
Google killed its Flights API back in 2018, but flight prices keep changing — for a single domestic route. If you want programmatic access to that data, scraping is basically the only game in town.
I've spent a lot of time testing different approaches to pulling flight data from Google, and the landscape has shifted dramatically — especially after Google deployed SearchGuard in January 2025. In this guide, I'll walk you through building a working Python scraper for Google Flights using Playwright, show you how to handle the anti-bot measures that trip up most people, and then extend the whole thing into an automated price tracker with alerts. If you'd rather skip the code entirely, I'll also cover a no-code shortcut using that gets you to the same result in about two minutes.
Why Scrape Google Flights with Python?
Google Flights dominates flight search. Its US mobile visibility , overtaking every major OTA. The travel metasearch market behind it is valued at , growing at 30.2% CAGR. Yet since the QPX Express API was , there's no official way to access this data programmatically.
Meanwhile, flight prices fluctuate for the same itinerary, with an average spread of about $20 between the lowest and highest price. Airlines like Delta use 77 fare buckets for dynamic pricing. The average US round-trip in early 2026 sits at $408, with airfares .
Dominant platform, no API, volatile pricing. That's why scraping Google Flights with Python has become one of the most popular projects on GitHub and travel forums alike.
Here's who benefits and how:
| User Type | Use Case | Key Benefit |
|---|---|---|
| Individual travelers | Track prices for specific routes over time | Save $50 per flight on average |
| Travel agencies | Competitive pricing intelligence | Real-time fare parity monitoring |
| Corporate travel teams | Cost optimization across routes | 10–30% savings on corporate travel |
| Developers | Build fare comparison apps | Programmatic access to pricing data |
| Researchers | Airline pricing volatility analysis | Academic and market research |
Users on forums are blunt about why they turned to scraping: "Google Flights API was discontinued and I should use web scraping instead" is a sentiment that comes up repeatedly. And the ROI is real — analyzing 5 billion+ price quotes daily, while Expedia's 2026 data shows booking 8–15 days ahead saves about .
What Data Can You Scrape from Google Flights?
A Google Flights results page contains a surprisingly rich set of data fields. Here's what's typically available:
- Airline name (and logo)
- Departure time and airport code
- Arrival time and airport code
- Total flight duration
- Number of stops and layover details (airport, duration, overnight status)
- Ticket price (currency-specific)
- CO2 emissions (kg CO2e, with percentage difference vs. typical flights)
- Travel class, flight number, airplane model
- Legroom specifications
- Extensions (Wi-Fi, power outlets, media streaming)
- Price level indicator (low/typical/high)
- Delay warnings ("Often delayed by over 30 min")
Data availability varies by route, date, and ticket type (one-way vs. round-trip). Here's what a single scraped flight record looks like as JSON:
1{
2 "search_date": "2026-04-16",
3 "route": "SFO-JFK",
4 "departure_date": "2026-05-15",
5 "flights": [
6 {
7 "airline": "United Airlines",
8 "flight_number": "UA123",
9 "departure_time": "08:00",
10 "departure_airport": "SFO",
11 "arrival_time": "16:35",
12 "arrival_airport": "JFK",
13 "duration_minutes": 335,
14 "stops": 0,
15 "price_usd": 287,
16 "price_level": "low",
17 "co2_kg": 156,
18 "co2_vs_typical": "-12%",
19 "travel_class": "Economy"
20 }
21 ]
22}Setting Up Your Python Environment
Before we write any scraping code, you'll need a few things in place.
