
If your Glassdoor scraper worked great in 2022 and now returns nothing but 403s, you're not alone. Forum after forum is littered with the same question: "Does anyone know why this scraper does not work anymore?"
The short answer: Glassdoor changed everything. Recruit Holdings folded Glassdoor into Indeed in July 2025, laid off , and tightened the anti-bot stack to the point where vanilla Selenium and requests-based scrapers get blocked before the first byte of HTML loads. As of February 2026, Glassdoor logins are handled entirely through Indeed Login — so any tutorial that hard-codes a Glassdoor-specific login form is structurally broken at the source. Meanwhile, the platform still holds across . That data is incredibly valuable for HR benchmarking, competitive intelligence, and sales prospecting — if you can actually get to it. This guide is the version that works after all those changes happened, and it covers all three Glassdoor data types (jobs, reviews, AND salaries) in a single place. I'll walk you through the Python approach with working 2025 code, explain exactly what blocks you and how to beat it, and show a no-code shortcut for anyone who'd rather skip the engineering entirely.
Why Scrape Glassdoor with Python in 2025?
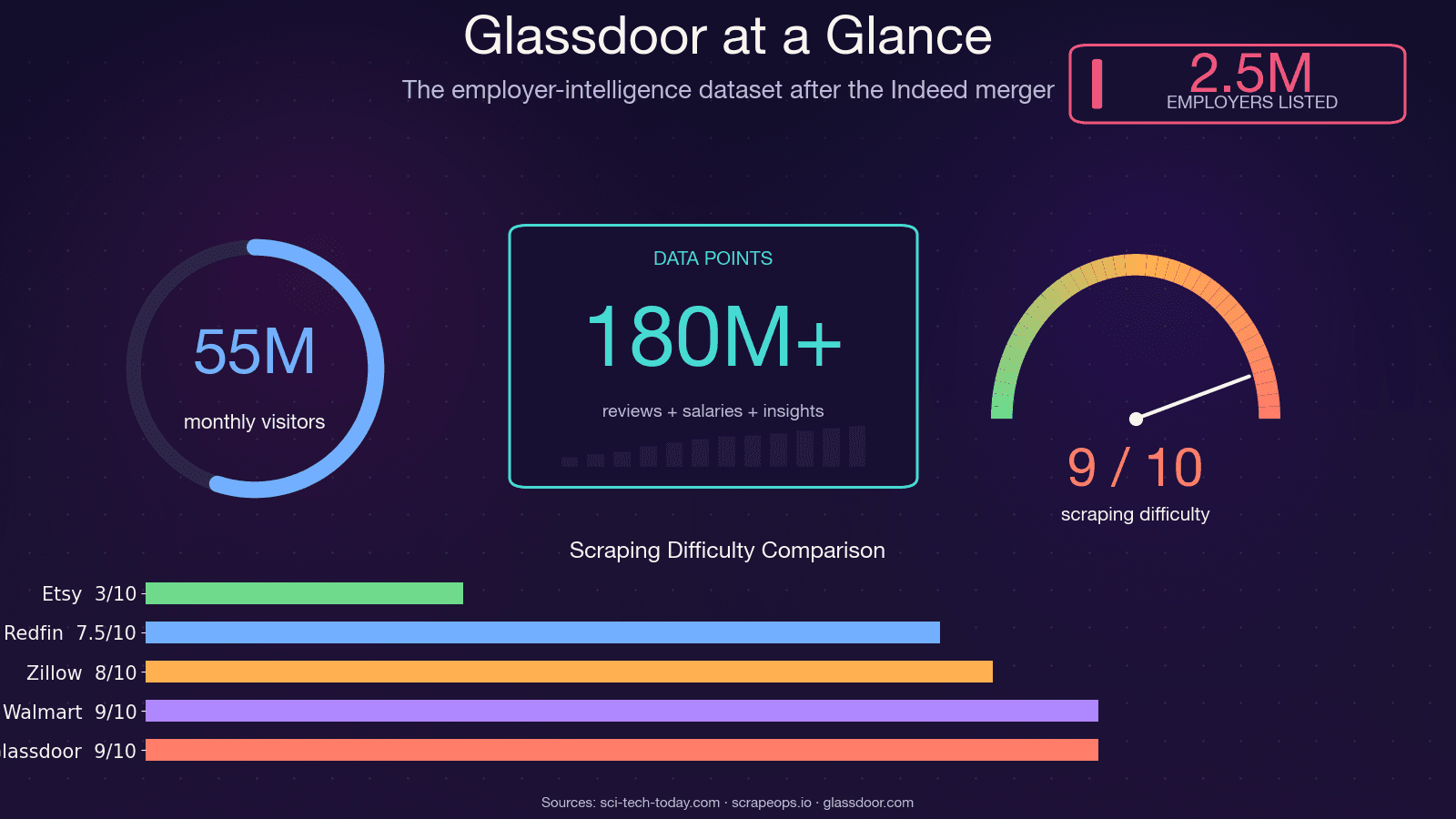
Glassdoor isn't just a job board. It's one of the richest employer-intelligence datasets on the web — used by roughly and drawing about 55 million monthly unique visitors. The data sitting behind those pages fuels real business decisions across multiple teams.
