

Před pár měsíci se mě kolega z obchodního týmu zeptal na otázku, kterou slýchám už desítkykrát: „Když si z veřejného webu stáhnu ceny konkurence, můžu mít z toho skutečně problém?“ Našel adresář kontaktů na dodavatele, ceny hezky srovnané do řádků a chtěl z toho jen tabulku. Váhání bylo skutečné — a upřímně, oprávněné.
Ve Spojeném království neexistuje jeden jediný „zákon o web scrapingu“. Místo toho o tom, jestli je konkrétní scraping legální, rozhodují čtyři překrývající se právní rámce. Proto je odpověď vždycky „záleží“ — ale nemusí to být paralyzující. V tomhle průvodci projdu, co zákon ve skutečnosti říká, jak se vztahuje na reálné situace, jaké hrozí sankce a jak zůstat v souladu s pravidly.
Pro náš tým v Thunderbit jsem tímhle tématem strávil spoustu času a chci se s vámi podělit o to, co jsem zjistil, abyste to nemuseli skládat z pěti různých blogů advokátních kanceláří a jednoho vlákna na Redditu.
Vyzkoušet Thunderbit pro web scraping
Co je web scraping (a proč ho britské firmy používají)
Web scraping je používání softwaru k automatickému sběru dat z webových stránek — tedy náhrada za úmorné kopírování a vkládání z webu do tabulky.
Sama technika je neutrální. Není sama o sobě legální ani nelegální. Záleží na tom, co scrapujete, jak k tomu přistupujete a co s daty uděláte potom.
Britské firmy používají scraping pro spoustu legitimních účelů:
- Porovnávání cen: například PriceSpy UK aktualizuje ceny produktů třikrát až pětkrát denně pomocí automatizovaného web scrapingu.
- Lead generation: obchodní týmy stahují názvy firem, e-maily a telefonní čísla z veřejných adresářů.
- Průzkum trhu: analytici sledují nabídky nemovitostí, pracovní portály nebo sortiment konkurence.
- Akademický výzkum: Úřad pro národní statistiku shromáždil mezi lety 2014 a 2015 přes 2,2 milionu cenových nabídek z webů supermarketů.
- Trénování AI modelů: rychle rostoucí — a právně stále nejasný — případ použití.
Trend je jasný. Průzkum Bright Data/Vanson Bourne mezi 500 rozhodovateli (z toho 200 ve Spojeném království) zjistil, že 89 % považuje veřejná webová data za klíčová nebo velmi důležitá pro globální ekonomiku a 38 % je získává alespoň denně.
Současně ale 73 % uvedlo, že je jejich organizace znepokojená nedostatkem jasné regulace. Přesně proto tenhle článek vznikl.
Je web scraping ve Spojeném království legální? Přímá odpověď
Žádný britský zákon web scraping výslovně nezakazuje. Různé zákony ale určují, jak se smí dělat, a zákonnost konkrétního projektu závisí na čtyřech faktorech:
- Jaká data scrapujete (osobní vs. faktická/ne-osobní data)
- Jak k nim přistupujete (veřejná stránka vs. obcházení přihlašování nebo CAPTCHA)
- Co říkají podmínky webu (zakazují automatizovaný přístup?)
- Jak data použijete potom (interní analýza vs. komerční další prodej)
Nejlepší přirovnání, na které jsem narazil: web scraping je jako fotografování na veřejném místě. Pořídit fotku na veřejnosti není automaticky nelegální — ale určité předměty, lokace, metody a způsoby použití vytvářejí právní riziko. U scrapingu je to podobné. To, že jsou data veřejně dostupná, je důležité, ale není to celý příběh.
Nedávná konzultace ICO k GenAI je jedním z nejjasnějších oficiálních britských vyjádření k web scraped osobním údajům. Uvedla, že oprávněný zájem zůstává jediným dostupným právním základem pro trénování generativních AI modelů pomocí web scraped osobních údajů — ale jen tehdy, pokud vývojář projde přísným tříkrokovým testem. To je vysoká laťka a ukazuje, jak vážně britští regulátoři k těmto datům přistupují.
