Dein CRM ist nur so stark wie die Daten, die du reinpackst. Und die richtig guten Daten findest du draußen auf öffentlichen Websites – nicht in überteuerten Drittanbieter-Datenbanken.
web extractor-Tools machen aus chaotischem Web-Kram saubere Tabellen. Die guten schaffen das in ein paar Minuten – komplett ohne Code.
Ich habe diese Tools in echten Projekten genutzt: Lead-Listen bauen, Wettbewerberpreise beobachten, Produktkataloge rausziehen. Hier sind 12, die sich wirklich bewährt haben – sortiert danach, wie gut sie bei echten Business-Aufgaben abliefern.
Warum Web-Extractor für Unternehmen unverzichtbar sind
Mal ehrlich: Das Web ist die größte (und gleichzeitig chaotischste) Datenbank der Welt. Und 2026 ziehen genau die Unternehmen davon, die dieses Durcheinander in klare Erkenntnisse verwandeln. Laut sind datengetriebene Firmen 5% produktiver und 6% profitabler als vergleichbare Unternehmen. Das ist kein „Messfehler“ – das ist ein echter Wettbewerbsvorteil.
Web-Extractor-Tools (auch als Webpage-Extractor oder web-extraktion-Lösungen bezeichnet) sind dabei der Hebel, der den Unterschied macht. Vertriebsteams können damit öffentliche Verzeichnisse, Social Media und Unternehmensseiten auslesen, um gezielte Prospect-Listen aufzubauen – statt veraltete Lead-Listen einzukaufen oder darauf zu hoffen, dass der Praktikant nicht mitten im Copy-Paste-Marathon hinschmeißt (). Marketing- und E-Commerce-Teams nutzen Web-Extractor, um Wettbewerberpreise zu tracken, Lagerbestände zu überwachen und Produkte in Echtzeit zu benchmarken – John Lewis zum Beispiel führt Web Scraping auf einen 4%igen Umsatzanstieg zurück, allein durch smartere Preisgestaltung ().
Aber es geht nicht nur um KPIs. Web-Extractor sparen brutal viel Zeit (ein Nutzer sprach von „Hunderten Stunden“, die durch automatisierte Datenerfassung weggefallen sind) und senken menschliche Fehler deutlich (). Operations-Teams setzen heute Scraper auf, die kontinuierlich Daten einsammeln, für die Praktikanten früher Wochen gebraucht hätten – und holen sich so Stunden zurück, die früher in stumpfes Copy-Paste geflossen sind (). Und dank KI-gestützter Extractor können selbst Nicht-Techniker Websites in strukturierte Daten für Analysen verwandeln ().
Unterm Strich: Wenn du 2026 keinen Web-Extractor nutzt, lässt du ziemlich sicher Insights (und Geld) auf dem Tisch liegen.
So haben wir die Top 12 Web-Extractor ausgewählt
Bei der Masse an Tools für web-extraktion stellt sich die Frage: Wie findest du das richtige? Ich habe Dutzende Optionen gecheckt – aber nur 12 haben es in diese Liste geschafft. Darauf habe ich besonders geachtet:
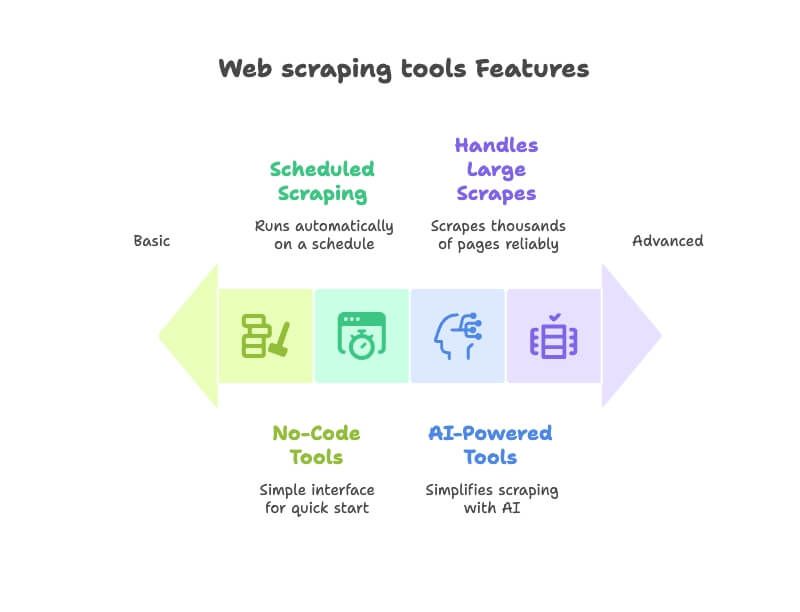
- Bedienbarkeit: Kommst du als Nicht-Techniker schnell rein, ohne Code zu schreiben? Ich habe No-Code- bzw. Low-Code-Tools mit intuitiver Oberfläche bevorzugt ().
