
Das Internet wächst in einem Tempo, bei dem einem fast schwindelig wird. 2024 gibt es über 1,1 Milliarden Websites und 149 Zettabyte an Daten, die durchs Netz geistern – im nächsten Jahr werden es voraussichtlich schon 181 ZB sein. Eine kaum vorstellbare Menge an digitalen Inhalten. Der Haken: Nur rund 4 % aller Online-Inhalte werden von Suchmaschinen indexiert. Der Rest verbirgt sich im sogenannten „Deep Web“ und bleibt für normale Suchanfragen unsichtbar. Wie behalten Suchmaschinen und Unternehmen in diesem Datendschungel den Überblick? Genau hier kommen Web-Crawler ins Spiel.
In diesem Guide geht es darum, was Web Crawling eigentlich ist, wie es funktioniert und warum es nicht nur für Technik-Nerds spannend ist, sondern für alle, die das Potenzial von Online-Daten ausschöpfen wollen. Außerdem klären wir, worin sich Web Crawling und Web Scraping unterscheiden (Spoiler: Das ist nicht dasselbe!), schauen uns Praxisbeispiele an und werfen einen Blick auf Lösungen mit und ohne Programmierkenntnisse – inklusive meinem Favoriten Thunderbit. Egal, ob du gerade erst einsteigst oder als Unternehmen mehr aus dem Web herausholen willst – hier bist du richtig.
Was ist ein Web-Crawler? Die Basics des Web Crawling
Ganz einfach erklärt: Ein Web-Crawler (auch Spider, Bot oder Website-Crawler genannt) ist ein automatisiertes Programm, das das Internet systematisch durchstöbert, Webseiten abruft und Links folgt, um immer neue Inhalte zu entdecken. Stell dir einen Roboter-Bibliothekar vor, der mit einer Liste von Büchern (URLs) startet, jedes Buch liest und dann allen Verweisen nachgeht, um weitere Bücher zu finden. Genau so arbeitet ein Crawler – nur mit Webseiten statt Büchern und im riesigen „Regal“ des Internets.
Das Grundprinzip:
- Start mit einer Liste von URLs (den sogenannten „Seeds“)
- Jede Seite besuchen und deren Inhalte (HTML, Bilder usw.) herunterladen
- Hyperlinks auf den Seiten finden und zur Warteschlange hinzufügen
- Wiederholen – neue Links besuchen, weitere Seiten entdecken usw.
Die Hauptaufgabe eines Web-Crawlers ist es, Seiten zu entdecken und zu katalogisieren. Bei Suchmaschinen werden die Inhalte kopiert und für die Indexierung vorbereitet. In anderen Fällen extrahieren spezialisierte Crawler gezielt bestimmte Datenpunkte (hier kommt Web Scraping ins Spiel – dazu gleich mehr).
Wichtig zu merken:
Web Crawling heißt, das Web zu erkunden und zu kartieren, nicht einfach nur Daten abzugreifen. Es ist die Grundlage dafür, dass Suchmaschinen wie Google und Bing überhaupt wissen, was im Netz alles existiert.
Wie funktioniert eine Suchmaschine? Die Rolle der Crawler
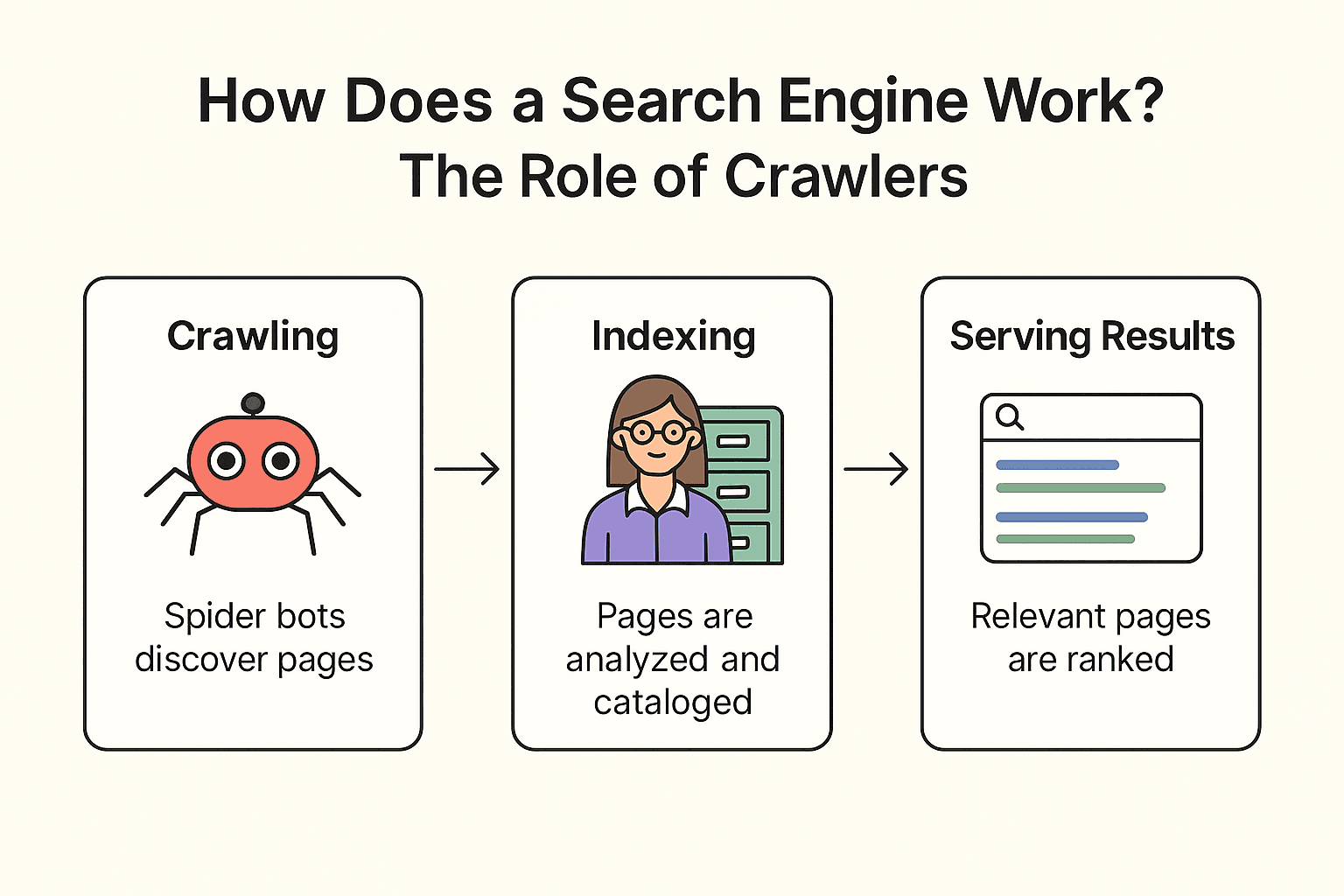
Wie gehen Google, Bing oder DuckDuckGo eigentlich vor? Im Kern läuft alles in drei Schritten ab: Crawling, Indexierung und Ausspielen der Suchergebnisse (Offizielle Google-Dokumentation).
Bleiben wir beim Bibliotheks-Beispiel:
-
Crawling:
Die Suchmaschine schickt ihre „Spider-Bots“ (wie Googlebot) los, um das Web zu erkunden. Sie starten bei bekannten Seiten, holen deren Inhalte und folgen Links zu neuen Seiten – wie ein Bibliothekar, der jedes Regal prüft und allen Fußnoten nachgeht, um weitere Bücher zu finden.
-
Indexierung:
Ist eine Seite gefunden, analysiert die Suchmaschine deren Inhalt, erkennt das Thema und speichert wichtige Infos in einem riesigen digitalen Katalog (dem Index). Nicht jede Seite landet darin – manche werden übersprungen, wenn sie blockiert, von schlechter Qualität oder doppelt sind.
-
Suchergebnisse anzeigen:
Suchst du z. B. nach „beste Pizza in der Nähe“, durchsucht die Suchmaschine ihren Index nach passenden Seiten und sortiert sie nach Hunderten von Faktoren (wie Keywords, Beliebtheit, Aktualität). Heraus kommt eine übersichtliche Liste von Webseiten, die du durchstöbern kannst.
