

Web scraping has become the secret sauce for modern business teams—whether you’re in sales, operations, or marketing, the ability to quickly gather data from the web can make or break your next big project. With the explosion of data-driven decision-making, companies are looking for tools that are not just fast, but also reliable and scalable. Enter Rust: a modern programming language that’s quietly making waves in the world of web scraping, especially for teams that demand both speed and safety.
It’s not just hype—Rust has been named the “most loved programming language” in the Stack Overflow Developer Survey for several years running, and its adoption in backend and data engineering is growing fast. But what does “web scraping with Rust” really mean for business users? And how does it stack up against no-code solutions like Thunderbit, which are designed for non-technical teams? Let’s break it all down in plain English—no coding degree required.
What Is Web Scraping with Rust? Breaking Down the Basics
At its core, web scraping is the process of automatically extracting data from websites. Think of it as sending out a digital assistant to visit hundreds (or thousands) of web pages, copy the information you care about—like product prices, contact info, or reviews—and bring it back in a neat, structured format. This is a huge time-saver for businesses that need up-to-date data for lead generation, market research, price monitoring, and more.
Rust is a systems programming language known for its high performance, memory safety, and reliability. Unlike older languages that can be prone to bugs or slowdowns, Rust is designed to catch errors before your code even runs. For web scraping, this means you can build tools that are both blazing fast and less likely to crash or leak memory—a big win when you’re dealing with large-scale data extraction.
But here’s the thing: while Rust is a favorite among developers, its benefits ripple out to business users too. Faster, safer scraping means fresher data, fewer errors, and more reliable insights for your team.
Why Choose Rust for Web Scraping? Key Advantages for Business Users
So, why are more teams considering Rust for web scraping, especially when Python and JavaScript have been the go-to choices for years? Let’s break down the key advantages:
- High Performance: Rust is compiled to machine code, making it significantly faster than interpreted languages like Python or JavaScript. For large-scale scraping—think millions of pages—this speed translates to real business value.
- Memory Safety: Rust’s unique approach to memory management (no garbage collector, strict ownership rules) means fewer bugs and crashes. Your scraping jobs are less likely to fail halfway through, saving time and reducing frustration.
- Reliability: Rust’s compiler enforces strict type checking and error handling, catching many issues before your code even runs. This leads to more stable, predictable scraping workflows.
- Concurrency: Rust makes it easier to write code that does many things at once (more on this in the next section), which is crucial for scraping lots of pages in parallel.
How does this compare to Python or JavaScript? While those languages are easier to start with, they can struggle with performance and reliability at scale. Rust’s technical strengths mean you can collect more data, more quickly, with fewer headaches—giving your business a competitive edge.
Rust’s Asynchronous Power: Efficient Large-Scale Web Scraping
Here’s where Rust really shines: asynchronous programming. In simple terms, async code lets your scraper fetch data from many websites at once, without waiting for each one to finish before starting the next. This is a game-changer when you need to gather large datasets quickly.
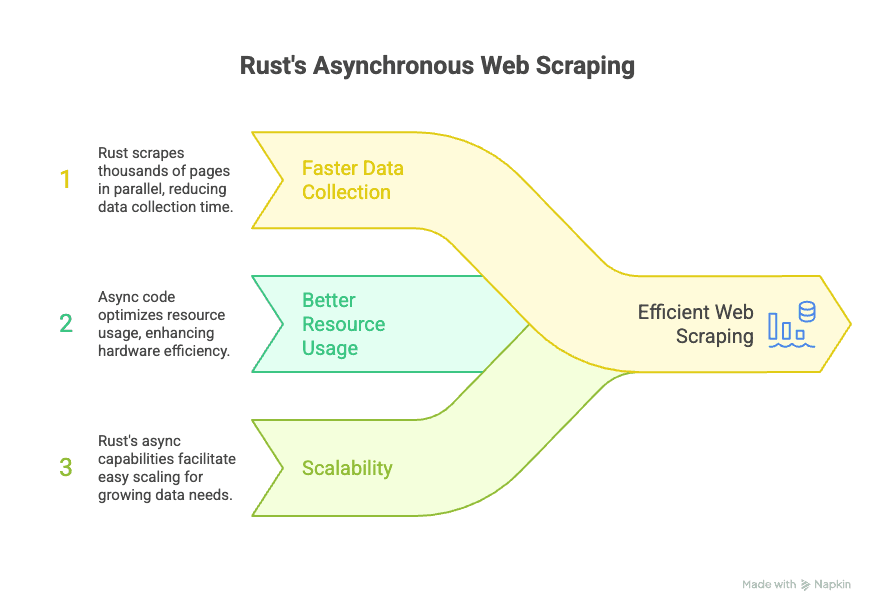
Rust’s async ecosystem is powered by libraries like Tokio and async-std, which allow your scraper to handle thousands of simultaneous requests without blocking the main process. For business users, this means:
- Faster data collection: Scrape thousands of pages in parallel, slashing the time it takes to build your dataset.
