
Yelp holds across — and getting that data into a usable format has never been harder. Yelp's 2024–2025 anti-bot crackdown has quietly broken most existing Python scraping tutorials.
If you've tried running a Yelp scraper recently and hit a wall of 403 errors, empty HTML responses, or CAPTCHAs that weren't there six months ago, you're not imagining things. Yelp now runs TLS/JA3 fingerprinting, rotating obfuscated CSS class names, and aggressive IP reputation scoring — meaning the old requests + BeautifulSoup approach that every tutorial still recommends dies on the first request. I've spent weeks testing different approaches against Yelp's current stack, and this guide covers everything that actually works in 2025: the official Fusion API (and why it probably won't be enough), a full Python scraping workflow with a layered anti-blocking strategy, and a 2-click no-code alternative with for readers who just want the data without the debugging marathon.
Why Scrape Yelp with Python (and Who Actually Benefits)
Before writing a single line of code, what's the actual business case for Yelp data? The platform isn't just a restaurant review site — it's effectively a live database of local businesses with structured contact info, ratings, categories, hours, and hundreds of millions of customer reviews.
Here's who benefits most and what they're extracting:
| Use Case | Key Data Fields | Why It Matters |
|---|---|---|
| Sales & lead generation | Business name, phone, website, address, category, rating | Build targeted prospect lists of local SMBs — 4 of 5 Yelp users are purchase-ready on arrival |
| Competitive intelligence | Reviews, star ratings, review volume, sentiment | Monitor competitor reputation, identify service gaps, track trends |
| Market research & NLP | Full review text, dates, reviewer metadata | Sentiment analysis, topic modeling — Yelp reviews are one of the most-used NLP corpora in academic research |
| Real estate & site selection | Business density, category mix, review quality by area | Franchise and retail site selection — Yelp sells Location Intelligence as a licensed B2B product for exactly this |
| Ecommerce & operations | Pricing signals, customer complaints, service hours | Track how competitors are reviewed, identify operational patterns |
The common thread: the real goal is structured data, and Python is just one vehicle to get there. Some readers will want full programmatic control. Others just need a spreadsheet of plumber contact info in Austin. Both paths are covered here.
Yelp Fusion API vs. Python Web Scraping: Which Should You Use?
Most guides skip this decision entirely and jump straight into code without evaluating whether the official (now rebranded as the "Yelp Places API") would have been sufficient. In my experience, that evaluation saves hours of wasted effort — because the API is great for some things and completely inadequate for others.
What the Fusion API Actually Gives You
The Fusion API provides structured business search, business details, autocomplete, and a reviews endpoint. It's authorized, well-documented, and doesn't require anti-bot gymnastics.
