Seien wir ehrlich: Wenn ich jedes Mal einen Dollar bekommen hätte, wenn mir jemand ein PDF mit „wichtigen Daten“ geschickt und erwartet hat, dass ich es wie von Zauberhand in eine Tabelle verwandle, könnte ich mir wahrscheinlich einen lebenslangen Kaffeevorrat leisten – und vielleicht noch ein paar zusätzliche Chrome-Erweiterungen dazu. PDFs sind überall: Verkaufsverträge, Produktkataloge, Forschungsarbeiten, Rechnungen, was auch immer. Aber wenn es darum geht, die Daten in diesen Dateien tatsächlich zu nutzen? Genau da fängt der Spaß an – also die Kopfschmerzen.
Ich habe das alles schon mitgemacht: kopieren, einfügen, neu formatieren und manchmal einfach aufgeben, wenn das Layout völlig aus dem Ruder läuft oder Bilder und Links sich in Luft auflösen. Die gute Nachricht: Die Welt des PDF-Scrapings hat sich dramatisch verändert, vor allem durch den Aufstieg KI-gestützter Tools. Wenn Sie es satt haben, stundenlang Zahlen neu einzugeben oder an kaputten Tabellen zu verzweifeln, sind Sie hier genau richtig. Tauchen wir ein in die Welt des PDF-Scrapings, warum sie wichtig ist und wie Tools wie es endlich schmerzfrei machen.
Was ist PDF-Scraping? Die Grundlagen der PDF-Datenextraktion
Fangen wir einfach an: PDF-Scraping ist nur eine schicke Umschreibung für „strukturierte Daten automatisch aus PDF-Dateien holen“. Ein PDF-Scraper ist ein Tool (Software, Erweiterung oder Dienst), das die Dinge herauszieht, die Sie brauchen – Text, Tabellen, Bilder, Links, was auch immer – und sie in ein Format bringt, das Sie wirklich verwenden können, etwa Excel, Google Sheets oder eine Datenbank.
Der Haken: PDFs sind nicht wie Webseiten oder Excel-Dateien. Sie sind eher wie digitale Ausdrucke – so gestaltet, dass sie überall gleich aussehen, nicht so, dass ein Computer sie leicht zerlegen kann. Manche PDFs enthalten auswählbaren Text, andere sind nur gescannte Bilder (dafür braucht man OCR – optische Zeichenerkennung), und das Layout kann völlig unterschiedlich sein. PDF-Scraping bedeutet also nicht nur, Text zu kopieren, sondern ein Puzzle aus Layouts, Schriftarten und manchmal sogar versteckten Metadaten zu entschlüsseln.
Was lässt sich aus einem PDF extrahieren?
- Einfacher Text (Absätze, Überschriften usw.)
- Tabellen (denken Sie an Finanzen, Produktspezifikationen, Umfragedaten)
- Bilder und Grafiken (Diagramme, Logos, gescannte Unterschriften)
- Hyperlinks und Verweise (eingebettete URLs, Zitate)
- Formulardaten (Felder aus ausfüllbaren Formularen)
- Metadaten (Autor, Titel, Erstellungsdatum, Tags)
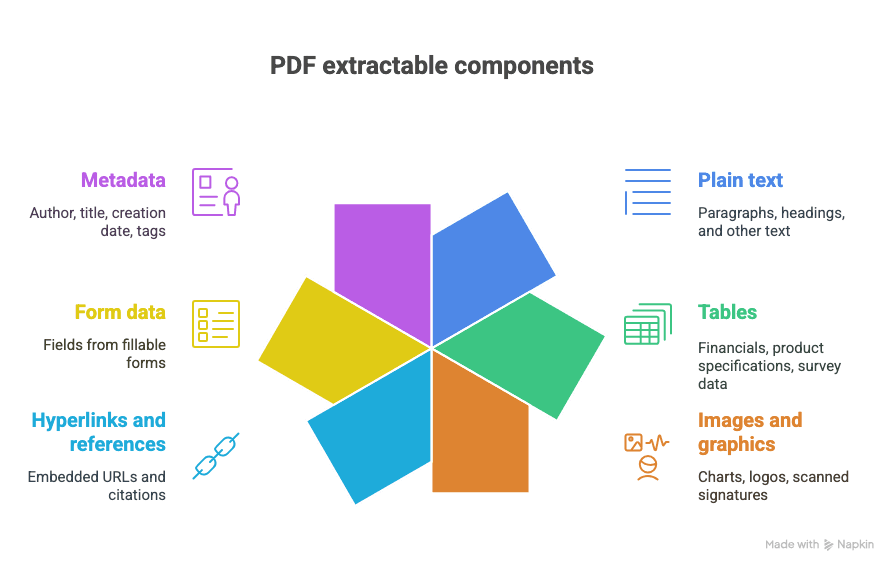
Und ja: Manchmal steckt das alles in einem einzigen herrlich chaotischen Dokument.