- Better resource usage: Async code is more efficient, so you can do more with less hardware.
- Scalability: As your data needs grow, Rust’s async capabilities make it easier to scale up without rewriting your entire workflow.
In practice, this means your team can react to market changes, monitor competitors, or generate leads in real time—without waiting hours (or days) for your data to finish downloading.
How Does Web Scraping with Rust Work? A Step-by-Step Overview
Curious what a typical Rust web scraping workflow looks like? Here’s a high-level, non-technical overview:
- Setup: Define what data you want to collect and from which websites.
- Fetching Data: Use libraries like Reqwest (for HTTP requests) to download web pages.
- Parsing Content: Use Scraper or Select to extract specific pieces of information (like product names, prices, emails) from the raw HTML.
- Handling Pagination/Subpages: Write logic to navigate through multiple pages or follow links to subpages (more on this below).
- Exporting Data: Save the extracted data into a structured format—CSV, Excel, or directly into a database—so your team can use it right away.
Each library has a specific role: Reqwest handles the “fetching,” Scraper/Select do the “parsing,” and you can use built-in Rust features or third-party crates for exporting and organizing your results.
Navigating Complex Websites: Rust’s Approach to Pagination and Subpages
Many business scraping tasks aren’t as simple as grabbing data from a single page. You might need to:
- Scrape all products from a multi-page catalog
- Collect reviews spread across several subpages
- Gather contact info from nested directories
Rust is well-suited for these challenges. Its strong type system and error handling make it easier to write code that can:
- Detect and follow “Next” buttons or pagination links automatically
- Visit subpages (like product details or author bios) and merge that data into your main dataset
- Handle unexpected changes (like missing pages or broken links) gracefully, so your scraper doesn’t crash
For example, a Rust scraper could start on a main product listing, follow each pagination link, and then visit every product’s detail page—collecting price, description, and reviews along the way. The result? A comprehensive, up-to-date dataset that’s ready for analysis.
Thunderbit vs. Rust Coding: The No-Code Advantage for Business Teams
Now, let’s talk about the elephant in the room: not everyone has the time (or technical chops) to build a custom Rust scraper from scratch. That’s where Thunderbit comes in.
