
Wenn du nach KI-gestützten Web-Scraping-Tools suchst, bist du sehr wahrscheinlich schon über crawl4ai gestolpert. Das populäre Open-Source-Projekt macht in der Entwickler-Community mit seinem Tempo und seiner Flexibilität von sich reden. Aber was, wenn du gar nicht programmierst – oder einfach nur schnell an Daten willst, ohne dich mit Python-Skripten herumzuschlagen? Ob du crawl4ai für dein nächstes Projekt in die engere Wahl nimmst oder als Profi aus Vertrieb, Marketing, E-Commerce oder Immobilien nach einer einsteigerfreundlicheren Alternative suchst – hier bist du richtig. Ich zeige, was crawl4ai kann, wo es überzeugt und wo es Wünsche offenlässt, und wie sich Thunderbit als moderne No-Code-Lösung für all jene schlägt, die das Web mit wenigen Klicks extrahieren wollen.
Was ist crawl4ai?
crawl4ai ist eine Open-Source-Python-Bibliothek für Web-Crawling und Datenextraktion, mit klarem Fokus auf KI- und Large-Language-Model-(LLM)-Anwendungsfälle. Auf GitHub hat das Tool durch sein schnelles, paralleles Crawling Beliebtheit gewonnen und durch die Fähigkeit, Daten in KI-freundlichen Formaten wie JSON und Markdown auszugeben. Im Kern ist es ein Entwickler-Toolkit, um Websites in großem Maßstab zu extrahieren und die Daten anschließend in KI-Modelle, Analyse-Dashboards oder eigene Datenbanken zu speisen.
![]()
Die wichtigsten Funktionen:
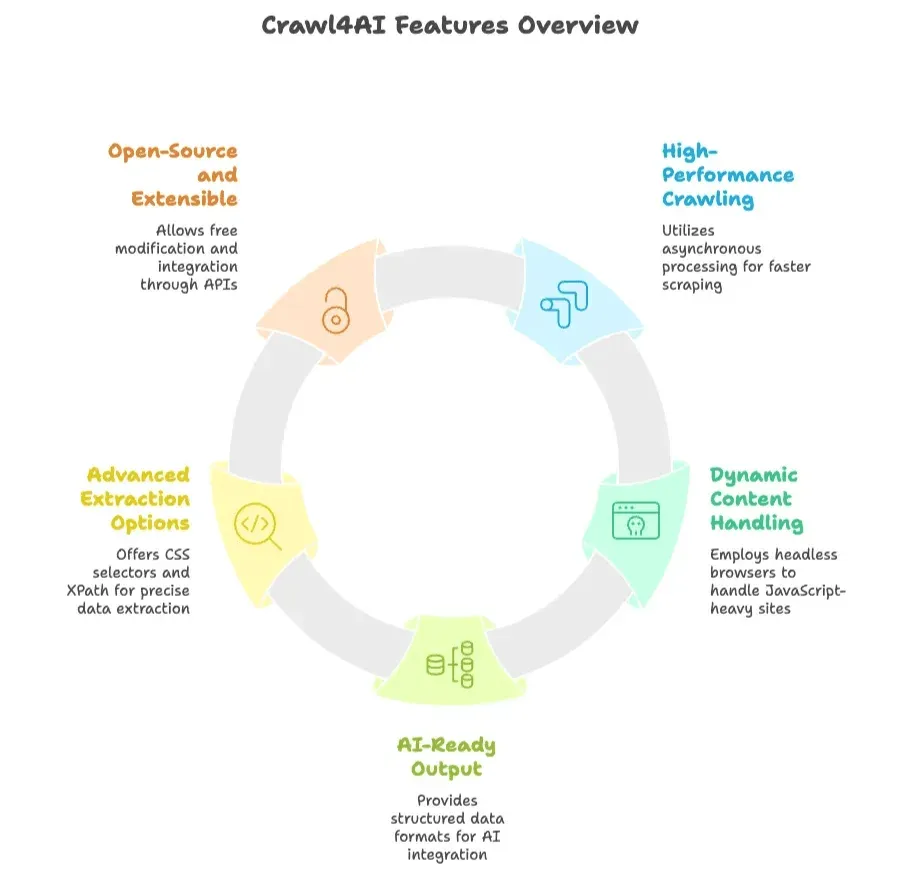
- Hochleistungs-Crawling: Nutzt asynchrone, parallele Verarbeitung, um viele Seiten gleichzeitig zu crawlen, und damit deutlich schneller als viele klassische Scraper.
