
If you're evaluating web scraping tools in 2026, you're usually not looking for a philosophy lesson. You want a shortlist you can trust, a fast way to separate business-user tools from engineering-heavy stacks, and enough real evidence to avoid buying the wrong thing. That's the job of this page.
I'm Shuai Guan, co-founder & CEO of . I work on AI-powered scraping and browser automation every day, so I care less about generic rankings and more about fit: which tools help a sales or ops team move this week, which ones belong in a developer workflow, and which ones only make sense when scale and anti-bot infrastructure become the main problem.
The Quick Answer
If you only need the routing logic, use this:
- Pick an AI web scraper if you want the fastest path from website to spreadsheet with minimal setup.
- Pick a no-code scraper if you need more task control, scheduling, or cloud runs without writing code.
- Pick an API platform if your team needs rendering, proxy rotation, anti-bot handling, or integration into an internal product.
- Pick an open-source library if you want full control and you can own maintenance, selectors, infrastructure, and failures.
This article keeps all 20 tools, but the recommendation logic is deliberately simple: start with the lightest tool that can reliably handle your workflow, then move down-stack only when maintenance, blocking, or scale forces you to.
Quick Comparison Table: The Best Web Scraping Tools in 2026
Pricing and plan models below were checked against official product or pricing pages on May 7, 2026. Where vendors use usage-based billing or custom enterprise quoting, I describe the pricing model instead of pretending there's one universally reliable sticker price.
| Tool | Type | Best Fit | Why It Made the 2026 List | Pricing Model (checked May 2026) |
|---|---|---|---|---|
| Thunderbit | AI Web Scraper | Sales, ops, ecommerce, real estate | Fastest path for non-coders; AI field suggestion, subpages, exports, browser + cloud workflow | Free tier, paid plans, business custom pricing |
| Browse AI | AI Web Scraper | Business users monitoring websites | Strong no-code robots, monitoring, and spreadsheet/API style outputs | Free plan, paid plans, premium managed tier |
| Bardeen | AI Automation + Scraping | Revenue ops and browser workflows | Better when scraping is one step inside a wider automation workflow | Free plan and paid plans |
| Diffbot | AI Extraction Platform | Enterprise and data teams | Strongest fit when you want AI extraction plus large-scale structured data workflows | Enterprise-style pricing |
| Instant Data Scraper | Lightweight Browser Scraper | Casual users and quick table grabs | Still one of the simplest ways to pull a visible list or table into CSV quickly | Free |
| Octoparse | No-Code Scraper | Analysts and ops teams with bigger recurring jobs | Mature visual builder with cloud extraction, anti-blocking, and templates | Free plan, paid from $69/month, enterprise custom |
| ParseHub | Low-Code Scraper | Analysts who need logic and desktop control | Flexible project logic and nested navigation, with a steeper learning curve than newer AI-first tools | Free plan and paid plans |
| Web Scraper | No-Code Scraper | Beginners and lightweight cloud jobs | Good entry point if you like sitemap-based scraping and browser-first setup | Free extension, paid cloud plans |
| Data Miner | Browser Scraper | Researchers and growth operators | Still useful for quick recipe-based extraction inside the browser | Free plan and paid plans |
| Apify | API + Actor Platform | Technical teams and hybrid operators | Excellent ecosystem of Actors plus custom runtime when you outgrow browser extensions | Free plan, starter from $29/month plus usage, larger paid tiers |
| ScrapingBee | Scraping API | Developers scraping JS-heavy sites | Good choice when you want rendering and proxy handling without building the browser layer yourself | Free trial and paid plans |
| ScraperAPI | Scraping API | Developers scaling requests fast | Straightforward API, trial credits, structured products, and easier infrastructure offload | 7-day trial with 5,000 credits, paid from $49/month |
| Bright Data | Enterprise API + Proxy Platform | High-volume, compliance-heavy programs | Broadest data-collection stack when unblock, proxy, and managed acquisition matter more than simplicity | Usage-based and product-based pricing |
| Oxylabs | Enterprise API + Proxy Platform | Teams buying scraping as infrastructure | Strong for large-scale collection, especially price, SEO, and market research workloads | Web Scraper API starts from $49/month; broader proxy pricing varies |
| Zyte | API + Anti-Bot Stack | Developer and data teams | Good fit if you want API-first extraction with strong browser, rotation, and anti-detection primitives | Trial with $5 free credit, usage-based commitments |
| Selenium | Open-Source Browser Automation | QA-style automation and hard interaction flows | Still useful when user interaction fidelity matters more than scraper throughput | Free and open-source |
| BeautifulSoup4 | Open-Source Parser | Beginners and lightweight parsing | Best as a parser in a simple stack, not as a full scraping platform | Free and open-source |
| Scrapy | Open-Source Crawling Framework | Production custom crawlers | Best balance of power and maturity if you want to own the pipeline yourself | Free and open-source |
| Puppeteer | Open-Source Browser Automation | Node-first scraping and browser scripting | Great if your team is already comfortable living in the Chrome/Node ecosystem | Free and open-source |
| Playwright | Open-Source Browser Automation | Modern multi-browser automation | Often the cleanest choice for modern browser automation with strong developer ergonomics | Free and open-source |
How I Evaluated These Tools
I used four filters:
- Time to first successful scrape
If a non-technical operator cannot get useful data quickly, that matters. - Maintenance burden
Fast setup is meaningless if the workflow breaks every time a site changes. - Scale ceiling
Some tools are ideal for 50 pages a week and terrible for 5 million requests a month. - Workflow fit
The best tool for a revenue ops team is rarely the best tool for a data platform team.
