

The web is a wild place in 2026—half of all internet traffic is now bots, and open-source web crawlers are the unsung heroes behind the scenes, powering everything from price monitoring to AI training. I’ve spent years in SaaS and automation, and if there’s one thing I’ve learned, it’s that picking the right self-hosted crawler can save your team months of headaches (and maybe a few late-night debugging sessions). Whether you’re scraping a handful of product pages or crawling millions of URLs for research, the open-source Firecrawl alternatives on this list have you covered—no matter your scale, tech stack, or appetite for complexity.
But here’s the twist: there’s no one-size-fits-all solution. Some teams need the raw horsepower of Scrapy or the archival muscle of Heritrix, while others might find the maintenance of open-source libraries too costly. So, let’s break down the top 9 open-source Firecrawl alternatives for 2026, show you where each one shines, and help you match the right tool to your business needs—without the trial-and-error pain.
How to Choose the Best Open-Source Firecrawl Alternative for Your Business
Before you dive into the list, let’s talk strategy. The open-source web crawling landscape is more diverse than ever, and your choice should depend on a few key factors:
- Ease of Use: Do you want a point-and-click interface, or are you comfortable writing Python, Go, or JavaScript?
- Scalability: Are you scraping a single site, or do you need to crawl millions of pages across hundreds of domains?
- Content Type: Is your target site static HTML, or does it rely on heavy JavaScript and dynamic loading?
- Integration Needs: How do you want to use the data—export to Excel, push to a database, or feed it into an analytics pipeline?
- Maintenance: Do you have the resources to maintain custom code, or do you want a tool that adapts to site changes automatically?
Here’s a quick cheat sheet to help you decide:
| Scenario | Best Tool(s) |
|---|---|
| No-code, offline browsing | HTTrack |
| Large-scale, multi-domain crawl | Scrapy, Apache Nutch, StormCrawler |
| Dynamic/JS-heavy sites | Puppeteer |
| Form automation/login required | MechanicalSoup |
| Static site download/archiving | Wget, HTTrack, Heritrix |
| Go developer, high performance | Colly |
Now, let’s dive into the top 9 open-source Firecrawl alternatives for 2026.
1. Scrapy: Best for Large-Scale Python Crawling

Scrapy is the heavyweight champion of open-source web crawling. Built in Python, it’s the framework of choice for developers who need to crawl at scale—think millions of pages, frequent updates, and complex site logic.
Why Scrapy?
- Massive Scale: Scrapy can handle thousands of requests per second, and is used by companies scraping billions of pages per month (Zyte).
- Extensible & Modular: Write custom spiders, plug in middleware for proxies, handle logins, and output to JSON, CSV, or databases.
- Active Community: Tons of plugins, documentation, and Stack Overflow answers.
- Battle-Tested: Used in production by e-commerce, news, and research teams worldwide.
Limitations: Steep learning curve for non-developers, and you’ll need to maintain your spiders as websites change. But if you want total control and scalability, Scrapy is hard to beat.
2. Apache Nutch: Best for Enterprise Search Engines
Apache Nutch is the granddaddy of open-source crawlers, designed for enterprise-grade, internet-scale crawling. If you dream of building your own search engine or crawling millions of domains, Nutch is your friend.
Why Apache Nutch?
- Hadoop-Powered Scale: Built on Hadoop, Nutch can crawl billions of pages across clusters of servers (Common Crawl uses it to crawl the public web).
- Batch Crawling: Feed it a list of seed URLs and let it run—great for scheduled, large-scale jobs.
- Integration: Works with Solr, Elasticsearch, and big data pipelines.
Limitations: Complex setup (think Hadoop clusters, Java config files), and it’s more about raw crawling than extracting structured data. Overkill for small projects, but unmatched for web-scale crawling.
3. Heritrix: Best for Web Archiving & Compliance
Heritrix is the Internet Archive’s own crawler, purpose-built for web archiving and digital preservation.
Why Heritrix?
- Archival-Grade Completeness: Captures every page, asset, and link—perfect for legal compliance or historical snapshots.
- WARC Output: Stores everything in standardized Web ARChive files, ready for replay or analysis.
- Web-Based Admin: Configure and monitor crawls through a browser UI.
Limitations: Heavyweight (needs lots of disk and memory), doesn’t execute JavaScript, and outputs raw archives rather than structured data tables. Best for libraries, archives, or regulated industries.
4. Colly: Best for High-Performance Go Developers
Colly is the darling of Go developers—a fast, lightweight, and highly concurrent web scraper.
Why Colly?
- Blazing Fast: Go’s concurrency lets Colly scrape thousands of pages with minimal CPU/RAM (Oxylabs).
- Simple API: Define callbacks for HTML elements, handle cookies and robots.txt automatically.
- Great for Static Sites: Perfect for server-rendered pages, APIs, or when you want to integrate scraping into a Go backend.
Limitations: No built-in JavaScript rendering (for dynamic sites, you’ll need to pair it with something like Chromedp), and you’ll need to know Go.
5. MechanicalSoup: Best for Simple Form Automation

MechanicalSoup is a Python library that bridges the gap between simple HTTP requests and full browser automation.
Why MechanicalSoup?
- Form Automation: Easily log in, fill out forms, and maintain sessions—great for scraping behind authentication.
- Lightweight: Uses Requests and BeautifulSoup under the hood, so it’s fast and easy to set up.
- Perfect for Interactive Sites: If you need to submit search forms or scrape data after login, MechanicalSoup is a great choice (Apify Blog).
Limitations: No JavaScript execution, so it won’t work on JS-heavy sites. Best for static or server-rendered pages with simple interactions.
6. Puppeteer: Best for Dynamic & JavaScript-Heavy Sites
Puppeteer is the Swiss Army knife for scraping modern, JavaScript-heavy websites. It’s a Node.js library that gives you full control over a headless Chrome browser.
Why Puppeteer?
- Handles Dynamic Content: Scrape SPAs, infinite scroll, and pages that load data via AJAX (Browserless Guide).
- User Simulation: Click buttons, fill forms, take screenshots, and even solve CAPTCHAs (with plugins).
- Powerful Automation: Great for testing, monitoring, and scraping anything a real user can see.
Limitations: Resource-intensive (runs full Chrome instances), slower than HTTP-only scrapers, and scaling requires robust hardware or cloud orchestration.
7. Wget: Best for Quick Command-Line Downloads

Wget is the classic command-line tool for downloading static websites and files.
Why Wget?
- Simplicity: Download entire sites or directories with a single command—no coding required.
- Speed: Written in C, it’s fast and efficient.
- Great for Static Content: Perfect for documentation sites, blogs, or bulk file downloads (HuggingFace Guide).
Limitations: No JavaScript execution or form handling, and it downloads raw pages (not structured data). Think of it as a digital vacuum cleaner for static sites.
8. HTTrack: Best for Offline Browsing (No-Code)
HTTrack is the user-friendly cousin of Wget, offering a graphical interface for mirroring websites.
Why HTTrack?
- GUI Simplicity: Step-by-step wizard makes it accessible for non-technical users.
- Offline Browsing: Adjusts links so you can browse mirrored sites locally.
- Great for Archiving: Perfect for researchers, marketers, or anyone who wants a snapshot of a site without coding (Reddit DataHoarder).
Limitations: No dynamic content support, can be slow on large sites, and isn’t designed for structured data extraction.
9. StormCrawler: Best for Real-Time Distributed Crawling

StormCrawler is the modern, distributed crawler for teams who need real-time, continuous web data at scale.
Why StormCrawler?
- Real-Time Crawling: Built on Apache Storm, it processes data as streams—great for news monitoring or search engines (Wikipedia).
- Modular & Scalable: Add parsing, indexing, and custom processing bolts as needed.
- Used by Common Crawl: Powers the news dataset for one of the largest open web archives.
Limitations: Requires Java development and a Storm cluster, so it’s best for teams with distributed systems experience. Overkill for small projects.
Comparing Open-Source Firecrawl Alternatives: Which Free Competitor Fits Your Needs?
Here’s a side-by-side look at all 9 tools:
| Tool | Best Use Case | Key Advantages | Drawbacks | Language / Setup |
|---|---|---|---|---|
| Scrapy | Large-scale, frequent crawling | Powerful, scalable, huge community | Steep learning curve, Python required | Python framework |
| Apache Nutch | Enterprise, web-scale crawling | Hadoop-powered, proven at scale | Complex setup, batch-oriented | Java/Hadoop |
| Heritrix | Archival, compliance crawling | Complete site capture, WARC output | Heavy, no JS, raw archives | Java app, web UI |
| Colly | Go devs, high-performance scraping | Fast, simple API, concurrency | No JS, Go required | Go library |
| MechanicalSoup | Form automation, login scraping | Lightweight, session handling | No JS, limited scale | Python library |
| Puppeteer | Dynamic/JS-heavy sites | Full browser control, automation | Resource-intensive, Node.js required | Node.js library |
| Wget | Static site download, offline access | Simple, fast, CLI | No JS, raw pages | Command-line tool |
| HTTrack | Non-tech users, site archiving | GUI, easy offline browsing | No JS, slow on big sites | Desktop app (GUI) |
| StormCrawler | Real-time, distributed crawling | Scalable, modular, real-time | Java/Storm expertise needed | Java/Storm cluster |
Should You Build Your Own or Use an Existing Open-Source Firecrawl Alternative?
Here’s the honest truth: building your own crawler sounds fun—until you’re knee-deep in maintenance, proxies, and anti-bot headaches. The open-source tools above encapsulate years of hard-won experience and community wisdom. According to industry reports, using existing solutions is the fastest, most reliable way to get results and avoid reinventing the wheel (IveerData).
- Adopt open-source if: Your needs align with what’s already out there, you want to reduce development time, and you value community support.
- Build your own if: You have truly unique requirements, deep in-house expertise, and scraping is core to your business.
However, open-source isn't "free" when you calculate the cost of engineering time, server maintenance, and constant updates to fight anti-scraping measures. If you want the benefits of a powerful crawler without the code, there is one more option.
Bonus: When Open-Source is Too Complex, Try Thunderbit
While the tools listed above are incredible for developers, they all share common limitations: they require coding knowledge, they struggle with dynamic AI-based anti-bots, and they need constant maintenance.
Thunderbit is my go-to recommendation for anyone who needs to bypass these limitations. It bridges the gap between powerful scraping and ease of use.
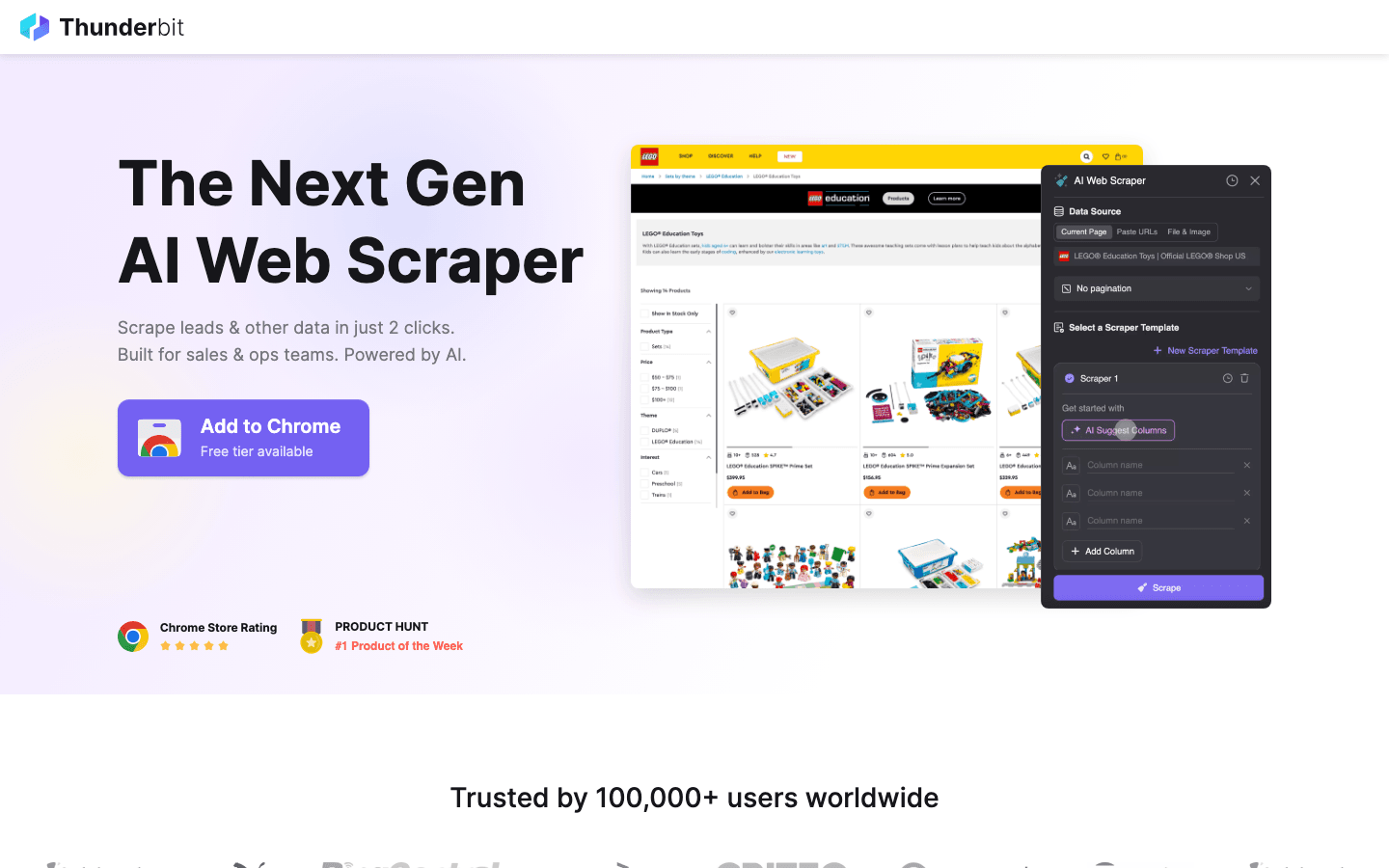
Why Consider Thunderbit over Open-Source?
- Zero Coding Required: Unlike Scrapy or Puppeteer, Thunderbit is an AI-powered Chrome Extension. You click “AI Suggest Fields,” and it builds the scraper for you.
- Handles the Hard Stuff: Dynamic content, infinite scrolling, and pagination are handled automatically by AI, saving you hours of writing custom scripts.
- Instant Export: Go from website to Excel, Google Sheets, or Notion in two clicks.
- No Maintenance: You don't need to update your code when a website changes its layout—Thunderbit’s AI adapts for you.
If you are a sales rep, marketer, or researcher who wants data now without learning Python or Go, Thunderbit is the perfect complement to the open-source tools on this list.
Want to see it in action? Download the Chrome Extension and try it for yourself.
Conclusion: Finding the Right Self-Hosted Web Crawler for 2026
Read more web scraping guides Get Started Free
The world of open-source Firecrawl alternatives is richer than ever. Whether you need the raw scale of Scrapy or Nutch, or the archival fidelity of Heritrix, there’s a solution for every business scenario. The key is to match your tool to your needs—don’t over-engineer if you just need a quick data grab, and don’t under-invest if you’re crawling at internet scale.
And remember, if the open-source route proves too technical or time-consuming, AI tools like Thunderbit are ready to pick up the slack.
Ready to get started? Spin up Scrapy for your next big data project, or Try Thunderbit for simple, AI-powered scraping. If you’re hungry for more web scraping tips, check out the Thunderbit Blog for deep dives and tutorials.
Try Thunderbit for AI-Powered Web Scraping
FAQs
1. What is the main advantage of using open-source Firecrawl alternatives? Open-source alternatives offer flexibility, cost savings, and the ability to self-host and customize your crawler. You avoid vendor lock-in and benefit from active community support and updates.
2. Which tool is best for non-technical users who need quick results? HTTrack is a solid open-source choice for offline browsing. However, for structured data extraction (like Excel tables), we recommend the bonus tool Thunderbit due to its AI capabilities.
3. How do I handle dynamic, JavaScript-heavy websites? Puppeteer is your best bet—it controls a real browser, so it can scrape anything a user can see, including SPAs and AJAX-loaded content.
4. When should I use a heavyweight crawler like Apache Nutch or StormCrawler? If you need to crawl millions of pages across many domains, or require real-time, distributed crawling (like for search engines or news monitoring), these tools are built for scale and reliability.
5. Is it better to build my own crawler or use an existing open-source solution? For most teams, using and customizing an existing open-source tool is faster, cheaper, and more reliable. Only build your own if you have highly specialized needs and the resources to maintain it long-term.
Happy crawling—and may your data always be fresh, structured, and ready for action.
Try Thunderbit AI Web Scraper for Free Get Started Free
Learn More