Prerequisites:
- Difficulty: Intermediate
- Time Required: ~1–2 hours for the full tutorial
- What You'll Need: Python 3.7+, basic Python knowledge, a Chrome-based browser
Install the Required Libraries
We're using Playwright for browser automation (Google Flights is 100% JavaScript-rendered — static HTTP requests return nothing useful), plus a few helpers:
1pip install playwright playwright-stealth pandas
2playwright install chromium- Playwright — headless browser automation, handles JavaScript rendering, built-in wait mechanisms
- playwright-stealth — patches common bot detection signals
- pandas — for data analysis and CSV export later
Why Playwright Over Selenium or Requests
Google Flights won't work with requests + BeautifulSoup alone — the page content is rendered entirely by JavaScript. You need a real browser.
| Feature | Playwright | Selenium | requests + BS4 |
|---|---|---|---|
| JS rendering | Full support | Full support | None |
| Speed | 42% faster overall | Baseline | N/A for this use case |
| Async support | Native | Sequential only | N/A |
| Memory usage | 30% less | Higher | Minimal |
| Bot detection evasion | Good (with stealth) | Easier to detect | N/A |
Playwright is faster, more modern, and has better async support. For Google Flights specifically, it's the clear winner.
Step-by-Step: How to Scrape Google Flights with Python
This is the core of the tutorial. We'll build the scraper piece by piece.
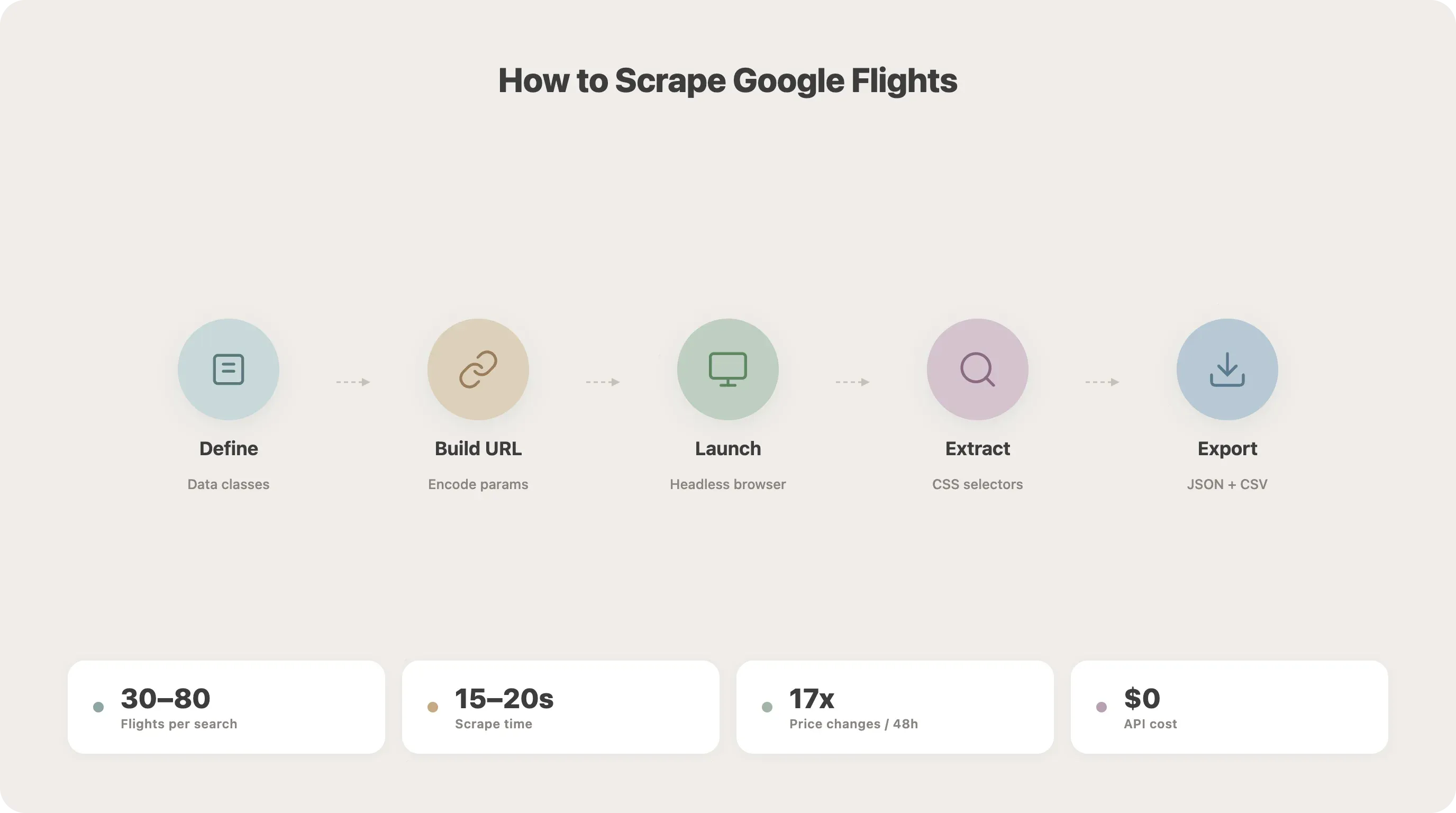
Step 1: Define Your Data Classes
Start by structuring your search parameters and flight data with Python dataclasses. This keeps things clean and makes the code easier to extend later.