- KI-Funktionen: Moderne Tools, die mit KI Scraping vereinfachen – z. B. automatische Felderkennung, Navigation über Seiten hinweg oder Anforderungen in normaler Sprache beschreiben ().
- Automatisierung & Zeitpläne: Die besten Web-Extractor laufen im Autopilot. Ich habe Tools gewählt, die wiederkehrende Scrapes oder Website-Monitoring per Zeitplan unterstützen ().
- Export & Integrationen: Lässt sich easy nach Excel, Google Sheets, Airtable oder Notion exportieren? Extra-Punkte gab’s für Workflow-Integrationen ().
- Skalierung & Zuverlässigkeit: Egal ob eine Seite oder Tausende – die Tools müssen das packen. Außerdem habe ich Reviews zur Stabilität mit einbezogen.
- Business-nahe Use Cases: Fokus auf Tools, die bei Sales, Marketing, E-Commerce und Operations beliebt sind – nicht nur bei Entwicklern.
Einige Tools sind KI-Newcomer, andere echte Klassiker. Alle helfen dir dabei, das Web zu deiner eigenen Business-Datenbank zu machen – ohne Stress.
Schnellvergleich: Web-Extractor-Tools auf einen Blick
Hier ist eine Übersicht der 12 Web-Extractor-Tools, die ich vorstelle – damit du sofort siehst, wie sie sich einordnen:
| Tool | KI-Automatisierung | Bedienbarkeit | Bester Einsatzfall |
|---|---|---|---|
| Thunderbit | Ja – KI schlägt Felder vor und verarbeitet Seiten automatisch | Sehr einfach (Chrome-Erweiterung, kein Code) | Schnelles Scraping für Leads, Preise usw. für Nicht-Techniker, die in Minuten Ergebnisse wollen. |
| Octoparse | Begrenzt (template-basiert, keine KI) | Für die meisten einfach (visuelles Drag-and-drop) | Individuelle Scraping-Workflows (mit Logins, Paginierung) für Analysten, die Kontrolle ohne Programmierung wollen. |
| Browse AI | Teilweise – Point-and-Click-„Robots“ | Einfach (No-Code, cloudbasiert) | Automatisches Monitoring von Daten (Preise, Listings etc.) nach Zeitplan, mit Alerts und Integrationen. |
| WebScraper.io | Nein (manuelle Konfiguration) | Mittel (Browser-Extension mit Sitemap-Setup) | Visuelles Scraping mehrstufiger Websites für Nutzer, die Schritte konfigurieren möchten. |
| ScraperAPI | k. A. (API-Service, Proxies via API) | Erfordert Coding (API-Integration) | High-Volume-Webdatenextraktion für Tech-Teams – Proxies & CAPTCHAs für Scrapes im großen Maßstab. |
| Data Miner | Nein | Sehr einfach (Browser-Extension mit One-Click-Templates) | Schnelle Einmal-Extraktion von Daten (v. a. Tabellen/Listen) direkt nach CSV/Excel. |
| Simplescraper | Nein (einige KI-unterstützte Features) | Einfach (Point-and-Click-Rezept-Builder) | No-Code-Scraping mit Integrationen – ideal für Google Sheets, Airtable oder API. |
| Instant Data Scraper | Ja – erkennt Datentabellen automatisch | Sehr einfach (klicken, keine Einrichtung) | Sofortiges, kostenloses Scraping von HTML-Tabellen und Listen für schnelle Datenabzüge. |
| ScrapeStorm | Ja – KI erkennt Seitenelemente | Einfach (visuelle Oberfläche; plattformübergreifende App) | Große oder komplexe Scraping-Projekte ohne Code, inkl. geplanter Crawls. |
| Apify | Teilweise – vorgefertigte „Actor“-Bots verfügbar | Mittel (Web-UI; Coding optional) | Skalierbares Cloud-Scraping und Automatisierung mit fertigen oder eigenen Skripten. |
| ParseHub | Nein (ohne Skripte, aber manuelles Setup) | Für Basics einfach (visueller Editor; Desktop-App) | Scraping dynamischer/komplexer Sites (AJAX) über eine No-Code-Oberfläche. |
| OutWit Hub | Nein | Einfach (Desktop-GUI) | Einfache, lokale Datenextraktion und Content-Archivierung für kleinere Projekte. |
Die meisten Tools bieten eine kostenlose Stufe oder Testphase sowie gestaffelte Abos. Der Fokus liegt hier auf Funktionen und Use Cases – nicht auf dem Preis.
