
Facebook scraping is still worth doing in 2026, but only if you choose the right collection model. Pew Research Center reported on November 20, 2025 that , and Meta said on April 29, 2026 that its in March 2026. That scale keeps Facebook useful for Marketplace monitoring, public-page research, lead generation, and competitor tracking. The hard part is not finding use cases. The hard part is getting clean data without getting stuck on login walls, dynamic loads, temporary blocks, or brittle scraping setups.
This annual shortlist is built for decision speed. I re-checked the official product pages, docs, and pricing signals on May 8, 2026, then kept the list focused on tools that still make sense for real business users. If your workflow is mostly “grab the data on this page and send it to a sheet,” start with Thunderbit. If you need API-scale infrastructure, Bright Data, Apify, and Nimble by Nimbleway belong near the top of the list. If your job includes cloud automations or follow-up actions after collection, PhantomBuster deserves a closer look.
Quick Picks by Job
- Need the fastest no-code Facebook or Marketplace export? Start with .
- Need enterprise API scale and managed unblocking? Shortlist .
- Need flexible cloud scraping workflows? Look closely at .
- Need API-first public-web collection with less scraper maintenance? Consider .
- Need a budget-friendly API for lighter jobs? is still relevant.
- Need scraping plus workflow automation? is the better fit.
- Need a point-and-click workflow builder with scheduling? remains a solid no-code option.
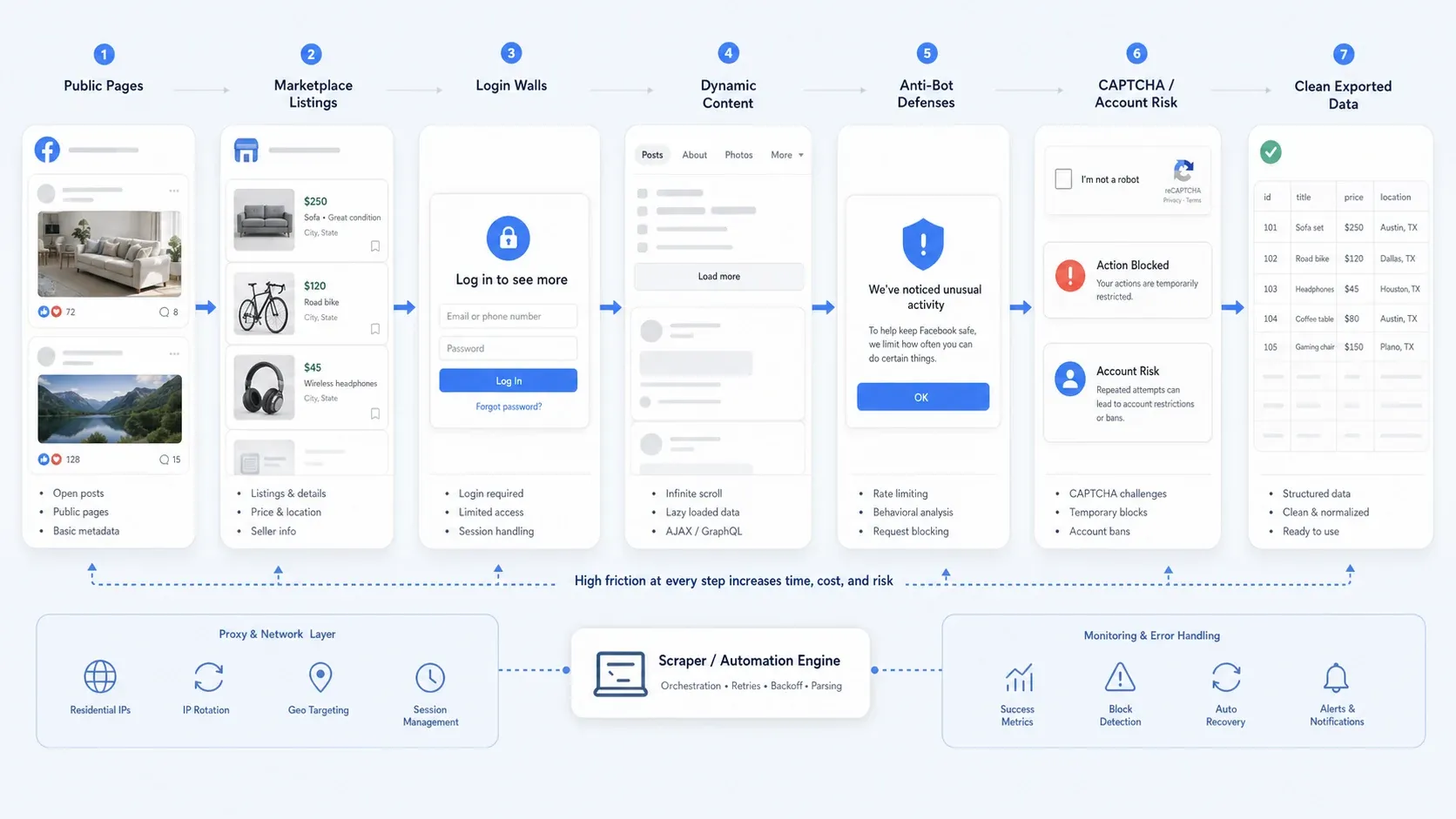
Why Facebook Scraping Is Still Hard in 2026
Facebook data collection is rarely just a selector problem anymore. In practice, most teams run into one or more of these issues:
- Partial public access: Some pages stay public, while other flows push you toward login to see more detail.
