
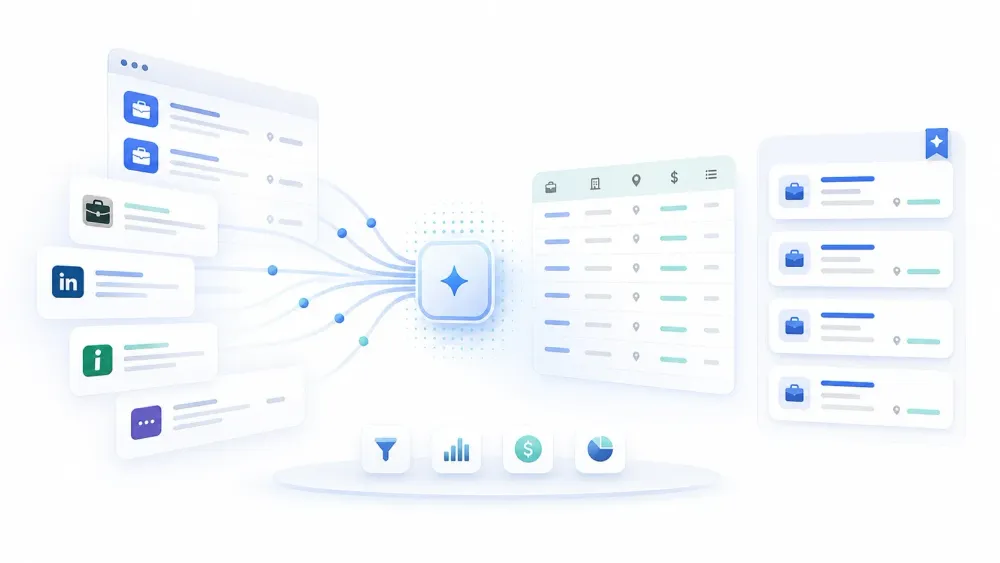
Wer den Stellenmarkt manuell im Blick behalten will, scheitert immer noch an denselben Hürden wie eh und je: zu viele Seiten, zu viele Formate, zu viel Copy-and-paste zwischen Jobbörsen, Karriereseiten und internen Trackern. Geändert hat sich 2026 vor allem, was HR- und Recruiting-Teams inzwischen erwarten: schnellere Benchmarks, sauberere Marktdaten und sofort verwertbare Informationen, die sich direkt mit Hiring Managern, Finance und Führung teilen lassen.
Genau hier hat Job-Scraping-Software ihren Wert bewiesen. Die besten Tools ziehen Stellenanzeigen nicht bloß in eine Tabelle. Sie helfen, unübersichtliche Felder zu vereinheitlichen, Daten nach Zeitplan zu aktualisieren, Rollen über mehrere Arbeitgeber hinweg zu vergleichen und von der reinen Sichtung in die Analyse zu wechseln, ohne auf das Engineering warten zu müssen. Ich entwickle Automatisierungsprodukte, darunter Thunderbit – entsprechend rückt dieses Update das in den Mittelpunkt, was in echten Recruiting-Workflows zählt: einfache Einrichtung, Abdeckung verschiedener Quellen, Exportoptionen, Automatisierungstiefe und wie viel Nacharbeit nach dem Scrape überhaupt noch anfällt.
Thunderbit für Job-Scraping testen
Was Job-Scraping-Software HR-Teams tatsächlich hilft zu tun
Job-Scraping-Software sammelt automatisch Stellenanzeigen von öffentlichen Jobbörsen, ATS-angebundenen Karriereseiten und unternehmenseigenen Recruiting-Seiten und verwandelt diese Einträge in strukturierte Zeilen, die Ihr Team sortieren, filtern, exportieren und vergleichen kann. Der praktische Nutzen liegt nicht in „mehr Daten“, sondern im schnellen Zugriff auf entscheidungsreife Daten.
