

The web in 2025 is a wild, ever-changing frontier—one minute you’re tracking competitor prices, the next you’re knee-deep in dynamic JavaScript and anti-bot mazes. As someone who’s spent years building automation tools for sales and operations teams, I can tell you: web scraping isn’t just a “nice-to-have” skill anymore. It’s a core business superpower. With 90% of enterprises now relying on analytics for strategic decisions and the volume of online data growing by nearly 193% in just four years, the ability to turn messy web content into actionable insights is what separates the leaders from the laggards.

But let’s be real: scraping isn’t what it used to be. The days of grabbing static HTML with a few lines of Python are fading fast. Now, you’re up against dynamic content, infinite scrolls, and anti-bot defenses that would make a secret agent sweat. Whether you’re a total beginner or looking to level up your scraping stack, this guide will walk you through the best practices, tools, and workflows for mastering Python scraping in 2025—and show you how to supercharge your projects with AI tools like Thunderbit.
Scrape data from any website using AI Get Started Free
From Novice to Pro: The Foundations of Python Scraping
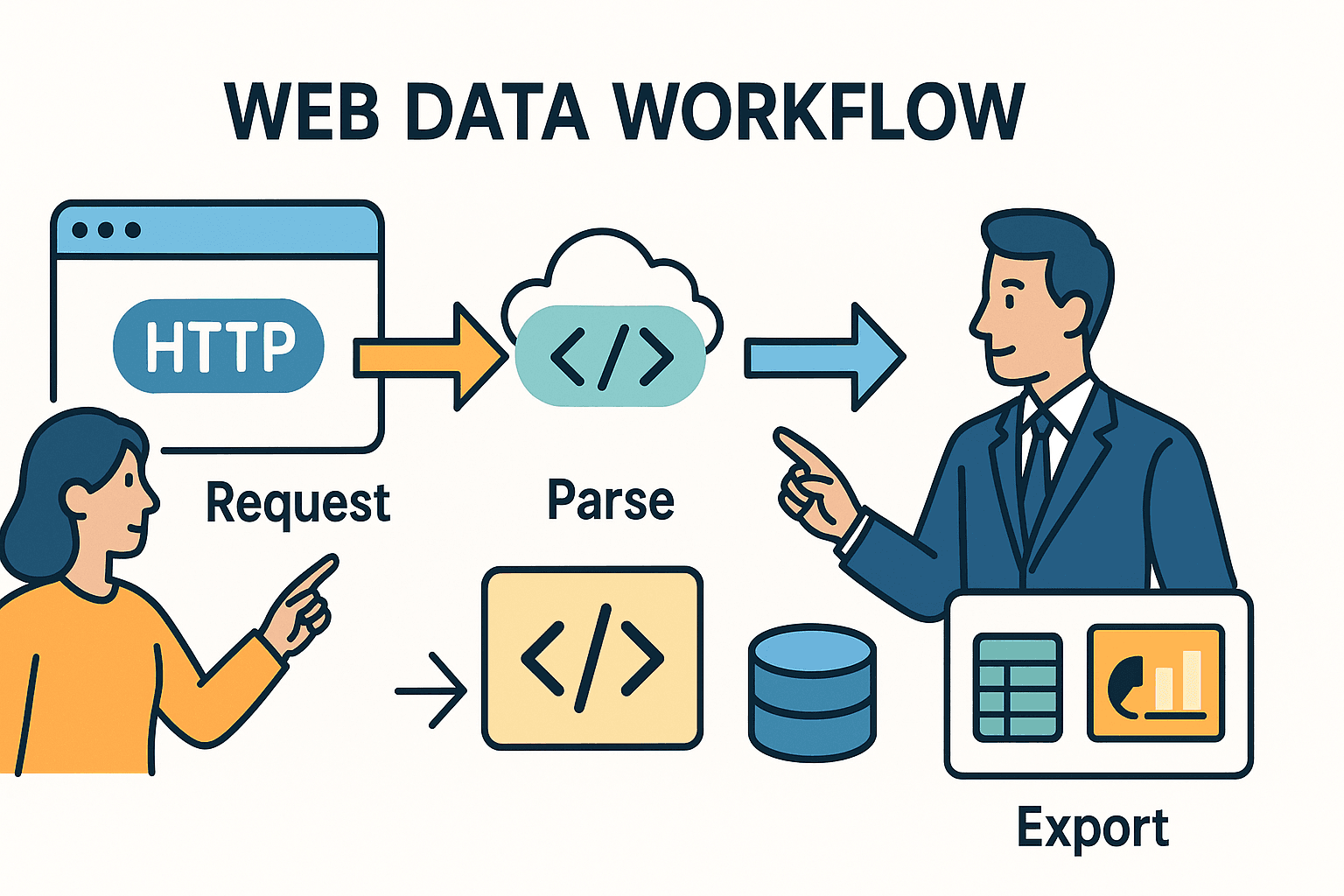
Let’s start at the beginning. Web scraping is, at its heart, about automating what you’d do in a browser: fetching a page, finding the data you want, and saving it for later. In Python, this usually means three steps:
- Send an HTTP request (like your browser does when you visit a URL).
- Parse the HTML to find your target data.
- Export or process that data—maybe to a spreadsheet, database, or dashboard.
Here’s the twist: the tools you use (and the challenges you face) depend on the complexity of the site and your goals.
Python Scraping 101: How It Works
Think of scraping like sending a librarian to fetch a newspaper, then using scissors to cut out only the articles you care about. Python’s requests library is your librarian—it fetches the HTML. BeautifulSoup is your scissors—it lets you slice and dice the HTML to extract the good stuff.
But what if the newspaper is written in invisible ink (hello, JavaScript!) or the articles are scattered across dozens of pages? That’s when you need more advanced tools—or a bit of AI magic.
Comparing the Core Tools
Here’s a quick rundown of the main Python scraping tools and when to use them:
| Tool/Library | Use When... | Pros | Cons |
|---|---|---|---|
| Requests + BeautifulSoup | Scraping static pages or small jobs | Simple, fast, easy for beginners. Full control. | Doesn’t handle JavaScript or large-scale crawling. |
| Scrapy | Large-scale projects, many pages/sites | High performance, built-in crawling, async, pipelines, robust error handling. | Steeper learning curve, project setup overhead. |
| Selenium/Playwright | Pages require JavaScript, logins, or user actions | Can scrape anything a browser can see. Handles dynamic content, logins, infinite scrolls. | Slower, resource-intensive, more complex to deploy. |
| Thunderbit (AI) | Unstructured data, PDFs, images, or no-code needed | AI auto-detects fields, handles subpages, exports to Excel/Sheets, no coding required. | Less customizable for edge cases, credit-based usage. |
For most business users, starting with requests and BeautifulSoup is perfect for simple, static sites. For large or complex jobs, Scrapy is your friend. And when you hit a wall—dynamic content, anti-bot, or unstructured data—AI tools like Thunderbit can be a lifesaver.
Try Thunderbit AI Web Scraper for Free
Mapping the Terrain: Step-by-Step Best Practices for Complex Scraping
So, how do you go from “I want that data” to a robust, maintainable scraper? Here’s my battle-tested workflow:
1. Inspect and Understand the Target Site
Before you write a single line of code, open your browser’s Developer Tools (F12 or right-click > Inspect). Find the data you want in the HTML. Is it in a table? A series of <div>s? Is there a hidden API call returning JSON? Sometimes the easiest path is right under your nose.
Pro tip: If you see a network request fetching JSON when you click “next page” or “load more,” you can often skip HTML parsing and just call that API directly with Python.
2. Prototype on a Single Page
Start small. Use requests to fetch one page, then BeautifulSoup to extract a couple of fields. Print the results. If you get blocked or the data is missing, try adding headers (like a real browser’s User-Agent), or check if the content is loaded by JavaScript (in which case, see Step 3).
3. Handle Dynamic Content and Pagination
If the data isn’t in the HTML, it’s probably loaded by JavaScript. Here’s what to do:
- Browser Automation: Use Selenium or Playwright to open the page, wait for content, and grab the rendered HTML.
- API Calls: Look for XHR requests in the Network tab. If you find an endpoint returning JSON, replicate that call with
requests. - Pagination: For multi-page data, loop through page numbers or follow “Next” links. For infinite scroll, use Selenium to scroll down or mimic the API calls triggered by scrolling.
4. Robust Error Handling and Politeness
Websites are not always happy to see scrapers. To avoid getting blocked:
- Respect
robots.txt: Always checkexample.com/robots.txtfor disallowed paths or crawl delays. - Rate Limiting: Add
time.sleep()between requests. Ifrobots.txtsaysCrawl-delay: 5, wait at least 5 seconds. - Custom User-Agent: Identify your scraper politely (e.g.,
"MyScraper/1.0 (your@email.com)"). - Retry Logic: Wrap requests in try/except blocks. Retry on failures, back off if you get HTTP 429 (Too Many Requests).
5. Parse and Clean Data
Use BeautifulSoup or Scrapy selectors to extract fields. Clean up whitespace, convert prices to numbers, parse dates, and validate completeness. For big datasets, use pandas for cleaning and deduplication.
6. Subpage Scraping
Often, the real gold is on detail pages. Scrape a list of links, then visit each one to extract more info. In Python, this means looping through URLs and fetching each page. In Thunderbit, you can use the “Scrape Subpages” feature to automate this step—AI will visit each subpage and enrich your dataset.
7. Export and Automate
Export your clean data to CSV, Excel, Google Sheets, or a database. For recurring jobs, schedule your script with cron, Airflow, or (if you’re using Thunderbit) set up a scheduled cloud scrape with natural language (“every Monday at 9am”).
How to Scrape Website Data into Excel using AI Get Started Free
Thunderbit: When AI Supercharges Your Python Scraping Workflow
Let’s talk about the elephant in the room: sometimes, even the best Python code can’t handle messy, unstructured, or protected data. That’s where Thunderbit comes in.
How Thunderbit Complements Python
Thunderbit is an AI-powered Chrome extension that reads web pages (or PDFs, images, etc.) and outputs structured data—no code required. Here’s how I use it alongside Python:
- For Unstructured Data: If I hit a PDF, image, or a site with unpredictable HTML, I let Thunderbit’s AI parse it. It can extract tables from PDFs, pull text from images, and even suggest fields automatically.
- For Subpage and Multi-Step Scraping: Thunderbit’s “Scrape Subpages” feature is a huge time-saver. Scrape a list page, then let AI visit each detail page and merge the results—no need to write nested loops or manage state.
- For Export: Thunderbit exports directly to Excel, Google Sheets, Notion, or Airtable. I can then pull that data into my Python pipeline for further analysis or reporting.
Real-World Example: Python + Thunderbit in Action
Suppose I’m tracking real estate listings. I use Python and Scrapy to crawl listing URLs from several sites. But one site only posts detailed specs in downloadable PDFs. Instead of writing a custom PDF parser, I upload those files to Thunderbit, let its AI extract the tables, and export to CSV. Then, I merge all data in Python for a unified market analysis.
Or, say I’m building a lead list for sales. I use Python to scrape company URLs, then use Thunderbit’s email and phone extractors (free features!) to pull contact info from each site—no regex headaches required.
Scrape Unstructured Data with Thunderbit AI
Building a Maintainable Scraping Workflow: From Code to Pipeline
A one-off script is great for a quick win, but most business scraping needs are ongoing. Here’s how I structure a maintainable, scalable scraping stack:
The CCCD Framework: Crawl, Collect, Clean, Debug
- Crawl: Gather all target URLs (from sitemaps, search pages, or a list).
- Collect: Extract data from each URL (with Python, Thunderbit, or both).
- Clean: Normalize, deduplicate, and validate the data.
- Debug/Monitor: Log each run, handle errors, and set up alerts for failures or data anomalies.
Visualize this as a pipeline:
URLs → [Crawler] → [Scraper] → [Cleaner] → [Exporter] → [Business Platform]
Scheduling and Monitoring
- For Python: Use cron jobs, Airflow, or cloud schedulers to run scripts at intervals. Log output, send email or Slack alerts on errors.
- For Thunderbit: Use the built-in scheduler—just type “every Monday at 9am,” and Thunderbit will run the scrape in the cloud and export the data where you need it.
Documentation and Handoff
Keep your code in version control (Git), document your workflow, and make sure at least one other person knows how to run or update the pipeline. For mixed Python/Thunderbit workflows, note which tool handles which site and where the outputs land (e.g., “Thunderbit scrapes Site C to Google Sheets, Python merges all data weekly”).
Ethics and Compliance: Scraping Responsibly in 2025
With great scraping power comes great responsibility. Here’s how to stay on the right side of the law and good business practice:
Robots.txt and Rate Limiting
- Check robots.txt: Always review the site’s robots.txt for disallowed paths and crawl delays. Use Python’s
robotparserto automate checks. - Polite Scraping: Add delays between requests, especially if
Crawl-delayis specified. Never overwhelm a site with rapid-fire requests. - User-Agent: Identify your scraper honestly. Don’t pretend to be Googlebot or another browser.
Data Privacy and Compliance
- GDPR/CCPA: If you scrape personal data (names, emails, phone numbers), you’re responsible for handling it according to privacy laws. Only scrape what’s necessary, secure the data, and be ready to delete on request.
- Terms of Service: Don’t scrape behind logins unless you have permission. Many ToS prohibit automated access—violating them can get you banned or worse.
- Public Data Only: Stick to data that’s publicly available. Don’t try to scrape private, copyrighted, or sensitive information.
Compliance Checklist
- Checked robots.txt for rules and delays
- Added polite rate limiting and custom User-Agent
- Scraping only public, non-sensitive data
- Handling personal data in line with privacy laws
- Not violating site ToS or copyright
Common Errors and Debugging Tips: Making Your Scraping Robust
Even the best scrapers hit snags. Here are the most common issues—and how I tackle them:
| Error Type | Symptom/Message | Debugging Tip |
|---|---|---|
| HTTP 403/429/500 | Blocked, rate-limited, or server error | Check headers, slow down, rotate IPs, or use proxies. Respect crawl delays. |
| Missing Data/NoneType | Data not found in HTML | Print and inspect HTML. Maybe the structure changed, or you got a block page. |
| JavaScript-Rendered Data | Data missing in static HTML | Use Selenium/Playwright or find the underlying API call. |
| Parsing/Encoding Issues | Unicode errors, weird characters | Set correct encoding, use .text or html.unescape(). |
| Duplicates/Inconsistencies | Repeated or mismatched data | Deduplicate by unique ID or URL. Validate field completeness. |
| Anti-Bot/CAPTCHA | CAPTCHA page or login required | Slow down, use browser automation, or switch to Thunderbit/AI for tricky cases. |
Debugging Workflow:
- Print raw HTML when things break.
- Use browser DevTools to compare what your script sees vs. the browser.
- Log every step—URLs, status codes, number of items scraped.
- Test on a small sample before scaling up.
Advanced Project Ideas: Level Up Your Python Scraping
Ready to put best practices into action? Here are some real-world projects to try:
1. Price Monitoring Dashboard for E-commerce
Scrape prices and stock from Amazon, eBay, and Walmart. Handle anti-bot measures, dynamic content, and export daily to Google Sheets for trend analysis. Use Thunderbit’s instant templates for quick wins.
2. Job Listings Aggregator
Aggregate job postings from Indeed and niche boards. Parse titles, companies, locations, and posting dates. Handle pagination and deduplicate by job ID. Schedule daily runs and export to Airtable.
3. Contact Info Extractor for Lead Generation
Given a list of company URLs, extract emails and phone numbers from homepages and contact pages. Use regex in Python or Thunderbit’s free extractors for one-click results. Export to Excel for your sales team.
4. Real Estate Listings Comparer
Scrape listings from Zillow and Realtor.com for a specific region. Normalize addresses and prices, compare trends, and visualize results in Google Sheets.
5. Social Media Mentions Tracker
Track brand mentions on Reddit using their JSON API. Aggregate post counts, analyze sentiment, and export time-series data for marketing insights.
Conclusion: Key Takeaways for Python Scraping in 2025
Let’s recap the essentials:
- Web scraping is more vital than ever for business intelligence, sales, and operations. The web is a goldmine—if you know how to mine it.
- Python is your Swiss Army knife: Start simple with
requestsandBeautifulSoup, scale up with Scrapy, and use browser automation for dynamic sites. - AI tools like Thunderbit are your secret weapon for unstructured, complex, or no-code scraping. Combine Python and AI for maximum efficiency.
- Best practices matter: Inspect first, code modularly, handle errors, clean your data, and automate your workflow.
- Compliance isn’t optional: Always check robots.txt, respect privacy laws, and scrape ethically.
- Stay adaptable: The web changes—monitor your scrapers, debug often, and be ready to update your approach.
The future of web scraping is hybrid, ethical, and business-driven. Whether you’re a beginner or a seasoned pro, keep learning, stay curious, and let the data drive your next big win.
Appendix: Python Scraping Tutorial Resources & Tools
Here’s my go-to list for learning and troubleshooting:
- Requests Documentation – HTTP for Humans, with all the bells and whistles.
- BeautifulSoup Docs – Learn to parse HTML like a pro.
- Scrapy Documentation – For large-scale, production-grade scraping.
- Selenium with Python / Playwright for Python – For browser automation and dynamic content.
- Thunderbit Chrome Extension – The easiest AI web scraper for business users.
- Thunderbit Blog – Tutorials, case studies, and best practices for AI-powered scraping.
- AIMultiple’s Legal Guide – Stay up to date on compliance and ethics.
- Stack Overflow / Reddit r/webscraping** – Community Q&A and troubleshooting.
And if you want to see how Thunderbit can make your scraping life easier, check out our YouTube Channel for demos and deep dives.
FAQs
1. What’s the best Python library for web scraping in 2025?
For static pages and small jobs, requests + BeautifulSoup is still the go-to combo. For large-scale or multi-page scraping, Scrapy is best. For dynamic content, use Selenium or Playwright. For unstructured or tricky data, AI tools like Thunderbit are invaluable.
2. How do I handle JavaScript-heavy or dynamic sites?
Use browser automation tools like Selenium or Playwright to render the page and extract data. Alternatively, inspect the Network tab for API calls that return JSON—these are often easier and more reliable to scrape.
3. Is web scraping legal?
Scraping public data is generally legal in the US, but always check robots.txt, respect site terms, and comply with privacy laws like GDPR/CCPA. Never scrape private, copyrighted, or sensitive information.
4. How can I automate and schedule my scraping workflows?
For Python scripts, use cron jobs, Airflow, or cloud schedulers. For no-code automation, Thunderbit offers built-in scheduling—just describe your schedule in plain English and let it run in the cloud.
5. What should I do if my scraper stops working?
First, check if the website structure changed or if you’re being blocked (HTTP 403/429). Inspect the HTML, update your selectors, slow down your requests, and check for anti-bot measures. For persistent issues, consider using Thunderbit’s AI features or switching to browser automation.
Happy scraping—and may your data always be clean, compliant, and ready for action. If you want to see how Thunderbit can fit into your workflow, download the Chrome extension and give it a spin. And if you’re hungry for more tips, the Thunderbit Blog is always open for business.
Try Thunderbit AI Web Scraper for Free Get Started Free