Fun Fact:
Suchmaschinen crawlen nicht jede Seite im Netz. Seiten hinter Logins, durch robots.txt blockiert oder ohne eingehende Links werden oft nie entdeckt. Deshalb reichen Unternehmen ihre URLs oder Sitemaps manchmal direkt bei Google ein.
Web Crawling vs. Web Scraping: Was ist der Unterschied?
Jetzt wird’s spannend: Viele werfen „Web Crawling“ und „Web Scraping“ in einen Topf, dabei sind das zwei verschiedene Paar Schuhe.
| Aspekt | Web Crawling (Spidering) | Web Scraping |
|---|---|---|
| Ziel | Möglichst viele Seiten entdecken und indexieren | Gezielt bestimmte Daten von einer oder mehreren Webseiten extrahieren |
| Vergleich | Bibliothekar, der jedes Buch im Katalog erfasst | Student, der sich gezielt Notizen aus relevanten Büchern macht |
| Ergebnis | Liste von URLs oder Seiteninhalten (für die Indexierung) | Strukturierte Datensätze (CSV, Excel, JSON) mit gezielten Infos |
| Nutzer | Suchmaschinen, SEO-Tools, Web-Archive | Vertrieb, Marketing, Forschung, u. a. |
| Umfang | Riesig (Millionen/Milliarden Seiten) | Fokussiert (Dutzende, Hunderte oder Tausende Seiten) |
Hier findest du einen visuellen Vergleich.
Kurz gesagt:
- Web Crawling dient dazu, Seiten zu finden (das Web zu kartieren)
- Web Scraping bedeutet, gezielt Daten von diesen Seiten zu extrahieren (z. B. für eine Tabelle)
Für Unternehmen (z. B. im Vertrieb, E-Commerce oder Marketing) ist meist das Scraping interessanter – also das strukturierte Sammeln von Daten für Analysen. Crawling ist die Basis für Suchmaschinen und große Datenprojekte, Scraping ist gezielte Datenernte.
Warum einen Web-Crawler nutzen? Praxisbeispiele für Unternehmen
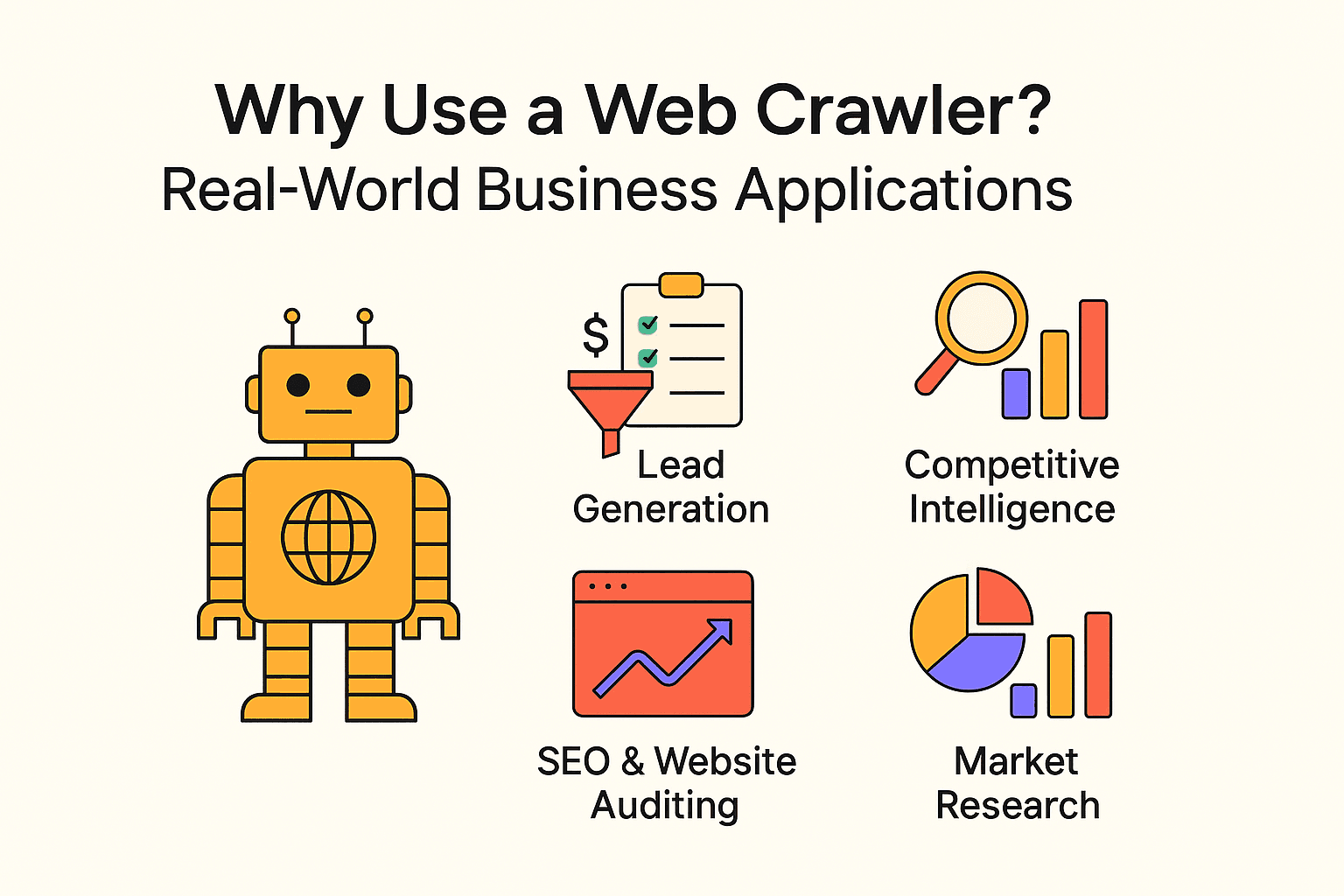
Web Crawling ist längst nicht nur für Suchmaschinen interessant. Unternehmen jeder Größe setzen Crawler und Scraper ein, um wertvolle Einblicke zu gewinnen und Routineaufgaben zu automatisieren. Ein paar typische Anwendungsfälle:
| Anwendungsfall | Zielgruppe | Nutzen |
|---|---|---|
| Lead-Generierung | Vertriebsteams | Automatisierte Akquise, CRM mit frischen Kontakten füllen |