1from dataclasses import dataclass, field
2from typing import Optional, List
3@dataclass
4class SearchParams:
5 origin: str # e.g., "SFO"
6 destination: str # e.g., "JFK"
7 departure_date: str # e.g., "2026-05-15"
8 return_date: Optional[str] = None
9 trip_type: str = "one-way" # "one-way" or "round-trip"
10 travel_class: str = "economy"
11@dataclass
12class FlightData:
13 airline: str = ""
14 departure_time: str = ""
15 arrival_time: str = ""
16 duration: str = ""
17 stops: str = ""
18 price: str = ""
19 co2_emissions: str = ""Each field maps directly to what we'll extract from the page. Having this structure upfront means you won't be passing around messy dictionaries later.
Step 2: Understand the Google Flights URL Structure
Google Flights encodes search parameters using Base64-encoded Protobuf in the tfs URL parameter. You can either reverse-engineer this encoding or take the simpler approach: construct a natural-language query URL.
The simplest method is using the search query format:
1https://www.google.com/travel/flights?q=flights+from+SFO+to+JFK+on+2026-05-15&curr=USDFor more control, you can build URLs programmatically:
1def build_flights_url(origin: str, destination: str, date: str) -> str:
2 base = "https://www.google.com/travel/flights"
3 query = f"flights from {origin} to {destination} on {date}"
4 return f"{base}?q={query.replace(' ', '+')}&curr=USD"The alternative — reverse-engineering the Protobuf encoding — gives you more precise control but breaks when Google changes the internal format. Libraries like on GitHub use Protobuf decoding to bypass HTML parsing entirely, but that's a more advanced approach.
Step 3: Launch the Browser and Navigate to Google Flights
Here's the Playwright setup. We're using playwright-stealth to reduce detection risk from the start.
1import asyncio
2from playwright.async_api import async_playwright
3from playwright_stealth import Stealth
4async def scrape_flights(params: SearchParams) -> List[FlightData]:
5 async with Stealth().use_async(async_playwright()) as pw:
6 browser = await pw.chromium.launch(
7 headless=True,
8 args=[
9 "--disable-blink-features=AutomationControlled",
10 "--disable-dev-shm-usage",
11 "--no-first-run",
12 ]
13 )
14 context = await browser.new_context(
15 viewport={"width": 1920, "height": 1080},
16 user_agent=(
17 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
18 "AppleWebKit/537.36 (KHTML, like Gecko) "
19 "Chrome/125.0.0.0 Safari/537.36"
20 ),
21 locale="en-US",
22 timezone_id="America/New_York",
23 )
24 # Pre-set cookie consent to skip the popup
25 await context.add_cookies([{
26 "name": "SOCS",
27 "value": "CAESHwgBEhJnd3NfMjAyNTAyMjctMF9SQzIaBXpoLUNOIAEaBgiAy6O-Bg",
28 "domain": ".google.com",
29 "path": "/"
30 }])
31 page = await context.new_page()We're running headless for production (switch to headless=False for debugging), setting a realistic viewport and user agent, and pre-setting the SOCS cookie to skip the consent popup — more on that in the anti-bot section.