- Umgang mit dynamischen Inhalten: Steuert einen Headless-Browser (etwa Chromium über Playwright), um JavaScript auszuführen und moderne, dynamische Websites zu erfassen.
- KI-fähige Ausgabe: Liefert Daten als strukturierten Text (JSON, Markdown oder bereinigtes HTML), der sich direkt für KI oder Datenanalysen eignet.
- Erweiterte Extraktionsoptionen: Erlaubt Extraktionsregeln per CSS-Selektor oder XPath und bindet bei Bedarf sogar LLMs für Zusammenfassungen oder Extraktion ein.
- Open Source und erweiterbar: Kostenlos, anpassbar und ausbaubar. Bietet eine Python-API, eine Kommandozeile und eine REST-API für flexible Integrationen.
Die Philosophie hinter crawl4ai ist es, „Daten zu demokratisieren“: Entwickler bekommen einen schnellen, codebasierten Scraper – ohne Paywalls oder die Limits kommerzieller Tools. Wer sich mit Python auskennt, hat damit ein starkes Werkzeug, um große Mengen an Webdaten zügig zu sammeln.
Für wen ist crawl4ai gedacht?
crawl4ai richtet sich vor allem an technische Anwender – also Entwickler, Data Scientists, KI-Forschende und alle, die mit Python-Skripten vertraut sind. Typische Einsatzgebiete:
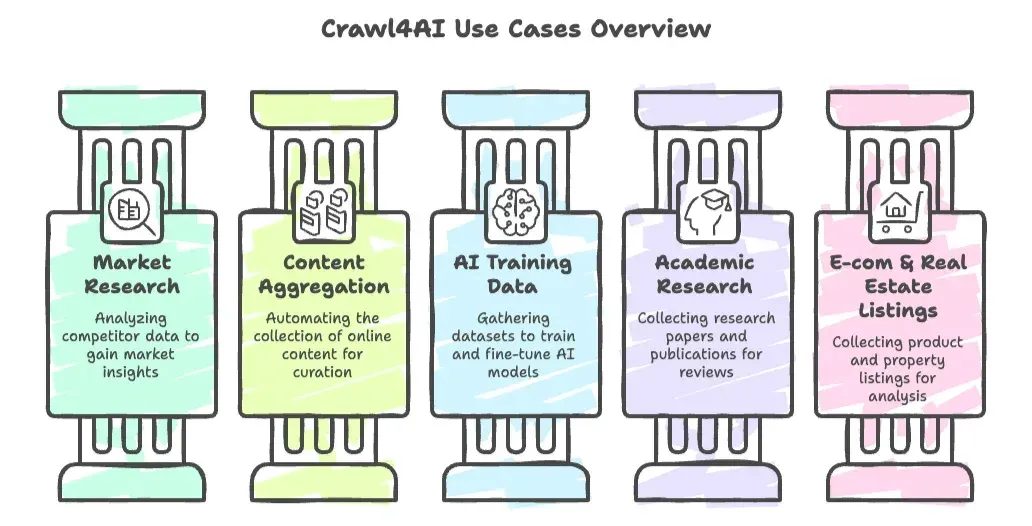
- Marktforschung und Wettbewerbsanalyse: Wettbewerber-Websites, Nachrichtenartikel oder Social-Media-Inhalte für Erkenntnisse extrahieren.
- Content-Aggregation: Das Sammeln von News, Blogbeiträgen oder Forenposts für Kuratierung oder Trendbeobachtung automatisieren.
- Trainingsdaten für KI sammeln: Große Datensätze wie Dokumentationen, Q&A oder Artikel zusammentragen, um Sprachmodelle zu trainieren oder feinzujustieren.
- Wissenschaftliche Recherche: Forschungsarbeiten, Rechtsprechung oder Online-Publikationen automatisch für Literaturrecherchen erfassen.
- E-Commerce- und Immobilien-Listings: Entwickler bauen eigene Crawler, um Produkt- oder Immobilienangebote für Analysen zu sammeln.
