Ich muss ehrlich sein: Als ich zum ersten Mal versucht habe, Google-Suchergebnisse für eine Wettbewerbsanalyse zu sammeln, dachte ich mir: „Wie schwer kann das schon sein?“ Ein paar Stunden später saß ich zwischen Python-Skripten, Proxy-Problemen und der gefürchteten Google-Meldung „Ungewöhnlicher Datenverkehr erkannt“. Mein Kaffee war längst kalt, meine Nerven am Limit – und die Daten? Immer noch nicht in meiner Tabelle.
Wer schon mal versucht hat, strukturierte Infos aus der Google-Suche zu ziehen – egal ob für SEO, Vertrieb oder einfach aus Datenhunger – kennt diesen Frust. Google verarbeitet und hält einen . Ein riesiger Schatz an aktuellen Marktdaten – wenn man drankommt. Doch für die meisten ist klassisches Google Scraping ein Labyrinth aus Code, Wartung und Anti-Bot-Hürden. Die gute Nachricht: 2025 machen No-Code-Tools mit KI wie das Extrahieren von Google-Suchergebnissen für alle möglich – nicht nur für Entwickler.
Schauen wir uns an, wie du Google-Suchergebnisse extrahieren kannst – ganz ohne Programmieren, ohne Kopfschmerzen und ohne kalten Kaffee.
Was bedeutet es, Google-Suchergebnisse zu scrapen?
Kurz gesagt: Google-Suchergebnisse scrapen heißt, strukturierte Infos wie Titel, URLs und Snippets aus den Suchergebnisseiten (SERPs) von Google zu ziehen. Stell dir vor, du würdest die blauen Links und Beschreibungen automatisch in eine Tabelle kopieren – nur viel schneller.
Was macht das Scrapen von Google so besonders im Vergleich zu einem Produktkatalog oder einer Nachrichtenseite? Googles SERPs sind dynamisch und vollgepackt mit verschiedenen Elementen:
- Organische Ergebnisse (die klassischen blauen Links mit Snippet)
- Bezahlte Anzeigen (mit „Anzeige“ gekennzeichnet)
- „Ähnliche Fragen“-Boxen
- Featured Snippets
- Karten, Bilder, Videos, Shopping-Ergebnisse
All diese Elemente enthalten wertvolle Daten – vorausgesetzt, dein Tool erkennt sie. Die Herausforderung: Googles Ergebnisse ändern sich ständig, und zwei Leute sehen bei derselben Suche oft unterschiedliche Resultate – je nach Standort oder Suchverlauf (). Google Scraping bedeutet also nicht nur, HTML zu kopieren, sondern eine sich ständig verändernde, unstrukturierte Seite in ein sauberes, strukturiertes Datenset zu verwandeln.
Warum ist das Scrapen von Google-Suchergebnissen für Unternehmen wichtig?
Warum sollte man sich überhaupt die Mühe machen, Google zu scrapen? Weil die SERPs ein Echtzeit-Spiegel dafür sind, was die Welt gerade interessiert – was im Trend liegt, wer im SEO vorne ist, was die Konkurrenz macht und wo potenzielle Kunden zu finden sind.
