Let me take you back to my early days as a product manager, when “getting the data” meant either bribing a developer with coffee or spending hours copy-pasting tables into Excel. (I still have nightmares about those endless Ctrl+C, Ctrl+V marathons.) Fast forward to today, and the world is swimming in data—so much so that by 2036, the web scraping software market alone is projected to reach . But here’s the catch: most of that data is locked behind screens, scattered across websites, PDFs, and apps that don’t exactly roll out the red carpet for easy export.
Enter screen scraping—an old-school technique that’s gotten a serious AI makeover. Whether you’re in sales, e-commerce, real estate, or just a spreadsheet enthusiast (no judgment), understanding how modern screen scraping works—and how AI-powered tools like make it accessible to everyone—can be a total lifesaver for your workflow. Let’s break it down.
What Is Screen Scraping? A Simple Explanation of Data Extraction
Screen scraping is, at its core, the digital equivalent of looking at a screen and jotting down what you see—except you get a robot to do the jotting. It’s the process of extracting data from the visual interface of an application, website, or even a PDF, and turning it into something you can actually use elsewhere ().
Think of it like this: If you’ve ever copied a table from a website into Excel, you’ve done manual screen scraping. The difference is, with automation, you don’t need to wear out your Ctrl and V keys. Instead, you use software to “read” what’s displayed—sometimes even using computer vision or OCR if the data isn’t selectable text.
Screen scraping is often confused with web scraping and data scraping. Here’s the quick-and-dirty difference:
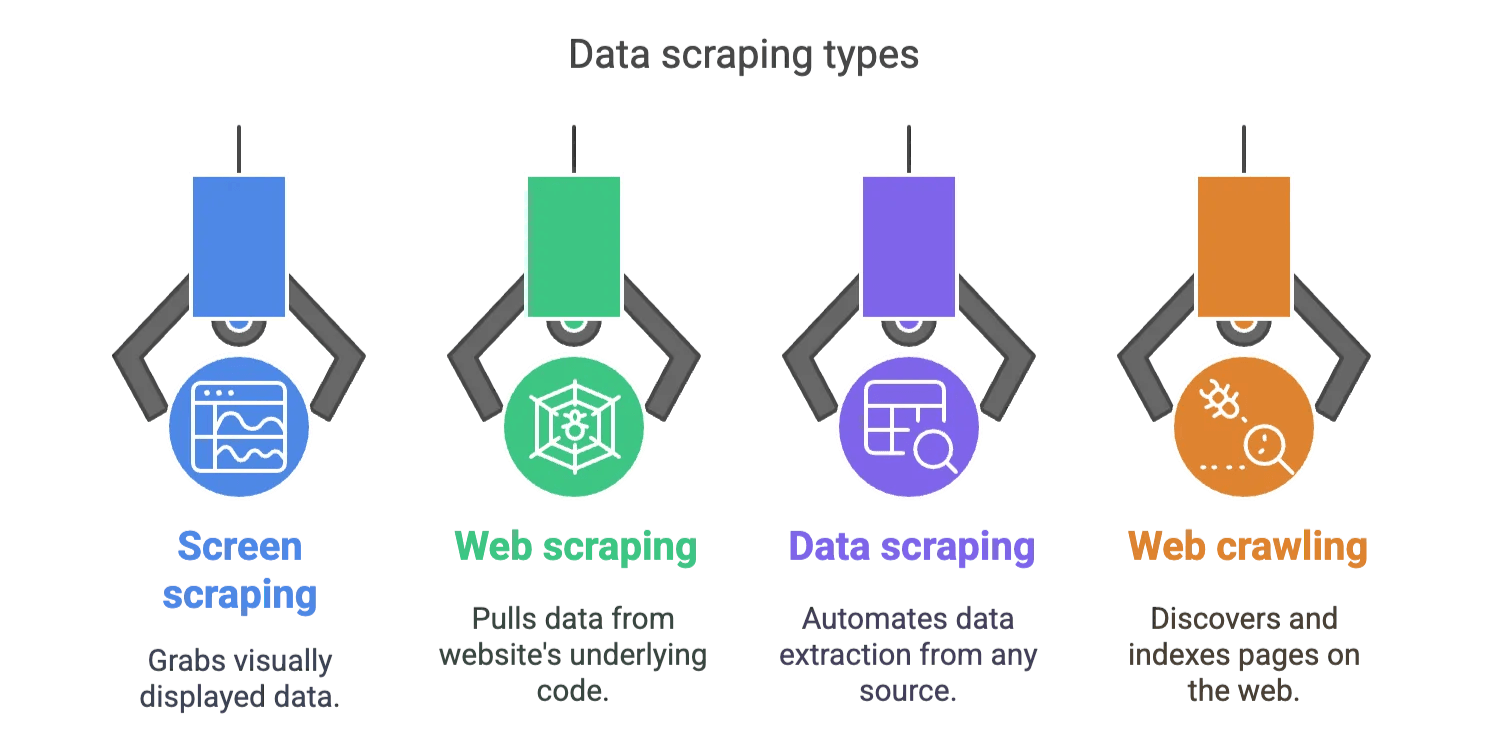
- Screen scraping: Grabs what’s visually displayed (what you see on the screen).
- Web scraping: Pulls data from the underlying code (HTML, JSON, etc.) of a website.
- Data scraping: The umbrella term for automating data extraction from any source (web, apps, files, you name it).
- Web crawling: The process of discovering and indexing pages, not necessarily extracting data from them.
So, if you need to get info from a legacy app, a locked-down PDF, or a website that doesn’t want to play nice, screen scraping is your secret weapon.