Für HR-, Recruiting- und People-Ops-Teams heißt das meist:
- Wettbewerber-Hiring-Tracker ohne manuelle Tabellenarbeit aufbauen
- Jobtitel, Standorte, Gehaltsbänder und Skills über verschiedene Arbeitgeber hinweg benchmarken
- interne Datensätze für Personalplanung und Skills-Gap-Analysen erstellen
- Zielunternehmen oder bestimmte Rollen in regelmäßigen Abständen beobachten
- saubere Exporte an Sheets, Excel, Airtable, Notion oder interne Datenbanken übergeben
2026 helfen die stärksten Tools auch bei der Nachbearbeitung. Das kann bedeuten: uneinheitliche Feldbezeichnungen zusammenzuführen, lange Beschreibungen zu verdichten, mehrsprachige Einträge zu übersetzen oder Detailseiten automatisch aufzurufen, um Übersichtsseiten anzureichern.
So habe ich die besten Job-Scraping-Tools 2026 bewertet
Die Tools in dieser Liste wurden anhand von sieben praxisnahen Kriterien bewertet:
| Kriterium | Was es in der Praxis bedeutet |
|---|---|
| No-Code-Bedienbarkeit | HR- und Recruiting-Teams sollten einen Scrape starten können, ohne CSS-Selektoren, XPath oder eigene Skripte zu brauchen. |
| Quellenflexibilität | Das Tool sollte auf Jobbörsen, Karriereseiten von Unternehmen und benutzerdefinierten ATS-Layouts funktionieren, nicht nur auf einer engen Quelle. |
| Automatisierungstiefe | Pagination, Scraping von Unterseiten, Zeitplanung und Cloud-Runs sind für wiederkehrendes Markt-Tracking wichtig. |
| Aufwand für Datenbereinigung | Die besten Produkte reduzieren die Nacharbeit nach dem Export, indem sie Felder, Bezeichnungen oder Formatierungen standardisieren. |
| Export und Integrationen | Für viele Teams reicht CSV allein nicht aus; Sheets, Excel, APIs und Workflow-Tools sind wichtig. |
| Skalierung und Zuverlässigkeit | Kleine Einzelabrufe und größere wiederkehrende Sammlungen haben unterschiedliche Anforderungen, besonders auf dynamischen oder geschützten Seiten. |
| Passung fürs Team | Eine starke Entwicklerplattform ist nicht automatisch ein starkes HR-Workflow-Tool – und umgekehrt. |
Wer sich vor dem Produktvergleich einen schnellen visuellen Überblick wünscht, sieht in dieser Thunderbit-Demo den grundlegenden Ablauf „Seite öffnen, Felder erkennen, Zeilen exportieren“, der heute das einfache Ende dieser Kategorie markiert.