Step 4: Navigate to the Search Results
Load the constructed URL and wait for flight results to appear:
1 url = build_flights_url(
2 params.origin, params.destination, params.departure_date
3 )
4 await page.goto(url, wait_until="networkidle")
5 # Wait for flight results to load
6 await page.wait_for_selector(
7 "li.pIav2d", timeout=15000
8 )If you see a timeout here, it usually means either the consent popup blocked the page (see Step 3's cookie fix) or Google is serving a CAPTCHA. We'll cover both scenarios in the anti-bot section.
Step 5: Load All Flight Results
Google Flights hides additional results behind a "Show more flights" button. You need to click it repeatedly until all flights are visible:
1 # Click "Show more flights" until all results are loaded
2 while True:
3 try:
4 more_button = page.locator(
5 'button:has-text("Show more flights")'
6 )
7 if await more_button.is_visible(timeout=3000):
8 await more_button.click()
9 await page.wait_for_timeout(2000)
10 else:
11 break
12 except Exception:
13 breakThis loop clicks the button, waits 2 seconds for new results to render, and stops when the button is no longer visible. In my testing, most routes have 1–3 pages of results.
Step 6: Extract Flight Data with CSS Selectors
Now we parse the actual flight data from the loaded page. Here are the selectors (verified as of April 2026 — see the maintenance section below for why this date matters):
1 flights = []
2 cards = await page.query_selector_all("li.pIav2d")
3 for card in cards:
4 flight = FlightData()
5 # Airline name
6 airline_el = await card.query_selector(
7 "div.sSHqwe span:not([class])"
8 )
9 if airline_el:
10 flight.airline = (await airline_el.inner_text()).strip()
11 # Departure time
12 dep_el = await card.query_selector(
13 'span[aria-label*="Departure time"]'
14 )
15 if dep_el:
16 flight.departure_time = (await dep_el.inner_text()).strip()
17 # Arrival time
18 arr_el = await card.query_selector(
19 'span[aria-label*="Arrival time"]'
20 )
21 if arr_el:
22 flight.arrival_time = (await arr_el.inner_text()).strip()
23 # Duration
24 dur_el = await card.query_selector("div.gvkrdb")
25 if dur_el:
26 flight.duration = (await dur_el.inner_text()).strip()
27 # Stops
28 stops_el = await card.query_selector("div.EfT7Ae span")
29 if stops_el:
30 flight.stops = (await stops_el.inner_text()).strip()
31 # Price
32 price_el = await card.query_selector(
33 "div.FpEdX span"
34 )
35 if price_el:
36 flight.price = (await price_el.inner_text()).strip()
37 # CO2 emissions
38 co2_el = await card.query_selector("div.O7CXue")
39 if co2_el:
40 flight.co2_emissions = (
41 await co2_el.get_attribute("aria-label") or ""
42 ).strip()
43 flights.append(flight)
44 await browser.close()
45 return flightsFair warning: class names like pIav2d, sSHqwe, and FpEdX are generated by Google's Closure Compiler and can change on any build. The aria-label selectors are more stable. I'll cover a full maintenance strategy below.
Step 7: Save Results to JSON or CSV
Finally, save the scraped data with a timestamp (critical for price tracking later):
1import json
2from datetime import datetime
3from dataclasses import asdict
4async def main():
5 params = SearchParams(
6 origin="SFO",
7 destination="JFK",
8 departure_date="2026-05-15"
9 )
10 flights = await scrape_flights(params)
11 output = {
12 "search_date": datetime.now().isoformat(),
13 "params": asdict(params),
14 "flights": [asdict(f) for f in flights],
15 }
16 with open("flights.json", "w") as f:
17 json.dump(output, f, indent=2)
18 # Also save as CSV
19 import pandas as pd
20 df = pd.DataFrame([asdict(f) for f in flights])
21 df["search_date"] = datetime.now().isoformat()
22 df["route"] = f"{params.origin}-{params.destination}"
23 df.to_csv("flights.csv", index=False)
24 print(f"Scraped {len(flights)} flights")
25asyncio.run(main())Run this and you should see a flights.json and flights.csv with your results. In my tests, a SFO-JFK search typically returns 30–80 flight options and takes about 15–20 seconds to complete.
