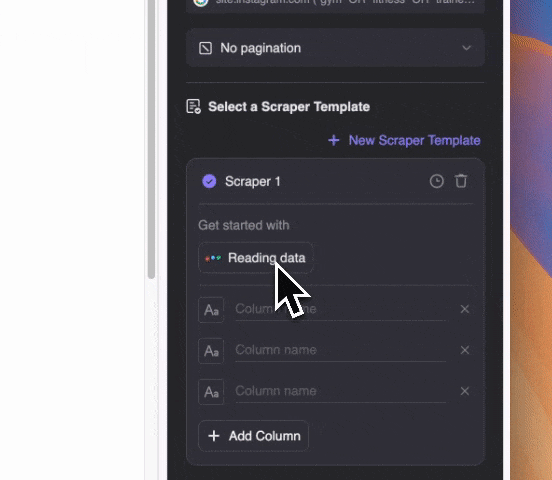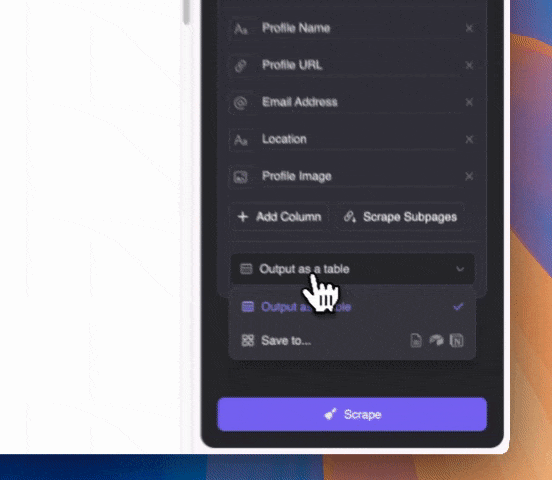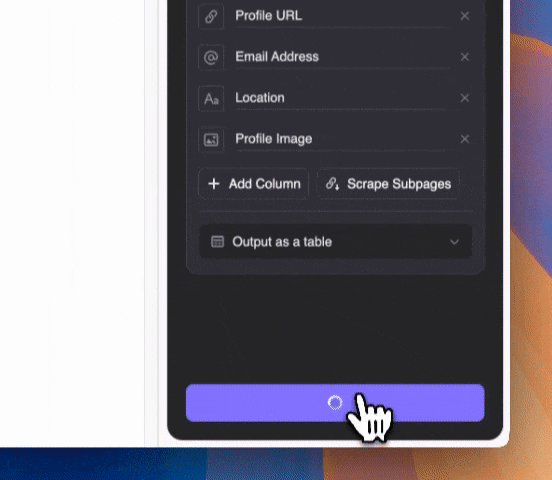 Beschreibe in Alltagssprache, welche Inhalte du extrahieren möchtest (über „Spalte detailliert anlegen“ kannst du weitere Angaben machen). Exportiere die Daten als Tabelle oder direkt nach Notion, Airtable oder Google Sheets.
Beschreibe in Alltagssprache, welche Inhalte du extrahieren möchtest (über „Spalte detailliert anlegen“ kannst du weitere Angaben machen). Exportiere die Daten als Tabelle oder direkt nach Notion, Airtable oder Google Sheets.Thunderbit nutzt KI, um die gewünschten Daten zu erkennen. Selbst wenn E-Mail-Adressen im Google-Snippet mit anderem Text vermischt sind, findet die KI diese zuverlässig.
Klicke auf „Scrape“ und warte auf die Ergebnisse!
Mit klassischem Web-Scraper
Auch klassische Web-Scraper können große Mengen an SERP-Daten erfassen. So funktioniert’s mit WebScraper.io:
- Web Scraper Extension installieren und Chrome Developer Tools öffnen.
- „Neues Sitemap erstellen“ wählen und die Google-Suchergebnisseite als Start-URL festlegen.
- Selektoren konfigurieren, um gezielt Daten auszuwählen.
| Selector Name | Type | Selector | Multiple? |
|---|---|---|---|
| name | Text | Nutzername auswählen | Nein ❌ |
| profile | Text | Meta-Beschreibung auf dieser Seite auswählen | Nein ❌ |
-
Scraper starten und Daten exportieren.
-
Um E-Mails aus den Profiltexten zu extrahieren, kannst du in Excel eine Regex-Formel nutzen:
1text=REGEXEXTRACT(A2,"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}")(A2 enthält dabei den Profiltext)
So filterst du gezielt E-Mail-Adressen heraus.
Der Nachteil: Du brauchst ein Grundverständnis für Web-Strukturen. Ändert sich die Webseite (was bei Google oft passiert), müssen die Selektoren neu eingestellt werden.
Mit Google-API oder Drittanbieter-SERP-APIs
Google bietet mit der eine offizielle Schnittstelle, um Suchergebnisse programmatisch abzurufen. Dafür musst du eine einrichten, einen API-Key generieren und zum Beispiel mit Python Anfragen stellen. Allerdings sind die Datenmengen und Anpassungsmöglichkeiten stark begrenzt.
Alternativ kannst du auf Drittanbieter-SERP-Scraper-APIs (wie Zen SERP, SerpApi, ScrapingBee) zurückgreifen. Auch hier ist die Einrichtung aufwendiger und erfordert Programmierkenntnisse. Nach der Installation musst du Code schreiben, um Instagram-Profile zu finden und E-Mails aus den Biografien zu extrahieren – für viele Unternehmen zu kompliziert.