Hier die wichtigsten Anwendungsfälle, die ich immer wieder sehe:
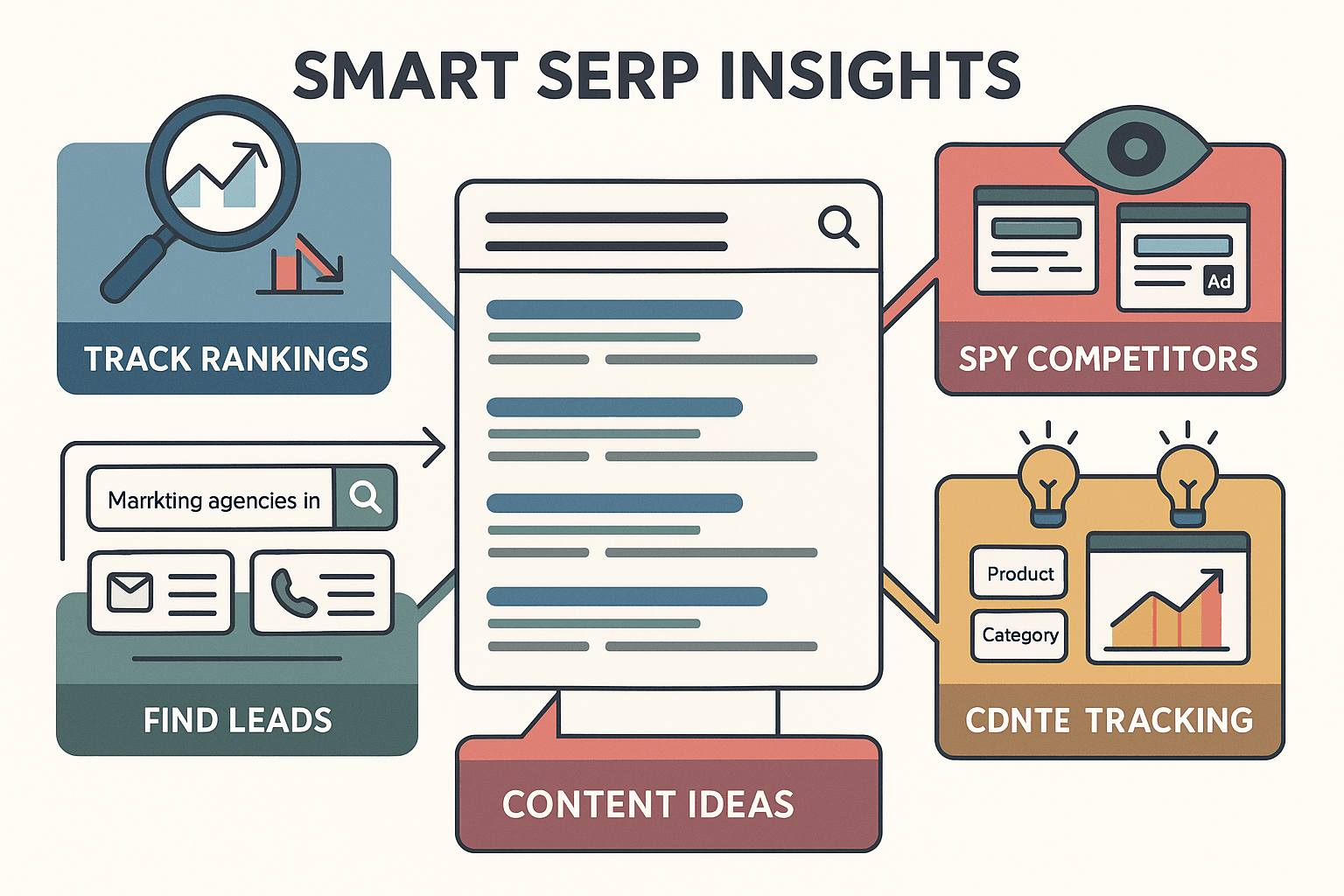
- SEO-Monitoring & Keyword-Tracking: Behalte deine Rankings im Blick, erkenne, wer dich überholt, und entdecke neue Content-Chancen durch die Analyse der Top-Ergebnisse und SERP-Features ().
- Wettbewerbsanalyse: Finde heraus, welche Konkurrenten bei deinen Keywords dominieren, wie sie Titel und Beschreibungen gestalten und welche Anzeigen sie schalten.
- Lead-Generierung: Starte gezielte Suchanfragen wie „Marketingagenturen in München“ und extrahiere Kontaktdaten aus den Ergebnissen ().
- Content-Strategie: Entdecke Trendthemen und häufige Fragen, indem du „Ähnliche Fragen“-Boxen und Überschriften scrapest ().
- Marktforschung: Erkenne Veränderungen im Nutzerinteresse, indem du beobachtest, welche Themen, Features oder Produkte in den SERPs aufsteigen ().
