
Hand aufs Herz: Wenn du im Vertrieb, Marketing, E-Commerce oder in der Unternehmensorganisation unterwegs bist, bist du mit Web-Scraping bestimmt schon mal in Kontakt gekommen – oder nutzt es vielleicht sogar, um neue Leads zu finden, die Konkurrenz im Blick zu behalten oder dir die mühsame Dateneingabe zu sparen. Nach vielen Jahren in der SaaS- und Automatisierungswelt kann ich sagen: Web-Scraping ist heute überall. Tatsächlich kam von Bots – darunter auch Web-Scraper. Aber die Frage, die mir am häufigsten gestellt wird, ist: Ist Web-Scraping eigentlich legal?
Die Antwort darauf: Es kommt darauf an. (Klingt nach typischer Juristensprache, oder?) Aber bleib dran, denn die Sache ist wirklich vielschichtig. Ob Web-Scraping erlaubt ist oder nicht, hängt davon ab, wo du dich befindest, welche Daten du sammelst, wie du dabei vorgehst und wofür du die Daten nutzen willst. Lass uns das Thema gemeinsam aufdröseln, damit du rechtssicher und entspannt scrapen kannst.
Was ist Web-Scraping? Einfach erklärt für Unternehmen
Web-Scraping heißt nichts anderes als „automatisiertes Sammeln von Daten aus dem Internet“. Stell dir einen Super-Praktikanten vor, der tausende Webseiten abklappert, gezielt Infos wie Kontakte, Preise oder Produktdaten raussucht und alles ordentlich in eine Tabelle packt. Genau das macht Web-Scraping – nur eben digital und viel schneller.
Tools wie (ja, ein bisschen Eigenwerbung – aber wir haben es speziell für Business-Anwender gebaut) machen Web-Scraping für alle zugänglich. Du musst weder coden noch dich mit komplizierten Einstellungen rumschlagen. Mit Thunderbit wählst du einfach aus, was du brauchst, und die KI schlägt dir vor, welche Daten du extrahieren kannst. Es ist wie ein persönlicher Datenassistent – nur ohne Krawatte.
Welche Daten kann man scrapen?
- Kontaktdaten (E-Mails, Telefonnummern)
- Produktinfos und Preise
- Bewertungen und Rezensionen
- Nachrichtenartikel, Stellenanzeigen, Immobiliendaten
- Bilder, PDFs und vieles mehr
Und ja, du kannst alles direkt nach Excel, Google Sheets, Airtable oder Notion exportieren. Wenn du tiefer einsteigen willst, schau dir unseren an.
Warum Unternehmen Web-Scraping-Tools nutzen
Mal ehrlich: Niemand hat wirklich Lust auf manuelle Dateneingabe. (Falls doch, melde dich – ich hätte da ein paar Tabellen für dich.) Aber Web-Scraping spart nicht nur Zeit, sondern bringt echten Mehrwert fürs Business. So setzen Unternehmen Web-Scraping-Tools heute ein:
| Business-Ziel | Web-Scraping-Anwendungsfall |
|---|---|
| Vertriebspipeline aufbauen | Verzeichnisse oder LinkedIn nach Leads durchsuchen – Namen, E-Mails, Telefonnummern – für gezielte Ansprache. |
| Wettbewerbsfähige Preisgestaltung | Preise und Lagerbestände der Konkurrenz überwachen, um die eigene Preisstrategie in Echtzeit anzupassen. |
| Markttrends analysieren | Bewertungen, Social-Media-Posts oder Forenbeiträge sammeln, um Trends zu erkennen und Produktentscheidungen zu treffen. |
| Compliance & Due Diligence | Öffentliche Register oder Watchlists für KYC, Risikomanagement oder regulatorische Anforderungen durchsuchen. |
| Content-Aggregation | Angebote oder Nachrichten aus verschiedenen Quellen in einem Dashboard bündeln (z. B. Immobilien, Reisen, Jobs). |
Das Beste daran: Mit Tools wie Thunderbit können auch Teams ohne IT-Know-how in wenigen Minuten eigene Scraper aufsetzen. Du musst nicht mehr auf die IT warten oder extra Entwickler beauftragen, nur um eine Lead-Liste zu bekommen.
Ist Web-Scraping legal? Die kurze Antwort: Es kommt darauf an
Ganz ehrlich: Web-Scraping ist nicht grundsätzlich verboten, aber auch nicht immer erlaubt. Es ist ein Werkzeug – wie ein Hammer. Du kannst damit ein Haus bauen oder ein Fenster einschlagen. Die Legalität hängt ab von:
- Rechtsraum: In welchem Land bist du und wo steht die Website?