Aber Achtung: crawl4ai ist nicht für nicht-technische Nutzer gemacht. Bist du Vertriebsleiter, Marketer oder Immobilienmakler ohne Programmiererfahrung, wirst du Einrichtung und Bedienung wahrscheinlich abschreckend finden. Das Tool setzt voraus, dass du Python beherrschst und mit der Konfiguration von Extraktionsregeln sowie der Fehlersuche vertraut bist.
Der Preisplan von crawl4ai
Einer der größten Pluspunkte von crawl4ai ist der Preis: Es ist komplett kostenlos. Als Open-Source-Projekt gibt es keine Lizenzgebühren, keine Abo-Stufen und keine Paywalls. Du installierst es per pip und legst sofort los.
Allerdings hat „kostenlos“ seine Tücken:
- Einrichtung und Wartung: Du investierst Zeit, um deine Umgebung aufzusetzen, Skripte zu schreiben und deine Scraping-Abläufe zu pflegen.
- Indirekte Kosten: Bei großen Crawls musst du womöglich für Proxys, Server oder Cloud-Ressourcen zahlen.
- Support: Es gibt keinen offiziellen Kundensupport, nur Community-Foren und GitHub-Issues.
Für Unternehmen mit internem technischem Know-how kann das eine kosteneffiziente Lösung sein. Für nicht-technische Teams relativieren der Zeitaufwand und die Mühe bis zum Laufen den Null-Euro-Preis schnell.
Nutzerfeedback zu crawl4ai
Um einen ehrlichen Eindruck davon zu bekommen, wie sich crawl4ai in der Praxis schlägt, habe ich Bewertungen auf Tech-Blogs, in KI-Tool-Verzeichnissen und Community-Foren durchgesehen. Das ist mir aufgefallen:
Was Nutzern gefällt
- Tempo und Kosteneffizienz: Entwickler sind begeistert, wie schnell crawl4ai große Websites extrahiert und dass es dabei oft kostenpflichtige Tools übertrifft. Dass es kostenlos ist, ist ein riesiger Vorteil.
- Open-Source-Flexibilität: Nutzer schätzen die volle Kontrolle über den Code, ohne Vendor-Lock-in oder Feature-Beschränkungen.
- KI-fähige Ausgabe: Die strukturierte, saubere Datenausgabe, besonders in JSON oder Markdown, spart Zeit für alle, die Daten in KI-Modelle oder Analysetools speisen.
Womit Nutzer hadern
Doch das Lob kommt mit deutlichen Einschränkungen, vor allem für Einsteiger oder Nicht-Programmierer.
1. Steile Lernkurve
Ein wiederkehrendes Thema: crawl4ai ist nicht anfängerfreundlich. Wer neu im Web-Scraping ist oder sich mit Python unwohl fühlt, hat eine steile Lernkurve vor sich. Es gibt keine Point-and-Click-Oberfläche; alles läuft über Skripte und Konfigurationsdateien. Die Umgebung einzurichten, Extraktionsregeln zu schreiben und asynchrones Crawling zu beherrschen, verlangt technisches Können. Ein Rezensent bringt es drastisch auf den Punkt: „Wenn du kein Coder bist, bist du verloren.“
2. Nicht einsteigerfreundlich
Selbst mit etwas technischem Hintergrund kann crawl4ai fordern. Die Dokumentation wird besser, aber die Community ist noch klein, sodass Hilfe manchmal auf sich warten lässt. Nutzer berichten von Bugs oder Abstürzen auf komplexen Websites, und die Fehlersuche bedeutet oft, sich durch GitHub-Issues oder Stack Overflow zu wühlen. Außerdem fehlen eingebaute Funktionen für typische Geschäftsanforderungen – etwa der Login auf Websites, das Lösen von CAPTCHAs oder das Planen wiederkehrender Crawls. Willst du zeitgesteuert extrahieren oder Authentifizierung handhaben, musst du das selbst bauen.
Aus der Praxis:
- Ein Marketingleiter eines mittelgroßen E-Commerce-Unternehmens wollte mit crawl4ai die Preise von Wettbewerbern überwachen. Nach mehreren Tagen im Ringen mit Python-Skripten und Browser-Treibern gab er auf und wechselte zu einem No-Code-Tool. Die technischen Hürden und der fehlende Support machten es für sein Team untauglich.