The Anti-Bot Survival Guide for Scraping Google Flights
Most tutorials stop here. Most scrapers fail here. Google deployed , which broke nearly every SERP scraper overnight. Google describes it as "the product of tens of thousands of person hours and millions of dollars of investment." Google Flights is rated for scraping.
No competitor article covers this in depth, yet it's the #1 reason people's scrapers stop working. Here's what you're up against and how to handle it.

Random Delays Between Requests
The simplest defense against rate limiting. Two lines of code, medium effectiveness:
1import time
2import random
3time.sleep(random.uniform(3, 7))Add this between page navigations. Fixed intervals (like exactly 5 seconds every time) are a red flag — randomize.
User-Agent Rotation
Sending the same user-agent string on every request is an easy tell. Rotate from a list:
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/125.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_5) AppleWebKit/605.1.15 Safari/605.1.15",
5 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:126.0) Gecko/20100101 Firefox/126.0",
7]
8user_agent = random.choice(USER_AGENTS)Headless Detection Bypass
Google checks for the navigator.webdriver flag and other automation signals. The playwright-stealth library handles most of these, but you should also set the launch arguments shown in Step 3. The key flags:
1args=[
2 "--disable-blink-features=AutomationControlled",
3 "--disable-dev-shm-usage",
4 "--no-first-run",
5]This gets you past basic detection. SearchGuard goes deeper — monitoring mouse velocity, keyboard timing, and scroll patterns — but for moderate-volume scraping, stealth mode plus realistic delays is usually enough.
Proxy Rotation: Datacenter vs. Residential
For anything beyond a handful of searches, you'll need proxies. The difference matters:
Residential proxies are roughly when scraping protected sites. Provider pricing in 2026: Smartproxy from $7/GB, Bright Data $8.40/GB, Oxylabs $8/GB.
Add a proxy to Playwright like this:
1browser = await pw.chromium.launch(
2 proxy={"server": "http://proxy-host:port",
3 "username": "user", "password": "pass"}
4)Cookie Consent Popup Handling
Users consistently report the "I agree to terms" popup as a blocker: "first google will show you the 'I agree to terms and conditions' popup." The cleanest fix is pre-setting the SOCS cookie (shown in Step 3). If that doesn't work, click through it:
1try:
2 accept_btn = page.locator('button:has-text("Accept all")')
3 if await accept_btn.is_visible(timeout=3000):
4 await accept_btn.click()
5 await page.wait_for_timeout(1000)
6except Exception:
7 pass # No popup presentNote: the button text varies by locale — "Alle akzeptieren" in German, "Tout accepter" in French.
Anti-Bot Quick Reference
| Technique | Difficulty | Effectiveness | Code Needed? |
|---|---|---|---|
| Random delays (2–7s) | Low | Medium | 2 lines |
| User-agent rotation | Low | Medium | 5 lines |
| Headless detection bypass | Medium | High | Playwright launch args |
| playwright-stealth plugin | Medium | 60–80% on basic sites | pip install |
| Proxy rotation (datacenter) | Medium | Medium | Config |
| Proxy rotation (residential) | Medium | 85–95% success | Config |
| Cookie consent pre-set (SOCS) | Low | Required | 1 line |
For recommended safe rates: keep delays at 10–20 seconds between requests with IP rotation. Google's thresholds are roughly 100 requests/minute per IP before you get a 429, and sustained volumes above 1,000 requests/day per IP can trigger temporary bans.
Why Your Google Flights Selectors Keep Breaking (and How to Fix Them)
The #1 pain point, by a wide margin. Forum threads are full of variations on "all I get back is 14 empty lists." Every tutorial gives you selectors. None explain why they break.
Why Google Flights Selectors Change
It comes down to three things:
-
Closure Compiler obfuscation. Google uses to generate class names like
BVAVmfandYMlIzviagoog.setCssNameMapping(). These change on every build — sometimes weekly. -
A/B testing. Different users see different HTML structures simultaneously. Your scraper might work on your machine but fail for someone in a different region.
-
Locale differences. EU users see different terms, layouts, and even data fields than US users.