Thunderbit: Der KI-Web-Extractor für alle

Starten wir mit Thunderbit – ja, das ist mein Baby, aber gib mir kurz eine Chance. Die Branche bewegt sich weg von „Bau dir deinen Scraper zusammen“ hin zu „Sag der KI einfach, was du brauchst“. Thunderbit ist das erste Tool, das ich gesehen habe (und mitentwickeln durfte), das sich wirklich wie ein KI-Datenassistent anfühlt – nicht wie der nächste „Crawler“.
Mit musst du dich nicht mit XPath, CSS-Selektoren oder Regex rumschlagen. Du sagst einfach in normalem Deutsch, welche Daten du willst – zum Beispiel „Hole Titel, Autor und Datum von dieser Seite“ – und Thunderbits KI macht den Rest (). Klick auf „AI Suggest Fields“, und Thunderbit liest die Seite, schlägt Spalten vor und verarbeitet sogar Unterseiten und Paginierung automatisch ().
Und es bleibt nicht beim Einsammeln. Thunderbit kann Daten während des Scrapings bereinigen, umformen, kategorisieren und sogar übersetzen. Telefonnummern vereinheitlichen, Beschreibungen zusammenfassen oder Produktnamen übersetzen? Ein kurzer Hinweis reicht – die KI übernimmt. Danach exportierst du direkt nach Excel, Google Sheets, Airtable oder Notion ().
Was Thunderbit wirklich abhebt: keine Einrichtung, keine Lernkurve. Als Chrome-Erweiterung bist du in Sekunden startklar. Keine Plugins, keine Konfiguration, kein Tech-Gelaber. Deshalb ist es besonders beliebt bei Sales-, Marketing- und Operations-Teams, die schnell Ergebnisse brauchen (). Die kostenlose Stufe deckt den kompletten Workflow zum Ausprobieren ab, und die bezahlten Pläne sind für die meisten Teams gut machbar.
Wenn du erleben willst, wie sich KI-Web-Extraktion anfühlt, lade die runter und teste sie. Vielleicht sind deine Copy-Paste-Tage damit wirklich gezählt.
Octoparse: Visueller Web-Extractor für individuelle Workflows
Octoparse ist ein Klassiker im visuellen Web-Scraping. Es ist eine Desktop-App mit Point-and-Click-Oberfläche: Du gehst auf der Website rum, markierst die Daten, die du brauchst, und Octoparse baut dir im Hintergrund den Workflow zusammen (). Logins, Paginierung und sogar Formular-Automatisierung gehen ohne Code.
Richtig stark ist Octoparse durch seine Bibliothek mit 500+ fertigen Templates für bekannte Seiten (Amazon, Twitter, LinkedIn usw.). Oft lädst du einfach ein Template und legst direkt los (). Für komplexere Sites kannst du in den manuellen Modus wechseln und jeden Schritt visuell festzurren. Octoparse kann Inhalte scrapen, die erst nach Klicks oder Scrollen laden, unterstützt Proxies und löst CAPTCHAs für anspruchsvollere Jobs. Zusätzlich gibt’s eine Cloud-Option für Zeitpläne und größere Läufe.