The result is not a universal ranking. It's a decision page for choosing the right class of tool first, then the right product inside that class.
Which Type of Web Scraping Tool Do You Actually Need?
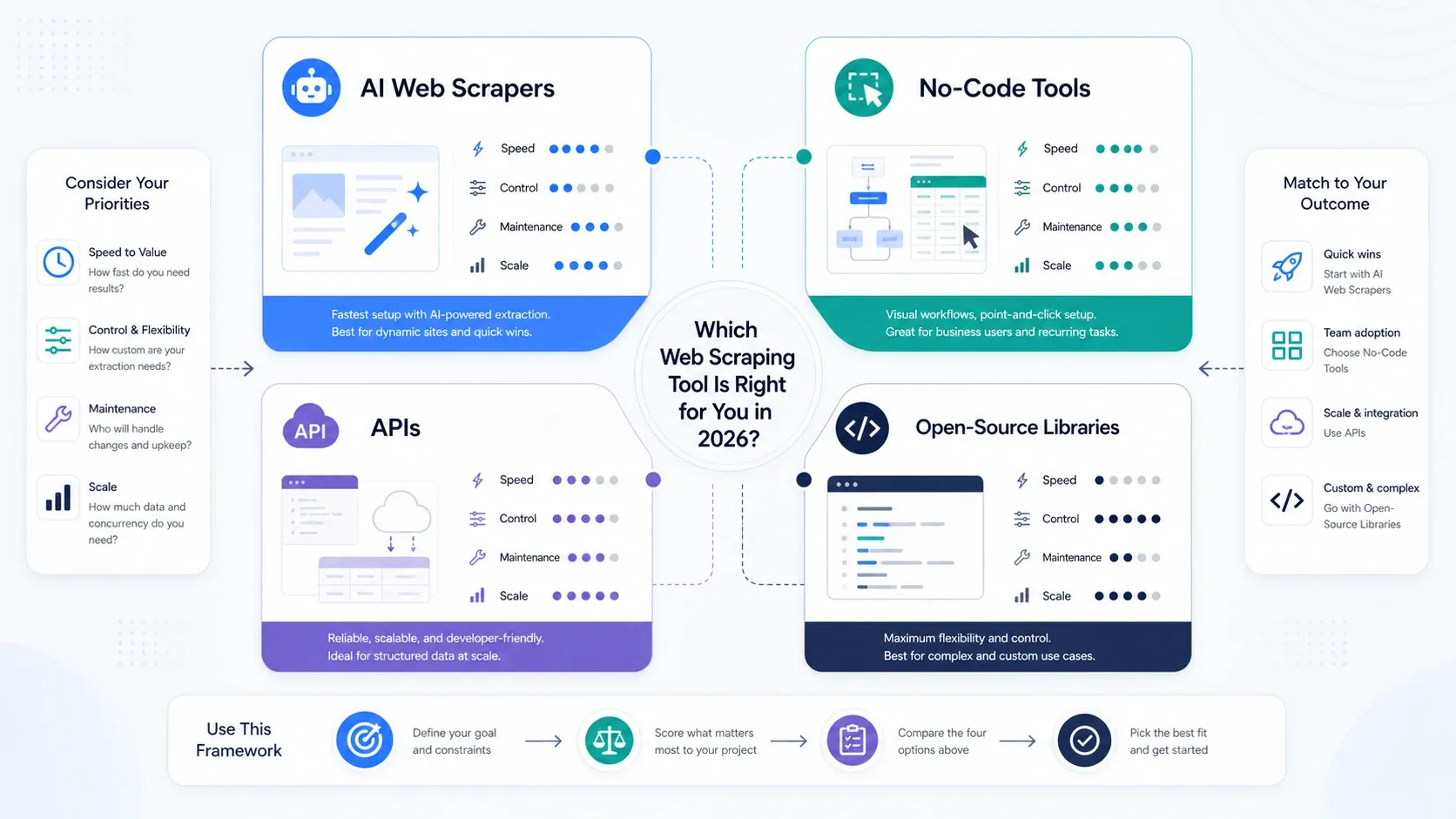
- Choose AI web scrapers if your primary goal is operational speed.