Čtyři britské zákony, které se na web scraping vztahují
Jsou tu čtyři překrývající se „čočky“ — jakýkoli scrapingový projekt může spustit jednu, dvě nebo všechny čtyři.
UK GDPR a Data Protection Act 2018
Když scrapujete osobní údaje — jména, e-maily, telefonní čísla, IP adresy, profily na sociálních sítích — vztahuje se na vás UK GDPR. „Veřejně dostupné“ neznamená „volně použitelné“.
Veřejně viditelné osobní údaje jsou pořád osobní údaje.
Nejrelevantnější právní základ pro komerční scraping je oprávněný zájem (článek 6) — ale nestačí to jen mávnout rukou. Musíte:
- určit konkrétní, legitimní účel
- prokázat, že je zpracování pro tento účel nezbytné
- vyvážit svůj zájem proti právům jednotlivců, jejichž údaje sbíráte
Odpověď ICO ke konzultaci o GenAI je obzvlášť výstižná: vývojáři by neměli předpokládat, že širší společenský přínos stačí, měli by doložit, proč alternativy ke scrapingu nejsou vhodné, a měli by používat transparentní mechanismy, které lidem umožní porozumět zpracování a uplatnit svá práva. Zdroj: odpověď ICO ke GenAI.
Stejná logika platí i pro B2B lead generation. Obchodní tým se může spoléhat na oprávněný zájem při sběru veřejně uvedených firemních kontaktních údajů, ale stále musí dokumentovat legitimní zájem, minimalizovat rozsah sbíraných polí, vyhýbat se zvláštním kategoriím údajů, tam kde je to možné poskytnout informace o ochraně soukromí a respektovat opt-out.
Autorské právo, databázová práva a výjimka pro TDM
Autorské právo chrání původní obsah webu: texty, obrázky, popisy produktů, články. Faktické údaje, jako jsou ceny, samy o sobě obvykle nejsou na autorské právo tak citlivé — ale když chráněný obsah kopírujete a znovu publikujete, dostáváte se do oblasti porušení práv.
Databázová práva jsou pro scraping důležitější, než si většina lidí uvědomuje. Spojené království si po brexitu ponechalo sui generis práva k databázím ve stylu EU a vytažení „podstatné části“ chráněné databáze — kurátorovaných adresářů, katalogů produktů, marketplace nabídek — může být porušením i tehdy, když jednotlivé údaje samy o sobě jsou faktické.
Výjimka pro text mining a data mining (TDM) podle § 29A CDPA dovoluje kopie pro textovou a datovou analýzu jen tehdy, když má uživatel zákonný přístup a účel je nekomerční výzkum. To je úzké vymezení. Komerční scraping, komerční trénování AI ani komerční prodej datových sad sem nespadají.
Britská vláda zvažovala rozšíření této výjimky pro trénování AI, ale k březnu 2026 ve zprávě o autorském právu a AI se rozhodla nezavádět reformy, dokud si nebude jistá, že splňují cíle pro tvůrce, vývojáře AI i britskou ekonomiku. Za současného stavu je obvykle potřeba povolení ke kopírování chráněných děl pro trénování AI, pokud se neuplatní nějaká existující výjimka.
Podmínky webu a smluvní právo
Většina webů má obchodní podmínky, které automatizovaný scraping zakazují nebo omezují. Když na web přistoupíte, můžete už na tyto podmínky přistupovat — zejména když projdete potvrzovací obrazovkou (clickwrap). U „browsewrap“ dohod (podmínky schované v odkazu v patičce) záleží víc na konkrétních okolnostech, ale britské soudy už ukázaly ochotu vynucovat omezení scrapingu. Ve sporu Ryanair v. Billigfluege soud považoval viditelné webové podmínky v kontextu screen-scrapingu za závazné.
robots.txt není zákon. Je to strojově čitelný signál od provozovatele webu. Typický soubor vypadá takto:
User-agent: *
Disallow: /account/
Disallow: /checkout/
Disallow: /private/
Crawl-delay: 10
Ignorování robots.txt samo o sobě scraping nečiní nelegálním, ale soudy a ICO ho berou jako důkaz záměru vlastníka webu. Když ho ignorujete, zvyšujete své právní riziko, zejména pokud se k tomu přidá porušení podmínek nebo agresivní objem požadavků.
