

A few years ago, if you’d asked me how to automate a web task—say, scraping product prices from a competitor’s site or running a bunch of UI tests—I’d have pointed you straight to Selenium or Puppeteer, handed you a stack of code samples, and wished you luck. Fast forward to today, and the landscape has shifted. The demand for browser automation and web data extraction has exploded, especially in sales, marketing, ecommerce, and real estate. Everyone wants web data, but not everyone wants to become a part-time developer just to get it.
The truth is, while tools like Puppeteer, Selenium, and Playwright are still the backbone of browser automation for many technical teams, business users are looking for something different: solutions that don’t require code, don’t break every time a web page changes, and don’t mean waiting in line for engineering help. That’s where AI-powered, no-code tools like Thunderbit are starting to turn heads. But before we dive into the future, let’s get a handle on the classics—and why the shift is happening.
What Is Puppeteer? A Quick Primer
Let’s start with Puppeteer. If you’ve ever wanted to control Chrome or Chromium with code—think opening pages, clicking buttons, taking screenshots, or scraping data—Puppeteer is your go-to Node.js library. It’s like having a remote control for your browser, but instead of a bunch of buttons, you write JavaScript.
Main use cases for Puppeteer:
- Automated end-to-end testing for web apps (think: “Does my checkout flow still work?”)
- Web scraping—extracting data from sites that don’t offer APIs
- Generating screenshots or PDFs of web pages (great for archiving or reporting)
- Simulating user interactions for performance audits or SEO checks
Puppeteer’s real strength is its tight integration with Chrome. It speaks the browser’s language, so it’s fast, reliable, and can handle all the modern web bells and whistles—single-page apps, dynamic content, you name it. But, and this is a big but, it’s basically Chrome-only. If you want to automate Firefox or Safari, you’re out of luck.
What Is Selenium? The Veteran of Browser Automation
Now, Selenium is the OG of browser automation. It’s been around since the days when “Web 2.0” was still a buzzword. Selenium isn’t just a library—it’s a whole ecosystem, with support for multiple programming languages (Python, Java, C#, JavaScript, Ruby, and more) and pretty much every major browser (Chrome, Firefox, Safari, Edge, even Internet Explorer if you’re feeling nostalgic).
What makes Selenium stand out:
- Multi-language support: Use your favorite language—no need to learn JavaScript if you’re a Pythonista.
- Multi-browser compatibility: Automate Chrome, Firefox, Safari, Edge, and more.
- Large community and ecosystem: Tons of tutorials, plugins, and integrations.
- UI testing at scale: It’s the backbone of automated testing for many QA teams.
But here’s the catch: Selenium’s architecture is a bit old-school. It uses a “driver + API” model, which means you’re always juggling drivers, browser versions, and sometimes, a fair bit of troubleshooting. It’s powerful, but it can feel like driving a stick shift in a world of Teslas.
Puppeteer vs Selenium: Core Differences Explained
So, how do Puppeteer and Selenium stack up? Let’s break it down.
| Feature | Puppeteer | Selenium |
|---|---|---|
| Language Support | JavaScript/Node.js only | Multiple (Python, Java, C#, JS, Ruby, etc.) |
| Browser Support | Chrome/Chromium (experimental Firefox) | Chrome, Firefox, Safari, Edge, IE |
| Performance | Fast, optimized for Chrome | Good, but can be slower due to abstraction |
| Ease of Use | Simpler API, modern syntax | More complex, steeper learning curve |
| Community/Ecosystem | Growing, but smaller than Selenium | Huge, mature, lots of resources |
| Use Cases | Testing, scraping, screenshots, PDFs | Testing, scraping, automation |
Architecture-wise:
- Both use a “driver + API” approach.
- Puppeteer is Chrome-centric, tightly coupled with the browser’s DevTools protocol.
- Selenium is browser-agnostic, using WebDriver for cross-browser support.
Bottom line:
If you’re all-in on Chrome and love JavaScript, Puppeteer is slick and speedy. If you need flexibility—different browsers, different languages—Selenium is your workhorse. But both require you to write and maintain scripts, and neither really “understands” the web page beyond the DOM.
Playwright: The Next-Gen Alternative to Puppeteer
Enter Playwright, Microsoft’s answer to the modern web’s automation needs. If Puppeteer is a high-performance sports car for Chrome, Playwright is the all-wheel-drive SUV that handles any terrain.
Why Playwright is getting so much love:
- True cross-browser support: Chrome, Firefox, Safari, Edge—all from one API.
- Built-in concurrency: Run multiple browser contexts in parallel, perfect for CI/CD pipelines.
- Robust auto-waiting: No more writing endless “wait for element” hacks—Playwright auto-waits for elements to be ready.
- Powerful selectors: Target elements by text, role, or even ARIA attributes.
- Modern features: Native support for handling downloads, uploads, geolocation, permissions, and more.
I’ve seen Playwright adopted like wildfire in teams that need reliable, fast, and maintainable tests—especially in continuous integration and deployment (CI/CD) setups. It’s also great for scraping, but, like Puppeteer and Selenium, it’s still a code-first tool. If you’re not comfortable writing scripts, you’ll hit a wall.
Playwright Alternatives: What Else Is Out There?
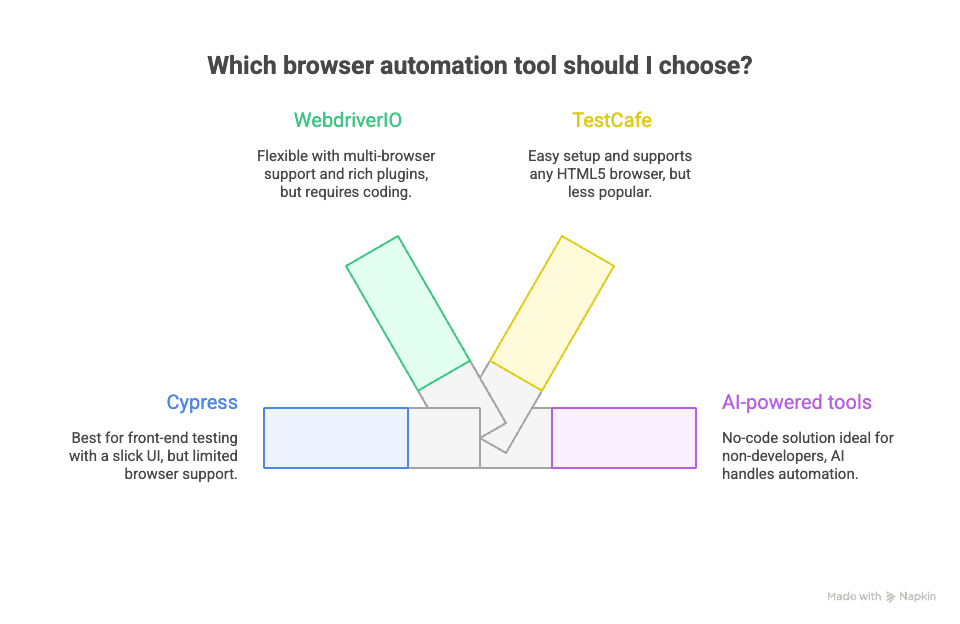
Let’s be honest: the browser automation space is crowded. Here are some other names you’ll hear, and how they stack up:
-
Cypress:
Focused on front-end testing, Cypress offers a slick UI and great developer experience, but it’s limited to Chrome-family browsers and doesn’t handle multi-tab or cross-origin well. It’s fantastic for testing, less so for scraping or automation outside of tests. Learn more about Cypress.
-
WebdriverIO:
A Node.js implementation of the WebDriver protocol, WebdriverIO is flexible, supports multiple browsers, and has a rich plugin ecosystem. It’s used for both testing and scraping, but again, you’re writing code. WebdriverIO official site.
-
TestCafe:
Another JavaScript-based tool, TestCafe is easy to set up and runs tests in any browser that supports HTML5. It’s less popular than Cypress or Playwright, but worth a look for simple test automation. TestCafe official site.
-
AI-powered tools like Thunderbit:
This is where things get interesting for business users. Thunderbit takes a totally different approach: no code, no scripts, just point, click, and let AI do the heavy lifting. I’ll dig into how this works in a minute, but suffice it to say, if you’re not a developer, this is the direction you’ll want to watch.
Summary Table: Code vs. No-Code Automation Tools
| Tool | Browser Support | Language(s) | Coding Required | Best For |
|---|---|---|---|---|
| Puppeteer | Chrome/Chromium | JavaScript | Yes | Devs, Chrome automation |
| Selenium | All major browsers | Many | Yes | Devs, cross-browser testing |
| Playwright | All major browsers | JavaScript, etc. | Yes | Modern automation, CI/CD |
| Cypress | Chrome-family | JavaScript | Yes | Front-end testing |
| WebdriverIO | All major browsers | JavaScript | Yes | Flexible automation |
| TestCafe | All major browsers | JavaScript | Yes | Simple test automation |
| Thunderbit | All major browsers* | N/A (No code) | No | Business users, scraping |
- Thunderbit runs in your browser, so it works wherever Chrome does.
From “Browser Automation” to “Intelligent Scraping”: The Thunderbit Approach
Scrape data from any website using AI Get Started Free
Here’s where my inner automation nerd gets excited. Traditional frameworks like Puppeteer, Selenium, and Playwright all work by manipulating the DOM—using selectors to find elements, clicking buttons, and scraping text. But they don’t actually “understand” what’s on the page. Change a class name, move a button, or load content asynchronously, and your script can break faster than you can say “selector not found.”
Thunderbit flips this on its head. Instead of just poking at the DOM, Thunderbit’s AI reads the page like a human would. It first converts the web page into a structured Markdown format, then feeds that to an AI model for semantic understanding. The AI figures out the context, the meaning of fields, and the logic of the data—so it knows the difference between a product name, a price, and a review, even if the HTML is a mess.
What does this mean in practice?
- Stable scraping on complex or dynamic pages: Pages with infinite scroll, pop-ups, or user-generated content? No problem.
- No more selector headaches: The AI adapts to layout changes, so you’re not rewriting scripts every time the site updates.
- Semantic extraction: Thunderbit can pull structured data (like tables, lists, or nested info) even from pages that look like chaos to a traditional scraper.
I’ve seen Thunderbit handle Facebook Marketplace, long-form comment sections, and ecommerce sites with dynamic content—scenarios that make most code-based scrapers cry uncle. And it does it all with a couple of clicks.
Why Business Teams Need No-Code, Semantic Web Scraping
What Is Data Scraping and How to Do It in 2025 Get Started Free
Let’s get real: most sales, marketing, ecommerce, and real estate teams don’t have a developer on speed dial. And even if they do, that developer is probably busy with “higher priority” work. Here’s what usually happens with code-based tools:
- Script maintenance hell: Every time a site changes, someone has to update selectors or rewrite scripts.
- Developer dependency: Non-technical users are stuck waiting for engineering help.
- Steep learning curve: Even “simple” automation frameworks require time to learn and debug.
- Fragile workflows: One small change on the target site, and the whole process breaks.
Thunderbit was built to solve these pain points. Here’s how:
- 2-Click Scraping: Just click “AI Suggest Fields” and then “Scrape.” The AI figures out what to extract.
- AI Suggest Fields: Thunderbit reads the page and recommends the right columns and data types.
- Subpage Scraping: Need data from linked pages (like product details or reviews)? Thunderbit can visit each subpage and enrich your table automatically.
- No code, no scripts: Anyone can use it—no technical background required.
Business User Experience Comparison Table
| Feature | Puppeteer/Selenium/Playwright | Thunderbit |
|---|---|---|
| Coding Required | Yes | No |
| Script Maintenance | Frequent | None (AI adapts) |
| Handles Dynamic Content | Manual scripting | AI semantic understanding |
| Subpage/Linked Data | Custom code | 1-click Subpage Scraping |
| Data Export (Excel, Sheets) | Manual parsing | Built-in, free export |
| Learning Curve | Steep | Minimal |
| Best For | Developers, QA | Sales, Marketing, Ops, Real Estate |
When to Use Puppeteer, Selenium, Playwright, or Thunderbit? (Decision Guide)
So, which tool should you actually use? Here’s my take, based on years of building automation for both technical and business teams:
Use Puppeteer, Selenium, or Playwright if:
- You have dedicated developers or QA engineers.
- You need highly customized workflows (e.g., complex test automation, custom browser interactions).
- You require integration with CI/CD pipelines or automated testing frameworks.
- Your team is comfortable maintaining code and handling script breakage.
Use Thunderbit if:
- You want to extract data from websites quickly, with no code.
- Your team is in sales, marketing, ecommerce, or real estate, and you need data now—not after a sprint.
- You’re tired of scripts breaking every time a site changes.
- You need to handle complex, dynamic, or frequently changing web pages.
- You want to export data directly to Excel, Google Sheets, Airtable, or Notion.
Decision Matrix
| Scenario | Best Tool(s) |
|---|---|
| Custom browser automation | Playwright, Puppeteer |
| Cross-browser UI testing | Selenium, Playwright |
| No-code web scraping | Thunderbit |
| Dynamic, changing web pages | Thunderbit |
| Business team, no devs | Thunderbit |
| Deep integration with CI/CD | Playwright, Selenium |
Try Thunderbit AI Web Scraper for Free
The Future: Combining Automation Frameworks with AI-Powered Scraping
Here’s where things get exciting. The old world of “browser automation” is merging with the new world of “intelligent scraping.” I see a future where technical and business teams don’t have to choose between code and no-code—they can have both.
Hybrid workflows are on the rise:
- Developers can use frameworks like Playwright for custom automation, but plug in AI-powered modules for semantic data extraction.
- Business users can start with no-code tools like Thunderbit, but escalate to code-based solutions when they need deep customization.
- AI models are getting better at understanding web page structure, context, and even intent—making scraping more reliable and less brittle.
Organizations that plan for this evolution—building workflows that are both programmable and accessible to non-technical users—will be more agile, more data-driven, and a lot less frustrated.
Conclusion: Choosing the Right Tool for Your Business
To sum it up:
- Puppeteer is a fast, Chrome-focused automation tool for JavaScript devs.
- Selenium is the cross-browser, multi-language veteran—powerful but a bit old-school.
- Playwright is the modern, cross-browser, concurrency-friendly alternative, great for CI/CD and advanced automation.
- Thunderbit is the no-code, AI-powered solution for business users who want reliable, semantic web scraping without the hassle.
The real question isn’t which tool is “best”—it’s which tool fits your team’s skills, needs, and appetite for maintenance. If you’re a developer building custom workflows, the classic frameworks are still your friends. But if you’re a business user who just wants data—fast, accurate, and without the headaches—Thunderbit is worth a serious look.
And if you’re curious about the future of web scraping and automation, keep an eye on how AI is reshaping the field. We’re moving from “click this, wait for that” scripts to tools that actually understand the web—making data extraction smarter, faster, and a whole lot more fun.
Want to see more about how AI is changing web scraping? Check out some of our other guides on the Thunderbit Blog, like What Is Data Scraping and How to Do It in 2025 or How to Scrape Any Website Using AI.
And if you’re ready to try no-code, AI-powered scraping for yourself, grab the Thunderbit Chrome Extension and see what intelligent automation feels like. Your future self (and your data-hungry team) will thank you.
Get Started with Thunderbit AI Web Scraper
FAQs
1. What are the main differences between Puppeteer and Selenium?
Puppeteer is a Node.js library designed primarily for automating Chrome and Chromium browsers, offering a simple, modern API for tasks like UI testing, scraping, and generating screenshots or PDFs. Selenium, on the other hand, is a more mature, cross-browser automation framework that supports multiple programming languages and all major browsers. While Puppeteer is faster and easier to use for Chrome-specific tasks, Selenium offers greater flexibility for cross-browser testing and has a larger community and ecosystem.
2. How does Playwright improve upon Puppeteer and Selenium?
Playwright, developed by Microsoft, builds on the strengths of Puppeteer by offering true cross-browser support (Chrome, Firefox, Safari, Edge) from a single API. It introduces features like built-in concurrency, robust auto-waiting for elements, and powerful selectors. Playwright is particularly popular for modern web app testing and automation in CI/CD pipelines, providing a more reliable and maintainable experience compared to its predecessors.
3. What are the advantages of using no-code, AI-powered tools like Thunderbit for web scraping?
No-code, AI-powered tools like Thunderbit are designed for business users who need web data quickly and without technical hurdles. Thunderbit uses AI to semantically understand web pages, making it resilient to layout changes and dynamic content. Users can extract structured data with just a few clicks, without writing or maintaining scripts. This approach eliminates common pain points such as script breakage, developer dependency, and steep learning curves.
4. When should I choose a code-based tool (like Puppeteer, Selenium, or Playwright) over a no-code solution like Thunderbit?
Code-based tools are best suited for teams with dedicated developers or QA engineers who need highly customized workflows, deep integration with CI/CD pipelines, or advanced browser automation. If your project requires complex test automation, custom browser interactions, or support for multiple programming languages and browsers, these frameworks are ideal. No-code solutions like Thunderbit are preferable when quick, reliable data extraction is needed by non-technical users, especially in business contexts.
5. What does the future hold for browser automation and web scraping tools?
The future of browser automation is moving toward a hybrid model that combines the programmability of traditional frameworks with the intelligence and accessibility of AI-powered, no-code tools. As AI models become better at understanding web page structure and context, both technical and business users will benefit from more robust, less brittle automation workflows. Organizations that embrace both code-based and no-code solutions will be more agile and data-driven.
Learn More:
- How to Scrape Any Website Using AI
- Convert Images to Excel: JPG to Word and Text Guide
- MAP Pricing Enforcement: A Complete Monitoring Guide
- Puppeteer vs Selenium: Which to Choose
Try AI Web Scraper Get Started Free