Screen Scraping vs. Web Scraping vs. Data Scraping: What’s the Difference?
These terms get tossed around like salad at a startup lunch, but they’re not the same. Here’s a handy table to keep them straight:
| Technique | What It Does | Where It Works | How It Works | Common Use Cases |
|---|---|---|---|---|
| Screen Scraping | Extracts data from what’s displayed on screen | Apps, legacy systems, PDFs, websites | Reads pixels, uses OCR, or UI automation | Migrating data, RPA, legacy systems |
| Web Scraping | Extracts data from webpage code (HTML/DOM) | Websites | Parses HTML, uses HTTP requests, DOM navigation | Price monitoring, lead gen, research |
| Data Scraping | Automates extraction from any data source | Web, files, databases, logs, etc. | Any automated method (scraping, parsing, queries) | Data integration, analytics |
| Web Crawling | Discovers and indexes web pages | The internet | Follows links, builds URL lists | Search engines, site mapping |
Why the confusion? Because these techniques often work together. For example, a web crawler finds all the pages on a site, then a web scraper pulls the data, and if the data is only visible on-screen (not in the code), screen scraping steps in.
Why Screen Scraping Matters for Business: Real-World Use Cases
Let’s get practical. Why do businesses care about screen scraping, web scraping, and data scraping? Because data is power—and most of it isn’t handed to you on a silver platter.
Here are some real-world scenarios:
| Team | Use Case | Benefit | ROI Example |
|---|---|---|---|
| Sales | Lead generation from directories | More leads, less manual work | 5+ hours/week saved per rep (Thunderbit users) |
| E-commerce | Competitor price monitoring | Dynamic pricing, higher margins | 4% sales boost (John Lewis) |
| Real Estate | Property listing aggregation | Faster market analysis | More deals, better investment decisions |
| Marketing | Scraping reviews/social data | Sentiment analysis, campaign ROI | Improved targeting, faster response |
| Operations | Vendor portal data extraction | Automated reporting, fewer errors | Reduced manual entry, fewer mistakes |
And that’s just the tip of the iceberg. I’ve seen teams use scraping to migrate content, monitor compliance, and even build internal dashboards that would make a data scientist jealous.