- Ein Immobilienmakler wollte Angebotsdaten von mehreren Websites sammeln. Schon die Einrichtung von crawl4ai überforderte ihn, und er kam an der ersten Konfiguration nicht vorbei. Ohne Entwickler an seiner Seite blieb das Projekt stecken.
crawl4ai ist also ein Kraftpaket für Entwickler, aber für Business-Anwender, die einfach ohne Kopfschmerzen an Daten wollen, schwer zu vermitteln.
Die wichtigsten Erkenntnisse aus dem crawl4ai-Test
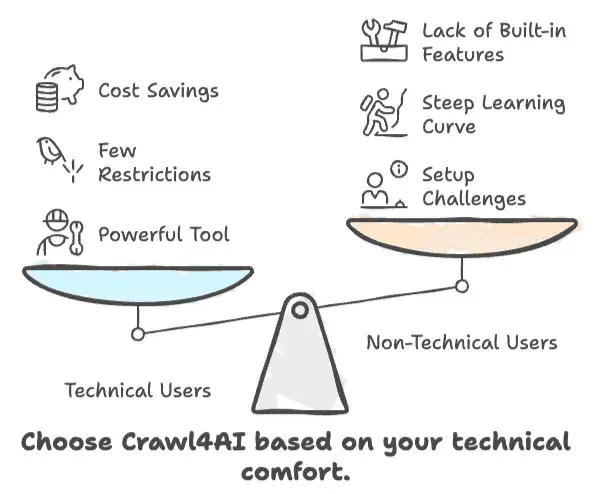
- crawl4ai ist schnell, flexibel und kostenlos – aber nur, wenn du mit Code umgehen kannst.
- Nicht-technische Nutzer kämpfen mit Einrichtung, Lernkurve und fehlenden eingebauten Business-Funktionen.
- Wenn du eine Point-and-Click-No-Code-Lösung brauchst, ist crawl4ai wahrscheinlich nichts für dich.
- Für Entwickler und KI-Praktiker ist es ein starkes Tool mit wenigen Einschränkungen.
- Für Business-Anwender können Zeit und Aufwand die Kostenvorteile überwiegen.
Thunderbit: der No-Code-KI-Web-Scraper für Business-Anwender
Nachdem wir gesehen haben, wo crawl4ai für nicht-technische Nutzer an seine Grenzen stößt, sprechen wir über eine bessere Alternative: Thunderbit.
Thunderbit ist eine KI-gestützte Chrome-Erweiterung für Web-Scraping, eigens für Business-Anwender entwickelt – also für Profis aus Vertrieb, Marketing, E-Commerce und Immobilien, die Daten von jeder Website schnell extrahieren wollen, ganz ohne Programmierung. Ich habe viele Scraping-Tools getestet, und Thunderbit hebt sich durch seine Einfachheit und Leistungsfähigkeit ab.
Was unterscheidet Thunderbit?
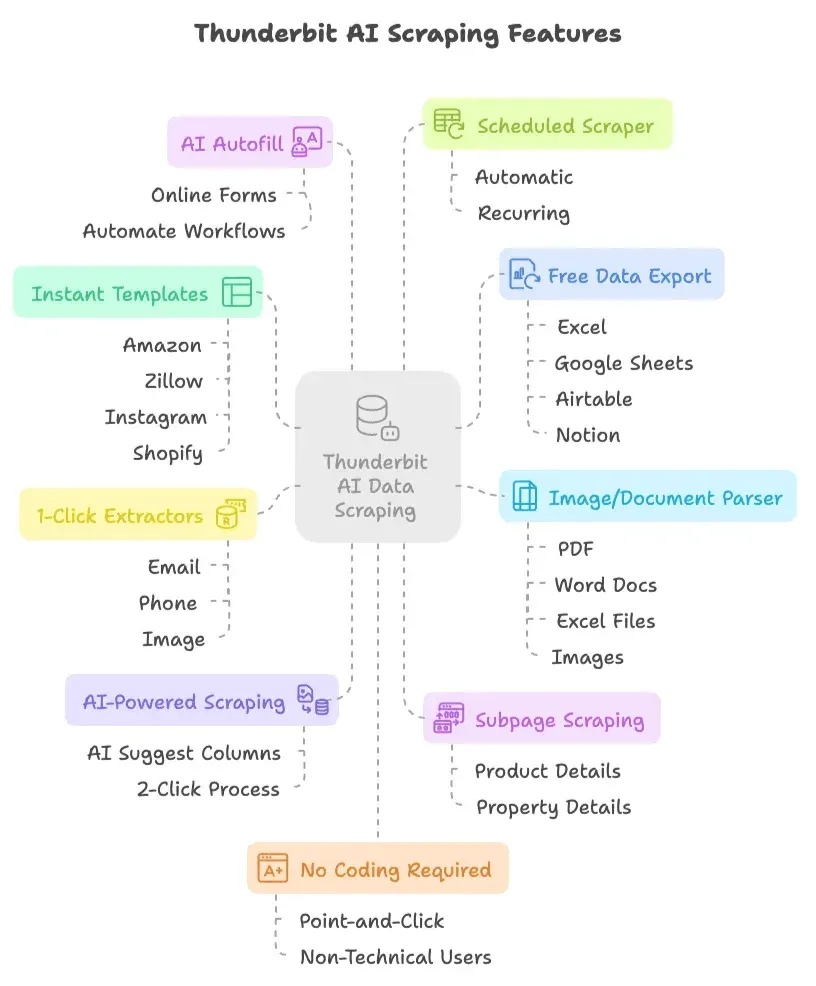
- KI-gestütztes Scraping in 2 Klicks: Klick auf „KI-Spaltenvorschlag“, lass die KI empfehlen, was extrahiert werden soll, und klick dann auf „Scrapen“. Mehr braucht es nicht. Keine Skripte, keine Selektoren, kein Stress.
- Subpage-Scraping: Thunderbits KI besucht automatisch Unterseiten (z. B. Produkt- oder Immobiliendetails) und reichert deine Datentabelle an, ganz ohne manuelle Einrichtung.
