
The web is overflowing with data, and every business wants a bigger slice of that pie. But let’s be honest—manually copying info from hundreds of web pages is about as fun as watching paint dry (and about as productive). That’s where node web scraping comes in. Over the past few years, I’ve seen more and more teams—sales, operations, market research, you name it—turn to automation to pull valuable insights from the web at scale. In fact, the global web scraping industry is projected to surpass , and it’s not just tech giants getting in on the action. From e-commerce price monitoring to lead generation, node web scraping is quickly becoming a must-have skill for anyone who wants to stay competitive.
If you’ve ever wondered how to extract data from websites using Node.js—or why Node.js is such a powerhouse for scraping dynamic, JavaScript-heavy sites—this guide is for you. I’ll walk you through what node web scraping is, why it matters for business users, and exactly how to build your own scraping workflow from scratch. And if you’re more of a “give me results now” type, I’ll also show you how tools like can save you hours (and a few headaches) by automating the whole process. Ready to turn the web into your personal data goldmine? Let’s dive in.
What is Node Web Scraping? Your Gateway to Automated Data Extraction
At its core, node web scraping means using Node.js (the popular JavaScript runtime) to automatically extract information from websites. Think of it as building a super-fast robot that visits web pages, reads their content, and pulls out the exact details you need—whether that’s product prices, contact info, or the latest news headlines.
Here’s how it works in a nutshell:
- Your Node.js script sends an HTTP request to a website (just like your browser does).
- It fetches the raw HTML of the page.
- Using libraries like Cheerio, it parses the HTML and lets you “query” the page for specific data (like a jQuery ninja).
- For sites where the content is loaded by JavaScript (think: modern, interactive web apps), you can use Puppeteer to control a real browser in the background, render the page, and grab the data after all the scripts have run.
Why Node.js? JavaScript is the language of the web, and Node.js lets you use it outside the browser. That means you can handle both static and dynamic sites, automate complex interactions (like logging in or clicking buttons), and process data at lightning speed. Plus, Node’s event-driven, non-blocking architecture makes it easy to scrape lots of pages in parallel—perfect for scaling up your data extraction.
Key tools in the Node web scraping toolkit:
- Axios: Fetches web pages (handles HTTP requests).
- Cheerio: Parses and queries HTML for static sites.
- Puppeteer: Automates a real browser for JavaScript-heavy or interactive sites.
If you’re picturing a robot army of browsers quietly collecting data while you sip your coffee… well, you’re not far off.
Why Node Web Scraping Matters for Business Teams
Let’s get real: web scraping isn’t just for hackers or data scientists anymore. It’s a business superpower. Companies across industries are using node web scraping to:
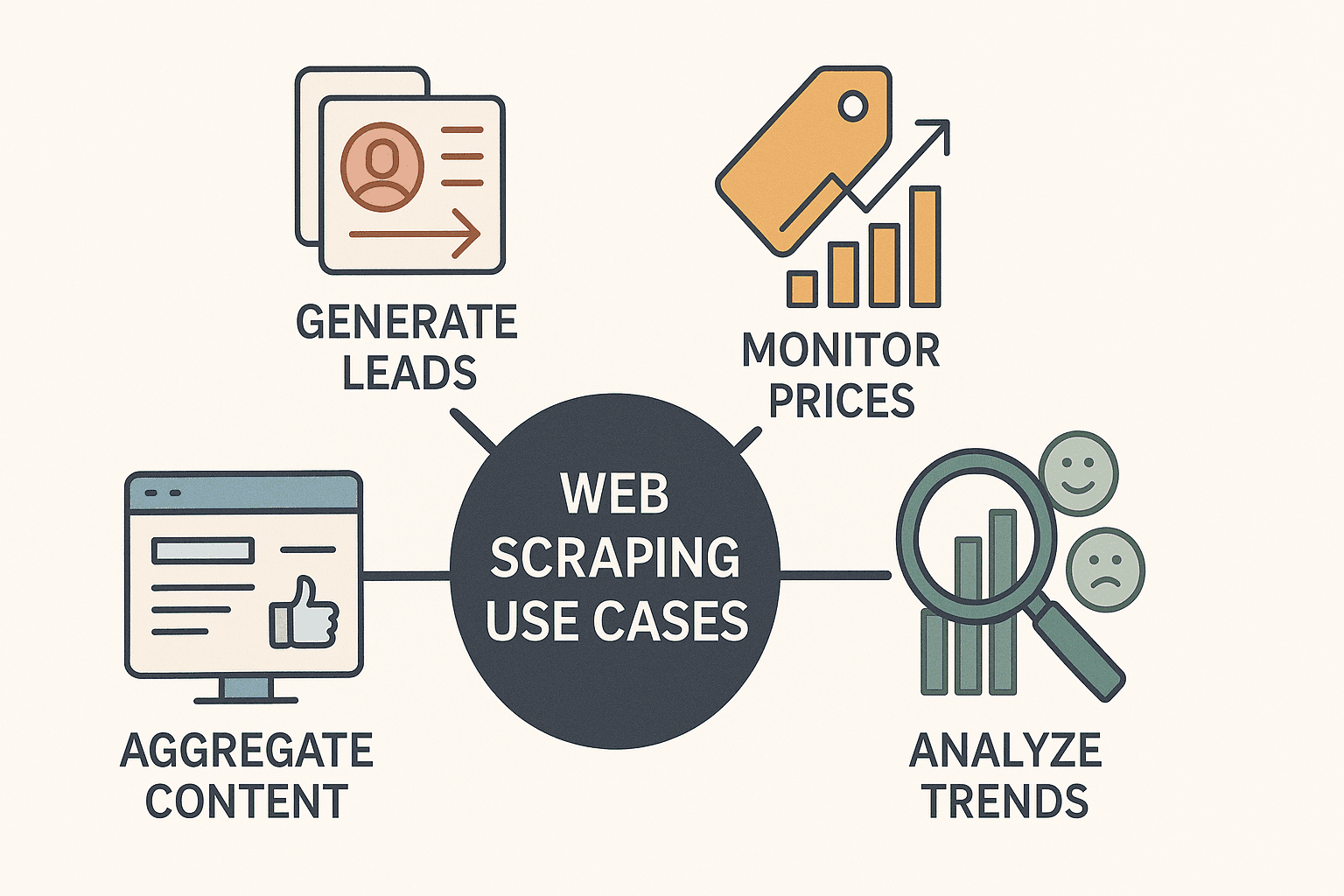
- Generate leads: Pull contact info from directories or LinkedIn for sales outreach.
- Monitor competitor prices: Track product listings and adjust pricing in real time (over scrape competitor prices daily).
- Aggregate content: Build dashboards of news, reviews, or social media mentions.
- Analyze market trends: Scrape reviews, forums, or job boards for sentiment and opportunities.
And the best part? Node.js makes all of this faster, more flexible, and easier to automate than ever before. Its asynchronous nature means you can fetch and process dozens (or hundreds) of pages at once, and its JavaScript roots make it the go-to choice for scraping sites built with modern frameworks.
Here’s a quick look at some real-world use cases:
| Use Case | Description & Example | Node.js Advantage |
|---|---|---|
| Lead Generation | Scrape business directories for emails, names, and phone numbers. | Fast, parallel scraping; easy integration with CRMs and APIs. |
| Price Monitoring | Track competitor pricing on e-commerce sites. | Async requests for bulk pages; easy scheduling for daily/hourly checks. |
| Market Trend Research | Aggregate reviews, forums, or social posts for sentiment analysis. | Versatile data handling; rich ecosystem for text processing and cleaning. |
| Content Aggregation | Pull news articles or blog posts into a single dashboard. | Real-time updates; seamless integration with notification tools (Slack, email, etc.). |
| Competitor Analysis | Scrape product catalogs, descriptions, and user ratings from rival sites. | JavaScript parsing for complex sites; modular code for multi-page crawls. |
Node.js is especially handy when you need to scrape sites that use a lot of JavaScript—something Python and other languages often struggle with. And with the right setup, you can go from “I wish I had this data” to “here’s my spreadsheet” in minutes.
Node Web Scraping Essentials: Tools and Libraries You Need
Before we jump into the code, let’s get familiar with the main tools in the Node.js scraping arsenal:
1. Axios (HTTP Client)

- What it does: Fetches web pages by sending HTTP requests.
- When to use: Anytime you need to grab the raw HTML of a page.
- Why it’s great: Simple, promise-based API; handles redirects and headers easily.
- Install with:
npm install axios
2. Cheerio (HTML Parser)

- What it does: Parses HTML and lets you use jQuery-like selectors to find data.
- When to use: For static sites where the data is present in the initial HTML.
- Why it’s great: Fast, lightweight, and super familiar if you know jQuery.
- Install with:
npm install cheerio
3. Puppeteer (Headless Browser Automation)

- What it does: Controls a real Chrome browser in the background, letting you interact with pages just like a user.
- When to use: For JavaScript-heavy or interactive sites (think: infinite scroll, login, pop-ups).
- Why it’s great: Can click buttons, fill forms, scroll, and extract data after scripts have run.
- Install with:
npm install puppeteer
Bonus: There are other tools like Playwright (multi-browser automation) and frameworks like Apify’s Crawlee for advanced workflows, but Axios, Cheerio, and Puppeteer are the “big three” for beginners.
Prerequisites: Make sure you have Node.js installed. Start a new project with npm init -y, then install the libraries above.
Step-by-Step: Build Your First Node Web Scraper from Scratch
Let’s roll up our sleeves and build a simple scraper. We’ll use Axios and Cheerio to scrape book data from the demo site .
Step 1: Fetch the Page HTML
1import axios from 'axios';
2import { load } from 'cheerio';
3const startUrl = 'http://books.toscrape.com/';
4async function scrapePage(url) {
5 const resp = await axios.get(url);
6 const html = resp.data;
7 const $ = load(html);
8 // ...extract data next
9}Step 2: Parse and Extract Data
1$('.product_pod').each((i, element) => {
2 const title = $(element).find('h3').text().trim();
3 const price = $(element).find('.price_color').text().replace('£', '');
4 const stock = $(element).find('.instock').text().trim();
5 const ratingClass = $(element).find('p.star-rating').attr('class') || '';
6 const rating = ratingClass.split(' ')[1];
7 const relativeUrl = $(element).find('h3 a').attr('href');
8 const bookUrl = new URL(relativeUrl, startUrl).href;
9 console.log({ title, price, rating, stock, url: bookUrl });
10});Step 3: Handle Pagination
1const nextHref = $('.next > a').attr('href');
2if (nextHref) {
3 const nextUrl = new URL(nextHref, url).href;
4 await scrapePage(nextUrl);
5}Step 4: Save the Data
After collecting the data, you can write it to a JSON or CSV file using Node’s fs module.
1import fs from 'fs';
2// After scraping is complete:
3fs.writeFileSync('books_output.json', JSON.stringify(booksList, null, 2));
4console.log(`Scraped ${booksList.length} books.`);And there you have it—a basic, working Node.js web scraper! This approach works wonders for static sites, but what about those pesky JavaScript-heavy pages?
Handling JavaScript-Heavy Pages: Using Puppeteer with Node Web Scraping
Some websites love to hide their data behind layers of JavaScript. If you try to scrape them with Axios and Cheerio, you’ll get an empty page or missing info. That’s where Puppeteer comes in.
Why use Puppeteer? It launches a real (headless) browser, loads the page, waits for all scripts to run, and then lets you grab the rendered content—just like a human user.
Sample Puppeteer Script
1import puppeteer from 'puppeteer';
2async function scrapeWithPuppeteer(url) {
3 const browser = await puppeteer.launch({ headless: true });
4 const page = await browser.newPage();
5 await page.goto(url, { waitUntil: 'networkidle2' });
6 await page.waitForSelector('.product_pod'); // Wait for data to load
7 const data = await page.evaluate(() => {
8 let items = [];
9 document.querySelectorAll('.product_pod').forEach(elem => {
10 items.push({
11 title: elem.querySelector('h3').innerText,
12 price: elem.querySelector('.price_color').innerText,
13 });
14 });
15 return items;
16 });
17 console.log(data);
18 await browser.close();
19}When to use Cheerio/Axios vs. Puppeteer:
- Cheerio/Axios: Fast, lightweight, perfect for static content.
- Puppeteer: Slower, but essential for dynamic or interactive pages (login, infinite scroll, etc.).
Pro tip: Always try Cheerio/Axios first for speed. If you’re missing data, switch to Puppeteer.
Advanced Node Web Scraping: Pagination, Login, and Data Cleaning
Once you’ve mastered the basics, it’s time to tackle more complex scenarios.
Handling Pagination
Loop through pages by detecting and following “next” links, or by generating URLs if they follow a pattern.
1let pageNum = 1;
2while (true) {
3 const resp = await axios.get(`https://example.com/products?page=${pageNum}`);
4 // ...extract data
5 if (!hasNextPage) break;
6 pageNum++;
7}Automating Logins
With Puppeteer, you can fill out login forms just like a user:
1await page.type('#username', 'myUser');
2await page.type('#password', 'myPass');
3await page.click('#loginButton');
4await page.waitForNavigation();Data Cleaning
After scraping, clean your data by:
- Removing duplicates (use a Set or filter by unique keys).
- Formatting numbers, dates, and text.
- Handling missing values (fill with null or skip incomplete records).
Regular expressions and JavaScript’s string methods are your friends here.
Node Web Scraping Best Practices: Avoiding Pitfalls and Staying Efficient
Web scraping is powerful, but it comes with its own set of challenges. Here’s how to avoid the most common pitfalls:
- Respect robots.txt and site terms: Always check if a site allows scraping and avoid restricted areas.
- Throttle your requests: Don’t hammer a site with hundreds of requests per second. Add delays and randomize them to mimic human behavior ().
- Rotate user agents and IPs: Use realistic headers and, for large-scale scraping, rotate IP addresses to avoid bans.
- Handle errors gracefully: Catch exceptions, retry failed requests, and log errors for debugging.
- Validate your data: Check for missing or malformed fields to catch changes in site structure early.
- Write modular, maintainable code: Separate fetching, parsing, and saving logic. Use config files for selectors and URLs.
And most importantly—scrape ethically. The web is a shared resource, and nobody likes a rude bot.
Thunderbit vs. DIY Node Web Scraping: When to Build, When to Use a Tool
Now, let’s talk about the elephant in the room: building your own scraper vs. using a tool like .
DIY Node.js Scraper:
- Pros: Full control, highly customizable, integrates with any workflow.
- Cons: Requires coding skills, time-consuming to set up and maintain, breaks when sites change.
Thunderbit AI Web Scraper:
- Pros: No code required, AI-powered field detection, handles subpages and pagination, instant export to Excel, Google Sheets, Notion, and more (). Maintenance-free—AI adapts to site changes automatically.
- Cons: Less flexibility for highly custom or complex workflows (but covers 99% of business use cases).
Here’s a quick comparison:
| Aspect | DIY Node.js Scraper | Thunderbit AI Web Scraper |
|---|---|---|
| Technical Skill | Coding required | No coding, point-and-click |
| Setup Time | Hours to days | Minutes (AI suggests fields) |
| Maintenance | Ongoing (site changes) | Minimal (AI adapts automatically) |
| Dynamic Content | Manual Puppeteer setup | Built-in handling |
| Pagination/Subpages | Manual coding | 1-click subpage/pagination support |
| Data Export | Manual code for export | 1-click to Excel, Sheets, Notion |
| Cost | Free (dev time, proxies) | Free tier, pay-as-you-go credits |
| Best For | Developers, custom logic | Business users, fast results |
Thunderbit is a lifesaver for sales, marketing, and ops teams who need data now—not after a week of coding and debugging. And for developers, it’s a great way to prototype or handle routine scraping tasks without reinventing the wheel.
Conclusion & Key Takeaways: Your Node Web Scraping Journey Starts Here
Node web scraping is your ticket to unlocking the web’s hidden data—whether you’re building lead lists, monitoring prices, or powering your next big idea. Here’s what to remember:
- Node.js + Cheerio/Axios is perfect for static sites; Puppeteer is your go-to for dynamic, JavaScript-heavy pages.
- Business impact is real: Companies using web scraping for data-driven decisions are seeing measurable gains, from to doubling international sales.
- Start simple: Build a basic scraper, then add features like pagination, login automation, and data cleaning as you go.
- Use the right tool for the job: For quick, no-code scraping and instant results, is hard to beat. For custom, integrated workflows, DIY Node.js scripts give you full control.
- Scrape responsibly: Respect site policies, throttle your bots, and keep your code clean and maintainable.
Ready to get started? Try building your own Node.js scraper, or and see how easy web data extraction can be. And if you’re hungry for more tips, check out the for deep dives, tutorials, and the latest in AI-powered scraping.
Happy scraping—and may your data always be fresh, structured, and one step ahead of the competition.
FAQs
1. What is node web scraping and why is Node.js a good choice?
Node web scraping is the process of using Node.js to automate data extraction from websites. Node.js is especially strong for scraping because it handles asynchronous requests efficiently and excels at scraping JavaScript-heavy sites, thanks to tools like Puppeteer.
2. When should I use Cheerio/Axios vs. Puppeteer for scraping?
Use Cheerio and Axios for static sites where the data is present in the initial HTML. Use Puppeteer when you need to scrape content loaded by JavaScript, interact with the page (like logging in), or handle infinite scroll.
3. What are the most common business use cases for node web scraping?
Top use cases include lead generation, competitor price monitoring, content aggregation, market trend analysis, and product catalog scraping. Node.js makes these tasks fast and scalable.
4. What are the biggest pitfalls in node web scraping, and how can I avoid them?
Common pitfalls include getting blocked by anti-bot measures, handling site structure changes, and managing data quality. Avoid them by throttling requests, rotating user agents/IPs, validating your data, and writing modular code.
5. How does Thunderbit compare to building my own Node.js scraper?
Thunderbit offers a no-code, AI-powered solution that handles field detection, subpages, and pagination automatically. It’s ideal for business users who want results fast, while DIY Node.js scraping is best for developers needing full customization or integration with other systems.
For more guides and inspiration, don’t forget to visit the and subscribe to our for hands-on tutorials.
Learn More