Hier eine kompakte Übersicht, wer Google Scraping nutzt und welchen Mehrwert es bringt:
| Anwendungsfall | Hauptnutzer | Nutzen |
|---|---|---|
| SEO-Performance-Tracking | SEO-Teams, Marketer | Keyword-Rankings überwachen, Top-Konkurrenten identifizieren, Inhalte optimieren, Featured Snippets & Fragen gezielt ansteuern |
| Wettbewerbsanalyse | Marketing, Strategie | Präsenz, Messaging und Anzeigen der Konkurrenz analysieren |
| Lead-Generierung | Vertrieb, Business Development | Interessentenlisten aufbauen, E-Mails/Telefonnummern aus SERP-Snippets und verlinkten Seiten extrahieren |
| Content-Strategie | Content-Marketer, Redakteure | Trendthemen, beliebte Fragen und Top-Content recherchieren |
| Markt- & Trendanalyse | Produktmanager, Analysten | Suchtrends verfolgen, neue Themen erkennen, Produktentwicklung und Positionierung steuern |
| Anzeigen-Monitoring | PPC-Marketing-Teams | Konkurrenzanzeigen sammeln, Gebote und Anzeigentexte optimieren, Sichtbarkeit von Ads verfolgen |
Nicht zu vergessen: Auch Teams aus Operations, PR oder Kundenservice können SERP-Daten nutzen, um Einträge zu prüfen, die Markenreputation zu überwachen oder Branchengespräche zu verfolgen. Fazit: Wer Google-Suchdaten nicht nutzt, verpasst wertvolle Einblicke, die die Konkurrenz längst hat.
Methoden im Vergleich: No-Code, Programmierung oder API für Google Scraping
Wie bekommst du die Google-Daten aus dem Browser in deinen Workflow? Es gibt drei Hauptwege:
- No-Code-Tools (wie Thunderbit): Intuitiv, KI-gestützt, für alle gemacht, die nicht coden wollen.
- Eigene Programmierung (Python, BeautifulSoup, Selenium): Maximale Kontrolle, aber viel Aufwand und Wartung.
- SERP-APIs (offiziell oder Drittanbieter): Zuverlässig im großen Stil, aber technisches Know-how und Budget nötig.
So schneiden die Methoden ab:
| Methode | Benutzerfreundlichkeit | Einrichtung & Wartung | Kosten | Flexibilität & Skalierung |
|---|---|---|---|---|
| No-Code-Tools (Thunderbit) | Am einfachsten | Minimal, automatische Updates | Kostenloser Einstieg, Credits für mehr Zeilen | Ideal für Standardfälle, mittlere Skalierung |
| Eigene Programmierung | Hohe Lernkurve | Viel Aufwand, oft fehleranfällig | Kostenlose Bibliotheken, aber hoher Zeitaufwand | Maximale Flexibilität, skalierbar mit eigener Infrastruktur |
| SERP-APIs | Mittel | Gering, Anbieter übernimmt | Kosten pro Anfrage, summiert sich schnell | Hohe Skalierung, aber auf API-Datenfelder beschränkt |
Für die meisten Unternehmen ist der No-Code-Weg der schnellste zum Ziel. Programmierung lohnt sich für Bastler oder mit Entwicklerteam, APIs sind ideal für große SEO-Plattformen oder tausende Abfragen pro Tag.
Thunderbit: Die No-Code-KI-Lösung für Google Scraping
Thunderbit ist der absolute Gamechanger, wenn es um einfaches Google Scraping geht. Die bringt einen KI-Web-Scraper direkt in deinen Browser. Das macht Thunderbit besonders:
- KI-Feldvorschläge: Die KI erkennt automatisch relevante Felder wie Titel, URL, Snippet, Anzeigen oder „Ähnliche Fragen“. Kein Herumprobieren mit CSS-Selektoren oder XPath.
- Subpage-Scraping: Thunderbit kann jede Ergebnis-URL besuchen und dort weitere Daten wie E-Mails oder Produktinfos extrahieren – ganz automatisch.
- Automatische Paginierung: Mehrere Ergebnisseiten werden automatisch durchgeklickt und gescrapet. Kein manuelles Kopieren mehr.
- Sofort-Export: Die Daten lassen sich direkt nach Excel, Google Sheets, Notion oder Airtable exportieren – ohne CSV-Chaos.
- Mehrsprachigkeit: Thunderbit unterstützt 34 Sprachen und kann SERPs aus jedem Markt extrahieren.
