

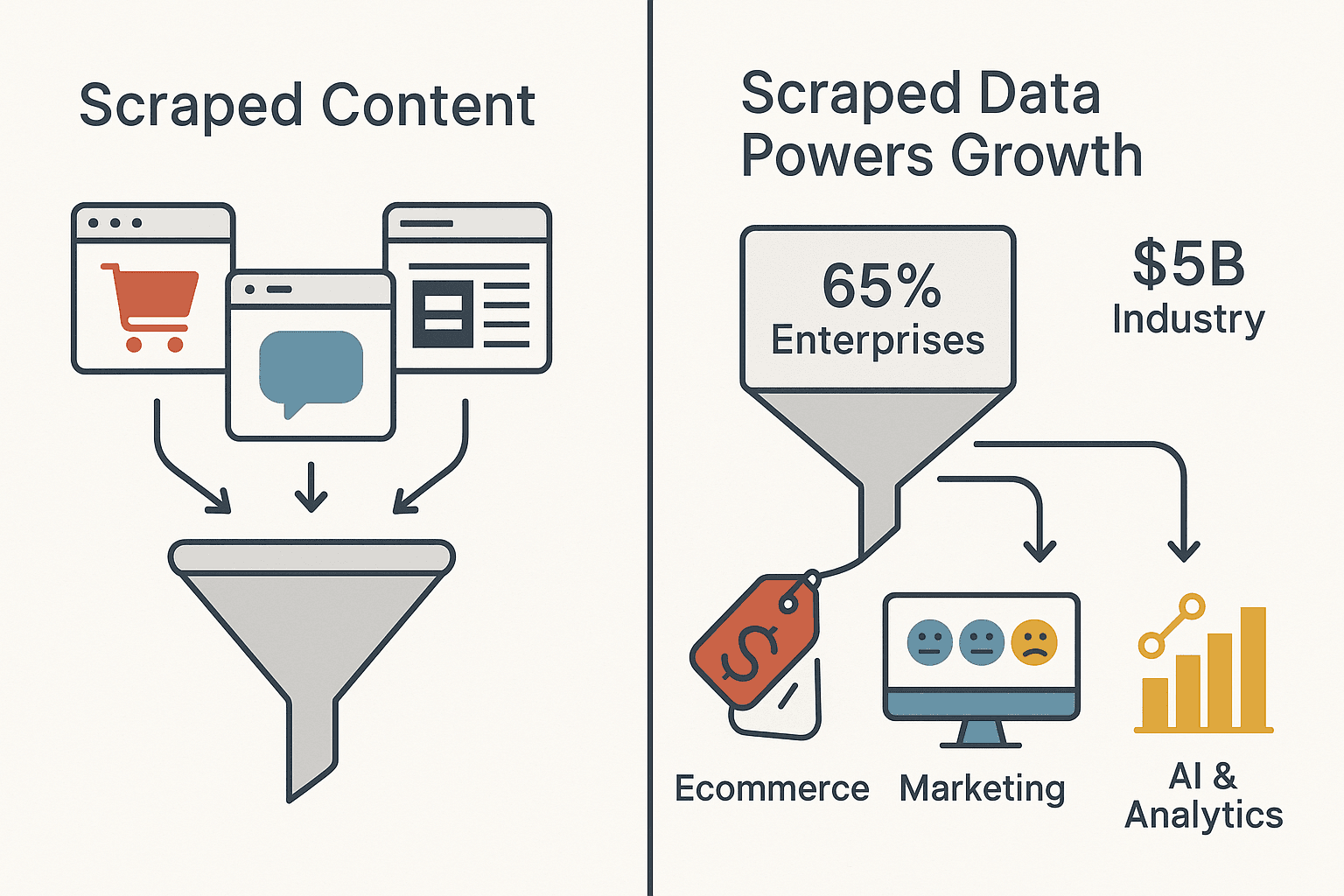
Ever wondered how some businesses always seem to know what their competitors are charging, which products are trending, or what customers are saying—before anyone else? It’s not magic, and it’s not just a room full of interns glued to their screens. The secret is scraped content: data automatically collected from websites and online sources, then transformed into actionable business intelligence. In today’s digital landscape, scraped content is fueling everything from pricing wars in ecommerce to real-time sentiment analysis in marketing. In fact, 65% of enterprises now use web scraping to power AI and analytics, and the global web scraping industry is already worth nearly $5 billion.