- Zweck: Nutzt du das Scraping für geschäftliche, wissenschaftliche oder private Zwecke?
- Website-Bedingungen: Was steht in den Nutzungsbedingungen (ToS) der Seite?
- Art der Daten: Sind die Daten öffentlich, privat, urheberrechtlich geschützt oder personenbezogen?
Hier eine praktische Übersicht:
| Scraping-Szenario | Rechtliche Einschätzung (allgemein) |
|---|---|
| Öffentlich zugängliche Daten (ohne Login) | In den USA meist erlaubt – aber Urheber- und Datenschutz beachten. |
| Daten hinter Login oder Bezahlschranke (ohne Erlaubnis) | Hohes Risiko – oft illegal (Verstoß gegen Anti-Hacking-Gesetze). |
| Ignorieren von ToS, die Scraping verbieten | Riskant – kann Vertragsbruch sein (zivilrechtlich, aber trotzdem unangenehm). |
| Urheberrechtlich geschützte Inhalte scrapen und veröffentlichen | Meist illegal – außer mit Erlaubnis oder im Rahmen von „Fair Use“ (z. B. Forschung). |
| Personenbezogene Daten für kommerzielle Zwecke scrapen | Stark reguliert – besonders in der EU (DSGVO). |
| Verwendung gescrapter Daten für Spam oder Diskriminierung | Illegal und unethisch – Finger weg. |
Die Antwort auf „Ist Data Scraping legal?“ ist also: Es kommt auf die Details an. Schauen wir uns das genauer an.
Wichtige rechtliche Faktoren beim Web-Scraping
1. Öffentlich zugängliche vs. private Daten
Das ist der Knackpunkt. Das Scrapen von öffentlich zugänglichen Daten – also Infos, die jeder ohne Login oder Umwege sehen kann – ist meist rechtlich unproblematisch, vor allem in den USA. Gerichte haben zum Beispiel entschieden, dass das Scrapen öffentlicher LinkedIn-Profile kein „Hacking“ ist ().
Anders sieht es aus, wenn du Daten hinter einem Login, einer Bezahlschranke oder technischen Hürden (wie CAPTCHA) scrapen willst. Das kann als unbefugter Zugriff gewertet werden – vergleichbar mit dem Betreten des Backstage-Bereichs eines Konzerts, obwohl du nur ein normales Ticket hast.
2. Nutzungsbedingungen (ToS) der Website
Viele Websites verbieten Scraping ausdrücklich in ihren ToS. Wer diese Bedingungen ignoriert – vor allem, wenn man aktiv „Ich stimme zu“ geklickt hat – riskiert eine Vertragsverletzung. Auch ohne Registrierung können Gerichte klar formulierte Nutzungsbedingungen durchsetzen.
3. Absicht und Zweck (kommerziell vs. privat)
Scrapst du für eigene Recherchen oder um ein Konkurrenzprodukt zu bauen? Kommerzielles Scraping wird strenger bewertet. Nicht-kommerzielle, wissenschaftliche oder journalistische Zwecke werden oft großzügiger behandelt, vor allem wenn sie dem öffentlichen Interesse dienen oder einen Mehrwert schaffen.
4. Art der Daten (Urheberrecht, Datenschutz, Sensibilität)
Nicht alle Daten sind gleich. Das Scrapen von Fakten (wie Preisen oder Produktnamen) ist meist unproblematisch. Bei urheberrechtlich geschützten Artikeln, Bildern oder personenbezogenen Daten (Namen, E-Mails, Fotos) greifen Urheber- und Datenschutzgesetze – besonders in der EU.
5. Technische Umsetzung
Wer schonend und wie ein normaler Nutzer scrapt, hat weniger Ärger zu befürchten. Wer aber eine Website mit tausenden Anfragen pro Sekunde bombardiert oder Sicherheitsmechanismen umgeht, kann sich schnell dem Vorwurf des „Hausfriedensbruchs“ oder des Umgehens technischer Schutzmaßnahmen aussetzen.
Öffentliche vs. eingeschränkte Daten: Wo liegt der Unterschied?
Kurz gesagt:
- Öffentliche Daten: Alles, was du ohne Login, Bezahlung oder Tricks auf einer Website sehen kannst. Zum Beispiel öffentliche Stellenanzeigen, Produktseiten oder staatliche Datenbanken.
