
Most eBay scraping tutorials have a shelf life of about three months. I know because our team at Thunderbit has watched developers cycle through broken code snippets, outdated CSS selectors, and "working" GitHub repos that quietly stopped working two eBay redesigns ago.
eBay sits on — the largest long-tail pricing dataset on the open web after Amazon. That data powers everything from reseller pricing to competitive intelligence. But getting at it programmatically is a moving target: eBay's React-based frontend churns CSS class names, A/B tests serve different DOM structures to different users, and Akamai Bot Manager sits between you and the HTML. This guide gives you Python code that works today, explains why scrapers break so you can build resilient ones, covers the eBay API vs. scraping decision honestly, and shows a no-code escape hatch for when Python isn't worth the setup.
What Does It Mean to Scrape eBay with Python?
Web scraping eBay with Python means writing scripts that programmatically download eBay web pages, parse the HTML (or hidden JSON), and extract structured data — titles, prices, seller info, sold dates, variant details — into a format you can actually use, like a CSV, spreadsheet, or database.
You can scrape several types of eBay pages:
- Search results (e.g., all "AirPods Pro" listings)
- Individual product detail pages (full specs, images, seller info)
- Sold/completed listings (actual transaction prices and dates)
- Seller profiles and reviews
Python is the go-to language for this work. Its ecosystem — Requests, BeautifulSoup, lxml, pandas — makes it straightforward to fetch pages, parse HTML, and wrangle data. There's a meaningful difference between scraping the website HTML and using eBay's official API, though — which I'll cover next.
Why Scrape eBay? Real-World Use Cases for Business Teams
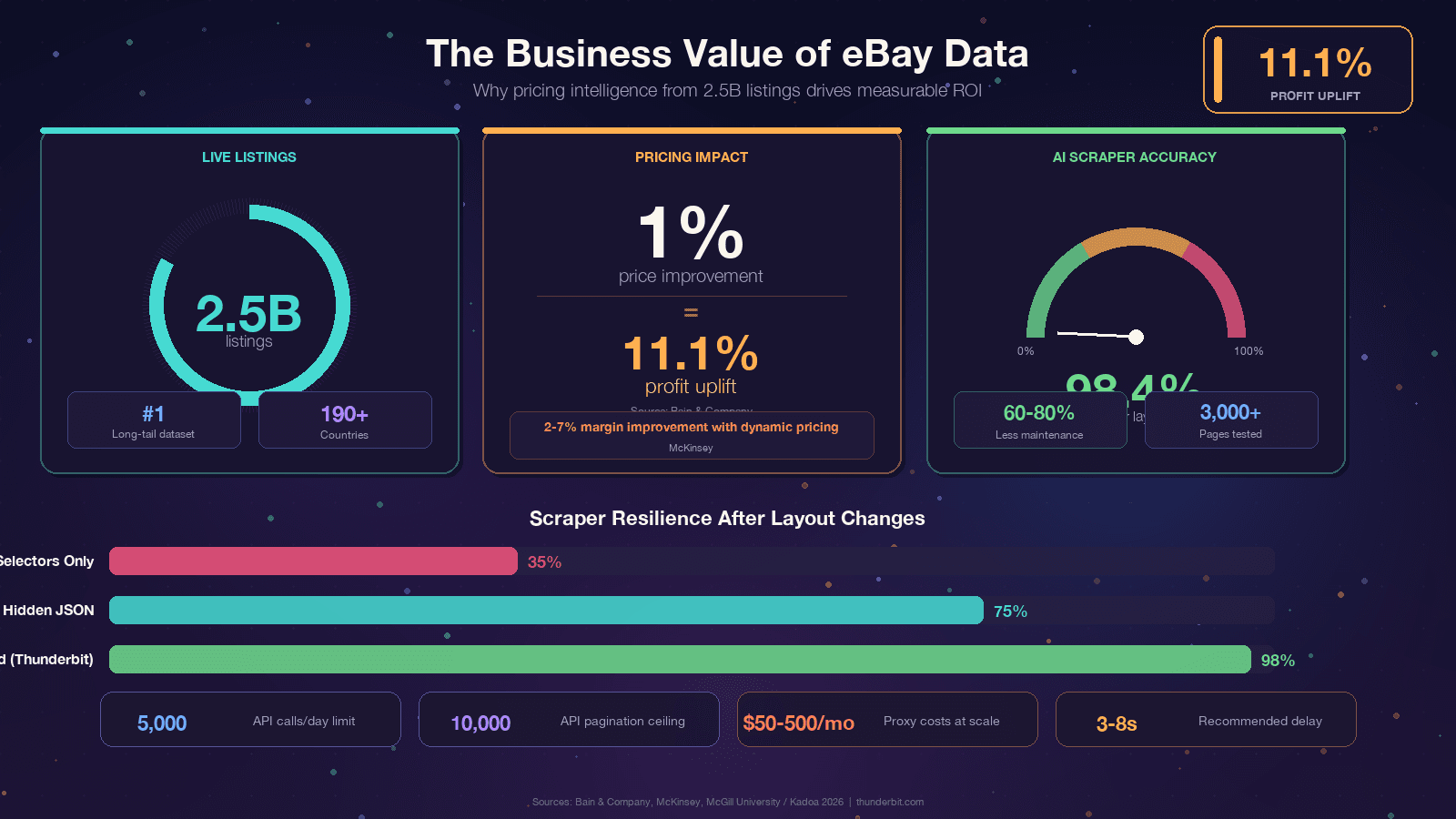
If you're reading this, you probably already have a reason. Still, grounding the discussion in concrete business value, because the ROI of eBay data is genuinely impressive. Bain found that a across thousands of businesses. McKinsey attributes to dynamic pricing in retail.
The use cases I see most often:
| Use Case | Data Needed | Business Outcome |
|---|---|---|
| Price monitoring & repricing | Active listing prices, shipping, condition | Competitive pricing, margin protection |
| Competitor analysis | Product assortments, promotions, shipping terms | Strategic positioning, assortment gaps |
| Market research & trend spotting | Listing velocity, category trends, demand patterns | New product identification, demand forecasting |
| Reseller pricing / appraisals | Sold prices, sold dates, condition | Fair market value, buy-box decisions |
| Sentiment analysis | Reviews, ratings, return policy | Product quality insights, customer satisfaction |
| Lead generation | Seller profiles, store info, contact details | B2B outreach to high-GMV sellers |
The common thread: eBay has the data, but it's locked in web pages.
Scraping is how you turn it into a competitive advantage.
eBay Official API vs. Python Web Scraping: Which Should You Choose?
This is the question I wish more tutorials answered honestly. eBay offers official APIs — primarily the — and many users wonder whether to use them or scrape directly. The answer depends entirely on what data you need.
| Criteria | eBay Browse/Finding API | Python Web Scraping |
|---|---|---|
| Sold/completed listings | Limited — Marketplace Insights API exists but access is commonly rejected | Full access via LH_Sold=1&LH_Complete=1 URL params |
| Rate limits | 5,000 calls/day on basic tier | Self-managed (proxy-dependent) |
| Data fields | Pre-defined (title, price, category, seller basics) | Anything visible on the page (reviews, full specs, variant matrix) |
| Setup complexity | OAuth 2.0, app registration, API keys | pip install + code |
| Stability | Stable endpoints | Breaks when HTML changes |
| Cost | Free tier available, paid for volume | Free code, but proxy costs at scale |
| Variant/MSKU data | Partial — parent SKU only in many cases | Full (via hidden JSON parsing) |
| Pagination depth | 10,000-item hard ceiling | Unlimited in theory |
A quick note: the old Finding API (which had findCompletedItems) was . If you're using ebaysdk-python or any library that hits the Finding module, it's broken in production right now.
My recommendation: Use the Browse API for stable, moderate-volume, structured catalog queries on active listings. Use Python scraping when you need sold prices, reviews, variant data, or any field the API doesn't expose. Many teams use both.
Tools and Libraries You Need to Scrape eBay with Python
Before we write any code, here's the toolkit. You don't need a headless browser for most eBay pages — the data is embedded in the server-rendered HTML.
| Library | Purpose |
|---|---|
requests or httpx | HTTP client to download eBay pages |
curl_cffi | HTTP client with real browser TLS fingerprinting (critical for bypassing Akamai) |
beautifulsoup4 | HTML parser for CSS selector extraction |
lxml | Fast parser backend for BeautifulSoup |
jmespath | Query language for parsing nested JSON blobs |
pandas | Data manipulation and CSV/Excel export |
gspread | Google Sheets integration |
Install everything in one line:
1pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspreadUse Python 3.11+ — pandas 3.0 requires 3.10+, and 3.11 gives you 10–60% speed gains on I/O-bound work.
One library deserves special mention: curl_cffi is the single most impactful upgrade a 2026 eBay scraper can make. eBay uses , and Akamai's primary detection vector is TLS fingerprinting. Plain requests emits a Python-shaped JA3 fingerprint that gets flagged instantly. curl_cffi impersonates a real Chrome browser's TLS handshake, which handles roughly 90% of Akamai-protected targets without needing a headless browser.
Step-by-Step: How to Scrape eBay Search Results with Python
This is the core tutorial. We'll scrape eBay search result pages for product listings.
- Difficulty: Beginner–Intermediate
- Time Required: ~30 minutes for first working scrape
- What You'll Need: Python 3.11+, the libraries above, a terminal, and a target eBay search URL
Step 1: Set Up Your Python Project
Create a project directory and install dependencies:
1mkdir ebay-scraper && cd ebay-scraper
2python -m venv venv
3source venv/bin/activate # Windows: venv\Scripts\activate
4pip install requests curl_cffi beautifulsoup4 lxml pandasCreate a file called scrape_ebay.py. That's your workspace.
Step 2: Build the eBay Search URL
eBay's search URL structure is straightforward. The key parameter is _nkw (keyword):
1import urllib.parse
2keyword = "airpods pro"
3base_url = "https://www.ebay.com/sch/i.html"
4params = {
5 "_nkw": keyword,
6 "_ipg": "120", # items per page: 60, 120, or 240 (240 can trigger bot flags)
7 "_pgn": "1", # page number
8}
9url = f"{base_url}?{urllib.parse.urlencode(params)}"
10print(url)
11# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1Other useful parameters:
LH_BIN=1— Buy It Now only_sacat=175673— specific category_sop=12— sort by best match (10 = price+shipping lowest, 13 = newly listed)LH_Complete=1&LH_Sold=1— sold/completed listings (covered in a dedicated section below)
Step 3: Send a Request and Handle the Response
This is where curl_cffi earns its keep. A plain requests.get() will often return a 403 from Akamai. With curl_cffi, we impersonate a real Chrome browser:
1from curl_cffi import requests as cffi_requests
2import random, time
3USER_AGENTS = [
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
7]
8HEADERS = {
9 "User-Agent": random.choice(USER_AGENTS),
10 "Accept-Language": "en-US,en;q=0.9",
11 "Accept-Encoding": "gzip, deflate, br",
12}
13def fetch_page(url, max_retries=5):
14 delay = 2
15 for attempt in range(max_retries):
16 try:
17 r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
18 if r.status_code == 200:
19 return r.text
20 if r.status_code in (403, 429, 503):
21 retry_after = r.headers.get("Retry-After")
22 sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
23 print(f" Status {r.status_code}, retrying in {sleep_for:.1f}s...")
24 time.sleep(sleep_for)
25 delay *= 2
26 continue
27 r.raise_for_status()
28 except Exception as e:
29 print(f" Request error: {e}, retrying...")
30 time.sleep(delay)
31 delay *= 2
32 raise RuntimeError(f"Failed after {max_retries} retries: {url}")The exponential backoff with jitter is important — fixed sleep intervals are themselves a bot fingerprint.
Step 4: Parse Product Listings from the Search Page
eBay is currently mid-migration between two search-result layouts. A resilient scraper must handle both:
| Field | Legacy Layout | New Layout |
|---|---|---|
| Card container | li.s-item | li.s-card or div.su-card-container |
| Title | .s-item__title | .s-card__title |
| URL | a.s-item__link[href] | a.su-link[href] |
| Price | span.s-item__price | .s-card__price |
The parsing code that handles both layouts:
1from bs4 import BeautifulSoup
2def parse_search_results(html):
3 soup = BeautifulSoup(html, "lxml")
4 cards = soup.select("li.s-item, li.s-card, div.su-card-container")
5 results = []
6 for card in cards:
7 # Title — try both layouts
8 title_el = card.select_one(".s-item__title, .s-card__title")
9 title = title_el.get_text(strip=True) if title_el else None
10 # Skip the phantom "Shop on eBay" placeholder card
11 if not title or "Shop on eBay" in title:
12 continue
13 # Price
14 price_el = card.select_one("span.s-item__price, .s-card__price")
15 price = price_el.get_text(strip=True) if price_el else None
16 # URL
17 link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
18 url = link_el["href"].split("?")[0] if link_el else None
19 # Image
20 img_el = card.select_one("img.s-item__image-img, .s-card__image img")
21 image = None
22 if img_el:
23 image = img_el.get("src") or img_el.get("data-src")
24 # Shipping
25 ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
26 shipping = ship_el.get_text(strip=True) if ship_el else None
27 results.append({
28 "title": title,
29 "price": price,
30 "url": url,
31 "image": image,
32 "shipping": shipping,
33 })
34 return resultsThat first-card phantom trap is a classic gotcha. The first li.s-item on many eBay search pages is a hidden placeholder with the title "Shop on eBay" and no real price. Always filter it out.