Traditional Screen Scraping Tools: How They Work and Their Limitations
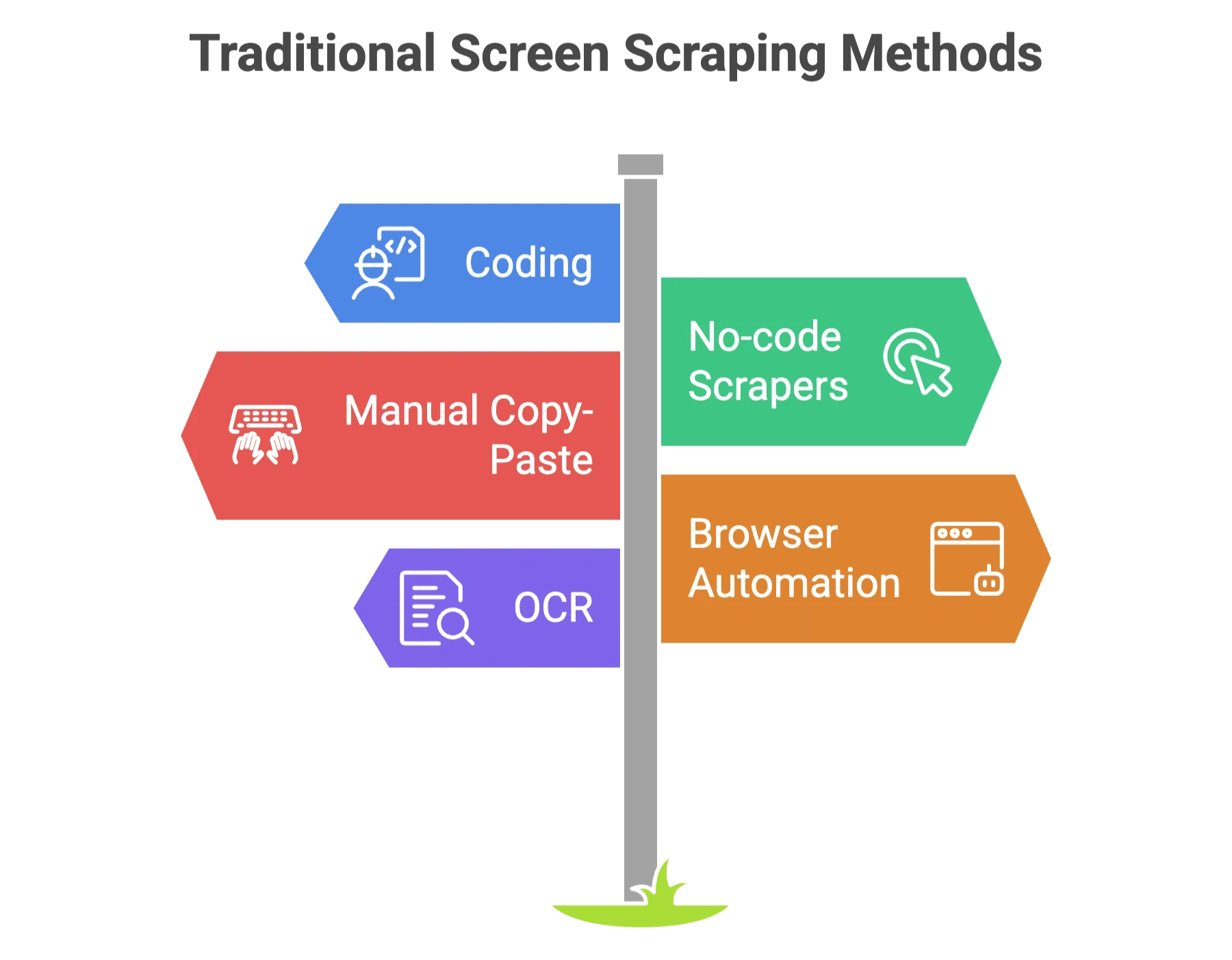
Before AI, screen scraping was a bit like assembling IKEA furniture with no instructions. You had two main options:
- Coding: Write custom scripts (Python, JavaScript, etc.) to fetch and parse data. Great if you love debugging at 2am.