Computer Misuse Act 1990
Tahle část lidi budí ze spaní — a právem. Vytváří totiž trestné činy. § 1 pokrývá neoprávněný přístup k počítačovému materiálu (maximálně 2 roky odnětí svobody). § 3 pokrývá neoprávněné jednání, které narušuje provoz počítače (maximálně 10 let odnětí svobody).
Riziko podle CMA je nejnižší tam, kde jsou data skutečně veřejná a scraper neobchází technické překážky. Riziko roste, když:
- obcházíte přihlašování, CAPTCHA nebo IP blokace
- používáte ukradené přihlašovací údaje nebo zakládáte falešné účty
- posíláte takové objemy provozu, že narušíte cílovou službu
Spojené království nemá čisté pravidlo typu amerického „veřejná data jsou fair game“. Proto jsou britská doporučení opatrnější: veřejný přístup riziko podle CMA výrazně snižuje, ale webové podmínky, technické kontroly a to, zda scraper ví o omezeních, pořád hrají roli.
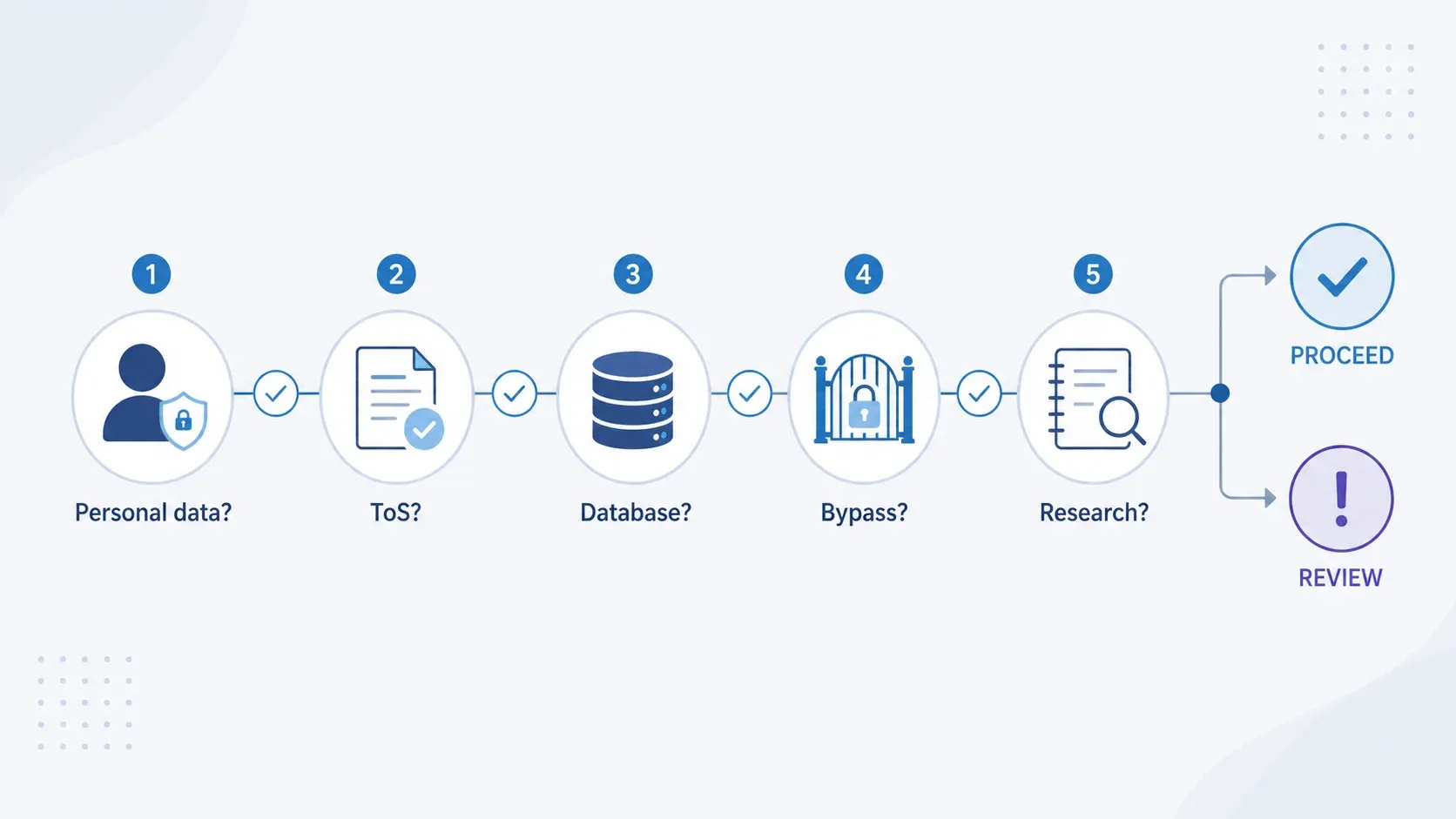
„Můžu to scrapeovat legálně?“ — rychlý rozhodovací strom
Než začnete cokoli scrapovat, projděte si těchto pět rozhodovacích bodů. Nejde o právní radu — jen o 60sekundové předběžné zhodnocení rizika.
| Rozhodovací bod | Když ANO | Když NE |
|---|---|---|
| Jsou data osobní údaje (jména, e-maily atd.)? | Platí UK GDPR. Určete právní základ, proveďte LIA, minimalizujte pole, plánujte transparentnost. | Vrstva GDPR se možná neuplatní, ale pokračujte dalšími kontrolami. |
| Podmínky webu scraping výslovně zakazují? | Riziko porušení smlouvy. Zvažte API, licenci nebo právní posouzení. | Nižší smluvní riziko, ale zkontrolujte robots.txt. |
| Extrahujete podstatnou část databáze? | Pravděpodobně porušujete sui generis databázové právo. Zvažte licenci nebo užší rozsah extrakce. | Autorské právo se může pořád vztahovat na jednotlivý kopírovaný obsah. |