- Choose no-code tools if you need more pagination, scheduling, and repeatable task control.
- Choose APIs and scraping platforms if rendering, rotation, and unblock capability are now the bottleneck.
- Choose open-source libraries if your team values control more than convenience and can support the stack internally.
If your team is still deciding whether scraping should live with ops or engineering, start with an AI or no-code tool first. You will learn what matters faster by running real jobs than by overdesigning the stack upfront.
Best AI Web Scrapers for Business Teams
These are the tools I would look at first if the outcome you want is spreadsheet-ready data with as little setup as possible.
1. Thunderbit
Thunderbit is the easiest option here if your team wants to extract structured data without learning selectors, browser scripting, or scraping infrastructure. The workflow is built around AI field suggestion, subpage enrichment, and direct export to the tools business users already live in.
- Best for: sales, ops, ecommerce, real estate, and other browser-heavy teams.
- Why it stands out: it compresses setup time better than anything else in this list for non-coders.
- Watchout: if you need deep custom crawler logic or highly specialized engineering control, you'll eventually move down-stack.
- Pricing model: free tier, self-serve paid plans, and business pricing.
2. Browse AI
Browse AI remains a strong pick for business users who want point-and-click setup plus recurring monitoring. Its robot model is especially useful when scraping and change detection are equally important.
- Best for: monitoring price pages, competitor pages, and repeatable list extraction.
- Why it stands out: polished onboarding, prebuilt robots, and a clear path from website to spreadsheet or API-like output.
- Watchout: complex, high-volume jobs can get expensive or operationally awkward faster than API-first stacks.
- Pricing model: free plan, paid plans, premium/managed tier.
3. Bardeen
Bardeen is most compelling when scraping is just one action inside a broader browser automation flow. If you're moving data into CRMs, spreadsheets, or outbound workflows, its automation angle matters more than raw scraping depth.
- Best for: revenue ops, lead workflows, and browser-native task automation.
- Why it stands out: stronger workflow automation story than pure extraction tools.
- Watchout: it's not the cleanest fit when the scraping itself is complex and mission-critical.
- Pricing model: free plan and paid plans.
4. Diffbot
Diffbot is here for teams that need AI extraction at enterprise scale, not for users looking for the cheapest or simplest route. It makes more sense when structured data quality and large-scale ingestion matter more than hands-on control.
- Best for: enterprise data teams, content intelligence, and large extraction programs.
- Why it stands out: computer-vision-style extraction and strong structured output orientation.
- Watchout: overkill for small teams and high-friction if your use case is lightweight.
- Pricing model: enterprise-style plans and custom sales motion.
5. Instant Data Scraper
Instant Data Scraper still deserves a place because there are plenty of situations where you just need the visible table, directory, or list right now. It is not a platform, but it is often enough.
- Best for: one-off extraction, quick lead lists, simple directories, and visible tables.
- Why it stands out: almost zero friction for the right pages.
- Watchout: limited automation, limited depth, and weak fit for advanced workflows.
- Pricing model: free.
Best No-Code Web Scraping Tools for Repeatable Jobs
Once the job is more than an occasional scrape, visual builders and cloud execution start to matter.
6. Octoparse
Octoparse remains one of the strongest no-code platforms if you need cloud runs, template coverage, and more sophisticated task management than a browser extension can offer.