| Wettbewerbsanalyse | Einzelhandel, E-Commerce | Preise, Lagerbestände und Produktänderungen der Konkurrenz überwachen |
| SEO & Website-Audit | Marketing, SEO-Teams | Fehlerhafte Links finden, Seitenstruktur optimieren |
| Content-Aggregation | Medien, Forschung, HR | Nachrichten, Stellenanzeigen oder öffentliche Datensätze sammeln |
| Marktforschung | Analysten, Produktteams | Bewertungen, Trends oder Stimmungen in großem Stil analysieren |
- Groupon hat seine Lead-Generierung verdoppelt – dank automatisiertem Web Crawling.
- 82 % der E-Commerce-Unternehmen und 71 % der Finanzdienstleister stützen ihre Entscheidungen auf Web Scraping.
- Web Scraping kann bis zu 90 % der Infrastrukturkosten und 60 % der Zeit gegenüber manueller Datenerfassung einsparen.
Fazit: Wer Webdaten nicht nutzt, überlässt das Feld der Konkurrenz.
Einen Web-Crawler mit Python programmieren: Das solltest du wissen
Wer sich mit Programmierung auskennt, greift für eigene Crawler meist zu Python. Das Grundrezept:
- Mit requests Webseiten abrufen
- Mit BeautifulSoup HTML parsen und Links/Daten extrahieren
- Mit Schleifen (oder Rekursion) Links folgen und weitere Seiten crawlen
Vorteile:
- Maximale Flexibilität und Kontrolle
- Komplexe Logik, individuelle Datenflüsse und Datenbankanbindung möglich
Nachteile:
- Programmierkenntnisse erforderlich
- Wartungsaufwand: Ändert sich das Webseiten-Layout, muss das Skript nachgezogen werden
- Anti-Bot-Maßnahmen, Verzögerungen und Fehlerbehandlung müssen selbst umgesetzt werden
Einsteigerfreundliches Python-Beispiel:
Hier ein einfaches Skript, das Zitate und Autoren von quotes.toscrape.com abruft:
import requests
from bs4 import BeautifulSoup
url = "<http://quotes.toscrape.com/page/1/>"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
for quote in soup.find_all('div', class_='quote'):
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
print(f"{text} --- {author}")
Um mehrere Seiten zu crawlen, ergänzt man eine Logik, die den „Next“-Button erkennt und so lange weiterläuft, bis keine Seiten mehr übrig sind.