Here's how different teams actually use Glassdoor data:
| Use Case | Data Type Needed | Who Benefits |
|---|---|---|
| Salary benchmarking | Salary distributions, sample sizes | HR, Total Rewards, Operations |
| Competitor hiring tracking | Job listings, posting velocity | Sales, Strategy, VC/Corp Dev |
| Employer brand monitoring | Review text, rating trends, CEO approval | HR, Marketing, Comms |
| Lead generation (growing companies) | Job listings + company info | Sales teams, SDRs |
| Market/academic research | All three | Analysts, Consultants, Researchers |
When the BLS couldn't publish jobs data during the October 2025 government shutdown, Glassdoor's own Economic Research team from their dataset. That's how seriously institutional analysts treat this data now.
Python remains the go-to language because the ecosystem is unmatched — Playwright for browser automation, parsel/lxml for parsing, curl_cffi for TLS fingerprint bypass, and a massive community that shares working patterns. The problem isn't Python. The problem is that Glassdoor got a lot harder to scrape.
If you want a no-code fallback for Glassdoor data extraction, Thunderbit can help you scrape jobs, reviews, and salary pages without building and maintaining a custom Python stack.
What Glassdoor Data Can You Actually Scrape?
Most tutorials only cover job listings. But user demand — based on forum threads, GitHub issues, and Reddit questions I've tracked — is highest for the two data types nobody teaches: reviews and salaries. Here's the full breakdown of what's extractable across all three categories.
Job Listings
The most accessible data type. You can pull: job title, company name, location, salary estimate, company rating, posted date, easy-apply badge, and job link. Job listings are partially available without logging in, though Glassdoor may throw a login popup after several pages.
Company Reviews
This is where it gets interesting for employer brand analysis. Extractable fields include: overall rating, sub-ratings (work-life balance, culture & values, diversity & inclusion, career opportunities, comp & benefits, senior management), pros text, cons text, reviewer job title, review date, and employment status. Full review text is login-gated — you'll see a snippet, but the complete pros/cons require authentication.
Salary Data
The most requested and most frustrating data type. You can extract: job title, base pay range, total compensation range, number of salary reports, and location. But salary pages are fully login-gated, and Glassdoor sometimes layers on a "contribute to unlock" flow where you need to submit your own salary before seeing others. No competing tutorial provides working code for this — we'll fix that.
What Requires Login vs. What Doesn't
This table saves you from discovering the hard way which pages will return empty data:
| Data Type | Available Without Login? | Notes |
|---|---|---|
| Job listing titles & basic info | Mostly yes | Popup may appear after several pages |
| Full job descriptions | Partial | Often gated after 2–3 views |
| Company reviews (full text) | No — login required | Snippet visible, full text gated |