Scrape data from any website using AI Get Started Free
As someone who’s spent years building automation and AI tools (and, yes, scraping my fair share of web data), I’ve seen firsthand how scraped content is reshaping business strategy. But with great data comes great responsibility—especially when it comes to legal compliance and data quality. Let’s break down what scraped content really is, why it matters, how to use it responsibly, and why Thunderbit is my top pick for making the most of this powerful resource.
Scraped Content: The Basics Explained
Let’s start with the basics. Scraped content is any data extracted from websites or online platforms using automated tools—think bots, scripts, or AI agents. Instead of painstakingly copying and pasting information, web scraping software can gather everything from product prices and reviews to images and contact details, all at scale and in a structured format.
Authoritative sources like DataDome define data scraping as “the process of extracting specific data in a structured form from publicly available websites or online sources.” In plain English: a scraper visits a webpage, pulls out the info you care about (like names, prices, dates), and drops it into a spreadsheet or database for easy analysis.
Manual vs. Automated Collection
Back in the day, if you wanted data from a website, you’d either copy it by hand or hope the site offered an API. Scraped content flips this on its head by automating the process. Modern scrapers can handle dynamic websites (those with JavaScript, infinite scroll, or “Load more” buttons) and can even mimic human browsing to access content that appears only after user interaction.
What Can Be Scraped?
Almost anything visible on a webpage can be scraped, including:
- Text: Product descriptions, prices, news articles, social media posts.
- Images: Photos from listings, social media, or product galleries.
- Links and Metadata: URLs, tags, or other HTML attributes.
- Structured Records: Tables, directories, stock data, real estate listings.
- User-Generated Content: Reviews, ratings, comments.
Businesses usually target specific data points relevant to their goals—like scraping competitor product prices in ecommerce, or aggregating customer reviews for sentiment analysis in marketing.
The Foundation of Data Science and Research
Once scraped, this content is stored in a structured format (think CSV, Excel, or JSON). It becomes the raw material for analytics, dashboards, and machine learning models. Whether you’re optimizing prices, tracking market trends, or building a lead list, scraped content is often the backbone of data-driven decision-making.
Why Scraped Content Matters in Modern Business
Scraped content isn’t just a buzzword—it’s a practical resource that’s changing how businesses operate. Here’s why it’s become so important:

- Competitive Intelligence: Retailers scrape competitor prices and product info to adjust their own offerings in real time. By 2025, 81% of U.S. retailers are expected to use automated price scraping tools.
- Speed and Scale: Scraping enables businesses to gather huge volumes of data in minutes, supporting agile, up-to-the-minute decisions.
- Data-Driven Decisions: Sales, marketing, product, and operations teams all rely on scraped content for pricing intelligence, trend analysis, lead generation, and more.
Here’s a quick snapshot of how different industries use scraped content:
| Industry/Team | Scraped Content Use Case | Business Benefit |
|---|---|---|
| Ecommerce/Retail | Scraping competitor prices and product listings | Real-time dynamic pricing, product strategy optimization |
| Marketing & Brand | Scraping reviews, ratings, social media comments | Sentiment analysis, brand reputation monitoring |
| Sales & Lead Gen | Scraping directories, LinkedIn, contact info | Building targeted lead lists, more efficient outreach |
| Real Estate | Scraping property listings from multiple sites | Market analysis, inventory aggregation, pricing strategy |
| Finance/Investment | Scraping financial news, stock data, public filings | Alternative data for trading, risk management, real-time market insights |
Scraped content delivers tangible ROI: companies using AI-driven scraping tools report 30–40% time savings on data extraction, freeing up teams to focus on analysis and strategy.
Scraped Content and Legal Compliance: What You Need to Know
With all this opportunity comes a big caveat: scraping isn’t a legal free-for-all. The rules around scraped content are shaped by copyright law, terms of service, and data privacy regulations. Here’s what you need to know:
Is Web Scraping Legal?
Generally, scraping public information isn’t illegal by itself in most places, but how you collect and use the data can raise legal issues. In the U.S., a landmark court case (hiQ Labs vs. LinkedIn) found that scraping publicly available data doesn’t violate anti-hacking laws—but violating a website’s terms of service (ToS) can still lead to lawsuits (meitar.com).
Key legal frameworks:
- Copyright: Facts like prices or stock numbers aren’t protected, but copying and republishing creative content (like articles or images) can trigger copyright claims. Use scraped content for internal analysis or ensure it falls under “fair use.”
- Data Privacy: Laws like Europe’s GDPR and California’s CCPA apply if you’re scraping personal data. Even public profiles can be protected, and non-compliance can lead to hefty fines.