- No-code scrapers: Point-and-click tools where you manually select what to extract. Easier, but still fiddly—and if the website changes, your setup might break faster than a cheap folding chair.
Other classic methods included:
- Manual copy-paste: Tedious, error-prone, and soul-crushing.
- Browser automation (Selenium, Playwright): Simulates a real user, but requires technical chops.
- OCR: For when data is stuck in images or scanned PDFs.
The pain points?
- Setup is slow and technical.
- Maintenance is a nightmare—one small website update and your scraper goes on strike.
- Limited data transformation—you get raw data, but making it useful is your problem.
- Non-technical users are left out.
If you’ve ever spent more time fixing a scraper than actually using the data, you know what I mean.
Enter AI-Powered Screen Scraping: How AI Changes the Game
Here’s where things get exciting. AI-powered screen scraping flips the script. Instead of wrestling with selectors or writing brittle code, you let an AI agent do the heavy lifting.
How does this work?
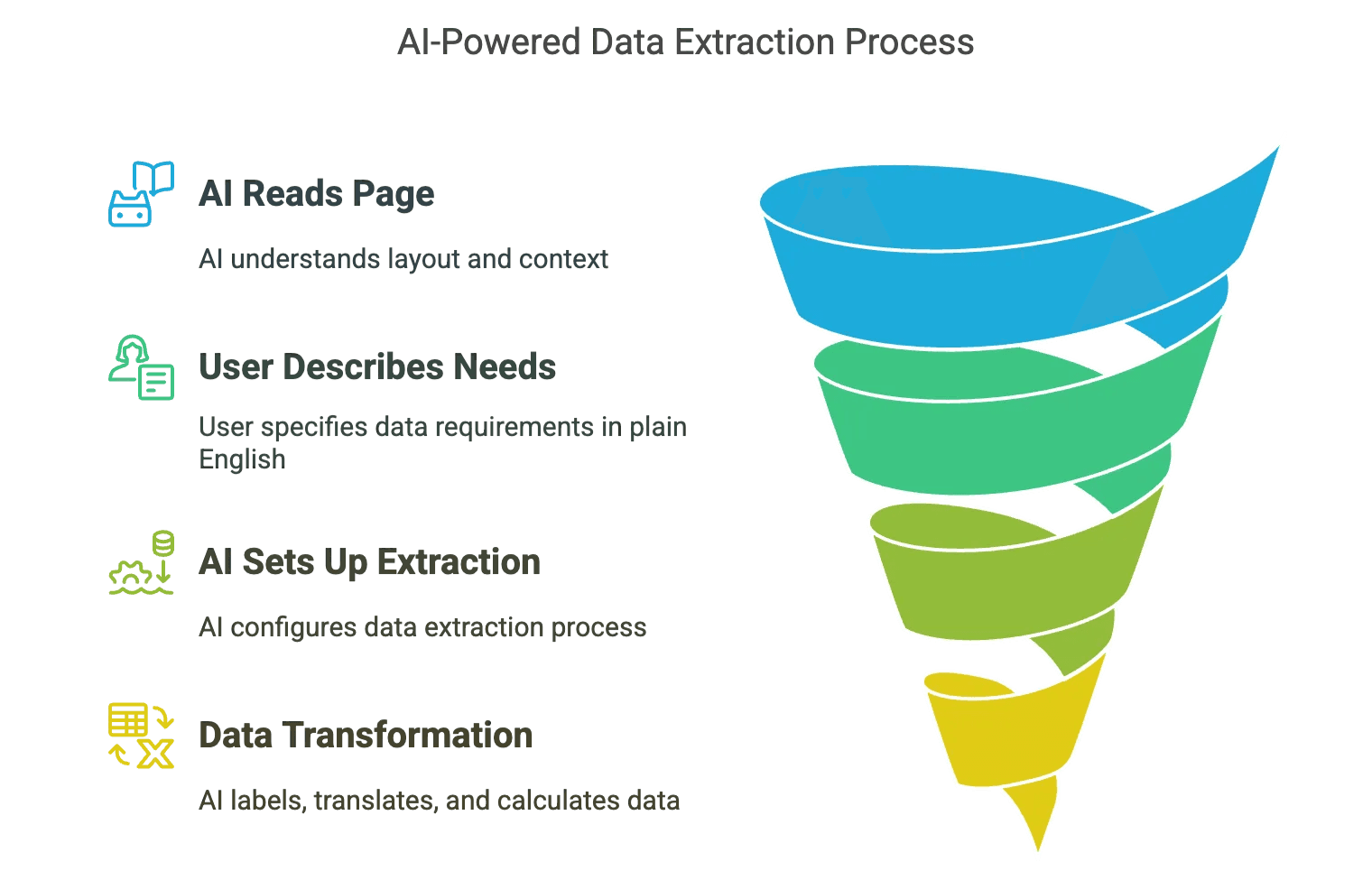
- AI “reads” the page like a human: It looks at the layout, understands context, and figures out what’s important—even if the website changes.
