
If you’ve ever tried to build a targeted sales list, scout new markets, or benchmark competitors, you know the goldmine that is Google Maps. But here’s the kicker: with over 1.5 billion “near me” searches every month and 76% of local searchers visiting a business within 24 hours (), the demand for up-to-date, location-based business data has never been higher.
Whether you’re in sales, marketing, or operations, extracting structured data from Google Maps can mean the difference between a cold call and a warm, high-converting lead.
I’ve spent years in SaaS and automation, and I’ve seen firsthand how teams are using Python (and now, AI-powered tools like ) to turn Google Maps into a strategic asset.
In this guide, I’ll break down exactly how to scrape Google Maps data with Python in 2026—step by step, with code, compliance tips, and a comparison to no-code solutions. Whether you’re a Python pro or just want the fastest path to actionable data, you’re in the right place.
What Does It Mean to Scrape Google Maps with Python?
Let’s start with the basics: scraping Google Maps with Python means programmatically extracting business information—like names, addresses, ratings, reviews, phone numbers, and coordinates—from Google Maps, so you can analyze, filter, and export it for business use.

There are two main ways to do this:
- Google Maps Places API: The official, licensed way. You use an API key to query Google’s servers and get back structured JSON data. This is stable, predictable, and (mostly) compliant, but it comes with quotas and costs.
- Web Scraping the HTML: You automate a browser (with tools like Playwright or Selenium) to load Google Maps, perform searches, and parse the rendered page. This is more flexible but fragile—Google changes its site structure often, and scraping the HTML can violate Google’s terms.
Typical data fields you can extract:
- Business name
- Category/type
- Full address (plus city, state, postal code, country)
- Latitude and longitude
- Phone number
- Website URL
- Rating and review count
- Price level
- Business status (open/closed)
- Opening hours
- Place ID (Google’s unique identifier)
- Google Maps URL
Why does this matter? Because these fields power everything from lead generation and territory planning to competitor benchmarking and market research. The key is targeting the right data for your business goals—don’t just scrape blindly.
Why Sales and Marketing Teams Extract Data from Google Maps Using Python
Let’s get practical. Why are so many sales and marketing teams obsessed with Google Maps data in 2026?
- Lead Generation: Build hyper-targeted lists of local businesses, complete with contact info and ratings, for outreach campaigns.
- Territory Planning: Map out sales territories, delivery zones, or service areas based on real business density and types.
- Competitor Monitoring: Track competitors’ locations, ratings, and reviews over time to spot trends and opportunities.
- Market Research: Analyze business categories, opening hours, and review sentiment to inform go-to-market strategies.
- Site Selection: For real estate and retail, evaluate potential locations based on nearby amenities, foot traffic, and competition.
Real-world impact: According to the , 92% of sales orgs plan to expand AI/data investments, and teams using targeted, local data see conversion rates up to 8× higher than those relying on generic cold lists (). One franchise lead-gen study found $15 in new revenue for every $1 spent on Google Maps-based lead lists.
Mapping business goals to Google Maps fields:
| Business Goal | Google Maps Fields Needed |
|---|---|
| Local lead list | name, address, phone, website, category |
| Territory planning | name, lat/lng, business_status, opening_hours |
| Competitor benchmarking | name, rating, userRatingCount, priceLevel, reviews |
| Site selection | category, lat/lng, review density, openingDate |
| Sentiment/menu intel | reviews, editorialSummary, photos, types |
| Email/phone outreach | nationalPhoneNumber, websiteUri (then enrich as needed) |
Setting Up Your Python Google Maps Scraper: Tools and Requirements
Before you start scraping, you’ll need to set up your Python environment and gather the right tools. Here’s what you need in 2026:
1. Install Python and Required Libraries
Recommended Python version: 3.10 or later.