1import requests
2from bs4 import BeautifulSoup
3import re
4# SerpApi-Zugangsdaten
5SERP_API_KEY = "your_serpapi_key"
6SEARCH_QUERY = "marketing consultant site:instagram.com"
7# Schritt 1: Instagram-Profile mit SerpApi abrufen
8def get_instagram_profiles(query):
9 url = "https://serpapi.com/search"
10 params = {
11 "engine": "google",
12 "q": query,
13 "api_key": SERP_API_KEY
14 }
15 response = requests.get(url, params=params)
16 data = response.json()
17 profile_urls = []
18 for result in data.get("organic_results", []):
19 link = result.get("link")
20 if "instagram.com" in link:
21 profile_urls.append(link)
22 return profile_urls
23# Schritt 2: E-Mail aus Instagram-Bio extrahieren
24def extract_email_from_bio(profile_url):
25 headers = {"User-Agent": "Mozilla/5.0"}
26 response = requests.get(profile_url, headers=headers)
27 if response.status_code != 200:
28 return None
29 soup = BeautifulSoup(response.text, "html.parser")
30 bio_section = soup.find("meta", attrs={"name": "description"})
31 if bio_section:
32 bio_content = bio_section.get("content", "")
33 emails = re.findall(r"[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}", bio_content)
34 return emails if emails else None
35 return None
36# Beispielanwendung
37if __name__ == "__main__":
38 profiles = get_instagram_profiles(SEARCH_QUERY)
39 print("Gefundene Instagram-Profile:", profiles)
40 for profile in profiles:
41 emails = extract_email_from_bio(profile)
42 if emails:
43 print(f"E-Mails gefunden in \{profile\}: \{emails\}")
44 else:
45 print(f"Keine E-Mail gefunden in \{profile\}")Vergleich der 3 Methoden
Du willst ohne technisches Vorwissen schnell und einfach Daten extrahieren? → ist die beste Wahl.
Du möchtest volle Kontrolle über die Datenfelder und kennst dich mit HTML/CSS aus? → Klassischer Web-Scraper
Du brauchst Millionen von Datensätzen und hast ein IT-Team? → Drittanbieter-SERP-API
Ist ein Google-Scraper legal?
Die rechtliche Lage beim Web-Scraping ist oft nicht eindeutig. Die Antwort: Es kommt darauf an. Die Legalität hängt vom Land, dem Zweck, den Nutzungsbedingungen und den konkreten Inhalten ab – eine pauschale Aussage gibt es nicht.
Googles verbieten automatisiertes Scraping ihrer Dienste. Grundsätzlich gilt aber: . Auch der Verwendungszweck (kommerziell oder gemeinnützig) spielt eine Rolle.
Um rechtlich auf der sicheren Seite zu sein, solltest du die Nutzungsbedingungen genau lesen, nur öffentlich zugängliche Daten extrahieren und die Infos nicht für illegale Zwecke nutzen. Bei groß angelegtem Scraping empfiehlt sich eine rechtliche Beratung.
Fazit
Daten sind das „Öl des digitalen Zeitalters“ () – und die Google-SERP ist eine bislang kaum genutzte Goldgrube. Wer SERP-Daten schnell in umsetzbare Strategien verwandelt, verschafft sich einen echten Vorsprung. Typische Anwendungsfälle sind Lead-Generierung, Marktforschung und Suchmaschinenoptimierung.
Je nach technischer Erfahrung, Budget, Datenmenge und Ziel haben wir dir die modernsten Tools vorgestellt: den KI-Web-Scraper Thunderbit, klassische Web-Scraper und SERP-APIs.
Für alle, die mit nur einem Klick alle Ergebnisse extrahieren möchten, ist Thunderbit die beste Wahl. Worauf wartest du noch? .
FAQ
1. Welche Daten kann ich von einer Google-Suchergebnisseite (SERP) extrahieren?
Du kannst viele Infos extrahieren, darunter Titel, URLs, Meta-Beschreibungen, Anzeigen, hervorgehobene Snippets, Shopping-Infos (wie Preis und Bilder), „Nutzer fragen auch“-Fragen, E-Mail-Adressen, Telefonnummern und vieles mehr.
2. Worin unterscheidet sich Thunderbit von klassischen Web-Scrapern oder SERP-APIs?
ist eine KI-gestützte Chrome-Erweiterung, die ohne Programmierung auskommt. Du beschreibst einfach in Alltagssprache, welche Daten du brauchst – die KI erledigt den Rest. Klassische Scraper erfordern technisches Setup, APIs setzen Programmierkenntnisse voraus und sind oft eingeschränkt.
3. Brauche ich technisches Know-how, um mit Thunderbit Google-Suchergebnisse zu extrahieren?
Nein. Thunderbit ist extra für Nicht-Techniker gemacht. Du gibst einfach in normaler Sprache an, welche Daten du möchtest – die KI macht den Rest.
4. Kann ich die extrahierten Daten in Tools wie Google Sheets oder Notion exportieren?
Ja. Thunderbit ermöglicht den direkten Export nach Google Sheets, Airtable, Notion oder als Tabelle zum Download – so kannst du deine Daten sofort weiterverwenden.
5. Welche praktischen Anwendungsfälle gibt es für das Extrahieren von Google-SERP-Daten?
Typische Einsatzbereiche sind Lead-Generierung, Wettbewerbsanalyse, SEO-Optimierung, Trendbeobachtung und Content-Planung. Vertriebsteams finden Kontaktdaten, Marketer analysieren Anzeigenplatzierungen und SEOs verfolgen Keyword-Performance und verwandte Suchanfragen.