Write Resilient Selectors
Prefer selectors tied to meaning rather than appearance:
1# Fragile — breaks on every build
2price_el = await card.query_selector("div.BVAVmf > div.YMlIz")
3# More resilient — tied to accessibility labels
4dep_el = await card.query_selector('span[aria-label*="Departure time"]')
5# Also resilient — text-based matching
6more_btn = page.locator('button:has-text("Show more flights")')Selector stability hierarchy (most to least stable):
aria-labelattributes — tied to accessibility, rarely changeddata-*attributes — explicitly added for functionalityroleattributes — ARIA roles are semantic- Text-based selectors — match visible content
- Substring class matching — e.g.,
[class*="price"] - Full obfuscated class names — avoid these when possible
Add a Validation Function
Don't let broken selectors silently produce empty data. Catch it early:
1import logging
2logger = logging.getLogger(__name__)
3def validate_flight(data: FlightData) -> bool:
4 required = ["airline", "price", "departure_time",
5 "arrival_time", "duration"]
6 valid = True
7 for field_name in required:
8 if not getattr(data, field_name, ""):
9 logger.warning(
10 f"Missing '{field_name}' — selectors may need updating"
11 )
12 valid = False
13 return validRun this on every scraped flight. If you start seeing warnings, it's time to inspect the page and update your selectors.
Selector Maintenance Strategy
- Check selectors monthly, or immediately when output quality drops
- Keep selectors in a separate config dictionary for easy updates
- Selectors in this article were last verified: April 2026
- Consider the as an alternative — it uses Protobuf decoding instead of CSS selectors, sidestepping this problem entirely (though it has its own fragility when Google changes internal data formats)
From One-Off Scrape to Automated Google Flights Price Tracker
Most tutorials end at "save to JSON." The title of this article says "Price Alerts." Time to deliver.
![]()
Schedule Your Scraper to Run Automatically
Option 1: Python schedule library (simplest, cross-platform):
1import schedule
2import time
3def run_scraper():
4 asyncio.run(main())
5schedule.every().day.at("06:00").do(run_scraper)
6schedule.every().day.at("18:00").do(run_scraper)
7while True:
8 schedule.run_pending()
9 time.sleep(60)Option 2: cron job (Linux/Mac):
1# Run at 6 AM and 6 PM daily
20 6,18 * * * cd /path/to/scraper && python scraper.pyOption 3: Windows Task Scheduler — create a basic task that runs python scraper.py on your preferred schedule.
The trade-off: all of these require a machine that's always on. If you're running this on a laptop that sleeps, you'll miss scrapes.
Store Historical Price Data
Switch from overwriting a JSON file to appending to a SQLite database:
1import sqlite3
2from datetime import datetime
3def init_db():
4 conn = sqlite3.connect("flights.db")
5 conn.execute("""
6 CREATE TABLE IF NOT EXISTS flights (
7 id INTEGER PRIMARY KEY AUTOINCREMENT,
8 scrape_date TEXT NOT NULL,
9 route TEXT NOT NULL,
10 airline TEXT,
11 departure_time TEXT,
12 arrival_time TEXT,
13 duration TEXT,
14 stops TEXT,
15 price_usd REAL,
16 co2_emissions TEXT
17 )
18 """)
19 conn.execute(
20 "CREATE INDEX IF NOT EXISTS idx_route_date "
21 "ON flights(route, scrape_date)"
22 )
23 conn.commit()
24 return conn
25def save_flight(conn, route: str, flight: FlightData):
26 price_num = float(
27 flight.price.replace("$", "").replace(",", "")
28 ) if flight.price else None
29 conn.execute(
30 "INSERT INTO flights "
31 "(scrape_date, route, airline, departure_time, "
32 "arrival_time, duration, stops, price_usd, co2_emissions) "
33 "VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)",
34 (datetime.now().isoformat(), route, flight.airline,
35 flight.departure_time, flight.arrival_time,
36 flight.duration, flight.stops, price_num,
37 flight.co2_emissions)
38 )
39 conn.commit()After a week of twice-daily scrapes, you'll have enough data to start spotting trends.