But the reviews endpoint is where things fall apart. Here's what Yelp staff have confirmed on GitHub:
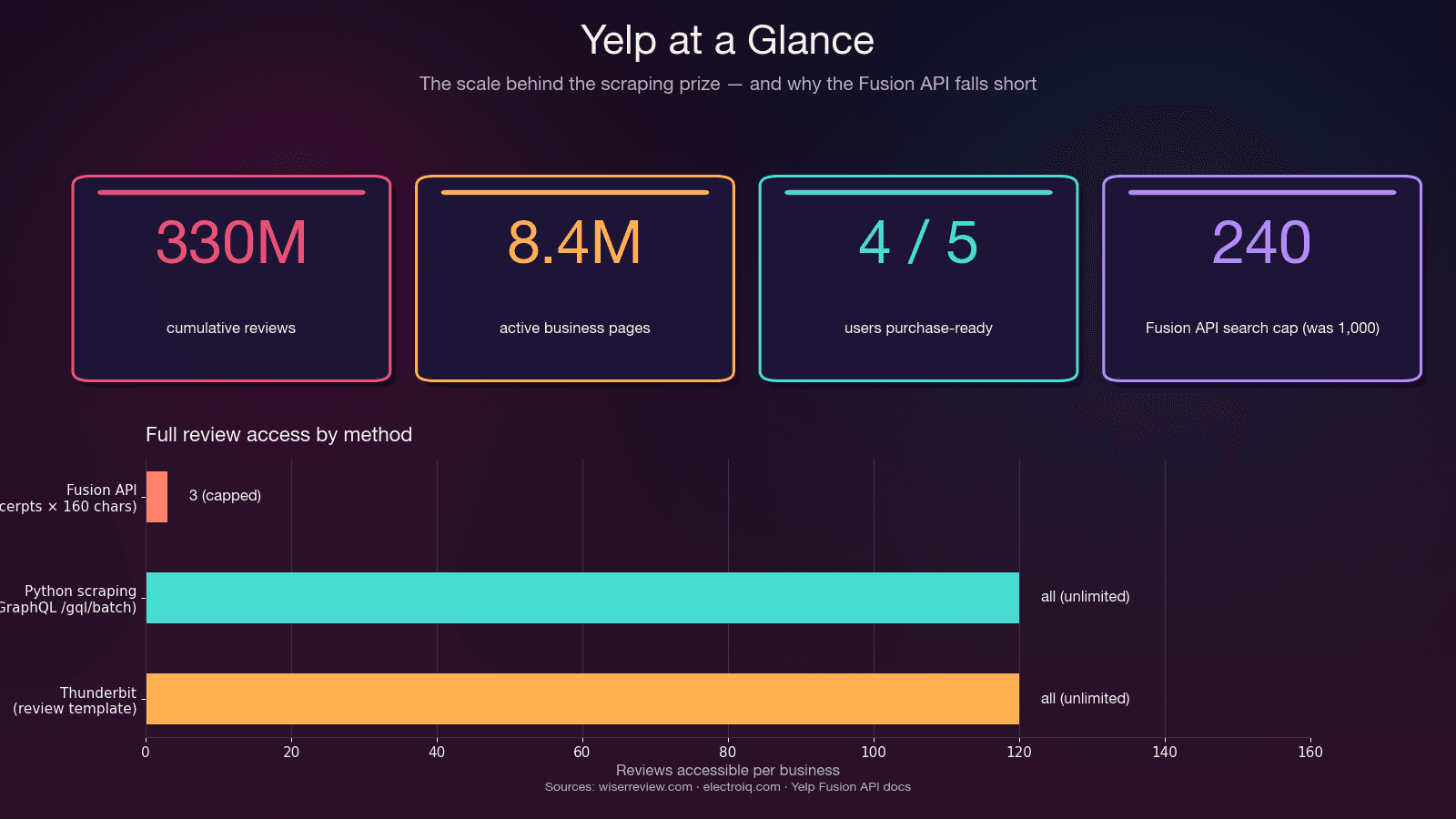
"The Yelp API does not return full review text. Three review excerpts of 160 characters are provided by default." —
That's not a bug — it's by design. The API physically caps at 3 review excerpts (7 on Premium), each truncated to ~160 characters. No review metadata (useful/funny/cool votes), no reviewer history, no owner replies. And the after May 2023 — down from 5,000. Entry pricing starts at .
The Decision Framework
| Factor | Yelp Fusion API | Python Web Scraping | Thunderbit (No-Code) |
|---|---|---|---|
| Full reviews | ❌ Only 3 excerpts (~160 chars each) | ✅ All reviews via GraphQL | ✅ All visible reviews |
| Rate limits | 300–500/day (new); 5,000 (legacy) | Self-managed (proxy budget) | Credit-based |
| Setup effort | ~15 min (API key + SDK) | Hours to days | ~2 minutes |
| Business fields | ~20 structured fields | Unlimited (parse HTML/JSON) | AI-suggested fields |
| Anti-bot handling | N/A (authorized) | Must build yourself | Handled automatically |
| Legal risk | ✅ Authorized | ⚠️ ToS gray area | ⚠️ Same as scraping |
| Cost | $29/mo minimum | Free (+ proxy costs $0.75–$4/GB) | Free tier available |
| Maintenance | Low (API stable) | High (selectors rot, anti-bot escalates) | Low (AI re-adapts) |
Use the Fusion API if: you need basic business info, small-scale lookups, or an authorized integration — and 3 review snippets per business is enough.
Use Python scraping if: you need full review text, all reviews for a business, review metadata, more than 240 results per search, or your budget is below $29/month.
Use Thunderbit if: you want the data fast without writing or maintaining code. More on this in the no-code section below.
The No-Code Shortcut: Scrape Yelp with Thunderbit (No Python Needed)
Before the Python deep-dive, here's the fastest path for readers whose real goal is the data, not the coding exercise. Every competitor guide assumes Python proficiency, but in my work at Thunderbit, I've seen that a huge chunk of people searching "scrape Yelp" are sales reps, ops managers, and small business owners who just want a spreadsheet of local businesses — not a crash course in TLS fingerprinting.
already ships pre-built Yelp templates:
- — extracts business name, rating, contact details, address, hours, category
- — extracts reviewer username, review content, rating, date, reviewer location
How It Works in Practice
- Open a Yelp search results page or business page in Chrome
- Click AI Suggest Fields in the — the AI reads the page and proposes columns (business name, rating, review count, price range, category, address, phone, URL)
- Click Scrape — done
For the pre-built Yelp templates, it's even simpler: open the template, click Scrape.
Subpage scraping handles the enrichment loop automatically — start from a Yelp search results page, enable subpage scraping, and Thunderbit visits each business page to pull hours, full reviews, website, photos, and amenities. No additional setup.
Pagination is automatic — both click-based and scroll-based, handled out of the box. (For more on how this works, see our .)
Exports are free on every tier — Excel, Google Sheets, Airtable, Notion, CSV, JSON. No pandas, no CSV-writing code.
Time Comparison
| Time | Python Scraper | Thunderbit |
|---|---|---|
| First run | Hours to days (write selectors, handle pagination, proxies, retry logic) | ~30 seconds with the pre-built Yelp template |
| When Yelp changes markup | Manually rewrite selectors | Click AI Suggest Fields again — re-adapts automatically |
| When IP gets banned | Debug, rotate proxy pools, re-test | Cloud mode handles IP rotation |
| Export to Google Sheets | Write OAuth + pandas glue | One click, free |
If you try Thunderbit first and find it covers your needs, you can skip the rest of this article. If you need full programmatic control, custom fields, or scale beyond a few thousand records per month — read on.
Python Libraries for Scraping Yelp: Which One to Pick
"Should I use Scrapy, BS4+requests, or Selenium?" is one of the most common questions in r/webscraping threads about Yelp. And yet every tutorial just picks their favorite library and moves on without explaining why. Here's the honest breakdown.
The 2025 Reality: requests + BeautifulSoup Is Broken for Yelp
The stack that every canonical Yelp tutorial recommends — pip install requests beautifulsoup4 — gets you blocked on the first request in 2025. Not the 50th. The first.
The reason: Python's requests library ships a TLS/JA3 fingerprint that doesn't match any real browser. Yelp's anti-bot layer flags it at the TLS-handshake level, before your User-Agent header is even read. I tested this repeatedly — fresh IP, realistic headers, randomized delays — and still hit 403 Forbidden immediately with vanilla requests.
The Library Decision Matrix
| Library | Best For | Handles JS? | Anti-Bot? | Learning Curve | Speed |
|---|---|---|---|---|---|
requests + BeautifulSoup | ❌ | ❌ | Very low | Fast (until blocked) | |
httpx async + parsel | Large-scale async scraping | ❌ | ❌ | Low | Very fast |
curl_cffi + parsel | Yelp-specific: TLS impersonation | ❌ | ✅ TLS/JA3/HTTP2 | Low | Very fast |
Scrapy 2.14 | Full crawl pipelines with pagination | Partial (via scrapy-playwright) | AutoThrottle, retry middleware | Medium-High | Fast |
Selenium 4.43 / Playwright 1.58 | JS-heavy pages, CAPTCHA workarounds | ✅ | Partial | Medium | Slow (~10–30 pages/min) |
| Thunderbit | Non-coders, quick extraction | ✅ (browser) | Built-in (Cloud mode) | Very low | Fast |
The curl_cffi Revelation
The library that changed my Yelp scraping workflow is — a Python binding for curl-impersonate. It emits the exact same TLS/JA3 + HTTP/2 fingerprint as real Chrome, and its API is a drop-in replacement for requests:
1from curl_cffi import requests
2r = requests.get(
3 "https://www.yelp.com/biz/some-restaurant",
4 impersonate="chrome131",
5)
6print(r.status_code, len(r.text))That single change — from curl_cffi import requests plus impersonate="chrome131" — bypasses Yelp's without spinning up a browser. In my testing, it's the difference between instant 403s and clean 200 responses.
My recommended stack for Yelp in 2025: curl_cffi + parsel + jmespath + residential proxies. If you need a full crawl pipeline with scheduling, wrap it in Scrapy 2.14 with a curl_cffi-based downloader middleware.
Setting Up Your Python Environment to Scrape Yelp
- Difficulty: Intermediate
- Time Required: ~15 minutes for setup, 1–2 hours for a working scraper
- What You'll Need: Python 3.10+ (3.12 recommended), a terminal, and optionally a residential proxy provider
Step 1: Create a Virtual Environment and Install Packages
1python3.12 -m venv .venv
2source .venv/bin/activate # On Windows: .venv\Scripts\activate
3pip install "curl_cffi>=0.11" "parsel>=1.9" "jmespath>=1.0" pandasWhat each package does:
curl_cffi— makes HTTP requests with Chrome's TLS fingerprint (the anti-bot bypass)parsel— CSS/XPath selectors for parsing HTML (same engine Scrapy uses, lighter weight)jmespath— declarative JSON querying (cleaner than nested dict access for Yelp's embedded JSON)pandas— data export to CSV/Excel
Optional but useful:
1pip install fake-useragent # Note: repo archived April 2026 but still installableStep-by-Step: How to Scrape Yelp with Python
This is the core tutorial. The key insight that makes everything more resilient: skip CSS selectors, pull hidden JSON instead. Yelp randomizes CSS class names at build time (y-css-14xwok2 one week, y-css-hcq7b9 the next), so any scraper pinned to them breaks within weeks. The embedded JSON payloads — application/ld+json schema and react-root-props — are stable.
Step 2: Scrape Yelp Search Results
Yelp search URLs follow a predictable pattern: https://www.yelp.com/search?find_desc={term}&find_loc={location}. The search results data is embedded in a <script data-id="react-root-props"> tag as JSON — not rendered in the CSS-class soup.
1import re, json, jmespath
2from curl_cffi import requests
3from parsel import Selector
4HEADERS = {
5 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
6 "AppleWebKit/537.36 (KHTML, like Gecko) "
7 "Chrome/124.0.0.0 Safari/537.36",
8 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
9 "image/avif,image/webp,image/apng,*/*;q=0.8",
10 "accept-language": "en-US,en;q=0.9",
11 "accept-encoding": "gzip, deflate, br",
12 "cookie": "intl_splash=false",
13}
14def scrape_search(term: str, location: str, max_pages: int = 3):
15 results = []
16 for page in range(max_pages):
17 url = (f"https://www.yelp.com/search?"
18 f"find_desc={term}&find_loc={location}&start={page * 10}")
19 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
20 if r.status_code != 200:
21 print(f"Blocked on page {page}: {r.status_code}")
22 break
23 sel = Selector(text=r.text)
24 script = sel.xpath(
25 "//script[@data-id='react-root-props']/text()"
26 ).get() or ""
27 m = re.search(r"react_root_props\s*=\s*(\{.*?\});", script, re.S)
28 if not m:
29 print(f"No react-root-props found on page {page} — possible soft block")
30 break
31 data = json.loads(m.group(1))
32 businesses = jmespath.search(
33 "legacyProps.searchAppProps.searchPageProps"
34 ".mainContentComponentsListProps"
35 "[?searchResultBusiness].searchResultBusiness.{"
36 "name: name, url: businessUrl, rating: rating, "
37 "reviews: reviewCount, phone: phone, "
38 "neighborhoods: neighborhoods}",
39 data,
40 ) or []
41 results.extend(businesses)
42 import time, random
43 time.sleep(random.uniform(3, 7))
44 return resultsYou should get back a list of dicts with business names, URLs, ratings, and review counts. If react-root-props is missing from the response, you've been served a block shell — rotate your IP and retry.
The Cookie: intl_splash=false header is a standard workaround for Yelp's country-splash redirect. Without it, non-US IPs hit a splash page that looks like a soft block but isn't.
Step 3: Scrape Yelp Business Pages
Each business URL from the search results leads to a detail page with richer data. The most stable extraction target is the <script type="application/ld+json"> block — it contains structured schema.org data that Yelp maintains for SEO and doesn't obfuscate.
1def scrape_business(biz_url: str) -> dict:
2 url = f"https://www.yelp.com{biz_url}" if biz_url.startswith("/") else biz_url
3 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
4 if r.status_code != 200:
5 return {"url": url, "error": r.status_code}
6 sel = Selector(text=r.text)
7 biz_id = sel.css('meta[name="yelp-biz-id"]::attr(content)').get()
8 for raw in sel.css('script[type="application/ld+json"]::text').getall():
9 try:
10 data = json.loads(raw)
11 except json.JSONDecodeError:
12 continue
13 for node in (data if isinstance(data, list) else [data]):
14 if node.get("@type") in (
15 "Restaurant", "LocalBusiness", "FoodEstablishment",
16 "HealthAndBeautyBusiness", "HomeAndConstructionBusiness",
17 ):
18 return {
19 "biz_id": biz_id,
20 "name": node.get("name"),
21 "rating": (node.get("aggregateRating") or {}).get("ratingValue"),
22 "review_count": (node.get("aggregateRating") or {}).get("reviewCount"),
23 "address": node.get("address"),
24 "telephone": node.get("telephone"),
25 "price_range": node.get("priceRange"),
26 "hours": node.get("openingHours"),
27 "url": url,
28 }
29 return {"biz_id": biz_id, "url": url}The meta[name="yelp-biz-id"] value is the encoded business ID you'll need for the reviews endpoint. Grab it here — you'll use it in the next step.
Step 4: Scrape Yelp Reviews with Pagination
This is where the Fusion API falls short and scraping shines. Yelp's internal GraphQL batch endpoint returns full review text, reviewer info, dates, ratings, and vote counts — everything the API withholds.
The endpoint is https://www.yelp.com/gql/batch, and it uses a static documentId for the GetBusinessReviewFeed operation. Pagination works via a base64-encoded cursor.
1import base64
2GQL_URL = "https://www.yelp.com/gql/batch"
3DOC_ID = "ef51f33d1b0eccc958dddbf6cde15739c48b34637a00ebe316441031d4bf7681"
4def fetch_reviews(enc_biz_id: str, num_pages: int = 5):
5 all_reviews = []
6 for page in range(num_pages):
7 offset = page * 10
8 cursor = base64.b64encode(
9 json.dumps({"version": 1, "offset": offset}).encode()
10 ).decode()
11 payload = [{
12 "operationName": "GetBusinessReviewFeed",
13 "variables": {
14 "encBizId": enc_biz_id,
15 "reviewsPerPage": 10,
16 "after": cursor,
17 "sortBy": "DATE_DESC",
18 "language": "en",
19 },
20 "extensions": {
21 "operationType": "query",
22 "documentId": DOC_ID,
23 },
24 }]
25 r = requests.post(
26 GQL_URL,
27 json=payload,
28 headers={
29 **HEADERS,
30 "content-type": "application/json",
31 "x-apollo-operation-name": "GetBusinessReviewFeed",
32 "apollographql-client-name": "yelp-main-frontend",
33 },
34 impersonate="chrome131",
35 )
36 if r.status_code != 200:
37 print(f"Review fetch failed at offset {offset}: {r.status_code}")
38 break
39 data = r.json()
40 # Navigate the response structure to extract reviews
41 try:
42 reviews = data[0]["data"]["business"]["reviews"]["edges"]
43 for edge in reviews:
44 node = edge.get("node", {})
45 all_reviews.append({
46 "reviewer": node.get("author", {}).get("displayName"),
47 "rating": node.get("rating"),
48 "date": node.get("localizedDate"),
49 "text": node.get("text", {}).get("full"),
50 })
51 except (KeyError, IndexError, TypeError):
52 break
53 import time, random
54 time.sleep(random.uniform(3, 7))
55 return all_reviewsEach page returns 10 reviews. Increment the offset in the base64 cursor to paginate. The sortBy parameter accepts DATE_DESC (newest first), RATING_ASC, RATING_DESC, and others.
Step 5: Export Your Scraped Yelp Data
1import pandas as pd
2# Assuming you've collected businesses and reviews
3df_businesses = pd.DataFrame(businesses)
4df_businesses.to_csv("yelp_businesses.csv", index=False)
5df_reviews = pd.DataFrame(all_reviews)
6df_reviews.to_csv("yelp_reviews.csv", index=False)
7# Or save as JSON for flexibility
8import json
9with open("yelp_data.json", "w") as f:
10 json.dump({"businesses": businesses, "reviews": all_reviews}, f, indent=2)For readers on the no-code path, Thunderbit exports the same data straight to Excel, Google Sheets, Airtable, or Notion — no pandas or file-writing code needed.
The Anti-Blocking Playbook: How to Scrape Yelp Without Getting Blocked
This section is the whole reason the article exists. Yelp's anti-bot measures have gotten significantly tougher since late 2024 — are all in play. Most existing guides are outdated because they were written before this crackdown.
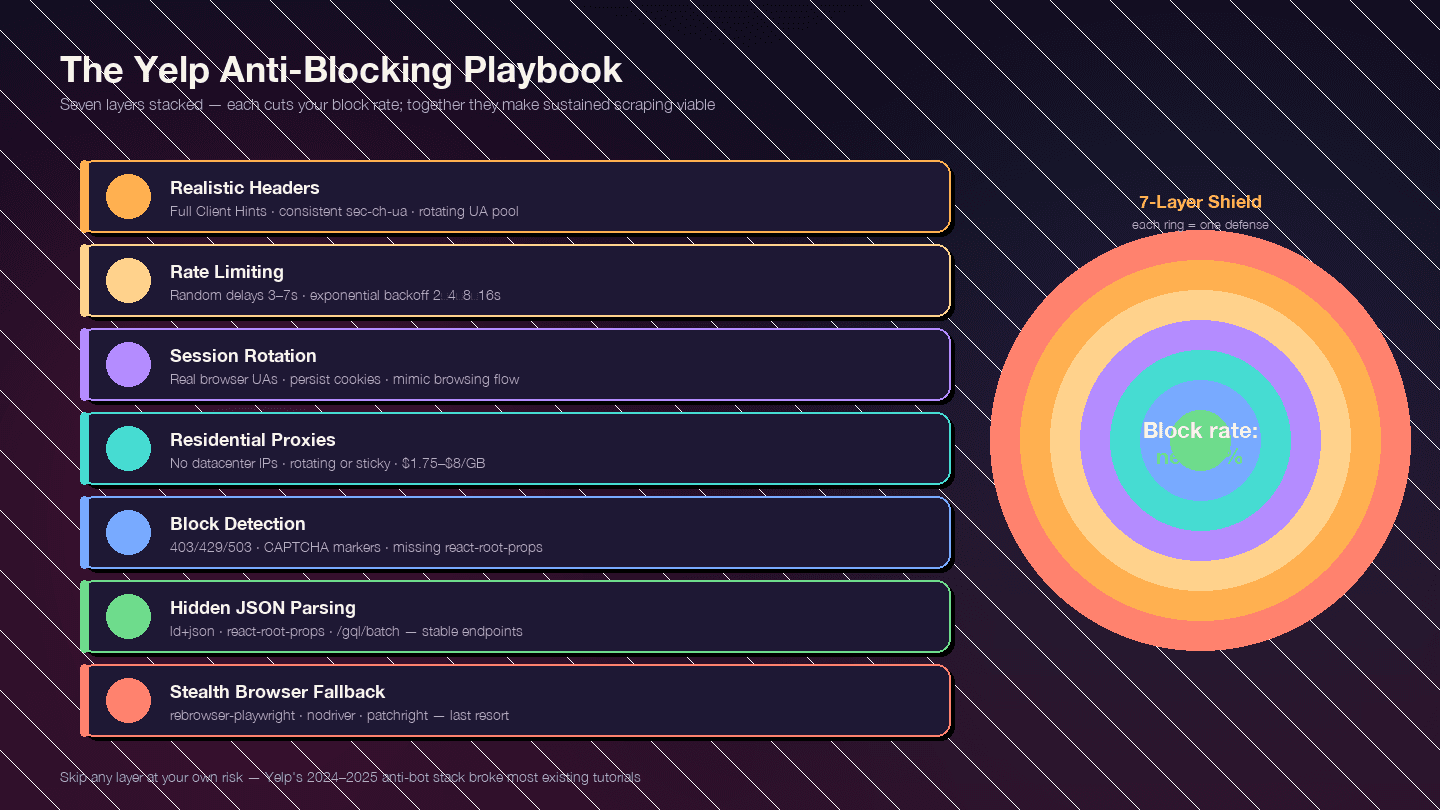
The strategy is layered. Each layer reduces your block rate; together, they make sustained scraping viable.
Layer 1: Realistic Request Headers
Default Python requests headers send User-Agent: python-requests/2.x — blocked instantly. But even a realistic User-Agent isn't enough. Yelp checks the full header set for consistency.
1FULL_HEADERS = {
2 "authority": "www.yelp.com",
3 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36",
6 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
7 "image/avif,image/webp,image/apng,*/*;q=0.8",
8 "accept-language": "en-US,en;q=0.9",
9 "accept-encoding": "gzip, deflate, br",
10 "sec-ch-ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
11 "sec-ch-ua-mobile": "?0",
12 "sec-ch-ua-platform": '"Windows"',
13 "sec-fetch-dest": "document",
14 "sec-fetch-mode": "navigate",
15 "sec-fetch-site": "same-origin",
16 "sec-fetch-user": "?1",
17 "upgrade-insecure-requests": "1",
18 "referer": "https://www.yelp.com/",
19 "cookie": "intl_splash=false",
20}Three mistakes that get you flagged:
- UA claims Chrome but
sec-ch-uais missing or contradicts the UA version sec-ch-ua-platformsays "Windows" but the UA string says macOS- Same exact UA across thousands of requests from one IP — rotate a pool of 10–20 recent Chrome/Firefox/Safari strings
Layer 2: Rate Limiting and Random Delays
Predictable timing patterns are a red flag. Add randomized sleep intervals and implement exponential backoff on error responses.
1import random, time
2def polite_get(client_get, url, attempt=0):
3 r = client_get(url, headers=FULL_HEADERS, impersonate="chrome131")
4 if r.status_code in (403, 429, 503):
5 if attempt >= 4:
6 raise RuntimeError(f"Blocked after {attempt + 1} attempts on {url}")
7 backoff = 2 ** (attempt + 1) + random.random()
8 print(f" Got {r.status_code}, backing off {backoff:.1f}s (attempt {attempt + 1})")
9 time.sleep(backoff)
10 return polite_get(client_get, url, attempt + 1)
11 time.sleep(random.uniform(3, 7))
12 return r| Parameter | Recommended Value |
|---|---|
| Random sleep between requests | random.uniform(3, 7) seconds |
| Backoff on 429/403/503 | 2 → 4 → 8 → 16s, max 5 attempts |
| Concurrent workers per IP | 1 (serialize per IP; use proxies for parallelism) |
| Max sustained rate per residential IP | ~1 req / 5s (~12 rpm) |
Layer 3: User-Agent and Session Rotation
Rotate through a pool of real browser User-Agent strings. Persist sessions and cookies to mimic real browsing behavior — Yelp uses cookie-based detection, so creating a fresh session for every request is itself suspicious.
1UA_POOL = [
2 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
3 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0",
5 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14.4; rv:125.0) Gecko/20100101 Firefox/125.0",
6 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/605.1.15 Safari/17.4.1",
7 # Add 5-10 more recent strings
8]Layer 4: Proxy Rotation
At any real volume, you need residential proxies. Datacenter and free proxies do not work on Yelp — Yelp's IP-reputation layer preemptively 403s AWS, GCP, and DigitalOcean IP ranges.
| Provider | Entry $/GB | Notes |
|---|---|---|
| IPRoyal | $1.75/GB | Cheapest; runs the most-cited Yelp tutorial |
| Decodo (ex-Smartproxy) | $3.20–$3.50 | Best GB/$ ratio at volume |
| Bright Data | $4.00 (PAYG) | 150M+ IP pool; dedicated Yelp Proxies page |
| Oxylabs | $6.00–$8.00 | Premium; 10M+ IPs |
| Aluvia (mobile SIM) | $3.00 | Real US carrier mobile IPs, positioned for Yelp |
Rotating residential (new IP per request) works best for high-volume search crawls. Sticky sessions (hold one IP for 10 minutes) are better when persisting cookies across a business-page → reviews → pagination flow.
Layer 5: Detecting and Handling Blocks
Not every block looks the same. Yelp often serves a generic "page not available" shell rather than a CAPTCHA, which is why naive scrapers think they're getting data when they're actually getting empty responses.
1BLOCK_MARKERS = (
2 "captcha", "px-captcha", "page not available",
3 "access denied", "unusual traffic",
4)
5def is_blocked(resp):
6 if resp.status_code in (401, 403, 429, 503):
7 return True
8 body = resp.text.lower()
9 if any(m in body for m in BLOCK_MARKERS):
10 return True
11 # If this is a search/business page but react-root-props is missing,
12 # Yelp served a stripped block response
13 if "react-root-props" not in body and "/biz/" in str(resp.url):
14 return True
15 return False| Signal | Meaning |
|---|---|
| HTTP 403 | Hard block — IP/header/TLS burned |
| HTTP 429 | Rate limited — often recoverable with backoff |
| HTTP 503 | Generic block or load shedding |
Redirect to /error or "page not available" body | Soft block |
| Empty with only | Challenge page waiting for JS |
captcha / g-recaptcha / px-captcha in body | Escalated — CAPTCHA required |
Missing react-root-props on a listing page | Stripped block response |
Layer 6: The Resilient Parsing Trick — Hidden JSON over CSS Selectors
Worth repeating: Yelp randomizes CSS class names at build time. A scraper pinned to h3.y-css-14xwok2 will break within weeks when Yelp redeploys with h3.y-css-hcq7b9.
The payloads that don't move:
<script type="application/ld+json">— schema.org structured data (name, address, phone, rating, hours)<script data-id="react-root-props">— full search results data as JSONhttps://www.yelp.com/gql/batch— GraphQL reviews endpoint with a stabledocumentId
If you're parsing CSS classes, you're building on sand. Parse the JSON instead.
Layer 7: The Stealth Browser Fallback
Escalate to a headless browser only when curl_cffi + residential proxies can't get through — typically when Yelp serves a JavaScript challenge page or CAPTCHA.
For 95% of business/search/review scraping, curl_cffi + hidden JSON + residential proxies is faster, cheaper, and more reliable than a browser. But when you do need a browser:
| Tool | Status (2025) | Notes |
|---|---|---|
| rebrowser-playwright | Recommended starting point | Drop-in Playwright patched to fix CDP leaks |
| nodriver | Best-in-class for Chrome stealth | Successor to undetected-chromedriver; avoids WebDriver protocol entirely |
| patchright | Actively maintained Playwright fork | Passes modern detection tests |
| playwright-stealth | Mature | Patches navigator.webdriver, strips HeadlessChrome from UA |
Skip vanilla Selenium for Yelp. It's too easily fingerprinted.
Yelp Fusion API vs. Python Scraping vs. Thunderbit: Full Comparison
| Dimension | Yelp Fusion API | Python Scraping | Thunderbit |
|---|---|---|---|
| Full review text | ❌ 3 excerpts × ~160 chars | ✅ Unlimited (GraphQL) | ✅ Built-in review template |
| Review metadata (votes, owner replies) | ❌ | ✅ | ✅ Via AI-suggested fields |
| Photos | ❌ (0 on Base) | ✅ Unlimited | ✅ |
| Max results per search | 240 (was 1,000 pre-2024) | Unlimited (paginated) | Unlimited |
| Daily rate limit | 300–500 (new) / 5,000 (legacy) | Proxy budget only | Credit-based (3,000/mo on Pro) |
| Setup effort | ~15 min | Hours to days | ~2 minutes |
| Anti-bot handling | N/A | Your problem | Handled (Cloud mode) |
| Legal risk | Low (authorized) | Medium (ToS gray area) | Medium (same as scraping) |
| Cost (entry) | $29/mo | ~$0.75–$4/GB proxies + dev time | Free tier |
| Cost (heavy use) | $643+/mo | $50–$500/mo proxies + dev time | $38–$49/mo |
| Data export | JSON | CSV/JSON (you write it) | Excel / Sheets / Airtable / Notion — free |
| Maintenance | Low | High (selectors rot, anti-bot escalates) | Low (AI re-adapts) |
Legal and Ethical Tips for Scraping Yelp
I'm not a lawyer, and this isn't legal advice. But the legal landscape has shifted enough in the last two years that you should know the basics before investing time in a Yelp scraping project.
What Yelp's Terms of Service say: The explicitly prohibits using "any robot, spider... or other automated device" to "access, retrieve, copy, scrape, or index any portion of the Service." It also added language about "AI Technologies and/or other automated tools."
: "Yelp does not allow any scraping of the site."
What robots.txt says: Yelp's has a wildcard User-agent: * / Disallow: / and specifically blocks GPTBot, ClaudeBot, PerplexityBot, CCBot, and Meta-ExternalAgent. Only Googlebot, Bingbot, and a few social-media crawlers are whitelisted.
The legal precedent that matters: In (N.D. Cal. Jan 2024), the court ruled that scraping publicly available, logged-out data did not violate Meta's Terms of Service. The key distinction: logged-out public data vs. logged-in data. The case established that scraping public data likely doesn't violate the CFAA, but hiQ still lost on state tort claims (trespass to chattels, misappropriation) and was hit with a $500,000 judgment.
Practical guidelines:
- Scrape only publicly available, logged-out pages
- Rate-limit your requests (the delays in this guide serve double duty as ethical rate limits)
- Don't resell raw review text attributed to named users — respect reviewer privacy
- Comply with local data protection laws (CCPA, GDPR)
- Don't log in to scrape — that crosses the authorization line
- Treat business info (name/address/phone/rating) as public factual data; treat review text as more sensitive
Consult a legal professional for your specific situation.
Wrapping Up
Three paths, one goal.
The Yelp Fusion API is the authorized, low-maintenance option — but it caps at 3 review excerpts and starts at $29/month. Python scraping gives you full control over every data point on Yelp, but it requires real investment: curl_cffi for TLS impersonation, residential proxies, randomized delays, hidden JSON parsing, and ongoing maintenance as Yelp's defenses evolve. Thunderbit gets you from "I need Yelp data" to "here's my spreadsheet" in about 30 seconds, with no code and no proxy configuration.
The anti-blocking essentials that actually work in 2025: realistic headers with full Client Hints, curl_cffi for TLS fingerprint impersonation, randomized delays with exponential backoff, residential proxy rotation, and — above all — parsing hidden JSON (application/ld+json and react-root-props) instead of fragile CSS selectors.
Not sure which path fits? Try first. If it covers your needs, you've saved yourself hours. If you need more control — full programmatic pipelines, custom fields, tight CRM integration — the Python guide above has you covered. And for a deeper look at the scraping tools landscape, check out our roundup of the or our guide to .
FAQs
Can I scrape Yelp for free with Python?
Yes — using free libraries like curl_cffi, parsel, and jmespath. But at any real volume (more than a few dozen pages), you'll need paid residential proxies, which start around . Thunderbit also offers a free tier with 6 pages/month for quick, no-code extraction.
Does Yelp block scrapers?
Yes, aggressively. Yelp uses . Vanilla requests gets blocked on the first hit. The layered anti-blocking strategy in this guide — curl_cffi for TLS impersonation, realistic headers, random delays, and residential proxies — is what works in 2025.
Is the Yelp Fusion API better than scraping?
Depends on your needs. The API is authorized and low-risk, but it only returns , caps search results at 240, and starts at $29/month. If you need full review text, review metadata, or more than a few hundred records per day, scraping is the only option.
How do I scrape Yelp reviews with Python?
Use curl_cffi with impersonate="chrome131" to fetch the business page, pull the encoded business ID from <meta name="yelp-biz-id">, then POST to https://www.yelp.com/gql/batch with the GetBusinessReviewFeed operation and paginate via a base64-encoded after cursor. The step-by-step code is in the tutorial section above. The is also a solid reference implementation.
Can I scrape Yelp without coding?
Yes — ships pre-built and templates. Open a Yelp page, click AI Suggest Fields, click Scrape. Exports to Google Sheets, Excel, Airtable, and Notion are free on every tier, including the free plan.
Learn More