| Salary data | No — login required | May also require "contribute to unlock" |
Why Your Old Glassdoor Scraper Is Probably Broken
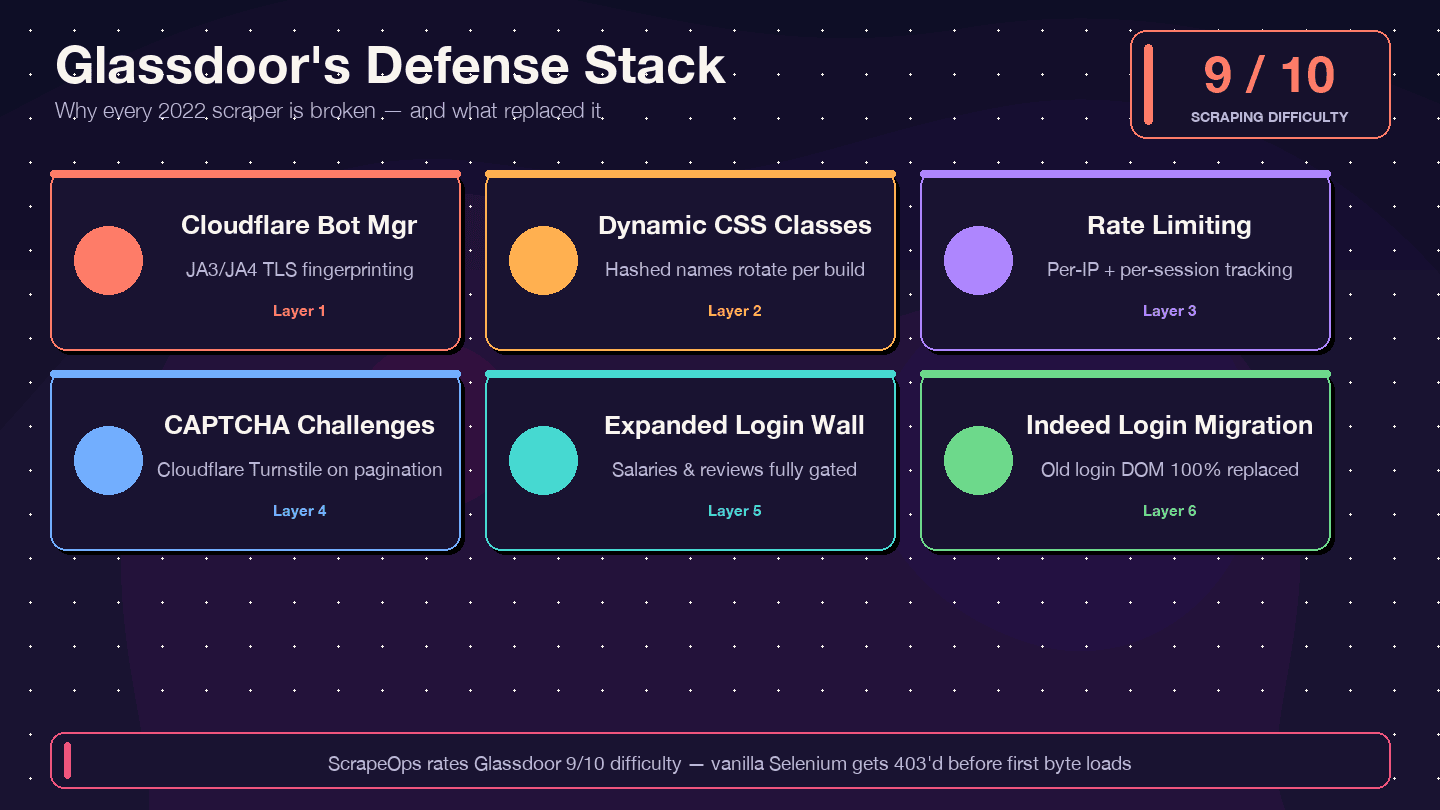
I want to be direct about this: if you're copying code from a 2021–2023 tutorial, it will not work. The most-starred legacy Glassdoor Selenium scraper on GitHub (, ~1.4k stars) has 12+ open, unresolved issues — including "Glassdoor new UI design," "Cloudflare anti-bot protection," and "NoSuchElementException." The repo is effectively abandoned. . and 8/10 bypass difficulty.
Here's what changed and why old code breaks:
| Defense Layer | What Changed | Impact on Old Scrapers |
|---|---|---|
| Cloudflare Bot Management | Stricter JA3/JA4 fingerprinting since 2024 | Basic requests/Selenium scripts get 403'd immediately |
| Dynamic CSS class names | Class names randomized on each build | Old CSS selectors from tutorials break silently |
| Rate limiting + session tracking | Tighter per-IP and per-session limits | Scrapers get blocked after fewer pages |
| CAPTCHA challenges (likely Cloudflare Turnstile) | More frequent, especially during pagination | Headless browsers trigger challenges |
| Expanded login wall | More page types require authentication | Salary and review pages return empty data |
| Indeed Login migration (Feb 2026) | Glassdoor login form replaced entirely | Any code targeting old login DOM is dead |
carries an explicit warning: "Glassdoor is known for its high blocking rate, so if you get None values while running the Python code, it's likely you're getting blocked." And a puts it bluntly: "Simple HTTP requests with requests or httpx get blocked instantly."
The countermeasures I'll show you — Patchright (a stealth Playwright fork), data-test attribute selectors, rotating residential proxies, and authenticated persistent sessions — are specifically designed to handle each of these layers.
Glassdoor API vs. Python Scraping: Pick the Right Approach First
Multiple forum threads ask "Should I just use the Glassdoor API?" — and the answer is: you can't.
The . The developer portal still technically exists but . There was never a public reviews endpoint — MatthewChatham's scraper was created explicitly "because Glassdoor doesn't have an API for reviews." And there's no migration path for reviews or salaries under Indeed's Publisher API.
Here's the honest comparison:
| Factor | Glassdoor Partner API v1 | Python Scraping | Thunderbit (no-code) |
|---|---|---|---|
| Access | Closed to new applicants | Open (you implement) | Chrome extension |
| Job listings | Limited/sunset | Available with effort | Available |
| Company reviews | Never existed publicly | Yes (login needed) | Yes (via Browser Mode) |
| Salary data | Never existed publicly | Yes (login needed) | Yes |
| Rate limits | Undocumented | You control pacing | Credit-based |
| Setup effort | Can't register new apps | Hours to days | ~2 minutes |
| Maintenance burden | N/A | High (HTML changes break code) | Low (AI re-suggests fields) |
If you need reviews or salary data — and most people reading this do — Python scraping or a no-code tool is your only realistic option.
Before You Start
- Difficulty: Intermediate (you should be comfortable with Python and the terminal)
- Time Required: ~30–60 minutes for the full setup; ~10 minutes per data type after that
- What You'll Need:
- Python 3.10+ (3.11 or 3.12 recommended)
- Chrome browser installed
- A Glassdoor account (free — needed for salary and review data)
- Rotating residential proxies (for scraping more than a handful of pages)
- Optional: if you want the no-code path
Tools and Libraries for Scraping Glassdoor with Python in 2025
The tooling landscape has shifted dramatically. Here's what actually works against Glassdoor's current defenses.
Why Patchright Is the Best Choice for Glassdoor
is a stealth fork of Playwright that patches the Runtime.Enable CDP leak — the specific technical reason vanilla Playwright fails on Cloudflare-protected sites. It uses the exact same API as Playwright, so if you know Playwright, you know Patchright. Version 1.58.2 (March 2026) is current and actively maintained.
Compared to the alternatives:
- Vanilla Playwright: Gets detected on Glassdoor's login page due to the Runtime.Enable leak
- Selenium + undetected-chromedriver: undetected-chromedriver's last release was February 2024 — it's effectively legacy. found it "failed on every domain in our test"
- requests + BeautifulSoup: Can't render JavaScript, blocked immediately by Cloudflare's TLS fingerprinting
- : Excellent for the fast path (10–20x faster than a browser) when pages ship
__NEXT_DATA__in the initial HTML, but can't handle login or interstitial challenges
Supporting Libraries
- parsel (1.11.0) or lxml (6.0.4): Fast HTML/XPath parsing
- csv or pandas: Data export
- asyncio: Async scraping for faster pagination
Proxies: Residential Only
Glassdoor's Cloudflare layer aggressively challenges datacenter ASNs. . Entry pricing is around (promotional) or $3.00/GB from . For production scraping, budget $3–8/GB depending on volume.
Random delays between requests (3–8 seconds minimum, 5–15 seconds for longer runs) are essential regardless of proxy quality.
Step 1: Set Up Your Python Environment
Create your project folder and install the recommended stack:
1mkdir glassdoor-scraper && cd glassdoor-scraper
2python3.11 -m venv .venv
3source .venv/bin/activate
4pip install --upgrade pip
5# Core stack
6pip install patchright==1.58.2 parsel==1.11.0
7# Install browser binaries
8patchright install chromium
9# Optional: fast path for __NEXT_DATA__ extraction
10pip install "curl_cffi==0.15.0"You should see Patchright download a Chromium binary. If patchright install chromium fails, check that you have sufficient disk space (~300MB) and that your Python version is 3.10+.
Step 2: Launch Patchright and Navigate to Glassdoor
Here's the baseline launch pattern that works against Glassdoor's Cloudflare layer:
1from patchright.sync_api import sync_playwright
2import random, time
3with sync_playwright() as p:
4 browser = p.chromium.launch(
5 headless=False, # headless is still more detectable
6 channel="chrome", # use real Chrome, not bundled Chromium
7 )
8 context = browser.new_context(
9 viewport={"width": 1440, "height": 900},
10 locale="en-US",
11 timezone_id="America/New_York",
12 user_agent=(
13 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
14 "AppleWebKit/537.36 (KHTML, like Gecko) "
15 "Chrome/134.0.0.0 Safari/537.36"
16 ),
17 )
18 page = context.new_page()
19 page.goto(
20 "https://www.glassdoor.com/Job/new-york-data-engineer-jobs-"
21 "SRCH_IL.0,8_IC1132348_KO9,22.htm"
22 )
23 # Dismiss the login overlay — content is still in the DOM
24 page.add_style_tag(content="""
25 #HardsellOverlay, .LoginModal { display: none !important; }
26 body { overflow: auto !important; position: initial !important; }
27 """)
28 page.wait_for_selector("[data-test='jobListing']")
29 print("Page loaded — job listings visible.")A few things to note here. The channel="chrome" flag tells Patchright to use your installed Chrome binary rather than its bundled Chromium — this produces a more authentic browser fingerprint. The add_style_tag trick hides Glassdoor's login modal (called #HardsellOverlay) without clicking anything. that "all of the content is still there, it's just covered up by the overlay" — the HTML contains the data regardless of whether the modal is showing.
You should see a Chrome window open, navigate to the Glassdoor job search page, and display job listing cards without the login popup blocking the view.
Step 3: Scrape Glassdoor Job Listings
Identify Stable Selectors
Glassdoor randomizes CSS class names on every build — so the .jobCard_xyz123 selector from a 2023 tutorial will silently return nothing today. Instead, use data-test attributes, which are Glassdoor's internal QA convention and remain stable across deploys.