- Best for: analysts, pricing teams, and operators running recurring collection jobs.
- Why it stands out: mature task builder, cloud extraction, anti-blocking features, and a large template ecosystem.
- Watchout: it is more powerful than AI-first browser tools, but that also means more setup overhead.
- Pricing model: free plan, paid from $69/month, enterprise custom.
7. ParseHub
ParseHub is still relevant for users who want more control than an AI scraper but don't want to build a codebase. It rewards patience, not speed.
- Best for: analysts and technically curious operators who can tolerate a steeper learning curve.
- Why it stands out: flexible navigation logic and better control than lightweight browser tools.
- Watchout: the product experience feels heavier than newer entrants, especially for fast-moving business teams.
- Pricing model: free plan and paid plans.
8. Web Scraper
Web Scraper is still a reasonable entry point if you like the sitemap model and want something that starts in the browser, then grows into cloud scheduling later.
- Best for: beginners, hobby projects, and smaller repeatable jobs.
- Why it stands out: approachable sitemap workflow and easy browser-first adoption.
- Watchout: it gets limiting once you need more adaptive extraction logic.
- Pricing model: free browser extension and paid cloud plans.
9. Data Miner
Data Miner is best understood as a fast extraction utility rather than a complete scraping platform. It still earns a spot because recipe-driven work is useful for many research and prospecting tasks.
- Best for: researchers, growth teams, and quick browser-side export work.
- Why it stands out: recipe model, low friction, and easy browser export.
- Watchout: not the right tool for serious platform-scale scraping.
- Pricing model: free plan and paid plans.
Best API Platforms When Scale and Blocking Become the Real Problem
This is the layer where engineering teams stop thinking about “how do I scrape this page?” and start thinking about “how do I make this reliable at volume?”
10. Apify
Apify is the most flexible platform in this group if you want both a marketplace of reusable scrapers and a place to run your own code. It bridges no-code discovery and developer execution better than most competitors.
- Best for: hybrid teams, developer-led scraping, and reusable automation workflows.
- Why it stands out: Actor ecosystem plus custom runtime gives it unusual range.
- Watchout: once you go custom, you are back in engineering-land and the simplicity advantage fades.
- Pricing model: free plan, starter from $29/month plus usage, larger usage tiers and enterprise.
11. ScrapingBee
ScrapingBee is a good choice when your real need is “give me a rendered page and handle the ugly infrastructure for me.” It fits JS-heavy targets well.
- Best for: developers scraping dynamic sites with limited appetite for infra work.
- Why it stands out: simple API around rendering, proxies, and browser automation.
- Watchout: it is an infrastructure service, so you still own parsing, retry logic, and downstream quality.
- Pricing model: trial and paid plans.
12. ScraperAPI
ScraperAPI is still one of the easiest ways to offload proxy management and request success rates when you want to scale quickly.
- Best for: developers who need to ramp from prototype to volume fast.
- Why it stands out: straightforward API, trial credits, structured products, and scaling tiers.
- Watchout: like all API-first products, it does not remove the need for engineering judgment around parsing and data validation.
- Pricing model: 7-day trial with 5,000 credits, paid from $49/month.
13. Bright Data
Bright Data is the heavyweight option when unblock capability, proxy inventory, and managed acquisition matter more than tool simplicity.
- Best for: enterprise programs, compliance-sensitive large-scale collection, and managed data acquisition.
- Why it stands out: breadth of proxy, scraper, browser, and dataset products.
- Watchout: expensive and easy to overbuy if your core workflow is still relatively simple.
- Pricing model: usage-based and product-based pricing across APIs, proxies, and managed services.
14. Oxylabs
Oxylabs remains a strong choice for teams buying scraping as infrastructure rather than as a browser tool. It is especially relevant when reliability and procurement maturity matter.
- Best for: enterprise collection, price monitoring, SEO monitoring, and market research.
- Why it stands out: robust infrastructure story, proxy depth, and a clearer enterprise buying motion.
- Watchout: not ideal if your team wants a casual self-serve workflow.
- Pricing model: Web Scraper API starts from $49/month; other products vary by unit and usage.
15. Zyte
Zyte still deserves serious consideration from developer and data teams that want anti-detection, browser actions, JS rendering, and rotating IPs behind a single API-first story.
- Best for: technical teams building repeatable extraction systems.
- Why it stands out: browser actions, JS rendering, IP rotation, and anti-bot posture in one stack.