Warum PDF-Scraping wichtig ist: Praxisbeispiele und geschäftlicher Nutzen
Warum also PDFs scrapen? Weil alle sie nutzen – und die darin enthaltenen Daten für Unternehmen oft geschäftskritisch sind. Hier spielt PDF-Scraping seine Stärken aus:
| Anwendungsfall | Manueller Aufwand | Mit PDF-Scraper | Zeit- und Fehlereinsparung |
|---|---|---|---|
| Extraktion von Vertriebsleads | Stundenlang Kontaktdaten aus Angeboten oder Veranstaltungs-PDFs kopieren, Risiko, Leads zu übersehen | Zieht alle Leads sofort in eine Tabelle | 80–90 % schneller, weniger Fehler |
| Produktdaten im E-Commerce | Tage damit verbringen, Produktspezifikationen aus Lieferanten-PDFs einzugeben, Formatierungschaos | Massenextraktion in CSV oder Sheets | Über 95 % Zeitersparnis, konsistente Daten |
| Analyse von Forschungsdaten | Wochenlang Tabellen aus wissenschaftlichen Arbeiten abtippen, hohe Tippfehlergefahr | Extrahiert Tabellen, Verweise und sogar gescannten Text | 80 % Zeitersparnis, höhere Genauigkeit |
Machen wir es konkreter:
- Jedes Jahr werden erstellt.
- nutzen PDF als Primärformat für den Informationsaustausch.
- Manuelle digitale Verwaltung, etwa die Eingabe von PDF-Daten, frisst .
- Automatisierte Tools können Fehlerraten von senken.
Wenn Sie im Vertrieb, E-Commerce oder in der Forschung arbeiten, ist die Automatisierung der PDF-Datenextraktion nicht nur ein nettes Extra – sie ist ein Wettbewerbsvorteil.
Herkömmliche PDF-Scraping-Methoden: Herausforderungen und Grenzen
Ganz ehrlich: Die alten Methoden, Daten aus PDFs zu holen, sind… nicht gerade großartig. Hier ist, was die meisten von uns ausprobiert haben – und warum es so frustrierend ist:

1. Manuelles Kopieren und Einfügen
- Schmerzpunkte: Die Formatierung zerbricht, Tabellen werden zum Chaos, Bilder und Links verschwinden, und am Ende bleibt ein dickes Kopfweh.
- Arbeitsaufwand: Hoch. Bei 5.000 PDFs sind selbst bei 1 Minute pro Datei mehr als 80 Stunden Ihres Lebens weg, die Sie nie zurückbekommen.
- Fehlerrate: 5–10 %. Tippfehler, übersprungene Zeilen, versehentlich gelöschte Inhalte – alles schon erlebt.
2. In Word/Excel konvertieren und dann aufräumen
- Schmerzpunkte: Für einfache Dokumente klappt es manchmal, aber komplexe Layouts oder Tabellen werden zerlegt. Den ganzen Schlamassel müssen Sie trotzdem noch bereinigen.
- Bilder/Links: Gehen meist verloren.
- Gezielte Extraktion: Vergessen Sie es – Sie bekommen das ganze Dokument, nicht nur das, was Sie brauchen.
3. Eigene Skripte (Python usw.)
- Schmerzpunkte: Man braucht Programmierkenntnisse – oder jemanden, den man auf Kurzwahl hat. Jedes neue PDF-Format bedeutet, das Skript anzupassen. Gescannte PDFs? Viel Glück.
- Wartung: Hoch. Jedes Mal, wenn ein Anbieter seine Rechnungsvorlage ändert, bricht Ihr Skript.
- Skalierbarkeit: Nichts für schwache Nerven – oder für technisch Unerfahrene.