Der Haken: Du brauchst etwas Einarbeitung – vor allem bei fortgeschrittenen Szenarien. Für Nicht-Programmierer und Datenanalysten, die maßgeschneiderte Scraping-Workflows ohne Code wollen, ist Octoparse aber eine sehr stabile Wahl ().
Browse AI: Automatisierte Web-Extraktion mit vorgefertigten Robots
Browse AI geht das Ganze eher spielerisch an: Du trainierst einen „Robot“, indem du per Klick die gewünschten Daten markierst, und er lernt, diese Infos auf ähnlichen Seiten wieder rauszuziehen (). Das läuft komplett in der Cloud und ohne Code – keine Skripte, keine Server.
Das Besondere bei Browse AI ist die Automatisierung und das Monitoring. Du kannst Robots regelmäßig laufen lassen und Benachrichtigungen bekommen, wenn sich Daten ändern (z. B. wenn ein Wettbewerber den Preis senkt oder ein neues Job-Listing auftaucht). Außerdem gibt’s eine Bibliothek mit vorgefertigten Robots für typische Aufgaben – oft startest du mit einer fertigen Lösung und passt nur noch Kleinigkeiten an ().
Browse AI integriert sich über Zapier und Make mit Tausenden Apps und exportiert direkt nach Google Sheets oder per API/Webhooks (). Ideal für laufendes Monitoring und wiederkehrende Datenerfassung, wenn du Alerts und Integrationen möglichst „hands-off“ willst.
WebScraper.io: Browserbasierter Webpage-Extractor

WebScraper.io (oft einfach „Web Scraper“) ist eine Browser-Erweiterung, mit der du „Sitemaps“ baust – also visuelle Pläne, wie eine Website abgeklappert wird und welche Elemente rausgezogen werden sollen (). Du definierst Selektoren für Daten und Links (z. B. „Next“-Button für Paginierung oder „öffne jedes Produkt für Details“).
Es braucht etwas Einarbeitung, aber ohne Programmierung: Du klickst Elemente an und legst Aktionen fest. Web Scraper unterstützt mehrstufige Navigation, Paginierung und sogar Infinite Scroll (die Schritte musst du allerdings manuell definieren). Weil es im Browser läuft, kannst du auch Seiten hinter einem Login scrapen, indem du dich einfach selbst einloggst.
WebScraper.io passt gut für „Citizen Data Analysts“, die sich mit Seitenstrukturen wohlfühlen und ein kostenloses, flexibles Tool suchen. Ein zuverlässiges Arbeitstier – wenn du bereit bist, deine Sitemaps selbst zu bauen.
ScraperAPI: API-first Web-Extractor für Entwickler und Teams
Nicht jedes Team will eine Klick-Oberfläche – manchmal brauchst du eine Backend-Lösung, die Webdaten direkt in Apps oder Datenbanken schiebt. ScraperAPI ist ein API-first Web-Extractor: Du gibst eine URL rein und bekommst HTML oder extrahierte Daten zurück – inklusive Proxy-Handling, Geo-IP-Rotation, Headless Browser und CAPTCHA-Lösung ().
ScraperAPI betreibt einen Pool von über 40 Millionen Proxies in 50+ Ländern und verarbeitet 36 Milliarden Requests pro Monat (). Optimal für Scraping im großen Maßstab, wenn Zuverlässigkeit und Anti-Blocking entscheidend sind. Du brauchst dafür Coding-Know-how – aber für Datenpipelines oder Produkt-Integrationen ist ScraperAPI eine Top-Option.
Data Miner: Chrome-Erweiterung für schnelle Webpage-Extraktion

Data Miner ist eine Chrome-Erweiterung für Business-Anwender und Researcher, die schnell Daten ziehen müssen. Sie bietet ein Point-and-Click-Erlebnis und eine Bibliothek mit fertigen „Recipes“ für typische Muster wie Tabellen, Listen oder bestimmte Websites ().
Du installierst die Extension, öffnest die Zielseite und klickst auf das Data-Miner-Icon. Dann nimmst du ein Recipe oder baust dir eins, indem du Elemente markierst. Perfekt für Einmal-Aufgaben oder spontane Datenbedarfe – etwa wenn Sales schnell Leads aus einem Verzeichnis ziehen oder E-Commerce Wettbewerberpreise vergleichen will.