Typische Stolperfallen:
- robots.txt oder Crawl-Delay ignorieren (bitte nicht!)
- Von Anti-Bot-Systemen blockiert werden
- In Endlos-Schleifen crawlen (z. B. Kalenderseiten ohne Ende)
Schritt-für-Schritt-Anleitung: Einen einfachen Web-Crawler mit Python bauen
Wer selbst Hand anlegen will, findet hier eine grobe Schrittfolge für einen Basis-Crawler.
Schritt 1: Python-Umgebung einrichten
Zuerst sicherstellen, dass Python installiert ist. Dann die benötigten Bibliotheken installieren:
pip install requests beautifulsoup4
Falls es hakt: Python-Version checken (python --version) und schauen, ob pip läuft.
Schritt 2: Die Kernlogik des Crawlers schreiben
So sieht ein einfaches Muster aus:
import requests
from bs4 import BeautifulSoup
def crawl(url, depth=1, max_depth=2, visited=None):
if visited is None:
visited = set()
if url in visited or depth > max_depth:
return
visited.add(url)
print(f"Crawling: {url}")
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
# Links extrahieren
for link in soup.find_all('a', href=True):
next_url = link['href']
if next_url.startswith('http'):
crawl(next_url, depth + 1, max_depth, visited)
start_url = "<http://quotes.toscrape.com/>"
crawl(start_url)
Tipps:
- Crawl-Tiefe begrenzen, um Endlos-Schleifen zu vermeiden
- Besuchte URLs speichern, um Dopplungen zu verhindern
- robots.txt beachten und Pausen (time.sleep(1)) zwischen Anfragen einbauen
Schritt 3: Daten extrahieren und speichern
Um Daten zu speichern, kann man z. B. eine CSV-Datei schreiben:
import csv
with open('quotes.csv', 'w', newline='', encoding='utf-8') as file:
writer = csv.writer(file)
writer.writerow(['Quote', 'Author'])
# Innerhalb der Crawl-Schleife:
writer.writerow([text, author])
Alternativ nutzt man das Python-json-Modul für JSON-Ausgaben.
Wichtige Hinweise und Best Practices beim Web Crawling
Web Crawling ist mächtig, aber mit dieser Macht kommt auch Verantwortung (und das Risiko, dass die eigene IP gesperrt wird). So bleibst du auf der sicheren Seite:
- robots.txt respektieren: Immer prüfen und beachten, was eine Website erlaubt oder verbietet.
- Schonend crawlen: Pausen zwischen Anfragen einbauen (mindestens ein paar Sekunden). Server nicht überlasten.
- Umfang begrenzen: Nur das crawlen, was wirklich gebraucht wird. Tiefe und Domain einschränken.
- Sich zu erkennen geben: Einen aussagekräftigen User-Agent verwenden.
- Gesetze beachten: Keine privaten oder sensiblen Daten scrapen. Nur öffentliche Daten nutzen.
- Ethik wahren: Keine kompletten Websites kopieren oder gescrapte Daten für Spam verwenden.
- Langsam testen: Mit kleinen Crawls starten und erst bei Erfolg ausweiten.
Mehr dazu im Best-Practices-Guide.
Wann ist Web Scraping die bessere Wahl? Thunderbit für Unternehmen
Mit KI Daten von jeder Website extrahieren Get Started Free
Mein ehrlicher Tipp: Solange du nicht gerade eine eigene Suchmaschine baust oder komplette Seitenstrukturen kartieren musst, sind Web-Scraping-Tools für die meisten Unternehmen die bessere Wahl.