Kurzvergleich: 8 Job-Scraping-Tools auf einen Blick
| Tool | Worin es am besten ist | Am besten geeignet für | Preisübersicht (2026) | Wichtigste Einschränkung |
|---|---|---|---|---|
| Thunderbit | KI-Felderkennung und strukturierte Exporte von fast jeder Job-Seite | HR-Teams, Recruiter, Ops-Teams, die die schnellste No-Code-Einrichtung wollen | Kostenlose Stufe + kostenpflichtige Pläne | Nicht als vorbefüllte Job-Datenbank gebaut |
| Octoparse | Visuelles Scraping mit starker Vorlagenunterstützung und Cloud-Runs | Analysten und HR-Ops-Nutzer, die mehr Workflow-Kontrolle wollen | Kostenloser Plan; kostenpflichtig ab 69 $/Monat | Mehr Einrichtungsaufwand als KI-basierte Tools |
| Apify | Cloud-Skalierung mit Actors und API-gesteuertem Scraping | Teams mit technischer Unterstützung oder großem wiederkehrendem Scrape-Bedarf | Kostenloser Plan; Starter ab 29 $/Monat plus Nutzung | Für Entwickler besser geeignet als für gelegentliche Business-Nutzer |
| PhantomBuster | LinkedIn-zentrierte Automatisierung und Workflow-Verkettung | Recruiter mit Fokus auf LinkedIn-lastigem Sourcing | 14-tägige Testphase + Start/Grow/Scale-Pläne | Engerer Fit außerhalb von Social-Network-Workflows |
| Bright Data | Scraping-Infrastruktur auf Enterprise-Niveau und Anti-Blocking | Große Datenteams und Datenerfassung mit hohem Volumen | Pay-as-you-go ab 1,5 $ / 1.000 Datensätze | Technisch und für die meisten HR-Teams überdimensioniert |
| DataMiner | Schnelle browserbasierte Extraktion für kleine Einzelaufgaben | Kleine manuelle Abrufe durch nicht-technische Nutzer | Kostenpflichtig ab 19,99 $/Monat | Begrenzte Automatisierungstiefe für größere wiederkehrende Aufgaben |
| ParseHub | Desktop-gestütztes Point-and-Click-Scraping für interaktive Seiten | Nutzer, die für individuelle Abläufe einen Desktop-Builder bevorzugen | Kostenloser Plan; kostenpflichtig ab 189 $/Monat | Weniger KI-Unterstützung und eine steilere Lernkurve |
| Diffbot | KI-Extraktion von Seiten und größere Crawl-basierte Pipelines | Entwickler- und Analytics-Teams, die viele Quellen überwachen | Startup ab 299 $/Monat | API-first und teuer für einfache Recruiting-Use-Cases |
1. Thunderbit
Thunderbit ist das einfachste Tool dieser Liste für nicht-technische Teams, die schnell saubere Jobdaten brauchen. Der Workflow ist KI-gestützt: Jobseite öffnen, auf KI-Felder vorschlagen klicken, Spalten prüfen, scrapen. Das ist deshalb so praktisch, weil Karriereseiten kaum je derselben Struktur folgen. Eine Seite nennt einen Abschnitt „Anforderungen“, die nächste „Wonach wir suchen“, und eine dritte verteilt die relevanten Felder über Übersichts- und Detailseiten.
Thunderbits Vorteil liegt darin, dass es diese Unterschiede als Content-Problem versteht und nicht als Übung im Bau von Selektoren. Besonders stark spielt es seine Karten aus, wenn das Team ein Tool braucht, das gemischte Unternehmens-Karriereseiten, eigene ATS-Layouts, Stellenverzeichnisse und wiederholte Exporte nach Sheets oder Excel zugleich bedient.
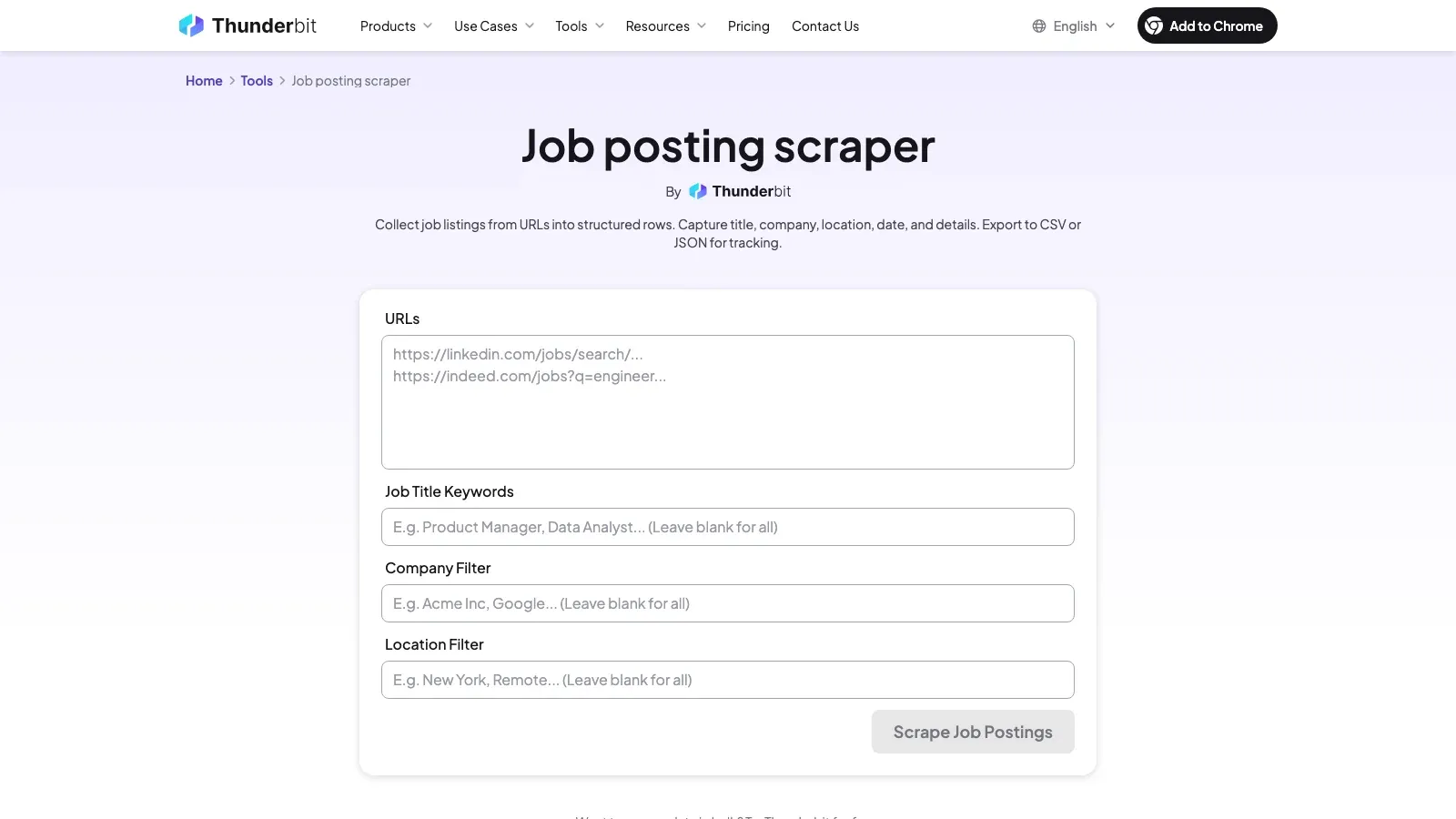
Warum Thunderbit herausragt
- KI-Feldvorschläge verkürzen die Einrichtungszeit für nicht-technische Teams deutlich.
- Scraping von Unterseiten verwandelt oberflächliche Einträge in vollständige strukturierte Datensätze.
- Die Nachbearbeitung kann Felder standardisieren, Beschreibungen verdichten und Inhalte übersetzen.
- Exporte nach Sheets, Excel, Airtable, Notion, CSV und JSON fügen sich gut in HR-Übergabeprozesse ein.
Preis: Kostenlose Stufe + kostenpflichtige Pläne.
Am besten für: HR-, Recruiting- und Ops-Teams, die den schnellsten No-Code-Workflow wollen.
Beachten Sie: Sie müssen trotzdem wissen, welche öffentlichen Seiten oder Karriereseiten Sie beobachten wollen.
2. Octoparse
Octoparse gehört weiterhin zu den stärksten visuellen Scraping-Tools für Nutzer, die mehr Kontrolle wollen, als ein vollständig KI-gestützter Ansatz bietet. Vorlagensystem, Point-and-Click-Builder und Cloud-Extraktion machen es nützlich für wiederkehrende Scraping-Projekte, die über einen schnellen Einzelexport hinausgehen.
Für Recruiting-Teams ist Octoparse vor allem dann attraktiv, wenn sie bereit sind, mehr Zeit in die Einrichtung zu stecken und dafür mehr Kontrolle über Pagination, dynamische Elemente und individuelle Workflows zu gewinnen.
Warum Octoparse herausragt
- Starker visueller Task-Builder für Nutzer, die den Workflow sehen und anpassen wollen.
- Gute Wahl für dynamische Websites und wiederkehrende geplante Jobs.
- Große Vorlagenbibliothek senkt die Einstiegskosten bei häufigen Quellen.
- Cloud-Runs ersparen Teams stundenlang laufende lokale Rechner.
Preis: Kostenloser Plan; kostenpflichtig ab 69 $/Monat.
Am besten für: HR-Ops und Analysten, die Kontrolle ohne Programmierung wollen.
Beachten Sie: Die Konfiguration dauert meist länger als bei Tools, die Felder automatisch erkennen.
Dieses Octoparse-Tutorial lohnt sich, wenn Sie die stärker vorlagengetriebene, visuelle Builder-Seite des Job-Scrapings kennenlernen wollen, bevor Sie sich festlegen.
3. Apify
Apify spielt in einem anderen Segment. Es ist nicht bloß ein No-Code-Scraper, sondern eine Plattform für Cloud-Actors, APIs und größere Automatisierungspipelines. Das macht es flexibel und leistungsstark, vor allem wenn Teams viele Quellen im großen Maßstab scrapen oder Ergebnisse in einen breiteren Daten-Workflow einbinden müssen.
Beim Job-Scraping liegt der Kernvorteil im Zugriff auf vorgefertigte Actors sowie in der Möglichkeit, eigene Logik zu bauen, sobald eine Zielquelle oder ein Workflow komplexer wird.

Warum Apify herausragt
- Starkes Ökosystem vorgefertigter Actors für gängige Scraping-Muster.
- Cloud-first-Architektur unterstützt Zeitplanung, parallele Runs und API-Auslieferung.
- Mehr Spielraum für Skalierung als leichte Browser-Erweiterungen.
- Gute Wahl, wenn Recruiting-Daten in Engineering- oder BI-Workflows einfließen sollen.
Preis: Kostenloser Plan; Starter ab 29 $/Monat plus Nutzung.
Am besten für: Teams mit technischer Unterstützung, wiederkehrenden Jobs oder größeren Datenoperationen.
Beachten Sie: Es ist eher eine Plattform als ein Einzelwerkzeug und kann sich für einfache HR-Use-Cases überdimensioniert anfühlen.
4. PhantomBuster
PhantomBuster ist die Spezialistenwahl für LinkedIn-zentrierte Workflows. Bekannt ist das Tool vor allem dafür, wiederholbare Aktionen in sozialen und beruflichen Netzwerken zu automatisieren – und genau das nützt Recruitern, deren Sourcing-Prozess öfter auf LinkedIn beginnt und endet als auf allgemeinen Jobbörsen.
Seine Stärke liegt nicht in breiter Website-Abdeckung, sondern in der Automatisierung bestimmter unterstützter Workflows und im Verketten einzelner Jobs.
Warum PhantomBuster herausragt
- Zweckgebundene Automatisierungs-Workflows für Recruiting-Prozesse mit starkem LinkedIn-Bezug.
- Nützliche Zeitplanung und Verkettung für wiederkehrende Sourcing-Aufgaben.
- No-Code-Formulare machen die Einrichtung gut zugänglich.
- Kostenpflichtige Pläne enthalten API-Zugang und unbegrenzten CSV-/JSON-Export.
Preis: 14-tägige Testphase und kostenpflichtige Start/Grow/Scale-Pläne.
Am besten für: Recruiter und Growth-Teams, die in LinkedIn-Workflows arbeiten.
Beachten Sie: Braucht Ihr Team breites Multi-Site-Scraping jenseits der unterstützten Automationen, wird der Fit eng.
5. Bright Data
Bright Data ist die Wahl für Enterprise-Infrastruktur. Wo Thunderbit die schnelle No-Code-Option und Octoparse der visuelle Builder ist, da ist Bright Data die Plattform für Organisationen, denen vor allem Volumen, Anti-Blocking-Systeme, Proxy-Infrastruktur und programmgesteuerte Auslieferung wichtig sind.
Beim Job-Scraping macht das das Tool für größere Datenteams sehr leistungsstark, aber meist zu technisch für ein eigenständiges HR-Team, das schlicht besseres Wettbewerber-Tracking und sauberere Job-Exporte will.
Warum Bright Data herausragt
- Gebaut für Datenerfassung im großen Maßstab über schwierige oder geschützte Seiten hinweg.
- Starke Proxy- und Anti-Blocking-Infrastruktur.
- Die Web Scraper API unterstützt Batch-Jobs, Echtzeit-Erfassung und strukturierte Ausgaben.
- Besser geeignet als leichte Tools, wenn Skalierung und Zuverlässigkeit im Vordergrund stehen.
Preis: Pay-as-you-go ab 1,5 $ / 1.000 Datensätze; Scale-Pläne ab 499 $/Monat.
Am besten für: Enterprise-Datenteams und fortgeschrittene Operations-Gruppen.
Beachten Sie: Für die meisten Recruiting-Teams ist es sowohl bei Komplexität als auch bei den Kosten überdimensioniert.
6. DataMiner
DataMiner ist die pragmatische, leichte Option. Es läuft als Browser-Erweiterung und ist hilfreich, wenn jemand eine gerade geöffnete Seite schnell scrapen muss, ohne dafür ein großes automatisiertes System aufzubauen.
Das macht es attraktiv für einmalige Recruiting-Recherchen, kleine Monitoring-Aufgaben oder schnelle Exporte von Seiten, die ohnehin schon im Browser offen sind.
Warum DataMiner herausragt
- Sehr zugänglich für schnelle, browsernahe Extraktionen.
- Das Rezept-Modell eignet sich gut für wiederkehrende einfache Aufgaben.
- Einfache CSV- und tabellenorientierte Exporte.
- Niedrigere Einstiegskosten als bei vielen schwereren Plattformen.
Preis: Kostenpflichtig ab 19,99 $/Monat.
Am besten für: Kleine Teams und schnelle manuelle Aufgaben.
Beachten Sie: Für große geplante Pipelines über mehrere Quellen hinweg ist es nicht die beste Wahl.
7. ParseHub
ParseHub spricht weiterhin Nutzer an, die eine Desktop-App mögen und sich an einem etwas handfesteren Einrichtungsprozess nicht stören. Es bewältigt interaktive Seiten und individuellere Logik besser als einfache Point-and-Click-Browser-Tools, nimmt aber nicht so viel Einrichtungsaufwand ab wie neuere AI-first-Produkte.
Für Job-Scraping-Teams ist ParseHub vor allem dann nützlich, wenn ein maßgeschneiderter Workflow wichtiger ist als Einfachheit und das Team bereit ist, Zeit in einen sauberen Aufbau zu investieren.
Warum ParseHub herausragt
- Starker Point-and-Click-Builder für interaktive Seiten.
- Der Desktop-Workflow passt zu Nutzern, die eine eigene Projektumgebung wollen.
- Unterstützt Zeitplanung und Premium-Funktionen in kostenpflichtigen Tarifen.
- Nützlich, wenn die Zielwebsite komplexere Scraping-Logik verlangt.
Preis: Kostenloser Plan; kostenpflichtig ab 189 $/Monat.
Am besten für: Nutzer, die Einfachheit gegen individuelle Kontrolle tauschen wollen.
Beachten Sie: Die Lernkurve ist steiler und die KI-Unterstützung begrenzt.
8. Diffbot
Diffbot ist in diesem Vergleich die API-first-Option. Das Prinzip: Sie geben eine URL oder ein größeres Crawl-Ziel vor, und die KI übernimmt Extraktion und Strukturierung der Seite. Das ist stark, wenn Teams maschinenlesbare Jobdaten aus vielen Quellen brauchen, ohne jedes Mal manuell Regeln pro Website zu schreiben.
Für die meisten HR-Teams liegt der Haken auf der Hand: Diffbot ist preislich und strategisch eher als Infrastruktur positioniert denn als schlichtes Business-Tool.
Warum Diffbot herausragt
- Starke automatische Extraktion strukturierter Jobdaten auf Seitenebene.
- Besser als viele leichtere Tools, wenn Teams API-nativen Output wollen.
- Nützlich in größeren Monitoring- oder Analytics-Pipelines über viele Quellen hinweg.
- Reduziert einen Teil des Pflegeaufwands für Regeln pro Website.
Preis: Startup-Tarif ab 299 $/Monat.
Am besten für: Analytics-, Engineering- und Teams mit groß angelegtem Monitoring.
Beachten Sie: Teuer und für kleinere HR-Workflows nicht erforderlich.
Welches Job-Scraping-Tool passt am besten zu Ihrem Team?
Verschiedene Tools lösen verschiedene Aufgaben. Der häufigste Käuferfehler ist die Annahme, jedes Produkt dieser Kategorie ließe sich am gleichen Maßstab messen.
| Wenn Ihr Team Folgendes braucht... | Beste Wahl | Warum |
|---|---|---|
| Die schnellste No-Code-Methode, um Stellenanzeigen aus gemischten Quellen zu scrapen | Thunderbit | KI-Felderkennung und starke Exportoptionen reduzieren Einrichtungs- und Nacharbeit. |
| Einen visuellen Builder mit mehr direkter Kontrolle | Octoparse | Besser, wenn das Team Workflows, Pagination und Cloud-Runs direkt anpassen möchte. |
| Skalierbares Scraping mit APIs und Automatisierungen | Apify | Starkes Actor-Ökosystem und bessere Cloud-Architektur für größere wiederkehrende Jobs. |
| Sourcing-Automatisierung mit Fokus auf LinkedIn | PhantomBuster | Am besten, wenn Recruiting-Arbeit eng an LinkedIn-unterstützte Automationen gebunden ist. |
| Enterprise-Erfassung mit hohem Volumen und Anti-Blocking-Infrastruktur | Bright Data | Für Skalierung, Proxys und Zuverlässigkeit gebaut, nicht für Einfachheit. |
| Schnelle Einzelabrufe im Browser | DataMiner | Einfache Erweiterungs-Workflows mit geringem Einrichtungsaufwand. |
| Einen Desktop-Point-and-Click-Scraper für individuelle Projekte | ParseHub | Besser für Nutzer, die einen eigenen Projekt-Builder und individuelle Logik bevorzugen. |
| API-first-Seitenauslesung über viele Websites hinweg | Diffbot | Am besten für entwicklungsgetriebene Extraktion und größere Analytics-Pipelines. |
Wenn Ihre Bewertung von leichter Recruiting-Recherche zu groß angelegter, wiederkehrender Datenerfassung übergeht, zeigt dieses Bright-Data-Video den stärker infrastrukturgetriebenen Marktbereich.
Was Sie vor dem Kauf prüfen sollten
Bevor Sie sich für ein Tool entscheiden, halten Sie diese vier Fragen hart dagegen:
- Wie viele Quellen zählen wirklich? Braucht das Team nur fünf oder zehn wiederkehrende Seiten, kann ein No-Code-Tool reichen. Geht es um Hunderte, wird die Plattformarchitektur entscheidend.
- Wer übernimmt den Workflow? Recruiter, HR-Ops-Analyst, Rev-Ops-Partner oder Entwickler brauchen jeweils ein anderes Maß an Kontrolle.
- Wie viel Nacharbeit ist akzeptabel? Manche Produkte sparen beim Erfassen Zeit und verschieben das Chaos in die Nachbearbeitung. Andere erledigen mehr Bereinigung vorab.
- Brauchen Sie einmalige Exporte oder einen dauerhaft laufenden Tracker? Für Ad-hoc-Recherche genügen manuelle Tools. Wiederkehrendes Wettbewerber-Monitoring verlangt Zeitplanung und Zuverlässigkeit.
Nehmen Sie auch Compliance ernst. Öffentlich heißt nicht automatisch unbeschränkt nutzbar. Ihr Team muss die Nutzungsbedingungen der Zielseite, datenschutzrechtliche Pflichten – in der EU die DSGVO – und interne Governance-Regeln zur Verwendung gescrapter Recruiting-Daten einhalten.
Fazit
Für die meisten HR- und Recruiting-Teams ist Thunderbit der stärkste Startpunkt, weil es mit dem geringsten technischen Aufwand am schnellsten zu nutzbaren Daten führt. Es passt am besten zu Teams, die Jobseiten in strukturierte Exporte verwandeln wollen, ohne Scraping-Logik von Hand zu bauen.
Octoparse und ParseHub passen besser, wenn das Team mehr direkte Kontrolle über den Aufbau des Workflows möchte. Apify, Bright Data und Diffbot ergeben mehr Sinn, sobald technische Unterstützung, APIs oder Skalierungsanforderungen ohnehin zum Projekt gehören. PhantomBuster ist der enge Spezialist für LinkedIn-getriebene Workflows, und DataMiner die leichte Option für schnelle manuelle Abrufe.
Die praktische Frage lautet nicht: „Welches Tool ist abstrakt am leistungsstärksten?“ Sondern: „Welches Tool bringt mein Team mit der geringsten Reibung von Jobseiten zu einem sauberen, wiederholbaren Marktdatensatz?“ Für die meisten Business-Anwender spricht die Antwort weiterhin für Einfachheit, gute Bereinigungsqualität und einfache Exporte statt für rohe technische Bandbreite.
Wenn Sie als nächsten Schritt tiefer einsteigen möchten, sind diese Folgeartikel besonders relevant:
- So scrapen Sie Stellenanzeigen mit KI
- Die besten Web-Scraping-Tools
- Daten von Websites nach Excel scrapen
Thunderbit AI Job Scraper kostenlos testen Get Started Free
FAQs
1. Was ist Job-Scraping-Software?
Job-Scraping-Software sammelt öffentliche Stellenanzeigen von Websites und wandelt sie in strukturierte Daten um, die Ihr Team exportieren, filtern, vergleichen und analysieren kann.
2. Warum sind KI-Job-Scraping-Tools heute nützlicher als ältere Scraper?
Die besseren Produkte reduzieren heute Einrichtungs- und Nacharbeit, indem sie Felder automatisch erkennen, uneinheitliche Bezeichnungen standardisieren und bei Zusammenfassungen, Übersetzungen oder der Extraktion von Folgeseiten helfen.
3. Welches Tool ist am besten für nicht-technische HR-Teams?
Thunderbit ist für die meisten nicht-technischen Teams der einfachste Einstieg, weil es Felder per KI vorschlägt und über viele verschiedene Seitenlayouts hinweg ohne manuelle Selektoren funktioniert.
4. Welches Tool ist am besten für größere technische oder Enterprise-Teams?
Apify, Bright Data und Diffbot sind die stärkeren Optionen, wenn das Team APIs, größere wiederkehrende Pipelines oder eine stärker infrastrukturgetriebene Datenerfassung braucht.
5. Ist Scraping mit Fokus auf LinkedIn dasselbe wie allgemeines Job-Scraping?
Nein. LinkedIn-spezifische Tools wie PhantomBuster sind am stärksten, wenn der Workflow an diese Plattform gebunden ist, während breitere Produkte wie Thunderbit, Octoparse, Apify, Bright Data, ParseHub und Diffbot besser für Markttracking aus mehreren Quellen geeignet sind.