Data Miner ist unkompliziert, direkt im Browser und ideal für interaktives, on-demand Scraping.
Simplescraper: No-Code Web-Extractor für schnelle Ergebnisse

Simplescraper macht seinem Namen wirklich alle Ehre. Es ist eine No-Code Chrome-Erweiterung (plus Web-App), mit der du Daten auf einer Seite visuell auswählst und daraus ein „Recipe“ für die Extraktion baust (). Du kannst Links folgen, Unterseiten scrapen, Paginierung abarbeiten und deinen Scrape sogar mit einem Klick als API-Endpunkt bereitstellen.
Stark ist Simplescraper bei den Integrationen: Daten direkt nach Google Sheets, Airtable oder via Zapier weiterreichen (). Dazu kommen Cloud-Scraping und Zeitpläne für wiederkehrende Jobs sowie „AI Enhance“, um Daten mit GPT zu bereinigen oder zu analysieren.
Wenn du schnelle Ergebnisse plus einfache Integrationen willst, ist Simplescraper so etwas wie das Schweizer Taschenmesser unter den leichten Scraping-Tools.
Instant Data Scraper: Schnelle Web-Extraktion für Tabellen und Listen
Manchmal brauchst du Daten sofort – ohne Setup. Genau dafür gibt es Instant Data Scraper (IDS). Eine kostenlose Chrome-Erweiterung, bekannt für One-Click-Scraping von Tabellendaten (). Aktivieren, und IDS erkennt automatisch Tabellen oder Listen. Paginierung und Infinite Scroll werden oft ebenfalls automatisch abgearbeitet.
IDS ist 100% kostenlos, ohne Anmeldung, ohne Code, ohne Wartezeit. Ideal für spontane oder dringende Scraping-Aufgaben – z. B. wenn Sales schnell eine Lead-Liste braucht oder Studierende Wikipedia-Tabellen exportieren. Wenn IDS deine Daten erkennt, hast du sie in Sekunden.
ScrapeStorm: Cloudbasierter Web-Extractor mit KI-Unterstützung
ScrapeStorm ist ein KI-gestütztes Web-Scraping-Tool, das eine visuelle Oberfläche mit starken Algorithmen kombiniert (). Du gibst eine URL ein, und die KI erkennt automatisch Datenfelder – Listen, Tabellen, Next-Buttons und mehr.
ScrapeStorm läuft plattformübergreifend (Windows, Mac, Linux) und bietet Desktop- sowie Cloud-Scraping. Du kannst Aufgaben planen, mehrere Jobs parallel laufen lassen und nach Excel, CSV oder JSON exportieren oder direkt in eine Datenbank schreiben (). Besonders beliebt ist es für E-Commerce und Marktforschung; per KI kann es sogar Daten aus Bildern oder PDFs auslesen.
Wenn du für große oder komplexe Projekte einen smarten Assistenten suchst, lohnt sich ScrapeStorm.
Apify: Web-Extractor-Marktplatz und Automatisierungsplattform

Apify ist nicht nur ein Scraper, sondern eine Plattform für Web Scraping und Automatisierung. Du nutzt sogenannte „Actors“ – Skripte für Scraping oder Browser-Automation. Der Clou ist der Marktplatz mit vorgefertigten Actors für typische Aufgaben (). Alle Reviews eines Shops extrahieren? Sehr wahrscheinlich gibt’s dafür schon einen Actor.
Für Entwickler bietet Apify die Möglichkeit, eigene Scraper in Node.js oder Python zu schreiben und in der Cloud zu betreiben. Es ist skalierbar, automatisierbar und per API integrierbar. Apify passt am besten zu Power-Usern und Organisationen, die Webdaten als strategische Ressource sehen – also laufende, großvolumige Extraktion oder Integration in Datenpipelines.
ParseHub: Visueller Webpage-Extractor für komplexe Websites

ParseHub ist eine Desktop-App (mit Cloud-Optionen), die für komplexe, dynamische Websites bekannt ist. Du navigierst in einer browserähnlichen Oberfläche, klickst Datenpunkte an, und ParseHub baut daraus deinen Scraper (). Unterstützt werden Bedingungslogik, verschachteltes Scraping, AJAX-Inhalte und mehr.