- Watchout: better for teams with engineering ownership than for non-technical operators.
- Pricing model: trial with $5 free credit and usage-based monthly commitments.
Best Open-Source Libraries for Developers Who Want Full Control
If you want to own the scraper stack end to end, these are the most useful building blocks in 2026.
16. Selenium
Selenium is still useful when you need QA-style interaction fidelity, legacy browser automation workflows, or very explicit user-flow control.
- Best for: interaction-heavy automation, QA overlap, and sites where browser behavior matters more than crawl throughput.
- Why it stands out: mature ecosystem and broad browser support.
- Watchout: heavier and slower than newer browser tooling for many scraping workloads.
- Pricing model: free and open-source.
17. BeautifulSoup4

BeautifulSoup is not a full scraping platform, but it remains one of the easiest ways to parse messy HTML in lightweight workflows.
- Best for: beginners, quick scripts, and parser-first tasks.
- Why it stands out: simple API and low cognitive load.
- Watchout: pair it with request, browser, or crawler tooling; on its own, it is only a parser.
- Pricing model: free and open-source.
18. Scrapy
Scrapy is still the best answer when you need a real crawler framework instead of a handful of scripts.
- Best for: production custom crawlers and internally owned data pipelines.
- Why it stands out: high performance, pipelines, middleware, and long-term extensibility.
- Watchout: there is real engineering overhead, and JS-heavy targets often require companion tooling.
- Pricing model: free and open-source.
19. Puppeteer
Puppeteer remains a strong fit for Node-first teams who want direct control over Chromium and browser scripting.
- Best for: Node-based scraping, screenshots, and browser automation tasks.
- Why it stands out: direct, powerful control of Chromium behavior.
- Watchout: narrower browser story than Playwright and still resource-hungry at scale.
- Pricing model: free and open-source.
20. Playwright
Playwright is my default recommendation for modern browser automation if your team is writing code and wants a newer abstraction than Selenium.
- Best for: modern browser automation, JS-heavy sites, and teams that care about developer ergonomics.
- Why it stands out: strong multi-browser model, reliable waiting behavior, and clean APIs.
- Watchout: you still own browser infra, concurrency, selector drift, and data validation.
- Pricing model: free and open-source.
My Shortlist by Team Type
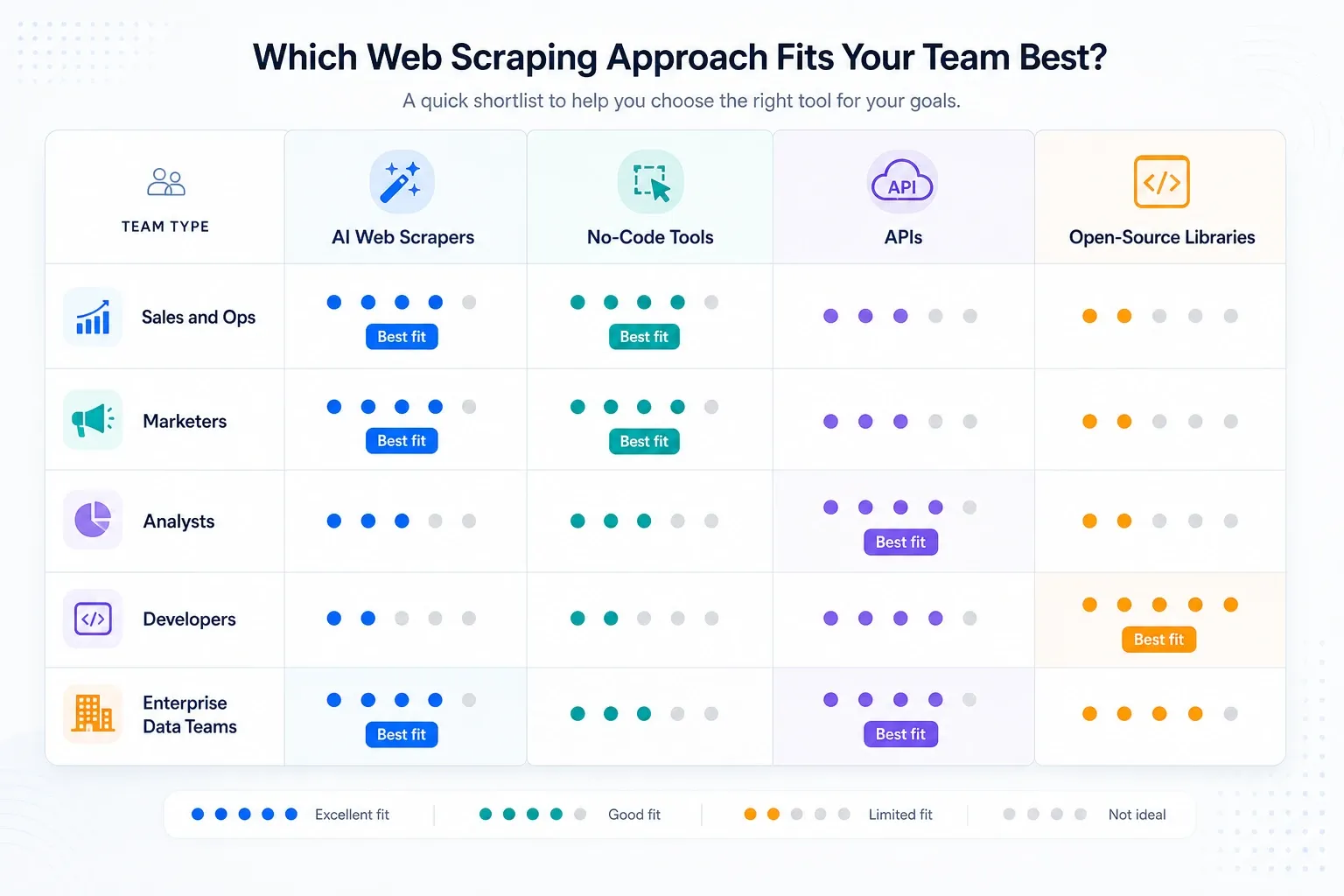
- Sales and ops teams: start with Thunderbit, then look at Browse AI if monitoring matters more than subpage enrichment.