| Obcházíte přihlašování, CAPTCHA nebo přístupové kontroly? | Možný trestný čin podle CMA 1990. Přestaňte a nechte to právně posoudit. | Nižší riziko podle CMA, pokud je přístup skutečně veřejný. |
| Účel je nekomerční výzkum? | Může se uplatnit výjimka TDM podle § 29A, pokud máte zákonný přístup. | Pro komerční použití neexistuje v Británii široký bezpečný přístav pro TDM. Je potřeba plná analýza IP a smluv. |
Uf, kéž by mi tohle někdo dal, když jsem pro náš tým poprvé řešil compliance kolem scrapingu. Z právní složitosti to dělá strukturované sebehodnocení, které zvládnete za méně než minutu.
Reálné scénáře: je konkrétní scraping v UK legální?
Abstraktní právo je jedna věc. Co lidi skutečně chtějí vědět: „Dostanu se do problémů s mým konkrétním projektem?“
To je fér. Tady je pět běžných use caseů scrapingu ve Spojeném království s krátkým posouzením právního rizika u každého.
Scrapování cen produktů pro srovnání
Jeden z nejběžnějších — a často i nejméně rizikových — obchodních use caseů. Ceny jsou faktická data a automatizovaný sběr cen je přesně to, jak fungují weby jako PriceSpy.
Riziko ale úplně nemizí. Pokud cílový web zakazuje scraping ve svých podmínkách, pokud kopírujete popisy produktů nebo obrázky, nebo pokud extrahujete podstatnou část kurátorované produktové databáze, mohou se objevit problémy se smlouvou, autorským právem a databázovými právy.
Úroveň rizika: NÍZKÁ až STŘEDNÍ
Klíčový krok k souladu: Sbírejte jen faktická cenová pole, nekopírujte doslovně popisy produktů, respektujte podmínky webu a robots.txt, používejte rate limiting a nezveřejňujte syrovou kopii katalogu konkurence.