ParseHub ist oft die Wahl, wenn andere Tools an einer Website scheitern. Es wird von Researchern, Analysten und kleinen Unternehmen genutzt, die schwierige Seiten knacken müssen. Es gibt eine Lernkurve – aber wenn du eine komplexe Site ohne Code scrapen willst, ist ParseHub eine Top-Option.
OutWit Hub: Desktop-Web-Extractor für Content-Archivierung

OutWit Hub ist etwas oldschool, aber als Desktop-Anwendung super praktisch, wenn du viele unterschiedliche Content-Typen (Links, Bilder, E-Mail-Adressen usw.) sammeln und organisieren willst (). Es fühlt sich an wie eine Mischung aus Browser und Spreadsheet: Seite öffnen, und OutWit Hub kann Tabellen, Listen, Bilder und mehr extrahieren.
Besonders nützlich ist es für Content-Archivierung oder Recherche – z. B. alle Beiträge eines Forums sichern oder eine Dateisammlung herunterladen. Da es lokal läuft, bleiben deine Daten bei dir. OutWit Hub eignet sich am besten für kleine bis mittlere Scraping-Aufgaben mit einer klaren Desktop-Oberfläche.
Welcher Web-Extractor passt am besten zu dir?
Zwölf Tools, unzählige Szenarien. Welchen Web-Extractor solltest du wählen? Hier mein Spickzettel:
-
Für absolute Einsteiger oder schnelle Einmal-Aufgaben:
Nimm Instant Data Scraper für einfache Tabellen und Listen (kostenlos und sofort). Data Miner ist ebenfalls sehr zugänglich und bietet mehr Templates, wenn du häufig ähnliche Seiten extrahierst.
-
Für Nicht-Techniker mit wiederkehrendem Bedarf oder Integrationen:
Thunderbit bietet den einfachsten Workflow dank KI – ideal für Business-Teams, die schnell und regelmäßig Ergebnisse brauchen. Browse AI ist stark für kontinuierliches Monitoring und Alerts. Simplescraper ist super, wenn Daten direkt nach Google Sheets oder per API in eine interne App fließen sollen.
-
Für komplexe Websites oder individuelle Workflows ohne Programmierung:
Greif zu visuellen Tools wie Octoparse oder ParseHub. Octoparse ist zugänglich und hat viele Templates. ParseHub kommt mit sehr dynamischen Sites klar und bietet feine Kontrolle. WebScraper.io ist ebenfalls stark, wenn du deine Sitemaps selbst konfigurieren möchtest.
-
Für Entwickler oder Data Engineers mit Skalierungsbedarf:
ScraperAPI ist gemacht dafür, Web Scraping in Software zu integrieren oder großvolumige Projekte stabil zu fahren. Apify passt, wenn du eine skalierbare Plattform mit Marktplatz für fertige oder eigene Skripte brauchst.
-
Für contentlastige Extraktion oder Offline-Nutzung:
OutWit Hub ist eine gute Wahl, um Inhalte systematisch zu sammeln und zu archivieren – besonders, wenn du aus Datenschutz- oder Kontrollgründen lieber lokal arbeitest.
Viele Teams nutzen ehrlich gesagt mehrere Tools – je nach Aufgabe. Du startest vielleicht mit Instant Data Scraper für etwas Einfaches, wechselst zu Thunderbit oder Octoparse für ein größeres Projekt und setzt ScraperAPI oder Apify ein, wenn du den Prozess industrialisieren willst. Die gute Nachricht: Die meisten Tools bieten Free-Tiers oder Trials – du kannst also testen, was wirklich passt.
