

Google Shopping processes over 1.2 billion product searches every month. That's a staggering amount of pricing data, product trends, and seller information — all sitting right there in your browser, aggregated from thousands of retailers.
Getting that data out of Google Shopping and into a spreadsheet? That's where things get messy. I've spent a fair amount of time testing different approaches — from no-code browser extensions to full Python scripts — and the experience ranges from "wow, that was easy" to "I've been debugging CAPTCHAs for three days and I want to quit." Most guides on this topic assume you're a Python developer, but in my experience, a huge chunk of people who need Google Shopping data are ecommerce operators, pricing analysts, and marketers who just want the numbers without writing code. So this guide covers three methods, ordered from easiest to most technical, so you can pick the path that fits your skill level and time budget.
What Is Google Shopping Data?
Google Shopping is a product search engine. Type in "wireless noise-cancelling headphones" and Google pulls listings from dozens of online stores — product titles, prices, sellers, ratings, images, links. A live, constantly updating catalog of what's for sale across the internet.
Why Scrape Google Shopping Data?
One product page tells you almost nothing. Hundreds of them, structured in a spreadsheet — that's where patterns emerge.
Here are the most common use cases I've seen:
| Use Case | Who Benefits | What You're Looking For |
|---|---|---|
| Competitive pricing analysis | Ecommerce teams, pricing analysts | Competitor prices, sale patterns, price changes over time |
| Product trend discovery | Marketing teams, product managers | New products, rising categories, review velocity |
| Ad intelligence | PPC managers, growth teams | Sponsored listings, which sellers are bidding, ad frequency |
| Seller/lead research | Sales teams, B2B | Active merchants, new sellers entering a category |
| MAP monitoring | Brand managers | Retailers violating minimum advertised price policies |
| Inventory and assortment tracking | Category managers | Stock availability, product assortment gaps |
78% of U.S. retailers now use AI-enabled pricing tools. Companies investing in competitive pricing intelligence have reported returns as high as 29x. Amazon updates prices roughly every 10 minutes. If you're still checking competitor prices by hand, the math isn't in your favor.
Scrape Google Shopping data with AI Get Started Free
Thunderbit is an AI Web Scraper Chrome Extension that helps business users scrape data from websites using AI. It is especially useful for ecommerce operators, pricing analysts, and marketers who want structured Google Shopping data without writing code.
What Data Can You Actually Scrape from Google Shopping?
Before you pick a tool or write a single line of code, it helps to know exactly what fields are available — and which ones take extra work to reach.
Fields from Google Shopping Search Results
When you run a search on Google Shopping, each product card on the results page contains:
| Field | Type | Example | Notes |
|---|---|---|---|
| Product Title | Text | "Sony WH-1000XM5 Wireless Headphones" | Always present |
| Price | Number | $278.00 | May show sale price + original price |
| Seller/Store | Text | "Best Buy" | Multiple sellers possible per product |
| Rating | Number | 4.7 | Out of 5 stars; not always shown |
| Review Count | Number | 12,453 | Sometimes absent for newer products |
| Product Image URL | URL | https://... | May return base64 placeholder on initial load |
| Product Link | URL | https://... | Links to Google's product page or direct store |
| Shipping Info | Text | "Free shipping" | Not always present |
| Sponsored Tag | Boolean | Yes/No | Indicates paid placement — useful for ad intel |
Fields from Product Detail Pages (Subpage Data)
If you click through to an individual product's detail page on Google Shopping, you can access richer data:
| Field | Type | Notes |
|---|---|---|
| Full Description | Text | Requires visiting the product page |
| All Seller Prices | Number (multiple) | Side-by-side price comparison across retailers |
| Specifications | Text | Varies by product category (dimensions, weight, etc.) |
| Individual Review Text | Text | Full review content from buyers |
| Pros/Cons Summaries | Text | Google sometimes auto-generates these |
Accessing these fields means visiting each product's subpage after scraping the search results. Tools with subpage scraping capability handle this automatically — I'll walk through the workflow below.
Three Ways to Scrape Google Shopping Data (Pick Your Path)

Three methods, ordered from easiest to most technical. Pick the row that matches your situation and jump ahead:
| Method | Skill Level | Setup Time | Anti-Bot Handling | Best For |
|---|---|---|---|---|
| No-code (Thunderbit Chrome Extension) | Beginner | ~2 minutes | Handled automatically | Ecommerce ops, marketers, one-off research |
| Python + SERP API | Intermediate | ~30 minutes | Handled by the API | Developers needing programmatic, repeatable access |
| Python + Playwright (browser automation) | Advanced | ~1 hour+ | You manage it yourself | Custom pipelines, edge-case handling |
Method 1: Scrape Google Shopping Data Without Code (Using Thunderbit)
- Difficulty: Beginner
- Time Required: ~2–5 minutes
- What You'll Need: Chrome browser, Thunderbit Chrome Extension (free tier works), a Google Shopping search query
Fastest path from "I need Google Shopping data" to "here's my spreadsheet." No code, no API keys, no proxy configuration. I've walked non-technical teammates through this workflow dozens of times — zero people stuck.
Step 1: Install Thunderbit and Open Google Shopping
Install the Thunderbit AI Web Scraper from the Chrome Web Store and sign up for a free account.
Then navigate to Google Shopping. You can either go directly to shopping.google.com or use the Shopping tab in a regular Google search. Search for whatever product or category you're interested in — for example, "wireless noise-cancelling headphones."
You should see a grid of product listings with prices, sellers, and ratings.
Step 2: Click "AI Suggest Fields" to Auto-Detect Columns
Click the Thunderbit extension icon to open the sidebar, then hit "AI Suggest Fields." The AI scans the Google Shopping page and proposes columns: Product Title, Price, Seller, Rating, Review Count, Image URL, Product Link.
Review the suggested fields. You can rename columns, remove ones you don't need, or add custom fields. If you want to get specific — say, "extract only the numeric price without the currency symbol" — you can add a Field AI Prompt to that column.
You should see a preview of the column structure in the Thunderbit panel.
Step 3: Click "Scrape" and Review Results
Hit the blue "Scrape" button. Thunderbit pulls every visible product listing into a structured table.
Multiple pages? Thunderbit handles pagination automatically — clicking through pages or scrolling to load more results depending on the layout. If you have a lot of results, you can choose between Cloud Scraping (faster, handles up to 50 pages at a time, runs from Thunderbit's distributed infrastructure) or Browser Scraping (uses your own Chrome session — useful if Google shows region-specific results or requires a login).
In my testing, scraping 50 product listings took about 30 seconds. The same task manually — opening each listing, copying title, price, seller, rating — would have taken me 20+ minutes.
Step 4: Enrich Data with Subpage Scraping
After your initial scrape, click "Scrape Subpages" in the Thunderbit panel. The AI visits each product's detail page and appends additional fields — full descriptions, all seller prices, specifications, and reviews — to the original table.
No extra configuration needed — the AI figures out each detail page's structure and pulls the relevant data. I built a full competitive pricing matrix (product + all seller prices + specs) for 40 products in under 5 minutes this way.
Try Thunderbit for Google Shopping scraping
Step 5: Export to Google Sheets, Excel, Airtable, or Notion
Click "Export" and choose your destination — Google Sheets, Excel, Airtable, or Notion. All free. CSV and JSON downloads are available too.
Two clicks to scrape, one click to export. The equivalent Python script? About 60 lines of code, proxy configuration, CAPTCHA handling, and ongoing maintenance.
Method 2: Scrape Google Shopping Data with Python + a SERP API
- Difficulty: Intermediate
- Time Required: ~30 minutes
- What You'll Need: Python 3.10+,
requestsandpandaslibraries, a SERP API key (ScraperAPI, SerpApi, or similar)
If you need programmatic, repeatable access to Google Shopping data, a SERP API is the most reliable Python-based approach. Anti-bot measures, JavaScript rendering, proxy rotation — all handled behind the scenes. You send an HTTP request, you get structured JSON back.
Step 1: Set Up Your Python Environment
Install Python 3.12 (the safest production default in 2025–2026) and the required packages:
pip install requests pandas
Sign up for a SERP API provider. SerpApi offers 100 free searches/month; ScraperAPI gives 5,000 free credits. Grab your API key from the dashboard.
Step 2: Configure Your API Request
Here's a minimal example using ScraperAPI's Google Shopping endpoint:
import requests
import pandas as pd
API_KEY = "YOUR_API_KEY"
query = "wireless noise cancelling headphones"
resp = requests.get(
"https://api.scraperapi.com/structured/google/shopping",
params={"api_key": API_KEY, "query": query, "country_code": "us"}
)
data = resp.json()
The API returns structured JSON with fields like title, price, link, thumbnail, source (seller), and rating.
Step 3: Parse the JSON Response and Extract Fields
products = data.get("shopping_results", [])
rows = []
for p in products:
rows.append({
"title": p.get("title"),
"price": p.get("price"),
"seller": p.get("source"),
"rating": p.get("rating"),
"reviews": p.get("reviews"),
"link": p.get("link"),
"thumbnail": p.get("thumbnail"),
})
df = pd.DataFrame(rows)
Step 4: Export to CSV or JSON
df.to_csv("google_shopping_results.csv", index=False)
Batch-friendly: loop through 50 keywords and build a full dataset in one script run. The tradeoff is cost — SERP APIs charge per query, and at thousands of queries per day, the bill climbs. More on pricing below.
Method 3: Scrape Google Shopping Data with Python + Playwright (Browser Automation)
- Difficulty: Advanced
- Time Required: ~1 hour+ (plus ongoing maintenance)
- What You'll Need: Python 3.10+, Playwright, residential proxies, patience
The "full control" approach. You launch a real browser, navigate to Google Shopping, and extract data from the rendered page. Most flexible, but also most fragile — Google's anti-bot systems are aggressive, and the page structure changes multiple times a year.
Fair warning: I've talked to users who spent weeks fighting CAPTCHAs and IP blocks with this approach. It works, but expect ongoing maintenance.
Step 1: Set Up Playwright and Proxies
pip install playwright
playwright install chromium
You'll need residential proxies. Datacenter IPs get blocked almost immediately — one forum user put it bluntly: "All AWS IPs will be blocked or face CAPTCHA after 1/2 results." Services like Bright Data, Oxylabs, or Decodo offer residential proxy pools starting around $1–5/GB.
Configure Playwright with a realistic user-agent and your proxy:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(
headless=True,
proxy={"server": "http://your-proxy:port", "username": "user", "password": "pass"}
)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ..."
)
page = context.new_page()
Step 2: Navigate to Google Shopping and Handle Anti-Bot Measures
Build the Google Shopping URL and navigate:
query = "wireless noise cancelling headphones"
url = f"https://www.google.com/search?udm=28&q={query}&gl=us&hl=en"
page.goto(url, wait_until="networkidle")
Handle the EU cookie consent popup if it appears:
try:
page.click("button#L2AGLb", timeout=3000)
except:
pass
Add human-like delays between actions — 2–5 seconds of random wait time between page loads. Google's detection systems flag rapid, uniform request patterns.
Step 3: Scroll, Paginate, and Extract Product Data
Google Shopping loads results dynamically. Scroll to trigger lazy loading, then extract product cards:
import time, random
# Scroll to load all results
for _ in range(3):
page.evaluate("window.scrollBy(0, 1000)")
time.sleep(random.uniform(1.5, 3.0))
# Extract product cards
cards = page.query_selector_all("[jsname='ZvZkAe']")
results = []
for card in cards:
title = card.query_selector("h3")
price = card.query_selector("span.a8Pemb")
# ... extract other fields
results.append({
"title": title.inner_text() if title else None,
"price": price.inner_text() if price else None,
})
A critical note: the CSS selectors above are approximate and will change. Google rotates class names frequently. Three different selector sets have been documented across 2024–2026 alone. Anchor on more stable attributes like jsname, data-cid, <h3> tags, and img[alt] rather than class names.
Step 4: Save to CSV or JSON
import json
from datetime import datetime
filename = f"shopping_{datetime.now().strftime('%Y%m%d_%H%M')}.json"
with open(filename, "w") as f:
json.dump(results, f, indent=2)
Expect to maintain this script regularly. When Google changes the page structure — which happens multiple times per year — your selectors break and you're back to debugging.
The Biggest Headache: CAPTCHAs and Anti-Bot Blocks
Forum after forum, the same story: "I spent a few weeks but gave up against Google's anti-bot methods." CAPTCHAs and IP blocks are the number-one reason people abandon DIY Google Shopping scrapers.
How Google Blocks Scrapers (and What to Do About It)
| Anti-Bot Challenge | What Google Does | Workaround |
|---|---|---|
| IP fingerprinting | Blocks datacenter IPs after a few requests | Residential proxies or browser-based scraping |
| CAPTCHAs | Triggered by rapid or automated request patterns | Rate limiting (10–20s between requests), human-like delays, CAPTCHA-solving services |
| JavaScript rendering | Shopping results load dynamically via JS | Headless browser (Playwright) or API that renders JS |
| User-agent detection | Blocks common bot user-agents | Rotate realistic, up-to-date user-agent strings |
| TLS fingerprinting | Detects non-browser TLS signatures | Use curl_cffi with browser impersonation or a real browser |
| AWS/cloud IP blocking | Blocks known cloud provider IP ranges | Avoid datacenter IPs entirely |
In January 2025, Google made JavaScript execution mandatory for SERP and Shopping results, breaking many static-HTML scrapers — including pipelines used by SemRush and SimilarWeb. Then in September 2025, Google deprecated the legacy product detail page URLs, redirecting them to a new "Immersive Product" surface that loads via async AJAX. Any tutorial written before late 2025 is now largely obsolete.
How Each Method Handles These Challenges
SERP APIs handle everything behind the scenes — proxies, rendering, CAPTCHA solving. You don't think about it.
Thunderbit Cloud Scraping uses distributed cloud infrastructure across the US, EU, and Asia to handle JS rendering and anti-bot measures automatically. The Browser Scraping mode uses your own authenticated Chrome session, which sidesteps detection entirely because it looks like a normal user browsing.
DIY Playwright puts the entire burden on you — proxy management, delay tuning, CAPTCHA solving, selector maintenance, and constant monitoring for breakage.
The Real Cost to Scrape Google Shopping Data: An Honest Comparison
"$50 for around 20k requests… a bit steep for my hobby project." That complaint shows up constantly in forums. But the conversation usually ignores the biggest cost of all.
Cost Comparison Table
| Approach | Upfront Cost | Per-Query Cost (est.) | Maintenance Burden | Hidden Costs |
|---|---|---|---|---|
| DIY Python (no proxy) | Free | $0 | HIGH (breakage, CAPTCHAs) | Your time debugging |
| DIY Python + residential proxies | Free code | ~$1–5/GB | MEDIUM-HIGH | Proxy provider fees |
| SERP API (SerpApi, ScraperAPI) | Free tier limited | ~$0.50–5.00/1K queries | LOW | Scales up fast at volume |
| Thunderbit Chrome Extension | Free tier (6 pages) | Credit-based, ~1 credit/row | VERY LOW | Paid plan for volume |
| Thunderbit Open API (Extract) | Credit-based | ~20 credits/page | LOW | Pay per extraction |
The Hidden Cost Everyone Ignores: Your Time
A $0 DIY solution that eats 40 hours of debugging isn't free. At $50/hour, that's $2,000 in labor — for a scraper that might break again next month when Google rotates its DOM.

McKinsey's Technology Outlook finds the build/buy breakeven only beyond 3.6 million daily requests. Below that threshold, building in-house "consumes budget without delivering ROI." For most ecommerce teams doing a few hundred to a few thousand lookups per week, a no-code tool or a SERP API is significantly more cost-effective than rolling your own.
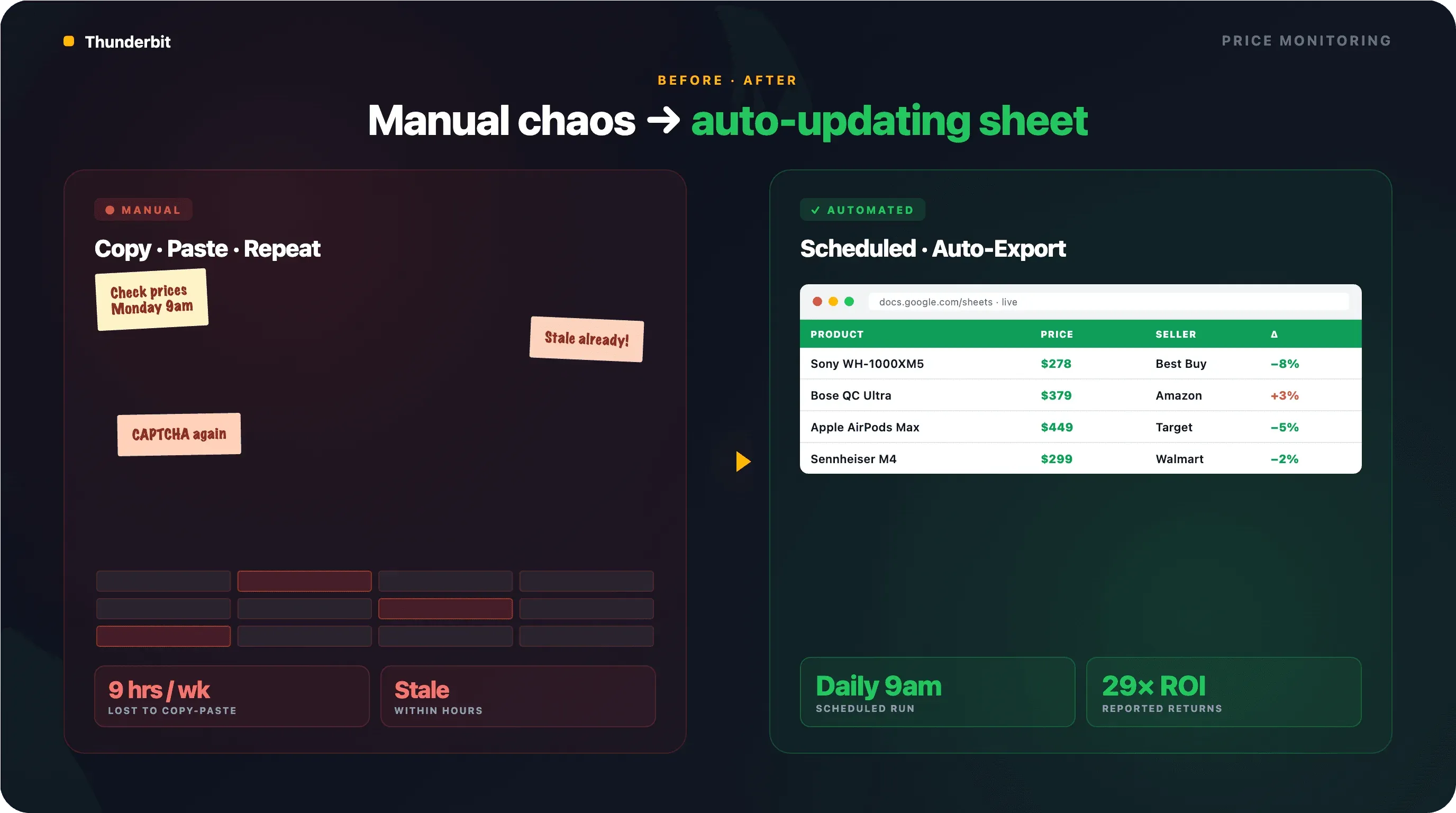
How to Set Up Automated Google Shopping Price Monitoring
Most guides treat scraping as a one-time task. The real use case for ecommerce teams is ongoing, automated monitoring. You don't just need today's prices — you need yesterday's, last week's, and tomorrow's.
Setting Up Scheduled Scraping with Thunderbit
Thunderbit's Scheduled Scraper lets you describe the time interval in plain English — "every day at 9 AM" or "every Monday and Thursday at noon" — and the AI converts it into a recurring schedule. Input your Google Shopping URLs, click "Schedule," and you're done.
Each run exports automatically to Google Sheets, Airtable, or Notion. The end state: a spreadsheet that auto-populates daily with competitor prices, ready for pivot tables or alerts.
No cron jobs. No server management. No Lambda function headaches. (I've seen forum posts from developers who spent days trying to get Selenium running in AWS Lambda — Thunderbit's scheduler skips all of that.)
For more on building price monitoring workflows, we've got a separate deep dive.
Scheduling with Python (for Developers)
If you're using the SERP API approach, you can schedule runs with cron jobs (Linux/Mac), Windows Task Scheduler, or cloud schedulers like AWS Lambda or Google Cloud Functions. Python libraries like APScheduler work too.
The tradeoff: you're now responsible for monitoring script health, handling failures, rotating proxies on schedule, and updating selectors when Google changes the page. For most teams, the engineering time spent maintaining a scheduled Python scraper exceeds the cost of a dedicated tool.
Tips and Best Practices for Scraping Google Shopping Data
Regardless of method, a few things will save you headaches.
Respect Rate Limits
Don't hammer Google with hundreds of rapid requests — you'll get blocked, and your IP might stay flagged for a while. DIY methods: space requests 10–20 seconds apart with random jitter. Tools and APIs handle this for you.
Match Your Method to Your Volume
A quick decision guide:
- < 10 queries/week → Thunderbit free tier or SerpApi free tier
- 10–1,000 queries/week → SERP API paid plan or Thunderbit paid plan
- 1,000+ queries/week → SERP API enterprise plan or Thunderbit Open API
Clean and Validate Your Data
Prices come with currency symbols, locale-specific formatting (1.299,00 € vs $1,299.00), and occasional garbage characters. Use Thunderbit's Field AI Prompts to normalize on extraction, or clean with pandas afterward:
df["price_num"] = df["price"].str.replace(r"[^\d.]", "", regex=True).astype(float)
Check for duplicates between organic and sponsored listings — they often overlap. Deduplicate by (title, price, seller) tuple.
Know the Legal Landscape
Scraping publicly available product data is generally considered legal, but the legal landscape is evolving fast. The most important recent development: Google sued SerpApi in December 2025 under DMCA § 1201 for circumventing Google's "SearchGuard" anti-scraping system. This is a new enforcement vector that sidesteps the defenses established in earlier cases like hiQ v. LinkedIn and Van Buren v. United States.
Practical guidelines:
- Scrape only publicly available data — don't log in to access restricted content
- Don't extract personal information (reviewer names, account details)
- Be aware that Google's Terms of Service prohibit automated access — using a SERP API or browser extension reduces (but doesn't eliminate) legal gray areas
- For EU operations, keep GDPR in mind, though product listings are overwhelmingly non-personal commercial data
- Consider consulting legal counsel if you're building a commercial product on scraped data
For a deeper look at web scraping legal considerations, we've covered the topic separately.
Which Method Should You Use to Scrape Google Shopping Data?
After running all three approaches on the same product categories, here's where I landed:
If you're a non-technical user who needs data fast — use Thunderbit. Open Google Shopping, click twice, export. You'll have a clean spreadsheet in under 5 minutes. The free tier lets you try it without commitment, and the subpage scraping feature gives you richer data than most Python scripts produce.
If you're a developer who needs repeatable, programmatic access — use a SERP API. The reliability is worth the per-query cost, and you skip all the anti-bot headaches. SerpApi has the best documentation; ScraperAPI has the most generous free tier.
If you need maximum control and are building a custom pipeline — Playwright works, but go in with eyes open. Budget significant time for proxy management, selector maintenance, and CAPTCHA handling. In 2025–2026, the minimum viable bypass stack is curl_cffi with Chrome impersonation + residential proxies + 10–20 second pacing. A plain requests script with rotating user-agents is dead.
The best method is the one that gets you accurate data without eating your week. For most people, that's not a 60-line Python script — it's two clicks.
Check out Thunderbit's pricing if you need volume, or watch our tutorials on the Thunderbit YouTube Channel to see the workflow in action.
Try Thunderbit for Google Shopping scraping Get Started Free
FAQs
Is it legal to scrape Google Shopping data?
Scraping publicly available product data is generally legal under precedents like hiQ v. LinkedIn and Van Buren v. United States. However, Google's Terms of Service prohibit automated access, and Google's December 2025 lawsuit against SerpApi introduced a new DMCA § 1201 anti-circumvention theory. Using reputable tools and APIs reduces risk. For commercial use cases, consult legal counsel.
Can I scrape Google Shopping without getting blocked?
Yes, but the method matters. SERP APIs handle anti-bot measures automatically. Thunderbit's Cloud Scraping uses distributed infrastructure to avoid blocks, while its Browser Scraping mode uses your own Chrome session (which looks like normal browsing). DIY Python scripts require residential proxies, human-like delays, and TLS fingerprint management — and even then, blocks are common.
What is the easiest way to scrape Google Shopping data?
Thunderbit's Chrome Extension. Navigate to Google Shopping, click "AI Suggest Fields," click "Scrape," and export to Google Sheets or Excel. No coding, no API keys, no proxy configuration. The entire process takes about 2 minutes.
How often can I scrape Google Shopping for price monitoring?
With Thunderbit's Scheduled Scraper, you can set up daily, weekly, or custom interval monitoring using plain English descriptions. With SERP APIs, frequency depends on your plan's credit limits — most providers offer enough for daily monitoring of a few hundred SKUs. DIY scripts can run as often as your infrastructure supports, but higher frequency means more anti-bot headaches.
Can I export Google Shopping data to Google Sheets or Excel?
Yes. Thunderbit exports directly to Google Sheets, Excel, Airtable, and Notion for free. Python scripts can export to CSV or JSON, which you can then import into any spreadsheet tool. For ongoing monitoring, Thunderbit's scheduled exports to Google Sheets create a live, auto-updating dataset.
- Learn More




