
Executive Summary
The asked a policy question: how many of the world's most-visited websites are telling AI crawlers what they can and cannot do?
This follow-up asks the operational question behind it: how reliable is robots.txt as the infrastructure now being asked to carry that policy?
The answer is uncomfortable. robots.txt still works because it is public, cheap, machine-readable, and already understood by crawlers. It is also being asked to do far more than it was built for. In 2026, the same plain-text file may contain SEO crawl controls, sitemap indexes, legacy search-engine extensions, AI training opt-outs, Cloudflare-injected policy vocabulary, copyright reservations, and legal language aimed at future disputes.
That is configuration debt.
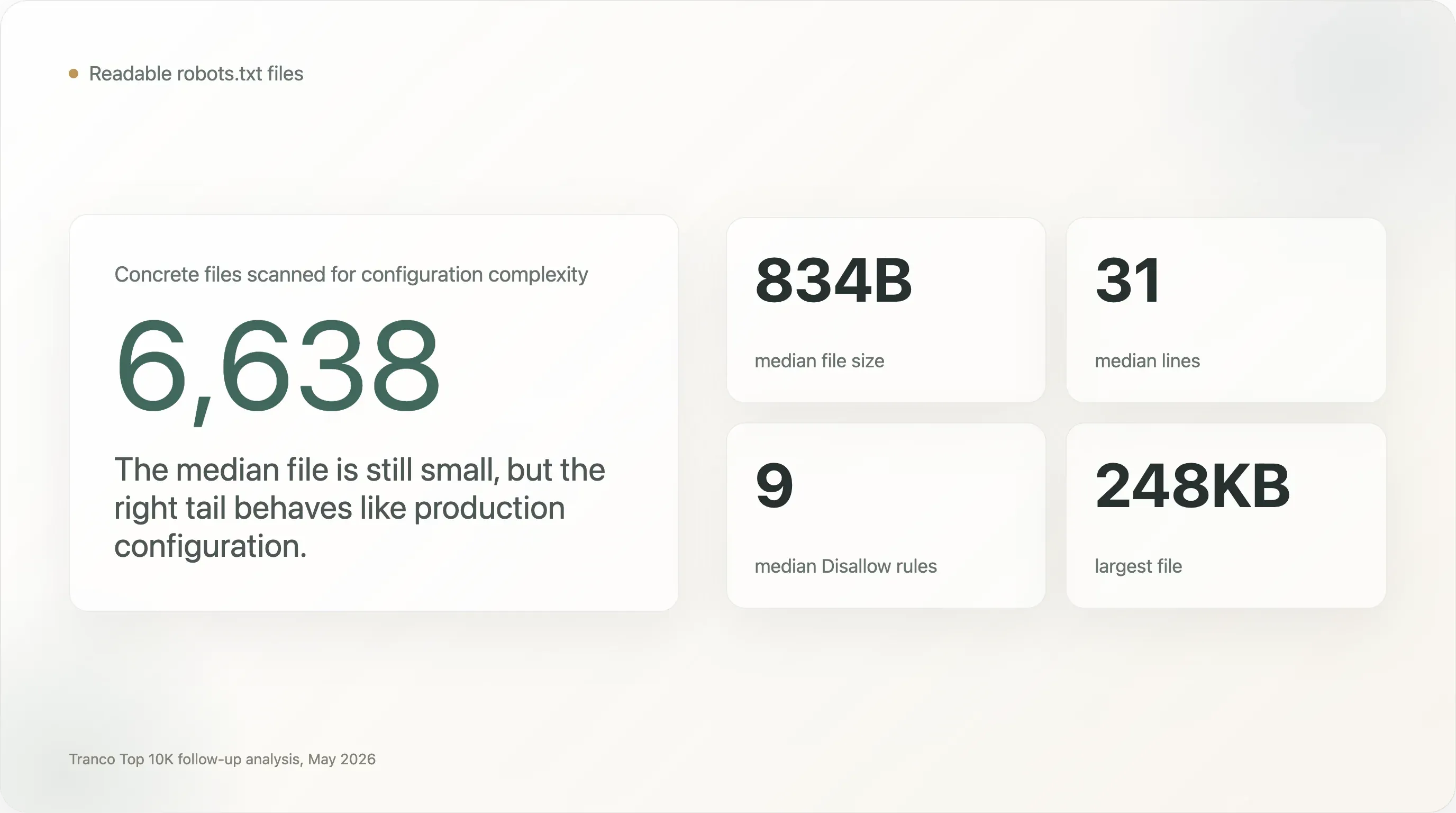
The dataset behind this report is the same Tranco Top 10,000 crawl used in the original AI crawler study. Of the 10,000 domains, 6,638 returned a readable robots.txt; another 610 returned 404, which is treated by the protocol as implicit allow. This gives 7,248 analyzable sites for bot-access decisions and 6,638 concrete files for configuration-complexity analysis.
Six findings stand out:
-
Most
robots.txtfiles are tiny, but the right tail is extremely complex. The median file is only 834 bytes and 31 lines. But 1,005 files are at least 5 KB, 273 are at least 20 KB, and 28 are at least 100 KB. The largest file in the sample is 248 KB. -
Hundreds of top websites run files that are closer to production configuration than policy notes. The median file has 9
Disallowdirectives. But 707 sites have at least 100Disallowrules, 13 have at least 1,000, 240 name at least 50 user agents, and 110 name at least 100 user agents. -
Protocol drift is not theoretical. Among the 6,638 readable files, 685 contain
Crawl-delay, 303 containHost, 200 containClean-param, 9 containRequest-rate, 5 containVisit-time, and 271 contain Cloudflare-styleContent-Signallanguage. These are not all part of the same clean standard. They are accumulated crawler folklore. -
Googlebot is treated as a special citizen. 562 analyzable domains block at least one traditional search crawler. In 404 of those cases, Googlebot is allowed while at least one other search crawler is blocked. AI crawler discrimination did not appear in a neutral ecosystem;
robots.txtalready encoded search-engine hierarchy. -
AI policy makes the debt more visible. 1,377 readable files contain AI-policy language; 719 contain copyright, terms, licensing, or permission language; and 501 contain both. The file has become both machine interface and legal artifact. That is useful, but fragile.
-
The riskiest files are not always the most anti-AI files. Ecommerce, travel, social, finance, academia, and news all produce complex files for different reasons: crawl-budget control, legacy paths, user-generated content, rights reservations, and bot-specific exceptions. AI rules are being layered onto an already messy base.
The main conclusion: robots.txt remains the public web's most important crawler-policy surface, but it is a weak foundation for high-stakes AI governance unless the ecosystem standardizes crawler identity, AI-use vocabulary, and policy auditability.
Methodology
This report reuses the dataset from the original Thunderbit analysis of AI crawler policy on the Tranco Top 10,000 domains.
The input materials were:
tranco_top10k.csv— the original Tranco Top 10K domain list.out/fetch_meta.csv— fetch status, byte count, scheme, redirect outcome, and error metadata.out/sites.csv— domain, rank, category, language, androbots.txtstatus.out/site_meta.csv— one analytical row per site, including template class, AI-blocking flags, file size, and bot-policy summary fields.out/bot_status.csv— one row per domain and crawler, including whether that bot is blocked and whether a specific rule exists.raw_robots/— cachedrobots.txtbodies for the 6,638 sites that returned status200.
For this follow-up, each readable robots.txt file was scanned for:
- file size and line count;
- active non-comment lines;
User-agent,Disallow,Allow, andSitemapdirective counts;- legacy or non-core directives such as
Crawl-delay,Host,Clean-param,Request-rate, andVisit-time; - AI-era vocabulary including
Content-Signal,llms.txt, AI, LLM, machine learning, TDM, and2019/790; - legal vocabulary such as copyright, terms of service, licensing, permission, and rights-reservation language;
- search-crawler treatment for Googlebot, Bingbot, DuckDuckBot, Slurp, Baiduspider, and YandexBot.
The report also defines a simple configuration debt score for triage. It combines file size, user-agent count, Disallow count, Allow count, non-standard directive count, and the mixture of AI-policy and legal language. The score is not intended as a universal measure of correctness. It is a way to identify files that are likely to be hard to maintain, review, or reason about.
All derived tables and charts are included in the delivery folder.
Finding 1: The Median File Is Simple; the Tail Is Not
The typical robots.txt file on the top web is still small.
Across the 6,638 readable files:
| Metric | Median | P90 | P95 | P99 | Max |
|---|---|---|---|---|---|
| File size | 834 bytes | 6.7 KB | 15.8 KB | 76.0 KB | 248.3 KB |
| Lines | 31 | 238 | 332 | 1,008 | 4,998 |
| Active lines | 23 | 198 | 282 | 837 | 4,998 |
User-agent directives | 1 | 21 | 39 | 137 | 823 |
Disallow directives | 9 | 103 | 176 | 422 | 4,997 |
Allow directives | 1 | 17 | 33 | 69 | 890 |
This distribution matters because robots.txt is often discussed as if it were a small declaration:
1User-agent: *
2Disallow: /private/That mental model is wrong for a meaningful minority of the high-traffic web.
In this dataset:
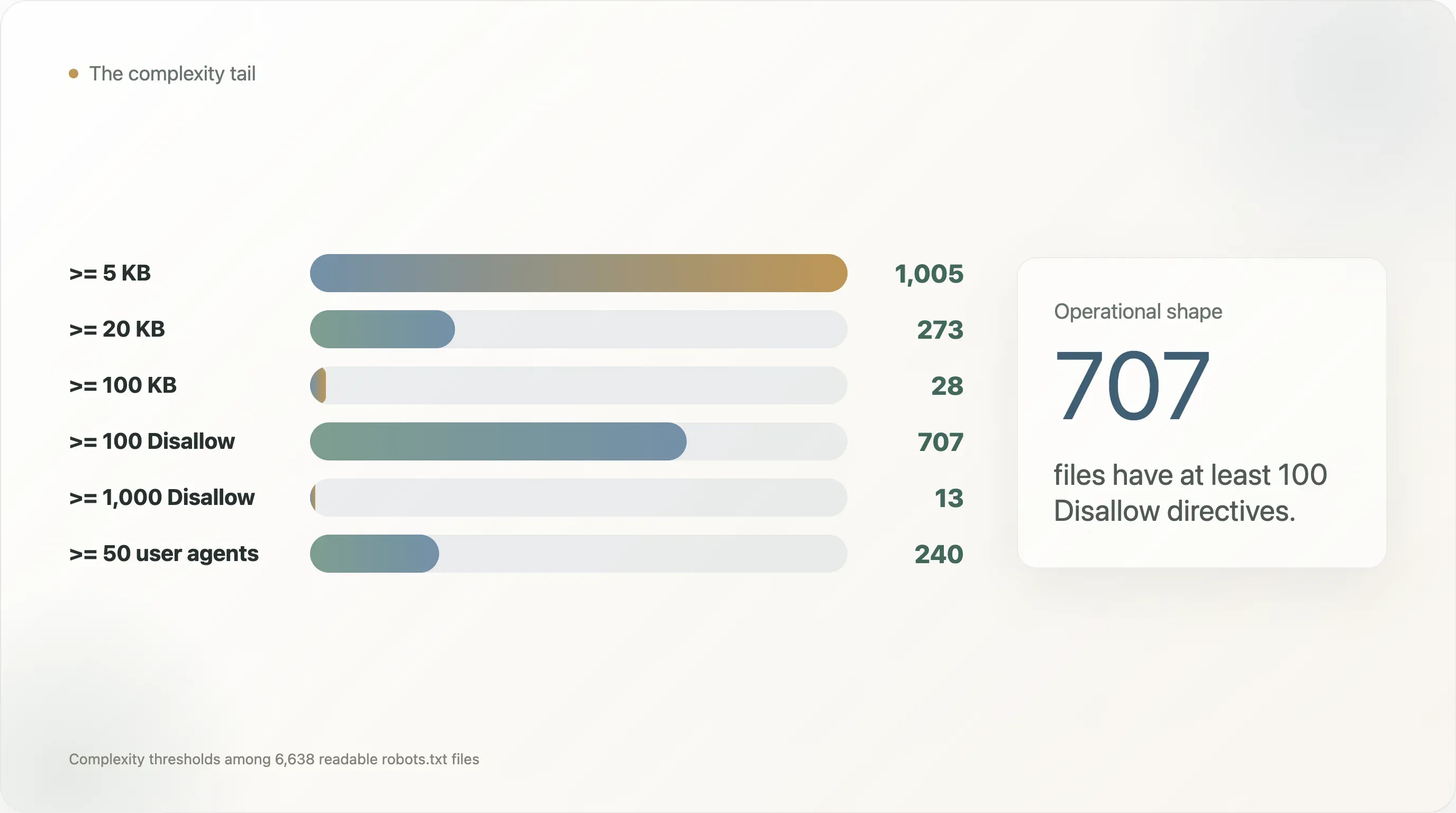
| Complexity threshold | Sites |
|---|---|
robots.txt larger than or equal to 5 KB | 1,005 |
| Larger than or equal to 20 KB | 273 |
| Larger than or equal to 100 KB | 28 |
At least 50 User-agent directives | 240 |
At least 100 User-agent directives | 110 |
At least 100 Disallow directives | 707 |
At least 1,000 Disallow directives | 13 |
At least 100 Allow directives | 40 |
The largest and most complex files are not academic curiosities. They belong to real, high-traffic properties:
| Domain | Rank | Category | Bytes | User-agent | Disallow | Allow |
|---|---|---|---|---|---|---|
linkedin.com | 17 | social | 114,341 | 76 | 4,184 | 281 |
runescape.com | 5,226 | unknown | 113,393 | 1 | 4,997 | 0 |
academia.edu | 832 | academia | 57,384 | 63 | 2,044 | 227 |
etsy.com | 286 | ecommerce | 51,320 | 3 | 1,621 | 120 |
thepaper.cn | 9,395 | news | 56,867 | 1 | 1,496 | 0 |
opentable.com | 4,137 | unknown | 70,494 | 32 | 1,683 | 176 |
alfabank.ru | 2,625 | finance | 73,158 | 2 | 1,566 | 133 |
These files are closer to production routing tables than policy slogans. They encode years of product launches, legacy paths, blocked parameter patterns, crawler exceptions, SEO experiments, CDN decisions, and now AI-crawler rules.
The tail is not only an AI story. Of the 273 files at or above 20 KB, 131 contain AI-policy language and 142 do not. Of the 707 files with at least 100 Disallow directives, only 207 contain AI-policy language. In other words, AI did not create the large-file problem. It arrived after years of ordinary web operations had already filled the file with path rules, sitemap references, and crawler exceptions.
That matters because maintainability depends on shape, not just intent. A small file with a direct AI block can be easy to audit. A 70 KB ecommerce or travel file can be hard to audit even if it says nothing about AI. The risk is not that every large file is wrong. The risk is that the effective policy becomes too hard for the people responsible for it to verify.
The operational risk is straightforward: as robots.txt grows, it becomes harder for a publisher, platform engineer, lawyer, or SEO lead to answer the basic question: what does this file actually permit?
That question is no longer trivial. Under RFC-style parsing, a crawler may match a more specific user-agent group instead of User-agent: *; longer path matches may override shorter ones; Allow and Disallow directives interact by precedence; and generic deny-all rules can accidentally capture new crawlers that did not exist when the file was written.
For a 30-line file, a human can reason about that. For a 4,000-line file with dozens of named bots, nobody should.
Finding 2: robots.txt Is Carrying More Than Crawl Rules
The AI-crawler debate made robots.txt politically visible, but the underlying file had already been accumulating unrelated responsibilities.
A modern top-site robots.txt can include:
- crawler path controls;
- sitemap discovery;
- search-engine-specific extensions;
- crawl-rate hints;
- host canonicalization hints;
- URL-parameter cleanup hints;
- CDN-injected policy vocabulary;
- copyright reservation text;
- AI training opt-outs;
- human-readable legal commentary.
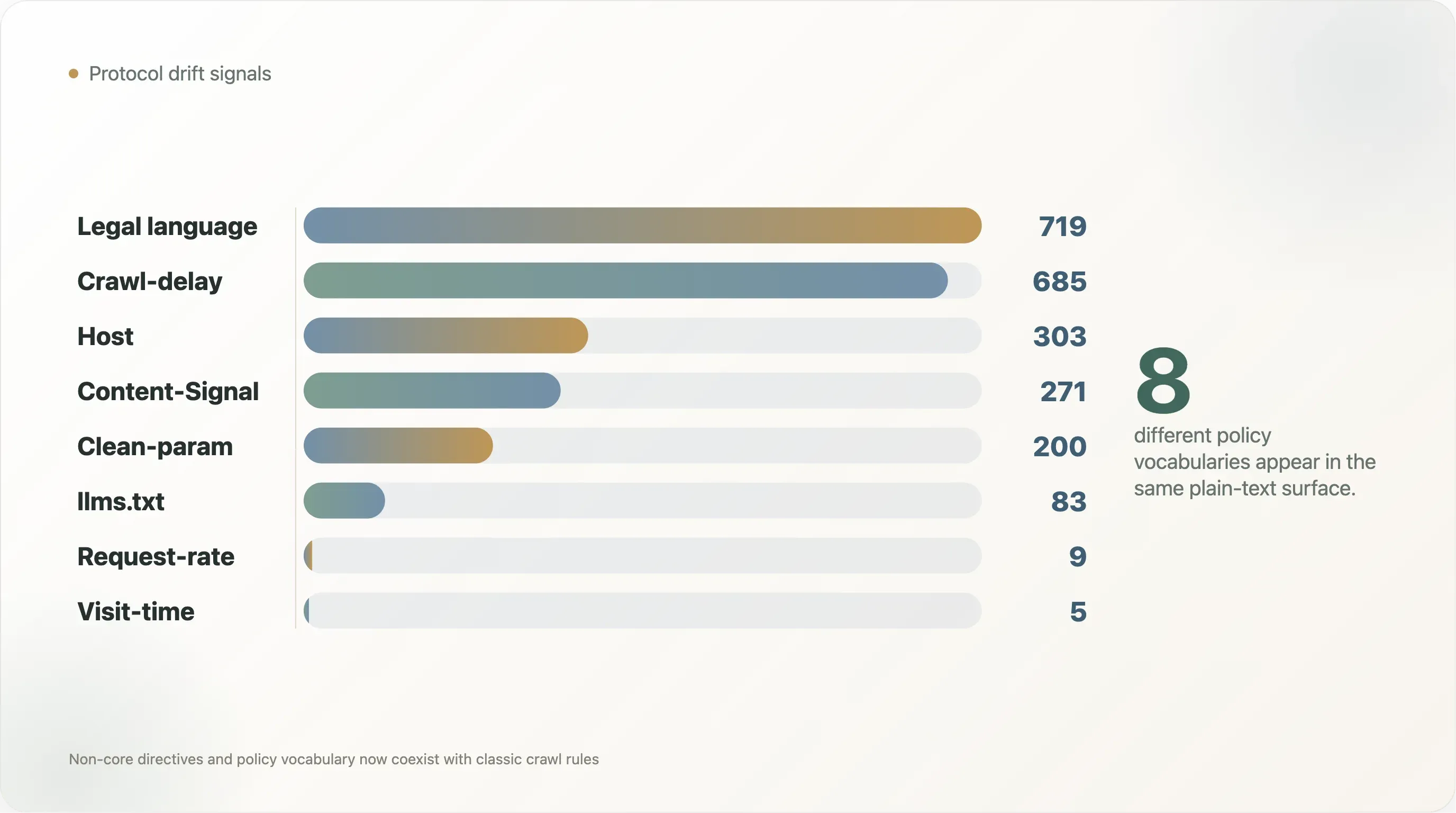
The dataset shows this layering clearly.
| Signal | Files | Share of readable files |
|---|---|---|
Crawl-delay | 685 | 10.3% |
Host | 303 | 4.6% |
Clean-param | 200 | 3.0% |
Content-Signal | 271 | 4.1% |
Request-rate | 9 | 0.1% |
Visit-time | 5 | 0.1% |
llms.txt mention | 83 | 1.3% |
| Copyright, terms, licensing, or permission language | 719 | 10.8% |
| AI-policy language | 1,377 | 20.7% |
Some of these directives are widely recognized by specific crawlers. Some are legacy conventions. Some are vendor-specific. Some are not really crawler directives at all, but legal or product language embedded in comments.
That is what protocol drift looks like.
Crawl-delay is a useful example. It is familiar to many site operators, but support is uneven across major crawlers. Host and Clean-param have historically been associated with Yandex behavior. Content-Signal is part of Cloudflare's AI-era policy vocabulary. llms.txt is a proposed adjacent discovery format, not a universally honored standard. Yet all of these appear in the same kind of file, often beside classic User-agent and Disallow rules.
The numbers also show how old and new conventions now coexist. Crawl-delay appears in 685 files, more than twice the 271 files with Content-Signal. Host appears in 303 files and Clean-param in 200, mostly reflecting search-era conventions. llms.txt, despite heavy discussion in AI-search circles, is mentioned in only 83 readable files. The live web is not converging on one vocabulary. It is stacking vocabularies.
The problem is not that any single extension is wrong. The problem is that the file has become an unversioned container for several overlapping governance systems.
That creates three kinds of debt:
- Semantic debt. Different crawlers may interpret the same file differently.
- Ownership debt. SEO, legal, infrastructure, security, and product teams may all have reasons to edit the file, but no single team may own the whole policy.
- Audit debt. A site can publish a policy that looks intentional while only a parser can determine its effective behavior.
AI makes this more important because the stakes have changed. When a legacy crawl-rate hint is ignored, the result may be extra traffic. When an AI training opt-out is ambiguous, the result may become evidence in a copyright or licensing dispute.
Finding 3: The File Has Become Both Machine Interface and Legal Artifact
The original AI-crawler report showed that 17.0% of analyzable sites had written explicit AI-specific rules. This follow-up looks at the textual burden those policies add.
Among the 6,638 readable robots.txt files:
- 1,377 contain AI-policy language;
- 719 contain copyright, terms, licensing, rights, or permission language;
- 271 contain
Content-Signal; - 83 mention
llms.txt.
The overlap is where the story gets more interesting:
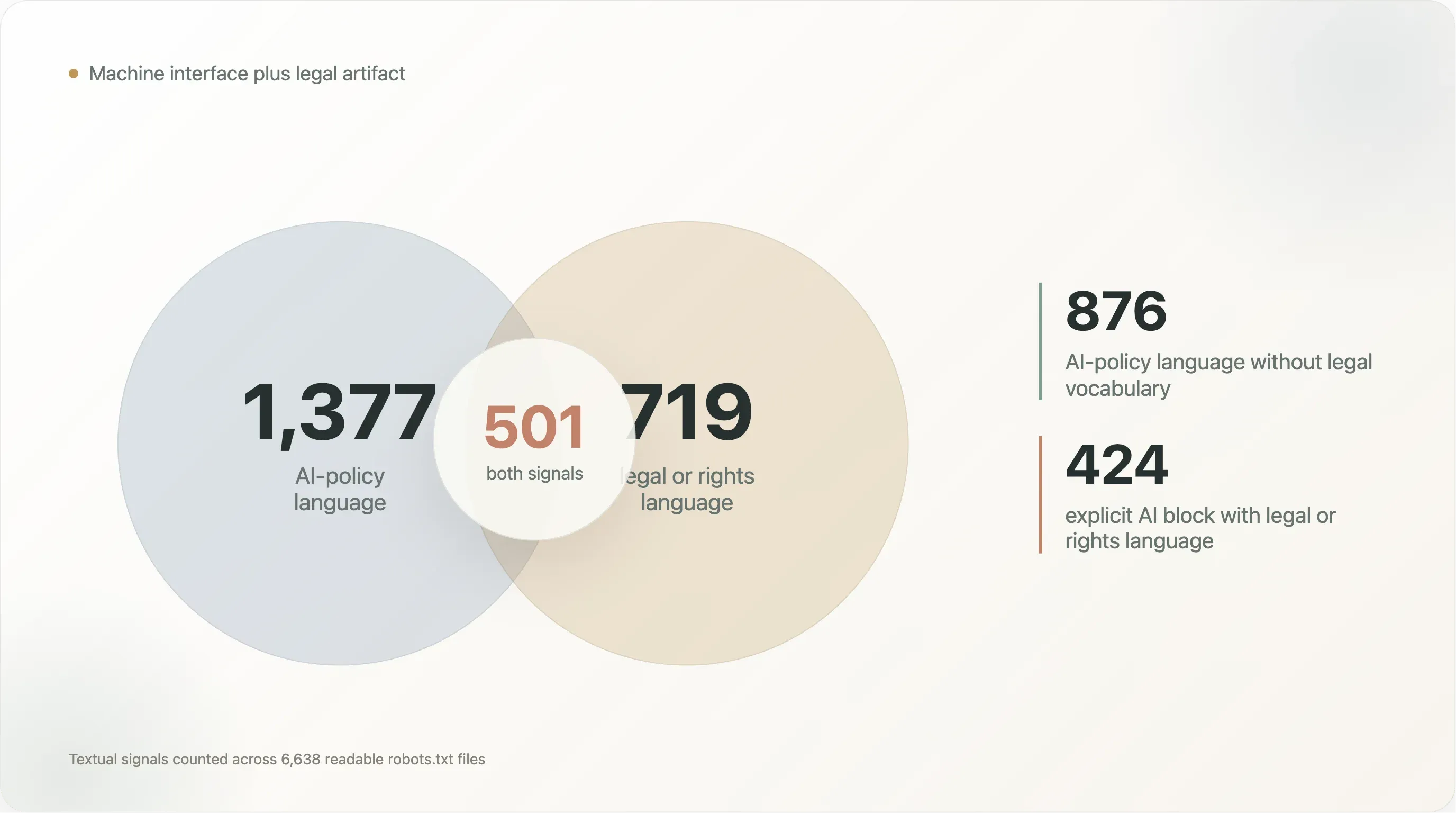
| Textual pattern | Files |
|---|---|
| AI-policy language and legal/rights language | 501 |
| AI-policy language without legal/rights language | 876 |
| Legal/rights language without AI-policy language | 218 |
Content-Signal with legal/rights language | 242 |
| Explicit AI block with legal/rights language | 424 |
This is a new kind of file.
A traditional robots.txt file is addressed to crawlers. A legal-preamble robots.txt file is addressed to at least four audiences at once:
- crawler operators, who need machine-readable directives;
- search and AI vendors, who need policy signals;
- lawyers, who want explicit reservation of rights;
- future auditors, courts, or journalists, who may read the comments as evidence of intent.
That multi-audience design explains why some files now read like policy documents. But it also weakens the clean separation between what a crawler can parse and what a human lawyer wants to declare.
The 876 files with AI-policy language but no legal vocabulary are mostly machine-policy files: bot names, Disallow blocks, and template language. The 501 files with both AI and legal language are different. They are trying to be crawler instructions and rights reservations at the same time. The 218 files with legal language but no AI vocabulary show that this pattern did not begin with LLMs; robots.txt was already being used as a place to state terms, permission boundaries, and rights claims.
For example, a comment may say that machine learning is prohibited, while the actual directive block may only disallow a subset of known user agents. A site may assert rights globally but only name a few crawlers. A CDN template may inject AI-related vocabulary into a file whose operator never hand-authored the legal language. A site may write a broad User-agent: * rule that blocks future crawlers unintentionally.
From a governance perspective, robots.txt has become attractive precisely because it is public and machine-readable. But the more policy it carries, the more its limitations matter:
- There is no authentication layer proving that a specific policy was reviewed by the rights holder rather than inherited from infrastructure.
- There is no native version history.
- There is no structured field for intended use, such as training, retrieval, search indexing, summarization, caching, or model evaluation.
- There is no universal registry of AI crawler identities.
- There is no enforcement mechanism.
This does not make the file useless. It makes it fragile.
The better interpretation is that robots.txt is becoming a notice layer: a public, inspectable declaration of preference and intent. It is not, by itself, a complete rights-management system.
Finding 4: Search Was Already Unequal Before AI Arrived
One of the strongest findings in the original report was that many publishers distinguish between AI training crawlers and search crawlers. They block CCBot, GPTBot, or Google-Extended while preserving Google search visibility.
This follow-up adds a different point: traditional search crawlers are not treated equally either.
We checked six search crawlers:
- Googlebot;
- Bingbot;
- DuckDuckBot;
- Slurp;
- Baiduspider;
- YandexBot.
Across the 7,248 analyzable sites:
| Search-crawler treatment | Sites |
|---|---|
| Blocks at least one search crawler | 562 |
| Allows Googlebot but blocks at least one other search crawler | 404 |
| Blocks all six checked search crawlers | 152 |
The blocked-bot counts are not evenly distributed:
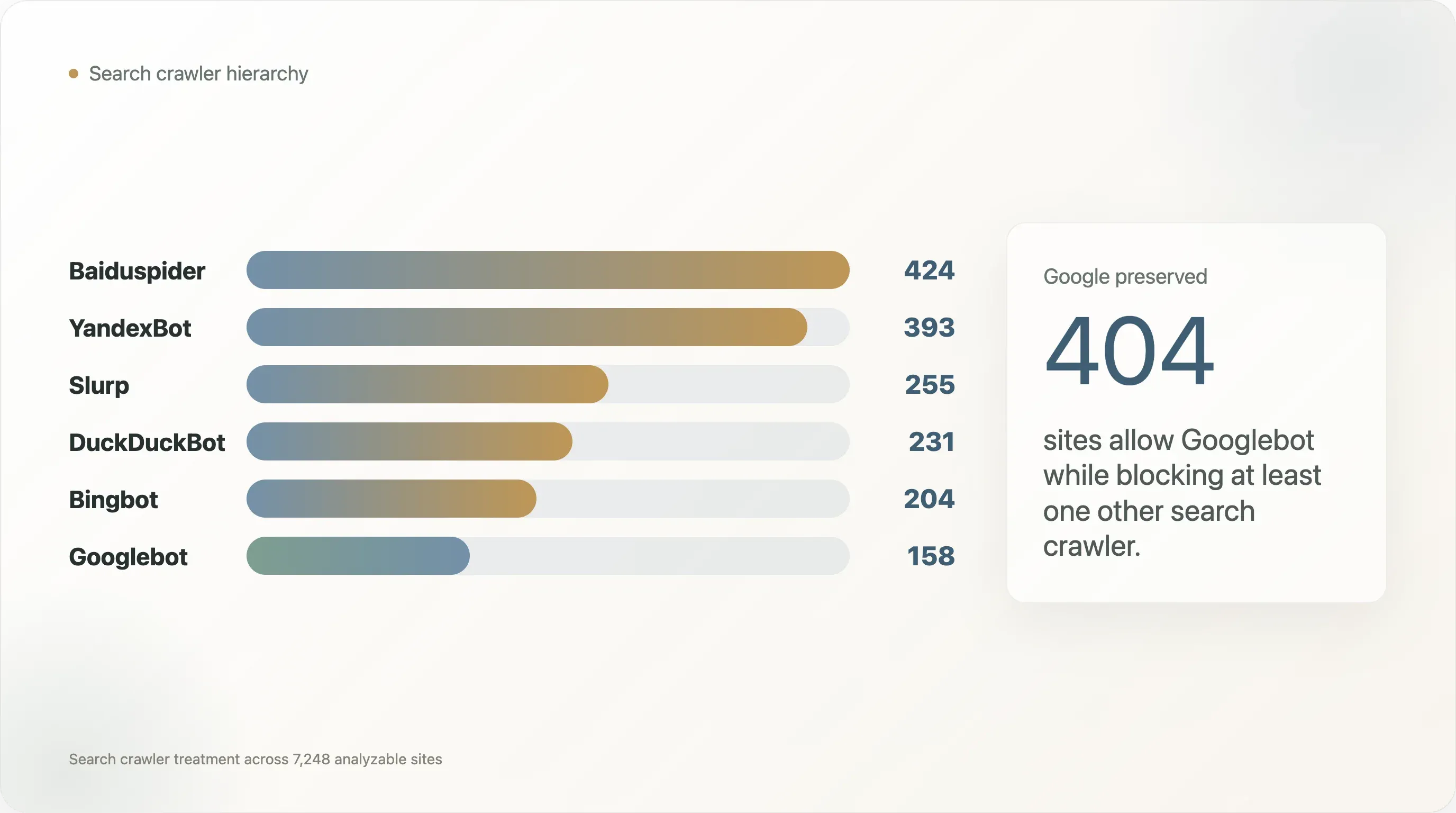
| Search crawler | Sites blocking it |
|---|---|
| Baiduspider | 424 |
| YandexBot | 393 |
| Slurp | 255 |
| DuckDuckBot | 231 |
| Bingbot | 204 |
| Googlebot | 158 |
Googlebot is the least-blocked crawler in this set. Baiduspider and YandexBot are blocked much more often, and in most of those cases Googlebot remains allowed. Among the 404 sites that allow Googlebot while blocking another search crawler, 269 block Baiduspider and 240 block YandexBot.
The examples are high-profile:
| Domain | Blocked search crawlers while Googlebot is allowed |
|---|---|
facebook.com | Baiduspider, YandexBot |
apple.com | Baiduspider |
twitter.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
netflix.com | DuckDuckBot, Slurp |
x.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
tiktok.com | Baiduspider |
baidu.com | Bingbot, DuckDuckBot, Slurp, YandexBot |
washingtonpost.com | YandexBot |
wsj.com | YandexBot |
bilibili.com | DuckDuckBot, Slurp, YandexBot |
temu.com | Slurp |
t-mobile.com | Baiduspider, YandexBot |
This matters for the AI debate because it shows that robots.txt was not a neutral universal-access protocol even before LLM crawlers arrived. The public web already had a hierarchy:
- Googlebot is often preserved because Google search traffic is too valuable to risk.
- Regional or competitor crawlers are easier to block.
- Some sites treat search crawler access as a market-by-market or vendor-by-vendor decision.
AI crawlers entered an ecosystem where differentiated access was already normal.
That makes the policy transition easier to understand. A publisher that writes "block Google-Extended, allow Googlebot" is not inventing a new form of discrimination. It is applying an old pattern to a new class of crawler: preserve distribution, restrict extraction.
The unresolved question is whether this old pattern scales. With search, there were only a handful of economically important crawlers. With AI, crawler identity is fragmented across model vendors, retrieval bots, data brokers, academic crawlers, synthetic browser agents, and infrastructure-level fetchers. The number of named user agents will keep growing unless the ecosystem consolidates around a smaller set of purpose-based signals.
That is how configuration debt compounds.
Finding 5: Complexity Varies by Sector, but Not the Way AI-Blocking Rates Do
The original report showed a large sector spread in AI blocking: news blocks at high rates; telecom, government, and SaaS block at low rates.
Configuration complexity cuts the web differently.
Among selected categories with enough readable robots.txt files for useful comparison:
| Category | n | Median bytes | P90 bytes | Median Disallow | P90 Disallow | Median User-agent | P90 User-agent |
|---|---|---|---|---|---|---|---|
| ecommerce | 215 | 1,738 | 10,388 | 37 | 164 | 3 | 49 |
| travel | 63 | 2,074 | 27,368 | 41 | 779 | 5 | 34 |
| news | 647 | 1,534 | 7,039 | 19 | 114 | 6 | 68 |
| finance | 121 | 1,002 | 8,337 | 17 | 132 | 2 | 23 |
| academia | 253 | 839 | 3,959 | 14 | 75 | 1 | 11 |
| government | 151 | 1,227 | 3,263 | 13 | 46 | 1 | 4 |
| SaaS | 368 | 485 | 12,606 | 4 | 56 | 1 | 10 |
| dev tools | 119 | 273 | 9,255 | 3 | 58 | 1 | 10 |
P90 Disallow by category chart here<<<<<<<<<<<<<<<<<<<<<<<<<
News is politically complex because it writes explicit AI rules and legal text. But ecommerce and travel are operationally complex because they have large catalogs, faceted navigation, search result pages, filters, user-account paths, and parameterized URLs.
That distinction is important.
Travel is the clearest example. It has only 63 readable files in this category slice, but its P90 robots.txt is 27.4 KB and its P90 Disallow count is 779, far above news. That does not mean travel sites have a more developed AI policy. It means travel sites have more surfaces that crawler operators can accidentally waste budget on: date searches, availability pages, review pagination, booking flows, filter combinations, and localized inventory paths.
SaaS is the opposite kind of surprise. Its median file is only 485 bytes, but the P90 file jumps to 12.6 KB. Most SaaS sites are open and light; a smaller set carries long path-control files, often because documentation, login surfaces, app routes, and marketing pages live under the same domain.
News sits in the middle operationally but near the top politically. Its P90 User-agent count is 68, higher than ecommerce, travel, finance, academia, government, SaaS, and dev tools in this table. That is a sign of bot-specific policy, not just path hygiene.
A publisher's robots.txt may be complex because of rights policy. A marketplace's file may be complex because of crawl-budget management. A university's file may be complex because thousands of legacy paths accumulated under one domain. A social platform's file may be complex because it has to expose some surfaces and suppress others at massive scale.
AI policy lands on top of all of that. It does not replace the existing reasons a file is complex.
This helps explain why AI-era robots.txt governance cannot be solved by a universal block list. The underlying files have different jobs:
- ecommerce sites manage duplicate paths and inventory surfaces;
- travel sites manage listings, calendars, reviews, and dynamic search pages;
- news sites manage copyright, archives, and licensing posture;
- SaaS and dev-tooling sites often want AI visibility;
- governments often need public access but may still have sensitive systems to exclude;
- social platforms manage user-generated content, profile surfaces, and anti-abuse concerns.
The same AI crawler rule means different things in each environment.
Finding 6: A Configuration Debt Index Identifies Review Risk, Not Moral Failure
This analysis created a simple configuration debt score to identify robots.txt files that are likely to be difficult to review.
The score weights:
- file size;
- number of
User-agentdirectives; - number of
Disallowdirectives; - number of
Allowdirectives; - number of non-core directives;
- presence of AI-policy language;
- mixture of explicit AI blocking and legal or copyright language.
This is not a correctness score. A high-complexity file can be perfectly intentional. A low-complexity file can still be wrong. The point is triage: if a file is large, policy-heavy, bot-specific, and full of exceptions, it deserves stronger review discipline.
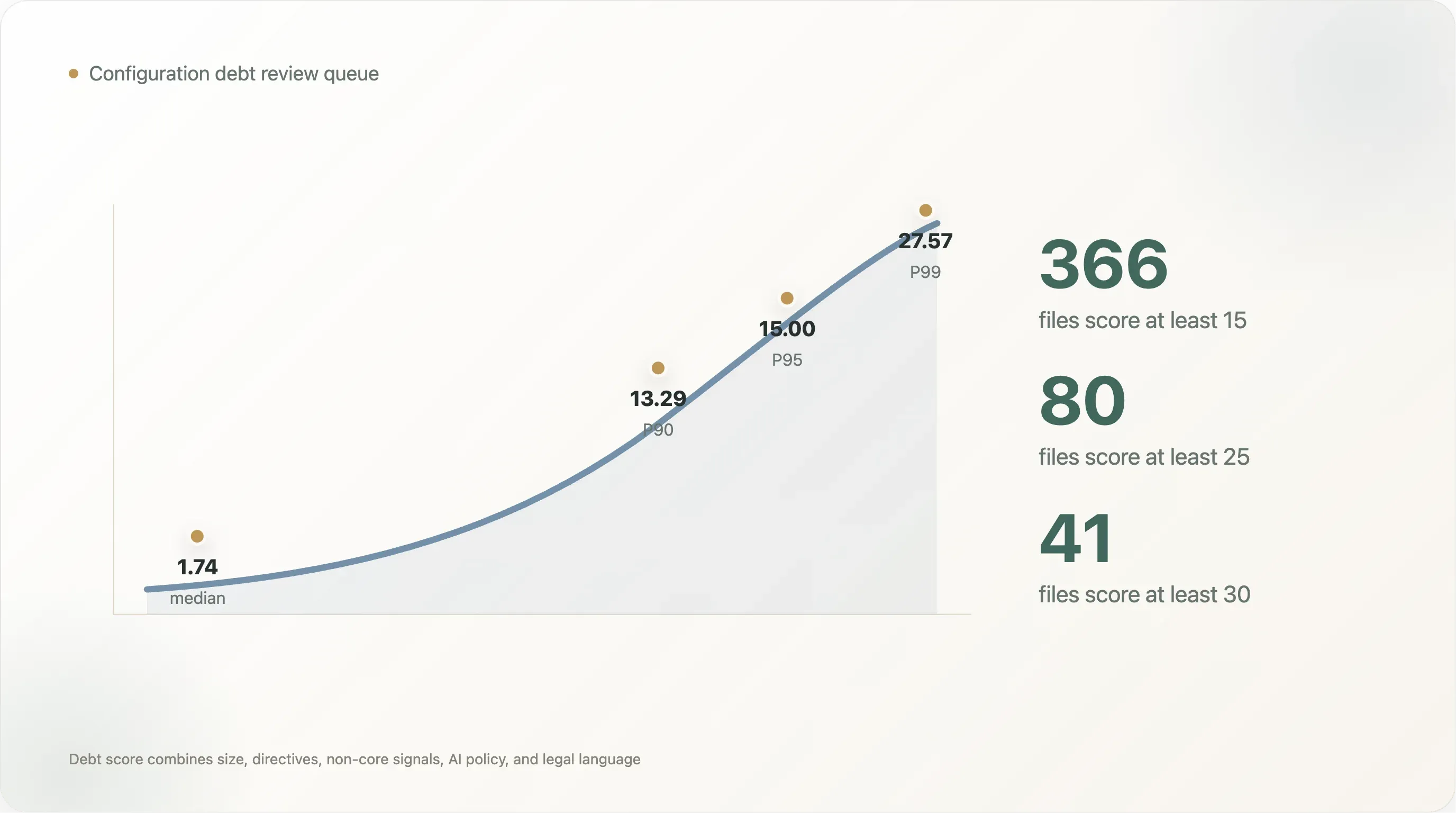
The score distribution is steep. The median readable file scores 1.74. The P90 score is 13.29, the P95 is 15.00, and the P99 is 27.57. Only 366 files score at least 15, 80 score at least 25, and 41 score at least 30. That is the practical review queue: not every site needs a governance project, but the upper tail does.
The category view also shows why a single "AI blocker" label is too flat:
| Category | Median score | P90 score |
|---|---|---|
| travel | 4.92 | 28.94 |
| search | 2.97 | 24.23 |
| social | 2.25 | 15.00 |
| news | 4.91 | 14.92 |
| finance | 1.67 | 12.61 |
| SaaS | 0.98 | 11.85 |
| ecommerce | 3.88 | 10.87 |
| government | 1.57 | 6.38 |
Travel and search have the highest P90 scores because a minority of files become very large and rule-heavy. News has one of the highest median scores because policy language and bot-specific treatment are more common across the whole category. Ecommerce has a high median Disallow count, but its P90 debt score is lower than travel because the complexity is more concentrated in path rules than in mixed policy/legal signals.
The highest-scoring files in this dataset include:
| Domain | Why it scores high |
|---|---|
linkedin.com | Very large file, thousands of path rules, many named user agents, explicit AI policy language |
lnkd.in | Same policy surface as LinkedIn shortlink infrastructure |
fragrantica.com | Hundreds of named user-agent blocks plus AI-policy language |
sovcombank.ru | Hundreds of user-agent blocks and legal/policy language |
academia.edu | Large allow/disallow matrix and explicit AI-blocking policy |
opentable.com | Large path-rule set, many sitemap directives, AI-related policy surface |
etsy.com | Large ecommerce path-control file with more than 1,600 Disallow rules |
runescape.com | Nearly 5,000 Disallow directives under one user-agent group |
These files should not be mocked for being complex. Complexity often reflects real business needs. But they demonstrate why robots.txt policy deserves the same engineering discipline as other production configuration:
- ownership should be explicit;
- changes should be reviewed;
- generated sections should be labeled;
- legal comments should be separated from machine directives where possible;
- test cases should assert expected bot access for critical crawlers;
- version history should be preserved;
- old bot names should be retired or documented;
- AI training, AI retrieval, search indexing, and archiving should be treated as separate purposes.
The last point is the most important. The current grammar is user-agent-first: it asks site operators to name bots. The AI-era need is purpose-first: it asks site operators to say what uses are permitted.
Those are not the same thing.
That mismatch is why longer block lists will not age well. A publisher can add GPTBot, ClaudeBot, CCBot, Google-Extended, Bytespider, Applebot-Extended, and PerplexityBot today, but the next crawler name, retrieval agent, or dataset broker can appear tomorrow. A purpose-based policy would let the site say "search indexing yes, AI training no, user-triggered retrieval maybe" without turning robots.txt into an address book of bots.
What This Means for AI Governance
The public debate often frames robots.txt as either meaningful or obsolete. The data suggests a more practical answer:
robots.txt is meaningful, but overloaded.
It is meaningful because major sites use it, crawlers can parse it, and policy choices are visible to researchers, journalists, vendors, and courts. The original report found that 17.0% of analyzable top sites had deliberate AI-specific rules. That is not symbolic noise.
It is overloaded because the file now has to express more than bot access:
- "Do not train on this content."
- "You may use this content for search indexing."
- "You may use this content for live retrieval."
- "You may not create cached datasets."
- "This legal reservation applies under EU text-and-data-mining law."
- "This CDN-managed site sends
Content-Signal: ai-train=no." - "This site wants Googlebot but not YandexBot."
- "This site has 1,000 legacy URL paths that should not be crawled."
The grammar was not designed for that many jobs.
Three changes would reduce the debt:
-
Crawler identity needs a registry. Site operators should not have to maintain an ever-growing list of
GPTBot,ClaudeBot,anthropic-ai,CCBot,Google-Extended,Applebot-Extended,Bytespider,OAI-SearchBot,ChatGPT-User, and dozens more. Without a registry, policy will always lag crawler behavior. -
AI use needs structured vocabulary. Training, retrieval, indexing, summarization, dataset resale, model evaluation, and user-triggered browsing are different uses. Expressing them through vendor-specific user-agent names is brittle.
-
Policy needs auditability. The web needs a way to distinguish hand-authored rights reservations from inherited CDN defaults, generated CMS templates, stale legacy rules, and accidental catch-all blocks. The distinction matters for trust and for litigation.
None of this means replacing robots.txt overnight. The better path is layering: keep robots.txt as the discovery and compatibility surface, but standardize adjacent machine-readable policy for AI-specific uses.
llms.txt is one attempt, but adoption in this dataset is still tiny: only 83 readable files mention it. Content-Signal is more visible because Cloudflare can distribute it through infrastructure, and all 271 Content-Signal files in this scan also matched AI-policy language. Still, distribution is not the same as consensus. A durable solution likely needs the boring machinery of standardization: clear fields, clear semantics, crawler commitments, and public test suites.
Conclusion
The AI crawler fight has turned robots.txt into a governance artifact. That is both useful and risky.
Useful, because the file is public. Researchers can audit it. Publishers can change it. Crawlers can honor it. Courts can read it. Infrastructure providers can deploy it at scale.
Risky, because it is carrying too much.
The median robots.txt file in the Tranco Top 10K is still small enough to understand. But the high-traffic web's long tail is full of large, old, layered, vendor-specific, and legally charged files. Hundreds of sites now maintain robots.txt configurations that are better understood as production policy systems than as simple crawler hints.
The central lesson is not that robots.txt has failed. It is that the web has promoted it without refactoring it.
If AI access policy is going to depend on machine-readable public declarations, the next step is not another longer block list. It is better policy infrastructure: purpose-based permissions, stable crawler identity, reviewable templates, and audit trails.
Until then, the public web's AI governance layer will keep resting on a text file that was never meant to carry this much weight.
Reproducibility Notes
The delivery folder includes:
source_data/analysis.json— original aggregate metrics.source_data/site_meta.csv— original per-site analytical table.source_data/bot_status.csv— original domain-by-bot policy table.source_data/fetch_meta.csv— original fetch metadata.source_data/sites.csv— original domain/category/status table.derived_data/robots_complexity_by_site.csv— per-site complexity metrics generated for this report.derived_data/search_bot_treatment.csv— search crawler treatment matrix.derived_data/category_complexity_summary.csv— category-level complexity summary.derived_data/top_config_debt_sites.csv— top sites by the triage score described above.derived_data/summary_metrics.json— all headline metrics quoted in this report.
Methodology corrections, dataset issues, and follow-up analyses welcome at support@thunderbit.com. This report is published independent of any commercial position Thunderbit holds; we build an AI-powered web scraper, and we have a structural interest in robots.txt continuing to be a meaningful, machine-readable contract on the public web. The data in this report stands on its own. — The Thunderbit research team, May 2026.