- Dynamic content: Marketplace views, long comment threads, and page content often load incrementally.
- Anti-bot defenses: Rate limiting, behavioral checks, CAPTCHAs, and temporary action blocks break naive automations.
- Operational risk: Login-only collection is much riskier than public-page scraping, especially if you care about account safety and repeatability.
How I Evaluated These Tools
I optimized this page for shortlist-building, not feature-padding. The tools here were compared on:
- Workflow fit: Does the product actually match Facebook and Marketplace collection jobs that real teams run?
- Ease of use: Can non-developers or lean teams get to usable output quickly?
- Scale and reliability: Does the tool still make sense once you move past a one-off scrape?
- Anti-bot and session handling: How much infrastructure pain does the product remove?
- Output quality: Can you get structured data into CSV, Sheets, or downstream systems without major cleanup?
- Pricing signal: Is the product practical to evaluate, or does it require a heavyweight enterprise motion?
- Compliance posture: Is the tool clearly oriented around public-data collection and responsible use?
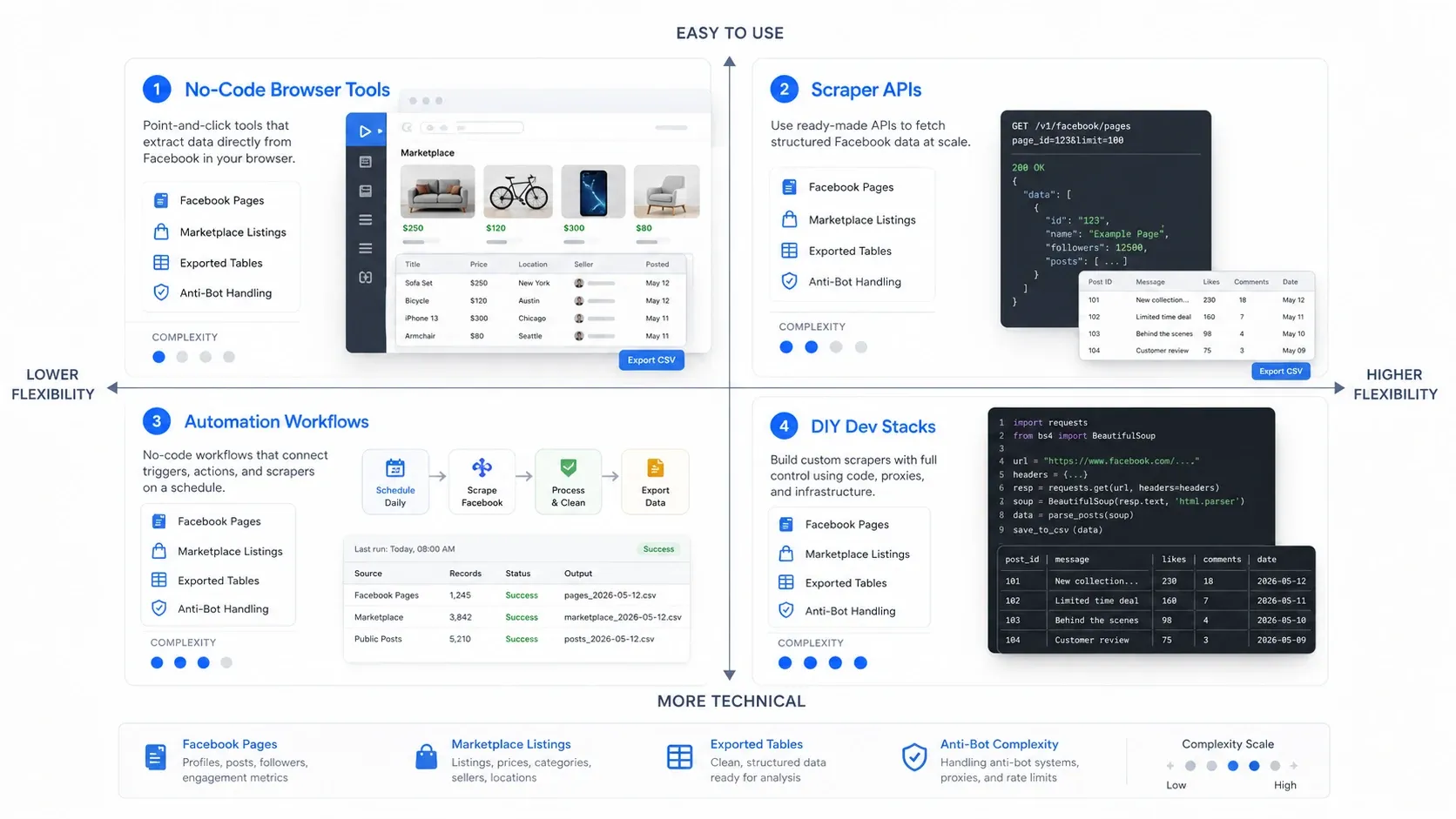
Which Type of Facebook Scraper Do You Need?
The fastest way to choose well is to choose the right category first. Facebook scraping tools usually fall into four operating models:
- No-code browser tools: Best when you want fast extraction from the page already open in front of you.
- Scraper APIs: Best when you need reliable, repeatable collection at higher volume.
- Automation workflows: Best when scraping is only one step in a broader go-to-market process.
- DIY dev stacks: Best when your team wants maximum control and is prepared to own the maintenance burden.
Comparison Table
| Tool | Best For | Why It Made the Shortlist | Pricing Signal |
|---|---|---|---|
| Thunderbit | Non-technical teams and fast ad-hoc jobs | AI field detection, browser-native dynamic page handling, fast exports | Free trial; credit-based paid plans |
| Bright Data | Large-scale public social data pipelines | Dedicated social media scraper APIs, managed unblocking, strong scale | Usage-based and enterprise pricing |
| Apify | Flexible cloud scraping workflows | Ready-made Facebook actors, scheduling, API access, customization room | Paid platform plans plus metered usage |
| Nimble by Nimbleway | API-first public web collection | URL-first API flow and lower scraper-maintenance burden | Sales-led pricing |
| ScrapingBot | Small public-data jobs and prototypes | Simple API, rendering support, lower entry pricing | Free tier; paid plans from about $22/month |
| PhantomBuster | GTM automation workflows | Cloud automations, browser-action workflows, lead-gen fit | Free trial; paid plans from about $56/month |