Here's the selector reference for job listing fields:
| Field | Selector |
|---|---|
| Job card container | [data-test="jobListing"] |
| Job title | [data-test="job-title"] |
| Job link | a[data-test="job-link"] |
| Company name | [data-test="employer-name"] |
| Location | [data-test="emp-location"] |
| Salary range | [data-test="detailSalary"] |
| Company rating | [data-test="rating"] |
| Posted date | [data-test="job-age"] |
| Pagination next | [data-test="pagination-next"] |
Extract Job Data
1from parsel import Selector
2import csv, random, time
3def scrape_jobs(page, max_pages=5):
4 all_jobs = []
5 for page_num in range(1, max_pages + 1):
6 html = page.content()
7 sel = Selector(text=html)
8 cards = sel.css('[data-test="jobListing"]')
9 if not cards:
10 print(f"Page {page_num}: No cards found — possible block or selector change.")
11 break
12 for card in cards:
13 job = {
14 "title": card.css('[data-test="job-title"]::text').get("").strip(),
15 "company": card.css('[data-test="employer-name"]::text').get("").strip(),
16 "location": card.css('[data-test="emp-location"]::text').get("").strip(),
17 "salary": card.css('[data-test="detailSalary"]::text').get("").strip(),
18 "rating": card.css('[data-test="rating"]::text').get("").strip(),
19 "link": card.css('a[data-test="job-link"]::attr(href)').get(""),
20 "posted": card.css('[data-test="job-age"]::text').get("").strip(),
21 }
22 if job["link"] and not job["link"].startswith("http"):
23 job["link"] = "https://www.glassdoor.com" + job["link"]
24 all_jobs.append(job)
25 print(f"Page {page_num}: scraped {len(cards)} jobs")
26 # Pagination
27 next_btn = page.query_selector('[data-test="pagination-next"]')
28 if next_btn and page_num < max_pages:
29 next_btn.click()
30 time.sleep(random.uniform(3, 8))
31 page.wait_for_selector("[data-test='jobListing']")
32 else:
33 break
34 return all_jobsSave to CSV
1def save_to_csv(jobs, filename="glassdoor_jobs.csv"):
2 if not jobs:
3 print("No jobs to save.")
4 return
5 keys = jobs[0].keys()
6 with open(filename, "w", newline="", encoding="utf-8") as f:
7 writer = csv.DictWriter(f, fieldnames=keys)
8 writer.writeheader()
9 writer.writerows(jobs)
10 print(f"Saved {len(jobs)} jobs to {filename}")A note on pagination limits: Glassdoor caps search results at roughly 30 pages regardless of total count. If you need more coverage, use filters (location, job type, salary range) to narrow each search rather than trying to paginate past the cap.
In my testing, scraping 5 pages of job listings (about 75 jobs) took around 45 seconds with random delays. Doing the same manually would take at least 20 minutes of copy-pasting.
Step 4: Scrape Glassdoor Company Reviews
This is the section no other tutorial provides working code for. Reviews are where the real employer intelligence lives — sentiment analysis, culture signals, management red flags.
Navigate to the Reviews Page
Review URLs follow this pattern: /Reviews/{Company}-Reviews-E{id}.htm. You can find the employer ID by searching for a company on Glassdoor and checking the URL.
1def navigate_to_reviews(page, company_reviews_url):
2 page.goto(company_reviews_url)
3 page.add_style_tag(content="""
4 #HardsellOverlay, .LoginModal { display: none !important; }
5 body { overflow: auto !important; position: initial !important; }
6 """)
7 page.wait_for_selector('[data-test="review"]', timeout=15000)The Hidden BFF Endpoint (the Cleanest Path)
Here's the biggest finding from my research: Glassdoor reviews have a working internal JSON API that bypasses HTML parsing entirely. The documents this endpoint, and it's far more reliable than DOM scraping.
1import json, re, requests
2def get_review_ids(page):
3 """Extract employerId and dynamicProfileId from the reviews page HTML."""
4 html = page.content()
5 sel = Selector(text=html)
6 script_text = sel.xpath(
7 "//script[contains(text(), 'profileId')]/text()"
8 ).get("")
9 employer_match = re.search(r'"employer"\s*:\s*(\{[^}]+\})', script_text)
10 if employer_match:
11 meta = json.loads(employer_match.group(1))
12 return meta.get("id"), meta.get("profileId")
13 return None, None
14def fetch_reviews_bff(page, employer_id, profile_id, max_pages=5):
15 """Call Glassdoor's internal BFF endpoint for structured review data."""
16 all_reviews = []
17 cookies = {c["name"]: c["value"] for c in page.context.cookies()}
18 for pg in range(1, max_pages + 1):
19 payload = {
20 "applyDefaultCriteria": True,
21 "employerId": employer_id,
22 "dynamicProfileId": profile_id,
23 "employmentStatuses": ["REGULAR", "PART_TIME"],
24 "language": "eng",
25 "onlyCurrentEmployees": False,
26 "page": pg,
27 "pageSize": 10,
28 "sort": "DATE",
29 "textSearch": "",
30 }
31 resp = requests.post(
32 "https://www.glassdoor.com/bff/employer-profile-mono/employer-reviews",
33 json=payload,
34 cookies=cookies,
35 headers={"Content-Type": "application/json"},
36 )
37 if resp.status_code != 200:
38 print(f"BFF returned {resp.status_code} on page {pg}")
39 break
40 data = resp.json()
41 reviews = data.get("data", {}).get("employerReviews", {}).get("reviews", [])
42 total_pages = data.get("data", {}).get("employerReviews", {}).get("numberOfPages", 1)
43 for r in reviews:
44 all_reviews.append({
45 "title": r.get("summary", ""),
46 "rating": r.get("ratingOverall"),
47 "pros": r.get("pros", ""),
48 "cons": r.get("cons", ""),
49 "author_role": r.get("jobTitle", {}).get("text", ""),
50 "date": r.get("reviewDateTime", ""),
51 "recommend": r.get("isRecommend"),
52 })
53 print(f"Reviews page {pg}/{total_pages}: got {len(reviews)} reviews")
54 if pg >= total_pages:
55 break
56 time.sleep(random.uniform(3, 6))
57 return all_reviewsThe BFF endpoint gives you clean JSON with all review fields — no HTML parsing, no CSS selector breakage. You need session cookies from an authenticated Playwright context (covered in Step 6 below), and you need to extract the employerId and dynamicProfileId from the reviews page HTML first.
HTML Fallback Selectors for Reviews
If the BFF endpoint changes or you prefer DOM parsing, here are the stable data-test selectors:
| Field | Selector |
|---|---|
| Review container | [data-test="review"] |
| Headline | [data-test="review-title"] |
| Overall rating | [data-test="overall-rating"] |
| Pros | [data-test="pros"] |
| Cons | [data-test="cons"] |
| Date | [data-test="review-date"] |
| Author role | [data-test="author-jobTitle"] |
Step 5: Scrape Glassdoor Salary Data
Salary pages are fully login-gated. You must have an authenticated session (Step 6) before any of this code will return real data.
Navigate to the Salary Page
Salary URLs follow: /Salary/{Company}-Salaries-E{id}.htm, paginated as _P{n}.htm.
1def scrape_salaries(page, salary_url, max_pages=3):
2 all_salaries = []
3 for pg in range(1, max_pages + 1):
4 url = salary_url if pg == 1 else salary_url.replace(".htm", f"_P{pg}.htm")
5 page.goto(url)
6 page.add_style_tag(content="""
7 #HardsellOverlay { display: none !important; }
8 body { overflow: auto !important; position: initial !important; }
9 """)
10 time.sleep(random.uniform(3, 7))
11 html = page.content()
12 sel = Selector(text=html)
13 items = sel.css('[data-test="salary-item"]')
14 if not items:
15 print(f"Salary page {pg}: No items — possible login gate or block.")
16 break
17 for item in items:
18 salary = {
19 "job_title": item.css('[class*="SalaryItem_jobTitle__"]::text').get("").strip(),
20 "salary_range": item.css('[class*="SalaryItem_salaryRange__"]::text').get("").strip(),
21 "count": item.css('[class*="SalaryItem_salaryCount__"]::text').get("").strip(),
22 }
23 all_salaries.append(salary)
24 print(f"Salary page {pg}: scraped {len(items)} entries")
25 return all_salariesNotice the [class*="SalaryItem_jobTitle__"] prefix-match pattern. Glassdoor's salary page uses CSS-module-hashed class names (e.g., SalaryItem_jobTitle__XWGpT) where the hash suffix rotates on every deploy. The prefix stays stable — the hash doesn't. Never hardcode the full class name.
Step 6: Get Past Glassdoor's Login Wall
This is the critical piece that unlocks salary data and full review text. The approach: log in once manually in a visible browser, save the authenticated session state, then reuse it for all subsequent scraping runs.
Save Your Authenticated Session
Run this script once. It opens a Chrome window, navigates to Glassdoor's login page (which now redirects to Indeed Login), and waits for you to log in manually:
1import asyncio
2from pathlib import Path
3from patchright.async_api import async_playwright
4STATE_FILE = Path("glassdoor_state.json")
5async def login_and_save():
6 async with async_playwright() as p:
7 browser = await p.chromium.launch(headless=False, channel="chrome")
8 context = await browser.new_context(
9 viewport={"width": 1366, "height": 800},
10 locale="en-US",
11 )
12 page = await context.new_page()
13 await page.goto("https://www.glassdoor.com/profile/login_input.htm")
14 print("Log in in the browser window, then press Enter here...")
15 input()
16 await context.storage_state(path=str(STATE_FILE))
17 print(f"Session saved to {STATE_FILE}")
18 await browser.close()
19asyncio.run(login_and_save())After you log in and press Enter, Patchright saves all cookies and local storage to glassdoor_state.json. This file contains your gdId, GSESSIONID, cf_clearance, and auth tokens.
Reuse the Session for Scraping
Every subsequent scraping run loads the saved state — no manual login needed:
1async def scrape_with_auth(target_url):
2 async with async_playwright() as p:
3 browser = await p.chromium.launch(headless=True, channel="chrome")
4 context = await browser.new_context(
5 storage_state="glassdoor_state.json"
6 )
7 page = await context.new_page()
8 await page.goto(target_url)
9 await page.add_style_tag(
10 content="#HardsellOverlay{display:none!important}"
11 )
12 await page.wait_for_load_state("networkidle")
13 html = await page.content()
14 await browser.close()
15 return htmlThe saved session typically lasts 20–30 minutes of active use before Glassdoor re-challenges. For longer scraping runs, build in a check: if you get zero results from a page that should have data, re-run the login script to refresh your state file.
Detecting and Dismissing the Login Popup
For partially gated pages (job listings that show data but overlay a modal), the CSS injection approach from earlier steps works:
1page.add_style_tag(content="""
2 #HardsellOverlay, .LoginModal { display: none !important; }
3 body { overflow: auto !important; position: initial !important; }
4""")This only works when the HTML already contains the data underneath the overlay. For fully server-side-gated pages (salaries, deep review pages), the authenticated session from Step 6 is the only path.
Tips to Keep Your Glassdoor Scraper Running
Glassdoor updates its frontend frequently. Here's how to build resilience into your scraper.
Prefer data-test Attributes Over Class Names
Glassdoor randomizes CSS class names but tends to keep data-test attributes stable. Always prefer [data-test="jobListing"] over .jobCard_abc123. When data-test isn't available (as with salary field classes), use the prefix-match pattern: [class*="SalaryItem_jobTitle__"].
Rotate Proxies and Randomize Delays
Use rotating residential proxies — datacenter IPs get challenged almost immediately. Add random delays of 3–8 seconds between page loads (5–15 seconds for longer runs). Avoid scraping during US business hours if possible, when Cloudflare's behavioral detection is most aggressive.
Monitor for Breakage
Build a simple check into your scraper: if a page that should contain data returns zero extracted records, treat it as a selector failure (not an empty result set) and alert yourself. Run a small test scrape weekly to catch breakage early — Glassdoor deploys frontend changes without announcement.
Use the __NEXT_DATA__ Fast Path When Possible
Glassdoor is a Next.js + Apollo GraphQL app. Many pages ship a <script id="__NEXT_DATA__"> tag containing the full GraphQL cache as JSON. Parsing this is far more resilient than DOM scraping and :
1import json
2def extract_next_data(html):
3 sel = Selector(text=html)
4 raw = sel.css("script#__NEXT_DATA__::text").get()
5 if raw:
6 return json.loads(raw)["props"]["pageProps"].get("apolloCache", {})
7 return NoneThis returns the structured Apollo cache with all job, review, and salary fields — no CSS selectors needed. It's the most resilient extraction strategy available, since it's the same data that powers Glassdoor's React frontend.
Skip the Code: Scrape Glassdoor with Thunderbit (No Python Required)
Not everyone reading this is a developer. HR teams, recruiters, sales ops analysts, and market researchers need Glassdoor data too — and they shouldn't have to manage Playwright contexts and proxy rotation to get it.
is an AI Web Scraper Chrome Extension that can extract the same jobs, reviews, and salary data without writing a line of code. I work on the Thunderbit team, so I'll be upfront about that — but the reason I'm including it here is that it genuinely solves the two hardest problems in Glassdoor scraping.
How Thunderbit Works on Glassdoor
The workflow is two clicks:
- Open any Glassdoor page in Chrome (job search, company reviews, salary page)
- Click AI Suggest Fields in the Thunderbit sidebar — the AI reads the page DOM and proposes columns (job title, company, rating, salary range, pros, cons, etc.)
- Click Scrape — data is extracted into a table without CSS selectors or browser automation code
Thunderbit has a that extracts 23+ fields per company in a single run. For job listings, reviews, or salaries, the generic AI Suggest Fields workflow handles any Glassdoor URL.
Handling the Login Wall Without Code
This is Thunderbit's structural advantage for Glassdoor specifically. Browser Mode runs inside your own Chrome session — if you're logged into Glassdoor in Chrome, Thunderbit inherits those cookies automatically. The salary and review login wall that blocks server-side scrapers simply doesn't apply. No cookie management, no persistent contexts, no session code.
Subpage Scraping for Enrichment
Start from a list page (e.g., 30 companies from a search), let Thunderbit enumerate the rows, then enable to visit each company's review or salary page and enrich the table with full descriptions, review text, or salary details.
Export to Business Tools
Unlike Python scripts that output CSV or JSON, Thunderbit exports directly to Google Sheets, Airtable, Notion, or Excel — free on every plan. Particularly useful for teams who need to share and analyze data collaboratively.
Python vs. Thunderbit: When to Use Which
| Scenario | Recommended Approach |
|---|---|
| Building a recurring data pipeline | Python + Patchright |
| One-off research or small team project | Thunderbit |
| Need programmatic control over every field | Python |
| Non-developer who needs Glassdoor data today | Thunderbit |
| Scraping 1,000+ pages in a single run | Python + proxies |
| Scraping 30 companies with enrichment | Either works — Thunderbit is faster to set up |
Thunderbit pricing starts at free (6 pages/month), with the for 3,000 credits. At 1 credit per output row (2 credits for subpage scraping), that's enough for roughly 33 runs of 30 enriched companies per month.
Is It Legal to Scrape Glassdoor?
I'll keep this brief and factual. Glassdoor's explicitly prohibit automated scraping: "You may not use any robot, spider, scraper... to access the Services for any purpose without our express written permission."
The legal landscape, however, is more nuanced than a single ToS clause:
- (N.D. Cal., Jan 2024): The court held that if you never log in, you never agreed to the ToS, and public logged-off scraping doesn't violate it
- hiQ Labs v. LinkedIn (9th Cir.): The CFAA doesn't apply to automated collection of publicly accessible data — but fake accounts and logged-in scraping are a different story
- Van Buren v. United States (Supreme Court, 2021): Narrowed "exceeds authorized access" under the CFAA
The practical takeaway: scraping public job listings without logging in sits in a comparatively safer legal zone. Scraping with a logged-in session means you accepted the ToS at signup, and they explicitly prohibit it. This applies equally to Python scripts and Thunderbit's Browser Mode.
Ethical guidelines worth following regardless:
- Rate-limit well below human browsing speed
- Don't scrape or resell personally identifying reviewer information
- Respect robots.txt directives
- Pull only the fields you actually need
Conclusion: Which Method Is Right for You?
This guide covered all three Glassdoor data types — jobs, reviews, and salaries — with working 2025 code that accounts for the Indeed Login migration, Cloudflare Bot Management, and the CSS-module class name rotation that broke every older tutorial.
Here's the decision framework:
| Your Situation | Best Path |
|---|---|
| Developer building a data pipeline | Python + Patchright (follow the step-by-step above) |
| One-off research or recurring small pulls | Thunderbit (no code, browser-based) |
| Only need basic job listings at small scale | Check if Glassdoor API access is still available first (probably not) |
| Need salary or review data specifically | Must use Python scraping or Thunderbit — the API never covered these |
| Team of non-developers who need shared data | Thunderbit → export to Google Sheets |
Glassdoor's defenses will continue evolving. Selectors will break. New challenges will appear. Bookmark this guide — and if you want a deeper look at web scraping tools and techniques, check out our posts on , , and . You can also watch walkthroughs on the .
FAQs
1. Can you scrape Glassdoor without logging in?
Yes, for most job listing data and top-line company ratings. No, for full salary breakdowns or complete review text beyond the first few pages. The #HardsellOverlay is a CSS-only modal — the underlying HTML still contains first-page data — but deeper content is server-side gated behind Glassdoor's "give-to-get" wall.
2. What Python library works best for scraping Glassdoor in 2025?
Patchright (a stealth Playwright fork) is the default recommendation. It patches the Runtime.Enable CDP leak that vanilla Playwright has and that Cloudflare explicitly checks for. For listing pages that ship __NEXT_DATA__ in the initial HTML, curl_cffi with impersonate="chrome124" is 10–20x faster but can't handle login-gated pages.
3. How do I avoid getting blocked when scraping Glassdoor?
Use Patchright or rebrowser-playwright (not vanilla Playwright or Selenium). Rotate residential proxies — datacenter IPs get challenged immediately. Add random delays of 3–8 seconds between pages. Persist cookies (gdId, cf_clearance, GSESSIONID) across requests. Expect a 20–30 minute session window before re-challenge.
4. Is there a Glassdoor API I can use instead of scraping?
Effectively no. The legacy Partner API is , a public reviews endpoint never existed, and there's no migration path under Indeed's Publisher API. Scraping or a no-code tool like Thunderbit is the only practical option for reviews and salary data.
5. How often do Glassdoor scrapers break?
Frequently. Glassdoor deploys frontend changes without announcement, and CSS-module class name hashes rotate on every build. The most stable extraction strategies are: (1) data-test attribute selectors, (2) the __NEXT_DATA__ JSON blob, and (3) the internal BFF reviews endpoint. Build in a zero-results check and run a small test scrape weekly to catch breakage early.
Learn More