Step 5: Handle Pagination to Scrape Multiple Pages
eBay paginates via the _pgn parameter. The next-page link uses a.pagination__next:
1import urllib.parse
2def scrape_ebay_search(keyword, max_pages=5):
3 all_results = []
4 for page_num in range(1, max_pages + 1):
5 params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
6 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
7 print(f"Scraping page {page_num}: {url}")
8 html = fetch_page(url)
9 results = parse_search_results(html)
10 if not results:
11 print(f" No results on page {page_num}, stopping.")
12 break
13 all_results.extend(results)
14 print(f" Found {len(results)} listings (total: {len(all_results)})")
15 # Polite delay — 3 to 8 seconds with jitter
16 time.sleep(random.uniform(3, 8))
17 return all_resultsThe 3–8 second random jitter is not optional.
eBay's Akamai layer flags sustained >1 req/s from a single IP.
Step 6: Export Your Scraped Data to CSV or JSON
1import pandas as pd
2results = scrape_ebay_search("airpods pro", max_pages=3)
3df = pd.DataFrame(results)
4df.to_csv("ebay_airpods.csv", index=False)
5df.to_json("ebay_airpods.json", orient="records", indent=2)
6print(f"Exported {len(df)} listings to CSV and JSON.")You should now have a clean spreadsheet of eBay listings. On my machine, scraping 3 pages (360 listings) took about 45 seconds including delays.
How to Scrape eBay Product Detail Pages with Python
Search results give you a summary. Product detail pages have the good stuff: full descriptions, seller feedback scores, item specifics, image carousels, and variant data.
Parsing a Single Product Listing Page
eBay item pages live at /itm/<ITEM_ID>. The most stable extraction path is JSON-LD — eBay embeds a Product schema block that survives almost all CSS reshuffles:
1import json
2def parse_item_page(html):
3 soup = BeautifulSoup(html, "lxml")
4 item = {}
5 # 1. JSON-LD — most stable extraction path
6 for tag in soup.find_all("script", type="application/ld+json"):
7 try:
8 data = json.loads(tag.string or "")
9 except (json.JSONDecodeError, TypeError):
10 continue
11 if isinstance(data, dict) and data.get("@type") == "Product":
12 item["title"] = data.get("name")
13 item["brand"] = (data.get("brand") or {}).get("name")
14 item["images"] = data.get("image")
15 offers = data.get("offers") or {}
16 item["price"] = offers.get("price")
17 item["currency"] = offers.get("priceCurrency")
18 break
19 # 2. CSS fallbacks for fields not in JSON-LD
20 def first_text(selectors):
21 for sel in selectors:
22 el = soup.select_one(sel)
23 if el and el.get_text(strip=True):
24 return el.get_text(strip=True)
25 return None
26 item.setdefault("title", first_text([
27 "h1.x-item-title__mainTitle",
28 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
29 ]))
30 item["condition"] = first_text([
31 ".x-item-condition-text .ux-textspans",
32 ])
33 item["seller"] = first_text([
34 ".x-sellercard-atf__info__about-seller a .ux-textspans",
35 ])
36 item["shipping"] = first_text([
37 "div.ux-labels-values--shipping .ux-textspans--BOLD",
38 ])
39 # 3. Item specifics
40 specifics = {}
41 for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
42 k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
43 v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
44 if k and v:
45 specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
46 item["specifics"] = specifics
47 return itemThe pattern here — JSON-LD first, CSS fallbacks second — is the key to building scrapers that don't break every quarter. More on that below.
Scraping eBay Product Variants (MSKU Data)
Some eBay listings have multiple variants — different colors, sizes, storage capacities. The visible DOM only shows a price range like "$899 to $1,099" until the user clicks an option. The actual per-variant pricing lives in a hidden JavaScript object called MSKU.
This is one area where the eBay API only provides partial data (parent SKU), making scraping the better approach.
1import re, json
2def extract_variants(html):
3 # Non-greedy match is critical — greedy .+ swallows the entire page
4 m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
5 if not m:
6 return []
7 try:
8 msku = json.loads(m.group(1))
9 except json.JSONDecodeError:
10 return []
11 item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
12 skus = []
13 for combo_key, variation_id in msku.get("variationCombinations", {}).items():
14 option_ids = combo_key.split("_")
15 options = [item_labels.get(oid, oid) for oid in option_ids]
16 var = msku.get("variationsMap", {}).get(str(variation_id), {})
17 bin_model = var.get("binModel", {})
18 price_spans = bin_model.get("price", {}).get("textSpans", [{}])
19 price = price_spans[0].get("text") if price_spans else None
20 qty = var.get("quantity")
21 skus.append({
22 "options": options,
23 "price": price,
24 "quantity_available": qty,
25 "variation_id": variation_id,
26 })
27 return skusThat non-greedy (.+?) in the regex is where every eBay scraper gets tripped up. Greedy .+ swallows everything up to the last "QUANTITY" on the page, producing malformed JSON. I've seen this bug in at least three "working" tutorials.
How to Scrape eBay Sold and Completed Listings with Python
This is the use case that justifies scraping over the API. Sold-item data — what actually transacted, at what price, on what date — is the gold standard for market research, reseller pricing, and appraisals. The eBay Browse API explicitly does not provide this. The technically does, but access is a "Limited Release" that's .
The URL parameters you need are LH_Complete=1 (completed listings) and LH_Sold=1 (restrict to actually sold). You must pass both. Passing LH_Sold=1 alone silently falls back to active listings on some categories — this is the #1 community pitfall.
1def scrape_sold_listings(keyword, max_pages=3):
2 all_sold = []
3 for page_num in range(1, max_pages + 1):
4 params = {
5 "_nkw": keyword,
6 "_ipg": "120",
7 "_pgn": str(page_num),
8 "LH_Complete": "1",
9 "LH_Sold": "1",
10 }
11 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
12 print(f"Scraping sold page {page_num}...")
13 html = fetch_page(url)
14 soup = BeautifulSoup(html, "lxml")
15 cards = soup.select("li.s-item")
16 for card in cards:
17 title_el = card.select_one(".s-item__title")
18 title = title_el.get_text(strip=True) if title_el else None
19 if not title or "Shop on eBay" in title:
20 continue
21 # Only include actually sold items (green POSITIVE price)
22 sold_tag = card.select_one(
23 ".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
24 )
25 if sold_tag is None:
26 continue # Unsold completed listing — skip
27 price_el = card.select_one("span.s-item__price")
28 price = price_el.get_text(strip=True) if price_el else None
29 # Parse sold date
30 sold_date = None
31 import re, datetime as dt
32 card_text = card.get_text()
33 m = re.search(r"Sold\s+([A-Z][a-z]{2}\s+\d{1,2},\s*\d{4})", card_text)
34 if m:
35 sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
36 link_el = card.select_one("a.s-item__link[href]")
37 url = link_el["href"].split("?")[0] if link_el else None
38 all_sold.append({
39 "title": title,
40 "sold_price": price,
41 "sold_date": sold_date,
42 "url": url,
43 })
44 if not cards:
45 break
46 time.sleep(random.uniform(3, 8))
47 return all_soldThe key difference in the HTML: sold items show the price in green (inside a .POSITIVE wrapper), while unsold completed listings show the price in red strikethrough. Always filter on that .POSITIVE class.
Why eBay Scrapers Break (And How to Build Resilient Ones)
If your eBay scraper stopped working, you're in good company. This is the #1 pain point in every eBay scraping forum thread I've read. The question isn't if your scraper will break — it's when.
Why it happens:
- eBay uses React-based rendering with dynamically generated class names that change on deploys
- A/B tests serve different DOM structures to different users (the dual
s-item/s-cardlayout is a live example right now) - Periodic site redesigns change HTML nesting, even when the data stays the same
- Old selectors like
#itemTitleand#prcIsumwere removed years ago but still appear in tutorials
As puts it: "The real challenge with eBay web scraping is handling eBay's CSS selector changes. eBay updates their frontend regularly, breaking scrapers that rely on specific class names."
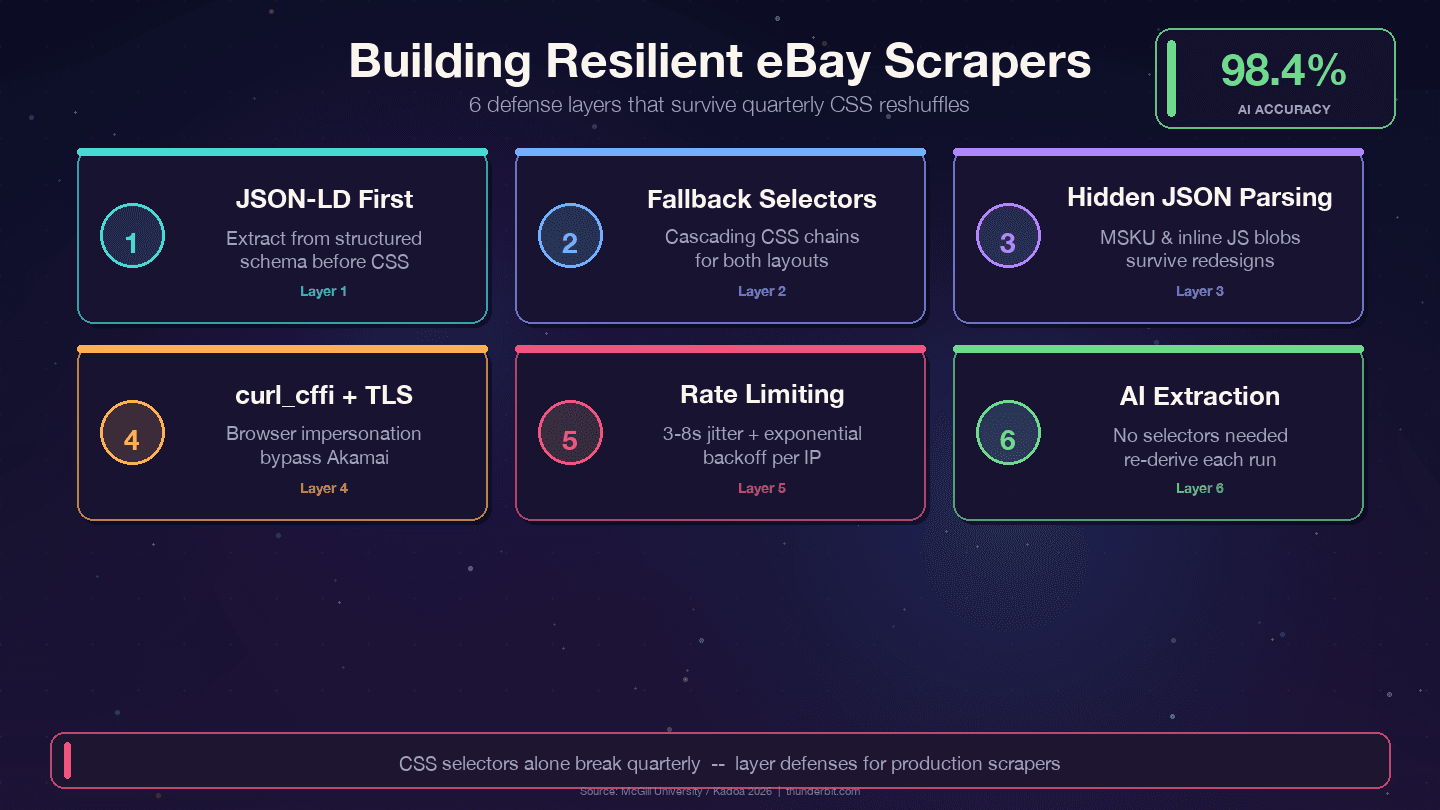
Defense Strategies for Long-Lasting eBay Scrapers
Four strategies that survive eBay's quarterly reshuffles:
1. Prioritize JSON-LD over CSS selectors. eBay embeds structured Product schema data in every item page. The data layer changes far less than the presentation layer — designers refactor CSS classes every quarter, but backend field names like price, name, and seller map to internal APIs and rarely rename.
2. Use cascading fallback selectors. Never rely on a single CSS selector. Always provide alternatives:
1def first_text(soup, selectors):
2 for sel in selectors:
3 el = soup.select_one(sel)
4 if el and el.get_text(strip=True):
5 return el.get_text(strip=True)
6 return None
7title = first_text(soup, [
8 "h1.x-item-title__mainTitle",
9 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
10 "[data-testid='x-item-title'] h1",
11])3. Parse hidden JSON blobs. The MSKU variant object and inline JavaScript data survive CSS changes because they're generated server-side. Regex extraction from <script> tags is more work upfront but dramatically reduces maintenance.
4. Log selector failures. Add monitoring so you know when a selector stops matching, not just that your data is empty:
1if title is None:
2 print(f"WARNING: title selector failed for {url}")5. Use curl_cffi with browser impersonation. This handles Akamai's TLS fingerprinting without a headless browser.
The AI-Powered Alternative: No Selector Maintenance
If you're tired of patching selectors every few months, there's a fundamentally different approach. Tools like use AI to read the page fresh each time and derive the extraction logic on the fly. A McGill University study tested AI vs. selector-based scrapers across 3,000 pages and found , with industry benchmarks citing .
| Approach | Breaks when eBay changes HTML? | Maintenance effort |
|---|---|---|
| Hardcoded CSS selectors | Yes, quarterly | High — ongoing patches |
| Hidden JSON / JSON-LD extraction | Rarely | Low |
| AI-based scraping (Thunderbit) | No — AI re-derives selectors each run | None |
I'll cover the Thunderbit workflow in detail later. For now, the takeaway: if you're building a scraper you plan to run for months, invest in JSON-first extraction and fallback selectors. If you don't want to maintain selectors at all, the AI approach is worth a look.
Automating Recurring eBay Scrapes for Price Monitoring
A one-time scrape is useful. But price monitoring, stock tracking, and competitor analysis require recurring data collection. Every competitor article I've read mentions price monitoring as a use case, but almost none show how to actually automate it.
Option 1: Cron Jobs (Linux/macOS) or Task Scheduler (Windows)
The simplest approach. Wrap your Python script in a cron job. Always use the absolute path to your venv's Python — cron runs with a minimal environment:
1crontab -e
2# Daily at 08:15
315 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1On Windows, use PowerShell:
1$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
2$T = New-ScheduledTaskTrigger -Daily -At 8:15am
3Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $TThis requires an always-on machine, and you manage proxies and anti-bot measures yourself.
Option 2: Cloud Functions (Serverless)
AWS Lambda or Google Cloud Functions let you run scrapers without a dedicated server. Higher setup effort — you need to package dependencies, handle timeouts (Lambda caps at 15 minutes), and still manage proxies. But no server maintenance.
Option 3: No-Code Scheduling with Thunderbit
Scheduled Scraper feature lets you describe the interval in plain language (e.g., "every day at 8am"), input eBay URLs, and click Schedule. It runs in the cloud with built-in anti-bot handling.
| Approach | Setup Effort | Needs Server? | Handles Anti-Bot? |
|---|---|---|---|
| Cron + Python script | Medium | Yes (always-on machine) | You manage proxies |
| Cloud function (Lambda) | High | No (serverless) | You manage proxies |
| Thunderbit Scheduled Scraper | Low (describe in words) | No (cloud-based) | Built-in |
For storing recurring scrape data, a local SQLite database is the right answer for price history. Use ON CONFLICT ... DO UPDATE (not INSERT OR REPLACE, which ):
1CREATE TABLE IF NOT EXISTS listings (
2 item_id TEXT PRIMARY KEY,
3 title TEXT NOT NULL,
4 price REAL,
5 last_price REAL,
6 first_seen_at TEXT DEFAULT (datetime('now')),
7 last_seen_at TEXT DEFAULT (datetime('now'))
8);
9CREATE TABLE IF NOT EXISTS price_history (
10 item_id TEXT NOT NULL,
11 observed_at TEXT NOT NULL DEFAULT (datetime('now')),
12 price REAL NOT NULL,
13 PRIMARY KEY (item_id, observed_at)
14);Don't Want to Code? How to Scrape eBay in 2 Minutes with Thunderbit
I've spent 2,000 words on Python code. Now I want to be honest about when you don't need it.
If you're a business user doing one-off market research, a reseller checking comps, or an ecommerce team that needs data today without a dev sprint, Python is overkill. The setup, the selector maintenance, the proxy management — it's a lot of overhead for "I just need these 200 listings in a spreadsheet."
How Thunderbit Scrapes eBay (Step by Step)
- Install the — no credit card required.
- Navigate to any eBay search results or product page in Chrome.
- Click "AI Suggest Fields" in the Thunderbit sidebar. The AI reads the page and proposes columns: Title, Price, Condition, Shipping, Seller, Rating.
- Click "Scrape." The extension walks through pagination and fills the data table. For eBay specifically, Thunderbit has that work in one click.
- Export to Google Sheets, Airtable, Notion, CSV, JSON, or Excel — for free.
The whole process takes under 2 minutes.
I timed it.
Subpage Enrichment: Get Detail-Page Data Without Extra Code
After scraping a search results page, Thunderbit can visit each listing's detail page and append additional fields — full specs, seller info, description, all images. This replaces the 20+ lines of Python subpage-scraping code we wrote earlier with a single click.
When to Still Use Python
Python wins when you need:
- Large-scale scraping (tens of thousands of pages per run)
- Deeply customized parsing logic or data transformation
- Integration into existing data pipelines (Airflow, dbt, Kafka)
- Fine-grained TLS/session control for advanced anti-bot work
- Unit economics — at millions of rows, a maintained stack beats credit-based SaaS
For most one-off or mid-scale projects, Thunderbit is faster and easier. For production pipelines at scale, Python gives you full control.
Tips to Avoid Getting Blocked When You Scrape eBay with Python
eBay's Akamai layer is real. What actually works in practice:
- Use
curl_cffiwithimpersonate="chrome124"— this is the biggest single improvement over plainrequests - Rotate User-Agent strings from a list of current browser versions (Chrome 143, Firefox 124, Safari 26)
- Add random delays of — fixed intervals are a fingerprint
- Use residential or rotating proxies for anything beyond a few dozen pages. Datacenter IPs (AWS, GCP, DigitalOcean) get flagged quickly by Akamai.
- Respect
robots.txt— most filtered browse URLs are explicitly Disallowed; item-detail pages (/itm/<id>) are not - Handle CAPTCHAs gracefully — detect them and retry with a different IP, or use a CAPTCHA-solving service
- Don't hammer the server. The precedent says trespass to chattels applies when scraping actually degrades servers. Staying at 1 req/s per IP keeps you far from that threshold.
For high-volume commercial use, consider using the Browse API for active listings and targeted scraping only for sold comps and data the API doesn't expose. That hybrid approach is cleaner both technically and legally.
Is It Legal to Scrape eBay with Python?
I'm not a lawyer, and this blog post isn't legal advice. So I'll keep this brief.
The legal landscape has shifted in favor of scraping publicly available data. The key precedents:
- (9th Cir., 2022): scraping publicly accessible data doesn't violate the CFAA
- Van Buren v. United States (SCOTUS, 2021): narrowed the CFAA's "exceeds authorized access" provision
- (N.D. Cal., 2024): logged-out scraping doesn't breach platform TOS because the scraper isn't a "user"
That said, eBay's explicitly prohibits "buy-for-me agents, LLM-driven bots, or any end-to-end flow that attempts to place orders without human review." The line is clear: read-only scraping of public pages is on solid ground; automating checkout is not.
Best practices: scrape only publicly visible data. Don't create fake accounts or bypass login walls. Don't resell copyrighted listing images wholesale. And consult legal counsel for commercial-scale projects.
Conclusion and Key Takeaways
Python is the most flexible way to scrape eBay, but it requires ongoing maintenance as the site's HTML changes. The decision framework:
- Use the eBay Browse API for stable, moderate-volume, structured queries on active listings
- Use Python scraping for sold listings, reviews, variant data, and anything the API doesn't expose
- Use if you want eBay data without writing or maintaining code
The code in this guide prioritizes resilience: JSON-LD extraction first, cascading CSS fallbacks second, hidden JSON parsing for variants. That layered approach means your scraper won't die the next time eBay's frontend team ships a redesign.
If you want to try the no-code route, lets you test it on eBay pages right now. And if you want to see how the works, it's one click away.
For more on web scraping tools, check out our guides on , , and . You can also watch tutorials on the .
FAQs
1. Can I scrape eBay for free with Python?
Yes. All the libraries (Requests, BeautifulSoup, curl_cffi, pandas) are free and open source. The costs come at scale — residential proxies for high-volume scraping typically run $50–500/month depending on bandwidth. For small projects (a few hundred pages), you can scrape from your home IP with careful rate limiting.
2. How do I scrape eBay sold items and completed listings with Python?
Add LH_Complete=1&LH_Sold=1 to your search URL parameters. You must pass both — LH_Sold=1 alone silently falls back to active listings on some categories. Filter results by checking for the .POSITIVE CSS class on the price element, which indicates an actual sale rather than an unsold expired listing.
3. Does eBay block web scraping?
eBay uses Akamai Bot Manager, which detects scrapers primarily through TLS fingerprinting and behavioral analysis. Plain requests calls often get 403 responses. Using curl_cffi with browser impersonation, rotating User-Agents, and adding 3–8 second random delays between requests handles most blocking. Residential proxies help at scale.
4. Should I use the eBay API or web scraping?
Use the Browse API for stable, moderate-volume queries on active listings (up to 5,000 calls/day). Use scraping when you need sold-price history, full variant/MSKU data, reviews, or any field the API doesn't expose. The Marketplace Insights API technically provides sold data, but access is restricted and .
5. What's the easiest way to scrape eBay without coding?
The uses AI to read eBay pages, suggest data columns, and extract listings with one click. It handles pagination, subpage enrichment, and exports to Google Sheets, Excel, Airtable, or Notion. Pre-built make it even faster for common use cases.
Learn More