- Sofort nutzbare Vorlagen: Für beliebte Seiten wie Amazon, Zillow, Instagram und Shopify exportierst du Daten per Klick mit vorgefertigten Vorlagen.
- Kostenloser Datenexport: Exportiere deine Daten nach Excel, Google Sheets, Airtable oder Notion, ohne Aufpreis.
- KI-Autofill (komplett kostenlos): Lass die KI Online-Formulare ausfüllen und Abläufe automatisieren. Einfach den Kontext wählen, Thunderbit erledigt den Rest.
- Geplanter Scraper: Richte automatische, wiederkehrende Scrapes per einfachem Zeitplan ein, ohne Cronjobs oder Server-Setup.
- E-Mail-, Telefon- und Bild-Extraktor mit 1 Klick: Zieh E-Mails, Telefonnummern oder Bilder sofort von jeder Website.
- Bild- und Dokument-Parser: Extrahiere Tabellen aus PDFs, Word-Dokumenten, Excel-Dateien oder Bildern. Datei hochladen, KI die Daten strukturieren lassen und auf „Scrapen“ klicken.
- Keine Programmierung nötig: Alles ist Point-and-Click und für nicht-technische Nutzer gemacht.
Daten von jeder Website mit KI scrapen Get Started Free
Thunderbit will Webdaten für alle zugänglich machen – nicht nur für Entwickler. Du willst sehen, wie es funktioniert? Schau dir die Download-Seite der Thunderbit Chrome-Erweiterung an oder stöbere im Thunderbit-Blog nach echten Anwendungsfällen.
Thunderbit KI-Web-Scraper kostenlos testen
Die Preispläne von Thunderbit
Thunderbit nutzt ein einfaches Creditsystem: 1 Credit = 1 Ausgabezeile. So sehen die Pläne aus:
| Stufe | Monatlicher Preis | Jahrespreis (pro Monat) | Credits (monatlich) |
|---|---|---|---|
| Kostenlos | Kostenlos | Kostenlos | 6 Seiten |
| Starter | 15 $ | 9 $ | 500 |
| Pro 1 | 38 $ | 16,5 $ | 3.000 |
| Pro 2 | 75 $ | 33,8 $ | 6.000 |
| Pro 3 | 125 $ | 68,4 $ | 10.000 |
| Pro 4 | 249 $ | 137,5 $ | 20.000 |
Du kannst kostenlos starten und bis zu 6 Seiten extrahieren (oder 10 mit einer kostenlosen Testphase). Bezahlte Pläne schalten mehr Credits und erweiterte Funktionen frei, doch selbst der kostenlose Tarif ist für gelegentliche Nutzung großzügig. Mehr Details findest du auf der Thunderbit-Preisübersicht.