Analyze Price Trends and Set Alerts
Find the cheapest option from your historical data:
1import pandas as pd
2import sqlite3
3conn = sqlite3.connect("flights.db")
4df = pd.read_sql_query(
5 "SELECT * FROM flights WHERE route = 'SFO-JFK'", conn
6)
7summary = df.groupby("scrape_date")["price_usd"].agg(
8 ["min", "max", "mean"]
9)
10cheapest = df.loc[df["price_usd"].idxmin()]
11print(
12 f"Cheapest: ${cheapest['price_usd']:.0f} on "
13 f"{cheapest['scrape_date']} ({cheapest['airline']})"
14)Trigger an email alert when a price drops below your threshold:
1import smtplib
2from email.mime.text import MIMEText
3def send_price_alert(route, price, threshold, recipient):
4 msg = MIMEText(
5 f"Price drop alert! {route}: ${price:.0f} "
6 f"(below your ${threshold:.0f} threshold)"
7 )
8 msg["Subject"] = f"Flight Deal: {route} at ${price:.0f}"
9 msg["From"] = "alerts@example.com"
10 msg["To"] = recipient
11 with smtplib.SMTP_SSL("smtp.gmail.com", 465) as server:
12 server.login("alerts@example.com", "your_app_password")
13 server.send_message(msg)
14# After each scrape, check for deals
15min_price = df["price_usd"].min()
16threshold = 250
17if min_price < threshold:
18 send_price_alert("SFO-JFK", min_price, threshold,
19 "you@email.com")For recommended scraping frequency: twice daily is sufficient for personal price watching (random timing reduces detection risk). Every 4–6 hours if you're monitoring for a business. Hourly only during peak sale periods, and only temporarily.
The Easy Path: Thunderbit's Scheduled Scraper
If managing cron jobs, a running server, and proxy configs sounds like more infrastructure than you want to maintain, Scheduled Scraper handles the same use case without any of that overhead. You describe the scraping interval in plain language, input your Google Flights URLs, and the scraper runs automatically on Thunderbit's cloud infrastructure — with anti-bot handling built in and results exported directly to . It's not a replacement for the full Python approach (you lose customization), but for the specific "I want a price-tracking spreadsheet" use case, it's the fastest path. You can try it on the .
When Python Is Overkill: No-Code Ways to Scrape Google Flights
After building all of the above, I'll be honest: it's a lot of moving parts. Not everyone needs this level of control. Selectors break, proxies need rotating, cron jobs need monitoring. If your goal is "get flight prices into a spreadsheet regularly," there are faster options.
Comparison: DIY Python vs. API Services vs. Thunderbit
| Approach | Setup Time | Coding Required | Handles Anti-Bot | Scheduling | Cost |
|---|---|---|---|---|---|
| DIY Playwright (this tutorial) | 1–2 hours | Python (intermediate) | Manual config | Manual (cron) | Free + proxy costs |
| SerpApi Google Flights endpoint | 15 min | API calls only | Handled | Via API | ~$50+/mo |
| Thunderbit Chrome Extension | 2 min | None | Cloud scraping | Built-in scheduler | Free tier available |
A note on SerpApi: Google , alleging their requests increased 25,000% over two years. That legal uncertainty is worth considering if you're evaluating API providers.
How Thunderbit Scrapes Google Flights
Open your Google Flights search results in Chrome, click Thunderbit's "AI Suggest Fields" button — the AI reads the page and suggests columns like airline, price, departure time, stops — review the suggested fields, and click "Scrape." Results appear in a table you can export to Excel, Google Sheets, Airtable, or Notion — all on the .
For the price tracking use case specifically, Thunderbit's Scheduled Scraper and (which can handle 50 pages concurrently) replace the entire cron + proxy + server infrastructure.
Python gives you full control and unlimited customization. Thunderbit gives you speed and zero maintenance. Pick based on your actual goal. If you want to learn more about no-code scraping approaches, check out our guide on .

Is Scraping Google Flights Legal? What You Need to Know
Forum users raise this regularly: "scraping Google Flights directly violates the TOS that Google has." Fair concern — especially since the API was discontinued and there's no sanctioned alternative.