| Octoparse | Visual no-code scheduled scraping | Point-and-click builder, cloud extraction, repeatable workflows | Free plan; paid plans from about $119/month |
1. Thunderbit
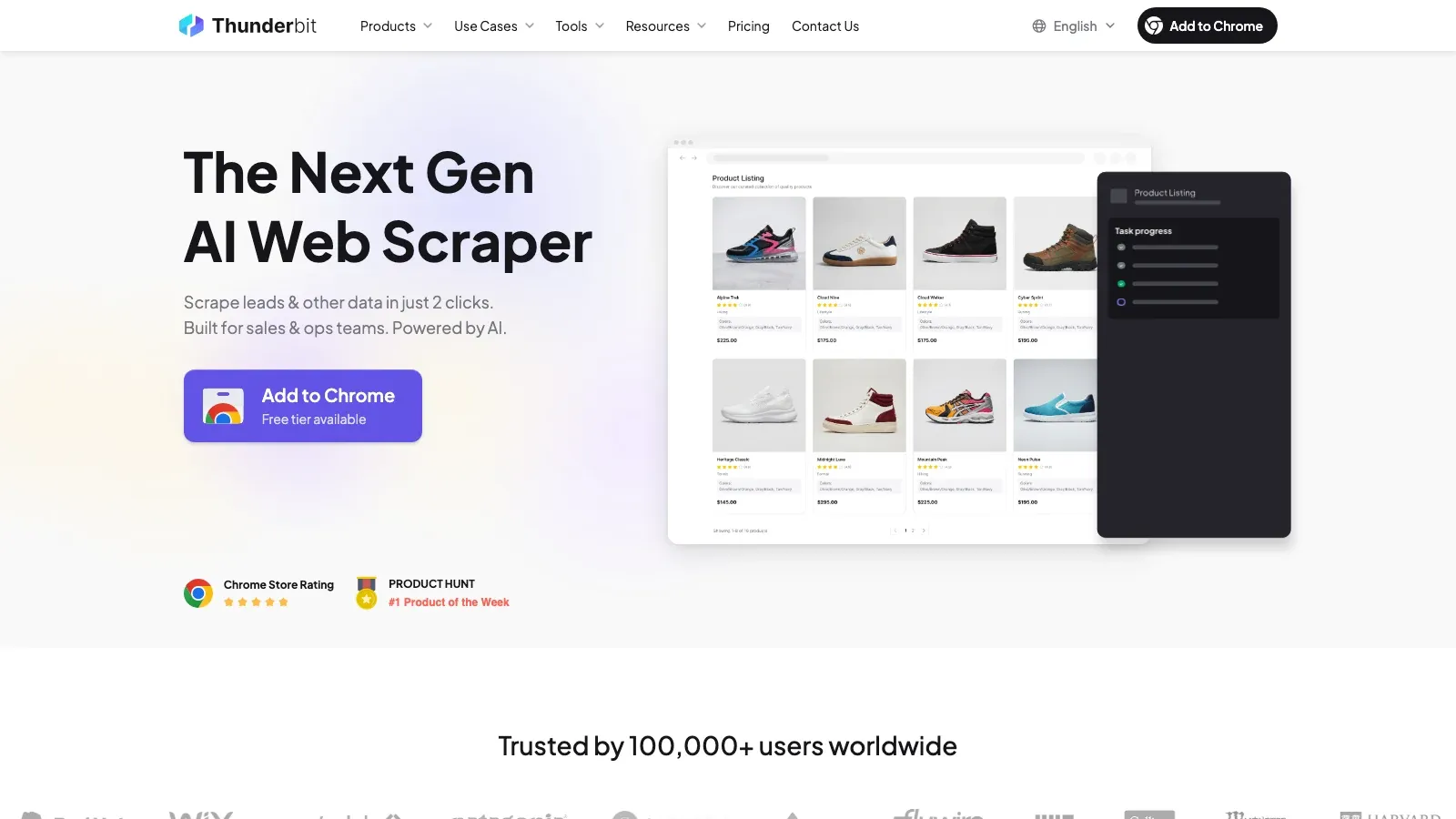
is the strongest choice here if your goal is to turn a Facebook page or Marketplace result list into structured data quickly without building or maintaining a scraper. Its core advantage is semantic extraction: it reads the page, suggests useful fields, and lets you export the result without dealing with selectors, proxies, or code.
Why it stands out:
- AI Suggest Fields: Thunderbit identifies likely fields such as title, price, seller, location, contact details, and URLs.
- Browser-native handling: Because it runs where the page is rendered, it works well on dynamic, scroll-heavy pages.
- Subpage enrichment: You can collect list data first, then open each listing or page for richer detail.
- Useful exports: Excel, Google Sheets, Airtable, and Notion are all natural endpoints.
If you want one video before testing a browser-native workflow yourself, this hands-on Thunderbit walkthrough is the most useful place to start because it shows the actual extraction flow instead of staying at the feature-claim level:
Best for: non-technical users, sales teams, operators, and researchers who want results fast.
Pricing signal: Free trial available; paid plans are credit-based. Check .
2. Bright Data
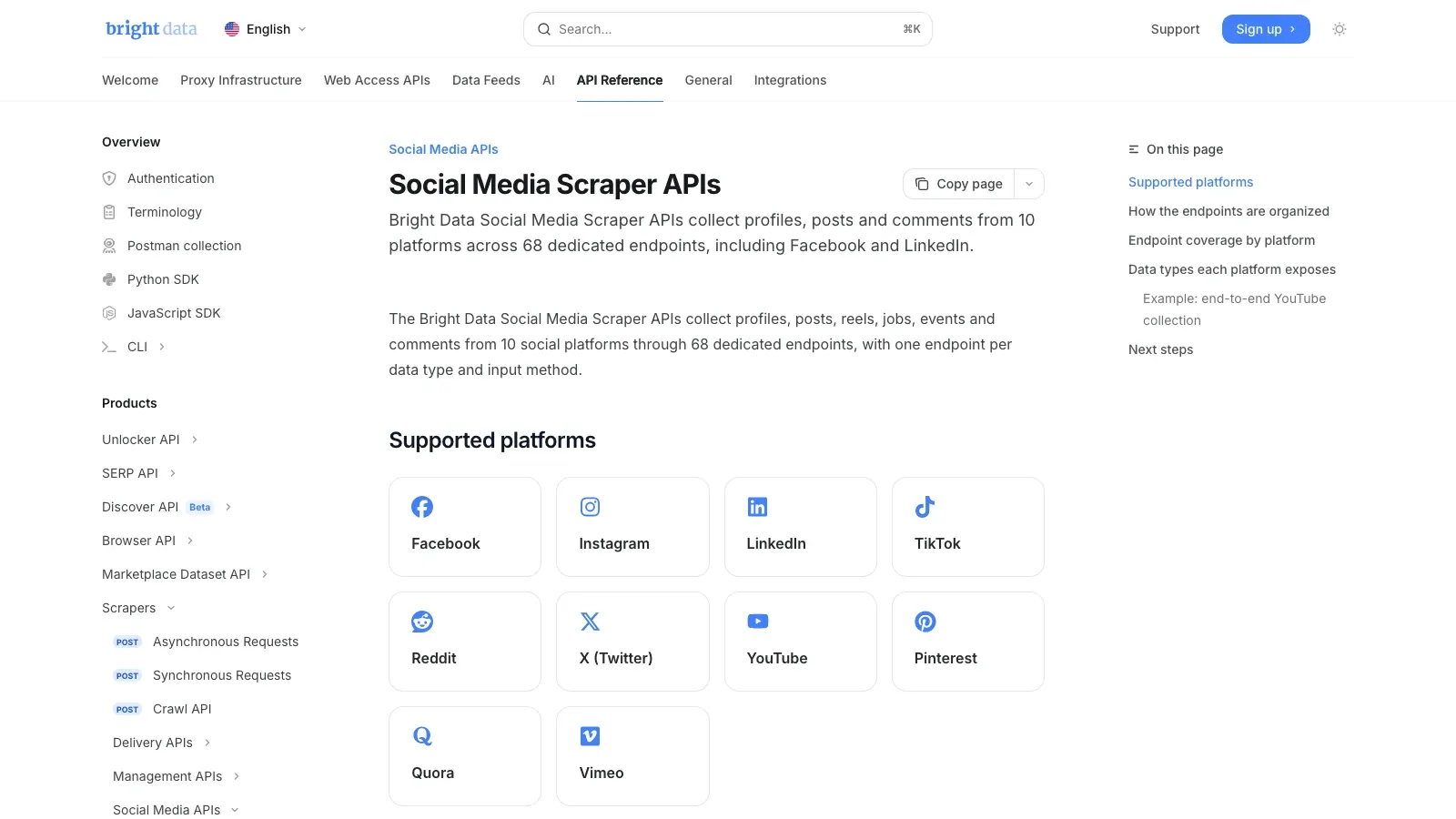
is the infrastructure-first pick. Bright Data’s own docs say its cover 10 platforms and 68 dedicated endpoints, including Facebook. If your job is large-scale public data collection, this kind of managed API stack is usually more realistic than trying to scale a browser extension or a hand-rolled scraper.
Why it belongs on the shortlist:
- Dedicated social-media scraping endpoints
- Managed unblocking and extraction
- Structured output delivery for data pipelines
- Better fit for reliability-sensitive monitoring and analytics jobs
Best for: analysts, data teams, large monitoring projects, and public social datasets at scale.
Pricing signal: Pricing varies by product and volume. Verify against .
3. Apify
stays relevant because it gives you a strong middle ground between templates and full customization. Its Facebook Pages Scraper actor is a useful starting point, while the broader Apify platform gives you cloud runs, scheduling, APIs, and room to extend the workflow if your needs become more complex.
Why it made the list:
- Ready-made Facebook actors
- Cloud execution and recurring schedules
- Flexible exports and API access
- Easier to extend than a pure no-code browser workflow
Best for: technical marketers, agencies, ops teams, and recurring collection jobs across multiple sites.
Pricing signal: Platform plans are paid and actor usage is metered separately. Check .
4. Nimble by Nimbleway
is the API-first option for teams that want to send a URL and let the platform handle access, rendering, and delivery. Nimble positions its as end-to-end public web data collection, which makes it useful when Facebook scraping is just one part of a broader data stack.
Why it is worth evaluating:
- URL-first API workflow
- Less scraper-maintenance burden for engineering teams
- Good fit for resilient public web extraction
- Useful when scraped data feeds internal products or dashboards
Best for: engineering-led teams, product data pipelines, and organizations that want infrastructure abstraction instead of point tools.
Pricing signal: Nimble does not emphasize public self-serve pricing on its core API pages, so expect sales-led pricing and verify directly with .
5. ScrapingBot
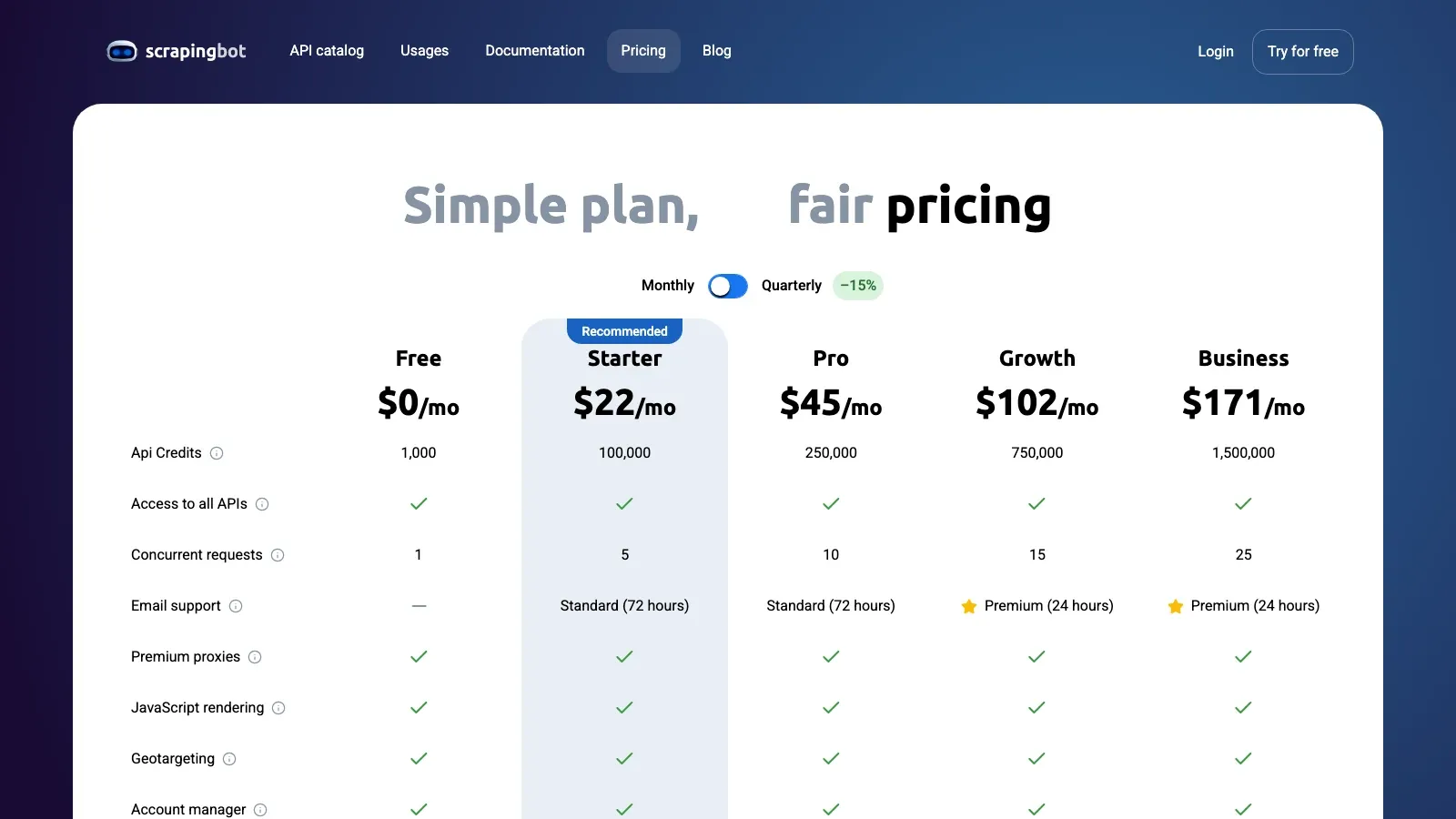
is the budget-conscious API option in this list. It is not the deepest Facebook-specialized platform here, but it still makes sense for smaller public-data jobs where you want an API, rendering support, and a lower cost floor than enterprise scraping infrastructure.
Where it fits:
- Simple API-driven public scraping
- Lower entry pricing
- Rendering and proxy handling included
- Better for prototypes and light recurring pulls than large intelligence programs
Best for: startups, small businesses, and developers testing lighter public-page collection use cases.
Pricing signal: Free tier available; the current public pricing page starts paid plans at about .
6. PhantomBuster
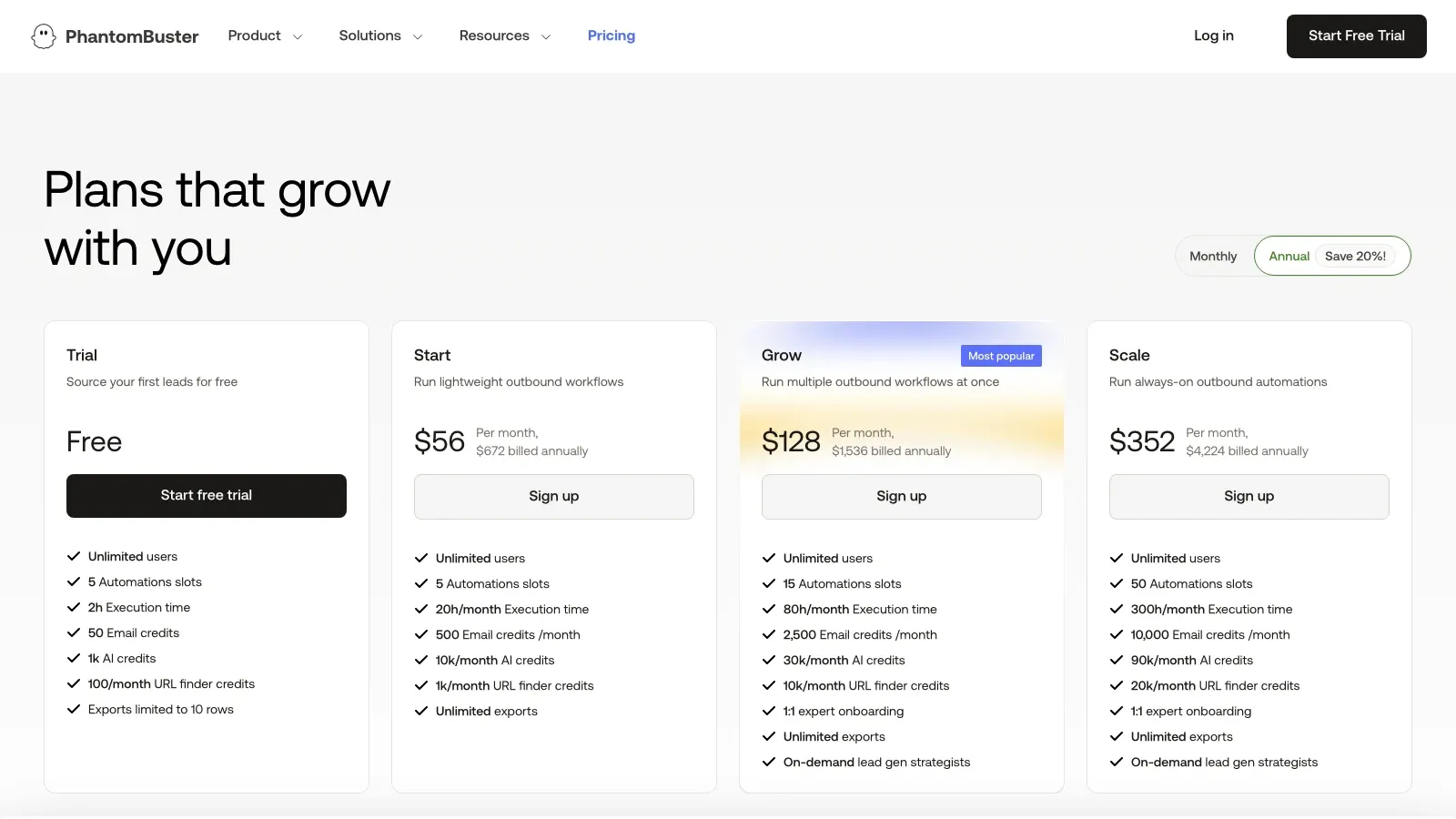
is less about raw scraping infrastructure and more about what happens after collection. If your use case is “collect the data, then trigger outreach, enrichment, or follow-up actions,” PhantomBuster is often more useful than a plain extractor because it is designed around cloud automations and browser-action workflows.