4. Online-Konverter
- Schmerzpunkte: Für einzelne Aufgaben leicht zu nutzen, aber Sie müssen vertrauliche Dokumente auf einen Server eines Drittanbieters hochladen – hallo, Compliance-Probleme. Außerdem haben Sie nur begrenzte Kontrolle darüber, was extrahiert wird.
- Formatierung: Mal klappt’s, mal nicht. Vielleicht verbringen Sie mehr Zeit mit Aufräumen, als Sie überhaupt gespart haben.
Kurz gesagt: Herkömmliche Methoden sind langsam, fehleranfällig und nicht skalierbar. Deshalb leben so viele Teams einfach damit – aber der Produktivitätsverlust ist enorm.
Moderne Lösungen für PDF-Scraping: Von Code bis zu No-Code-Tools
Zum Glück sind wir nicht mehr im digitalen Mittelalter. Der Markt ist voll mit intelligenteren, schnelleren und benutzerfreundlicheren PDF-Scraping-Optionen.
1. Coding-Bibliotheken (für Entwickler)
- Beispiele: , , .
- Stärken: Sehr flexibel, für große Stapel automatisierbar, kostenlos (Open Source).
- Schwächen: Hoher Einrichtungsaufwand, Programmierkenntnisse nötig, fragil (bricht bei neuen Formaten), begrenzte OCR-/Bildunterstützung.
2. Online-PDF-Konverter
- Beispiele: , , .
- Stärken: Kein Setup, leicht für Nicht-Techniker, schnell für kleine Aufgaben.
- Schwächen: Begrenzte Anpassungsmöglichkeiten, Datenschutzbedenken, Formatierungsfehler, Dateigrößen- und Seitenlimits.
3. KI-gestützte PDF-Scraper
- Beispiele: , Nanonets, Docparser.
- Stärken: Kein Code nötig, verarbeitet Text/Tabellen/Bilder/Links, KI schlägt vor, was extrahiert werden soll, unterstützt Batch-Jobs, integriert sich mit Sheets/Notion/Airtable.
- Schwächen: Manche haben Credit- oder Seitenlimits, benötigen eventuell eine Internetverbindung, bei komplexen Dokumenten kann es eine kurze Einarbeitung geben.
PDF-Scraping-Tools im Vergleich: Welcher Ansatz passt zu Ihnen?
| Tool/Methode | Einrichtung | Am besten geeignet für | Extrahiert | Anpassbar? | Kosten |
|---|---|---|---|---|---|
| Tabula (Tabula-py) | Mittel (UI/Coding) | Tabellen in PDFs | Tabellen | Eingeschränkt | Kostenlos |
| PDFMiner | Programmierung erforderlich | Textlastige PDFs | Text | Ja (Code) | Kostenlos |
| PyPDF2 | Programmierung erforderlich | Einfache Texte/Metadaten | Text, Metadaten | Ja (Code) | Kostenlos |
| Smallpdf/Online-Konverter | Keine (webbasiert) | Schnelle Konvertierungen | Gesamtes Dokument (Word/Excel) | Nein | Freemium |
| Thunderbit | Installation in 2 Klicks | Geschäftsanwender, Teams | Text, Tabellen, Bilder, Links | Ja (KI-Prompts) | Freemium (16,50 $/Monat für Pro) |
Lernen Sie Thunderbit kennen: Die KI-PDF-Scraper-Chrome-Erweiterung
Kommen wir nun zu dem Tool, das mein Leben – und das vieler Geschäftsanwender – so viel einfacher gemacht hat: .
Was macht Thunderbit anders?
- Extraktion in 2 Klicks: Öffnen Sie ein PDF in Chrome, klicken Sie auf die Thunderbit-Erweiterung, und lassen Sie die KI den Rest erledigen.
- KI-gestützte Feldvorschläge: Thunderbits „KI-Felder vorschlagen“ liest Ihr PDF und empfiehlt die Spalten, die Sie wahrscheinlich brauchen (z. B. „Name“, „E-Mail“, „Preis“ usw.).
- Verarbeitet Bilder, Links und Tabellen: Nicht nur reiner Text – Thunderbit kann Bilder, Hyperlinks und sogar OCR für gescannte Dokumente nutzen.
- Eigene Prompts: Sie brauchen nur Telefonnummern oder Produktspezifikationen? Fügen Sie eine benutzerdefinierte Anweisung hinzu, und Thunderbit konzentriert sich genau darauf.