- Analysts and research teams: Octoparse first if recurring jobs are bigger than browser-extension tools can comfortably handle.
- Automation-heavy GTM teams: Bardeen if scraping is only one step in a wider workflow.
- Developer teams building internal tooling: Apify, Zyte, ScraperAPI, or Playwright depending on how much stack ownership you want.
- Enterprise data programs: Bright Data, Oxylabs, Diffbot, and Zyte are the serious infrastructure conversations.
When to Move Down-Stack
Use this rule:
- Stay with AI tools until you hit repeatability or edge-case limits.
- Move to no-code tools when scheduling, pagination, anti-blocking, or cloud runs matter more than one-click simplicity.
- Move to APIs when unblock rate, JS rendering, and concurrency become the real bottlenecks.
- Move to open-source libraries when the cost of vendor abstraction becomes higher than the cost of owning the whole stack.
Most teams move down-stack too early. That's one of the most common mistakes I see.
Final Take
For most non-technical teams, the right answer in 2026 is not “the most powerful scraper.” It's the tool that gets accurate data into the next workflow with the least maintenance. That's why AI-first tools continue to win for operators, while APIs and open-source stacks remain the better fit for technical teams with clear scale requirements.
If you want the shortest path from page to structured output, start with Thunderbit. If you already know your job needs heavy infrastructure, jump directly to the API and developer layers. Just don't confuse complexity with sophistication.
FAQs
1. What is the best web scraping tool for non-technical users in 2026?
For most non-technical users, AI-first tools like Thunderbit and Browse AI offer the fastest path to useful data because they reduce selector work, setup friction, and maintenance overhead.
2. What should I choose if my sites are JavaScript-heavy or block requests aggressively?
Move toward ScrapingBee, ScraperAPI, Zyte, Bright Data, Oxylabs, Playwright, or Selenium depending on whether you want a managed service or direct engineering control.
3. Are no-code tools still relevant now that AI web scrapers are better?
Yes. No-code tools like Octoparse and ParseHub still matter when you need more explicit control over task logic, cloud execution, and repeatable job management.
4. Which tools make the most sense for engineering teams?
Apify, Zyte, ScraperAPI, Scrapy, Playwright, Puppeteer, and Selenium are the most natural choices when developers own the workflow.
5. How should I shortlist quickly instead of over-researching?
First choose the tool type, not the vendor. Decide whether you need AI simplicity, no-code control, API infrastructure, or open-source ownership. Then compare products inside that layer.
Related Reading