Komerční scrapování a další prodej dat
Nejrizikovější komerční scénář, tečka. Přetváříte datovou investici někoho jiného do produktu na prodej — a to může současně aktivovat všechny čtyři právní pilíře.
Úroveň rizika: VYSOKÁ
Klíčový krok k souladu: Právní posouzení je nezbytné. Zvažte licenční smlouvy s vlastníky dat. Pokud produkt obsahuje osobní údaje, přidejte posouzení dopadů na ochranu osobních údajů.
Extrakce firemních kontaktů pro lead generation
Každý obchodní tým, se kterým jsem mluvil, dělá nějakou variantu tohohle: scrapuje e-maily, telefonní čísla a názvy firem z adresářů. Háček? Firemní kontaktní údaje často zahrnují osobní údaje. E-mail pojmenovaného zaměstnance je osobní údaj, i když je veřejně uvedený.
Úroveň rizika: STŘEDNÍ
Klíčový krok k souladu: Proveďte posouzení oprávněného zájmu, sbírejte pokud možno jen firemní kontaktní údaje (ne soukromé), dokumentujte právní základ a nabídněte možnost opt-out. Nástroje jako Thunderbit tady mohou snížit riziko přístupu, protože rozšíření Chrome běží v prohlížeči uživatele — přistupuje jen k tomu, co už uživatel vidí, bez obcházení přístupových kontrol.
Akademická nebo portfoliová analýza dat
Pokud děláte skutečně nekomerční výzkum, máte nejsilnější cestu přes výjimku v autorském právu: § 29A CDPA, pokud máte zákonný přístup.
Úroveň rizika: NÍZKÁ (pokud je opravdu nekomerční)
Klíčový krok k souladu: Zdokumentujte nekomerční účel, citujte zdroje, kde je to možné anonymizujte nebo agregujte a nepřeposílejte chráněný obsah ani osobní údaje.
Scrapování obsahu pro trénování AI modelů
To je téma, na které se v roce 2026 ptá úplně každý — a odpověď je pořád neuspokojivá. ICO považuje web scraped osobní údaje pro trénování za vysoce rizikové, neviditelné zpracování. Zpráva britské vlády z roku 2026 nezavedla širokou komerční výjimku TDM.
Úroveň rizika: STŘEDNÍ až VYSOKÁ
Klíčový krok k souladu: Licence, původ datové sady, analýza autorských práv, filtrování osobních údajů, dokumentace právního základu a pečlivé sledování změn britské regulace.
Souhrnná tabulka scénářů
| Scénář | Klíčové spuštěné zákony | Úroveň rizika | Klíčový krok k souladu |
|---|---|---|---|
| Monitorování cen produktů | Podmínky webu, databázová práva, autorské právo | Nízké–střední | Sbírat faktická pole, respektovat signály webu |
| Komerční další prodej dat | Všechny čtyři pilíře | Vysoké | Nutné právní posouzení a licence |
| B2B lead generation | UK GDPR, podmínky webu | Střední | Proveďte LIA, minimalizujte osobní údaje |
| Akademický výzkum | Autorské právo (výjimka TDM), GDPR pokud jde o osobní údaje | Nízké | Zachovat nekomerční účel, nepřepublikovávat |
| Trénování AI modelů | UK GDPR, autorské právo, databázová práva | Střední–vysoké | Licencovat data, dokumentovat právní základ, sledovat politiku |
UK vs. USA vs. EU: jak se liší právo web scrapingu
Pokud působíte jen ve Spojeném království, můžete tuhle část přeskočit. Většina firem, se kterými mluvím, ale scrapuje mezinárodně — nebo alespoň weby hostované v jiných jurisdikcích. Rozdíly jsou důležitější, než by se zdálo.