- You describe what you want in plain English: “Get me all the product names, prices, and images,” and the AI sets up the extraction.
- Data transformation happens on the fly: Labeling, translation, calculations—AI can handle it as it scrapes.
This means:
- No more manual setup.
- No more constant maintenance.
- Anyone can do it—not just developers.
For example, with , you can scrape any website, regardless of layout, because the AI agent adapts on the fly. Need to transform or label data as you go? Thunderbit’s got you covered. And the best part? It’s genuinely easy to use.
Thunderbit: The Easiest AI Web Scraper for Everyone
Okay, shameless plug time—but honestly, this is why we built :
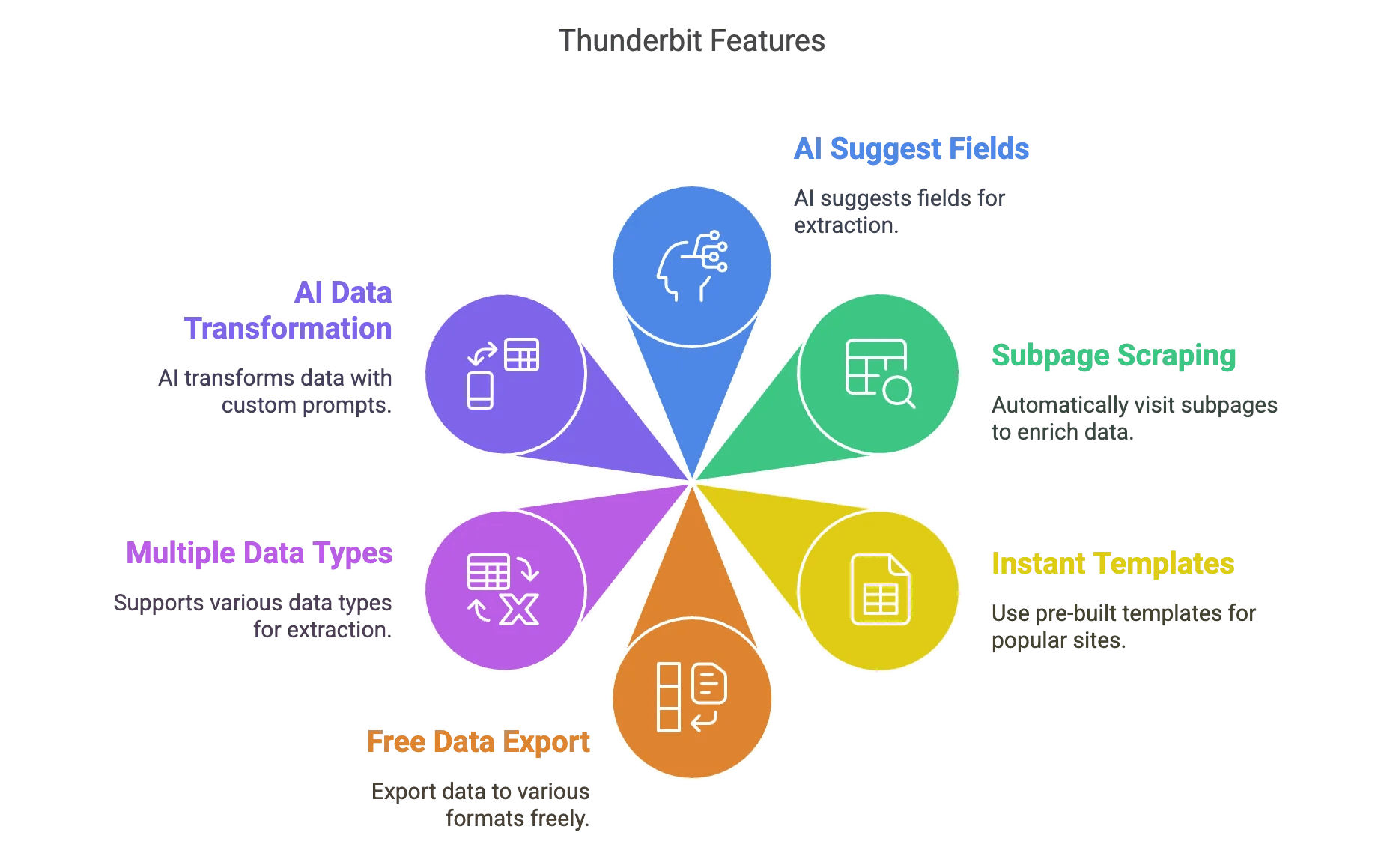
- AI Suggest Fields: Click one button, and Thunderbit’s AI analyzes the page and suggests the best fields to extract. No more guessing or fiddling with selectors.
- Subpage Scraping: Need more details? Thunderbit can automatically visit each subpage (like individual product or profile pages) and enrich your dataset.
- Instant Templates: For popular sites (Amazon, Zillow, Instagram, Shopify, etc.), use pre-built templates to get data in one click.
- Free Data Export: Export to Excel, Google Sheets, Airtable, Notion, CSV, or JSON—no extra fees.
- Multiple Data Types: Text, numbers, dates, URLs, emails, phone numbers, images—you name it.
- AI Data Transformation: Add custom prompts to label, format, or even translate data as you scrape.
And yes, it’s all packed into a that’s actually fun to use. (Well, as fun as data extraction gets.)
How AI-Powered Screen Scraping Works: Step-by-Step
Let’s walk through how an AI-powered screen scraping workflow looks with Thunderbit:
- Install the Thunderbit Chrome Extension.
- Grab it from the .
- Navigate to the website or PDF you want to scrape.
- Thunderbit supports websites, PDFs, and even images.
- Click “AI Suggest Fields.”
- The AI reads the page and suggests columns (e.g., Name, Price, Email, Image).
- Review and adjust fields if needed.
- Add or rename columns, set data types, or add custom AI prompts for labeling or translation.
- Click “Scrape.”
- Thunderbit extracts the data and displays it in a structured table.
- (Optional) Scrape Subpages.
- If you want more details, let Thunderbit visit each link and pull in extra info.
- Export your data.
- Download as CSV, Excel, or send directly to Google Sheets, Airtable, or Notion.
Tips for best results:
- Use clear field names (e.g., “Product Name,” “Price in USD”).