Install the key libraries:
1pip install \
2 requests==2.33.1 httpx==0.28.1 \
3 beautifulsoup4==4.14.3 lxml==6.0.3 \
4 pandas==2.3.3 \
5 selenium==4.43.0 playwright==1.58.0 \
6 googlemaps==4.10.0 google-maps-places==0.8.0 \
7 schedule==1.2.2 APScheduler==3.11.2 \
8 python-dotenv==1.2.2 tenacity==9.1.4
9playwright install chromiumWhat these do:
requests,httpx: HTTP requests (API calls)beautifulsoup4,lxml: HTML parsing (for web scraping)pandas: Data cleaning, analysis, exportselenium,playwright: Browser automation (for HTML scraping)googlemaps,google-maps-places: Google Maps API clientsschedule,APScheduler: Task schedulingpython-dotenv: Load API keys securely from.envfilestenacity: Retry logic for error handling
2. Get a Google Maps API Key (for API-based scraping)
- Go to .
- Create or select a project.
- Enable billing (required, even for free-tier usage).
- Enable “Places API (New)” in APIs & Services > Library.
- Go to Credentials > Create Credentials > API Key.
- Restrict your key to specific APIs and IPs for security.
- Store your API key in a
.envfile (never commit it to code):
1GOOGLE_MAPS_API_KEY=your_actual_api_key_hereNote: As of March 2025, Google no longer offers a universal $200/month free credit. Instead, you get free monthly thresholds per API tier (see ).
How to Extract Data from Google Maps Using Python: Step-by-Step Guide
Let’s break down both main approaches—API-based and HTML scraping—so you can choose what fits your needs.
Approach 1: Using the Google Maps Places API (Recommended)
Step 1: Install and Import Required Libraries
1import os
2import httpx
3import pandas as pd
4from dotenv import load_dotenvStep 2: Load Your API Key Securely
1load_dotenv()
2API_KEY = os.environ["GOOGLE_MAPS_API_KEY"]Step 3: Build Your Search Query
You’ll use the Text Search endpoint to find businesses matching your criteria.
1URL = "https://places.googleapis.com/v1/places:searchText"
2FIELD_MASK = ",".join([
3 "places.id", "places.displayName", "places.formattedAddress",
4 "places.location", "places.rating", "places.userRatingCount",
5 "places.priceLevel", "places.types",
6 "places.nationalPhoneNumber", "places.websiteUri",
7 "nextPageToken",
8])Step 4: Make the API Request
1def text_search(query, lat, lng, radius=3000, min_rating=4.0):
2 body = {
3 "textQuery": query,
4 "minRating": min_rating, # server-side filter
5 "includedType": "restaurant",
6 "openNow": False,
7 "pageSize": 20,
8 "locationBias": {
9 "circle": {
10 "center": {"latitude": lat, "longitude": lng},
11 "radius": radius,
12 }
13 },
14 }
15 headers = {
16 "Content-Type": "application/json",
17 "X-Goog-Api-Key": API_KEY,
18 "X-Goog-FieldMask": FIELD_MASK, # Always set this!
19 }
20 r = httpx.post(URL, json=body, headers=headers, timeout=30)
21 r.raise_for_status()
22 return r.json()Step 5: Handle Pagination and Collect Results
1def collect_all_results(query, lat, lng, radius=3000, min_rating=4.0):
2 results = []
3 next_page_token = None
4 while True:
5 data = text_search(query, lat, lng, radius, min_rating)
6 places = data.get('places', [])
7 results.extend(places)
8 next_page_token = data.get('nextPageToken')
9 if not next_page_token:
10 break
11 return resultsStep 6: Export Data with Pandas
1df = pd.DataFrame(collect_all_results("coffee shops in Brooklyn", 40.6782, -73.9442))
2df.to_csv("brooklyn_coffee_shops.csv", index=False)Pro tips:
- Always set the
X-Goog-FieldMaskheader to control costs. If you ask for reviews or photos, your price per 1,000 requests can jump from $5 to $25 (). - Use server-side filters (like
minRating,includedType,locationBias) to avoid wasting credits on irrelevant results. - Cache
place_idvalues for deduplication and future updates.
Approach 2: Web Scraping Google Maps HTML (For Educational/One-Off Use)
Warning: Google Maps is a single-page app. You must use browser automation (Playwright or Selenium), and scraping the HTML can violate Google’s terms. Use this for research, not production.
Step 1: Install Playwright and Launch a Browser
1from playwright.sync_api import sync_playwright
2import time, re
3def scrape_maps(query, max_results=100):
4 with sync_playwright() as pw:
5 browser = pw.chromium.launch(headless=True)
6 ctx = browser.new_context(
7 user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
8 locale="en-US",
9 )
10 page = ctx.new_page()
11 page.goto("https://www.google.com/maps", timeout=60_000)
12 page.fill("#searchboxinput", query)
13 page.click('button[aria-label="Search"]')
14 page.wait_for_selector('div[role="feed"]')
15 feed = page.locator('div[role="feed"]')
16 prev = 0
17 while True:
18 feed.evaluate("el => el.scrollBy(0, el.scrollHeight)")
19 time.sleep(2)
20 count = page.locator('div[role="feed"] > div > div[jsaction]').count()
21 if count == prev or count >= max_results:
22 break
23 prev = count
24 if page.locator("text=You've reached the end of the list").count():
25 break
26 rows = []
27 cards = page.locator('div[role="feed"] > div > div[jsaction]')
28 for i in range(cards.count()):
29 c = cards.nth(i)
30 name = c.locator("div.fontHeadlineSmall").inner_text() if c.locator("div.fontHeadlineSmall").count() else ""
31 rating_el = c.locator('span[role="img"]').first
32 raw = rating_el.get_attribute("aria-label") if rating_el.count() else ""
33 m = re.search(r"([\d.]+)\s+stars?\s+([\d,]+)\s+Reviews", raw or "")
34 rating = float(m.group(1)) if m else None
35 reviews = int(m.group(2).replace(",", "")) if m else None
36 rows.append({"name": name, "rating": rating, "reviews": reviews})
37 browser.close()
38 return rowsTips:
- Google randomizes CSS classes every few weeks, so this code may need regular updates.
- Use human-like delays and avoid scraping too fast to reduce the risk of being blocked.
- Never try to bypass CAPTCHAs or Google’s SearchGuard system—this can expose you to legal risk.
Avoid Blind Scraping: How to Precisely Target the Data You Need
Scraping everything is a recipe for wasted time and bloated datasets. Here’s how to target only the data that matters:
- Generate targeted URL lists: Use Google Maps’ own search filters (category, location, rating, open now) to narrow results before scraping.
- Use phrase matching: Search for exact business types or keywords (e.g., “vegan bakery in Austin”).
- Location filters: Specify city, neighborhood, or even coordinates and radius for pinpoint accuracy.
- Server-side filtering (API): Use
minRating,includedType, andlocationBiasin your API request body. - Client-side filtering (Python): After scraping, use pandas to filter for businesses with ratings above 4.0, more than 50 reviews, or specific categories.
Example: Filtering only restaurants in Manhattan with ratings above 4.0
1df = pd.DataFrame(results)
2filtered = df[(df['rating'] >= 4.0) & (df['types'].apply(lambda x: 'restaurant' in x))]
3filtered.to_csv("manhattan_top_restaurants.csv", index=False)Using Python Libraries to Organize and Export Google Maps Data
Once you’ve scraped your data, it’s time to clean, analyze, and export it for your team.
Cleaning and Structuring Data with Pandas
1import pandas as pd
2df = pd.read_json("brooklyn_restaurants.json")
3df = (
4 df.dropna(subset=["name", "address"])
5 .drop_duplicates(subset=["place_id"])
6 .assign(
7 name=lambda d: d["name"].str.strip(),
8 phone=lambda d: d["phone"].astype(str)
9 .str.replace(r"\D", "", regex=True)
10 .str.replace(r"^1?(\d\{10\})$", r"+1\1", regex=True),
11 rating=lambda d: pd.to_numeric(d["rating"], errors="coerce"),
12 user_ratings_total=lambda d: pd.to_numeric(
13 d["user_ratings_total"], errors="coerce"
14 ).fillna(0).astype("int32"),
15 )
16)Analyzing and Summarizing Data
Example: Average rating by neighborhood
1by_neighborhood = (
2 df.groupby("neighborhood", as_index=False)
3 .agg(avg_rating=("rating", "mean"),
4 n_places=("place_id", "nunique"),
5 median_reviews=("user_ratings_total", "median"))
6 .sort_values("avg_rating", ascending=False)
7)Exporting to Excel or CSV
1df.to_csv("brooklyn_top.csv", index=False)
2df.to_excel("brooklyn_top.xlsx", index=False, sheet_name="Top Rated")Large datasets? Use Parquet format for speed and size efficiency:
1df.to_parquet("brooklyn_top.parquet", compression="zstd")Thunderbit: AI-Powered Alternative to Python Google Maps Scraper
Now, if you’re thinking, “This is a lot of setup for a simple lead list,” you’re not alone. That’s exactly why we built —an AI-powered, no-code web scraper that makes extracting Google Maps data (and much more) as easy as a couple of clicks.
Why Thunderbit?
- No coding or API keys required: Just open the , navigate to Google Maps, and click “AI Suggest Fields.”
- AI field detection: Thunderbit’s AI reads the page and suggests the right columns—name, address, rating, phone, website, and more.
- Subpage scraping: Want to enrich your table with data from each business’s website? Thunderbit can visit each subpage and pull in extra info automatically.
- Export to Excel, Google Sheets, Airtable, or Notion: No more pandas wrangling—just click “Export” and your data is ready for your team.
- Scheduled scraping: Set up recurring jobs to monitor competitors or refresh your lead list automatically.
- Zero maintenance: Thunderbit’s AI adapts to site changes, so you’re not constantly fixing broken scripts.
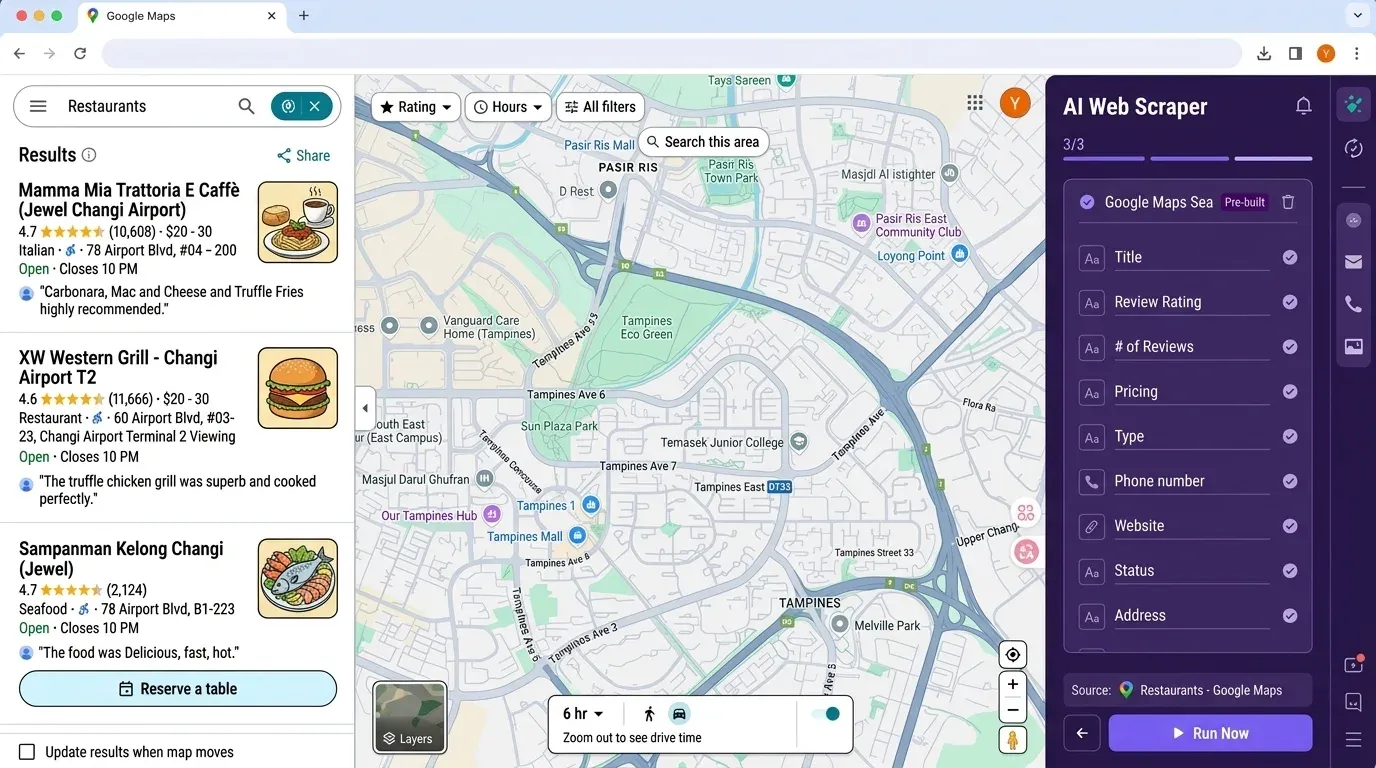
Thunderbit vs Python workflow:
| Step | Python Scraper | Thunderbit |
|---|---|---|
| Install tools | 30–60 min (Python, pip, libs) | 2 min (Chrome Extension) |
| API key setup | 10–30 min (Cloud Console) | None needed |
| Field selection | Manual code, field masks | AI Suggest Fields (1 click) |
| Data extraction | Write/run scripts, handle errors | Click “Scrape” |
| Export | pandas to CSV/Excel | Export to Excel/Sheets/Notion |
| Maintenance | Manual updates for site changes | AI auto-adapts |
Bonus: Thunderbit is trusted by over , and the free tier lets you scrape up to 6 pages (or 10 with a trial boost) at no cost.
Staying Compliant: Google Maps Terms of Service and Scraping Ethics
This is where most Python tutorials get dangerously out of date. Here’s what you need to know in 2026:
- Google Maps Platform ToS §3.2.3 strictly prohibits scraping, caching, or exporting data outside of the official APIs (). The only exception: latitude/longitude values may be cached for up to 30 days; Place IDs can be stored indefinitely.
- API users are bound by contract: If you use an API key, you’ve agreed to Google’s terms—even if you’re only scraping public data.
- Bypassing technical barriers (CAPTCHAs, SearchGuard) is now a potential DMCA §1201 violation, which can carry criminal penalties ().
- GDPR and privacy laws: If you collect personal data (emails, phones, reviewer names) from Google Maps, you must have a lawful basis and honor deletion requests. The French CNIL fined KASPR €200,000 in 2024 for scraping LinkedIn contacts ().
- Best practices:
- Default to the Places API where possible.
- Rate-limit requests (≤10 QPS for API, 1–2 req/s for HTML scraping).
- Never bypass CAPTCHAs or technical blocks.
- Don’t redistribute scraped personal data.
- Honor opt-out and deletion requests.
- Always review local laws—GDPR, CCPA, and others are actively enforced.
Bottom line: If compliance is a concern, stick to the API and minimize the data you collect. For most business users, a no-code tool like Thunderbit reduces your risk footprint (no API key, no redistribution).
Scheduling and Automating Your Google Maps Scraping with Python
If you need to keep your data fresh—say, for weekly competitor monitoring or monthly lead list updates—automation is your friend.
Simple Scheduling with schedule
1import schedule, time
2from my_scraper import run_job
3schedule.every().day.at("03:00").do(run_job, query="restaurants in Brooklyn")
4schedule.every(6).hours.do(run_job, query="coffee shops in Manhattan")
5while True:
6 schedule.run_pending()
7 time.sleep(30)Production-Grade Scheduling with APScheduler
1from apscheduler.schedulers.background import BackgroundScheduler
2from apscheduler.triggers.cron import CronTrigger
3sched = BackgroundScheduler(timezone="America/New_York")
4sched.add_job(
5 run_job,
6 CronTrigger(hour=3, minute=15, jitter=600), # 3:15 AM ± 10 min
7 kwargs={"query": "restaurants in Brooklyn"},
8 id="brooklyn_daily",
9 max_instances=1,
10 coalesce=True,
11 misfire_grace_time=3600,
12)
13sched.start()Tips for Safe Automation
- Add random jitter to your schedule to avoid predictable patterns.
- For HTML scraping, never run more than 1–2 requests per second.
- For API usage, monitor your quota and set up billing alerts.
- Always log errors and maintain a “dead-letter” file for failed requests.
Thunderbit bonus: With Thunderbit, you can schedule recurring scrapes directly in the UI—no code, no cron jobs, no server setup.
Key Takeaways: Efficient, Targeted, and Compliant Google Maps Data Extraction
Let’s recap the essentials:
- Google Maps is the #1 source for business location data, powering everything from lead gen to market research.
- Python scraping offers flexibility and control, but comes with setup, maintenance, and compliance overhead—especially as Google’s anti-bot measures and legal enforcement ramp up.
- API-based extraction is the safest and most scalable path for most teams. Always use field masks and server-side filters to control costs.
- HTML scraping is fragile and risky—use it only for one-off research, and never bypass technical barriers.
- Target your data: Use phrase matching, location filters, and pandas workflows to extract only what you need.
- Thunderbit is the fastest path for non-coders: AI-powered, no setup, instant export, and built-in scheduling.
- Compliance matters: Respect Google’s terms, privacy laws, and rate limits to avoid legal headaches.
For more tutorials and tips, check out the and our .
FAQs
1. Is it legal to scrape Google Maps data with Python in 2026?
Scraping Google Maps via the official API is allowed within Google’s terms, as long as you respect quotas and don’t redistribute restricted data. HTML scraping of Google Maps is explicitly prohibited by Google’s ToS and carries legal risk, especially if you bypass technical barriers or collect personal data without consent. Always check local laws (GDPR, CCPA, etc.) and stick to best practices for compliance.
2. What’s the difference between using the Google Maps API and web scraping the HTML?
The API is stable, licensed, and designed for data extraction, but requires an API key and is subject to quotas and costs. HTML scraping uses browser automation to extract data from the rendered page, but is fragile (site changes often), can violate terms, and is riskier legally. For most business use, the API is the recommended path.
3. How much does it cost to extract data from Google Maps using Python in 2026?
Google’s Places API pricing is per 1,000 requests, ranging from $5 (Essentials) to $25 (Enterprise+Atmosphere) depending on the fields you request. There are free monthly thresholds (10,000 for Essentials, 5,000 for Pro, 1,000 for Enterprise), but large-scale scraping can add up quickly. Always use field masks and server-side filters to control costs.
4. How does Thunderbit compare to Python-based Google Maps scrapers?
Thunderbit is a no-code, AI-powered web scraper that lets you extract Google Maps data (and much more) without programming, API keys, or maintenance. It’s ideal for sales and marketing teams who want fast, reliable exports to Excel, Google Sheets, Airtable, or Notion. For technical users needing custom logic, Python offers more flexibility but requires more setup and compliance management.
5. How can I automate recurring Google Maps data extraction?
With Python, use scheduling libraries like schedule or APScheduler to run your scraper at set intervals (daily, weekly, etc.). Add random jitter to avoid detection and monitor your API quota. With Thunderbit, you can schedule recurring scrapes directly in the UI—no code or server setup required.
Ready to turn Google Maps into your sales and marketing superpower? Whether you’re a Python enthusiast or want the fastest, no-code solution, the tools are here in 2026. Give a try for instant, AI-powered scraping—or roll up your sleeves and dive into the API. Either way, may your lead lists be fresh, your exports be clean, and your campaigns be full of high-converting local prospects. Happy scraping!
Learn More