- Cloud- oder Browser-Modus: Wähle Cloud-Scraping für Geschwindigkeit (bis zu 50 Seiten gleichzeitig) oder Browser-Modus für eingeloggte oder lokale Ergebnisse.
Das Beste: Von „Ich brauche diese Daten“ bis „Ich habe diese Daten“ dauert es nur etwa zwei Minuten. Kein Code, keine Konfigurationsdateien, keine kaputten Skripte.
Klassische Programmierung: Python-Skripte und eigene Parser
Wer Entwickler ist (oder gerne tüftelt), greift vielleicht zu Python und Bibliotheken wie BeautifulSoup oder Selenium. Die Realität:
- Aufwendige Einrichtung: Du musst Code schreiben, um das HTML zu laden, Ergebnisse zu parsen, Paginierung zu steuern und Daten zu speichern.
- Ständige Wartung: Googles HTML ändert sich laufend. Dein Skript wird regelmäßig ausfallen – Debugging ist vorprogrammiert.
- Anti-Bot-Maßnahmen: Google erkennt Bots sehr gut. CAPTCHAs, IP-Sperren und „Ungewöhnlicher Datenverkehr“-Fehler sind an der Tagesordnung. Proxies, Delays und ggf. CAPTCHA-Lösungen werden nötig.
- Flexibilität: Du kannst alles extrahieren, verbringst aber mehr Zeit mit Wartung als mit der Datennutzung.
Wenn Scraping nicht dein Hauptjob ist, ist dieser Weg eher was für Profis oder sehr spezielle Anforderungen ().
Google SERP-APIs: Vorteile, Nachteile und Kosten
Für große Projekte sind APIs oft die Rettung. Google bietet eine , dazu gibt es viele Drittanbieter. Das Wichtigste:
- Vorteile: APIs übernehmen das ganze Drumherum – CAPTCHAs, IP-Wechsel, Parsing. Du schickst eine Anfrage und bekommst strukturierte Daten zurück.
- Nachteile: APIs kosten meist Geld. SerpAPI verlangt z. B. ca. 75 $/Monat für 5.000 Suchanfragen (), Zenserp etwa 29 $ für 5.000 Suchen (). Bei vielen Abfragen summiert sich das schnell.
- Technische Kenntnisse nötig: Du musst Skripte schreiben, um die API anzusprechen und die Daten zu verarbeiten.
- Einschränkungen: APIs liefern nicht immer alle SERP-Features und sind auf die unterstützten Datenfelder begrenzt.
APIs sind ideal für große Unternehmen, aber für die meisten reicht ein No-Code-Tool – schneller, günstiger und flexibler für Einzelabfragen oder mittlere Mengen.
Schritt-für-Schritt-Anleitung: Google-Suchergebnisse mit Thunderbit extrahieren
So einfach geht’s – Schritt für Schritt mit Thunderbit, ganz ohne Programmieren.
Schritt 1: Thunderbit installieren und einrichten
. Die Installation dauert nur 30 Sekunden. Melde dich mit Google oder E-Mail an – fertig. Thunderbit unterstützt 34 Sprachen, du kannst also SERPs aus jedem Markt extrahieren.
Schritt 2: Google-Suche öffnen und Suchbegriff eingeben
Öffne Chrome und gehe auf google.com. Gib deinen Suchbegriff ein, zum Beispiel „bestes CRM-Tool 2025“, und drücke Enter. Warte, bis die Ergebnisseite komplett geladen ist. Für länderspezifische Ergebnisse kannst du die Google-Einstellungen anpassen oder ein VPN nutzen.
Schritt 3: Mit KI-Feldvorschlägen SERP-Daten erkennen
Klicke auf das Thunderbit-Icon im Browser. Im Thunderbit-Panel wähle KI-Feldvorschläge. Die KI scannt die Seite und schlägt Felder wie Titel, URL und Snippet vor. Du kannst Felder umbenennen, löschen oder weitere hinzufügen – etwa „Ähnliche Fragen“ oder Anzeigenüberschriften.
Du kannst sogar eigene KI-Anweisungen für jedes Feld definieren – für die meisten Google-Suchen reichen aber die Standardvorschläge.