- Terms of Service: Violating a site’s ToS (like scraping when it’s explicitly forbidden) can result in civil lawsuits—even if the data is public.
Regional differences: The EU is much stricter about scraping personal data, often requiring explicit consent or a strong legitimate interest. The U.S. is more permissive with public data but still enforces copyright and contract rights.
Data Privacy and User Consent in Scraped Content
Privacy is a hot topic, especially when scraping personal or sensitive data:
- Public ≠ Free-for-All: Just because info is public doesn’t mean it’s fair game for any use. Regulators expect companies to minimize data collection and be transparent about how they use scraped data.
- Consent Challenges: It’s tough to get consent from every individual whose data you scrape. Many companies rely on “legitimate interest,” but this is under increasing scrutiny in the EU.
- Best Practices: Anonymize data where possible, collect only what you need, and publish a clear privacy notice about your scraping activities. If someone objects, be ready to remove their data.
For more on legal compliance, check out this detailed guide.
Thunderbit: The Smarter Way to Handle Scraped Content
Now, let’s talk about actually getting this data—without losing your mind or your legal standing. Thunderbit is an AI-powered web scraper Chrome Extension built for business users who want results, not headaches.
Why Thunderbit?
- Ridiculously Easy to Use: With Thunderbit, you don’t need to be a coder. Just load a webpage, click “AI Suggest Fields,” and the AI figures out what to extract—like product names, prices, or contact info.
- AI-Driven Data Structuring: Thunderbit ensures your scraped data is clean, structured, and ready for analysis. You can even add custom AI prompts to format, categorize, or translate data as it’s scraped.
- Subpage and Pagination Scraping: Need to grab details from every product page or handle infinite scroll? Thunderbit’s AI detects subpages and paginated content, automating what used to be a tedious manual process.
- Cloud or Local Scraping: Scrape in the cloud for speed (up to 50 pages at once) or use your browser for login-protected sites.
- Free Data Export: Export directly to Excel, Google Sheets, Airtable, or Notion—no extra fees, no hoops to jump through.
- Compliance-First Approach: Thunderbit encourages responsible scraping by letting you control exactly what data you collect, helping you avoid personal or sensitive info unless you really need it.
Thunderbit is trusted by over 50,000 users worldwide, from sales teams to ecommerce operators to real estate pros.
Try Thunderbit AI Web Scraper for Free
How Thunderbit Simplifies the Scraped Content Workflow
Here’s what the Thunderbit workflow looks like:
- AI Suggest Fields: Open a webpage, click the Thunderbit icon, and let the AI suggest which fields to extract (e.g., “Product Name,” “Price,” “Details URL”).
- Customize Fields: Add or rename columns, set data types, or add AI prompts for formatting or categorization.
- Scrape: Click “Scrape” and let Thunderbit do the heavy lifting. For paginated or multi-level sites, Thunderbit navigates automatically.
- Subpage Enrichment: Need more details? Use “Scrape Subpages” to visit each link and pull additional info.
- Export: Review your structured table and export to your favorite tool—Excel, Sheets, Notion, or Airtable.
- Schedule: Set up recurring scrapes (“every Monday at 9am”) so your data stays fresh.
Compared to traditional scraping tools (which often require coding, manual setup, and constant maintenance), Thunderbit’s AI-first approach means minimal setup, less breakage, and more time spent on analysis—not troubleshooting.
Scraped Content in Action: Real-World Business Applications
Let’s get concrete. Here are some ways businesses are using scraped content for a real edge:
- Ecommerce Price Monitoring: Retailers scrape competitor prices daily (or even hourly) to adjust their own pricing in real time. This has become so common that 81% of U.S. retailers now use automated scraping for dynamic pricing.
- Customer Sentiment Analysis: Marketing teams scrape reviews and social media comments to gauge customer satisfaction and spot issues early. One hospitality chain used scraped reviews to identify underperforming properties and retrain staff, boosting guest satisfaction scores.
- Lead Generation: Sales teams build hyper-targeted lead lists by scraping directories, LinkedIn, or event attendee lists. With Thunderbit, you can even enrich leads by scraping subpages for extra context.
- Real Estate Market Research: Agents and investors scrape property listings from multiple sites to analyze pricing trends, inventory, and market shifts—saving hours of manual research and spotting opportunities faster.
- Operations Automation: Teams scrape supplier websites to monitor stock levels or price changes, automating what used to be a manual, error-prone process.