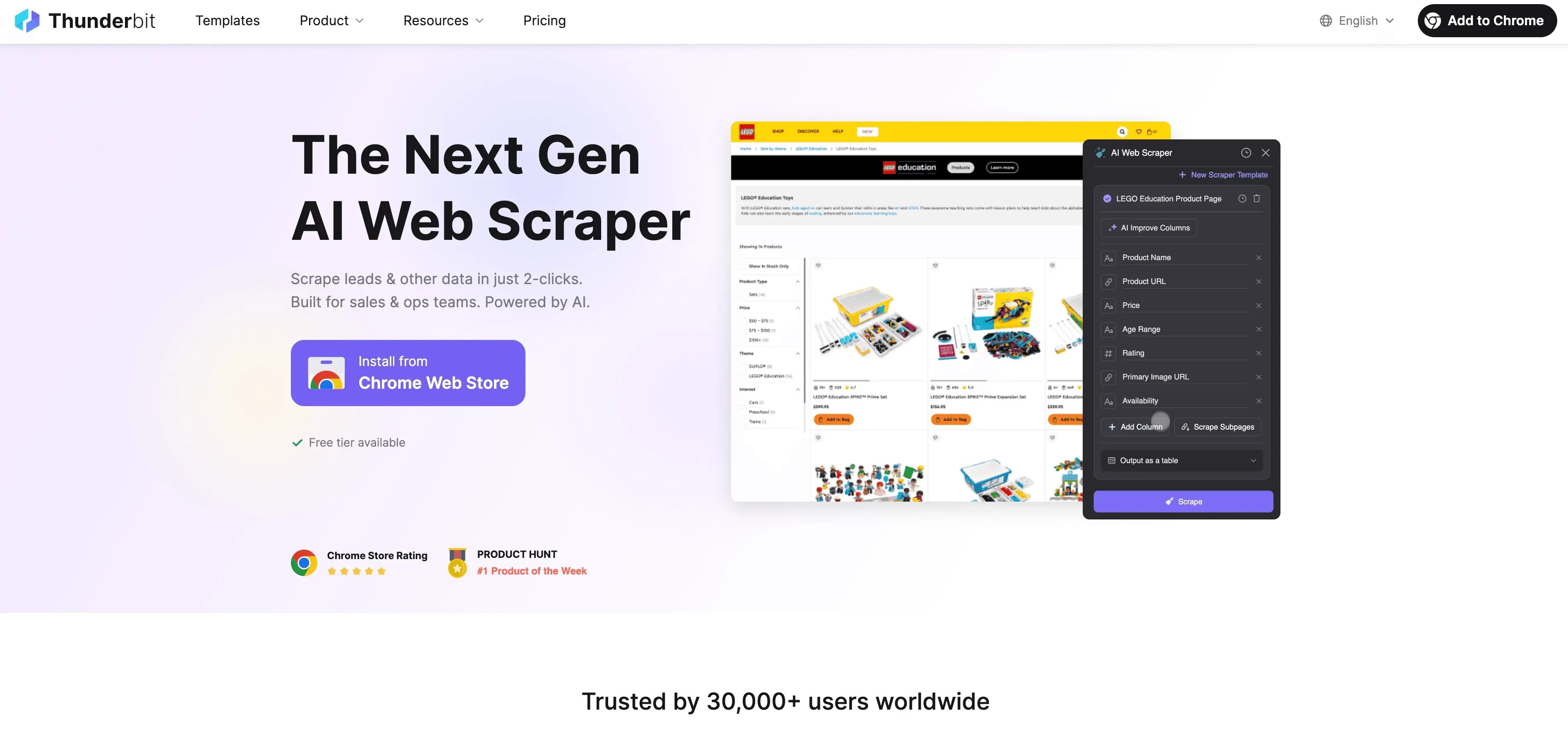
Thunderbit is an AI-powered, no-code web scraper designed for business users. Instead of writing code, you just:
- Open the Thunderbit Chrome Extension
- Navigate to the website you want to scrape
- Click “AI Suggest Fields” and let Thunderbit’s AI recommend what data to extract
- Hit “Scrape” and export your results directly to Excel, Google Sheets, Airtable, or Notion
No templates, no coding, no maintenance. Thunderbit even handles pagination and subpage scraping automatically—just like a custom Rust scraper, but with a point-and-click interface.
Try Thunderbit AI Web Scraper for Free
When to Use Thunderbit Over Rust? Choosing the Right Tool
So, which approach is best for your team? Here’s a quick cheat sheet:
| Scenario | Thunderbit | Rust |
|---|---|---|
| Quick lead generation for sales | ✅ Easiest, fastest | Possible, but overkill |
| Competitor price monitoring (ecommerce) | ✅ No-code, scheduled | ✅ For custom integrations |
| Scraping complex, custom workflows | Possible, but limited | ✅ Full control, highly customizable |
| Large-scale, integrated data pipelines | Possible (with API) | ✅ Best for deep integration |
| Non-technical users (sales, ops, marketing) | ✅ Designed for you | ❌ Requires coding skills |
| Need for rapid prototyping or one-off tasks | ✅ 2-click setup | Possible, but slower to start |
In short: Thunderbit is perfect for business users who want fast, reliable data extraction without the technical hassle. Rust is ideal when you need maximum control, custom logic, or are scraping at massive scale.
