
GitHub surfaces more than right now. Sounds like a buffet. The catch: only about 28% show any maintenance activity in the last twelve months. I've spent the last few weeks digging through these repos, testing endpoints, reading issue queues, and cross-referencing Reddit's own policy updates. The goal: save you from cloning a repo, fighting with OAuth, and discovering at midnight that the whole thing quietly broke in 2024. The Reddit scraper GitHub landscape in 2026 is a graveyard of good intentions mixed with a handful of genuinely useful tools. This guide covers what still works, what broke, when to skip code entirely, and how to stay on the right side of Reddit's increasingly strict enforcement. If you're looking for a shortcut, is the no-code option we built for exactly this kind of problem—but I'll be honest about where code-based solutions still make more sense, too.
What Is a Reddit Scraper GitHub Repo (And Why So Many Are Broken)
A "reddit scraper github" repo is typically an open-source Python (or sometimes JavaScript) project that automates pulling posts, comments, user data, or media from Reddit. They generally fall into four camps:
- API wrappers (like PRAW): use Reddit's official API, require OAuth, and play by Reddit's rules.
- Pushshift/PSAW-based tools: used to tap into Pushshift's massive Reddit archive for historical data.
- Public
.jsonendpoint scrapers: append.jsonto Reddit URLs or hit public-facing endpoints without authentication. - Browser-based scrapers: use Playwright, Selenium, or browser extensions to load Reddit pages and extract rendered content.
Why did so many break? Three reasons.
- Reddit's API pricing overhaul in mid-2023. Free API limits dropped to . Higher commercial usage now costs $0.24 per 1,000 API calls. Many repos were built for a world where API access was essentially unlimited—and that world is gone.
- Pushshift's public access was revoked. Pushshift was the backbone for historical Reddit research. Once Reddit restricted it, a huge share of "historical scraper" repos lost their main data source. Some READMEs still make these tools look alive, but the dependency underneath is gone for ordinary users.
- Reddit hardened both policy and enforcement. The 2024 robots.txt update, 2025 , and the March 2026 all signal that Reddit is no longer treating bulk scraping as harmless background noise. They've even .
The upshot: search "reddit scraper github" and you'll get hundreds of results. The last-commit dates and open-issue counts tell a very different story.
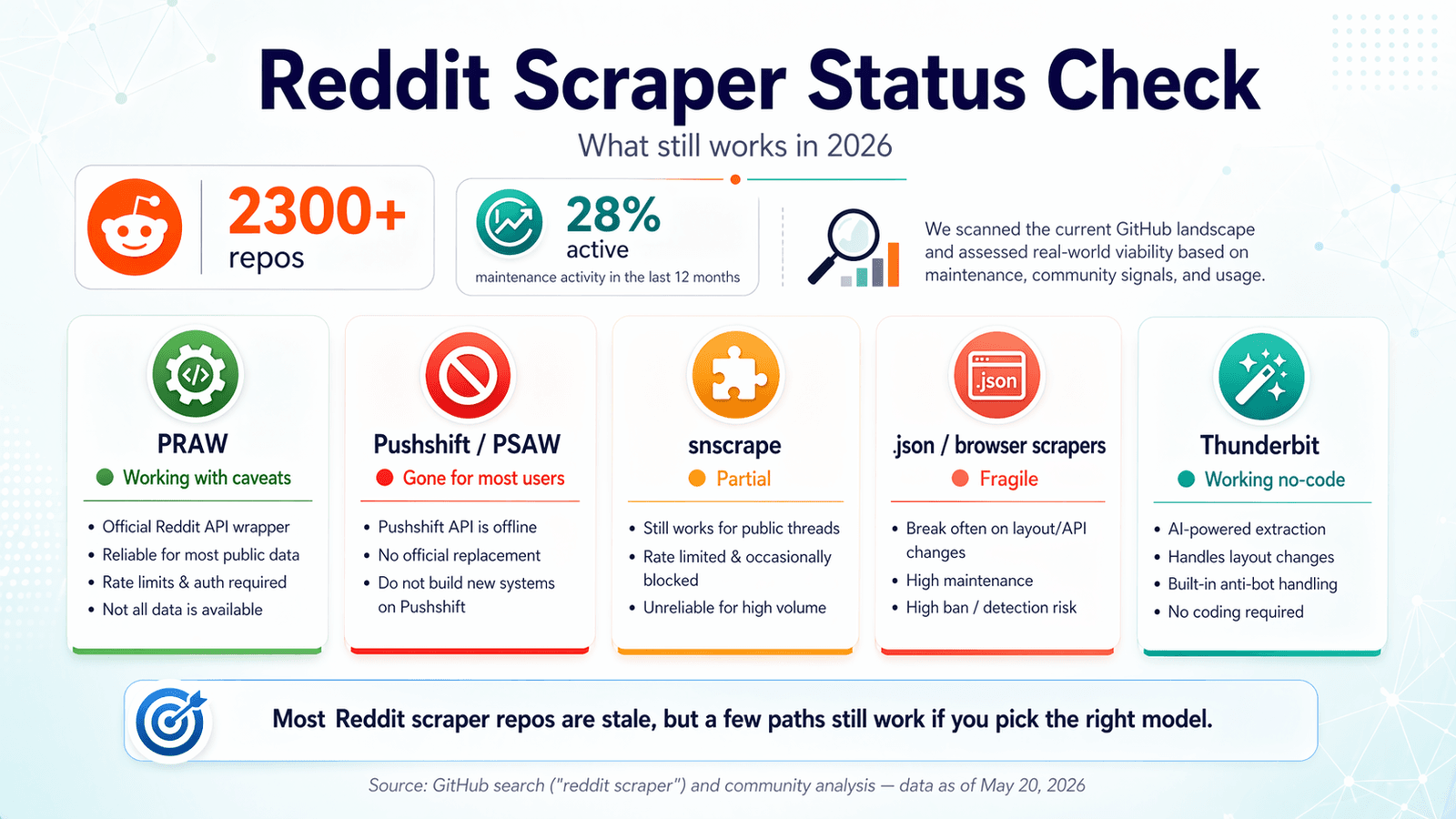
The 2026 Reddit Scraper GitHub Status Check: What Still Works
Most competing articles were written in 2023 or 2024 and never updated. Forum users keep hitting errors with repos that worked a year ago—one user's plea, "Keep running into Reddit API limitation error :\ Any ideas how I can get past this?" is basically the 2026 Reddit scraper experience in a nutshell.
I ran a freshness audit, verified as of April 2026. Here's what I found.
PRAW: The Official Python Wrapper
Status: ✅ Still working, with caveats.
(Python Reddit API Wrapper) remains the most reliable open-source foundation for Reddit scraping. It's actively maintained—4,099 stars, last pushed April 20, 2026, only 6 open issues, and (released October 2024).
Strengths: Official, well-documented, abstracts most of Reddit's API complexity.
2026 limitations:
- Stricter OAuth requirements. You need a registered Reddit app with an approved use-case description.
- Lower rate limits since 2024 (100 queries/min with OAuth, 10 without).
- The hard ~1,000-post listing cap persists. Community threads on r/redditdev and Stack Overflow confirm: per listing endpoint.
PRAW is the safest bet if you can live inside the API's box.
It's just not a free-form bulk scraper anymore.
If you want a practical walkthrough of the official API route, this tutorial fits this section well:
Pushshift / PSAW: The Archive That Went Dark
Status: ❌ Public access gone.
was the go-to Python wrapper for Pushshift, which used to be the easiest route for historical Reddit data. In 2026, the repo is archived, the README literally says "THIS REPOSITORY IS STALE," and recent open issues include gems like "Pushshift.io UNABLE to connect" and "The code not working. Possibly due to pushshift api."
Academic access may still exist through specific channels, but for anyone searching "reddit scraper github" today, Pushshift/PSAW is not a viable option. If you need deep historical Reddit data, you'll need to look into approved academic data access or licensed paths.
snscrape (Reddit Module): Partial and Unreliable
Status: ⚠️ Partial — intermittent breakage, largely unmaintained.
has 5,337 stars, but the last push was November 15, 2023. The README still says Reddit scraping is supported "via Pushshift." Open Reddit-related issues include "Error reddit scraping" and "Reddit scraper returns no submissions before 2022-11-03," with no recent meaningful repair activity.
It can work for small, one-off pulls in some environments, but it's not reliable for production or recurring scrapes. Treat it as legacy.
Playwright and .json Endpoint Scrapers: The Workaround That Works (Sometimes)
Status: ✅ Working, but fragile.
The idea here is straightforward: use a headless browser (Playwright, Puppeteer) to load Reddit pages and scrape rendered content, or append .json to Reddit URLs to get structured data without the official API.
Strengths: No API key needed, can bypass the 1k-post cap, access to rendered content.
Weaknesses: Breaks when Reddit changes its front-end layout or JSON structure, can trigger anti-bot measures, and requires more technical setup. In my own testing this month, direct requests to public Reddit .json endpoints returned 403 responses. That doesn't mean every environment will be blocked, but it does mean the .json shortcut is no longer something you should assume will "just work."
Repos like are refreshingly honest about this: the README warns users to "Use with rotating proxies, or Reddit might gift you with an IP ban." That's basically the April 2026 story in one sentence.
If you're evaluating the browser-automation workaround path, this Playwright tutorial is a strong companion to the section below:
Thunderbit: AI-Powered Browser Scraping (No Code, No API Key)
Status: ✅ Working — adapts to page changes automatically.
takes a fundamentally different approach. It's a that uses AI to read Reddit pages, suggest data fields (post title, author, upvotes, timestamp, URL, etc.), and extract structured data in two clicks. No OAuth setup, no API key registration, no Python environment, no dependency management. The AI reads the page fresh each time, so when Reddit changes its layout, Thunderbit adapts automatically instead of breaking silently.
Free export to CSV, Google Sheets, Airtable, or Notion. Handles pagination and subpage scraping (e.g., scraping a subreddit listing, then visiting each post to pull comments). For the audience that wants Reddit data without maintaining a GitHub repo, this is the path of least resistance.
(Full disclosure: we built Thunderbit, so I'm biased—but I'll be clear about where code-based solutions still make more sense later in this article.)
Side-by-Side Status Summary Table
| Tool / Category | Still Working (April 2026)? | API Key Required? | Notes |
|---|---|---|---|
| PRAW | ✅ Yes, with caveats | Yes (OAuth) | Best-maintained open-source foundation. Constrained by rate limits and 1k-post cap. |
| Pushshift / PSAW | ❌ No (for most users) | N/A | Public access gone. Repo archived. |
| snscrape (Reddit module) | ⚠️ Partial / unreliable | No | Still documents Reddit "via Pushshift." Maintenance stalled since 2023. |
| .json / public-endpoint scrapers | ⚠️ Partial | No | Can work, but direct requests increasingly blocked. Proxy-dependent. |
| Playwright / browser scrapers | ✅ Yes, but fragile | Usually no | Most viable no-API DIY workaround. Page changes and anti-bot checks still matter. |
| Thunderbit | ✅ Yes | No | AI/browser workflow. No OAuth, no selectors. Best fit for non-developers. |
Rate Limits, the 1k-Post Cap, and What Actually Helps
This is the #1 pain point for anyone using a reddit scraper github project. Forum threads are full of frustration: "tired of runs dying halfway through because of rate limits," "Why am I only getting around 1,000 items?" The two core constraints are Reddit's API rate limits (requests per minute) and the ~1,000-post listing cap (the API only returns the most recent ~1,000 posts per listing endpoint).
Rate-Limit Management Best Practices
Reddit's current public baseline: . Here's how to handle that in practice:
- Exponential backoff. If you get a rate-limit response, wait, then retry after a longer delay each time (1s, 2s, 4s, 8s…). Don't just hammer the endpoint.
- Read
X-Ratelimit-Remainingheaders. Reddit's API responses include headers that tell you how many requests you have left and when the window resets. Pace your requests based on these values, not on guesswork. - Rotating user-agents. Some repos suggest this to avoid detection. It can help, but use it ethically—don't use it to evade bans you've earned.
- Log everything. Add logging for API responses, rate-limit headers, and errors. When your scraper dies at 2 AM, logs are your best friend.
Breaking the 1,000-Post Ceiling
The most credible workaround for the API's ~1,000-item listing cap is time-window chunking:
- Query one time slice using
beforeandaftertimestamp parameters. - Move the window forward (or backward).
- Repeat.
- Deduplicate on post ID.
This isn't elegant, but it's more honest than pretending one request loop can pull arbitrary history from a listing endpoint. For truly historical data, you'd need approved academic access or a licensed path—Pushshift is no longer the default answer.
Browser-based scraping (Playwright or Thunderbit) sidesteps this cap entirely since it scrapes what's rendered on the page, not what the API returns. Thunderbit's pagination feature lets you click through pages and collect data across as many pages as you need.
Deduplication and Error Recovery
Most reddit scraper github repos don't handle dedup or error recovery out of the box. Users explicitly complain that "none had deduping, rate limit avoidance after errors, checking if files are already downloaded." Here's what to do:
- Deduplication: Hash each post's ID (or ID + content). Store seen hashes in a simple SQLite database or even a flat file. Before inserting, check if the hash already exists. This is especially important when chunking time windows or re-running failed jobs.
- Error recovery: Save progress to a checkpoint file after every N records. If the run fails, restart from the last checkpoint instead of from scratch. This turns a 3-hour job that dies at hour 2 into a 1-hour resume.
How Different Approaches Handle These Constraints

| Approach | Rate-Limit Handling | >1k Posts? | Auto-Dedup? | Error Recovery? |
|---|---|---|---|---|
| PRAW (raw) | Manual (sleep/retry) | ❌ (API cap) | ❌ | ❌ |
| PRAW + time-window chunking | Manual | ✅ (workaround) | ❌ | ❌ (unless you add it) |
| Playwright .json scraping | N/A (no API) | ✅ | ❌ | ❌ |
| Thunderbit (browser scraping) | Built-in (AI pacing) | ✅ (pagination) | N/A (visual review) | Built-in |
When a Reddit Scraper GitHub Repo Isn't the Answer: The No-Code Path
Most reddit scraper github articles assume Python proficiency. But a lot of the people searching for Reddit scraping solutions are marketers, sales reps, researchers, or indie founders who don't write Python daily. For that audience, a GitHub repo adds hidden costs:
- Setting up OAuth credentials and a Reddit developer app
- Managing Python virtual environments and dependency conflicts
- Debugging cryptic error messages when PRAW's internals change
- Handling API key revocation if Reddit decides your use case isn't approved
- Maintaining the script every time Reddit changes something
These aren't hypothetical. has 2,563 stars and 107 open issues. Recent reports include "Struggling to install," "PRAW module error," and "Exception not allowing to even authenticate."
Use a GitHub Repo If...
- You need custom scraping logic (e.g., specific comment tree traversal, custom NLP pipeline integration).
- You want to integrate into an existing Python data pipeline.
- You need to scrape at very high scale with custom storage (database, data warehouse).
- You're comfortable maintaining code and handling breaking changes.
Use a No-Code Tool If...
- You need Reddit data quickly—within minutes, not hours of setup.
- You don't want to manage API keys, OAuth apps, or Python environments.
- You want to export directly to spreadsheets, Notion, or Airtable for immediate use.
- You want the tool to adapt automatically when Reddit's layout changes.
Thunderbit fits squarely in the no-code lane. Users can in 2 clicks with AI-suggested fields, export free to CSV/Google Sheets/Airtable/Notion, and handle pagination without writing code. Its browser-based scraping means no OAuth setup and no API-key registration.
Quick Walkthrough: Scraping Reddit with Thunderbit (Step by Step)
- Install the .
- Navigate to the Reddit page you want to scrape (subreddit, search results, user profile).
- Click "AI Suggest Fields." Thunderbit reads the page and suggests columns—post title, author, upvotes, timestamp, URL, etc.
- Adjust fields if needed, then click "Scrape."
- Review the data table. Optionally click "Scrape Subpages" to visit each post and pull comments or additional details.
- Export to your preferred destination: Google Sheets, Excel, Airtable, Notion, CSV, or JSON.
Two minutes. Zero lines of code. If you want to see it in action, check out the .
Match the Reddit Scraper to the Job: A Use-Case Decision Matrix
Most reddit scraper github articles organize by tool. That's backwards.
Start from your goal and work backward to the right tool.
Lead Generation and Pain-Point Mining
What you need: Posts + comments with keyword filtering, AI tagging/labeling, export to CRM-ready formats.
Best approach: No-code scraper with AI enrichment.
Recommended tool: (AI labeling + export to Google Sheets/Airtable for CRM import).
Example workflow: Scrape a subreddit for posts mentioning a specific pain point. Use Thunderbit's Field AI Prompt to categorize sentiment or tag topics. Export to your sales team's Airtable or Google Sheet.
Market Research and Idea Validation
What you need: High-volume post titles + scores, subreddit-level trend data.
Best approach: PRAW with time-window chunking for volume, or Thunderbit for quick pulls.
Example: Scraping r/SaaS or r/startups for trending topics and upvote patterns over the past 90 days.
Image and Media Archiving
What you need: Media URLs, deduplication, scheduled runs.
Best approach: Specialized GitHub repo (e.g., ) + cron job.
Note: Dedup matters here—same image posted across subreddits is common.
Academic Research and Historical Data
What you need: Historical data, full comment trees, large datasets.
Best approach: Approved academic access or licensed data path. Pushshift is no longer a general-purpose answer.
Reality check: This is the hardest use case in 2026 due to Pushshift restrictions and Reddit's tightened data policies.
Competitor Monitoring and Scheduled Scraping
What you need: Recurring scrapes at set intervals, change detection.
Best approach: Thunderbit's (describe the time interval in plain English, input URLs, click Schedule) or cron + script for code-based users.
Use-Case Decision Matrix Table
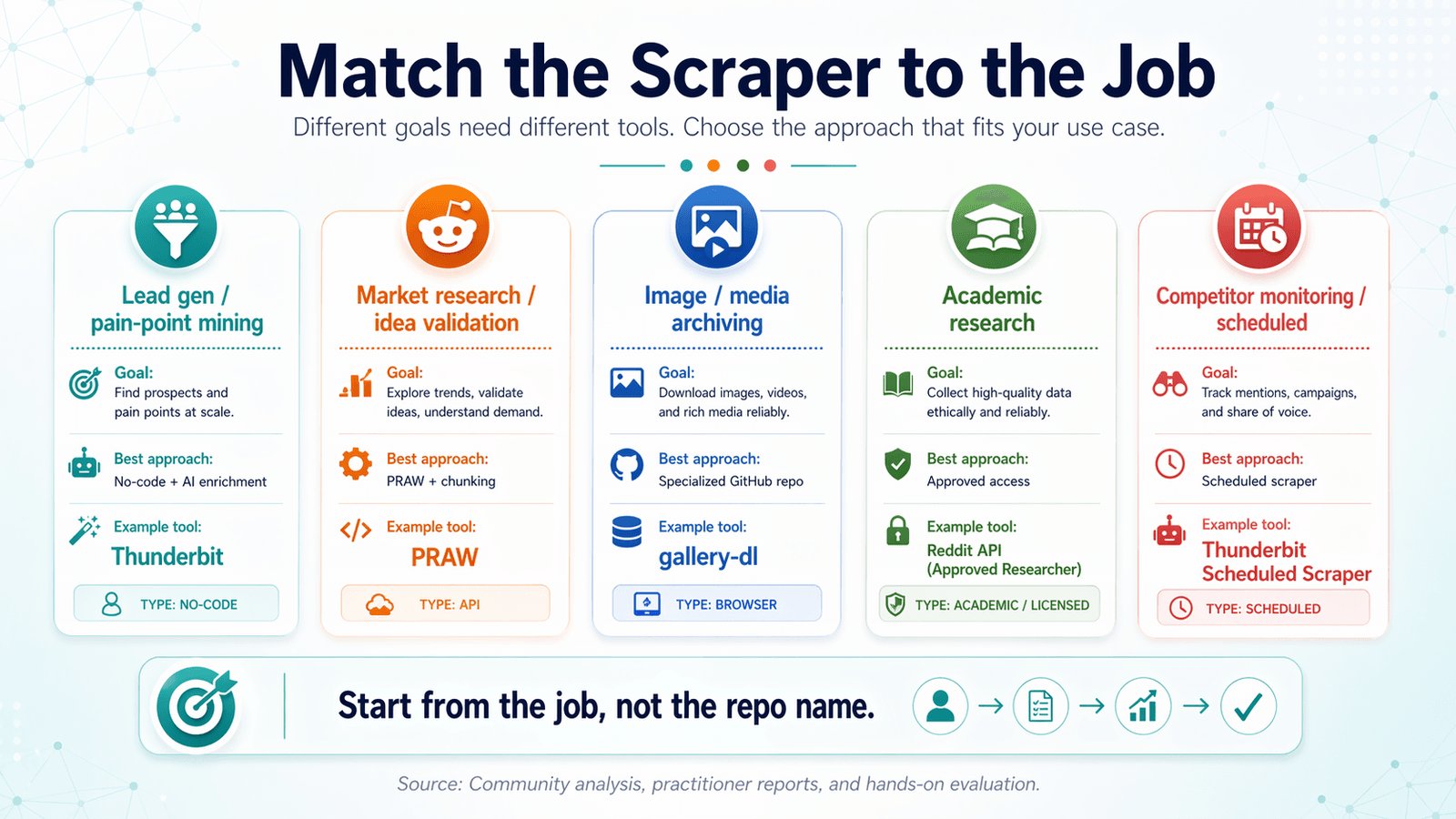
| Use Case | What You Need | Best Approach | Example Tool |
|---|---|---|---|
| Lead gen / pain-point mining | Posts + comments, keyword filtering, AI tagging | No-code scraper + AI enrichment | Thunderbit |
| Market research / idea validation | High-volume post titles + scores, subreddit-level data | PRAW + time-window chunking or Thunderbit | PRAW or Thunderbit |
| Image/media archiving | Media URLs, dedup, scheduled runs | Specialized GitHub repo + cron | bulk-downloader-for-reddit |
| Academic research | Historical data, full comment trees | Approved academic access or Playwright | Pushshift academic API (if accessible) |
| Competitor monitoring / scheduled | Recurring scrapes, change detection | Scheduled scraper | Thunderbit Scheduled Scraper or cron + script |
How to Evaluate Any Reddit Scraper GitHub Repo Before You Commit
Before you clone a repo and start debugging, run this 5-minute health check. It'll save you hours.
The 5-Minute Repo Health Check
- Last commit date. If it's been more than 6 months, proceed with caution. Reddit's API changes frequently.
- Open issues vs. closed issues ratio. A high number of unanswered issues is a red flag. Check if recent issues mention auth failures, 403s, or Pushshift outages.
- LICENSE file. Check if one exists. No license = legally ambiguous (more on this below).
- Dependencies. Are the required libraries up to date? Does it use deprecated packages? A
requirements.txtfull of pinned 2022 versions is a warning sign. - README quality. Does it explain setup clearly? Are there usage examples? Poor docs = more debugging time for you.
- Stars vs. forks vs. recent activity. High stars but low recent activity may mean the project was popular but is now abandoned. Compare stars to the
pushed_atdate.
A quick example: has 364 stars—looks credible at a glance. But the repo is archived and the README says "THIS REPOSITORY IS STALE."
Stars alone don't tell the story.
Tips for Getting the Most Out of Your Reddit Scraper GitHub Setup
If you do decide to go the code route, here's how to save yourself headaches.
Always Use a Virtual Environment
A virtual environment keeps your scraper's dependencies isolated so they don't conflict with other Python projects. One command: python -m venv venv and then activate it before installing anything. This is basic hygiene, but I've seen enough GitHub issues titled "module not found" to know it's worth repeating.
Store Credentials Securely
Never hardcode your Reddit API client ID or secret in the script. Use environment variables or a .env file, and add .env to your .gitignore. If you accidentally push credentials to GitHub, rotate them immediately—bots scan for exposed API keys.
Log Everything
Add logging for API responses, rate-limit headers, and errors. When something breaks, logs are the difference between "I know exactly what happened" and "I have no idea why it stopped."
Schedule and Automate Thoughtfully
If running recurring scrapes, use cron (Linux/Mac) or Task Scheduler (Windows)—but monitor for failures. A cron job that silently fails for two weeks is worse than no automation at all.
Alternative: Thunderbit's lets you describe the interval in plain English, no cron syntax needed.
Legal and Ethical Best Practices for Reddit Scraping
This isn't a throwaway disclaimer. Reddit has aggressively enforced its terms since the 2023 API changes, and scraping personal data carries real legal exposure.
Here's what actually matters.
Reddit's Terms of Service: What They Actually Say
Reddit's (revised through March 31, 2026) explicitly prohibits accessing, searching, or collecting data from the services by automated means unless allowed by the terms or a separate agreement. The and add more detail: Reddit may monitor and audit developer use, change or discontinue access, and permanently block access for excessive or abusive usage. Commercial use generally requires explicit approval.
The March 2026 goes further: approval is required before accessing Reddit data through the API, unapproved commercialization and AI/data-mining uses are prohibited, and enforcement can include revoking tokens, suspending apps or accounts, and suspending associated bots or domains.
robots.txt Compliance
Reddit's current is unusually restrictive:
1User-agent: *
2Disallow: /That's a blanket disallow for all automated user agents. It also references the . This is much stronger than the permissive robots.txt patterns some developers still assume from older web-scraping norms.
Best practice: always check robots.txt before scraping, even if your tool doesn't enforce it automatically.
Personal Data and Privacy (GDPR/CCPA)
If you're scraping usernames, post history, or any personally identifiable information, (EU) and CCPA (California) may apply. Best practice: anonymize or aggregate personal data before storing. Don't build profiles of individual users without a lawful basis.
GitHub Repo Licensing: Check Before You Build
Many reddit scraper github repos use MIT or Apache licenses (permissive), but some have no license file at all—which legally means "all rights reserved." Before forking, modifying, or building on a repo, always check the LICENSE file. No license = legally ambiguous, regardless of how many stars it has.
Enforcement Is Real in 2025–2026
Reddit's enforcement story didn't stop in 2023. Reddit filed a complaint against Anthropic in 2025 alleging unauthorized scraping/use of Reddit content, and also pursued Reddit v. SerpApi in late 2025. These are signs that Reddit is willing to pursue legal enforcement, not just technical blocking.
Picking the Right Reddit Scraper GitHub Approach in 2026
The reddit scraper github landscape has changed dramatically since 2023. Most repos are outdated. Rate limits and the 1k-post cap are real constraints. Pushshift is gone for ordinary users. And Reddit's policy stack is more explicit and more enforced than ever.
The short version:
- PRAW is still the most reliable open-source foundation if you can accept Reddit's API limits and want to build custom logic.
- Pushshift/PSAW is no longer a general-purpose answer.
- snscrape's Reddit module is legacy and unreliable.
- .json and public-endpoint scrapers are fragile and often blocked in 2026.
- Browser-based tools—whether Playwright repos or no-code options like —are the most practical path for many users, especially non-developers.
Start from your use case, not the tool. Run the 5-minute repo health check before committing to any GitHub project.
And if you'd rather skip the setup and start scraping Reddit in minutes, .
FAQs
What are the best open-source Reddit scrapers on GitHub in 2026?
remains the most reliable API wrapper, with active maintenance and good documentation. is a credible maintained CLI tool built on PRAW. Playwright-based scrapers work for non-API scraping, and snscrape's Reddit module is partially functional but largely unmaintained. Always check the last-commit date and open issues before using any repo—most of the on GitHub are stale.
Is it legal to scrape Reddit?
Scraping publicly available data occupies a legal gray area, but Reddit's own terms are restrictive. The , , , , and all push against unauthorized bulk scraping. Commercial redistribution of scraped data may require Reddit's explicit permission. If you're scraping personal data, GDPR and CCPA may also apply.
How do I get past Reddit's API rate limits?
Use exponential backoff, monitor X-Ratelimit-Remaining headers, and consider time-window chunking to work within the limits. Browser-based scraping (Playwright or ) bypasses API rate limits since it scrapes rendered pages, but comes with its own considerations (page-load speed, anti-bot measures). There's no magic trick to remove rate limits entirely—they're enforced server-side.
Can I scrape Reddit without an API key?
Yes. Playwright-based scrapers and the .json URL trick don't require API keys. also requires no API key since it scrapes via the browser. The trade-offs: .json endpoints are increasingly blocked (returning 403 in many environments as of April 2026), and browser-based scraping is slower and more resource-intensive than API calls.
What happened to Pushshift for Reddit scraping?
Pushshift's public API access was removed following Reddit's data licensing changes starting in 2023. The wrapper is archived and stale. Limited academic access may exist through specific approved channels, but for most users searching "reddit scraper github" today, Pushshift is no longer a viable option. If you need deep historical Reddit data, look into Reddit's approved academic or licensed data paths.
Learn More