

A few months ago, one of our users asked a question that stopped me mid-sip of coffee: "If I scrape public product prices from Coupang, will I end up in a Korean courtroom?" Honestly, I didn't have a confident one-liner ready — and neither did most of the legal guides I found online.
That question stuck with me because it's the same one thousands of e-commerce operators, sales teams, and SaaS founders quietly Google every week. The global web scraping services market hit roughly USD 1.03 billion in 2024 and is growing fast. More businesses than ever are collecting web data — and more of them are wondering where the legal lines are in Korea. Korea doesn't ban scraping outright.
But four major statutes can apply depending on what you scrape, how you scrape it, and why. The landmark case everyone references is the Korean Supreme Court's Yanolja ruling (2021Do1533, decided May 12, 2022), which acquitted a competitor's scraping tool on criminal charges — and then, in a separate civil track, hit the same company with roughly KRW 1 billion in damages. That dual outcome is the single most important thing a non-lawyer needs to understand about Korean scraping law, and it's the backbone of this guide. No law degree required — just a practical risk framework you can actually use.
Difficulty: Beginner (no legal or technical background needed)
Time Required: ~15 minutes to read; ongoing reference
What You'll Need: A basic understanding of what web scraping does (if you need a refresher, check out our post on what is web scraping)
Is Web Scraping Legal in Korea? The Short Answer
Web scraping itself is not illegal in Korea. It's a neutral technology — like a web browser or a spreadsheet formula. Korean courts have consistently focused not on the tool, but on the conduct surrounding its use.
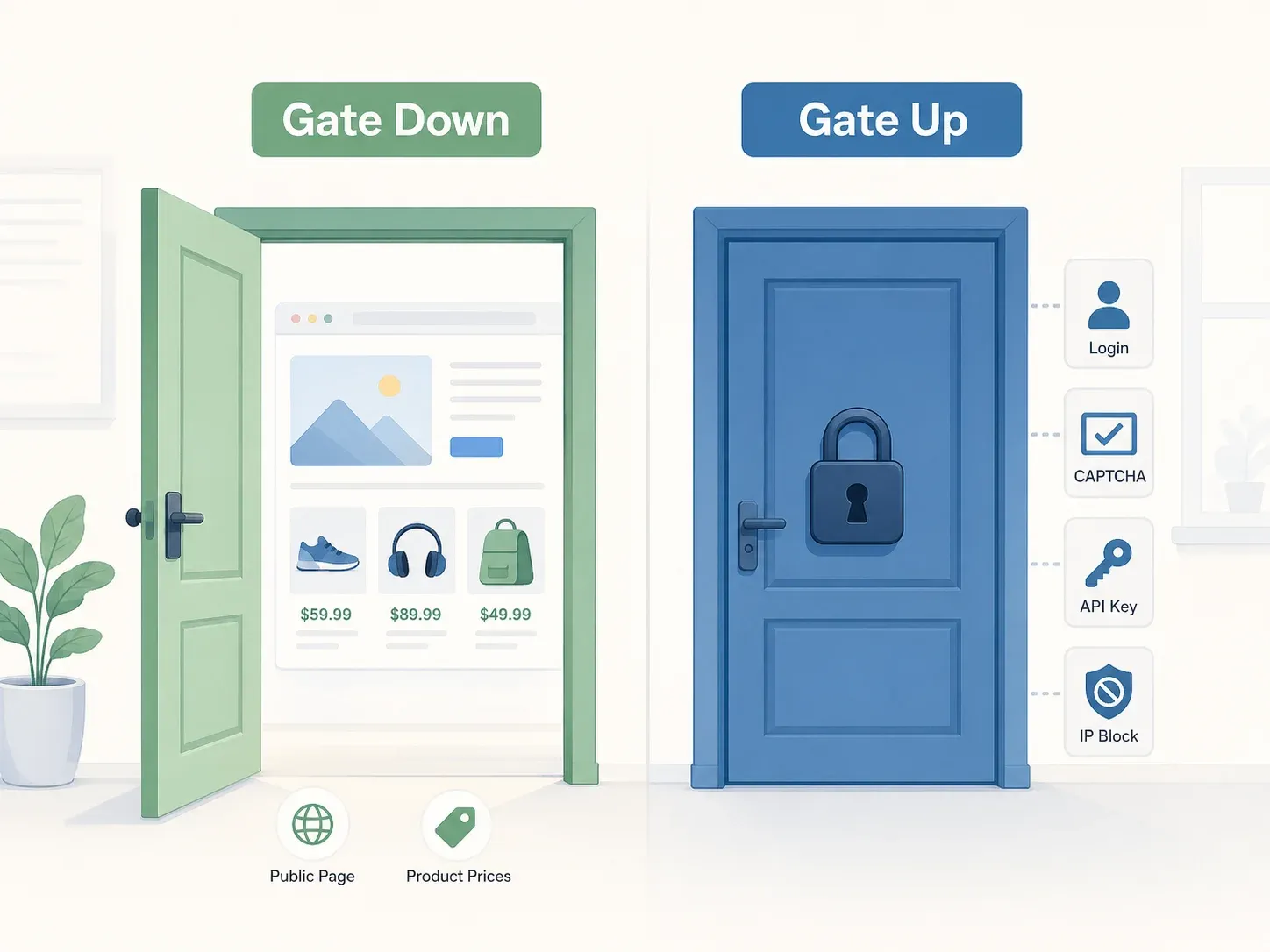
The best mental model comes from the Yanolja Supreme Court decision: the "gate up vs. gate down" principle. If a website has no objective access restrictions — no login wall, no CAPTCHA, no API key requirement, no IP block — the gate is "down," and accessing publicly available data is generally not a criminal offense under Korea's Information and Communications Network Act (ICNA). The Court specifically looked at whether "protective measures, terms of use, and other objectively revealed circumstances" restricted access, and found that Yanolja's API server was freely reachable through the public app.
