

A few months ago, a colleague on our sales team asked me a question I've heard dozens of times: "If I scrape competitor prices from a public website, can I actually get in trouble?" He'd found a directory of supplier contacts, prices lined up in neat rows, and all he wanted was a spreadsheet. The hesitation was real—and honestly, justified.
The UK has no single "web scraping law." Instead, four overlapping legal frameworks determine whether a specific scraping activity is lawful. That's why the answer is always "it depends"—but it doesn't have to be paralyzing. In this guide, I'll walk through what the law actually says, how it applies to real-world scenarios, what the penalties look like, and how to stay compliant.
I've spent a lot of time researching this for our team at Thunderbit, and I want to share what I've found so you don't have to piece it together from five different law firm blogs and a Reddit thread.
Try Thunderbit for Web Scraping
What Is Web Scraping (and Why UK Businesses Use It)
Web scraping is using software to automatically collect data from websites—replacing the tedious process of copying and pasting from web pages into a spreadsheet.
The technique itself is neutral. Not inherently legal, not inherently illegal. What matters is what you scrape, how you scrape it, and what you do with the data afterward.
UK businesses use scraping for all sorts of legitimate purposes:
- Price comparison: PriceSpy UK, for example, updates product prices three to five times per day using automated web scraping.
- Lead generation: Sales teams pulling company names, emails, and phone numbers from public directories.
- Market research: Analysts monitoring property listings, job boards, or competitor product ranges.
- Academic research: The Office for National Statistics collected over 2.2 million price quotes from supermarket websites between 2014 and 2015.
- AI model training: A rapidly growing—and legally unsettled—use case.
The trend is clear. A Bright Data/Vanson Bourne survey of 500 decision-makers (including 200 in the UK) found 89% saw public web data as crucial or very important to the global economy, and 38% sourced it at least daily.
Yet 73% also said the lack of clear regulation worried their organisation. That anxiety is exactly why this article exists.
Is Web Scraping Legal in the UK? The Direct Answer
No UK law bans web scraping outright. Multiple laws regulate how it can be done, though, and the legality of any specific project depends on four factors:
- What data you're scraping (personal data vs. factual/non-personal data)
- How you access it (public page vs. bypassing login walls or CAPTCHAs)
- What the website's terms say (do they prohibit automated access?)
- How you use the data afterward (internal analysis vs. commercial resale)
The best analogy I've found: web scraping is like photography in a public space. Taking a photo in public isn't automatically illegal—but certain subjects, locations, methods, and uses create legal risk. Scraping is similar. Public availability is relevant, but it's not the whole story.
The ICO's recent GenAI consultation is one of the clearest official UK statements on scraped personal data. It said legitimate interests remains the sole available lawful basis for training generative AI models using web-scraped personal data—but only if the developer passes a strict three-part test. That's a high bar, and it signals how seriously UK regulators treat scraped data.
The Four UK Laws That Apply to Web Scraping
Four overlapping lenses—any scraping project might trigger one, two, or all four.
UK GDPR and the Data Protection Act 2018
Scrape personal data—names, emails, phone numbers, IP addresses, social media profiles—and UK GDPR applies. "Publicly available" doesn't mean "free to use."
Publicly visible personal data is still personal data.
The most relevant lawful basis for commercial scraping is legitimate interests (Article 6)—but you can't just wave that phrase around. You must:
- Identify a specific, legitimate purpose
- Show the processing is necessary for that purpose
- Balance your interest against the rights of the individuals whose data you're collecting
The ICO's GenAI consultation response is especially pointed: developers should not assume broad societal benefit is enough, should evidence why alternatives to scraping are unsuitable, and should use transparency mechanisms that let individuals understand and exercise their rights. Source: ICO GenAI response.
For B2B lead generation, the same logic applies. A sales team may rely on legitimate interests for collecting publicly listed business contact info, but it still needs to document the legitimate interest, minimise fields collected, avoid special-category data, provide privacy information where feasible, and honour opt-outs.