- Add prompts for special formatting or translation.
- Choose the right data type for each field.
For more step-by-step guides, check out our or .
Example Workflow: Scraping Leads from a Website with Thunderbit
Let’s say you’re a sales rep hunting for leads on an industry directory. Here’s how I’d do it:
- Open the directory page.
- Click the Thunderbit extension and hit “AI Suggest Fields.”
- Thunderbit suggests: Name, Company, Email, Phone Number, Website.
- I tweak the columns—maybe add “Location” or “Industry.”
- Click “Scrape.” Thunderbit pulls all visible leads into a table.
- Some leads link to detailed profiles. I click “Scrape Subpages,” and Thunderbit visits each one, grabbing extra info like LinkedIn URLs or bios.
- Export the list to Excel or Google Sheets, ready for outreach.
No code, no headaches, and no more bribing developers with Starbucks gift cards.
Beyond Text: Advanced Data Scraping with AI (Images, Labels, Translations, and More)
Modern AI scrapers aren’t just about grabbing text. With Thunderbit, you can:
- Extract images: Perfect for product catalogs or real estate listings.
- Pull emails and phone numbers: Thunderbit can auto-detect and format these fields.
- Translate data on the fly: Scrape a French website and get English output.
- Label or categorize data: Use AI prompts to tag, summarize, or group entries.
- Integrate with Notion, Airtable, and more: Send your data straight to your favorite tools.
This is a huge win for business users. Imagine enriching your CRM with images, multilingual data, or categorized leads—all in one go.
For more on advanced workflows, see and .
Staying Legal and Secure: What Businesses Need to Know
Screen scraping is powerful, but you’ve got to play by the rules. Here’s what I always recommend:
- Check website terms of service: Some sites ban scraping outright. When in doubt, ask for permission or look for an official API.
- Respect robots.txt: It’s not legally binding, but it’s polite—and helps you avoid getting blocked.
- Avoid scraping behind logins (unless it’s your own data): This is where legal trouble starts.
- Handle personal data with care: GDPR, CCPA, and other privacy laws apply if you’re scraping names, emails, etc.
- Don’t overload servers: Use rate limiting and be a good web citizen.
For a deeper legal dive, see Is LinkedIn Scraping Legal? and .
Key Takeaways: The Future of Screen Scraping with AI
Screen scraping has come a long way—from manual drudgery to AI-powered wizardry. The rise of tools like Thunderbit means anyone can extract, transform, and use data from almost any source, with minimal setup and zero coding.
Here’s what matters most:
- Screen scraping unlocks data from places APIs can’t reach.
- AI-powered tools make it accessible to everyone—not just developers.
- Business teams can now automate lead gen, price monitoring, market research, and more, in just a few clicks.
- Legal and ethical use is critical—always respect the source and the law.
If you’re ready to leave manual data collection in the past (where it belongs), give a try. Your Ctrl and V keys will thank you.
Curious to learn more? Check out our for deep dives on , , and more. Or just install the and see for yourself how easy screen scraping can be.
And if you’re still copy-pasting data by hand… well, let’s just say there’s a better way.
FAQs
-
Does screen scraping work on mobile apps? Yes, screen scraping can be applied to mobile apps, especially legacy or closed systems. It typically requires UI automation or mobile-specific tools to extract data from rendered app interfaces.
-
Can screen scraping extract images or visual content? Screen scraping isn’t limited to text—it can also extract images, charts, or UI elements by capturing screen regions or using computer vision to detect and label visual content.
-
What tools are needed to start screen scraping? You can start with scripting tools like Python and libraries like Selenium or Playwright. For non-coders, visual scrapers or AI-powered tools offer point-and-click alternatives with minimal setup.
-
What are the risks of screen scraping? Risks include legal issues, IP blocking, or data accuracy problems. Changes to the screen layout can break scrapers, and scraping personal data may violate privacy regulations if not handled properly.
Learn More