
Somewhere around my fiftieth copy-paste of a job title from Indeed into a spreadsheet, I started questioning my career choices. If you've ever tried to pull structured data from Indeed programmatically, you already know the punchline: the 403 error is not a bug — it's a feature of Indeed's defense system.
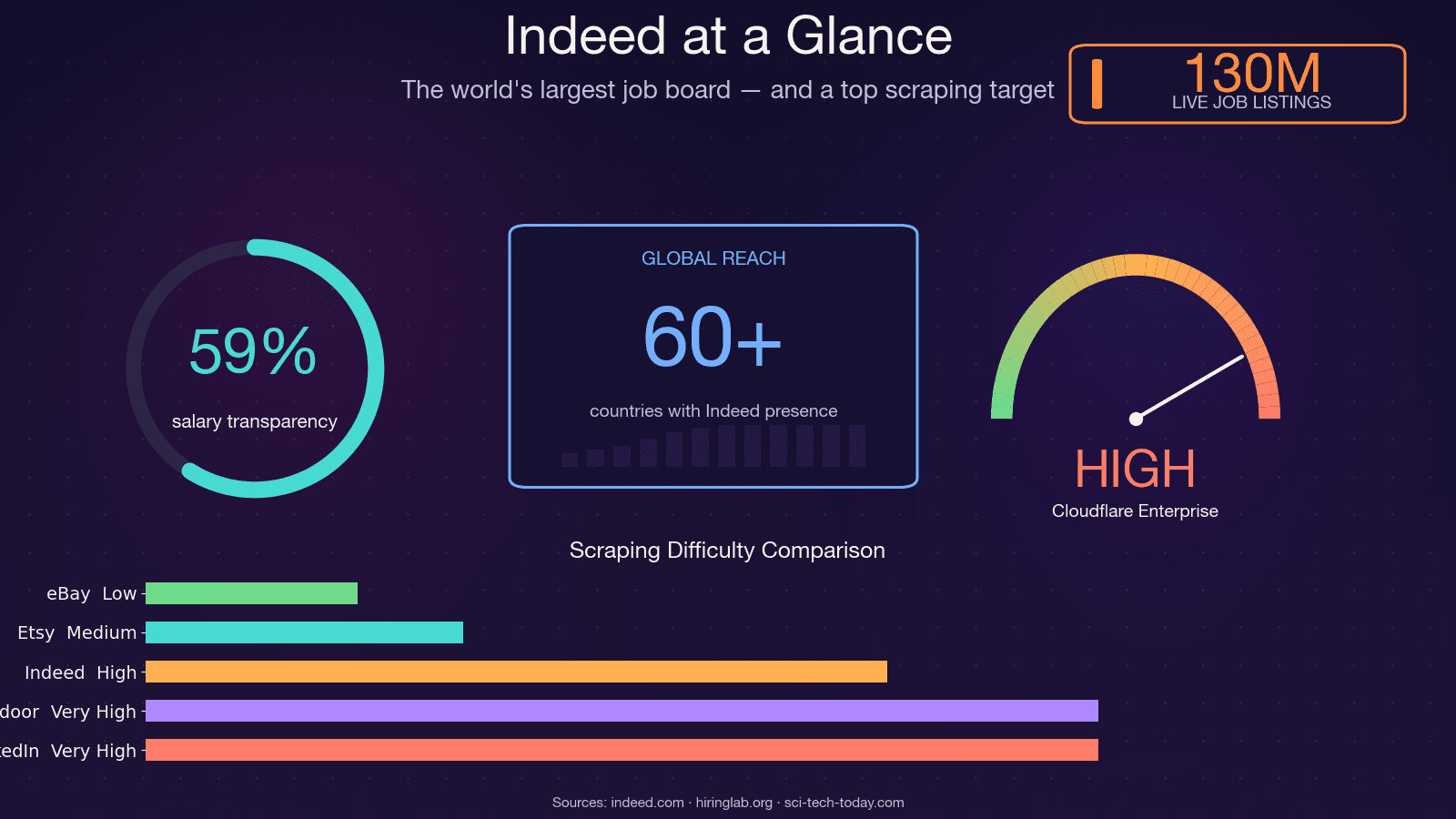
Indeed is the world's largest job board, with roughly , at any given time, and operations across . That makes it one of the richest sources of job market data on the planet — and one of the hardest to scrape. The open-source scraper JobFunnel (thousands of GitHub stars) was literally in December 2025 after years of losing the anti-bot arms race. The maintainer's own words: "All users can scrape some jobs, but are quickly hit by captcha, and the scraping fails, yielding no jobs." Another contributor reported getting a CAPTCHA . So yeah — this is not a trivial scraping target. In this guide, I'll walk through every practical method for scraping Indeed with Python, show you how to actually survive the 403 gauntlet, and — for those who'd rather skip the debugging entirely — demonstrate a no-code alternative using .
What Does It Mean to Scrape Indeed with Python?
Web scraping, at its core, is the automated extraction of structured data from web pages. When we talk about scraping Indeed with Python, we mean writing a script that visits Indeed's search results and job detail pages, reads the underlying HTML (or embedded data), and pulls out fields like job title, company, location, salary, and description into a usable format — a CSV, a database, a Google Sheet.
The typical Python libraries involved are Requests (for HTTP calls), BeautifulSoup (for HTML parsing), and Selenium or Playwright (for browser automation). But Indeed is not a simple static site. It's a hybrid: server-rendered HTML with an embedded JSON state blob, fronted by Cloudflare Bot Management. That means your scraper needs to handle JavaScript-rendered content, rotating CSS class names, and aggressive anti-bot protections — all before you parse a single job title.
There's also no official, free, read-only Indeed API in 2026. The old Publisher Jobs API was deprecated around 2020, and what remains is employer-side only (Job Sync, Sponsored Jobs). So scraping or paying a third-party data provider are the only realistic options.
Why Scrape Indeed Job Data?
The business case for scraping Indeed is straightforward: manual browsing of thousands of listings is impractical, and the data inside those listings is genuinely valuable.
| Use Case | Who Benefits | Example |
|---|---|---|
| Lead generation | Sales & recruiting teams | Build lists of hiring companies with contact info |
| Job market research | Analysts, HR teams | Identify trending skills, salary benchmarks by region |
| Competitive intelligence | Employers, staffing agencies | Monitor competitor hiring patterns and salary offers |
| Personal job search automation | Job seekers | Aggregate listings matching your criteria across locations |
| Training data for ML models | Data scientists | Build salary prediction models from historical job data |
Indeed Hiring Lab's own research that posting data closely tracks BLS JOLTS and can serve as a near-real-time proxy for US labor market conditions. Hedge funds use job-posting velocity as an alternative data signal. HR teams benchmark compensation using scraped salary ranges. And recruiters build prospect lists from companies that are actively hiring.
One practical note: salary data on Indeed is improving but still incomplete. As of mid-2025, roughly include salary info, but only about give an exact figure — the rest are ranges. Any salary analysis built on Indeed data should account for that sparsity.
Choosing Your Method to Scrape Indeed with Python
There's no single "right" way to scrape Indeed. The best approach depends on your skill level, how much data you need, and how much maintenance you're willing to tolerate. I've tested all four of the major approaches, and here's how they compare:
| Criteria | BS4 + Requests | Selenium | Hidden JSON (window.mosaic) | No-Code (Thunderbit) |
|---|---|---|---|---|
| Difficulty | Beginner | Intermediate | Intermediate-Advanced | None (2 clicks) |
| Speed | Fast | Slow (browser render) | Fast | Fast (cloud scraping) |
| JS-rendered content | No | Yes | Yes (embedded data) | Yes |
| Anti-bot resilience | Low | Medium (detectable) | Medium-High | High (handled automatically) |
| Maintenance when HTML changes | High (selectors break) | High | Medium (JSON structure more stable) | None (AI adapts) |
| Best for | Quick prototypes | Dynamic pages, login-gated | Bulk structured data | Non-developers, fast results |
This guide walks through each method. If you're a Python developer, you'll want to read the BS4, Hidden JSON, and Selenium sections. If you're a non-coder (or just tired of debugging 403s), skip ahead to the Thunderbit section.
Before You Start
- Difficulty: Beginner to Intermediate (Python sections); None (Thunderbit section)
- Time Required: ~20–60 minutes for Python setup and first scrape; ~2 minutes with Thunderbit
- What You'll Need: Python 3.9+, a code editor, Chrome browser, and (for the no-code path) the
Setting Up Your Python Environment for Indeed Scraping
Before writing any scraping code, get your environment ready.
Install the Required Libraries
Create a virtual environment and install the packages you'll need:
1python -m venv indeed_env
2source indeed_env/bin/activate # On Windows: indeed_env\Scripts\activate
3# For the HTTP + parsing approach
4pip install requests beautifulsoup4 lxml httpx
5# For the hidden JSON approach (recommended)
6pip install curl_cffi parsel tenacity
7# For the browser automation approach
8pip install seleniumA few notes:
curl_cffiis the 2026 default for scraping Cloudflare-protected sites. It impersonates real browser TLS fingerprints, which plainrequestsandhttpxcannot do. More on why this matters in the anti-bot section.- Selenium 4.6+ ships with Selenium Manager, so you no longer need to manually download ChromeDriver — it auto-manages the browser binary.
- Use
lxmlas your BeautifulSoup parser backend. It's roughly than the stdlibhtml.parser.
Create Your Project Structure
Keep it simple:
1indeed_scraper/
2├── scraper.py
3├── requirements.txt
4└── output/All code samples below build on scraper.py.
How to Scrape Indeed with Python Using BeautifulSoup
This is the beginner-friendly approach: use requests to fetch the page and BeautifulSoup to parse the HTML. It's the fastest to set up, but also the most fragile on Indeed.
Step 1: Build the Indeed Search URL
Indeed's search URLs follow a predictable pattern:
1https://www.indeed.com/jobs?q=<query>&l=<location>&start=<offset>For example, searching for "data analyst" in "Austin, TX" starting from the first page:
1from urllib.parse import urlencode
2params = {
3 "q": "data analyst",
4 "l": "Austin, TX",
5 "start": 0,
6}
7url = f"https://www.indeed.com/jobs?{urlencode(params)}"
8print(url)
9# https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX&start=0Indeed paginates in increments of 10, with a hard ceiling of 1,000 results (start <= 990). Any offset above 990 silently returns the same page.
Step 2: Send an HTTP Request with Proper Headers
Indeed blocks requests with default Python user-agent strings immediately. You need realistic headers:
1import requests
2headers = {
3 "User-Agent": (
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
5 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36"
6 ),
7 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept-Encoding": "gzip, deflate, br",
10 "Referer": "https://www.indeed.com/",
11}
12response = requests.get(url, headers=headers, timeout=30)
13print(response.status_code)If you get a 200, you're in — for now. If you get a 403, Cloudflare caught you. (More on surviving that below.)
Step 3: Parse Job Listings from the HTML
Use BeautifulSoup to select job card elements. Target data-testid attributes — they're more stable than Indeed's randomized CSS class names:
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(response.text, "lxml")
3cards = soup.find_all("div", attrs={"data-testid": "slider_item"})
4jobs = []
5for card in cards:
6 title_el = card.find("h2", class_="jobTitle")
7 title = title_el.get_text(strip=True) if title_el else None
8 company = card.find(attrs={"data-testid": "company-name"})
9 location = card.find(attrs={"data-testid": "text-location"})
10 link = title_el.find("a")["href"] if title_el and title_el.find("a") else None
11 jobs.append({
12 "title": title,
13 "company": company.get_text(strip=True) if company else None,
14 "location": location.get_text(strip=True) if location else None,
15 "url": f"https://www.indeed.com\{link\}" if link else None,
16 })
17print(f"Found {len(jobs)} jobs")Step 4: Handle Pagination
Loop through pages by incrementing the start parameter:
1import time, random
2all_jobs = []
3for page in range(0, 50, 10): # First 5 pages
4 params["start"] = page
5 url = f"https://www.indeed.com/jobs?{urlencode(params)}"
6 response = requests.get(url, headers=headers, timeout=30)
7 # ... parse as above ...
8 all_jobs.extend(jobs)
9 time.sleep(random.uniform(3, 6))Limitations of This Approach
I'll be upfront: BS4 + Requests is the weakest method for Indeed in 2026. Plain requests uses Python's stdlib TLS library, which produces a that Cloudflare instantly identifies as "not a browser." It also doesn't support HTTP/2, which Indeed serves. You'll likely get blocked after a handful of pages. And the CSS selectors? Indeed rotates class names like css-1m4cuuf and jobsearch-JobComponent-embeddedBody-1n0gh5s — so any selector targeting them is a ticking time bomb.
Use this method for quick prototyping on a single page. For anything at scale, use the hidden JSON approach.
How to Scrape Indeed with Python Using Hidden JSON Data
This is the method I recommend for most Python developers. Instead of parsing fragile HTML elements, you extract structured data from a JavaScript variable embedded in Indeed's page source: window.mosaic.providerData["mosaic-provider-jobcards"].
Every field you care about — job title, company, location, salary, job key, posting date, remote flag — is already in this JSON blob. No JavaScript execution required. The schema has been , making it far more resilient than DOM selectors.
Step 1: Fetch the Page HTML
Use curl_cffi instead of requests — it impersonates real browser TLS fingerprints, which is critical for surviving Cloudflare:
1from curl_cffi import requests as cffi_requests
2response = cffi_requests.get(
3 "https://www.indeed.com/jobs?q=python+developer&l=Remote&start=0",
4 impersonate="chrome124",
5 headers={
6 "Accept-Language": "en-US,en;q=0.9",
7 "Referer": "https://www.indeed.com/",
8 },
9 timeout=30,
10)
11print(response.status_code, len(response.text))Why curl_cffi? It's a Python binding over curl-impersonate, which reproduces the exact TLS ClientHello, HTTP/2 SETTINGS frame, and header ordering of real browsers. It's the only actively-maintained Python HTTP client that defeats in a single call. Supported impersonation targets include chrome120, chrome124, chrome131, Safari, and Edge variants.
Step 2: Extract the JSON with a Regular Expression
The JSON blob is embedded in a <script> tag. Pull it out with a regex:
1import re, json
2MOSAIC_RE = re.compile(
3 r'window\.mosaic\.providerData\["mosaic-provider-jobcards"\]=(\{.+?\});',
4 re.DOTALL,
5)
6match = MOSAIC_RE.search(response.text)
7if match:
8 data = json.loads(match.group(1))
9 results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
10 print(f"Found {len(results)} jobs in hidden JSON")
11else:
12 print("Hidden JSON not found — possible block or page change")Step 3: Parse Job Fields from the JSON
Each item in results contains more data than what's visible on the page:
1jobs = []
2for job in results:
3 jobs.append({
4 "jobkey": job["jobkey"],
5 "title": job["title"],
6 "company": job.get("company"),
7 "location": job.get("formattedLocation"),
8 "remote": job.get("remoteLocation"),
9 "salary": (job.get("salarySnippet") or {}).get("text"),
10 "posted": job.get("formattedRelativeTime"),
11 "job_type": job.get("jobTypes"),
12 "easy_apply": job.get("indeedApplyEnabled"),
13 "url": f"https://www.indeed.com/viewjob?jk={job['jobkey']}",
14 })The JSON often includes salary estimates, taxonomy attributes (skill tags), and company ratings that aren't always visible in the rendered HTML.
Step 4: Scrape Multiple Pages
Use tierSummaries in the JSON to understand total result counts, then loop:
1import time, random
2all_jobs = []
3for start in range(0, 50, 10): # First 5 pages
4 url = f"https://www.indeed.com/jobs?q=python+developer&l=Remote&start=\{start\}&sort=date"
5 response = cffi_requests.get(
6 url,
7 impersonate="chrome124",
8 headers={"Accept-Language": "en-US,en;q=0.9", "Referer": "https://www.indeed.com/"},
9 timeout=30,
10 )
11 match = MOSAIC_RE.search(response.text)
12 if match:
13 data = json.loads(match.group(1))
14 results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
15 all_jobs.extend([{
16 "jobkey": j["jobkey"],
17 "title": j["title"],
18 "company": j.get("company"),
19 "location": j.get("formattedLocation"),
20 "salary": (j.get("salarySnippet") or {}).get("text"),
21 "url": f"https://www.indeed.com/viewjob?jk={j['jobkey']}",
22 } for j in results])
23 time.sleep(random.uniform(3, 7))
24print(f"Total: {len(all_jobs)} jobs scraped")Why Hidden JSON Is More Resilient
The window.mosaic.providerData structure changes less frequently than CSS class names. You get clean, structured data without parsing messy HTML. That said, you still need anti-bot mitigation (headers, delays, proxies) — which we'll cover next.
How to Scrape Indeed with Python Using Selenium
Selenium is the browser automation approach. It's useful when you need to interact with the page — clicking into job detail panels, handling login-gated content, or scraping dynamically loaded descriptions that aren't in the initial HTML.
When to Use Selenium Instead of HTTP Clients
- Indeed loads some content dynamically (full job descriptions in the right-side panel)
- You need to scrape pages that require session state or login
- You're doing small-scale scraping where speed isn't critical
Quick Walkthrough
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3from selenium.webdriver.chrome.options import Options
4import time
5options = Options()
6options.add_argument("--disable-blink-features=AutomationControlled")
7# options.add_argument("--headless=new") # Headless is more detectable — use with caution
8driver = webdriver.Chrome(options=options)
9driver.get("https://www.indeed.com/jobs?q=data+engineer&l=New+York")
10time.sleep(3)
11cards = driver.find_elements(By.CSS_SELECTOR, "[data-testid='slider_item']")
12for card in cards:
13 try:
14 title = card.find_element(By.CSS_SELECTOR, "h2.jobTitle").text
15 company = card.find_element(By.CSS_SELECTOR, "[data-testid='company-name']").text
16 location = card.find_element(By.CSS_SELECTOR, "[data-testid='text-location']").text
17 print(f"\{title\} | \{company\} | \{location\}")
18 except Exception:
19 continue
20driver.quit()Limitations
Selenium is slow — each page requires full browser rendering. Headless Chrome is (Cloudflare checks navigator.webdriver, WebGL vendor strings, plugin counts, and more). Even undetected-chromedriver only delays detection; it doesn't prevent it permanently. And like BS4, your selectors will break when Indeed updates its UI.
For most use cases, the hidden JSON approach gives you the same data faster and with less maintenance. Reserve Selenium for edge cases where you genuinely need a browser.
How to Avoid 403 Errors When Scraping Indeed with Python
This is the section that matters most. If you've landed here from a frustrated Google search, you're in the right place.
Why Indeed Blocks Your Scraper
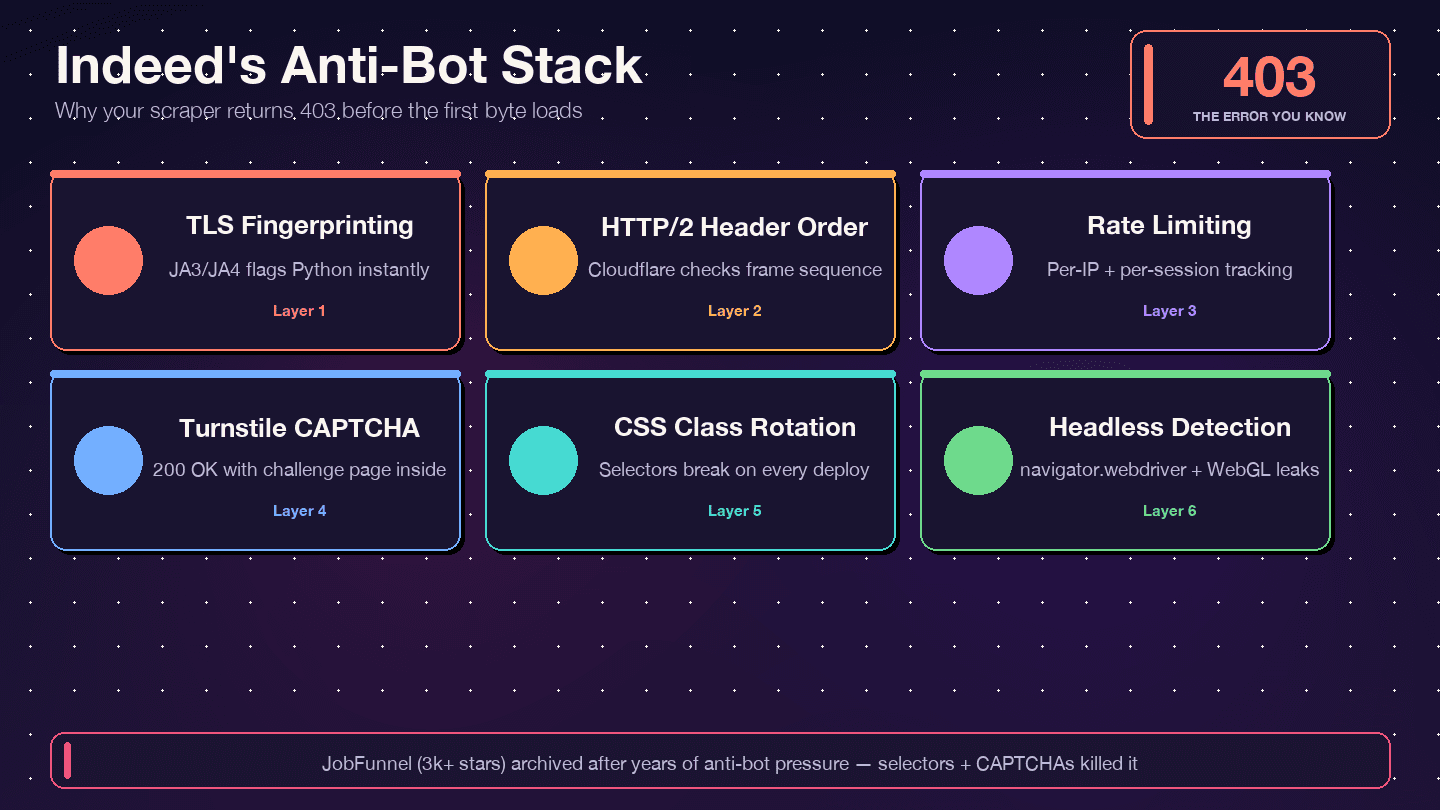
Indeed uses — not DataDome, not PerimeterX. The response headers confirm it: server: cloudflare, cf-ray, and the __cf_bm bot-management cookie. Cloudflare inspects your TLS fingerprint (JA3/JA4), HTTP/2 header ordering, request patterns, and browser behavior signals. If any of those look non-human, you get a 403, a 429, a 503, or — the sneakiest case — a 200 OK with a Turnstile challenge page instead of actual job data.
Rotate User-Agent and Request Headers
A single, static User-Agent is the fastest way to get blocked. Rotate from a pool of current, realistic strings. Important: Chrome's minor-version fields are since User-Agent Reduction — don't invent non-zero minor versions or anti-bots will flag you.
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
4 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 "
6 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
7 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
8 "(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36 Edg/145.0.3800.97",
9 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0",
10 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 "
11 "(KHTML, like Gecko) Version/17.4 Safari/605.1.15",
12]
13headers = {
14 "User-Agent": random.choice(USER_AGENTS),
15 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
16 "Accept-Language": "en-US,en;q=0.9",
17 "Accept-Encoding": "gzip, deflate, br, zstd",
18 "Referer": "https://www.indeed.com/",
19 "Sec-Fetch-Dest": "document",
20 "Sec-Fetch-Mode": "navigate",
21 "Sec-Fetch-Site": "same-origin",
22}Also make sure your sec-ch-ua Client Hints match the UA version. A sec-ch-ua: "Chrome";v="131" next to a User-Agent claiming Chrome 145 is an instant red flag.
Add Random Delays Between Requests
Fixed intervals get flagged by pattern detection. Use random jitter:
1import time, random
2# Between each request
3time.sleep(random.uniform(3, 6))
4# On retry after a block
5def backoff_sleep(attempt):
6 base = 4
7 sleep_time = base * (2 ** attempt) + random.uniform(0, 2)
8 time.sleep(min(sleep_time, 60))Field consensus from and is 3–6 seconds between requests per IP, with a hard cap of ~100 requests per IP per session before rotating.
Use Proxy Rotation
This is the single biggest determinant of success. Datacenter proxies from AWS/GCP ranges hit roughly 5–15% success on Cloudflare Enterprise targets — effectively unusable on Indeed. Residential proxies plus correct TLS fingerprinting climb to 80–95% success.
1PROXIES = [
2 "http://user:pass@us.residential.example:7777",
3 "http://user:pass@us.residential.example:7778",
4 "http://user:pass@us.residential.example:7779",
5]
6proxy = random.choice(PROXIES)
7response = cffi_requests.get(
8 url,
9 impersonate="chrome124",
10 headers=headers,
11 proxies={"https": proxy},
12 timeout=30,
13)Residential proxy pricing in 2026 runs roughly depending on provider and commitment level. For Indeed specifically, start with a small pool and scale up as needed.
Handle 403, 429, and 503 Status Codes Gracefully
Don't just retry blindly. Different status codes mean different things:
1def fetch_with_retry(url, proxy_pool, max_retries=5):
2 for attempt in range(max_retries):
3 proxy = random.choice(proxy_pool)
4 headers["User-Agent"] = random.choice(USER_AGENTS)
5 try:
6 r = cffi_requests.get(
7 url,
8 impersonate=random.choice(["chrome124", "chrome120", "edge101"]),
9 headers=headers,
10 proxies={"https": proxy},
11 timeout=30,
12 )
13 # Check for the sneaky "200 with challenge" case
14 if r.status_code == 200 and "cf-turnstile" not in r.text and "Just a moment" not in r.text:
15 return r
16 if r.status_code == 403:
17 print(f"403 — blocked. Rotating proxy, attempt {attempt + 1}")
18 elif r.status_code == 429:
19 print(f"429 — rate limited. Slowing down.")
20 elif r.status_code == 503:
21 print(f"503 — server overloaded or JS challenge.")
22 backoff_sleep(attempt)
23 except Exception as e:
24 print(f"Request error: \{e\}")
25 backoff_sleep(attempt)
26 raise RuntimeError(f"Failed after \{max_retries\} retries: \{url\}")The 200-with-challenge case is the trickiest. Always scan the response body for cf-turnstile or Just a moment markers before treating a 200 as success.
The Easier Alternative: Let Thunderbit Handle Anti-Bot for You
For users who don't want to build and maintain proxy pools, header rotation, and TLS fingerprint impersonation, cloud scraping handles CAPTCHAs, proxy rotation, and anti-bot protections automatically. No proxy setup, no curl_cffi configuration, no CAPTCHA-solving libraries. It's the path of least resistance when you just need the data.
Why Your Indeed Scraper Keeps Breaking (And How to Fix It)
The 403 wall is the acute pain. The chronic pain is maintenance — scrapers that work today break next week, silently returning empty data or stale results.
How Indeed Breaks Your Selectors
Indeed rotates CSS class names aggressively. Bright Data's guide that classes like css-1m4cuuf and css-1rqpxry "appear to be randomly generated — likely at build time." A/B testing means different sessions see different page layouts. And DOM restructuring happens without notice.
The JobFunnel saga is instructive. One contributor reported: "CaptchaBuster has successfully mitigated the captcha, and the reason for still unsuccessfully scraping the page [is] due to outdated beautiful soup selectors." The scraper wasn't blocked — it was parsing the wrong elements.
Strategy: Prefer Hidden JSON Over DOM Parsing
The window.mosaic.providerData blob has been schema-stable since at least 2023. The metaData.mosaicProviderJobCardsModel.results[] path is in 2026. DOM selectors break monthly. JSON extraction breaks annually, if at all.
Strategy: Use Data Attributes Over Class Names
When you do need to touch the DOM, target functional attributes:
| Selector | Purpose |
|---|---|
[data-testid="slider_item"] | Each job card container |
[data-testid="job-title"] or h2.jobTitle > a | Job title anchor |
[data-testid="company-name"] | Employer name |
[data-testid="text-location"] | Location text |
data-jk="<jobkey>" on each card | The single most stable hook — unchanged since 2019 |
Add Assertion Checks to Detect Stale Selectors
Never let your scraper run silently with zero results. Add a check after every fetch:
1results = parse_hidden_json(html)
2assert len(results) > 0, (
3 f"Indeed returned empty result set at start=\{start\} — "
4 "possible block, CAPTCHA, or selector drift. "
5 f"First 500 chars of response: {html[:500]}"
6)Log the first 500–2000 characters of the raw response on failure. That way you can immediately tell whether you got a Turnstile challenge, a sign-in wall, or a schema change. Run a daily CI-level smoke test against a fixed query (e.g., q=python&l=remote) that asserts non-zero results.
The AI Alternative: Scrapers That Never Break
Thunderbit's AI reads the page structure fresh each time — it doesn't rely on hardcoded selectors or regex patterns. When Indeed changes its HTML, Thunderbit adapts automatically. This directly addresses the maintenance burden that forum users consistently cite as their top frustration. If you've ever woken up to a Slack message saying "the scraper is returning empty rows again," you know the value of not having to fix it.
Scrape Indeed Without Writing Python: The No-Code Alternative
Every competing guide assumes you'll write Python code. But the forum data tells a different story. Users say things like "it's just so difficult with constant bugs and errors" and some suggest hiring someone on Fiverr just to get the data. If that sounds like you, this section is your escape hatch.
How to Scrape Indeed with Thunderbit (Step-by-Step)
Step 1: Install the from the Chrome Web Store. It's free to start.
Step 2: Navigate to an Indeed search results page in your browser — for example, https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX.
Step 3: Click the Thunderbit icon in your browser toolbar, then click "AI Suggest Fields." Thunderbit's AI scans the page and auto-detects columns like Job Title, Company, Location, Salary, Job URL, and Posted Date. You can review and adjust the suggested fields — remove columns you don't need, or add custom ones by describing what you want in plain English.
Step 4: Click "Scrape." Thunderbit extracts data from the page and displays it in a structured table. You should see rows of job listings with the fields you configured.
Enrich with Subpage Scraping
After scraping the listing page, click "Scrape Subpages" to have Thunderbit visit each individual job detail page. It pulls full job descriptions, qualifications, benefits, and application links — no additional setup needed. This is the equivalent of writing a second Python scraper to visit each /viewjob?jk=<jobkey> URL, except it takes one click.
Handle Pagination Automatically
Thunderbit auto-handles Indeed's click-based pagination. No need to manually construct offset URLs or write pagination loops. It clicks through pages and aggregates the results.
Export to Your Favorite Tools
Export scraped data to CSV, Excel, Google Sheets, Airtable, or Notion — . No need to write csv.writer() or pandas.to_csv() code.
When to Use Python vs. Thunderbit
| Scenario | Best Tool |
|---|---|
| Custom data pipelines, scheduled automation via cron/Airflow | Python |
| Integration into a larger codebase | Python |
| Highly customized parsing logic | Python |
| One-off research or market analysis | Thunderbit |
| Non-technical team members need data | Thunderbit |
| Getting data now without debugging 403s | Thunderbit |
| Subpage enrichment with zero setup | Thunderbit |
Time comparison: Python setup + anti-bot debugging = hours to days (especially your first time). Thunderbit = under 2 minutes for the same data. I'm not saying Python is wrong — I'm saying it depends on what you need.
Is Scraping Indeed Legal? What You Need to Know
None of the top-ranking Indeed scraping guides address legality, which is surprising given how often "Is scraping Indeed legal?" comes up in forums. This isn't legal advice, but here's the landscape.
Indeed's Terms of Service
Indeed's ToS () does not contain a blanket "no scraping" clause. The only explicit automation prohibition is Section A.3.5, which bans "use of any automation, scripting, or bots to automate the Indeed Apply process." That's narrowly scoped to the Apply flow, not passive reading of public job listings. Indeed's primary enforcement tool is technical — Cloudflare challenges, IP bans, device fingerprinting — not the courtroom.
Relevant Legal Precedent
The most-cited US case is hiQ Labs v. LinkedIn. The 9th Circuit that scraping publicly accessible data "likely does not violate the CFAA" (Computer Fraud and Abuse Act). However, hiQ was later found because its employees had created fake LinkedIn profiles and accepted the ToS.
More recently, Meta v. Bright Data (N.D. Cal., Jan 2024) produced an even clearer ruling. Judge Chen that Facebook and Instagram's Terms "do not bar logged-off scraping of public data." Meta voluntarily dismissed the remaining claims the following month.
Indeed's robots.txt
Indeed's broadly disallows /jobs/ and /job/ for the default User-agent: *, but explicitly allows Googlebot and Bingbot to access /viewjob? — the individual job detail pages. AI training crawlers (GPTBot, CCBot, anthropic-ai) are heavily restricted. robots.txt is not legally binding in the US, but respecting it is a best practice and evidence of good faith.
Practical Guidelines for Responsible Scraping
- Scrape only publicly available data — never log in, never create fake accounts
- Respect rate limits: 1 request every 3–6 seconds per IP, single-digit concurrency
- Don't republish scraped data as your own job board
- Use data for personal or internal research, not commercial resale without permission
- Discard or hash PII you don't need; set a retention ceiling on personal-adjacent data
- If you operate at scale or in the EU/UK, consult a lawyer — GDPR's Article 14 transparency obligations apply to scraped personal data
The risk spectrum: personal job search automation sits at the low end. Large-scale commercial resale of Indeed's data sits at the high end.
Conclusion and Key Takeaways
Scraping Indeed with Python is doable, but it's not a weekend project you set and forget. Indeed's Cloudflare protection, rotating selectors, and aggressive anti-bot measures mean you need to approach this with the right tools and the right expectations.
Here's what I'd take away from all of this:
- Indeed is the richest source of job market data on the web — 350M monthly visitors, 130M listings — but it fights back hard against scrapers.
- Hidden JSON extraction (
window.mosaic.providerData) is the most resilient Python approach. The schema has been stable for years, while CSS selectors break monthly. curl_cffiwith browser impersonation is the 2026 default HTTP client for Cloudflare-protected sites. Plainrequestsandhttpxget blocked on TLS fingerprint alone.- Always use rotating headers, random delays, and residential proxies to avoid 403 errors. Datacenter proxies are near-useless against Cloudflare Enterprise.
- Add assertion checks so you know immediately when selectors break or when you're getting served a challenge page instead of job data.
- For non-technical users or anyone who just wants results fast, provides a no-code, AI-powered path that adapts to site changes automatically — no proxies, no debugging, no maintenance.
If you want to try the no-code route, so you can test it on Indeed without any commitment. And if you're going the Python route, the code samples above are a solid starting point — just remember to treat anti-bot resilience as a first-class concern, not an afterthought.
For more on web scraping approaches and tools, check out our guides on , , and . You can also watch tutorials on the .
FAQs
What Python libraries are best for scraping Indeed?
For HTTP requests, curl_cffi is the strongest choice in 2026 — it impersonates real browser TLS fingerprints, which is essential for bypassing Cloudflare. httpx with HTTP/2 is a decent fallback for less-protected targets. For HTML parsing, BeautifulSoup4 with lxml remains the standard. For browser automation, Playwright (with playwright-stealth) or undetected-chromedriver work, though both are increasingly detectable. The hidden JSON regex approach (window.mosaic.providerData) avoids the need for heavy parsing altogether.
Why do I keep getting 403 errors when scraping Indeed?
Indeed uses Cloudflare Bot Management, which inspects your TLS fingerprint (JA3/JA4), HTTP/2 header ordering, request patterns, and browser behavior. If you're using plain requests, your TLS fingerprint immediately identifies you as a Python script — the 403 comes before your headers are even read. Fix it by switching to curl_cffi with browser impersonation, rotating realistic User-Agent strings, adding random delays (3–6 seconds), and using residential proxies. Also check for the "200 with Turnstile challenge" case — scan response bodies for cf-turnstile markers.
Can I scrape Indeed without coding?
Yes. Tools like let you extract Indeed job listings in a few clicks — install the Chrome extension, navigate to an Indeed search page, click "AI Suggest Fields," then "Scrape." Thunderbit's AI auto-detects fields like job title, company, location, and salary. It handles pagination, subpage enrichment (full job descriptions), and anti-bot protections automatically. Export to CSV, Google Sheets, Airtable, or Notion for free.
How often does Indeed change its HTML structure?
Indeed regularly rotates CSS class names (e.g., css-1m4cuuf, randomized hashed strings) and restructures DOM elements without notice. A/B testing means different users may see different layouts simultaneously. The hidden JSON approach (window.mosaic.providerData) is significantly more stable — the schema has been consistent since at least 2023. When you must use DOM selectors, target data-testid attributes and data-jk (job key) rather than CSS classes.
Is it legal to scrape Indeed?
Logged-out scraping of publicly accessible Indeed job URLs is unlikely to create CFAA liability in the US, based on the 9th Circuit's hiQ v. LinkedIn ruling (2022) and the Meta v. Bright Data decision (2024). Indeed's ToS prohibits automating the Apply process specifically, not passive reading of public listings. That said, always scrape responsibly: don't log in, don't create fake accounts, respect rate limits, don't republish data as your own job board, and handle any personal data (recruiter names, emails) carefully under GDPR/CCPA. For commercial-scale operations, consult a lawyer.
Learn More