Copyright, Database Rights, and the TDM Exception
Copyright protects original website content: text, images, product descriptions, articles. Factual data points like prices are usually less copyright-sensitive on their own—but copy and republish protected expression, and you're in infringement territory.
Database rights matter more for scraping than most people realise. The UK retained EU-style sui generis database rights after Brexit, and extracting a "substantial part" of a protected database—curated directories, product catalogues, marketplace listings—can infringe even where individual data points are factual.
The Text and Data Mining (TDM) exception under Section 29A CDPA permits copies for text and data analysis only where the user has lawful access and the purpose is non-commercial research. This is narrow. Commercial scraping, commercial AI training, and commercial dataset resale are not covered.
The UK government considered broadening this exception for AI training but, as of its March 2026 Copyright and AI report, decided not to introduce reforms until confident they meet objectives for creators, AI developers, and the UK economy. Under the status quo, permission is usually needed to copy protected works for AI training unless an existing exception applies.
Website Terms of Service and Contract Law
Most websites have Terms of Service (ToS) that prohibit or restrict automated scraping. Access the site, and you may already be agreeing to those terms—especially if you click through an acceptance screen (clickwrap). Browsewrap agreements (terms behind a footer link) are more fact-sensitive, but UK courts have shown willingness to enforce ToS restrictions on scraping. In the Ryanair v Billigfluege dispute, the court treated visible website terms as binding in a screen-scraping context.
robots.txt is not a statute. It's a machine-readable signal from the site owner. A typical file looks like this:
User-agent: *
Disallow: /account/
Disallow: /checkout/
Disallow: /private/
Crawl-delay: 10
Ignoring robots.txt doesn't automatically make scraping illegal, but it's treated by courts and the ICO as evidence of the website owner's intent. Ignoring it increases your legal exposure, especially if combined with ToS breach or aggressive request volumes.
The Computer Misuse Act 1990
This one keeps people up at night—and for good reason. It creates criminal offences. Section 1 covers unauthorised access to computer material (maximum 2 years' imprisonment). Section 3 covers unauthorised acts impairing computer operation (maximum 10 years' imprisonment).