Schritt 4: Google-Suchergebnisse scrapen und Vorschau anzeigen
Klicke auf Scrapen. Thunderbit extrahiert die Daten der aktuellen Seite und zeigt sie in einer Tabelle an. Jede Zeile entspricht einem Ergebnis, mit Spalten für Titel, URL, Snippet und weitere Felder. Prüfe, ob alles passt. Falls etwas fehlt, passe die Felder an und starte erneut.
Schritt 5: Daten nach Excel, Google Sheets, Notion oder Airtable exportieren
Jetzt kommt der beste Teil: Klicke auf Exportieren und wähle das gewünschte Format. Du kannst als Excel/CSV herunterladen, in die Zwischenablage kopieren oder die Daten direkt nach , Notion oder Airtable senden. Keine Zusatzkosten, keine Exportlimits – auch im Gratis-Tarif.
Nun hast du deine SERP-Daten in einer Tabelle – bereit für Analyse, Visualisierung oder Team-Sharing.
Schritt 6: Profi-Tipps – Paginierung, Subpages und Zeitplanung
Du willst mehr als nur die erste Ergebnisseite? Aktiviere Paginierung in den Thunderbit-Einstellungen, und das Tool klickt automatisch auf „Weiter“, um mehrere Seiten zu scrapen – einfach die gewünschte Seitenzahl angeben. Willst du Infos von den Zielseiten extrahieren? Nutze Subpage-Scraping, um jede URL zu besuchen und z. B. E-Mails oder Preise zu erfassen.
Und falls du eine SERP regelmäßig überwachen willst – etwa tägliche Ranking-Checks – nutze die Zeitplanung von Thunderbit. Beschreibe den Zeitplan einfach in natürlicher Sprache („jeden Tag um 9 Uhr“), und Thunderbit übernimmt das Scraping automatisch, auch wenn dein Browser geschlossen ist.
Wichtige Hinweise und Best Practices für Google Scraping
Ein paar Tipps aus der Praxis:
- Googles Regeln beachten: Automatisiertes Scraping ist laut Googles Nutzungsbedingungen nicht erlaubt. Für kleine, interne Analysen ist das meist unproblematisch – aber keine Massenabfragen oder Weiterverkauf der Daten. Für große Projekte lieber offizielle APIs nutzen ().
- Google nicht überlasten: Scrape in menschlichem Tempo. Bei vielen Seiten nutze den Cloud-Modus von Thunderbit, um Anfragen zu verteilen. Bei CAPTCHAs: manuell lösen oder langsamer scrapen.
- Kontext prüfen: Google personalisiert Ergebnisse nach Standort und Suchverlauf. Für konsistente Daten am besten im Inkognito-Modus scrapen oder Standort/Sprache gezielt einstellen.
- Daten bereinigen: Nach dem Scraping Duplikate entfernen, Formatierungen anpassen und Zeitstempel ergänzen – das erleichtert die Auswertung.
- Ethik beachten: Bei E-Mail- oder Personendaten immer Datenschutzgesetze wie die DSGVO einhalten. Die Daten zur Strategie nutzen, nicht für Spam oder Content-Kopien.
Mehr Tipps findest du im .
Wann Thunderbit und wann andere Google-Scraping-Methoden?
Welche Methode passt zu dir? Meine Faustregel:
- Thunderbit (No-Code-KI): Ideal für schnelle, unkomplizierte Extraktion – besonders für Nicht-Techniker, Einzelprojekte oder mittlere Mengen. Wer in Minuten von der Idee zu den Daten will, ist hier richtig.
- Eigene Programmierung: Wenn du spezielle Logik, tiefe Integration oder sehr individuelle Anforderungen hast. Zeit für Wartung einplanen!
- SERP-APIs: Perfekt für große, automatisierte Datenfeeds – etwa tägliches Tracking von tausenden Keywords für SEO-Plattformen. Skripting und API-Budget nötig.
Oft starten Teams mit Thunderbit für schnelle Insights und wechseln bei Bedarf zu APIs oder eigenem Code. Es gibt keine Einheitslösung – wähle das Tool, das zu deinen Anforderungen, Fähigkeiten und Ressourcen passt.