- Eingeschränkte Daten: Alles, was hinter einem Login, einer Bezahlschranke oder technischen Barrieren liegt. Sobald ein Passwort nötig ist, gilt es als eingeschränkt.
Beispiel:
- Öffentliche Immobilienanzeigen scrapen? In der Regel kein Problem.
- Mitgliederverzeichnisse oder private Facebook-Gruppen scrapen? Riskant.
Gerichte machen diesen Unterschied klar. Im Fall hiQ v. LinkedIn wurde das Scrapen öffentlicher Profile als legal eingestuft, das Scrapen privater Daten (hinter Logins) jedoch nicht ().
Nutzungsbedingungen: Warum du vor dem Scrapen das Kleingedruckte lesen solltest
Ich weiß, AGBs liest niemand gern. Aber die ToS können über Erfolg oder Misserfolg deines Scraping-Projekts entscheiden. Viele Seiten verbieten Scraping oder automatisierten Zugriff ausdrücklich. Wer dagegen verstößt, riskiert:
- Kontosperrungen oder IP-Blockaden
- Abmahnungen oder Unterlassungserklärungen
- Klagen wegen Vertragsverletzung
Tipp:
- Suche nach Formulierungen wie „kein Scraping“ oder „kein automatisierter Zugriff“.
- Gibt es eine offizielle API? Nutze sie – das ist meist erlaubt.
- Im Zweifel: Frag nach. Ein höfliches Nachfragen öffnet manchmal Türen.
Kommerziell vs. privat: Macht der Zweck einen Unterschied?
Definitiv. Wer für private Recherchen oder wissenschaftliche Zwecke scrapt, hat meist mehr Spielraum (und ein geringeres Risiko, verklagt zu werden). Gerichte und Behörden sind nachsichtiger, wenn das Scraping dem Gemeinwohl dient oder nicht-kommerziell ist.
Wer jedoch für kommerzielle Zwecke scrapt – etwa um ein Konkurrenzprodukt zu bauen oder Daten weiterzuverkaufen – muss mit rechtlichen Konsequenzen rechnen. Unternehmen schützen ihre Daten und setzen sowohl rechtliche als auch technische Mittel ein, um Scraper zu stoppen.
Fazit:
- Kommerzielles Scraping = höheres Risiko
- Privates/wissenschaftliches Scraping = geringeres Risiko, aber kein Freifahrtschein
Internationaler Vergleich: Wie unterscheiden sich die Gesetze zum Web-Scraping?
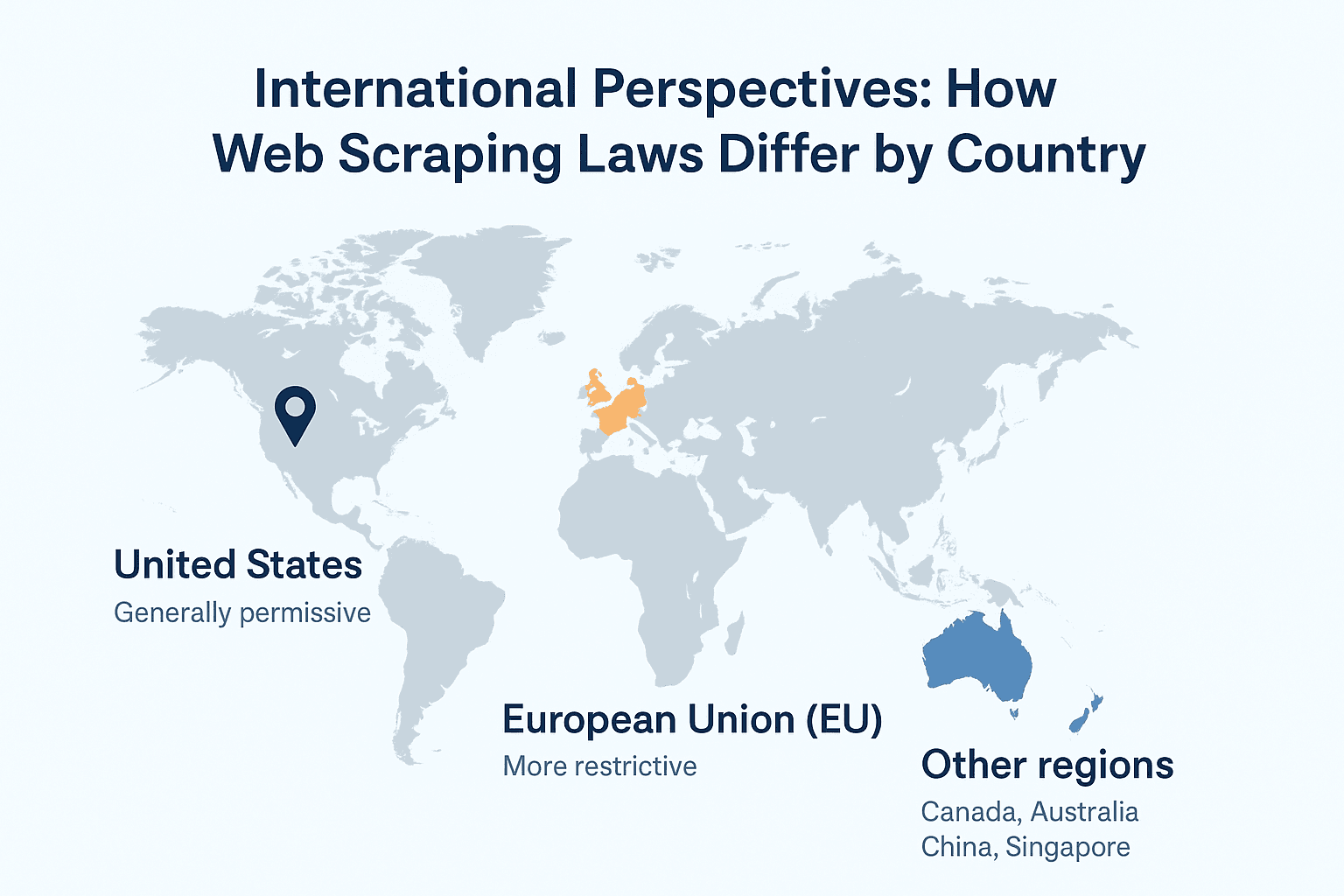
Hier wird’s spannend: Die Rechtslage zum Web-Scraping ist weltweit sehr unterschiedlich.
USA