Hier kommt Thunderbit ins Spiel. Als Mitgründer und CEO bin ich vielleicht etwas voreingenommen, aber ich bin überzeugt: Thunderbit ist der einfachste Weg für Nicht-Techniker, Webdaten zu extrahieren.
Warum Thunderbit?
- In zwei Klicks startklar: „KI-Felder vorschlagen“ und dann „Scrapen“ – fertig.
- KI-gestützt: Thunderbit erkennt automatisch die wichtigsten Datenfelder (z. B. Produktnamen, Preise, Bilder).
- Bulk- & PDF-Support: Daten von aktuellen Seiten, mehreren URLs oder sogar PDFs extrahieren.
- Flexible Exporte: Als CSV/JSON herunterladen oder direkt an Google Sheets, Airtable oder Notion senden.
- Kein Code nötig: Wer einen Browser bedienen kann, kommt auch mit Thunderbit zurecht.
- Unterseiten scrapen: Mehr Details nötig? Thunderbit besucht automatisch Unterseiten und reichert die Daten an.
- Zeitplanung: Wiederkehrende Scrapes in Klartext einrichten (z. B. „jeden Montag um 9 Uhr“).
Thunderbit Chrome-Erweiterung kostenlos testen
Wann ist ein Crawler sinnvoller?
Willst du eine komplette Website kartieren (z. B. für einen Suchindex oder eine Sitemap), ist ein Crawler das richtige Werkzeug. Geht es aber um strukturierte Daten von bestimmten Seiten (z. B. Produktlisten, Bewertungen oder Kontaktdaten), ist Scraping schneller, einfacher und effizienter.
Fazit & wichtigste Erkenntnisse
Kurz und knapp:
- Web Crawling ist die Methode, mit der Suchmaschinen und große Datenprojekte das Web entdecken und kartieren. Es geht um die Breite – möglichst viele Seiten finden.
- Web Scraping geht in die Tiefe – gezielt die Daten extrahieren, die wirklich gebraucht werden. Für die meisten Unternehmen ist Scraping relevanter als Crawling.
- Eigene Crawler lassen sich programmieren (Python eignet sich gut dafür), aber das kostet Zeit, Know-how und Pflegeaufwand.
- No-Code- und KI-Tools wie Thunderbit machen die Webdatenerfassung für alle zugänglich – ganz ohne Programmierung.
- Best Practices sind wichtig: Immer verantwortungsvoll crawlen und scrapen, Website-Regeln respektieren und Daten ethisch nutzen.
Wer gerade erst startet, sucht sich am besten ein kleines Projekt – zum Beispiel Produktpreise scrapen oder Leads aus einem Verzeichnis sammeln. Mit Tools wie Thunderbit gelingt der Einstieg schnell, oder du probierst Python aus, wenn du tiefer einsteigen willst.
Das Web ist eine wahre Schatzkammer an Informationen. Mit dem richtigen Ansatz lassen sich daraus wertvolle Erkenntnisse gewinnen, Zeit sparen und das eigene Unternehmen voranbringen.
Jetzt mit Thunderbit Daten extrahieren
FAQ
- Was ist der Unterschied zwischen Web Crawling und Web Scraping?
Crawling findet und kartiert Seiten. Scraping extrahiert gezielt Daten daraus. Crawling = Entdecken; Scraping = Sammeln.
- Ist Web Scraping legal?
Das Extrahieren öffentlicher Daten ist meist erlaubt, solange robots.txt und die Nutzungsbedingungen eingehalten werden. Private oder urheberrechtlich geschützte Inhalte sollten gemieden werden.
- Muss ich programmieren können, um Websites zu scrapen?
Nein. Mit Tools wie Thunderbit geht das per Klick und KI – ganz ohne Code.
- Warum ist nicht das ganze Web bei Google indexiert?
Weil viele Inhalte hinter Logins, Bezahlschranken oder Sperren liegen. Nur etwa 4 % sind tatsächlich indexiert.
Weiterführende Links
- FreeCodeCamp – Web Scraping mit Python und BeautifulSoup
- Scrapy Offizielles Tutorial
- Real Python – Selenium und Python für Web Scraping
- Apify Academy: Web Scraping und Automatisierung
KI-Web-Scraper ausprobieren Get Started Free