Thunderbit gegen crawl4ai: der direkte Vergleich
Die folgende Gegenüberstellung von Thunderbit und crawl4ai zeigt, worin jedes Tool stark ist und wo Thunderbit Business-Anwendern das Leben leichter macht.
| Funktion / Kriterium | Thunderbit | crawl4ai |
|---|---|---|
| No-Code-, Point-and-Click-Oberfläche | ✅ | ❌ |
| KI-Spaltenvorschlag (Auto-Erkennung) | ✅ | ❌ |
| Subpage-Scraping (automatisch) | ✅ | ❌ |
| Sofortvorlagen (Amazon usw.) | ✅ | ❌ |
| Kostenloser Datenexport (Excel, Sheets) | ✅ | ❌ |
| KI-Autofill (Formularausfüllung) | ✅ | ❌ |
| Geplantes Scraping (ohne Code) | ✅ | ❌ |
| E-Mail-/Telefon-/Bild-Extraktion mit 1 Klick | ✅ | ❌ |
| Tabellenextraktion aus Bildern/Dokumenten | ✅ | ❌ |
| Umgang mit dynamischen Inhalten | ✅ | ✅ |
| Open Source | ❌ | ✅ |
| Erfordert Programmierung | ❌ | ✅ |
| Kostenloser Tarif verfügbar | ✅ | ✅ |
| Community-Support | ✅ | ⚠️ (begrenzt) |
| Für Business-Anwender gemacht | ✅ | ❌ |
| Für Entwickler gemacht | ⚠️ | ✅ |
| Preis | $ (kostenlos & bezahlt) | Kostenlos |
| Kundensupport | ✅ | ❌ |
Legende:
✅ = Ja
❌ = Nein
⚠️ = Begrenzt / teilweise
$ = Bezahlte Pläne verfügbar
Fazit
Bist du Entwickler, experimentierst gern mit Code und willst die volle Kontrolle, ist crawl4ai ein starkes, kostenloses Tool für Web-Scraping im großen Maßstab. Bist du dagegen Business-Anwender – besonders in Vertrieb, Marketing, E-Commerce oder Immobilien – und willst einfach ohne Aufwand an Daten kommen, ist Thunderbit der klare Gewinner. Es ist für nicht-technische Nutzer gebaut, mit KI-gestützter Automatisierung, Sofortvorlagen und einer Oberfläche, die dich in Sekunden von der Website zur Tabelle bringt.
Mit Thunderbit jede Website scrapen
FAQs
1. Wie schneidet Thunderbit im Vergleich zu anderen KI-Web-Scrapern wie crawl4ai ab?
Thunderbit ist für nicht-technische Nutzer entwickelt und bietet eine No-Code-Point-and-Click-Oberfläche, während crawl4ai eine entwicklerorientierte Open-Source-Python-Bibliothek ist. Thunderbit automatisiert komplexe Aufgaben mit KI und macht Web-Scraping für alle zugänglich.
2. Welche einzigartigen Funktionen bietet Thunderbit für Business-Anwender?
Thunderbit bietet KI-gestützte Spaltenvorschläge, Subpage-Scraping, Sofortvorlagen für beliebte Websites und kostenlosen Export nach Excel oder Google Sheets – alles ohne Programmierung. Hinzu kommen geplantes Scraping und 1-Klick-Extraktoren für E-Mails, Telefonnummern und Bilder.
3. Kann Thunderbit komplexe Datenextraktion wie PDFs oder Bilder bewältigen?
Auf jeden Fall. Thunderbits KI extrahiert Tabellen aus PDFs, Word-Dokumenten, Excel-Dateien und Bildern. Lade einfach deine Datei hoch, lass die KI die Daten strukturieren und klick auf „Scrapen“ für sofortige Ergebnisse. Mehr dazu im Thunderbit-Blog.
Mehr erfahren
- Was ist Data Scraping und wie macht man es 2025? – Thunderbit Blog
- Die besten Web-Scraper-Tools & Software 2025 – Thunderbit Blog
- Die besten KI-Tools zur Datenerfassung für modellbereite Datensätze – Medium
- Wie KI-Web-Scraper bei Datenextraktion und Analyse helfen können – Forbes
KI-Web-Scraper testen Get Started Free