- Grundsätzlich erlaubt, wenn es um öffentliche Daten geht.
- Anti-Hacking-Gesetze (CFAA) greifen, wenn Logins oder technische Barrieren umgangen werden.
- Datenschutzgesetze sind lückenhaft – auf bundesstaatliche Regelungen achten (z. B. Illinois Biometrie-Gesetz).
Europäische Union
- Deutlich strenger, vor allem bei personenbezogenen Daten.
- sieht das Scrapen personenbezogener Daten (auch wenn sie öffentlich sind) als „Verarbeitung“ – meist ist eine Rechtsgrundlage oder Einwilligung nötig.
- Datenbankrechte können das Scrapen großer strukturierter Datenmengen zusätzlich einschränken.
Weitere Regionen
- Kanada und Australien: Datenschutzgesetze gelten für personenbezogene Daten.
- Asien: Sehr unterschiedlich – Japan ist eher offen, China sehr restriktiv, Singapur stellt großflächiges, unbefugtes Scraping unter Strafe.
Wer Daten aus dem Ausland scrapt, sollte sich unbedingt rechtlich beraten lassen. Die Strafen – vor allem in der EU – können empfindlich sein.
Best Practices: So nutzt du Web-Scraping-Tools rechtssicher und verantwortungsvoll
Du willst auf Nummer sicher gehen? Hier meine Checkliste für verantwortungsvolles Web-Scraping:
- ToS lesen: Schau dir immer die Regeln der Website an, bevor du scrapest.
- Nur öffentliche Daten scrapen: Wenn ein Login nötig ist, lieber zweimal überlegen.
- Anfragen drosseln: Überlaste die Website nicht – scrape in menschlichem Tempo.
- Personenbezogene Daten vermeiden: Vor allem ohne Einwilligung. Falls nötig, anonymisieren und aggregieren.
- Gescrapte Daten nicht einfach weiterveröffentlichen oder verkaufen: Füge Mehrwert hinzu, transformiere die Daten oder hol dir eine Erlaubnis.
- Offizielle APIs nutzen, wenn vorhanden: Sie sind genau dafür gedacht.
- Protokoll führen: Dokumentiere deine Scraping-Aktivitäten für den Fall von Rückfragen.
- Auf dem Laufenden bleiben: Gesetze ändern sich – behalte neue Regelungen und Urteile im Blick.
- Bei großen oder sensiblen Projekten einen Anwalt fragen: Besonders bei großem Umfang oder in regulierten Branchen.
Und vor allem: Scrape mit Verantwortung. Nur weil es technisch geht, ist es nicht immer richtig.