| Právní oblast | 🇬🇧 UK | 🇺🇸 USA | 🇪🇺 EU |
|---|---|---|---|
| Hlavní zákon o ochraně osobních údajů | UK GDPR + DPA 2018 | Žádný federální ekvivalent (státní zákony se liší) | EU GDPR |
| Klíčový precedent pro scraping | Clearview AI (pokuta ICO 7,5 mil. £) | hiQ v. LinkedIn (scraping veřejných dat OK, 9. obvod — ale hiQ nakonec dostal trvalý zákaz a v konečném souhlaseném rozsudku zaplatil 500 tis. $) | Ryanair v. PR Aviation (SDEU, C-30/14, databázová práva) |
| Zákon o přístupu k počítačům | Computer Misuse Act 1990 | CFAA (zúžený rozhodnutím Van Buren, 2021) | Liší se podle členského státu |
| Autorské právo / výjimka TDM | Úzká: jen nekomerční výzkum (§ 29A) | Doktrína fair use (širší, případ od případu) | Směrnice DSM čl. 3 a 4 (širší práva TDM s vyhrazením práv) |
| Databázová práva | Ano (převzatá z EU směrnice o databázích) | Žádné srovnatelné federální právo | Sui generis právo podle směrnice o databázích |
| Vymahatelnost podmínek webu | Platí smluvní právo; browsewrap je sporný | Smíšené: browsewrap bývá často nevymahatelný | Liší se; Ryanair posílil postavení podmínek |
Praktické shrnutí: pokud scrapujete napříč jurisdikcemi, řiďte se nejpřísnějším použitelným právem. USA jsou podle hiQ k přístupu k veřejným datům benevolentnější, ale hiQ není bianko šek (hiQ nakonec nesměl LinkedIn scrapovat a zaplatil 500 tis. $). EU má přes směrnici DSM širší architekturu pro TDM. Británie je někde mezi — žádná široká komerční výjimka TDM, silná databázová práva a aktivní regulátor.
Sankce a vymáhání: co se skutečně stane, když vás chytí
Nejasná varování o „pokutách“ a „právních problémech“ nikomu nepomůžou. Tady jsou skutečná čísla.
Pokuty podle UK GDPR
Maximální sankce: 17,5 milionu £ nebo 4 % ročního celosvětového obratu, podle toho, co je vyšší.
Reálný příklad: Clearview AI dostala od ICO v roce 2022 pokutu 7 552 800 £ za scraping obličejových fotografií z britských sociálních sítí. First-tier Tribunal rozhodnutí zrušil z jurisdikčních důvodů, ale Upper Tribunal v říjnu 2025 vyhověl odvolání ICO a věc vrátil. ICO uvedl, že Clearview měla k projednání u Court of Appeal povolení k prosinci 2025.
Trestní sankce podle Computer Misuse Act
- § 1 (neoprávněný přístup): až 2 roky odnětí svobody
- § 3 (neoprávněné narušení): až 10 let odnětí svobody
Trestní stíhání za běžný scraping veřejných stránek je extrémně vzácné.
Rizikový profil se dramaticky mění ve chvíli, kdy se chování podobá hackingu, zneužití přihlašovacích údajů, obcházení CAPTCHA nebo narušení služby.
Autorské právo a databázová práva
Občanskoprávní náhrada škody plus soudní zákaz. Trestní sankce jsou možné u úmyslného komerčního porušení, ale většina sporů o scraping se vede jako občanskoprávní.
Porušení smlouvy (ToS)
Občanskoprávní náhrada škody, zrušení účtu, blokování IP. To bývá v praxi nejčastější vymáhání — a často úplně první, co se stane.