Fazit & wichtigste Erkenntnisse
Google-Suchergebnisse zu extrahieren war früher eine technische Herausforderung. 2025 ist es eine Sache von zwei Minuten – auch ohne Programmierkenntnisse. Mit werden SERPs zu wertvollen Daten für SEO, Vertrieb, Marketing und mehr.
Das solltest du dir merken:
- Google-SERP-Daten sind ein Goldschatz für Business-Intelligence. Wer sie nicht nutzt, verschenkt Potenzial.
- No-Code-KI-Tools wie Thunderbit machen Scraping für alle zugänglich – schnell, präzise und ohne Programmieraufwand.
- Klassische Programmierung und APIs haben ihren Platz für Power-User, aber für die meisten Business-Anwendungen ist No-Code die beste Wahl.
- Verantwortungsvoll scrapen: Googles Regeln respektieren, Server nicht überlasten und Daten ethisch nutzen.
Wenn du das nächste Mal Google-Daten brauchst, lass die Skripte links liegen und probiere Thunderbit aus. Dein Kaffee bleibt heiß, deine Daten sind strukturiert – und du hast mehr Zeit für das Wesentliche: Erkenntnisse in Taten umsetzen.
Du willst mehr über Web-Scraper, List Crawling oder den Export nach Excel erfahren? Im findest du weitere Anleitungen und Tipps. Und wenn du Google-Suchergebnisse jetzt einfach extrahieren willst, .
Viel Erfolg beim Scrapen – ganz ohne Code!
FAQs
1. Was bedeutet es, Google-Suchergebnisse zu scrapen?
Beim Scrapen von Google-Suchergebnissen werden strukturierte Daten wie Titel, URLs, Snippets, Anzeigen oder „Ähnliche Fragen“-Boxen aus den Suchergebnisseiten (SERPs) extrahiert. So werden unstrukturierte Webseiten in saubere, auswertbare Datensätze verwandelt – ideal für SEO-Tracking, Wettbewerbsanalyse, Lead-Generierung und mehr.
2. Ist es legal, Daten aus der Google-Suche zu extrahieren?
Für private oder interne Zwecke ist das Scrapen von Google weit verbreitet, allerdings verbieten die Nutzungsbedingungen von Google automatisierte Datenerfassung. Für große oder kommerzielle Projekte empfiehlt sich die Nutzung offizieller APIs. Immer verantwortungsvoll scrapen und Datenschutzgesetze wie die DSGVO beachten.
3. Welche Vorteile bietet ein No-Code-Tool wie Thunderbit beim Scraping?
No-Code-Tools wie Thunderbit ermöglichen das Scrapen von Google ohne Programmierkenntnisse. Vorteile sind:
- KI-gestützte Felderkennung (z. B. Titel, URL, Snippet)
- Unterstützung für Subpage-Scraping und Paginierung
- Export nach Excel, Google Sheets, Notion oder Airtable
- Keine Einrichtung oder Wartung nötig Ideal für Business-Anwender, die schnell und einfach SERP-Daten benötigen.
4. Wie schneidet Thunderbit im Vergleich zu Python-Skripten oder SERP-APIs ab?
Thunderbit ist deutlich einfacher und schneller einzurichten als Python-Skripte, die Programmierkenntnisse und laufende Wartung erfordern. Im Vergleich zu SERP-APIs ist Thunderbit für Einzelabfragen oder mittlere Mengen zugänglicher, während APIs sich für große, automatisierte Workflows eignen.
5. Was kann ich mit gescrapten Google-Daten machen?
Gescrapte SERP-Daten sind nützlich für:
- SEO-Monitoring: Keyword-Rankings und Featured Snippets verfolgen
- Wettbewerbsanalyse: Sichtbarkeit und Auftritt der Konkurrenz analysieren
- Lead-Generierung: Kontaktlisten aus Geschäftsanfragen erstellen
- Content-Strategie: Trendthemen und häufige Fragen entdecken
- Marktforschung: Suchtrends und Veränderungen im Nutzerinteresse beobachten Diese Daten helfen Teams, fundierte Entscheidungen in Marketing, Vertrieb und Produktentwicklung zu treffen.
Mehr erfahren: