
A crawl-based study of how high-traffic websites are publishing machine-readable guidance for large language models, what early implementations look like, and why measuring adoption requires more than counting HTTP 200 responses.
- Dataset:
data/llms_probe_results_top_10000.csv - Tranco list downloaded: May 6, 2026
- Scope: root-level
/llms.txtand/llms-full.txt
Key Metrics
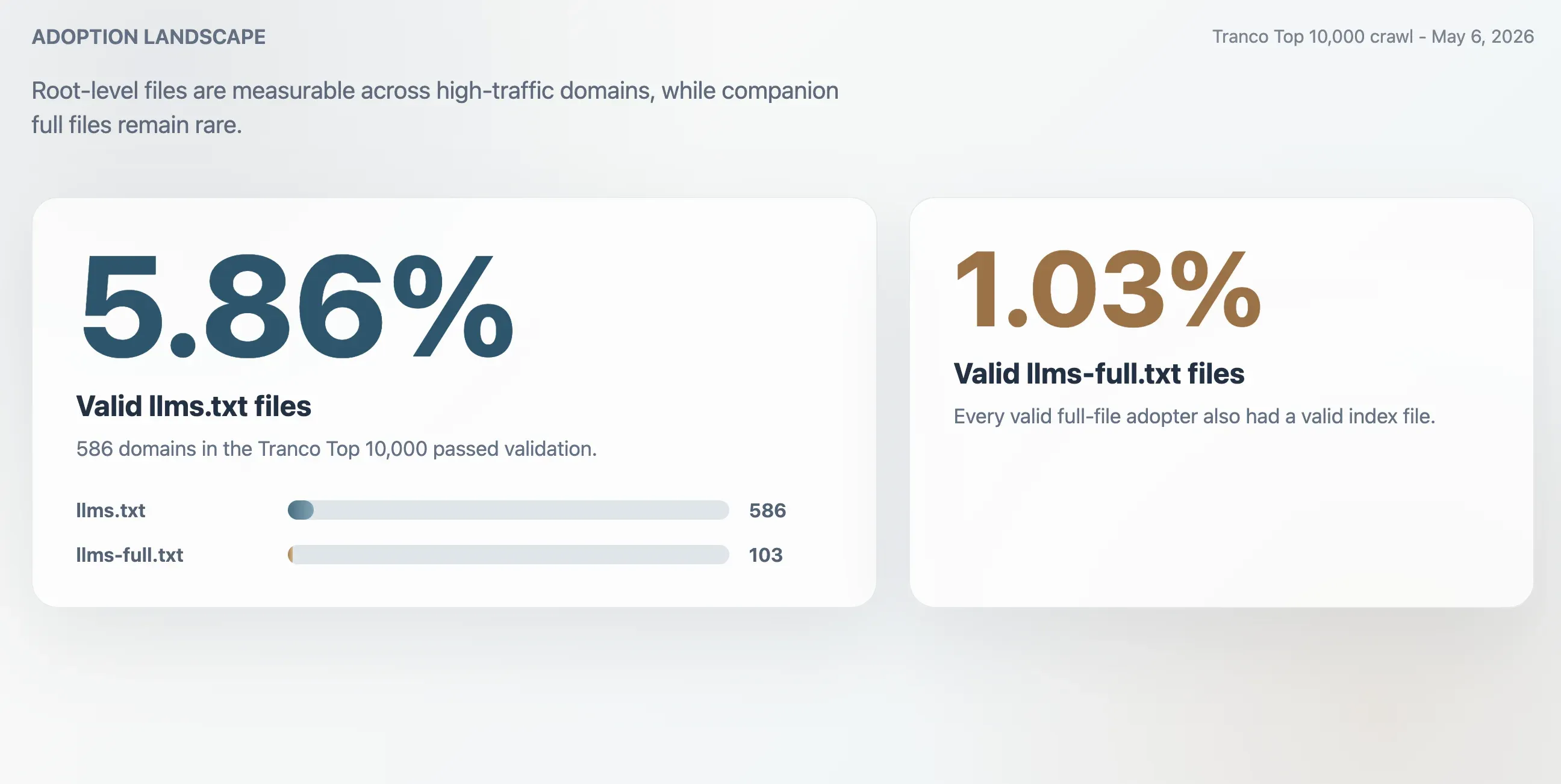
- 5.86%: Valid
llms.txtadoption across the Tranco Top 10,000, equal to 586 domains. - 1.03%: Valid
llms-full.txtadoption, equal to 103 domains. Every valid full-file adopter also had a valid index file. - 63.51%: Share of HTTP 200 responses for
/llms.txtthat failed validation. - 2.74x: Approximate overcount if adoption were measured by raw HTTP 200 responses alone.
Executive Summary
llms.txt is still an early web convention, but it is no longer a fringe experiment. In a May 6, 2026 crawl of the Tranco Top 10,000 domains, this study found 586 valid llms.txt files, for an observed adoption rate of 5.86%. The companion llms-full.txt file was much less common: 103 domains had a valid full file, for a 1.03% adoption rate.
The most important methodological finding is that status codes are a poor proxy for adoption. The crawler observed 1,606 HTTP 200 responses for /llms.txt, but only 586 passed validation. The remaining 1,020 were mostly off-target redirects, generic HTML pages, empty bodies, or other invalid responses. A naive crawler that counts every 200 response as adoption would overestimate valid adoption by about 2.74 times.
Among valid adopters, implementation quality is higher than a pure placeholder narrative would suggest. The median valid file was about 7.1 KB, 61.77% of valid files were larger than 5 KB, 70.82% contained six or more Markdown sections, and 77.47% contained 11 or more Markdown links. The early adopter set includes Cloudflare, Azure, GitHub, DigiCert, WordPress.org, Adobe, Dropbox, PayPal, Stripe, Salesforce, Slack, Zendesk, Okta, Datadog, and Cloudinary.
llms.txtis best understood as an explanatory and navigational signal for AI systems, not as a replacement forrobots.txt. Its value is not merely that a file exists, but whether the file helps machines find authoritative, compact, current information.
Context: The Web Is Adding AI-Facing Signals
Websites have long used robots.txt to express crawler preferences, sitemap.xml to improve URL discovery, and structured data to help search and platform systems interpret pages. Generative AI introduces a different problem. Content may be used for training, retrieval, summarization, agentic browsing, code assistance, customer support, and answer generation. That creates two simultaneous needs: publishers want more control over automated use, but they also want AI systems to find the right canonical information when those systems do interact with their sites.
The , introduced by Jeremy Howard in 2024, frames the file as a Markdown document placed at a website root to provide LLM-friendly information at inference time. The proposal argues that HTML pages often include navigation, advertising, scripts, and other noise that make them harder for language models to process. A concise Markdown file can point models toward the most important pages, docs, APIs, examples, policies, and product information.
External web research provides the broader backdrop. describes a rapid increase in AI-related restrictions in robots.txt and terms of service, and argues that existing web consent mechanisms were not designed for large-scale AI data reuse. has also made AI crawler and robots.txt patterns visible at the Top 10,000-domain level. In that environment, llms.txt sits on the constructive side of AI signaling: not “do not crawl this,” but “if you need to understand this site, start here.”
External Evidence and the Adoption Debate
The public debate around llms.txt is split between two claims. The optimistic claim is that the file gives AI systems a cleaner, more efficient path to authoritative content. The skeptical claim is that no major LLM provider has publicly committed to using it as a ranking, crawling, or citation signal, so publishers should not expect traffic gains from the file alone. The three external references reviewed for this update support a more nuanced conclusion: llms.txt is useful infrastructure, but the evidence for direct traffic impact remains limited and context-dependent.
External Adoption Benchmarks Are Moving Quickly
reported a 0.3% adoption rate across the top 1,000 websites as of June 22, 2025, or 3 out of 1,000 sites. It describes monthly automated scanning of domain.com/llms.txt, with validation that excludes redirects and HTML responses. That methodology is directionally similar to this study's conservative validation approach.
The difference in results is large: this study found 75 valid llms.txt files in the Tranco Top 1,000 on May 6, 2026, or 7.50%. The two numbers should not be treated as a strict time-series because the ranking source, implementation details, validation logic, and crawl timing may differ. Still, the contrast suggests that adoption changed materially between mid-2025 and May 2026, especially among developer, SaaS, cloud, security, and documentation-heavy sites.
| Source | Snapshot | Sample | Reported valid adoption | Interpretation |
|---|---|---|---|---|
| Rankability | June 22, 2025 | Top 1,000 websites | 0.3% | Early public benchmark showing minimal adoption in mid-2025. |
| This study | May 6, 2026 | Tranco Top 1,000 | 7.50% | Later crawl showing visible adoption among high-traffic sites. |
| This study | May 6, 2026 | Tranco Top 10,000 | 5.86% | Broader sample showing adoption is measurable but not mainstream. |
Traffic Experiments Remain Mixed
published a 10-site analysis in January 2026 that tracked sites for 90 days before and 90 days after implementation. The article reported that two sites saw AI traffic increases of 12.5% and 25%, eight saw no measurable improvement, and one declined by 19.7%. Its key interpretation was causal caution: the two apparent success stories also launched new templates, rebuilt resource centers, added extractable comparison tables, earned press coverage, fixed technical issues, or published new FAQ-style content. In that framing, llms.txt documented stronger content and technical work; it did not appear to cause the growth by itself.
reached a more positive conclusion from a smaller site-level observation. It compared two four-month periods in Yandex.Metrica after adding both llms.txt and llms-full.txt. LLM referral sessions rose from 75 to 92, a 23% increase, while users rose from 51 to 64. Perplexity sessions increased from 29 to 55, while ChatGPT sessions fell from 31 to 26. The same post also notes that total referral traffic grew faster, from 160 to 290 sessions, so the LLM session share fell from 47% to 32%.
| Evidence type | Observed result | Main caveat | How it affects this report |
|---|---|---|---|
| Search Engine Land 10-site before/after study | Two sites rose, eight had no measurable change, one declined. | Positive cases had concurrent content, PR, and technical changes. | Supports treating llms.txt as infrastructure, not a standalone growth lever. |
| Alimbekov personal blog before/after observation | LLM referral sessions rose 23% over the after period. | No control group; total referral traffic rose 81%, and LLM share fell. | Suggests possible upside for technical blogs, especially via Perplexity, but causality is not isolated. |
| This crawl-based adoption study | 586 valid files and many structured implementations. | Measures presence and structure, not downstream traffic impact. | Shows adoption and implementation maturity, but not ROI by itself. |
What the Debate Clarifies
The external evidence sharpens the interpretation of this dataset. A well-structured llms.txt file can reduce machine parsing friction, especially for developer documentation, API references, and knowledge-base content. But the strongest traffic cases still appear to depend on content that is useful, extractable, authoritative, and discoverable outside the file. For that reason, the practical question is not “does llms.txt matter?” in isolation. It is whether the file is part of a broader AI-readable content system.
Updated interpretation:
llms.txtshould be implemented as low-cost AI-facing infrastructure. It should not be positioned as a substitute for better documentation, structured content, technical accessibility, citations, links, or brand authority.
Methodology
This study used the Tranco Top 10,000 domains as its sample. Tranco is a research-oriented top-site ranking designed to be more stable and manipulation-resistant than many traditional top lists. The Tranco source file was downloaded on May 6, 2026, with a source Last-Modified timestamp of May 5, 2026 at 22:17:59 GMT.
The crawler probed two root-level paths for each domain:
https://example.com/llms.txt, with HTTP fallback when needed.https://example.com/llms-full.txt, with HTTP fallback when needed.
For each probe, the crawler recorded status code, final URL, fetch method, response bytes, content type, error message, elapsed time, and validation result. Successful response bodies were saved under raw_llms_txt/ for review and secondary analysis.
Validation Rules
A response was counted as a valid file only if it returned a successful body and did not look like a generic web fallback. The final URL path had to remain /llms.txt or /llms-full.txt. Empty bodies were rejected. Obvious HTML documents and app shells were rejected. Content type was treated as supporting evidence rather than the only rule, because a small number of valid text-like files were served with unusual content types.
Adoption Landscape
The crawl found 586 valid llms.txt files in the Tranco Top 10,000. This yields a valid adoption rate of 5.86%. The smaller llms-full.txt companion file was present and valid on 103 domains, or 1.03% of the sample.
| Metric | Count | Share of Top 10,000 |
|---|---|---|
| Domains crawled | 10,000 | 100.00% |
| Valid llms.txt files | 586 | 5.86% |
| Valid llms-full.txt files | 103 | 1.03% |
| HTTP 200 responses for /llms.txt | 1,606 | 16.06% |
| HTTP 200 responses rejected as invalid | 1,020 | 10.20% |
Adoption Is Not Purely Top-Heavy
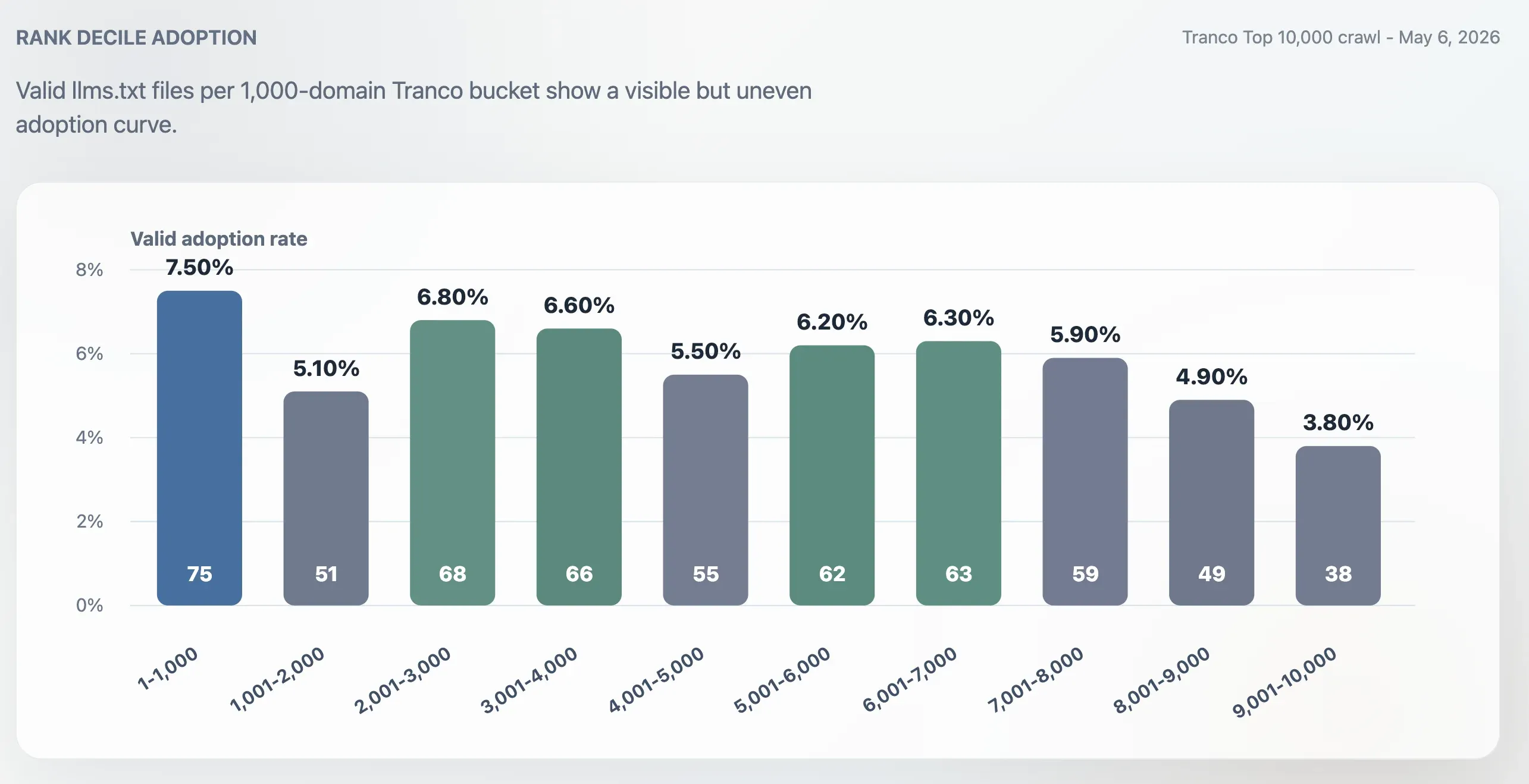
Adoption was higher in the Top 1,000 than in the full Top 10,000, but it was not confined to the very largest sites. The Top 1,000 adoption rate was 7.50%. The final 1,000-domain bucket, ranks 9,001-10,000, dropped to 3.80%. The middle of the ranking remained active: the 2,001-3,000, 3,001-4,000, 5,001-6,000, and 6,001-7,000 buckets all landed around 6%.
Early Adopters
The highest-ranked valid adopter was Cloudflare at Tranco rank 4. Other high-ranking adopters included Azure, GitHub, DigiCert, WordPress.org, Adobe, Sentry, Dropbox, PayPal, Shopify, Taboola, Avast, Weather.com, Oxylabs, SourceForge, Cisco, Stripe, Slack, Dell, NVIDIA, Indeed, Zendesk, Calendly, Palo Alto Networks, Okta, Braze, Klaviyo, Intercom, Datadog, Cloudinary, ClassLink, and OneSignal.
These adopters are not random. They tend to have large documentation surfaces, product lines that require explanation, APIs or developer ecosystems, support content, pricing pages, security and privacy material, and enough brand authority to care about how AI systems interpret their sites.
| Rank | Domain | File size | Observed pattern |
|---|---|---|---|
| 4 | cloudflare.com | 4,225 B | Compact product, developer, company, and pricing index. |
| 26 | azure.com | 47,037 B | Developer tools, AI, compute, storage, security, monitoring, and optional resources. |
| 28 | github.com | 27,108 B | Programmatic access, Copilot, MCP, REST API, Actions, repositories, and CLI links. |
| 248 | stripe.com | 64,229 B | Payments, Connect, Checkout, Billing, Tax, Atlas, Radar, and developer docs. |
| 265 | salesforce.com | 1.02 MB | Massive product and Agentforce link catalog, with no Markdown section headings. |
Top 1,000 Adopter Categories
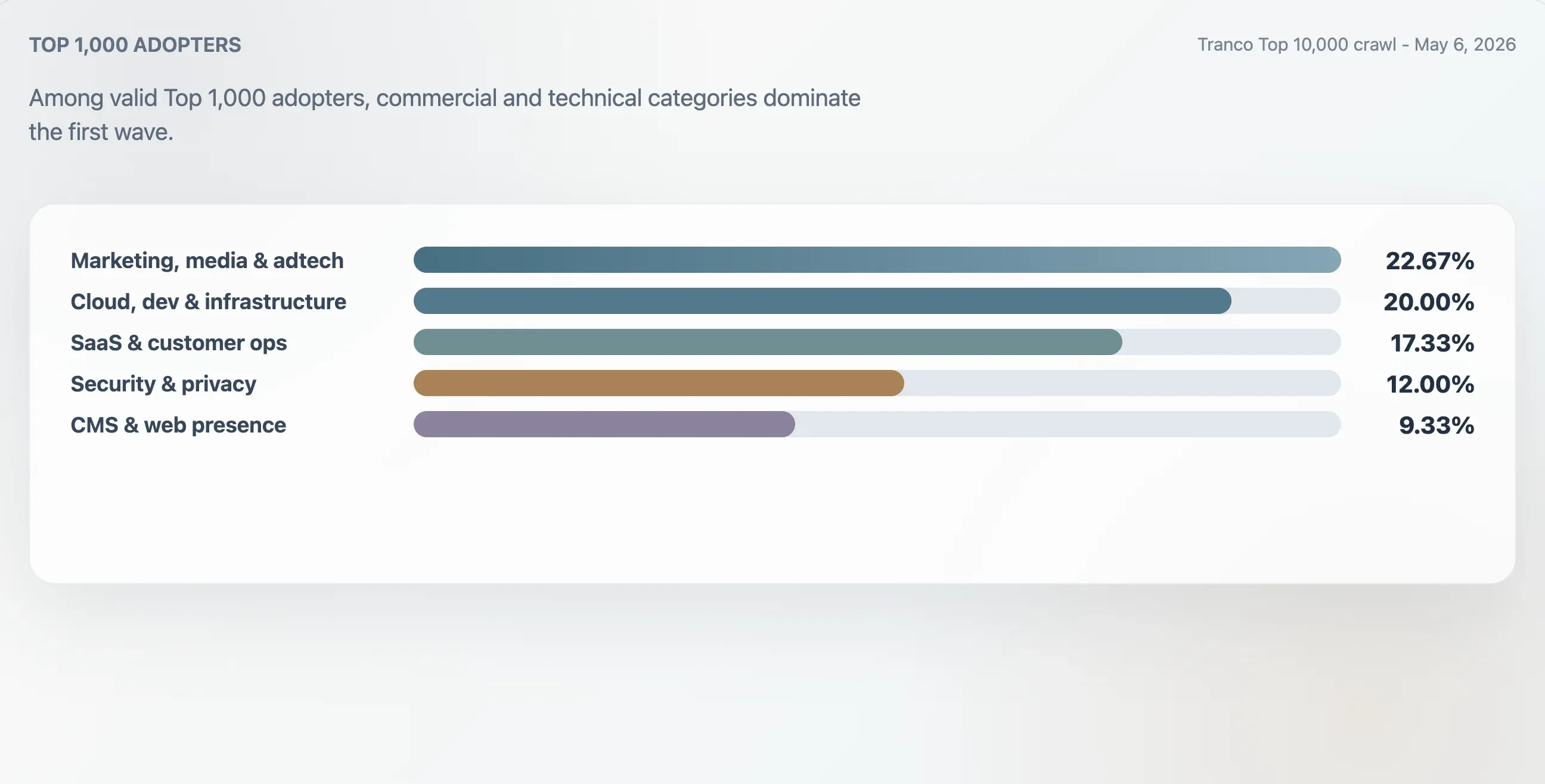
This study classified the 75 valid adopters in the Tranco Top 1,000 using domain context, first headings, raw file structure, and content keywords. The largest group was marketing, media, and adtech at 22.67%. Cloud, developer, and infrastructure sites accounted for 20.00%. SaaS, productivity, and customer-operations sites accounted for 17.33%. Security, identity, and privacy sites accounted for 12.00%.
| Category | Domains | Share of Top 1,000 adopters | Median quality score | Median links |
|---|---|---|---|---|
| Marketing, media & adtech | 17 | 22.67% | 94 | 25 |
| Cloud, dev & infrastructure | 15 | 20.00% | 94 | 62 |
| SaaS, productivity & customer ops | 13 | 17.33% | 94 | 46 |
| Security, identity & privacy | 9 | 12.00% | 98 | 78 |
| CMS, hosting & web presence | 7 | 9.33% | 100 | 24 |
TLD Patterns
Top-level domains are not industry labels, but they are useful directional signals. Among TLDs with at least 50 domains in the sample, .io had the highest valid adoption rate at 14.44%. .com followed at 8.19%. Lower adoption among .gov, .edu, and .net suggests that the early adopter base is more commercial and technical than institutional.
Implementation Quality
Valid adoption does not mean uniform implementation quality. Some files are concise, well-sectioned indexes. Some are mostly prose. Some are raw link catalogs. Some are near-empty placeholders. Some are multi-megabyte content dumps that may be complete but expensive to fetch and parse.
Among valid llms.txt files, 362 were larger than 5 KB, or 61.77% of valid adopters. The median file size was about 7.1 KB. The P90 file size was 156 KB, P95 was 356 KB, P99 was 2.54 MB, and the largest observed file was 7.97 MB.
Common Content Signals
A keyword-level scan of valid files found that many sites are not merely publishing a declaration; they are pointing models toward operationally useful material. Support or help terms appeared in 70.31% of valid files. Blog, guide, or tutorial terms appeared in 67.92%. Security, privacy, compliance, or terms appeared in 61.43%. Pricing appeared in 53.92%, documentation in 52.22%, API terms in 33.96%, and changelog or release signals in 27.30%.
Quality Scoring and Archetypes
To move from presence to maturity, this study created a lightweight implementation score. The score considers content type, file size, Markdown structure, link count, topic coverage, and warning signs such as missing headings, no Markdown links, unusual content types, tiny files, very large files, and link-dump behavior. This is not a formal standard. It is a research scoring model for comparing observed implementations.
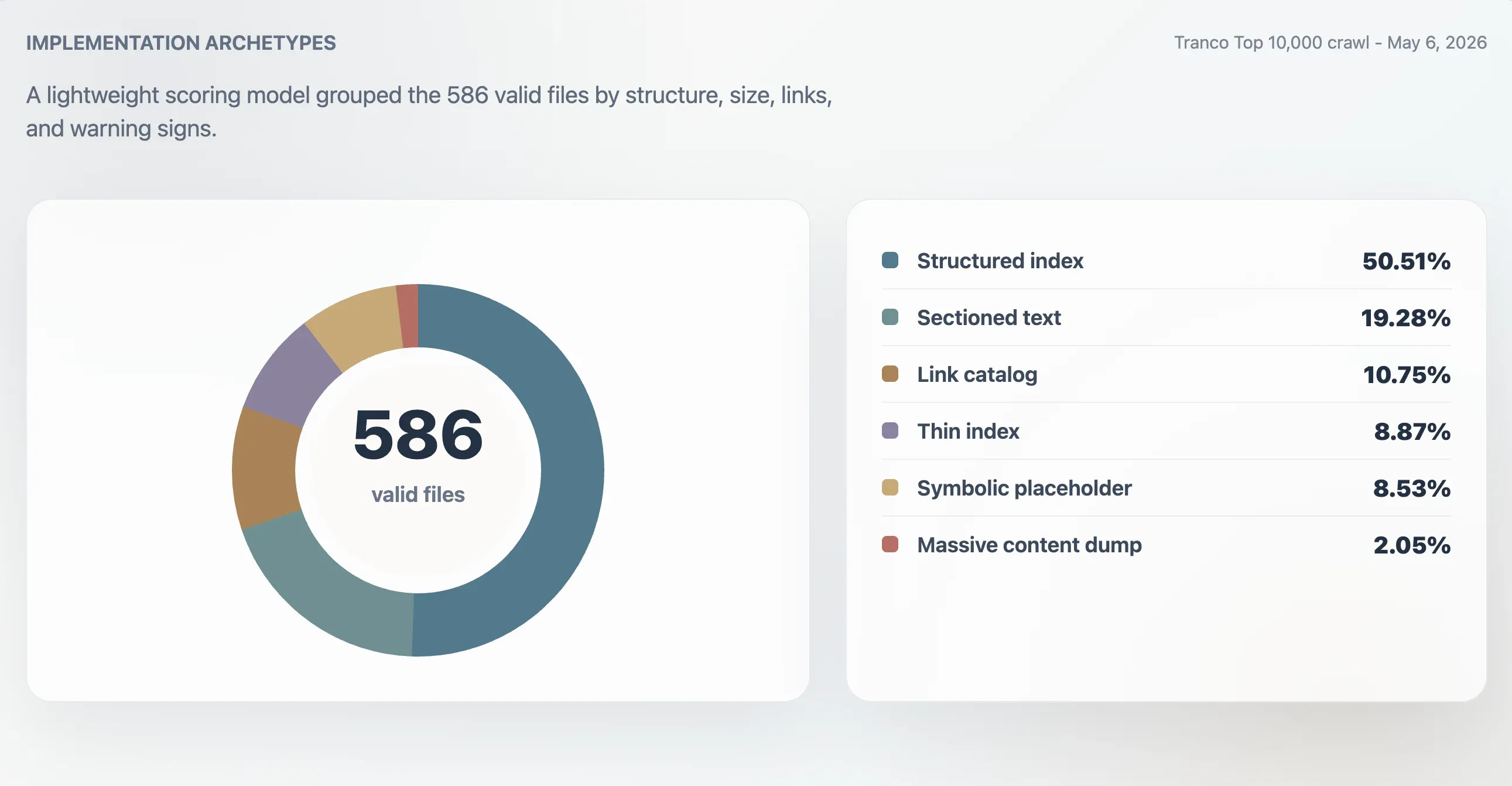
Using this model, 416 valid files were classified as strong structured indexes, 107 as usable indexes, 24 as thin or irregular, and 39 as symbolic or low utility. A separate archetype analysis found 296 structured indexes, 113 sectioned-text files, 63 link catalogs, 52 thin indexes, 50 symbolic or placeholder files, and 12 massive content dumps.
| Archetype | Domains | Share of valid files | Median score | Median file size | Median links |
|---|---|---|---|---|---|
| Structured index | 296 | 50.51% | 98 | 11,241 B | 61.5 |
| Sectioned text | 113 | 19.28% | 78 | 4,718 B | 0 |
| Link catalog | 63 | 10.75% | 86 | 4,160 B | 23 |
| Thin index | 52 | 8.87% | 66 | 2,814 B | 0 |
| Symbolic or placeholder | 50 | 8.53% | 27 | 15 B | 0 |
| Massive content dump | 12 | 2.05% | 74 | 2.84 MB | 7,259.5 |
Top Adopters Have Denser Implementations
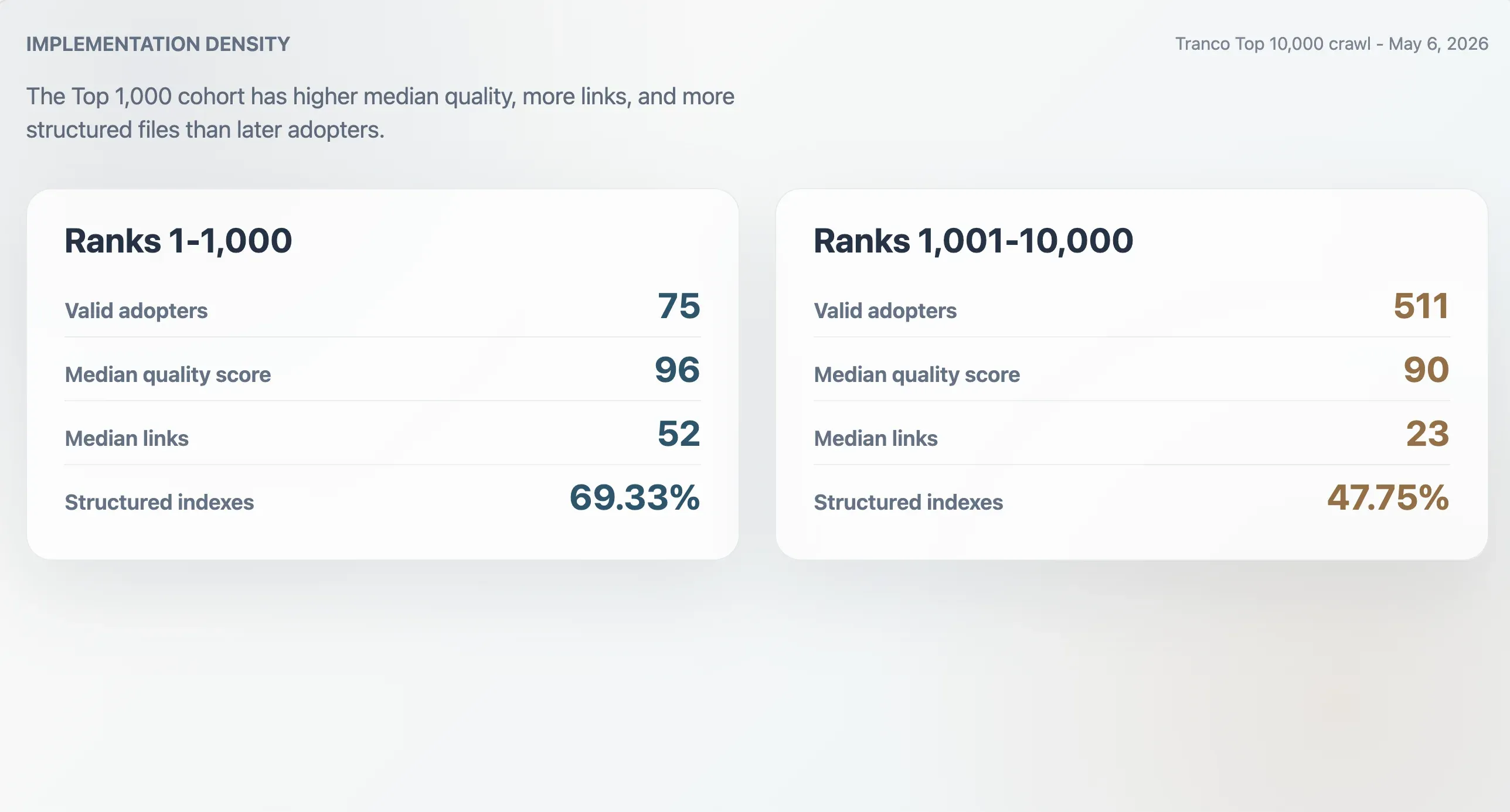
The 75 valid adopters in the Tranco Top 1,000 had a median quality score of 96, median file size of 9,068 bytes, median Markdown link count of 52, and median section count of 11. The 511 adopters ranked 1,001-10,000 had lower medians: score 90, file size 6,506 bytes, 23 Markdown links, and 9 sections. Top 1,000 adopters were also more likely to be structured indexes: 69.33% versus 47.75% in the later cohort.
The False Positive Problem

The largest measurement risk is false positives. Of the 1,606 domains that returned HTTP 200 for /llms.txt, 1,020 failed validation. The most common invalid reason was off-target redirection, with 618 cases. Another 367 responses were generic HTML documents. Twenty-nine returned an empty body, and six were other or uncategorized invalid responses.
This matters because many large sites route unknown paths to login pages, homepages, app shells, regional pages, consent surfaces, or marketing fallbacks. These responses can look healthy to a status-code crawler but contain no valid llms.txt signal.
llms-full.txt: Scarcer and More Uneven
The companion llms-full.txt file was much less common than llms.txt. The crawl found 103 valid full files, equal to 17.58% of valid llms.txt adopters and 1.03% of the full Top 10,000 sample.
Full-file implementations were uneven. Among the 103 dual-file adopters, 57 had a llms-full.txt file larger than the index file, but 46 either had a full file no larger than the index file or had a full file under 100 bytes. The median full-to-index size ratio was 1.43, but extreme cases were much higher. Supabase's full file was roughly 7,139 times the size of its index file. Made-in-China.com had an 89.89 MB full file.
| Domain | llms.txt | llms-full.txt | Ratio |
|---|---|---|---|
| made-in-china.com | 4.49 MB | 89.89 MB | 20.0x |
| sendbird.com | 281.86 KB | 11.99 MB | 42.5x |
| taboola.com | 286.78 KB | 11.73 MB | 40.9x |
| supabase.co | 1.26 KB | 8.98 MB | 7,139.3x |
| neon.tech | 27.44 KB | 5.01 MB | 182.7x |
Recommendation: publish
llms-full.txtonly when the site already has a stable documentation pipeline, versioning discipline, and a clear reason to expose large volumes of content in a single machine-readable file.
llms.txt, robots.txt, and sitemap.xml
llms.txt should not be treated as a new robots.txt. They are both root-level machine-readable files, but they communicate different things. robots.txt is a crawler preference and access-control signal. sitemap.xml is a URL discovery signal. llms.txt is an explanatory and navigational signal.
| Signal | Primary role | Typical reader | Interpretation in this study |
|---|---|---|---|
robots.txt | Declare crawler preferences and path-level restrictions. | Search crawlers, AI crawlers, archive crawlers, generic bots. | Governance and access signal. |
sitemap.xml | List discoverable URLs for indexing systems. | Search engines and indexing pipelines. | Discovery signal. |
llms.txt | Provide compact site context, important links, docs, APIs, examples, and policy references. | LLM applications, AI agents, developer tools, retrieval systems. | Explanation and navigation signal. |
Recommendations
For sites considering llms.txt, the strongest implementations in this dataset and the external traffic evidence suggest a pragmatic pattern:
- Publish
/llms.txtat the root and keep it accessible without login, JavaScript execution, consent walls, or off-path redirects. - Serve it as
text/plainortext/markdownwhen possible. - Start with a short description of the site, then group links by product, documentation, API, pricing, changelog, examples, support, policies, and company resources.
- Prefer canonical links over exhaustive URL lists.
- Avoid empty symbolic files; they count as a weak signal at best.
- Avoid massive undifferentiated dumps unless there is a strong machine-consumption use case and a reliable generation pipeline.
- Validate final URL, response body, content type, Markdown structure, link count, and file size after publishing.
Teams should also set expectations carefully. The available public experiments do not prove that llms.txt independently increases AI referral traffic. If a team wants to test business impact, it should track LLM referrals, cited pages, bot requests, index freshness, and content changes together. A useful experiment would compare matched page groups, hold content updates constant where possible, and separate platform-specific traffic such as Perplexity, ChatGPT, Gemini, Claude, and Bing/Copilot.
Limitations
This is a crawl-based snapshot, not a permanent ground truth. Websites can add, remove, or change llms.txt files at any time. Some domains may block automated requests or behave differently by geography, TLS configuration, redirect logic, user agent, or bot mitigation. The study tested root-level files only and did not search subdomains or nonstandard paths.
The quality score and archetypes are research tools, not official compliance labels. The topic analysis is keyword based and should be read as directional. The study does not prove that any specific AI platform currently reads, honors, or uses llms.txt in production.
The external traffic evidence reviewed in this version also has limitations. Search Engine Land's analysis is stronger as a cautionary multi-site observation than as a randomized experiment. Alimbekov's result is useful as a transparent site-level case study, but it lacks a control group and includes a period when total referral traffic rose substantially. These references help frame the debate, but they do not turn this crawl into a causal traffic study.
Files and Reproducibility
| File | Purpose |
|---|---|
crawl_llms_txt.py | Crawler for /llms.txt and /llms-full.txt. |
analyze_llms_txt.py | Primary adoption analysis and chart generation. |
deep_analyze_llms_txt.py | Secondary analysis for rank deciles, TLDs, topic signals, quality scores, archetypes, and dual-file behavior. |
deep_dive_early_quality.py | Early-adopter classification and implementation-quality deep dive. |
data/llms_probe_results_top_10000.csv | Main crawl result dataset. |
data/deep_analysis_top_10000.json | Secondary analysis summary. |
data/deep_early_quality_analysis.json | Early adopter categories, quality cohort comparison, archetype details, and case studies. |
Sources
- , Jeremy Howard, 2024.
- .
- .
- .
- , Data Provenance Initiative.
- .
- , Search Engine Land, January 2026.
- , Rankability, June 2025.
- , Renat Alimbekov.
Methodology corrections, dataset issues, and follow-up analyses welcome at support@thunderbit.com. This report is published independent of any commercial position Thunderbit holds. The data in this report stands on its own. — The Thunderbit research team, May 2026.