Souhrn závažnosti sankcí
| Právní rámec | Maximální sankce | Pravděpodobnost u typického firemního scrapingu | Reálný příklad |
|---|---|---|---|
| UK GDPR | 17,5 mil. £ nebo 4 % globálního obratu | Střední, pokud jde o osobní údaje ve velkém; nízká u neosobních dat | Pokuta Clearview AI 7,5 mil. £ |
| CMA § 1 | 2 roky odnětí svobody | Nízká u veřejných stránek; vyšší při obcházení kontrol | Pokyny CPS k neoprávněnému přístupu |
| CMA § 3 | 10 let odnětí svobody | Nízká, pokud provoz nenarušuje systémy | Příklady narušení typu DDoS |
| Autorské právo / databázová práva | Náhrada škody a soudní zákaz | Střední při kopírování chráněného obsahu nebo kurátorovaných databází | Věci Ryanair a BHB |
| Porušení ToS | Náhrada škody, zrušení účtu, blokace | Vysoká jako praktický způsob vymáhání | Spory o screen-scraping u Ryanairu |
Jak vám správný scrapingový nástroj snižuje právní riziko
Nástroj, který si vyberete, sám o sobě nezmění nelegální scraping v legální. Může ale odstranit rizika, kterým se dá předejít.
Podle mých zkušeností je rozdíl mezi nástrojem, který respektuje signály webu, a nástrojem, který všechno agresivně obchází, často rozdíl mezi rutinním datovým projektem a právním problémem.
Respektuje robots.txt a signály webu
Zodpovědný nástroj by měl usnadnit kontrolu a respektování robots.txt ještě před scrapováním. I když právně závazný není, soudy a ICO ho berou jako důkaz dobré víry. Dokumentace Thunderbitu doporučuje uživatelům scrapovat veřejně dostupná data a respektovat robots.txt i podmínky webu.
Browser scraping vs. cloud scraping
Tento rozdíl je právně důležitý. Browser scraping přistupuje jen k tomu, co uživatel vidí ve své přihlášené relaci — v podstatě automatizuje to, co byste dělali ručně. Cloud scraping posílá požadavky ze serverů, což je rychlejší u veřejných webů, ale z pohledu webu to může víc připomínat „automatizovaný přístup“.
Thunderbit nabízí oba režimy. Browser scraping je vhodný pro weby vyžadující přihlášení (snižuje riziko „neoprávněného přístupu“ podle CMA), zatímco cloud scraping dobře funguje pro veřejně dostupné e-commerce stránky, kde záleží na rychlosti. Tenhle dvojí přístup umožňuje přizpůsobit metodu scrapingu právnímu rizikovému profilu konkrétního webu.
Žádné obcházení přístupových kontrol
Nástroj, který funguje uvnitř prohlížeče a neprolamuje CAPTCHA ani neobchází přihlašovací bariéry, je z pohledu Computer Misuse Act ze své podstaty méně rizikový. Rozšíření Chrome od Thunderbitu funguje v relaci uživatele v prohlížeči — přistupuje jen k tomu, co už uživatel vidí.
Transparentní export dat (podpora souladu s GDPR)
Thunderbit exportuje přímo do Excelu, Google Sheets, Airtable nebo Notion. Uživatel má kontrolu nad tím, kam data jdou. To podporuje transparentnost a dokumentaci právního základu podle GDPR: přesně víte, jaká data jste nasbírali a kam se dostala. Žádné skryté zpracování ani uchovávání dat nástrojem.
Rate limiting a odpovědný přístup
Agresivní objemy požadavků mohou spustit § 3 CMA (neoprávněné narušení). Rate limiting není jen technická best practice — je to i právní pojistka. Odpovědné nástroje nezahlcují servery, čímž snižují jak právní riziko, tak šanci, že vám web zablokuje IP.

Praktický checklist souladu pro web scraping v UK
Než začnete cokoliv scrapovat, projděte si tohle:
- Přečtěte si obchodní podmínky cílového webu a zásady přijatelného použití.
- Zkontrolujte soubor robots.txt a zdokumentujte, zda jsou relevantní cesty zakázané.
- Určete, zda jsou data, která chcete sbírat, osobní údaje. Pokud ano, najděte právní základ podle UK GDPR.
- Posuďte, zda neextrahujete „podstatnou část“ databáze.
- Potvrďte, že neobcházíte žádné technické přístupové kontroly (CAPTCHA, přihlášení, limitování rychlosti).
- Pokud je váš účel nekomerční výzkum, zdokumentujte to, abyste mohli využít výjimku TDM.
- Používejte rate limiting. Nezahlcujte cílový server.