Real-World Example: Rust Web Scraping in Action
Let’s bring this to life with a practical scenario. Imagine you’re a market research analyst tasked with collecting data on all laptops listed on a major ecommerce site. The site uses pagination (multiple pages of products), and each product has a detail page with specs and reviews.
With Rust, you’d:
- Use Reqwest to fetch the main listing page
- Parse the HTML with Scraper to extract product links
- Detect and follow the “Next” button to scrape all pages
- For each product, visit the detail page and extract specs/reviews
- Handle errors (like missing pages) gracefully, retrying as needed
- Export the final dataset to CSV or your analytics platform
The business value? You get a complete, up-to-date snapshot of the market—fueling smarter pricing, inventory, and marketing decisions.
Key Challenges and Considerations for Web Scraping with Rust
Of course, even with Rust’s strengths, web scraping isn’t always smooth sailing. Here are some common challenges (and how Rust helps):
- Website changes: If the site layout changes, your scraper might break. Rust’s strict typing helps catch these issues early, but you’ll still need to update your code.
- Anti-bot measures: Many sites use CAPTCHAs or rate limits. Rust’s speed can help you stay under the radar, but you may need to add delays or use proxies.
- Data formatting: Not all data is clean—Rust’s strong parsing tools make it easier to handle messy or inconsistent HTML.
- Maintenance: Custom scrapers require ongoing upkeep. For business users, this means working closely with technical teams or considering no-code tools like Thunderbit for routine tasks.
What Is Data Scraping and How to Do It in 2025 Get Started Free
Pro tip: Whether you’re using Rust or Thunderbit, always respect website terms of service and privacy laws when scraping data.
Conclusion: Unlocking Business Value with Web Scraping in Rust (and Beyond)
Web scraping is now a must-have capability for any business that wants to stay ahead in a data-driven world. Rust offers unmatched performance, safety, and reliability for teams that need custom, large-scale scraping solutions—especially when speed and stability are non-negotiable. But for most business users, the technical barrier is real.
That’s where Thunderbit shines: it brings the power of web scraping to everyone, with an AI-driven, no-code interface that handles even complex tasks like pagination and subpage extraction. Whether you’re a sales rep building a lead list, an ecommerce manager tracking prices, or an analyst gathering market intel, Thunderbit lets you get the data you need—fast.
Key takeaways:
- Rust is a powerhouse for custom, large-scale web scraping—ideal for technical teams.
- Thunderbit democratizes web scraping, making it accessible to non-technical users.
- Choose the right tool for your needs: use Rust for deep customization, Thunderbit for speed and simplicity.
Scrape data from any website using AI Get Started Free
Curious to try web scraping for your business? Download Thunderbit and see how easy data extraction can be. Or, if you’re ready to invest in a custom solution, explore Rust’s growing ecosystem for high-performance scraping.
Try AI Web Scraper Get Started Free
FAQs
1. What is web scraping with Rust, and how is it different from other languages?
Web scraping with Rust means using the Rust programming language to automate data extraction from websites. Rust stands out for its speed, memory safety, and reliability compared to languages like Python or JavaScript, making it ideal for large-scale or mission-critical scraping tasks.
2. Is Rust suitable for non-technical business users who need web scraping?
Rust is powerful but requires programming skills. For non-technical users, tools like Thunderbit offer a no-code, AI-driven approach to web scraping—making data extraction accessible to everyone.
3. How does Rust handle complex scraping tasks like pagination or subpages?
Rust’s strong type system and async libraries make it easier to write code that can automatically navigate paginated listings, follow subpage links, and handle errors—resulting in more complete and reliable datasets.
4. When should I use Thunderbit instead of building a custom Rust scraper?
Use Thunderbit when you need quick, easy data extraction without coding—ideal for sales, marketing, and operations teams. Choose Rust for highly customized, large-scale, or deeply integrated scraping workflows that require technical expertise.
5. What are the main challenges of web scraping with Rust, and how can they be managed?
Common challenges include website changes, anti-bot measures, and ongoing maintenance. Rust’s safety features help catch errors early, but you’ll still need to update your code as websites evolve. For routine business scraping, a no-code tool like Thunderbit can save time and reduce headaches.
Learn More:




