

The web isn’t what it used to be. These days, nearly every site you visit is powered by JavaScript, loading content on the fly—think infinite scrolls, pop-ups, and dashboards that only reveal their secrets after a click or two. In fact, a whopping 98.7% of all websites now use JavaScript, which means the old-school scraping tools that just read static HTML are missing out on a ton of valuable data. If you’ve ever tried to scrape product prices from a modern e-commerce site or pull real estate listings from an interactive map, you know the frustration: the data you want just isn’t there in the source code.
That’s where scraping with Selenium comes in. As someone who’s spent years building automation tools (and, yes, scraping more than my fair share of websites), I can tell you: mastering Selenium is a superpower for anyone who needs up-to-date, dynamic data. In this hands-on Selenium web scraping tutorial, I’ll walk you through the key steps—from setup to automation—and show you how to combine Selenium with Thunderbit for structured, ready-to-export data. Whether you’re a business analyst, a sales pro, or just a curious Python user, you’ll walk away with practical skills and a few laughs (because, let’s face it, debugging XPath selectors can be character-building).
What is Selenium and Why Use It for Web Scraping?
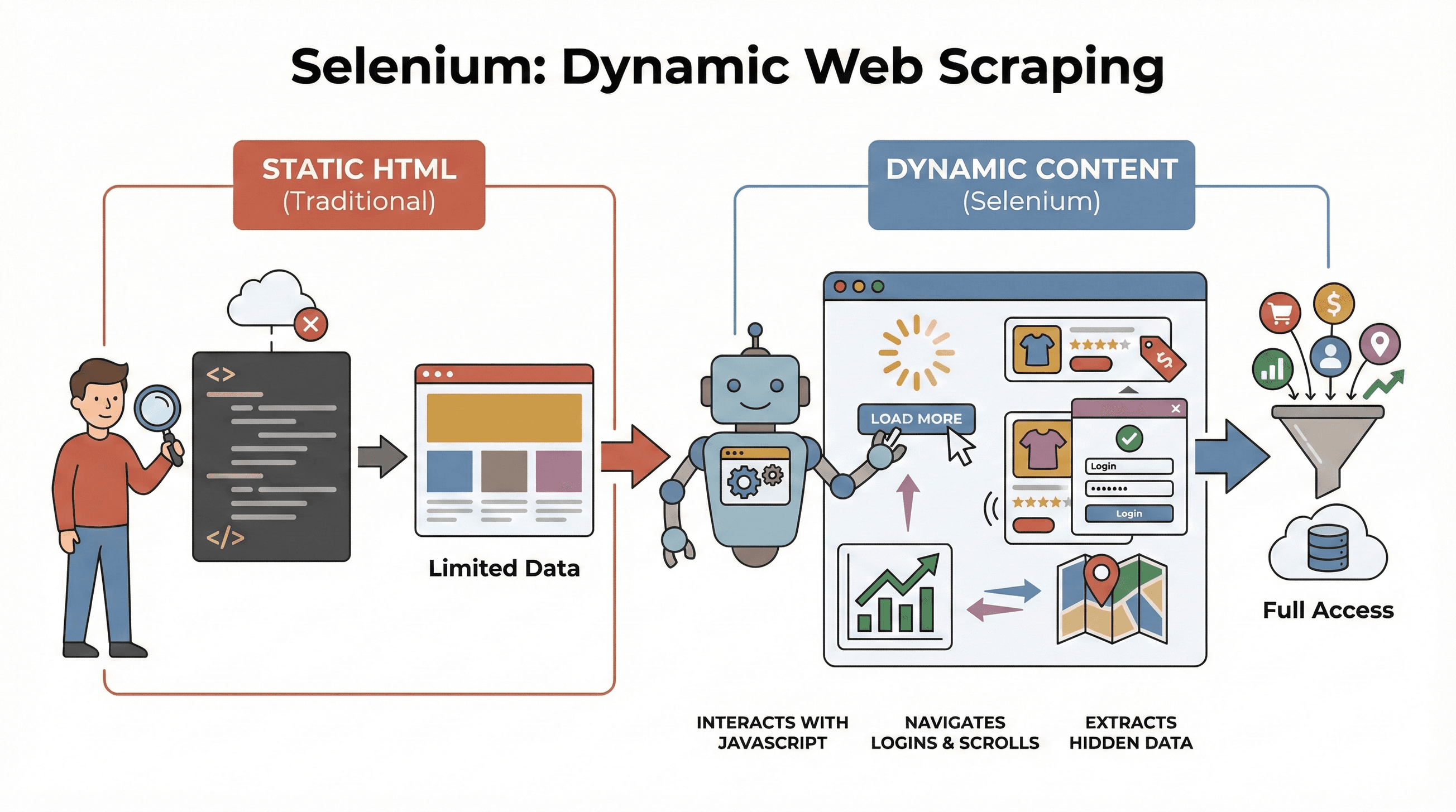 Let’s start with the basics. Selenium is an open-source framework that lets you control a real web browser—like Chrome or Firefox—using code. Think of it as a robot that can open pages, click buttons, fill out forms, scroll, and even run JavaScript, just like a human user. This is a big deal because most modern websites don’t show you all their data up front. Instead, they load content dynamically, often after you interact with the page.
Let’s start with the basics. Selenium is an open-source framework that lets you control a real web browser—like Chrome or Firefox—using code. Think of it as a robot that can open pages, click buttons, fill out forms, scroll, and even run JavaScript, just like a human user. This is a big deal because most modern websites don’t show you all their data up front. Instead, they load content dynamically, often after you interact with the page.
What Is Data Scraping and How to Do It in 2026 Get Started Free
Why does this matter for scraping? Traditional tools like BeautifulSoup or Scrapy are great for static HTML, but they can’t “see” anything loaded by JavaScript after the initial page load. Selenium, on the other hand, can interact with the page in real time, making it perfect for:
- Scraping product lists that only appear after clicking “Load More”
- Grabbing prices or reviews that update dynamically
- Navigating through login forms, pop-ups, or infinite scrolls
- Extracting data from dashboards, maps, or other interactive elements
In short, Selenium is your go-to tool when you need to scrape data that only appears after the page has finished loading—or after a user action.
Key Steps for Python Selenium Web Scraping
Scraping with Selenium boils down to three essential steps:
| Step | What You Do | Why It Matters |
|---|---|---|
| 1. Environment Setup | Install Selenium, WebDriver, and Python libraries | Get your tools ready and avoid setup headaches |
| 2. Element Location | Find the data you want using IDs, classes, XPath, etc. | Target the right info, even if it’s hidden by JavaScript |
| 3. Data Extraction & Saving | Pull out text, links, or tables and save to CSV/Excel | Turn raw web data into something you can use |
Let’s dive into each step with practical examples and code you can copy, tweak, and brag about to your friends.
Step 1: Setting Up Your Python Selenium Environment
First things first: you need to install Selenium and a browser driver (like ChromeDriver for Chrome). The good news? It’s easier than ever.
Install Selenium
Open your terminal and run:
pip install selenium
Get a WebDriver
- Chrome: Download ChromeDriver (make sure it matches your Chrome version).
- Firefox: Download GeckoDriver.
Pro tip: With Selenium 4.6+, you can use Selenium Manager to auto-download drivers, so you might not even need to mess with PATH variables anymore (docs).
Your First Selenium Script
Here’s a quick “hello world” for Selenium:
from selenium import webdriver
driver = webdriver.Chrome() # Or webdriver.Firefox()
driver.get("https://example.com")
print(driver.title)
driver.quit()
Troubleshooting tips:
- If you get a “driver not found” error, check your PATH or use Selenium Manager.
- Make sure your browser and driver versions match.
- If you’re on a headless server (no GUI), see the headless mode tips below.
Step 2: Locating Web Elements for Data Extraction
Now for the fun part: telling Selenium what data you want. Websites are built with elements—divs, spans, tables, you name it—and Selenium gives you several ways to find them.
Common Locator Strategies
By.ID: Find an element with a unique IDBy.CLASS_NAME: Find elements by CSS classBy.XPATH: Use XPath expressions (super flexible, but can be fragile)By.CSS_SELECTOR: Use CSS selectors (great for complex queries)
Here’s how you might use them:
from selenium.webdriver.common.by import By
# Find by ID
price = driver.find_element(By.ID, "price").text
# Find by XPath
title = driver.find_element(By.XPATH, "//h1").text
# Find all product images by CSS selector
images = driver.find_elements(By.CSS_SELECTOR, ".product img")
for img in images:
print(img.get_attribute("src"))
Pro tip: Always use the simplest, most stable locator (ID > class > CSS > XPath). And if you’re scraping a page that loads data after a delay, use explicit waits:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
price_elem = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".price")))
This keeps your script from crashing if the data takes a second to show up.
Step 3: Extracting and Saving Data
Once you’ve found your elements, it’s time to grab the data and save it somewhere useful.
Extracting Text, Links, and Tables
Let’s say you’re scraping a table of products:
data = []
rows = driver.find_elements(By.XPATH, "//table/tbody/tr")
for row in rows:
cells = row.find_elements(By.TAG_NAME, "td")
data.append([cell.text for cell in cells])
Saving to CSV with Pandas
import pandas as pd
df = pd.DataFrame(data, columns=["Name", "Price", "Stock"])
df.to_csv("products.csv", index=False)
You can also save to Excel (df.to_excel("products.xlsx")) or even push to Google Sheets using their API.
Full Example: Scraping Product Titles and Prices
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
driver = webdriver.Chrome()
driver.get("https://example.com/products")
data = []
products = driver.find_elements(By.CLASS_NAME, "product-card")
for p in products:
title = p.find_element(By.CLASS_NAME, "title").text
price = p.find_element(By.CLASS_NAME, "price").text
data.append([title, price])
driver.quit()
df = pd.DataFrame(data, columns=["Title", "Price"])
df.to_csv("products.csv", index=False)
Selenium vs. BeautifulSoup and Scrapy: What Makes Selenium Unique?
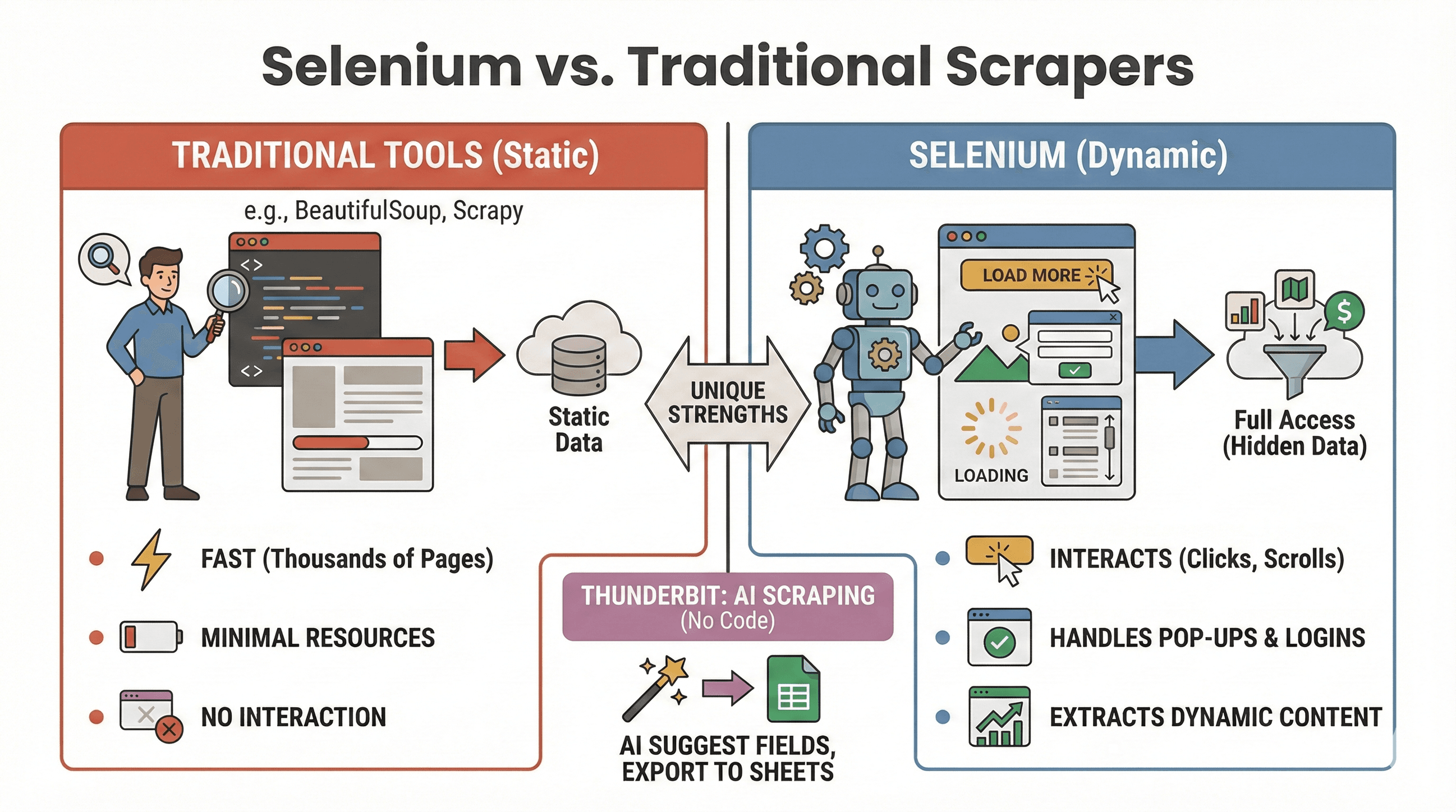 Let’s settle the debate: when should you use Selenium, and when is something like BeautifulSoup or Scrapy a better fit? Here’s a quick comparison:
Let’s settle the debate: when should you use Selenium, and when is something like BeautifulSoup or Scrapy a better fit? Here’s a quick comparison:
| Tool | Best For | Handles JavaScript? | Speed & Resource Use |
|---|---|---|---|
| Selenium | Dynamic/interactive sites | Yes | Slower, uses more memory |
| BeautifulSoup | Simple static HTML scraping | No | Very fast, lightweight |
| Scrapy | High-volume static site crawling | Limited* | Super fast, async, low RAM |
| Thunderbit | No-code, business scraping | Yes (AI) | Fast for small/medium jobs |
*Scrapy can handle some dynamic content with plugins, but it’s not its strong suit (ScrapingBee).
When to use Selenium:
- The data only appears after clicking, scrolling, or logging in
- You need to interact with pop-ups, infinite scrolls, or dynamic dashboards
- Static scrapers just aren’t cutting it
When to use BeautifulSoup/Scrapy:
- The data is in the initial HTML
- You need to scrape thousands of pages quickly
- You want minimal resource usage
And if you want to skip coding altogether, Thunderbit lets you scrape dynamic sites with AI—just click “AI Suggest Fields” and export to Sheets, Notion, or Airtable. (More on that below.)
How to Scrape Any Website Using AI Get Started Free
Automating Web Scraping Tasks with Selenium and Python
Let’s be honest: nobody wants to wake up at 2 a.m. to run a scraping script. The good news is, you can automate your Selenium jobs using Python’s scheduling tools or your operating system’s scheduler (like cron on Linux/Mac or Task Scheduler on Windows).
Using the schedule Library
import schedule
import time
def job():
# Your scraping code here
print("Scraping...")
schedule.every().day.at("09:00").do(job)
while True:
schedule.run_pending()
time.sleep(1)
Or with Cron (Linux/Mac)
Add this to your crontab to run every hour:
0 * * * * python /path/to/your_script.py
Tips for automation:
- Run Selenium in headless mode (see below) to avoid GUI pop-ups.
- Log errors and send yourself alerts if something goes wrong.
- Always close the browser with
driver.quit()to free up resources.
Boosting Efficiency: Tips for Faster and More Reliable Selenium Scraping
Selenium is powerful, but it can be slow and resource-hungry if you’re not careful. Here’s how to speed things up and avoid common headaches:
1. Run in Headless Mode
No need to watch Chrome open and close a hundred times. Headless mode runs the browser in the background:
from selenium.webdriver.chrome.options import Options
opts = Options()
opts.headless = True
driver = webdriver.Chrome(options=opts)
2. Block Images and Other Unnecessary Content
Why load images if you’re just scraping text? Block them to speed up page loads:
prefs = {"profile.managed_default_content_settings.images": 2}
opts.add_experimental_option("prefs", prefs)
3. Use Efficient Locators
- Prefer IDs or simple CSS selectors over complex XPaths.
- Avoid using
time.sleep()—use explicit waits (WebDriverWait) instead.
4. Randomize Delays
Add random pauses to mimic human browsing and avoid getting blocked:
import random, time
time.sleep(random.uniform(1, 3))
5. Rotate User Agents and IPs (If Needed)
If you’re scraping a lot, rotate your user agent string and consider using proxies to avoid simple anti-bot measures.
6. Manage Sessions and Errors
- Use try/except blocks to handle missing elements gracefully.
- Log errors and take screenshots for debugging.
For more optimization tips, check out BrowserStack’s guide.
Advanced: Combining Selenium with Thunderbit for Structured Data Export
Here’s where things get really interesting—especially if you want to save time on data cleanup and export.
After you’ve scraped raw data with Selenium, you can use Thunderbit to:
- Auto-detect fields: Thunderbit’s AI can read your scraped pages or CSVs and suggest column names (“AI Suggest Fields”).
- Subpage scraping: If you have a list of URLs (like product pages), Thunderbit can visit each one and enrich your table with more details—no extra code needed.
- Data enrichment: Translate, categorize, or analyze data on the fly.
- Export anywhere: One-click export to Google Sheets, Airtable, Notion, CSV, or Excel.
Workflow Example:
- Use Selenium to scrape a list of product URLs and titles.
- Export the data to CSV.
- Open Thunderbit, import your CSV, and let the AI suggest fields.
- Use Thunderbit’s subpage scraping to pull more details (like images or specs) from each product URL.
- Export your final, structured dataset to Sheets or Notion.
This combo saves hours of manual cleanup and lets you focus on analysis, not wrangling messy data. For more on this workflow, check out Thunderbit’s Selenium guide.
Export Selenium Data with Thunderbit AI
Best Practices and Troubleshooting for Selenium Web Scraping
Web scraping is a bit like fishing: sometimes you catch a big one, sometimes you get tangled in weeds. Here’s how to keep your scripts reliable—and ethical:
Best Practices
- Respect robots.txt and site terms: Always check if scraping is allowed.
- Throttle your requests: Don’t overload servers—add delays and watch for HTTP 429 errors.
- Use APIs when available: If the data is public via API, use it—it’s safer and more reliable.
- Scrape only public data: Avoid personal or sensitive info, and be mindful of privacy laws.
- Handle pop-ups and CAPTCHAs: Use Selenium to close pop-ups, but be careful with CAPTCHAs—they’re tough to automate.
- Randomize user agents and delays: Helps avoid detection and blocking.
Common Errors and Fixes
| Error | What It Means | How to Fix |
|---|---|---|
NoSuchElementException | Can’t find the element | Double-check your locator; use waits |
| Timeout errors | Page or element took too long | Increase wait time; check network speed |
| Driver/browser mismatch | Selenium can’t launch browser | Update your driver and browser versions |
| Session crashes | Browser closed unexpectedly | Use headless mode; manage resources |
For more troubleshooting tips, see Thunderbit’s Selenium tutorial.
Conclusion & Key Takeaways
Dynamic web scraping isn’t just for hardcore developers anymore. With Python Selenium, you can automate any browser, interact with the trickiest JavaScript-heavy sites, and pull out the data your business needs—whether it’s for sales, research, or just satisfying your curiosity. Remember:
- Selenium is the tool of choice for dynamic, interactive sites.
- The three key steps: setup, locate, extract & save.
- Automate your scripts for regular data updates.
- Optimize for speed and reliability with headless mode, smart waits, and efficient locators.
- Combine Selenium with Thunderbit for easy data structuring and export—especially if you want to skip the spreadsheet headaches.
Ready to try it yourself? Start with the code examples above, and when you’re ready to take your scraping to the next level, give Thunderbit a spin for instant, AI-powered data cleanup and export. And if you’re hungry for more, check out the Thunderbit Blog for deep dives, tutorials, and the latest in web automation.
Happy scraping—and may your selectors always find what you’re looking for.
Try Thunderbit AI Web Scraper for Free Get Started Free
FAQs
1. Why should I use Selenium for web scraping instead of BeautifulSoup or Scrapy?
Selenium is ideal for scraping dynamic websites where content loads after user actions or JavaScript execution. BeautifulSoup and Scrapy are faster for static HTML but can’t interact with dynamic elements or simulate clicks and scrolls.
2. How do I make my Selenium scraper run faster?
Use headless mode, block images and unnecessary resources, use efficient locators, and add random delays to mimic human browsing. See BrowserStack’s guide for more tips.
3. Can I schedule Selenium scraping tasks to run automatically?
Yes! Use Python’s schedule library or your OS’s scheduler (cron or Task Scheduler) to run scripts at set intervals. Automating scraping helps keep your data up to date.
4. What’s the best way to export data scraped with Selenium?
Use Pandas to save data to CSV or Excel. For more advanced exports (Google Sheets, Notion, Airtable), import your data into Thunderbit and use its one-click export features.
5. How can I handle pop-ups and CAPTCHAs in Selenium?
You can close pop-ups by locating and clicking their close buttons. CAPTCHAs are much harder—if you encounter them, consider using a manual workaround or a captcha-solving service, and always respect site terms of service.
Want to see more scraping tutorials, AI automation tips, or get the latest on business data tools? Subscribe to the Thunderbit Blog or check out our YouTube channel for hands-on demos.
Learn More