CMA risk is lowest where data is truly public and the scraper doesn't bypass technical barriers. Risk rises when you:
- Bypass login walls, CAPTCHAs, or IP blocks
- Use stolen credentials or create fake accounts
- Send traffic volumes that impair the target service
The UK has not produced a clean US-style "public data is fair game" rule. That makes UK advice more cautious: public access materially lowers CMA risk, but website terms, technical controls, and the scraper's knowledge of restrictions can still matter.
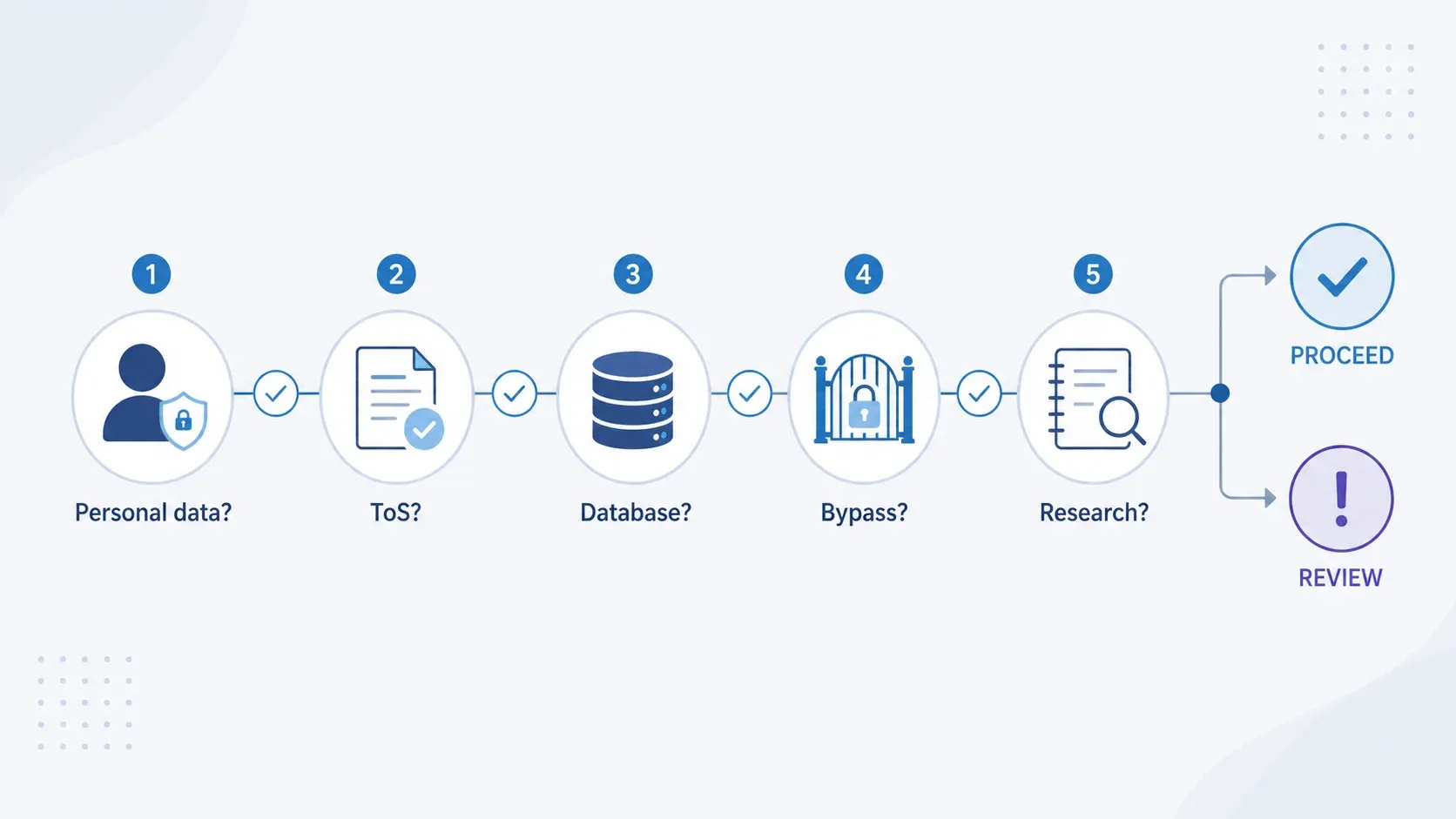
"Can I Legally Scrape This?" — A Quick Decision Flowchart
Before you scrape anything, walk through these five decision points. Not legal advice—just a 60-second risk triage.
| Decision Point | If YES | If NO |
|---|---|---|
| Data is personal data (names, emails, etc.)? | UK GDPR applies. Identify lawful basis, run LIA, minimise fields, plan transparency. | GDPR layer may not apply, but continue to other checks. |
| Site ToS explicitly prohibit scraping? | Breach-of-contract risk. Consider API, licence, or legal review. | Lower contract risk, but check robots.txt. |
| Extracting a substantial part of a database? | Sui generis database right likely infringed. Consider licensing or narrower extraction. | Copyright may still apply to individual copied content. |
| Bypassing login, CAPTCHA, or access controls? | Potential criminal offence under CMA 1990. Stop and get legal review. | Lower CMA risk if access is genuinely public. |
| Purpose is non-commercial research? | Section 29A TDM exception may apply if you have lawful access. | No broad UK commercial TDM safe harbour. Full IP and contract analysis needed. |
Ugh, I wish someone had given me this when I first started researching scraping compliance for our team. It turns legal complexity into a structured self-assessment you can run in under a minute.
Real Scenarios: Is Your Specific Scraping Activity Legal in the UK?
Abstract law is one thing. What people actually want to know: "Is my specific project going to get me in trouble?"
Fair enough. Here are five common UK scraping use cases with a mini legal risk assessment for each.
Scraping Product Prices for Comparison
One of the most common—and often lowest-risk—business use cases. Prices are factual data, and automated price collection is how sites like PriceSpy operate.
Risk doesn't disappear entirely, though. If the target site prohibits scraping in its ToS, if you copy product descriptions or images, or if you extract a substantial part of a curated product database, contract, copyright, and database-right issues may arise.
Risk level: LOW to MEDIUM
Key compliance step: Collect only factual price fields, avoid copying product descriptions verbatim, respect ToS and robots.txt, use rate limiting, and don't republish a raw mirror of the competitor's catalogue.
Scraping and Reselling Data Commercially
The highest-risk commercial scenario, full stop. You're turning another party's data investment into a product for sale—and that can implicate all four legal pillars simultaneously.
Risk level: HIGH
Key compliance step: Legal review is essential. Consider licensing agreements with data owners. If the product includes personal data, add a data protection impact assessment.
Extracting Business Contact Info for Lead Generation
Every sales team I've talked to does some version of this: scraping emails, phone numbers, and company names from directories. The catch? Business contact data often includes personal data. A named employee's email is personal data, even if it's publicly listed.
Risk level: MEDIUM
Key compliance step: Conduct a Legitimate Interests Assessment, only collect business (not personal-life) contact data where possible, document your lawful basis, and provide an opt-out route. Tools like Thunderbit can reduce access risk here because the Chrome extension operates in the user's browser—it accesses only what the user can already see, without bypassing access controls.
Academic or Portfolio Data Analysis
If you're doing genuinely non-commercial research, you have the strongest copyright exception pathway: Section 29A CDPA, provided you have lawful access.
Risk level: LOW (if genuinely non-commercial)
Key compliance step: Document non-commercial purpose, cite sources, anonymise or aggregate where possible, and avoid redistributing copyrighted content or personal data.
Scraping Content for AI Model Training
This is the one everyone asks about in 2026—and the answer is still unsatisfying. The ICO treats web-scraped personal data for training as high-risk invisible processing. The UK government's 2026 report did not introduce a broad commercial TDM exception.
Risk level: MEDIUM to HIGH
Key compliance step: Licensing, dataset provenance, copyright analysis, personal-data filtering, lawful-basis documentation, and close monitoring of UK policy changes.
Scenario Summary Table
| Scenario | Key Laws Triggered | Risk Level | Key Compliance Step |
|---|---|---|---|
| Product price monitoring | ToS, database rights, copyright | Low–Medium | Collect factual fields, respect site signals |
| Commercial data resale | All four pillars | High | Legal review and licensing essential |
| B2B lead generation | UK GDPR, ToS | Medium | Run LIA, minimise personal data |
| Academic research | Copyright (TDM exception), GDPR if personal | Low | Keep purpose non-commercial, don't republish |
| AI model training | UK GDPR, copyright, database rights | Medium–High | Licence data, document lawful basis, monitor policy |
UK vs. US vs. EU: How Web Scraping Law Differs
If you only operate in the UK, you can skip this section. But most businesses I talk to scrape internationally—or at least scrape websites hosted in other jurisdictions. The differences matter more than you'd think.
| Legal Dimension | 🇬🇧 UK | 🇺🇸 US | 🇪🇺 EU |
|---|---|---|---|
| Primary data protection law | UK GDPR + DPA 2018 | No federal equivalent (state laws vary) | EU GDPR |
| Key scraping precedent | Clearview AI (ICO £7.5M fine) | hiQ v LinkedIn (scraping public data OK, Ninth Circuit—but hiQ was permanently barred and paid $500K in final consent judgment) | Ryanair v PR Aviation (CJEU, C-30/14, database rights) |
| Computer access law | Computer Misuse Act 1990 | CFAA (narrowed by Van Buren, 2021) | Varies by member state |
| Copyright / TDM exception | Narrow: non-commercial research only (Section 29A) | Fair use doctrine (broader, case-by-case) | DSM Directive Art. 3 & 4 (broader TDM rights with rights reservation) |
| Database rights | Yes (retained from EU Database Directive) | No equivalent federal right | Sui generis right under Database Directive |
| ToS enforceability | Contract law applies; browsewrap debated | Mixed: browsewrap often unenforceable | Varies; Ryanair strengthened ToS position |
The practical takeaway: if you scrape across jurisdictions, comply with the strictest applicable law. The US is more permissive on public-data access under hiQ, but hiQ is not a blanket permission slip (hiQ was ultimately barred from scraping LinkedIn and paid $500K). The EU has broader TDM architecture through the DSM Directive. The UK sits somewhere in between—no broad commercial TDM exception, strong database rights, and an active regulator.
Penalties and Enforcement: What Actually Happens If You Get Caught
Vague warnings about "fines" and "legal trouble" don't help anyone. Here are the actual numbers.
UK GDPR Fines
Maximum penalty: £17.5 million or 4% of annual global turnover, whichever is greater.
Real example: Clearview AI was fined £7,552,800 by the ICO in 2022 for scraping facial images from UK social media. The First-tier Tribunal overturned on jurisdictional grounds, but the Upper Tribunal in October 2025 allowed the ICO's appeal and remitted the case. The ICO noted Clearview had permission to appeal to the Court of Appeal as of December 2025.
Computer Misuse Act Criminal Penalties
- Section 1 (unauthorised access): up to 2 years' imprisonment
- Section 3 (unauthorised impairment): up to 10 years' imprisonment
Criminal prosecution for ordinary public-page scraping is extremely rare.
The risk profile changes dramatically when conduct resembles hacking, credential misuse, CAPTCHA bypass, or service impairment.
Copyright and Database Rights
Civil damages plus injunctive relief. Criminal penalties possible for wilful commercial infringement, but most scraping disputes proceed as civil claims.
Contract (ToS) Breach
Civil damages, account termination, IP blocking. This is usually the most common practical enforcement action—and often the first thing that happens.
Penalty Severity Summary
| Legal Framework | Maximum Penalty | Likelihood for Typical Business Scraping | Real-World Example |
|---|---|---|---|
| UK GDPR | £17.5m or 4% global turnover | Medium if personal data at scale; low for non-personal | Clearview AI £7.5M fine |
| CMA Section 1 | 2 years' imprisonment | Low for public pages; higher if bypassing controls | CPS guidance on unauthorised access |
| CMA Section 3 | 10 years' imprisonment | Low unless traffic impairs systems | DDoS-style impairment examples |
| Copyright/database rights | Damages and injunctions | Medium for copying protected content or curated databases | Ryanair and BHB line of cases |
| ToS breach | Damages, account termination, blocking | High as a practical enforcement route | Ryanair screen-scraping disputes |
How the Right Scraping Tool Reduces Your Legal Risk
The tool you choose doesn't make an unlawful scrape lawful. But it can eliminate avoidable risk.
In my experience, the difference between a tool that respects site signals and one that aggressively bypasses everything is often the difference between a routine data project and a legal headache.
Respects robots.txt and Website Signals
A responsible tool should make it easy to check and respect robots.txt before scraping. While not legally binding, compliance with robots.txt is treated by courts and the ICO as evidence of good faith. Thunderbit's documentation advises users to scrape publicly available data and honour robots.txt and terms.
Browser Scraping vs. Cloud Scraping Options
This distinction matters legally. Browser scraping accesses only what the user can see in their authenticated session—essentially automating what you'd do manually. Cloud scraping sends requests from servers, which is faster for public sites but can look more like "automated access" from the site's perspective.
Thunderbit offers both modes. Browser scraping is appropriate for sites requiring login (reducing the risk of "unauthorised access" under the CMA), while cloud scraping works well for publicly available ecommerce pages where speed matters. This dual approach lets users match their scraping method to the legal risk profile of each site.
No Bypass of Access Controls
A tool that works within the browser and doesn't crack CAPTCHAs or circumvent login walls is inherently lower-risk under the Computer Misuse Act. Thunderbit's Chrome extension operates within the user's browser session—it accesses only what the user can already see.
Transparent Data Export (Supporting GDPR Compliance)
Thunderbit exports directly to Excel, Google Sheets, Airtable, or Notion. The user controls where data goes. This supports GDPR transparency and lawful basis documentation: you know exactly what data you collected and where it went. No hidden processing or data retention by the tool.
Rate Limiting and Responsible Access
Aggressive request volumes can trigger CMA Section 3 (unauthorised impairment). Rate limiting isn't just a technical best practice—it's a legal safeguard. Responsible tools avoid overwhelming servers, which reduces both legal risk and the chance of getting your IP blocked.

A Practical Compliance Checklist for UK Web Scraping
Run through this before you scrape anything:
- Read the target website's Terms of Service and Acceptable Use Policy.
- Check the robots.txt file and document whether relevant paths are disallowed.
- Determine whether the data you want is personal data. If yes, identify your lawful basis under UK GDPR.
- Assess whether you're extracting a "substantial part" of a database.
- Confirm you're not bypassing any technical access controls (CAPTCHAs, logins, rate limits).
- If your purpose is non-commercial research, document this to benefit from the TDM exception.
- Use rate limiting. Don't overwhelm the target server.
- Document everything: your lawful basis, ToS review, data fields collected, export destinations, retention period.
- If in doubt, get legal advice from a solicitor who specialises in data protection and IP.
This checklist doesn't replace a solicitor's opinion—but it gives you a solid starting framework and demonstrates good faith if questions ever come up.
Key Takeaways
- Web scraping is not illegal in the UK—but it's regulated by four overlapping legal frameworks: UK GDPR, copyright/database rights, contract law, and the Computer Misuse Act.
- The legality of any scrape depends on what you scrape, how you access it, what the website's terms say, and what you do with the data.
- Personal data scraping carries the highest compliance burden. Legitimate interests is usually the only viable lawful basis, and it requires a documented balancing test.
- The UK has no broad commercial TDM exception. Commercial AI training and dataset resale are high-risk without licensing.
- Use the decision flowchart and scenario table above to assess your specific situation before you start.
- Choose tools that align with compliance best practices: browser-based access, no CAPTCHA bypass, transparent data export, and rate limiting. Thunderbit is designed with these principles in mind—but the compliance responsibility always sits with the user.
- When in doubt, document your reasoning and talk to a solicitor. The cost of a legal opinion is almost always less than the cost of an ICO investigation.
Try AI Web Scraper with Thunderbit Get Started Free
FAQs
Is it legal to scrape publicly available data in the UK?
Generally, yes—scraping public data is lower risk than scraping gated or private data. But "publicly available" doesn't mean "free to use however you want." UK GDPR can still apply to public personal data, copyright can apply to copied expression, database rights can protect curated collections, and ToS can restrict automated access.
Can I scrape emails and phone numbers from UK websites?
If the data is personal data (which emails and phone numbers typically are), you need a lawful basis under UK GDPR. Legitimate interests is the most common basis for B2B lead generation, but you must conduct a balancing test, minimise the data you collect, and provide an opt-out route. Scraping personal-life contact data (mobile numbers, personal emails) is much higher risk than business directory listings.
What's the difference between web scraping and web crawling under UK law?
Legally, there's no meaningful distinction—the law cares about conduct, not labels. Crawling usually means discovering or indexing pages; scraping usually means extracting structured data. Both involve automated access to websites and are subject to the same legal frameworks.
Does robots.txt make scraping illegal?
No. robots.txt is not legally binding. However, ignoring it increases your legal exposure because courts and the ICO treat it as evidence of the website owner's intent. If you ignore robots.txt and the site's ToS also prohibits scraping, you're stacking risk factors—and that's a much harder position to defend.
Can I get criminally prosecuted for web scraping in the UK?
Only if you bypass access controls (CAPTCHAs, logins, IP blocks) or cause damage to a computer system under the Computer Misuse Act 1990. Ordinary scraping of genuinely public data, at reasonable volumes, without technical evasion, is extremely unlikely to result in criminal charges. The risk profile changes dramatically when conduct resembles hacking or deliberate service impairment.
Learn More