Fazit: Die Zukunft der Web-Extraktion für Business-Teams
Web-Extractor haben sich extrem weiterentwickelt – und 2026 sind sie endgültig im Mainstream angekommen. Der große Trend: Web Scraping wird einfacher, stärker automatisiert und tiefer in tägliche Workflows integriert (). KI-getriebene Scraper machen selbst komplexe, dynamische Websites beherrschbar – ohne Spezialwissen. Wie es ein Data Engineer formulierte: „Seit KI-Web-Scraping-Tools auf dem Markt sind, kann ich Aufgaben viel schneller und in größerem Umfang erledigen … mit KI ist [Datenbereinigung] automatisch Teil meines Workflows.“
Ein weiterer Shift: Die Grenzen zwischen Scraping, Monitoring und Automatisierung verschwimmen. Tools wie Browse AI und Thunderbit extrahieren nicht nur Daten, sondern halten sie aktuell und können sogar Aktionen auslösen (z. B. Formulare ausfüllen oder Alerts triggern). Der Adoption-Schub ist real – eine große Plattform verzeichnete über 140% Wachstum bei monatlich aktiven Nutzern innerhalb eines Jahres (). Unternehmen jeder Größe merken: Zugriff auf öffentliche Webdaten (ethisch und rechtlich sauber) ist entscheidend, um konkurrenzfähig zu bleiben.
Für Business-Teams heißt das vor allem mehr Selbstbestimmung: Du musst nicht Wochen auf Entwickler warten oder Entscheidungen aus dem Bauch heraus treffen. Die Tools in dieser Liste bringen Webdaten in deine Hände – mit Oberflächen und Features, die auf echte Use Cases in Sales, Marketing, Operations und darüber hinaus zugeschnitten sind. Und bei dem Tempo, das wir gerade sehen, erwarte ich bald noch nutzerfreundlichere UIs, smartere KI und tiefere Integrationen mit BI- und Analytics-Plattformen.
Wichtig: Respektiere die Nutzungsbedingungen von Websites und robots.txt-Regeln und stell sicher, dass du Datenschutzgesetze einhältst. Ethisches Scraping ist entscheidend, damit das Ganze langfristig sauber bleibt.
Egal ob du mit einer kostenlosen Extension startest oder eine Enterprise-Scraping-Flotte ausrollst: Es war nie einfacher, Webinfos in umsetzbare Insights zu verwandeln. Die Web-Extractor-Revolution ist da – wähle ein Tool, probier’s aus und heb den Wert, der offen sichtbar im Web steckt. Deine datengetriebene Zukunft ist nur einen Klick entfernt.
FAQs
1. Was ist ein Web-Extractor und warum ist er für Unternehmen wichtig?
Ein Web-Extractor ist ein Tool, das strukturierte Daten automatisch von Websites erfasst. Für Unternehmen ist das wichtig, weil sich damit unübersichtliche Online-Informationen in verwertbare Erkenntnisse verwandeln lassen – das steigert Produktivität, erhöht Profitabilität und ersetzt manuelle Datenerfassung.
2. Wer kann Web-Extractor nutzen – brauche ich technische Kenntnisse?
Für viele moderne Web-Extractor brauchst du keine technischen Kenntnisse. Tools wie Thunderbit, Browse AI und Instant Data Scraper sind für Nicht-Techniker gebaut: intuitive Oberflächen, KI-Automatisierung und No-Code-Workflows.
3. Wie profitieren Sales-, Marketing- und Operations-Teams von Web-Extractoren?
Sales kann Lead-Listen aus Online-Verzeichnissen erstellen, Marketing kann Wettbewerberpreise überwachen, und Operations kann Datenerfassungsprozesse automatisieren. Das spart Zeit, reduziert Fehler und liefert aktuelle, verlässliche Insights für strategische Entscheidungen.
4. Worauf sollte ich bei der Auswahl eines Web-Extractor-Tools achten?
Wichtige Kriterien sind Bedienbarkeit, KI-Funktionen, Automatisierung/Planung, Integrationen (z. B. Google Sheets oder Airtable), Skalierbarkeit und Passung zu deinem Use Case (z. B. Leads, Preis-Monitoring, Content-Archivierung).
5. Gibt es kostenlose oder günstige Web-Extractor-Tools?
Ja. Viele Web-Extractor bieten Free-Tiers oder günstige Einstiegspläne. Instant Data Scraper ist für Basisfälle komplett kostenlos. Tools wie Thunderbit, Simplescraper und Data Miner haben großzügige kostenlose Pläne und Upgrade-Optionen.
Du willst tiefer einsteigen – in web-extraktion, KI-Scraping oder wie Websites zum nächsten Wettbewerbsvorteil deines Teams werden? Im findest du weitere Guides, Tipps und Praxisberichte aus der Datenautomatisierung.