- Dokumentujte vše: právní základ, kontrolu ToS, sbíraná pole, cílová úložiště exportu, dobu uchování.
- Když si nejste jistí, získejte právní radu od advokáta specializovaného na ochranu osobních údajů a duševní vlastnictví.
Tenhle checklist nenahrazuje stanovisko advokáta — ale dává vám pevný výchozí rámec a prokazuje dobrou víru, pokud se někdy objeví otázky.
Hlavní poznatky
- Web scraping není ve Spojeném království nelegální — ale reguluje ho čtveřice překrývajících se právních rámců: UK GDPR, autorské právo / databázová práva, smluvní právo a Computer Misuse Act.
- Legálnost každého scrapingu závisí na tom, co scrapujete, jak k tomu přistupujete, co říkají podmínky webu a co s daty děláte.
- Scraping osobních údajů nese největší nároky na compliance. Oprávněný zájem je obvykle jediný reálně použitelný právní základ a vyžaduje zdokumentovaný balancing test.
- Spojené království nemá širokou komerční výjimku TDM. Komerční trénování AI a další prodej datových sad jsou bez licence vysoce rizikové.
- Před startem použijte rozhodovací strom a tabulku scénářů výše k posouzení vlastní situace.
- Volte nástroje, které odpovídají best practices souladu: přístup přes prohlížeč, žádné obcházení CAPTCHA, transparentní export dat a rate limiting. Thunderbit je navržen s těmito principy v mysli — odpovědnost za compliance ale vždy leží na uživateli.
- Když si nejste jistí, zdokumentujte své zdůvodnění a poraďte se s advokátem. Cena právního posudku je téměř vždy nižší než cena vyšetřování ICO.
Vyzkoušet AI Web Scraper s Thunderbit Get Started Free
Nejčastější dotazy
Je legální scrapovat veřejně dostupná data ve Spojeném království?
Obecně ano — scraping veřejných dat je méně rizikový než scraping uzamčených nebo soukromých dat. Ale „veřejně dostupné“ neznamená „můžu to použít jakkoli“. UK GDPR se může vztahovat i na veřejné osobní údaje, autorské právo se může vztahovat na kopírované vyjádření, databázová práva mohou chránit kurátorované soubory a ToS může automatizovaný přístup omezit.
Můžu scrapovat e-maily a telefonní čísla z britských webů?
Pokud jde o osobní údaje (což e-maily a telefonní čísla obvykle jsou), potřebujete právní základ podle UK GDPR. Oprávněný zájem je nejčastější základ pro B2B lead generation, ale musíte provést balancing test, minimalizovat sbíraná data a nabídnout opt-out. Scrapování kontaktních údajů ze soukromého života (mobilní čísla, osobní e-maily) je mnohem rizikovější než obchodní firemní adresáře.
Jaký je rozdíl mezi web scrapingem a web crawlingem podle britského práva?
Právně žádný podstatný rozdíl neexistuje — zákon se dívá na chování, ne na nálepku. Crawling obvykle znamená objevování nebo indexaci stránek; scraping obvykle znamená extrakci strukturovaných dat. Obě činnosti znamenají automatizovaný přístup k webu a podléhají stejným právním rámcům.
Znamená robots.txt, že scraping je nelegální?
Ne. robots.txt není právně závazný. Ignorování ale zvyšuje vaše riziko, protože soudy a ICO ho berou jako důkaz záměru provozovatele webu. Když ignorujete robots.txt a podmínky webu scraping navíc zakazují, skládáte si rizikové faktory na sebe — a to se mnohem hůř obhajuje.
Mohu být ve Spojeném království za web scraping trestně stíhán?
Jen pokud obcházíte přístupové kontroly (CAPTCHA, přihlášení, IP bloky) nebo způsobíte škodu počítačovému systému podle Computer Misuse Act 1990. Běžný scraping skutečně veřejných dat, v rozumném objemu a bez technického obcházení, velmi pravděpodobně nepovede k trestnímu stíhání. Riziko se dramaticky mění ve chvíli, kdy se chování podobá hackingu nebo úmyslnému narušení služby.
Zjistit více