Thunderbit und rechtssicheres Web-Scraping: So unterstützt unser Tool die Compliance

Bei haben wir unsere mit Fokus auf Rechtssicherheit und Ethik entwickelt. So helfen wir dir, auf der sicheren Seite zu bleiben:
- Fokus auf öffentliche Daten: Thunderbit ist darauf ausgelegt, nur das zu scrapen, was du im Browser siehst – kein Hacking, kein Umgehen von Logins.
- Nutzerhinweise: Wir erinnern dich daran, die ToS zu prüfen und keine eingeschränkten oder personenbezogenen Daten zu scrapen. Bei Seiten mit strengen Regeln bekommst du eine Warnung.
- Menschliches Scraping: Da Thunderbit im Browser läuft, passiert das Scraping in natürlicher Geschwindigkeit – das senkt das Risiko von Sperren oder Serverüberlastung.
- Individuelle Einstellungen: Du bestimmst, welche Daten gesammelt werden, wie oft und wohin sie exportiert werden. Das sorgt für Datensparsamkeit und Transparenz.
- Datenschutz und Sicherheit: Deine gescrapten Daten bleiben bei dir. Wir speichern oder nutzen deine Daten nicht – sie gehören dir.
- Compliance-Features: Unsere Vorlagen für beliebte Websites sind so konfiguriert, dass sie die jeweiligen Regeln und Best Practices beachten.
- Wissensvermittlung: Wir veröffentlichen regelmäßig zu rechtssicherem und ethischem Scraping, damit du immer auf dem neuesten Stand bist.
Wir ersetzen keine Rechtsberatung, aber wir tun unser Bestes, um dich verantwortungsvoll zu unterstützen. Bei Unsicherheiten empfehlen wir immer, einen Experten zu Rate zu ziehen – vor allem bei großen oder sensiblen Projekten.
Fazit: Das Wichtigste für Unternehmen auf einen Blick
Kurz und knapp:
- Web-Scraping ist nicht grundsätzlich illegal – aber auch nicht immer erlaubt. Es kommt auf Land, Datenart, Vorgehen und Zweck an.
- Das Scrapen öffentlicher Daten ist meist erlaubt, vor allem in den USA – aber Urheberrecht, Datenschutz und Website-Regeln müssen beachtet werden.
- Kommerzielles Scraping birgt mehr Risiken als private oder wissenschaftliche Nutzung.
- Die Rechtslage ist international unterschiedlich – besonders die EU hat strenge Vorgaben für personenbezogene Daten.
- Best Practices sind entscheidend: ToS lesen, nur öffentliche Daten scrapen, Anfragen drosseln und sensible Daten meiden.
- Thunderbit ist für verantwortungsvolles Scraping entwickelt, mit Funktionen und Hinweisen für rechtssicheres Arbeiten.
Kurz gesagt: Scrape mit Bedacht, ethisch und hol dir im Zweifel Rat. Richtig eingesetzt, ist Web-Scraping ein starkes Werkzeug für dein Unternehmen – ganz ohne rechtliche Probleme.
Du willst mehr über Web-Scraping, Compliance und Automatisierung wissen? Lies unseren oder probiere direkt aus. Wenn du sofort loslegen willst, hol dir unsere und erlebe, wie einfach und rechtssicher Datensammlung sein kann.
FAQ: Web-Scraping & Recht
-
Ist es legal, öffentliche Websites zu scrapen?
Manchmal. Öffentlich heißt nicht automatisch frei verfügbar. In den USA ist das Scrapen öffentlicher Daten meist erlaubt, aber prüfe die Nutzungsbedingungen, vermeide personenbezogene Daten und veröffentliche keine urheberrechtlich geschützten Inhalte weiter.
-
Was ist das größte rechtliche Risiko?
Das Scrapen von privaten Daten, das Ignorieren von ToS oder die Nutzung gescrapter personenbezogener Daten für geschäftliche Zwecke ohne Einwilligung – besonders in der EU unter der DSGVO.
-
Darf ich LinkedIn oder Amazon scrapen?
Vielleicht. Das Scrapen von LinkedIn wurde vor Gericht bestätigt (hiQ-Fall), aber LinkedIn blockiert es weiterhin. Amazon erlaubt das Scrapen einiger Daten, kann Bots aber einschränken. Immer die ToS prüfen.
-
Wie unterstützt Thunderbit die Compliance?
Thunderbit:
- Scrapt nur sichtbare, öffentliche Daten
- Läuft im Browser (keine Server-Bots)
- Warnt bei ToS-Problemen
- Hält deine Daten privat