- Export überallhin: Senden Sie Ihre Daten direkt nach Excel, Google Sheets, Airtable oder Notion. Kein CSV-Akrobatik mehr.
- Batch- und Unterseiten-Scraping: Haben Sie eine Liste von PDFs oder Links? Thunderbit kann sie alle in einem Durchgang verarbeiten.
- Zuverlässigkeit auf Unternehmensniveau: Entwickelt für Genauigkeit, Datenschutz und reale Arbeitsabläufe.
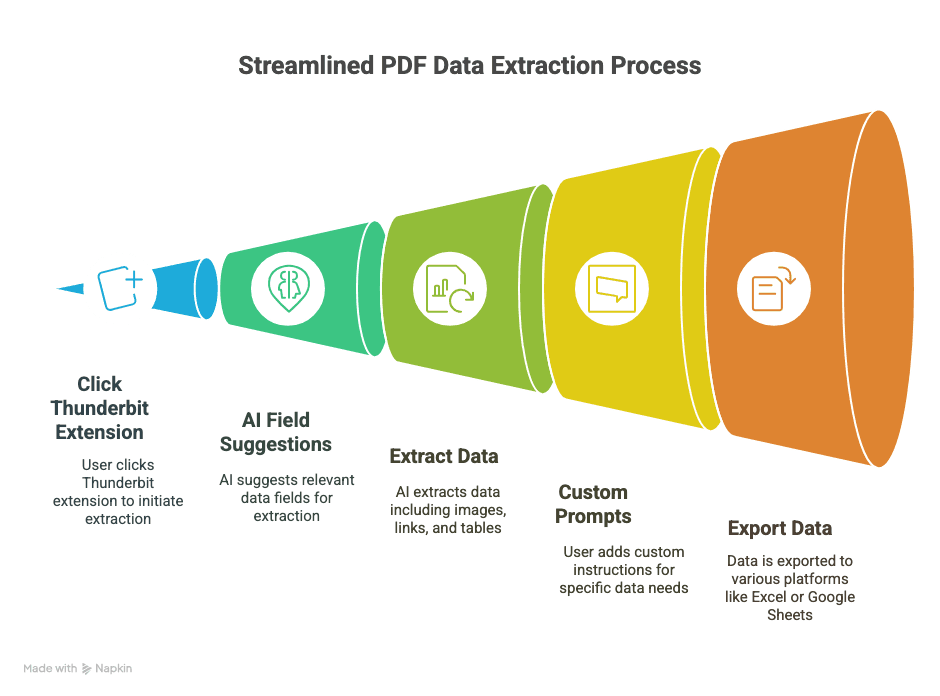
Kurz gesagt: Es ist, als hätten Sie einen digitalen Praktikanten, der Daten eingeben wirklich gern hat – und nie müde wird.
So scrapen Sie mit Thunderbit Daten aus einem PDF: Schritt-für-Schritt-Anleitung
Bereit zu sehen, wie einfach das sein kann? So nutze ich Thunderbit, um PDFs in strukturierte, nutzbare Daten zu verwandeln:
1. Thunderbit installieren
- Holen Sie sich die .
- Registrieren Sie sich (Google-Konto oder E-Mail – dauert nur Sekunden).
2. Öffnen Sie Ihr PDF in Chrome
- Öffnen Sie ein PDF entweder über einen Weblink oder ziehen Sie eine lokale PDF-Datei in einen Chrome-Tab.
3. Thunderbit im PDF starten
- Klicken Sie in der Browser-Symbolleiste auf das Thunderbit-Symbol.
- Wählen Sie „AI Web Scraper“ – Thunderbit erkennt das PDF und macht sich bereit.
4. Lassen Sie sich Felder von der KI vorschlagen
- Klicken Sie auf „KI-Spalten vorschlagen“.
- Thunderbits KI scannt das PDF und empfiehlt Spalten (z. B. „Datum“, „Betrag“, „Kontaktname“ usw.).
- Prüfen Sie die extrahierten Daten direkt in der Erweiterung in einer Tabelle.
5. Anpassen, falls nötig
- Benennen Sie Spalten um, löschen Sie überflüssige oder fügen Sie eigene hinzu (z. B. „Garantiezeitraum“ oder „Produkt-URL“).
- Bei kniffligen Daten können Sie Text im PDF markieren, um der KI zu zeigen, wonach sie suchen soll.
6. Exportformat wählen
- Wählen Sie zwischen CSV, Google Sheets, Airtable oder Notion.
- Autorisieren Sie Thunderbit für die Verbindung (einmalige Einrichtung).
7. Scrapen und exportieren
- Klicken Sie auf „Scrape“ oder „Exportieren“.
- Thunderbit verarbeitet das PDF und sendet die Daten dorthin, wo Sie sie haben möchten – meist in wenigen Sekunden.
Das war’s. Kein Code, kein Kopieren und Einfügen, kein Drama.
Tipps für eine präzise PDF-Datenextraktion mit Thunderbit
- KI-vorgeschlagene Felder prüfen: Die KI ist clever, aber ein kurzer Blick stellt sicher, dass Sie genau das bekommen, was Sie brauchen.
- Komplexe Tabellen behandeln: Bei mehrseitigen oder seltsam formatierten Tabellen nutzen Sie die Vorschau, um Probleme zu erkennen und Spalten bei Bedarf anzupassen.
- Bilder/Links extrahieren: Achten Sie darauf, diese Felder aufzunehmen, wenn Ihr PDF sie enthält – Thunderbit kann sie ebenfalls erfassen.
- Gescannte PDFs: Thunderbits integriertes OCR ist stark, aber je sauberer der Scan, desto besser das Ergebnis.
- Eigene Prompts: Sie möchten nur E-Mail-Adressen oder Telefonnummern? Fügen Sie einen Prompt wie „Alle E-Mail-Adressen extrahieren“ hinzu, und Thunderbit konzentriert sich darauf.
Fortgeschrittenes PDF-Scraping: Bilder, Links und benutzerdefinierte Daten extrahieren
Thunderbit geht über reinen Text hinaus. So holen Sie noch mehr aus Ihren PDFs heraus:
- Bilder: Logos, Diagramme oder andere eingebettete Grafiken extrahieren. Thunderbit kann sogar Text in Bildern per OCR lesen.
- Hyperlinks: Alle URLs oder Verweise herausziehen – ideal für wissenschaftliche Arbeiten oder Lebensläufe.
- Benutzerdefinierte Datentypen: Nutzen Sie KI-Prompts, um nur das zu extrahieren, was Sie brauchen (z. B. „Alle Produkt-SKUs und ihre Preise finden“).
- Zusammenfassungen und Kategorisierung: Fügen Sie eine Spalte hinzu und lassen Sie Thunderbit einen Abschnitt zusammenfassen oder Daten spontan kategorisieren.
Daten aus PDFs für konkrete Geschäftsanforderungen parsen
- Vertrieb: Nur Kontaktinformationen aus einer Reihe von Angeboten extrahieren.
- E-Commerce: Produktspezifikationen, Preise und Bilder aus Lieferantenkatalogen holen.
- Forschung: Tabellen, Verweise und sogar Zusammenfassungen aus wissenschaftlichen Arbeiten erzeugen.
Und sobald Sie die Daten haben, strukturieren Sie sie für eine einfache Analyse in Excel, Google Sheets oder Notion – Thunderbit erledigt die schwere Arbeit, Sie nutzen einfach das Ergebnis.
Ihre PDF-Daten exportieren und nutzen: Von der Extraktion zur Aktion
Die Daten herauszuholen ist nur der Anfang. So machen Sie wirklich etwas daraus:
- Exportoptionen: CSV, Excel, Google Sheets, Airtable, Notion – wählen Sie Ihren Favoriten.
- Formatierungstipps: Nutzen Sie Thunderbits Spaltentyp-Einstellungen (Zahl, Datum, Text) für saubere, analysierbare Daten.
- Workflow-Integration: Verbinden Sie Ihre exportierten Daten mit CRMs, Bestandssystemen oder Analyse-Dashboards.
- Zusammenarbeit: Teilen Sie Google Sheets oder Airtable-Basen mit Ihrem Team – alle arbeiten mit denselben aktuellen Daten.
Das Beste daran? Kein Hin- und Herschicken von Tabellen mehr und kein Rätselraten, ob Sie eine Zeile übersehen haben.
Häufige Stolperfallen beim PDF-Scraping und wie Sie sie vermeiden
Selbst mit den besten Tools können ein paar Fallstricke auftauchen. Das habe ich gelernt – manchmal auf die harte Tour:
- OCR-Fehler: Unscharfe Scans oder seltsame Schriftarten können selbst die beste OCR aus dem Tritt bringen. Nutzen Sie möglichst saubere PDFs und prüfen Sie kritische Felder doppelt.
- Komplexe Layouts: Mehrspaltige oder verschachtelte Tabellen brauchen manchmal etwas manuelle Führung – nutzen Sie Thunderbits manuelle Auswahl oder Prompts.
- Datentypen: Zahlen mit Kommas oder Daten in ungewöhnlichen Formaten? Legen Sie den Spaltentyp vor dem Export fest oder bereinigen Sie die Daten in Excel/Sheets.
- Dateigrößen- und Seitenlimits: Riesige PDFs? Teilen Sie sie in kleinere Abschnitte auf oder nutzen Sie Thunderbits Cloud-Modus für Batch-Jobs.
- KI-„Halluzinationen“: Selten, aber manchmal rät die KI einen Spaltennamen oder ergänzt fehlende Daten. Prüfen Sie die Ausgabe immer stichprobenartig, besonders bei wichtigen Zahlen.
- Manuelle Kontrolle: Bei geschäftskritischen Daten lohnt sich eine schnelle Validierung – automatisierte Tools sind genau, aber ein menschlicher Blick schadet nie.
Und wenn Sie feststecken, helfen Thunderbits Support und Community weiter.
Fazit und wichtigste Erkenntnisse: PDF-Scraping für Ihr Unternehmen nutzbar machen
Fassen wir zusammen. Daten aus PDFs zu scrapen war früher ein Albtraum – langsam, fehleranfällig und schlicht mühsam. Mit modernen Tools wie ist es heute schnell, genau und – ich wage es zu sagen – fast schon angenehm.
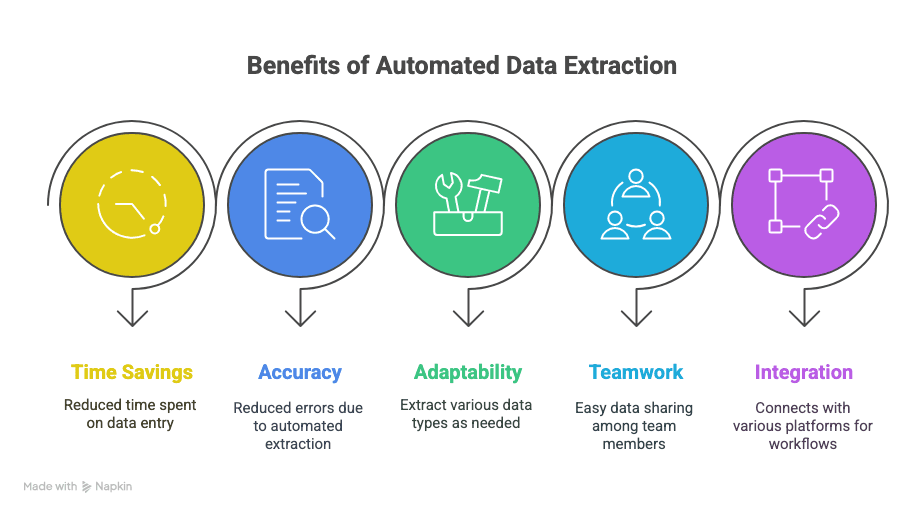
Das bekommen Sie:
- Mehr Zeit: Stunden oder sogar Wochen bei der manuellen Dateneingabe sparen.
- Weniger Fehler: Automatisierte Extraktion bedeutet weniger Tippfehler und weniger übersehene Zeilen.
- Flexibilität: Genau das extrahieren, was Sie brauchen – Text, Tabellen, Bilder, Links, was auch immer.
- Zusammenarbeit: Daten sofort mit Ihrem Team teilen, egal wo es sich befindet.
- Intelligentere Workflows: Mit Sheets, Notion, Airtable und mehr integrieren.
Bereit zum Ausprobieren? Laden Sie die herunter, lassen Sie sie bei Ihrem nächsten PDF laufen und sehen Sie, wie viel leichter das Leben sein kann. Ihr zukünftiges Ich – und Ihr Karpaltunnel – werden es Ihnen danken.
Für weitere Tipps und Anleitungen schauen Sie im vorbei oder tauchen Sie tiefer ein mit .
Machen wir aus PDF-Kopfschmerzen Produktivitätsgewinne – Klick für Klick.
Shuai Guan, Mitgründer & CEO, Thunderbit