But "not criminal" does not mean "zero risk."
Civil liability is a completely separate question. You can avoid prosecution and still face a billion-won damages award. The Yanolja case proved this with painful clarity.
Four Korean laws can apply to web scraping:
- ICNA (Information and Communications Network Act) — the "no trespassing" rule
- Copyright Act — database producer rights
- PIPA (Personal Information Protection Act) — personal data collection rules
- UCPA (Unfair Competition Prevention Act) — the "don't free-ride" catch-all
The rest of this guide maps these laws to real-world scenarios so you can figure out where your scraping project actually falls.
The Green-Yellow-Red Risk Framework for Web Scraping in Korea
Every legal article I found on Korean scraping law reads like it was written for attorneys. If you're an e-commerce operations manager or a SaaS founder, you don't need a 40-page statutory analysis — you need a quick way to assess risk before you start a project. Think of this as a traffic light. Green means go (with normal caution). Yellow means slow down and check your mirrors. Red means stop and call a lawyer.
Green Zone: Low-Risk Scraping Scenarios
| Scenario | Risk Level | Key Statute(s) | Why |
|---|---|---|---|
| Scraping public product listings (no login, no CAPTCHA) | 🟢 Low | ICNA, Copyright Act | Yanolja ruling: no access restriction = no ICNA violation; factual data (prices, availability) is not creative expression |
| Scraping public prices for internal analytics only | 🟢 Low | UCPA, Copyright Act | Factual data, limited scope, no competitive redistribution |
| Collecting non-personal, non-copyrighted facts from public pages | 🟢 Low | ICNA, Copyright Act | No access barrier bypassed; individual facts are not protected |
The Yanolja criminal decision anchors this zone. The Supreme Court found no ICNA intrusion because the API server was freely reachable — ordinary users could access it through the app with or without membership, and no separate protective measures blocked API access.
For Thunderbit users, this is the sweet spot. If you're scraping public e-commerce or real-estate pages using cloud scraping mode — collecting product names, prices, availability, or listing metadata while excluding personal data fields — you're typically operating in the green zone. (That said, "typically" is not "always," and I'll explain the nuances below.)
Try Thunderbit for public data scraping
Yellow Zone: Medium-Risk Scraping Scenarios
| Scenario | Risk Level | Key Statute(s) | Why |
|---|---|---|---|
| Scraping personal data (names, emails, phone numbers) even from public pages | 🟡 Medium | PIPA, ICNA | PIPA applies regardless of public visibility; 2023 amendments tightened consent rules |
| Scraping large volumes that might constitute a "substantial part" of a competitor's database | 🟡 Medium | Copyright Act, UCPA | Quantitative + qualitative test under Korean law |
| Ignoring robots.txt signals | 🟡 Medium | Evidence of bad faith | Not criminal per se, but can be used against you in court |
| Scraping public data but using it to directly compete with the source | 🟡 Medium | UCPA | Free-riding on another platform's investment |
Personal data is the single biggest yellow-zone trigger.
Even if a phone number or email is visible on a public webpage, PIPA still applies. The 2023 PIPA reform broadened data-subject rights and tightened consent requirements. And in 2024, Korea's Personal Information Protection Commission (PIPC) issued guidance specifically addressing publicly available personal information in the context of AI and data collection — making clear that public accessibility alone is not a blanket permission.
Volume matters too. The Yanolja Supreme Court said both quantitative and qualitative factors determine whether you've copied a "substantial part" of a database. Compare the copied portion to the overall database, and ask whether it reflects the producer's substantial investment.
Red Zone: High-Risk Scraping Scenarios
| Scenario | Risk Level | Key Statute(s) | Why |
|---|---|---|---|
| Scraping behind a login wall or bypassing access controls | 🔴 High | ICNA Art 48 | "Gate up" = unauthorized access; high prosecution risk |
| Circumventing CAPTCHAs, IP bans, or bot-detection systems | 🔴 High | ICNA Art 48(4) | 2024 amendment specifically targets bypass tools/devices |
| Copying and reselling a competitor's full database | 🔴 High | Copyright Act (DB rights), UCPA | Substantial reproduction + commercial free-riding |
| Collecting personal information without legal basis for marketing/outreach | 🔴 High | PIPA | Up to 5 years / KRW 50M fine; administrative penalties up to 3% of revenue |
A 2024 addition to ICNA — Article 48(4) — now specifically prohibits installing, transferring, or distributing programs or technical devices that bypass "normal protection or authentication procedures" without legitimate reason.
Separately, a November 2024 Supreme Court decision (2021Do5555) reinforced that unauthorized network intrusion can exist even without physical destruction of protective measures. Using another person's identifiers or improper commands to evade access limits is enough.
The Four Korean Laws That Apply to Web Scraping
| Law | What It Protects | When It Kicks In for Scrapers |
|---|---|---|
| ICNA Article 48 | Network stability, access authority | Bypassing login, CAPTCHA, authentication, IP blocks, API key limits |
| Copyright Act (Art 93) | Creative works + database producer rights | Copying expressive content, images, or all/substantial parts of a database |
| PIPA | Personal information, data-subject rights | Collecting names, phone numbers, emails, IDs — even from public pages |
| UCPA (Art 2(1)(k) and (m)) | Fair competition, commercially valuable data | Free-riding on another platform's data investment for your own competing business |
ICNA Article 48: The "No Trespassing" Rule
ICNA Article 48(1) says no one shall intrude into an information and communications network "without legitimate access authority or beyond permitted access authority." In scraping terms: if the website has access restrictions you bypass, you're in violation. If there are no restrictions — public page, no login — you're likely fine.
The penalty for violation is up to five years' imprisonment or a fine up to KRW 50 million under ICNA Article 71.
One nuance worth noting: the Korean Supreme Court has consistently treated Terms of Service restrictions as different from access restrictions. Yanolja's app terms limited commercial reuse and prohibited automated programs that burdened the server, but the Court found these clauses did not objectively restrict access to the API server itself.
Copyright Act: Database Producer Rights
Korea's Copyright Act protects database producers separately from copyright on individual content. Under Article 93, reproducing "all or a substantial part" of a database is illegal — even if individual data points are public facts.
The test is both quantitative (how much did you copy relative to the whole?) and qualitative (does the copied portion reflect the producer's substantial investment in building, verifying, or maintaining the database?). Repeated or systematic copying of smaller portions can also count if it effectively achieves the same result as copying a substantial part.
Penalty for database producer right infringement: up to three years or KRW 30 million under Article 136(2)(3). Statutory damages under Article 125-2 allow up to KRW 10 million per work, or KRW 50 million per work for intentional for-profit infringement.
PIPA: Personal Information Protection Act
PIPA governs collection of personal data — names, contact info, IDs — even if publicly visible. The 2023 reform was significant: it expanded data-subject rights, tightened consent requirements, introduced automated decision-making rules, and set administrative penalties of up to 3% of total sales for specified violations.
The PIPC's 2024 public-data AI guideline directly mentions data obtained through "web crawling and scraping" in the context of publicly available personal information. The guideline clarifies that legitimate interests may serve as a basis in some contexts, but organizations need balancing, safeguards, rights protection, and governance.
And the trend is getting stricter. In March 2026, Korean press reported a PIPA amendment increasing maximum penalties for serious repeated data-leak failures to up to 10% of revenue, effective later in 2026.
UCPA: The Unfair Competition "Catch-All"
The UCPA is the statute that caught GC Company in the Yanolja civil case. The current Act contains two relevant provisions:
- Article 2(1)(k): covers unfair uses of electronically accumulated and managed technical or business data that is not secret
- Article 2(1)(m): the broader catch-all for using another person's outcomes achieved through substantial investment or efforts, for one's own business without permission, contrary to fair commercial practices
UCPA is civil-only for these provisions — no criminal penalty — but it can result in injunctions under Article 4, damages under Article 5, and even treble damages for specified willful cases under Article 14-2. The Yanolja civil case awarded roughly KRW 1 billion under this framework.
The Yanolja Case: Why You Can Win Criminally but Lose Civilly
This is the case every business user in Korea needs to understand. I'm going to tell it as a single story, because that's how it actually played out — and because the split outcome is the whole point.
What Happened: GC Company Scraped Yanolja's Travel Data
GC Company operated a competing online travel platform. They built a self-developed crawler that accessed Yanolja's Baro Reservation app API server, learning the API URLs and request commands and sending them to the server. The scraper collected accommodation information — partner names, addresses, prices, availability, and images. GC Company used this data internally for marketing and competitive positioning.
Yanolja filed both a criminal complaint and a civil lawsuit.
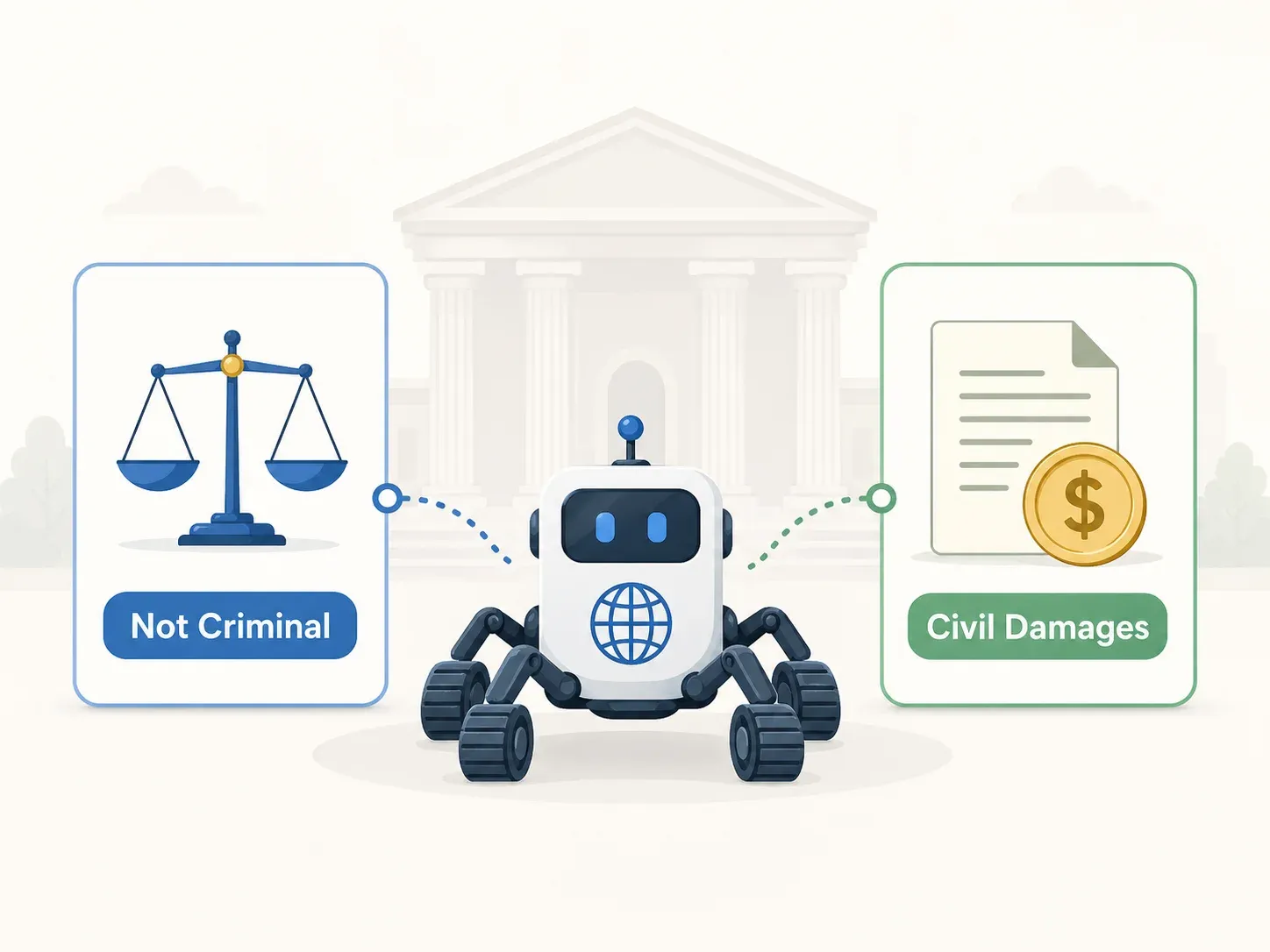
Criminal Verdict: Not Guilty on All Counts (Supreme Court 2021Do1533)
The Supreme Court affirmed the appellate court's acquittal on May 12, 2022, across all three charges:
- ICNA Article 48 (intrusion): No access restrictions existed. The API server was publicly accessible via browser and mobile app. No technical blocking was in place. ToS clauses limited use, not access.
- Copyright Act (database producer rights): The defendants didn't reproduce "all or a substantial part" of the database. The copied data was already publicly known, and the evidence didn't prove that the copied portion reflected Yanolja's substantial investment.
- Criminal Act Article 314 (business interference): No actual disruption to Yanolja's API server operation was proven. No modification of data. No mens rea for business interference.
The quotable rule: access restrictions must be assessed through "protective measures, terms of use, and other objectively revealed circumstances." If the gate is down, walking through it isn't trespassing.
Civil Verdict: KRW 1 Billion in Damages Under UCPA
Here's where the story turns. The Seoul Central District Court — and then the Seoul High Court (case 2021Na2034740, decided August 25, 2022) — ruled that GC Company violated the UCPA catch-all provision. The court awarded approximately KRW 1 billion (~USD 800K) in compensatory damages and ordered cessation of further data duplication.
The reasoning: Yanolja's accommodation database had commercial value and reflected substantial investment — collecting, verifying, and updating accommodation data. GC Company free-rode on that investment. The civil judgment was finalized at the Seoul High Court level.
Practical Takeaway: Criminal Acquittal Does Not Equal Civil Safety
This is the single most counterintuitive lesson from Korean scraping law. Criminally lawful access did not immunize commercially unfair use. "Can I be prosecuted?" and "Can I be sued?" are different questions with potentially opposite answers.
For business users: even if your scraping method is clearly in the green zone for criminal purposes, your use of the data — especially if it competes directly with the source — determines your civil risk.
Korea vs. US vs. EU: How Web Scraping Laws Compare
I couldn't find another guide that puts this in a single table — which is wild considering how many businesses scrape across borders.
| Dimension | South Korea | United States | EU / EEA |
|---|---|---|---|
| Core statute | ICNA Art 48, Copyright Act | CFAA (18 U.S.C. §1030), state laws | GDPR, Database Directive (96/9/EC) |
| Landmark case | Yanolja v GC Company (Supreme Court 2021Do1533, 2022) | hiQ v LinkedIn (9th Cir. 2022), Van Buren v. US (2021) | Ryanair v PR Aviation (CJEU C-30/14, 2015) |
| Public data scraping | Legal if no objective access barriers ("gate down") | Legal per hiQ reasoning (public data); Van Buren narrowed CFAA | Depends on DB rights, contract, copyright, GDPR, member-state law |
| Personal data rules | PIPA (2023 amended) — consent or legal basis | Sectoral: CCPA (California), state privacy laws | GDPR — strict consent / legitimate interest; max fine €20M or 4% global revenue |
| ToS violation = crime? | No (courts hold ToS ≠ ICNA violation) | No (Van Buren 2021: ToS ≠ CFAA) | Generally no, but contract breach possible (Ryanair) |
| Database protection | Copyright Act DB producer rights | No federal DB right | Sui generis database right |
| Max criminal penalty | Up to 5 yrs / KRW 50M (ICNA) | Up to 10 yrs / $250K (CFAA) | Varies by member state |
Key Differences That Matter for Your Business
- Korea has no broad text-and-data-mining (TDM) exception like the EU's DSM Directive. If you're training AI models on scraped Korean data, you don't get a statutory carve-out.
- Korea's UCPA catch-all is broader and less predictable than US unfair competition law. The Yanolja civil outcome would be much harder to replicate under US law.
- All three jurisdictions agree: violating Terms of Service alone is not a criminal offense.
- Korea's database protection is statutory (like the EU), while the US has no general federal database right. This gives Korean platform owners more civil tools.
- If you scrape across borders, the strictest applicable law governs. A scraping project touching Korean, US, and EU data needs to satisfy all three regimes.
Sector-Specific Scenarios: Is Web Scraping Legal in Korea for Your Industry?
The risk profile varies dramatically by industry, and no guide I've found maps Korean scraping law to specific verticals. So I pieced it together myself.
E-Commerce: Price Monitoring and Product Data

Scraping public product prices from Coupang, Gmarket, or 11Street is the cleanest green-zone example — stick to factual fields (price, availability, product name), avoid login-only areas, don't bypass technical blocks, and use the data internally for benchmarking.
Risk increases when you scrape product descriptions (creative content → copyright), seller contact information (PIPA), images (copyright), or an entire catalog (database producer rights + UCPA).
I didn't find a leading Korean e-commerce scraping lawsuit comparable to Yanolja. The more developed precedent is in travel and recruitment — but absence of lawsuits isn't absence of risk.
Thunderbit's scheduled scraper and cloud scraping mode are built for exactly this pattern: recurring price and inventory checks on public pages, with AI Suggest Fields letting you select the columns you want and exclude personal data fields.
Real Estate: Property Listings
Real estate is naturally yellow-zone territory. Listings on platforms like Zigbang or Naver Real Estate mix factual data (price, area, neighborhood) with agent names, office phone numbers, mobile numbers, photos, and curated platform databases.
Scraping public property details can be lower risk. But collecting agent contact columns immediately triggers PIPA — and scraping all listings in a region starts to look like substantial database copying.
Mitigation: exclude personal columns, reduce geographic scope, document a legitimate business purpose, respect rate limits, and avoid reproducing a competing listings service. Thunderbit's AI can be configured to extract only the property fields you need — price, square meters, location — while skipping personal contact data.
Recruitment: Job Postings
Recruitment is the high-risk sector, full stop. Korea has a direct precedent: JobKorea v. Saramin. Saramin scraped JobKorea's job-posting database and was found liable for database-right and unfair-competition infringement. Recruitment data commonly combines platform investment (curated, verified listings), high-volume database copying, and personal or recruiter contact information.
My recommendation: generally avoid scraping a competing job platform to build or enrich a rival job database. If the use case is narrow, get legal review before collection, minimize volume, remove personal contacts, and don't redistribute the results.
Complete Penalty Reference: What You Risk if Web Scraping Goes Wrong in Korea
| Korean Statute | Violation Type | Max Criminal Penalty | Max Civil/Admin Remedy | Key 2023–2026 Change |
|---|---|---|---|---|
| ICNA Art 48 | Unauthorized access / interference | 5 yrs / KRW 50M fine | Damages + injunction | 2024: Art 48(4) added, targeting bypass tools |
| Copyright Act (DB rights, Art 93) | Substantial reproduction of DB | 3 yrs / KRW 30M fine | Statutory damages up to KRW 50M/work (intentional for-profit) | — |
| PIPA | Unlawful personal data collection | 5 yrs / KRW 50M fine | Admin penalty up to 3% of total sales; class action possible | 2023 reform; 2024 public-data AI guideline; 2026 trend toward 10% for repeated leaks |
| UCPA Art 2(1)(k)/(m) | Unfair data acquisition / use | Civil only (no criminal for catch-all) | Damages + injunction; treble damages for specified willful cases | 2022 Data Framework Act strengthened provisions |
| Criminal Code Art 314 | Business interference via tech means | 5 yrs / KRW 15M fine | — | Yanolja: no actual disruption proven |
The critical point: criminal and civil tracks run independently. You can face both simultaneously — and win one while losing the other.
Your 10-Point Compliance Checklist for Web Scraping in Korea
Here are ten yes/no questions to run through before starting any scraping project. Print this out, bookmark it, tape it to your monitor — whatever works.
- Does the target site require no login to access the data you want? If a login, token, or account is needed, risk moves sharply toward ICNA Article 48.
- Are there no technical access restrictions? CAPTCHAs, IP blocks, API keys, rate limits, and bot walls are strong red-zone signals.
- Have you reviewed the site's robots.txt? Not legally binding by itself in Korean precedent, but useful evidence of site expectations and your good faith.
- Are you collecting any personal data? If names, phone numbers, emails, IDs, or individual contact details are in scope, PIPA analysis is required.
- Are you copying a "substantial part" of the site's database? Ask both quantitative and qualitative questions — how much, and does the copied portion reflect the source's investment?
- Have you defined your purpose? Internal analytics is lower risk than redistribution or building a competing database. (But Yanolja shows internal competitive use isn't a complete shield.)
- Have you documented your legitimate business purpose in writing? Documentation helps with PIPA legitimate-interest balancing and good-faith evidence.
- Have you stripped or anonymized personal data fields before storing/using? Excluding contact details often moves real-estate, recruitment, and directory scraping out of the most dangerous PIPA pattern.
- Are you using reasonable request intervals? Avoid server overload — Criminal Act Article 314 and ICNA Article 48(3) risks rise when scraping impairs service operation.
- Have you consulted Korean legal counsel for high-volume, commercial, or cross-border projects? Korean law plus GDPR/US privacy or computer-access laws may all apply.
⚠️ Disclaimer: This checklist is for orientation, not legal advice. Always consult local Korean legal counsel for specific situations.
How Thunderbit Helps You Scrape Korean Websites Responsibly
Full disclosure: I work on the marketing team at Thunderbit. But I genuinely think the product-law fit here is useful, not just a sales pitch.
Thunderbit is designed for the green-zone use cases this article describes: scraping publicly available data with no login required. Here's how specific features map to the compliance framework:
- Cloud scraping mode for public sites — no need to log in, no local session required, stays within publicly accessible boundaries. This aligns with the Yanolja "gate down" principle.
- AI Suggest Fields lets you define exactly which data columns to extract. Need product prices and availability but not seller phone numbers? Just exclude the personal columns. This is the simplest way to avoid PIPA triggers.
- Scheduled scraper for recurring price, inventory, or listing checks at reasonable intervals — no need to hammer a server with constant requests.
- Free data export to Excel, Google Sheets, Airtable, and Notion for internal analytics workflows.
- Subpage scraping to enrich public listing data (e.g., clicking into individual product pages for specs) without accessing login-only or restricted areas.
- AI layout adaptation — the scraper reads the site structure fresh each time, adapting to layout changes without brittle hardcoded selectors.
Thunderbit supports multilingual use across dozens of languages, which matters for teams working with Korean-language sites. You can try it free via the Thunderbit Chrome Extension.
No tool eliminates legal risk. But responsible configuration — public pages, factual data, excluded personal fields, reasonable intervals — keeps you in the compliance framework this article describes.
Key Takeaways on Web Scraping Legality in Korea
Five things worth remembering:
- Web scraping technology itself is legal in Korea. The Supreme Court confirmed this in the Yanolja decision.
- Risk depends on access method (gate up vs. gate down), data type (personal vs. factual), and use (internal vs. competitive redistribution).
- Criminal acquittal ≠ civil safety. The Yanolja case proves you can avoid prosecution but still face billion-won damages.
- When scraping public, non-personal, factual data for internal use with no access barriers, you're generally in the safe zone. But "generally" carries weight — scope, volume, and purpose all matter.
- Always consult local Korean legal counsel for large-scale or commercial projects. This article is for orientation, not legal advice.
If you're looking to start scraping Korean websites responsibly, Thunderbit's free tier lets you test the workflow on a small scale. For more on how AI-powered scraping works in practice, check out our guides on AI web scraping and web scraping without coding. And if you want to see the tool in action, our YouTube channel has walkthroughs for common use cases.
FAQs
1. Is scraping publicly available data legal in Korea?
Generally yes for criminal purposes — per the Yanolja Supreme Court ruling, accessing data from a site with no objective access restrictions does not violate ICNA. Civil liability under the UCPA or Copyright Act may still apply, though, depending on volume, the source's investment, and your commercial use of the data.
2. Can I be sued for web scraping in Korea even if it's not criminal?
Yes. The criminal and civil tracks are independent. GC Company was acquitted on all criminal charges but ordered to pay approximately KRW 1 billion in civil damages under the UCPA catch-all provision. Criminal acquittal provides no shield against civil claims.
3. Does violating a website's Terms of Service make scraping illegal in Korea?
Korean courts have consistently held that ToS violations alone do not constitute criminal offenses under ICNA — the Court distinguished between restricting use (ToS) and restricting access (technical barriers). That said, ToS violations could still support a civil breach-of-contract claim or serve as evidence of bad faith in an unfair competition analysis.
4. How does Korea's web scraping law compare to the US?
Both jurisdictions protect public data scraping (Yanolja in Korea, hiQ v LinkedIn in the US) and both hold that ToS breach alone is not a criminal offense (Van Buren in the US). The key difference: Korea has stronger statutory database protection and a broader unfair-competition catch-all than the US, which has no general federal database right. Korean platform owners have more civil-law tools to pursue scrapers.
5. What happens if I scrape personal data from Korean websites?
PIPA applies regardless of whether the information is publicly visible. Collecting personal information — names, phone numbers, emails — without consent or another legal basis is a violation. The 2023 PIPA amendment strengthened these protections, and the PIPC's 2024 guideline on publicly available personal information specifically addresses web crawling and scraping. Penalties can reach up to 5 years' imprisonment, KRW 50 million in fines, and administrative penalties of up to 3% of total sales.
Try Thunderbit for Responsible Web Scraping Get Started Free
Learn More