In all these cases, scraped content isn’t just a pile of data—it’s a strategic asset that drives faster, smarter decisions.
The Evolving Landscape: From Quantity to Quality in Scraped Content
The early days of web scraping were all about “more is better”—grab as much data as possible and sort it out later. But as AI and analytics have matured, the focus has shifted to quality over quantity:
- Targeted Scraping: Businesses now prioritize scraping the right sources and the right data points, not just everything they can find.
- AI for Data Enrichment: Tools like Thunderbit use AI to clean, categorize, and even summarize data as it’s scraped, making it more actionable.
- Freshness and Relevance: Real-time or scheduled scraping ensures data is always up to date—critical for things like price monitoring or sentiment analysis.
- Compliance as a Quality Metric: Legally and ethically sourced data is higher quality because it’s safe to use and won’t land you in hot water.
Thunderbit is built for this new era: it helps you focus on the data that matters, ensures it’s structured and compliant, and integrates seamlessly into your workflow.
What Is Data Scraping and How to Do It in 2025 Get Started Free
Scraping is evolving rapidly, and staying ahead means using the right tools and best practices.
Common Challenges and How to Overcome Them
Scraping isn’t always smooth sailing. Here are some common hurdles—and how Thunderbit helps you clear them:
- Data Duplication: Scraping from multiple sources can create duplicate records. Thunderbit structures data with unique keys and makes deduplication easy in Excel or Sheets.
- Quality and Accuracy: Website changes can break scrapers or cause missing data. Thunderbit’s AI adapts to layout changes, and you can quickly re-run “AI Suggest Fields” to fix issues.
- Website Defenses: CAPTCHAs, IP blocks, and dynamic content can trip up basic scrapers. Thunderbit’s browser-based approach handles dynamic sites, and cloud scraping uses multiple IPs for speed and reliability.
- Scale and Performance: Need to scrape thousands of pages? Thunderbit’s cloud mode scrapes up to 50 pages at once, and you can schedule recurring jobs for ongoing needs.
- Compliance Risks: Accidentally scraping personal or sensitive data can be a legal minefield. Thunderbit lets you control exactly what you collect, helping you avoid unnecessary risks.
The key is to use a tool that’s flexible, AI-driven, and designed for business users—not just developers.
Key Takeaways: Making the Most of Scraped Content
Let’s wrap up with the essentials:
- Scraped content is a cornerstone of modern, data-driven business. It powers everything from competitive intelligence to lead generation, and it’s only getting more important.
- Quality beats quantity. Focus on relevant, accurate, and timely data—not just collecting everything you can.
- Legal and ethical compliance is non-negotiable. Understand copyright, privacy, and terms of service before you scrape.
- Thunderbit makes scraping accessible and responsible. With AI-driven field suggestions, subpage scraping, and compliance-first design, Thunderbit is the easiest way for business users to turn web data into business value.
- Integrate scraped content into your decision-making. The real power comes from using this data to drive strategy, not just letting it sit in a spreadsheet.
Ready to see how scraped content can transform your workflow? Download the Thunderbit Chrome Extension and try it for yourself—no coding required. And for more tips, check out the Thunderbit Blog.
Start Scraping with Thunderbit Now
FAQs
1. What exactly is scraped content?
Scraped content is data automatically collected from websites or online sources using tools like web scrapers or AI agents. It can include text, images, prices, reviews, contact info, and more—structured for analysis and business use.
2. Is web scraping legal?
Scraping public data is generally legal, but using scraped content in ways that violate copyright, privacy laws, or a website’s terms of service can lead to legal trouble. Always check local regulations and scrape responsibly.
3. How do businesses use scraped content?
Companies use scraped content for competitive pricing, lead generation, sentiment analysis, market research, and more. It helps teams make faster, data-driven decisions.
4. What makes Thunderbit different from other scraping tools?
Thunderbit uses AI to make scraping easy for non-technical users. Features like “AI Suggest Fields,” subpage and pagination scraping, and direct export to Excel, Sheets, Notion, and Airtable set it apart. It’s also designed with compliance and data quality in mind.
5. How can I ensure my scraping is compliant and ethical?
Stick to public data, avoid collecting personal or sensitive info unless necessary, respect website terms of service, and anonymize data where possible. Tools like Thunderbit help you control exactly what you collect, reducing compliance risks.
Curious to dive deeper? Explore more guides and best practices on the Thunderbit Blog—and let’s turn the web into your next business advantage.
Try Thunderbit AI Web Scraper Today Get Started Free