Why teams still shortlist it:
- Cloud-based automation workflows
- Useful for lead generation and GTM operations
- Stronger fit when scraping is one step in a broader process
- Practical for operators who care about actions, not just exports
Best for: GTM teams, growth teams, recruiters, and operators chaining collection into downstream action.
Pricing signal: Free trial available; paid plans on the current pricing page start at about .
7. Octoparse
remains one of the better no-code visual scraping tools for users who want repeatable workflows and scheduled cloud runs. It is not as lightweight as Thunderbit for quick one-off Facebook jobs, but it gives non-developers more explicit control over how the extraction logic is built and repeated.
Why it stays relevant:
- Point-and-click visual workflow builder
- Cloud extraction and scheduling
- Good for structured repeated tasks
- Better suited to analysts who want repeatability without code
Best for: non-technical analysts, SMB ops teams, and repeatable collection tasks with more explicit workflow logic.
Pricing signal: Octoparse’s public pricing page lists paid plans starting at about .
Shortlist by Team
If you already know what kind of team will own the workflow, start here:
- Solo operator or small business: Thunderbit, ScrapingBot, or Octoparse
- Sales / GTM team: Thunderbit or PhantomBuster
- Ops analyst: Thunderbit, Apify, or Octoparse
- Growth automation team: PhantomBuster or Apify
- Data engineering team: Bright Data, Nimble, or Apify

How to Choose the Right Facebook Scraper
- Choose Thunderbit if speed and simplicity matter more than maximum scale.
- Choose Bright Data if you need public-data scale and managed reliability.
- Choose Apify if you want platform flexibility and actor-based workflows.
- Choose Nimble if you want an API-first abstraction layer with less scraper maintenance.
- Choose PhantomBuster if scraping is only one step in a broader GTM automation workflow.
- Choose Octoparse if you want visual repeatability without code.
- Choose ScrapingBot if budget matters and the job is relatively simple.
Final Takeaway
The market split is clearer in 2026 than it was a year ago. You are not really choosing one universal “best Facebook scraper.” You are choosing a collection model: fast no-code extraction, managed API scale, cloud automation, or hands-on visual workflow control. Start there and the shortlist gets much easier.
If your team wants the fastest path from a Facebook page or Marketplace listing to usable structured data, Thunderbit is still the easiest place to start. If your volume or engineering requirements are much heavier, Bright Data, Apify, and Nimble make more sense. If your workflow begins with scraping but ends in follow-up actions, PhantomBuster is the smarter shortlist.
FAQs
1. What is the easiest Facebook scraping tool for non-technical users?
Thunderbit is the easiest starting point for most non-technical users because it works in the browser, suggests fields automatically, and exports data quickly without code.
2. Which Facebook scraping tool is best for large-scale public data collection?
Bright Data is the strongest infrastructure pick in this list when the job is large-scale public social data collection and reliability matters more than ease of use.
3. What if I need scraping plus follow-up automation?
PhantomBuster is the better fit when data collection is only one step in a broader lead generation or GTM workflow.
4. Is Facebook scraping still difficult in 2026?
Yes. Dynamic content, login walls, rate limits, anti-bot systems, and account-risk issues still make Facebook more difficult than scraping simpler public websites.
5. How should teams think about compliance?
Stay focused on public data, use reasonable rates, avoid credential abuse, and review the platform terms and applicable privacy rules before scaling a workflow.
Further reading: