
There’s something almost electric about watching a trend explode on Twitter (or X, if you’re keeping up with the rebrand). One minute, your brand is humming along quietly; the next, there’s a viral tweet, a flood of customer feedback, or a competitor’s bold new move lighting up your feed. For business teams, this real-time pulse is pure gold—but only if you can actually capture and make sense of it. That’s where most people hit a wall: Twitter data is fast, messy, and, unless you’re a developer or have a lot of patience for copy-paste marathons, tough to collect in a way that’s actually useful.
I’ve spent years in SaaS and automation, and I’ll be honest—Twitter data collection used to be one of those “I wish there was an easier way” problems. Now, with , we’ve finally made it possible for anyone (not just the technical folks) to grab, structure, and analyze Twitter data in just a couple of clicks. Let’s dive into why Twitter data matters, what makes it so tricky to collect, and how Thunderbit can turn that firehose of tweets into actionable business intelligence.
Why Twitter Data Collection Matters for Business Teams

Twitter is where the world’s conversations happen in real time. With , it’s a living, breathing barometer of public sentiment, industry trends, and competitor activity. But what does that mean for business teams?
Real-World Value of Twitter Data
-
Brand Monitoring & Reputation Management: Customers don’t wait to fill out a survey—they tweet their praise, complaints, and questions directly. In fact, . If you’re not tracking brand mentions, you’re missing the chance to turn a public complaint into a loyalty win—or to spot a brewing PR crisis before it erupts ().
-
Trend Detection & Audience Insights: Twitter is often the first place new trends surface. A fashion retailer that noticed a spike in tweets about sustainable clothing was able to pivot products and marketing before competitors even noticed (). And with , it’s a key channel for understanding what your audience cares about—right now.
-
Competitive Intelligence: Twitter is an open book for competitor activity. By tracking rivals’ tweets and the reactions they get, you can spot new product launches, marketing pushes, or customer pain points as they happen ().
-
Campaign Measurement & Influencer Discovery: Want to know if your hashtag campaign is working? Scrape all tweets with your branded hashtag, tally engagement, and identify which users are amplifying your message ().
-
Lead Generation: Some of the best sales leads are people tweeting “Looking for recommendations on [product].” If you can capture those tweets (and the user profiles behind them), you’re ahead of the competition ().
In short, Twitter data is a treasure trove for marketing, sales, product, and strategy teams. But here’s the catch: the sheer volume and speed of tweets make manual collection nearly impossible.
The Challenges of Traditional Twitter Data Collection
Let’s be real—most business users aren’t developers, and even those who are don’t want to spend hours wrestling with APIs or broken scripts. Here’s what the old-school approaches look like:
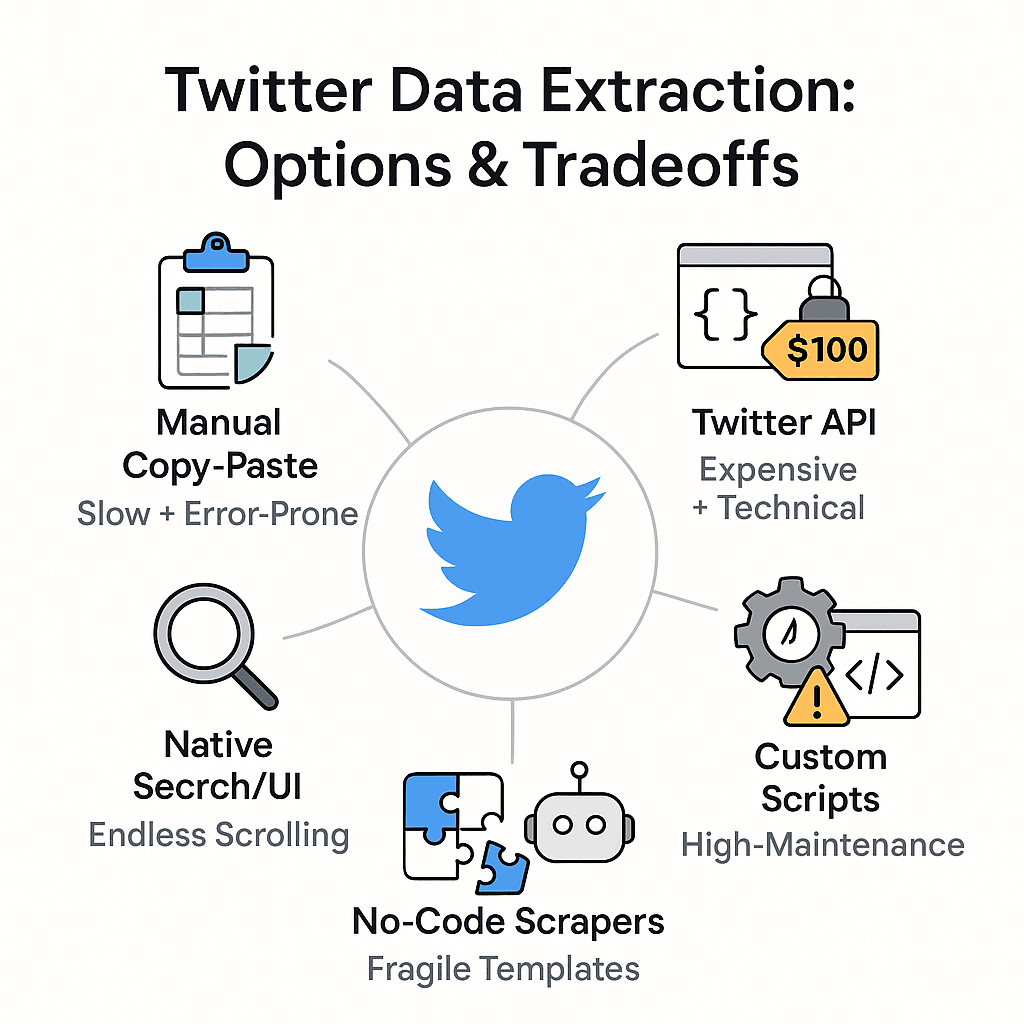
-
Manual Copy-Paste: Open Twitter, scroll, copy tweet text, paste into a spreadsheet, repeat until your wrist hurts. This is slow, error-prone, and you’ll miss half the context (timestamps, likes, replies, etc.) ().
-
Native Twitter Search/UI: Endless scrolling and screenshotting. Twitter’s interface isn’t built for data extraction, and you risk hitting login prompts or rate limits if you scroll too much.
-
Twitter API: Once the gold standard, but now . Plus, you need programming skills, API keys, and patience for JSON parsing. Not exactly “grab and go.”
-
Custom Scripts (Python, Selenium, etc.): Powerful, but high-maintenance. Twitter’s UI changes frequently, breaking scripts. Handling infinite scroll, logins, and anti-scraping measures is a headache ().
-
No-Code Scrapers & RPA Bots: Most require you to manually select page elements or build templates. Twitter’s dynamic layout (infinite scroll, pop-ups, nested replies) makes this a moving target. Templates break when Twitter updates its UI, and handling login-only content is tricky ().
The result? Most teams either make do with incomplete data or burn hours on grunt work. That’s exactly the problem I wanted to solve with Thunderbit.
Thunderbit: Simplifying Twitter Data Collection for Everyone
is an AI-powered Chrome extension that turns Twitter data collection from a technical slog into a 2-click, no-code workflow. Here’s how it changes the game:
-
Natural Language & AI-Driven Scraping: Just describe what you want (“Grab all tweets, usernames, dates, and likes from this page”) or click “AI Suggest Fields.” Thunderbit’s AI reads the page and figures out the rest ().
-
No-Code, 2-Click Workflow: Open Twitter, click “AI Suggest Fields,” then “Scrape.” That’s it. No coding, no templates, no setup. Even first-timers get results in minutes ().
-
Instant Structured Data: Thunderbit outputs a clean table—tweet text, username, date, likes, retweets, replies, and more—ready for analysis or export ().
-
Handles Infinite Scroll & Subpages: Thunderbit auto-scrolls through timelines, search results, or hashtag feeds, loading and scraping hundreds or thousands of tweets. Want replies or deeper context? Use “Scrape Subpages” to visit each tweet’s page and extract replies or author details ().
-
No Fragile Templates: Thunderbit’s AI adapts to Twitter UI changes. If something breaks, just click “AI Suggest Fields” again to re-learn the page ().
-
Export Anywhere: Download your data to Excel, CSV, Google Sheets, Airtable, or Notion with one click. Perfect for team collaboration ().
-
Cloud Scraping for Scale: Need to scrape thousands of tweets? Thunderbit’s Cloud mode can process up to 50 pages in parallel, running in the background while you get on with your day ().
-
Affordable Pricing: Thunderbit uses a credit system—1 credit per output row. The free tier lets you scrape up to 6 pages (or 10 with a trial), and paid plans start at just $15/month for 500 credits ().
Thunderbit vs. Traditional Twitter Data Collection Methods
Let’s put it side by side:
| Aspect | Traditional Methods (Manual, API, Scripts) | Thunderbit AI Scraper |
|---|---|---|
| Ease of Use | Coding/manual work required | No-code, point-and-click |
| Setup Time | 30+ minutes to hours | 1–2 minutes |
| Maintenance | High (breaks with UI changes) | Low (AI adapts automatically) |
| Data Format | Raw, needs cleaning | Structured, ready-to-use |
| Pagination | Manual or custom code | Auto-scrolls, clicks “Load more” |
| Export | CSV/JSON, manual import | Excel, Sheets, Airtable, Notion |
| Scalability | Hard (rate limits, proxies) | Cloud mode, 50 pages at once |
| Cost | High (API fees, dev time) | Free tier, affordable plans |
Thunderbit is like trading in your flip phone for a smartphone—you get more power, less hassle, and it just works.
Step-by-Step Guide: Collecting Twitter Data with Thunderbit
Ready to see how easy this can be? Here’s how I collect Twitter data with Thunderbit (and how you can, too):
Step 1: Install Thunderbit and Access Twitter
- Install the . It works on Chrome, Edge, and Brave.
- Sign up or log in. You’ll need a Thunderbit account to track credits and unlock features.
- Open Twitter and log in. Most Twitter content now requires login, so make sure you’re signed in on your browser.
That’s it. You’ll see the Thunderbit ⚡ icon in your toolbar, ready to go.
Step 2: Use AI Suggest Fields for Smart Data Structuring
- Navigate to your target Twitter page: This could be a user profile, search results, a hashtag feed, or a followers list.
- Click the Thunderbit icon, then “AI Suggest Fields.” Thunderbit scans the page and suggests columns like Tweet Text, Username, Date, Likes, Retweets, Replies, Tweet URL, and more ().
- Customize fields if needed: Rename columns, remove what you don’t need, or add custom AI prompts (more on that soon). For example, add a “Sentiment” column with the prompt: “Label the sentiment of the tweet as Positive, Negative, or Neutral.”
Thunderbit handles the messy part—no need to touch HTML or selectors.
Step 3: Start the Twitter Data Collection Process
- Click “Scrape.” Thunderbit starts extracting tweets, auto-scrolling and loading more as needed.
- Watch the table fill up: Each tweet becomes a row, with all your selected fields neatly organized.
- Need replies or deeper info? Use “Scrape Subpages” to visit each tweet’s page and extract replies, author bios, or more engagement data.
Thunderbit can handle hundreds or thousands of tweets in a single run. For massive jobs, switch to Cloud mode for speed and scale.
Step 4: Export and Share Twitter Data
- Export to Excel, CSV, Google Sheets, Airtable, or Notion: Just click your preferred export option. Thunderbit will create a new file or table and populate it automatically ().
- Share with your team: Google Sheets and Airtable are perfect for collaboration—multiple people can view, comment, or analyze the data in real time.
Pro tip: Add a “Date Collected” column to keep track of when each batch was scraped, especially if you’re running regular updates.
Maximizing Value: AI-Powered Field Extraction and Data Analysis
Thunderbit isn’t just about grabbing raw data—it’s about turning that data into actionable insight, right as you collect it.
Here’s where things get fun. For any field, you can add a custom AI instruction (a “Field AI Prompt”) to categorize, label, or format the data as it’s scraped. Some of my favorite use cases:
- Sentiment Analysis: Add a “Sentiment” field with the prompt: “Analyze the tone of the tweet and label it Positive, Negative, or Neutral.” Instantly see which tweets are complaints, praise, or neutral ().
- Topic or Intent Tagging: Add a “Category” field: “Categorize the tweet as a Question, Complaint, Praise, or Other.” Perfect for support or PR teams.
- Hashtag & Mention Extraction: Add a “Hashtags” field: “List all hashtags used in the tweet.” Or a “Mentions” field: “List all usernames mentioned.”
- Translation: Add “English Text” with: “Translate the tweet into English.” Great for global brands.
- Viral Tweet Flag: Add “Viral?” with: “If the tweet has more than 1000 likes, label as ‘Viral’.”
- Influencer Detection: Add “Influencer” with: “If author has more than 10,000 followers, mark as ‘Influencer’.”
All of this happens as Thunderbit scrapes—no need for post-processing or extra tools. The result? You get a spreadsheet that’s already enriched and ready for analysis.
Automating Twitter Data Collection: Best Practices for Teams
Collecting Twitter data once is great—but the real magic happens when you automate it. Thunderbit’s scheduling feature lets you set up regular scrapes (daily, weekly, hourly—you name it) so your data is always fresh.
Setting Up Scheduled Twitter Data Updates
- Set up your scrape as usual: Choose your Twitter page, define fields, and save the task.
- Click “Schedule” in Thunderbit: Describe your schedule in plain English (“every day at 9:00 AM” or “every Monday at 10:00 GMT”).
- Thunderbit runs the scrape automatically: In Cloud mode, you don’t even need your computer on. Your data lands in your chosen export (Google Sheets, Airtable, etc.) on schedule ().
Use cases:
- Competitor Monitoring: Daily scrapes of competitor accounts to spot new campaigns.
- Brand Mentions: Hourly scrapes of your brand name or hashtag to catch PR issues early.
- Campaign Tracking: Nightly scrapes of your campaign hashtag to measure engagement.
- Lead Generation: Weekly scrapes of search queries like “recommend a [product]” for fresh leads.
Exporting Twitter Data for Team Collaboration
- Google Sheets: Perfect for real-time collaboration, analysis, and sharing.
- Airtable: Great for database-style workflows, linking tweets to other records.
- Notion: Ideal for embedding data in reports or knowledge bases.
Tips:
- Use consistent field names across scrapes.
- Add a “Date Collected” field for version control.
- Set up notifications in Google Sheets or Airtable for critical events (e.g., a negative tweet from an influencer).
Thunderbit Twitter Data Collection: Tips and Troubleshooting
A few practical pointers from my own experience (and from helping hundreds of Thunderbit users):
- Target your search: Use Twitter’s search operators to filter tweets before scraping. The more focused your query, the cleaner your data ().
- Only scrape what you need: Disable unnecessary fields to speed up scraping and keep your data lean.
- Watch for rate limits: Scraping tens of thousands of tweets at once can trigger Twitter’s anti-bot measures. For big jobs, break them into chunks or use scheduling.
- Stay logged in: If Thunderbit isn’t scraping anything, double-check you’re logged in to Twitter on your browser.
- Adapt to layout changes: If a field stops working (e.g., like counts go blank), click “AI Suggest Fields” again to re-learn the page.
- Monitor your credits: Each tweet = 1 credit. Plan your schedule and scope accordingly ().
- Scrape responsibly: Stick to public data, respect privacy, and don’t use scraped info for spam or shady purposes ().
- Keep Thunderbit updated: Enable auto-updates for the extension to get the latest features and fixes.
- Check out and for more tips.
Conclusion & Key Takeaways
Twitter is the world’s real-time water cooler, and the insights hidden in its millions of daily tweets can make or break your next campaign, product launch, or PR response. But collecting and structuring that data shouldn’t require a PhD in computer science or a week of your life.
With , you can go from “What are people saying about us right now?” to a fully structured, enriched spreadsheet of tweets—complete with sentiment, topics, and engagement metrics—in less time than it takes to finish your coffee. No code, no templates, no headaches.
Key takeaways:
- Twitter data is essential for marketing, brand monitoring, and competitive intelligence.
- Manual and code-based collection methods are slow, error-prone, and often inaccessible for business teams.
- Thunderbit democratizes Twitter data collection with AI-powered, 2-click scraping and instant export to your favorite tools.
- AI prompts let you enrich and categorize data as you collect it—think sentiment, hashtags, influencer detection, and more.
- Scheduling and automation turn Twitter into a live feed of actionable business intelligence for your whole team.
Ready to see what you’ve been missing? , try a Twitter scrape, and experience the difference for yourself. And if you want more tips on web scraping, data-driven marketing, or automation, check out the .
FAQs
1. What types of Twitter data can Thunderbit collect?
Thunderbit can extract tweet text, usernames, display names, timestamps, likes, retweets, replies, tweet URLs, hashtags, mentions, media links, and more. You can also use AI prompts to categorize sentiment, detect language, or flag viral tweets ().
2. Do I need to know how to code to use Thunderbit for Twitter data collection?
Nope! Thunderbit is built for non-technical users. Just install the extension, open Twitter, click “AI Suggest Fields,” and “Scrape.” No coding or template setup required.
3. Can Thunderbit handle large-scale Twitter scraping (thousands of tweets)?
Yes. Thunderbit’s Cloud mode can scrape up to 50 pages in parallel, making it easy to collect thousands of tweets quickly. For very large jobs, break them into smaller chunks or use scheduling for best results.
4. How do I automate regular Twitter data collection with Thunderbit?
Use Thunderbit’s scheduling feature to set up daily, weekly, or custom scrapes. Data can be exported automatically to Google Sheets, Airtable, or Notion for team collaboration and reporting.
5. Is it legal and ethical to scrape Twitter data with Thunderbit?
Thunderbit is designed for responsible use. Stick to public data, avoid scraping private or login-only content without permission, and use the data for analysis—not spam. Always respect Twitter’s terms and privacy guidelines ().
Ready to turn Twitter’s chaos into clarity? and see how easy data-driven decision-making can be.
Learn More