
Every Node.js fetch tutorial teaches you await fetch(url) and calls it a day. Then your production app silently swallows a 500 error, a request hangs for 90 seconds with no timeout, and you spend a Friday night debugging something that should have been obvious.
I've been building internal tools and data pipelines at for a while now, and I can tell you: the gap between "fetch works in my tutorial" and "fetch works in production" is where most of the pain lives. A developer on Reddit put it perfectly: "when you go into production, you realise you need something more resilient than the native fetch."
Another confessed, "Worked for 3 years as a web developer, TIL the fetch API's catch block is NOT for HTTP errors." This guide covers the five things most tutorials skip — the error trap, AbortController timeouts, retry logic, connection reuse, and when to move beyond fetch for structured data extraction. If you've ever had a fetch call fail silently in production, this one's for you.
What Is the Node.js Fetch API?
The Node.js Fetch API is the built-in, browser-compatible way to make HTTP requests (GET, POST, PUT, DELETE, etc.) from Node.js — without installing Axios, node-fetch, or any other package. If you've used fetch() in the browser, you already know the syntax. Now the same API works on the server.
Here's the quick version history:
| Milestone | Node Version | What happened |
|---|---|---|
| Experimental fetch flag | v17.5.0 / v16.15.0 | fetch added behind --experimental-fetch |
| Default global fetch | v18.0.0 | Experimental fetch available globally, powered by Undici |
| Stable fetch | v21.0.0 | No longer experimental |
| 2026 production baseline | v22 LTS / v24 LTS | Recommended for production; v20 is now EOL |
Under the hood, Node's fetch is powered by Undici — a high-performance HTTP client built specifically for Node.js. It does not rely on the older built-in http module. The practical benefit: you get a modern, Promise-based HTTP API that works the same way in your browser code, your Express backend, your serverless function, and your CLI scripts.
Why the Node.js Fetch API Matters for Your Projects
Before Node 18, every new project started with the same ritual: npm install axios or npm install node-fetch. In 2026, if your project runs on a maintained Node LTS, basic HTTP requests require zero dependencies. That's a real win for bundle size, supply-chain security, and onboarding (front-end and back-end developers finally share the same API).
Here's where native fetch shines:
| Scenario | Why native fetch works well | Production caveat |
|---|---|---|
| Express/Fastify backend calling REST APIs | Familiar async/await, no dependency | Add timeout and response.ok checks |
| Serverless functions (Lambda, Vercel, etc.) | Small cold-start surface, no package install | Keep timeout below platform max duration |
| CLI scripts and automations | Simple GET/POST without project setup | Add retry/backoff for flaky APIs |
| Webhook delivery or forwarding | Standard HTTP methods and headers | Don't blindly retry non-idempotent POSTs |
| Reports and dashboards | Good for pulling JSON from APIs | Use pagination and connection pooling for loops |
| Microservice communication | Works for simple internal HTTP calls | Consider Got or Undici directly for retry, hooks, or HTTP/2 |
For new Node 22+ projects, native fetch is the sensible default — unless you know you need features it doesn't provide (interceptors, built-in retry, HTTP/2, etc.). The npm download numbers tell the story of a landscape in transition: , but much of that is legacy and transitive dependencies. , , , and . The trend is clear: native fetch is the new baseline, and third-party clients are for specific needs.
Native Fetch vs node-fetch vs Axios vs Got vs Ky: The 2026 Decision Matrix
The most common question I see in developer forums: "Which HTTP client should I use in Node.js?" One Reddit user summed it up: "why import a library…when the language/framework has functionality built in?" Fair point — but the answer depends on what you need.
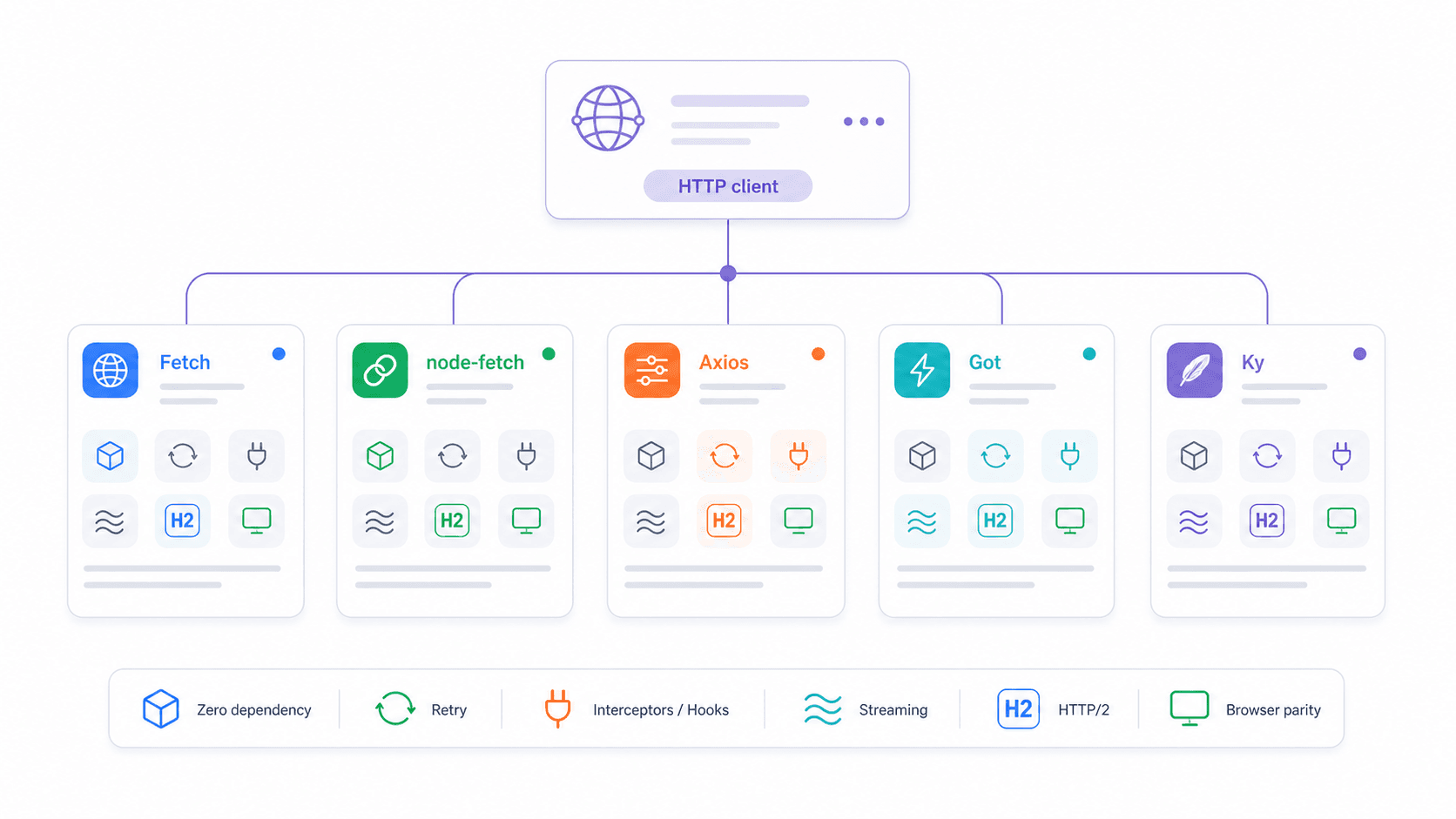
| Feature | Native fetch | node-fetch v3 | axios | got v15 | ky v2 |
|---|---|---|---|---|---|
| Node.js version | ≥18 (recommend 22/24 LTS) | ≥12.20 | Broad | ≥22 | ≥22 |
| Install required | No | Yes | Yes | Yes | Yes |
| ESM + CJS support | Both (global) | ESM-only (v3) | Both | ESM-only | ESM-only |
| Auto-reject on 4xx/5xx | No | No | Yes | Yes | Yes |
| Built-in retry | No | No | No | Yes | Yes |
| Request interceptors | No | No | Yes | Yes (hooks) | Yes (hooks) |
| Streaming support | Web ReadableStream | Yes | Limited | Strong Node streams | Fetch-based |
| Bundle/install footprint | 0 KB | ~107 KB, 3 deps | ~2.8 MB, 4 deps | ~355 KB, 12 deps | ~405 KB, 0 deps |
| HTTP/2 support | Via Undici dispatcher | No | No | Yes | No (fetch wrapper) |
A quick note on the ESM/CJS headache: node-fetch v3 is ESM-only, which broke a lot of projects that used require(). Native fetch is global — it works in both CJS and ESM files without any import gymnastics. If you're stuck on node-fetch v2 because of CommonJS, native fetch solves that problem entirely.
And about early stability concerns: yes, there were real bugs in Node 18's initial fetch implementation. One developer on Reddit mentioned "Had a wild bug with native node 18 fetch recently so had to convert our app." That was 2023. In 2026, with Node 22 and 24 LTS, those issues are resolved. Native fetch is production-ready.
When to Stick with Native Fetch
Go with native fetch when:
- Your project runs on Node 22 LTS or Node 24 LTS.
- Requests are straightforward REST calls (GET, POST, PUT, DELETE).
- You're willing to add a small wrapper for
response.ok, JSON parsing, timeouts, and retry. - You want zero dependency surface and fewer supply-chain concerns.
- You value browser/server API parity.
- You're in serverless or edge environments where built-in APIs are preferred.
When Axios, Got, or Ky Makes More Sense
Axios is the right call when your team relies on request/response interceptors (e.g., automatic auth token refresh, tenant headers, centralized logging), when you want default rejection on HTTP errors, or when you need backward compatibility with older Node runtimes.
Got is built for high-throughput Node services that need built-in retries, hooks, advanced timeout phases, streams, pagination helpers, Unix sockets, proxy/caching workflows, or HTTP/2 support. It's the Swiss Army knife for Node-only HTTP work.
Ky is the sweet spot if you like fetch's simplicity but want less boilerplate — it adds retry, timeout, hooks, and HTTPError in a tiny package with zero dependencies.
How to Make GET Requests with the Node.js Fetch API
A GET request with async/await looks like this:
1const response = await fetch('https://jsonplaceholder.typicode.com/posts/1');
2const post = await response.json();
3console.log(post.title);
4// → "sunt aut facere repellat provident occaecati excepturi optio reprehenderit"And the .then() chain version, if you prefer:
1fetch('https://jsonplaceholder.typicode.com/posts/1')
2 .then(response => response.json())
3 .then(post => console.log(post.title))
4 .catch(error => console.error(error));Both work. But neither is production-safe yet (more on that in a moment).
Response readers you should know:
| Method | Use when |
|---|---|
response.json() | Server returns JSON |
response.text() | Server returns HTML, plain text, CSV, Markdown |
response.arrayBuffer() | You need binary data (images, files) |
response.body | You need streaming/chunked processing |
A better pattern — one that actually checks for errors:
1async function getPost(id) {
2 const response = await fetch(`https://jsonplaceholder.typicode.com/posts/$\{id\}`);
3 if (!response.ok) {
4 throw new Error(`HTTP $\{response.status\} $\{response.statusText\}`);
5 }
6 return response.json();
7}
8const post = await getPost(1);
9console.log(post.title);That if (!response.ok) line is the difference between a tutorial and production code. Which brings us to the biggest trap.
How to Send POST Requests with the Node.js Fetch API
POST requests follow the same shape — you just set the method, headers, and body:
1const response = await fetch('https://jsonplaceholder.typicode.com/posts', {
2 method: 'POST',
3 headers: {
4 'Content-Type': 'application/json',
5 },
6 body: JSON.stringify({
7 title: 'Node fetch guide',
8 body: 'Production fetch needs error handling.',
9 userId: 1,
10 }),
11});
12if (!response.ok) {
13 throw new Error(`HTTP $\{response.status\}`);
14}
15const created = await response.json();
16console.log(created.id); // → 101Sending Other Request Types (PUT, DELETE, PATCH)
PUT, PATCH, and DELETE use the identical structure with a different method value:
1// PUT — full replacement
2await fetch('https://jsonplaceholder.typicode.com/posts/1', {
3 method: 'PUT',
4 headers: { 'Content-Type': 'application/json' },
5 body: JSON.stringify({ id: 1, title: 'Replaced', body: 'Full replacement', userId: 1 }),
6});
7// PATCH — partial update
8await fetch('https://jsonplaceholder.typicode.com/posts/1', {
9 method: 'PATCH',
10 headers: { 'Content-Type': 'application/json' },
11 body: JSON.stringify({ title: 'Partial update' }),
12});
13// DELETE
14await fetch('https://jsonplaceholder.typicode.com/posts/1', {
15 method: 'DELETE',
16});The Express body-parser trap: If you're POSTing JSON to an Express server and req.body comes back undefined, the fix is almost always this: use express.json(), not express.urlencoded(). The server needs express.json() middleware before your route to parse Content-Type: application/json bodies. This is one of the most common about Express, and it catches people every time.
1import express from 'express';
2const app = express();
3app.use(express.json()); // ← This is the one you need for JSON POST bodies
4app.post('/api/posts', (req, res) => {
5 res.json({ received: req.body });
6});The fetch() Error Trap That Breaks Production Apps
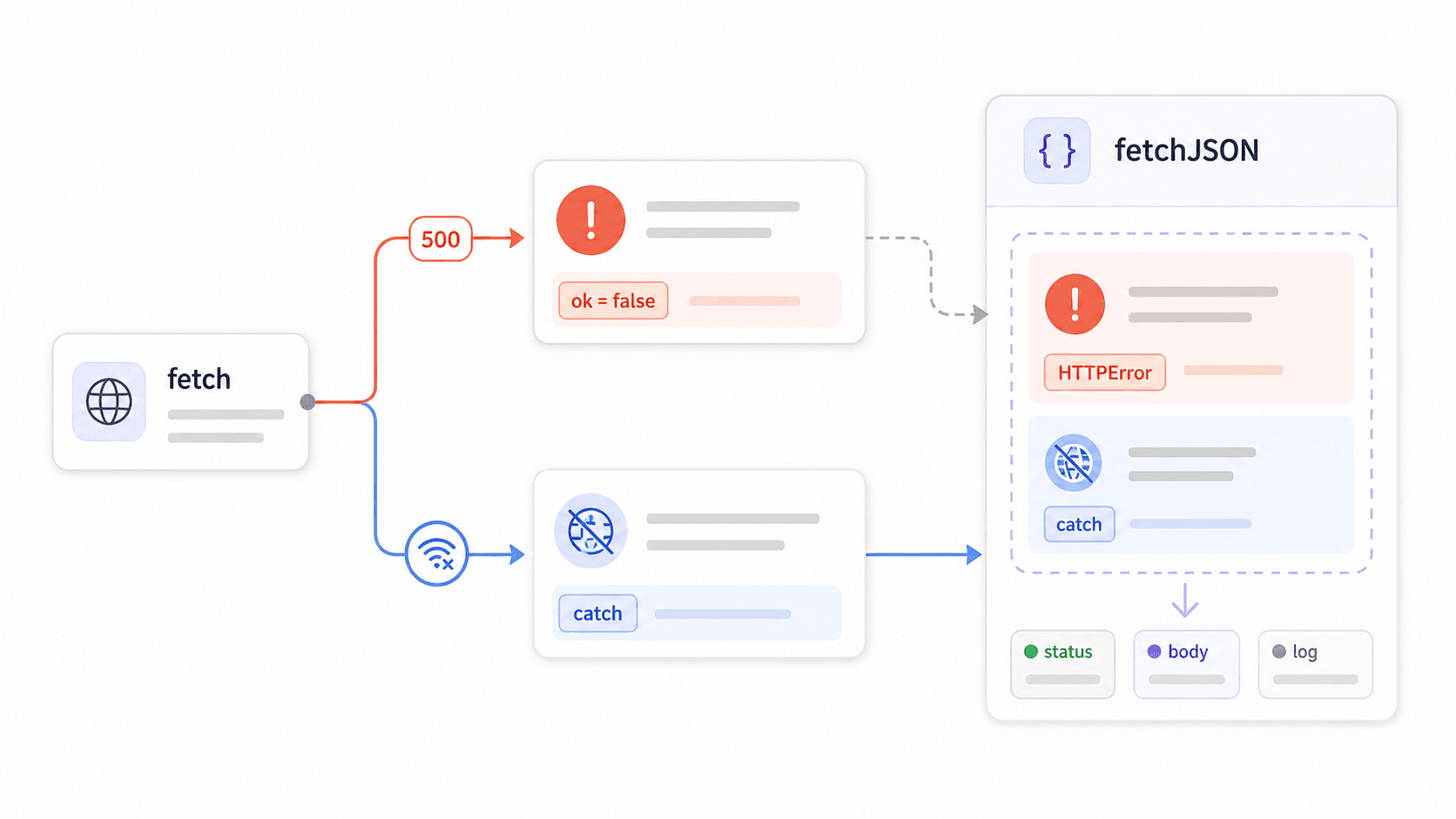
This is where most production fetch bugs come from.
fetch() does not reject its promise on HTTP 4xx or 5xx errors. It only rejects on network-level failures — DNS errors, no internet, aborted requests. If the server returns a 403 Forbidden or a 500 Internal Server Error, fetch considers that a successful response. Your .catch() block never runs. Your try/catch never catches it. Your code happily processes whatever the server sent back.
states this clearly, but most tutorials gloss over it. The result? Code like this looks fine but silently swallows errors:
1try {
2 const response = await fetch('https://api.example.com/private');
3 const data = await response.json(); // ← This runs even on a 403
4 console.log('Looks successful:', data);
5} catch (error) {
6 // Only network-level failures land here
7 console.error('Caught:', error);
8}A quick breakdown of what each pattern actually catches:
| Pattern | Catches network errors | Catches 4xx/5xx | Parses JSON safely | Reusable |
|---|---|---|---|---|
Raw .then(res => res.json()) | Yes (via .catch()) | No | No content-type guard | No |
try/catch with await fetch() | Yes | No | No content-type guard | No |
Manual if (!res.ok) per call | Yes | Yes | Depends on each call | Partial |
Custom fetchJSON() wrapper | Yes | Yes | Yes | Yes |
Build a Reusable fetchJSON() Wrapper
Build one wrapper. Import it everywhere. Stop copy-pasting if (!response.ok) into every file:
1export class HTTPError extends Error {
2 constructor(message, { status, statusText, url, body }) {
3 super(message);
4 this.name = 'HTTPError';
5 this.status = status;
6 this.statusText = statusText;
7 this.url = url;
8 this.body = body;
9 }
10}
11export async function fetchJSON(url, options = {}) {
12 const response = await fetch(url, {
13 headers: {
14 Accept: 'application/json',
15 ...options.headers,
16 },
17 ...options,
18 });
19 const contentType = response.headers.get('content-type') || '';
20 const isJSON = contentType.includes('application/json');
21 const body = isJSON ? await response.json().catch(() => null) : await response.text();
22 if (!response.ok) {
23 throw new HTTPError(`HTTP $\{response.status\} $\{response.statusText\}`, {
24 status: response.status,
25 statusText: response.statusText,
26 url: response.url,
27 body,
28 });
29 }
30 return body;
31}Now, when the server returns a 403:
1try {
2 const data = await fetchJSON('https://api.example.com/private');
3} catch (error) {
4 if (error instanceof HTTPError) {
5 console.error(`Server returned $\{error.status\}:`, error.body);
6 } else {
7 console.error('Network or other failure:', error);
8 }
9}The error carries the status code, the response body, and the URL — everything you need for logging, alerting, or user-facing messages. Import this once, use it everywhere.
AbortController and Timeouts: The Production Pattern for the Node.js Fetch API
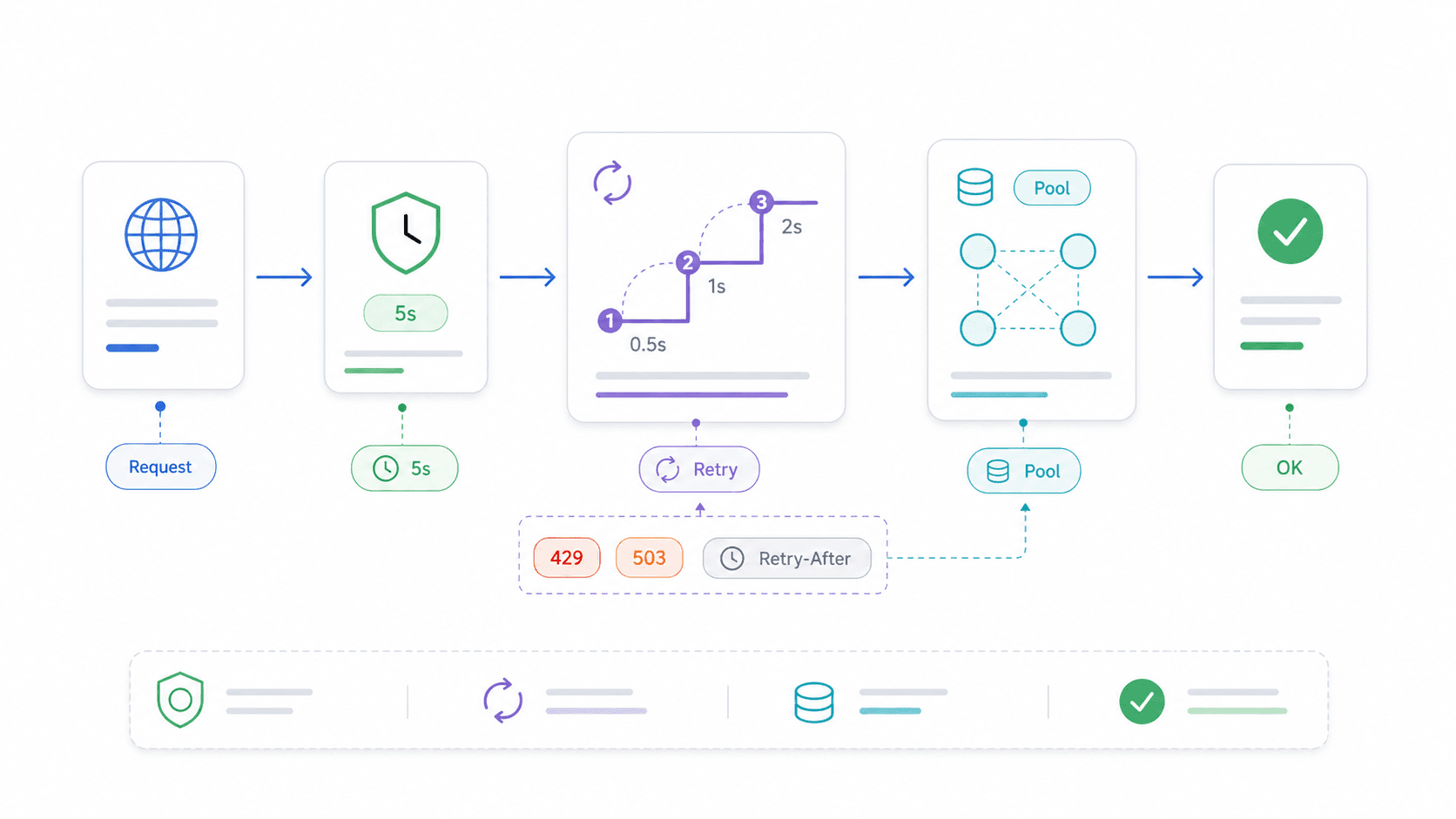
Without a timeout, a fetch call hangs indefinitely when the remote server goes silent. Your Express route blocks. Your Lambda burns through its execution budget. Your script just... sits there.
I checked the top search results: not a single Node.js-specific fetch tutorial covers request cancellation or timeouts. Yet timeouts are one of the top reasons developers stick with Axios or Got. One Reddit thread is literally titled "Node fetch does not timeout".
Using AbortSignal.timeout() (Node 18.11+)
The simplest approach — one extra option:
1try {
2 const response = await fetch('https://api.example.com/data', {
3 signal: AbortSignal.timeout(5000), // 5 seconds
4 });
5 if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
6 const data = await response.json();
7 console.log(data);
8} catch (error) {
9 if (error.name === 'TimeoutError') {
10 console.error('The request timed out after 5 seconds.');
11 } else {
12 throw error;
13 }
14}Note: AbortSignal.timeout() throws a TimeoutError, not an AbortError. This is a detail that even some experienced developers get wrong.
Manual Timeout with AbortController
For more control — or if you need to cancel a request based on user action, not just a timer:
1const controller = new AbortController();
2const timeout = setTimeout(() => controller.abort(), 5000);
3try {
4 const response = await fetch('https://api.example.com/data', {
5 signal: controller.signal,
6 });
7 const data = await response.json();
8 console.log(data);
9} catch (error) {
10 if (error.name === 'AbortError') {
11 console.error('The request was manually aborted.');
12 } else {
13 throw error;
14 }
15} finally {
16 clearTimeout(timeout);
17}Handling AbortError vs TimeoutError
This distinction matters for logging and user-facing messages:
| Abort path | Error name in catch block |
|---|---|
AbortSignal.timeout(ms) | TimeoutError |
controller.abort() | AbortError |
| DNS/network failure | Typically TypeError: fetch failed |
Here's a practical scenario — an Express route that calls an external API and must respond within 3 seconds:
1app.get('/dashboard', async (req, res, next) => {
2 try {
3 const data = await fetchJSON('https://api.example.com/report', {
4 signal: AbortSignal.timeout(3000),
5 });
6 res.json(data);
7 } catch (error) {
8 if (error.name === 'TimeoutError') {
9 res.status(504).json({ error: 'Upstream API timed out' });
10 return;
11 }
12 next(error);
13 }
14});Without this pattern, a slow upstream API would block your entire route until the client gives up.
Retry Logic and Connection Reuse: Making the Node.js Fetch API Production-Grade
Native fetch has no built-in retry. A network blip or a transient 503 means the request simply fails. For most read operations in production, that's not acceptable.
A Composable Retry Wrapper with Exponential Backoff
This is intentionally short — about 10 lines of actual logic:
1const wait = ms => new Promise(resolve => setTimeout(resolve, ms));
2export async function fetchWithRetry(url, options = {}, retries = 2) {
3 for (let attempt = 0; ; attempt++) {
4 try {
5 const response = await fetch(url, options);
6 if (response.ok || ![408, 429, 500, 502, 503, 504].includes(response.status)) {
7 return response;
8 }
9 if (attempt >= retries) return response;
10 } catch (error) {
11 if (attempt >= retries) throw error;
12 }
13 await wait(250 * 2 ** attempt); // 250ms, 500ms, 1000ms...
14 }
15}When to Retry (and When Not To)
- Do retry: Idempotent GET and HEAD requests, transient statuses (408, 429, 500, 502, 503, 504), network blips.
- Do not retry: Non-idempotent POST requests that create records, charge money, or trigger side effects — unless you use idempotency keys.
- Respect Retry-After: For 429 (rate limit) and 503 (service unavailable), check the
Retry-Afterheader before backing off.
If you'd rather not build your own retry logic, is a lightweight fetch wrapper that adds retry, timeout, hooks, and HTTPError out of the box — with zero dependencies.
Connection Reuse with Undici's Agent and Pool
For high-throughput loops — scraping hundreds of pages, calling an API in a batch, polling a service — reusing TCP connections saves significant time. Each new connection means a fresh DNS lookup, TCP handshake, and (for HTTPS) TLS negotiation.
Since Node's fetch is powered by Undici, you can pass a custom dispatcher:
1import { Agent } from 'undici';
2const agent = new Agent({
3 keepAliveTimeout: 10_000,
4 keepAliveMaxTimeout: 60_000,
5});
6const response = await fetch('https://api.example.com/data', {
7 dispatcher: agent,
8});For even more control with a specific origin:
1import { Pool } from 'undici';
2const pool = new Pool('https://api.example.com', { connections: 10 });
3const response = await fetch('https://api.example.com/data', {
4 dispatcher: pool,
5});
6// When done:
7await pool.close();The show that connection reuse and pooling can dramatically improve throughput — undici - dispatch clocked about 22,234 req/sec versus undici - fetch at about 5,904 req/sec in their local benchmark. Real-world numbers will vary, but the direction is clear: if you're making lots of requests to the same origin, pooling matters.
One more thing: always consume or cancel response bodies. Unconsumed bodies can cause resource leaks in Node's HTTP internals.
Streaming Responses with the Node.js Fetch API
Large file downloads, chunked JSON feeds, server-sent events, LLM output — these are cases where waiting for the full response before processing wastes time and memory. Streaming lets you handle data as it arrives.
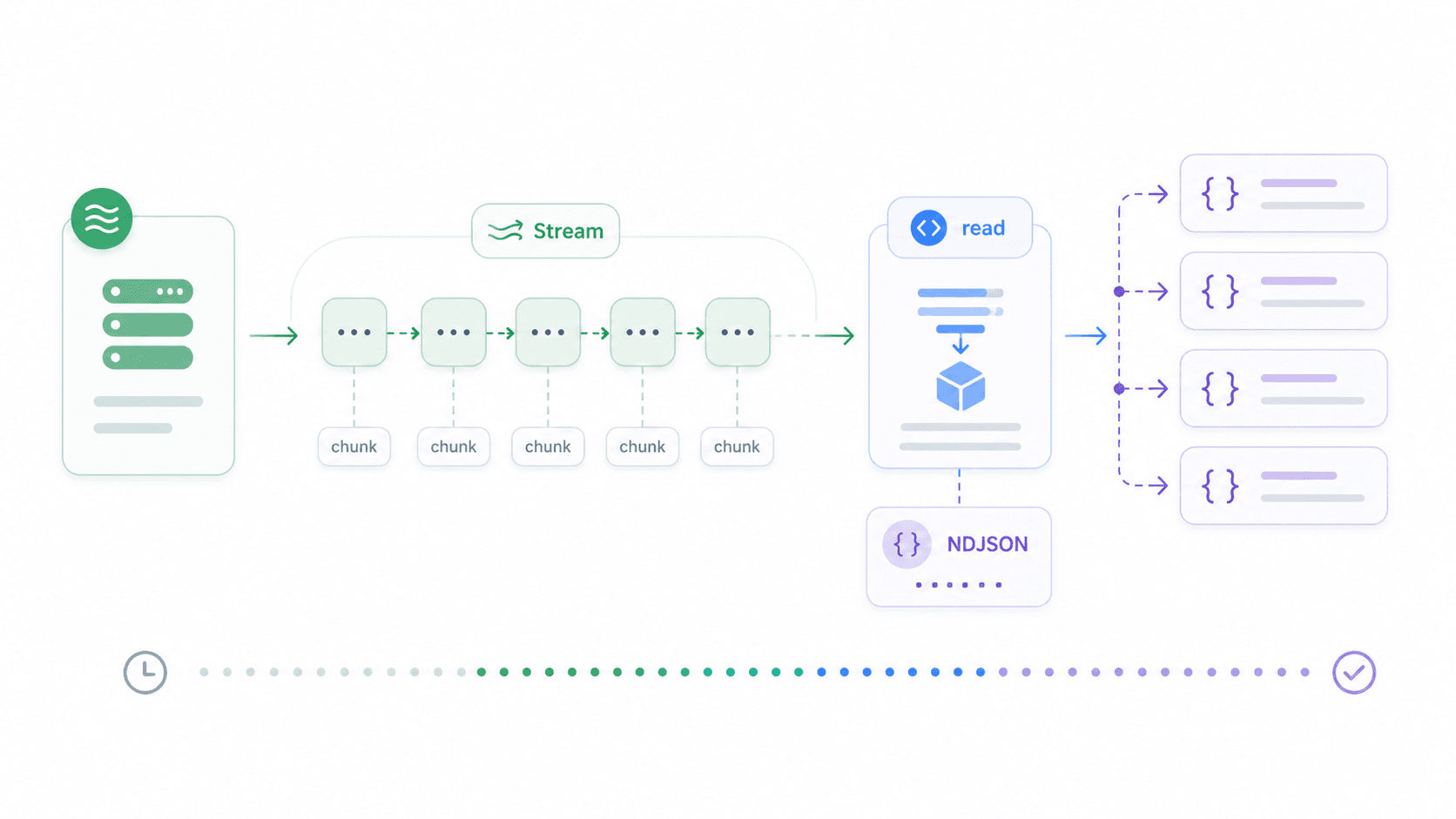
Node 18+ includes browser-compatible ReadableStream. Here's how to stream a newline-delimited JSON response and process each line as it arrives:
1const response = await fetch('https://example.com/large-file.ndjson');
2if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
3const reader = response.body.getReader();
4const decoder = new TextDecoder();
5let buffer = '';
6while (true) {
7 const { value, done } = await reader.read();
8 if (done) break;
9 buffer += decoder.decode(value, { stream: true });
10 let newlineIndex;
11 while ((newlineIndex = buffer.indexOf('\n')) >= 0) {
12 const line = buffer.slice(0, newlineIndex).trim();
13 buffer = buffer.slice(newlineIndex + 1);
14 if (line) {
15 const item = JSON.parse(line);
16 console.log('Processed:', item.id);
17 }
18 }
19}For simpler text streaming (e.g., piping LLM output to stdout):
1const response = await fetch('https://example.com/stream');
2const reader = response.body.getReader();
3const decoder = new TextDecoder();
4for (;;) {
5 const { value, done } = await reader.read();
6 if (done) break;
7 process.stdout.write(decoder.decode(value, { stream: true }));
8}Streaming is one area where native fetch and Got both excel. Axios's streaming support is more limited.
When fetch() Hits Its Limits: Structured Web Scraping with APIs
At some point, fetch is no longer the bottleneck. The real problem becomes: "I have HTML, now what?"
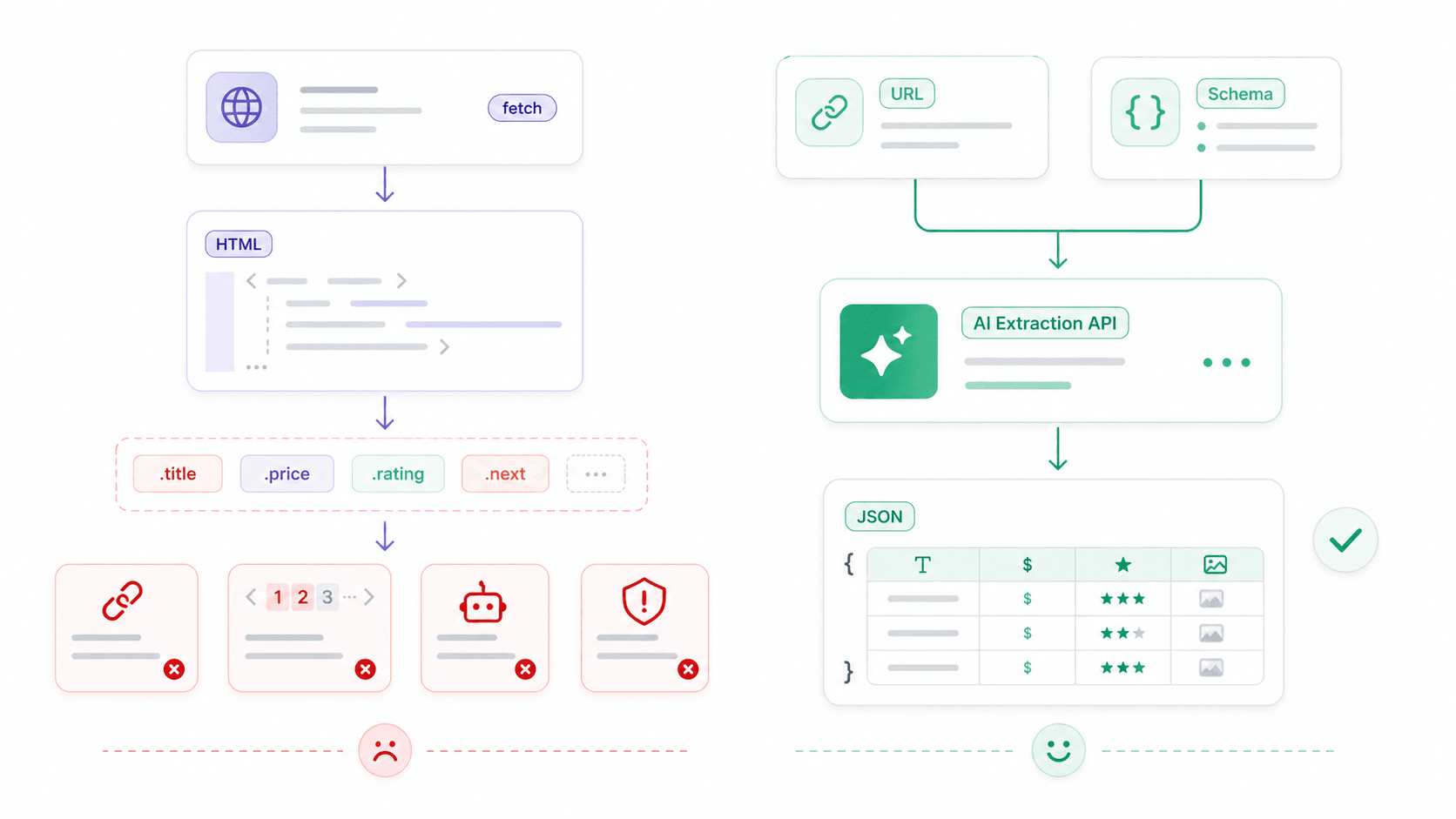
Fetch is an HTTP client — it retrieves bytes, text, JSON, or HTML. It has no concept of a product card, a price, a rating, or a contact table. For structured web scraping, the typical raw stack looks like this:
fetch()to download HTML- Cheerio (or similar) to select elements with CSS selectors
- Custom pagination logic
- JavaScript rendering when pages are client-side
- Proxy/anti-bot/CAPTCHA handling
- Selector maintenance every time the site layout changes
Here's a typical fetch + Cheerio example — about 15 lines to scrape product titles:
1import * as cheerio from 'cheerio';
2const response = await fetch('https://example-store.com/products');
3if (!response.ok) throw new Error(`HTTP $\{response.status\}`);
4const html = await response.text();
5const $ = cheerio.load(html);
6const products = $('.product-card')
7 .map((_, el) => ({
8 name: $(el).find('.product-title').text().trim(),
9 price: $(el).find('.price').text().trim(),
10 url: new URL($(el).find('a').attr('href'), response.url).href,
11 }))
12 .get();
13console.log(products);This works for stable pages with predictable HTML. It becomes fragile fast — JavaScript-rendered content, changing class names, anti-bot measures, and pagination all add complexity.
Thunderbit's Open API: From Raw HTML to Structured Data in One Call
This is where a different kind of tool becomes useful. At , we built an API layer that handles the messy parts — JavaScript rendering, anti-bot protection, layout changes — so you can focus on the data you actually want.
Distill API (POST /distill): Converts any URL to clean Markdown. Useful for feeding LLMs, building knowledge bases, or content analysis — no HTML parser needed.
Extract API (POST /extract): Define a JSON Schema describing the structured data you want (product name, price, rating), and AI extracts it. No CSS selectors, no breakage when layouts change.
Here's the same product scraping task using Thunderbit's Extract API — called with native fetch:
1const response = await fetch('https://openapi.thunderbit.com/openapi/v1/extract', {
2 method: 'POST',
3 headers: {
4 Authorization: `Bearer $\{process.env.THUNDERBIT_API_KEY\}`,
5 'Content-Type': 'application/json',
6 },
7 body: JSON.stringify({
8 url: 'https://example-store.com/products',
9 renderMode: 'basic',
10 schema: {
11 type: 'object',
12 properties: {
13 products: {
14 type: 'array',
15 items: {
16 type: 'object',
17 properties: {
18 name: { type: 'string', description: 'Product name' },
19 price: { type: 'string', description: 'Displayed product price' },
20 rating: { type: 'number', description: 'Average customer rating' },
21 },
22 required: ['name', 'price'],
23 },
24 },
25 },
26 required: ['products'],
27 },
28 }),
29});
30if (!response.ok) throw new Error(`Thunderbit API: $\{response.status\}`);
31const result = await response.json();
32console.log(result.data);The comparison: ~15 lines of fetch + Cheerio (plus fragile selectors) versus a single API call that returns clean JSON. For batch jobs, Thunderbit supports up to 50 URLs per batch extract call and up to 100 URLs per batch distill call.
Thunderbit isn't a replacement for fetch — fetch is the transport. Thunderbit is the extraction layer you reach for when raw HTML parsing becomes the actual problem. If you're curious about pricing, the gives you 600 API units to experiment with, and paid plans start at $6/month. You can also check out the for no-code extraction directly in your browser.
For more on structured scraping approaches, our guides on , , and cover specific workflows in detail.
Quick Reference: Node.js Fetch API Cheat Sheet
This section is meant to be bookmarked. Come back when you need a pattern to copy-paste.
| Pattern | Snippet |
|---|---|
| Basic GET | const res = await fetch(url); const data = await res.json(); |
| Basic POST | await fetch(url, { method: 'POST', headers: { 'Content-Type': 'application/json' }, body: JSON.stringify(payload) }); |
| HTTP error check | if (!res.ok) throw new Error(\HTTP ${res.status}`);` |
| Timeout (simple) | await fetch(url, { signal: AbortSignal.timeout(5000) }); |
| Manual abort | const c = new AbortController(); setTimeout(() => c.abort(), 5000); await fetch(url, { signal: c.signal }); |
| Retry statuses | Retry 408, 429, 500, 502, 503, 504. Don't blindly retry POST. |
| JSON wrapper | Use fetchJSON() to check ok, parse content type, throw HTTPError. |
| Connection pool | import { Pool } from 'undici'; const pool = new Pool(origin, { connections: 10 }); fetch(url, { dispatcher: pool }); |
| Stream chunks | const reader = res.body.getReader(); loop over await reader.read() |
| Structured extraction | Use Thunderbit Extract API when the goal is fields from a web page, not raw HTML. |
Conclusion and Key Takeaways
Native fetch in Node.js is production-ready in 2026 — no node-fetch required for new projects, no default Axios dependency needed. But raw fetch() alone is not a production HTTP strategy.
The five things most tutorials skip — and that this guide covers:
- The error trap:
fetch()doesn't throw on 4xx/5xx. Always checkresponse.okor use a wrapper likefetchJSON(). - Timeouts: Use
AbortSignal.timeout()for simple cases.AbortSignal.timeout()throwsTimeoutError; manualcontroller.abort()throwsAbortError. - Retry logic: Not built in. Add exponential backoff for idempotent requests and transient failures. Or use Ky for fetch-style retry out of the box.
- Connection reuse: For high-throughput loops, use Undici's
AgentorPoolvia thedispatcheroption. - Structured extraction: When you need data from web pages (not just raw HTML), consider an extraction API like Thunderbit instead of maintaining fragile CSS selectors.
The decision matrix in one sentence: use native fetch for most projects, Axios for interceptors, Got for built-in retry and HTTP/2, Ky for fetch with better defaults, and Thunderbit's API when your fetch-based scraping scripts get too complex to maintain.
Try the patterns in this guide. And if you want to see how Thunderbit handles structured extraction, the is a good place to start — or watch a walkthrough on the .
FAQs
1. Is fetch built into Node.js or do I need to install it?
Fetch is built into Node.js 18 and later — no installation needed. It became stable in Node 21 and is fully supported in Node 22 LTS and Node 24 LTS. For older Node versions, you can use the node-fetch npm package, but new projects should target a maintained LTS release.
2. Does fetch throw an error on 404 or 500 responses?
No. Fetch only rejects its promise on network-level failures (DNS errors, no connectivity, aborted requests). HTTP responses like 404, 403, and 500 resolve normally with response.ok === false. You must check response.ok or response.status explicitly — or use a wrapper like the fetchJSON() function shown in this guide.
3. How do I add a timeout to fetch in Node.js?
The simplest approach is AbortSignal.timeout(ms), available in Node 18.11+: await fetch(url, { signal: AbortSignal.timeout(5000) }). This throws a TimeoutError if the request exceeds 5 seconds. For more control, create an AbortController manually and call controller.abort() from a setTimeout. Catch AbortError for the manual pattern and TimeoutError for AbortSignal.timeout().
4. Can I use fetch for web scraping in Node.js?
Yes, but fetch only returns raw HTML. You'll need a parser like Cheerio to extract specific elements, plus custom logic for pagination, JavaScript-rendered pages, and anti-bot measures. For structured data extraction at scale — where you want clean JSON with product names, prices, or contact info — consider , which uses AI to return structured data without CSS selectors or layout-dependent code.
5. Should I switch from Axios to native fetch in 2026?
For new projects on Node 22+, native fetch is a strong default. It's zero-dependency, Promise-based, and shares the same API as browser fetch. Keep Axios if you rely on request/response interceptors, default HTTP-error rejection, or need backward compatibility with older Node versions. Both are valid choices — the decision depends on what features your project actually uses.
Learn More