TOS Violation vs. Legal Liability
Google's Terms of Service (updated May 22, 2024) state that users must not "access or use the Services or any content through the use of any automated means (such as robots, spiders or scrapers)." Violating ToS is a breach of contract (civil matter) — it's not the same as breaking the law.
The key legal precedent: hiQ v. LinkedIn (Ninth Circuit, 2022) established that scraping publicly available data does not violate the Computer Fraud and Abuse Act (CFAA). However, the case ended in settlement, and Google's December 2025 lawsuit against SerpApi uses a different legal theory — DMCA Section 1201 (circumvention of technological protection measures) — which is potentially more serious.
Best Practices for Responsible Scraping
- Rate-limit your requests — 10–20 second delays with IP rotation
- Don't scrape personal data — flight prices are publicly displayed aggregate data
- Don't circumvent CAPTCHAs programmatically (this is the DMCA risk area)
- Use the data for personal research, not to build a competing commercial product without proper licensing
- Consider official APIs where available
Alternative Data Sources
If scraping feels too risky for your use case, there are legitimate API options:
| Provider | Cost | Free Tier | Notes |
|---|---|---|---|
| SerpApi | $75–$3,750+/mo | 250 searches/mo | Direct Google Flights JSON (under legal scrutiny) |
| Kiwi Tequila | Free (affiliate model) | Unlimited | Best for startups and testing |
| Amadeus | Pay-as-you-go | 2,000 req/mo | 400+ airlines, booking capability |
| Skyscanner | Custom | Requires approval | 52 markets, 30 languages |
We wrote a deeper breakdown of if you want the full picture.
Conclusion and Key Takeaways
That was a lot. Here's what matters:
- Python + Playwright is the most flexible approach for scraping Google Flights, but it requires ongoing maintenance
- Anti-bot measures (delays, user-agent rotation, residential proxies) are not optional — they're essential for reliability, especially post-SearchGuard
- Selectors break often — use
aria-labeland text-based selectors where possible, validate your output, and keep a maintenance schedule - Automate with
scheduleor cron to turn a one-off scrape into a real price tracker with historical data and email alerts - offers a no-code alternative with built-in scheduling, cloud scraping, and anti-bot handling — ideal if your goal is a price-tracking spreadsheet rather than a coding project
- Respect legal boundaries — rate-limit, scrape only public data, and consider API alternatives for commercial use
Grab the code from this tutorial, or install the for the quick path. Either way, you'll be tracking flight prices instead of manually refreshing Google Flights.
For more Python scraping techniques, check out our guides on and .
FAQs
1. Can I scrape Google Flights without Python?
Yes. API services like SerpApi and Kiwi Tequila provide structured flight data via API calls (no browser automation needed). For a fully no-code approach, can scrape Google Flights results directly from your browser with AI-suggested fields and one-click export.
2. Does Google block flight scraping?
Google uses bot detection (SearchGuard), CAPTCHAs, and rate limiting. With proper anti-bot measures — random delays, user-agent rotation, residential proxies, and stealth browser settings — you can maintain reliable scraping at moderate volumes. See the anti-bot section above for specific techniques and thresholds.
3. How often should I scrape Google Flights for price tracking?
Twice daily (at random times) is sufficient for personal price watching and keeps detection risk low. For business monitoring, every 4–6 hours with proxy rotation. Avoid hourly scraping except during short-term fare sales — it significantly increases the chance of getting blocked.
4. Is there a free Google Flights API?
The official Google QPX Express API was . There is no free official replacement. The closest free option is the (affiliate model, unlimited searches). SerpApi offers 250 free searches per month. For most users, scraping or a no-code tool like Thunderbit is the practical path.
5. Why do my Google Flights CSS selectors keep returning empty data?
Google uses Closure Compiler to generate obfuscated class names that change on every build. A/B testing and locale differences also cause HTML structure to vary between users. The fix: use aria-label attributes and text-based selectors instead of class names, add a validation function to catch breakage early, and check your selectors monthly. See the selector maintenance section for a detailed strategy.
Learn More