

My OpenRouter dashboard showed $47 spent before lunch on a Tuesday. I'd run maybe a dozen coding tasks — nothing crazy, just some refactoring and a few bug fixes. That's when I realized OpenClaw's defaults were quietly routing every single interaction, including background heartbeat pings, through Claude Opus at $15+ per million tokens.
If you've seen similar surprises — and based on the forums, plenty of people have ("I already spend 40 dollars and doesn't even use it much," one user wrote) — this guide walks through the full audit-and-optimize approach I used to cut my monthly spend by roughly 90%. Not just "swap to a cheaper model," but a systematic teardown of where tokens actually go, how to monitor them, which budget models hold up for real agentic work, and three copy-paste configs you can use today. The whole process took an afternoon.
What Is OpenClaw Token Usage (and Why Is It So High by Default)?
Tokens are the billing unit for every AI interaction in OpenClaw. Think of them as tiny chunks of text — roughly 4 English characters per token. Every message you send, every response you receive, every background process that fires: all billed in tokens.
The problem is that OpenClaw's defaults are tuned for maximum capability, not minimum cost. Out of the box, the primary model is set to anthropic/claude-opus-4-5 — the most expensive option available. Heartbeat pings? They run on Opus too. Sub-agents that spawn to handle side tasks? Also Opus. Using Opus for a heartbeat ping is like hiring a neurosurgeon to apply a Band-Aid. Technically competent, catastrophically overpriced.
Most users don't realize they're paying premium rates for trivial background tasks. The default configuration essentially assumes you want the best model for everything, all the time — and bills accordingly.
Why Reducing OpenClaw Token Usage Saves More Than Just Money
The obvious benefit is cost savings. But there are secondary wins that compound over time.
Cheaper models are often faster. Gemini 2.5 Flash-Lite runs at roughly 214 tokens per second versus Opus at around 51 — that's a 4x speed improvement on every interaction. GPT-OSS-120B on Cerebras hits 1,917 tokens per second, which is roughly 35x faster than Opus. In an agentic loop with 50+ tool-calling turns, that speed difference means finishing in minutes instead of waiting through Opus's painful 13.6-second time-to-first-token on every round-trip.
You also get more headroom before hitting rate limits, fewer throttled sessions, and room to scale usage without scaling your anxiety about the bill.
Projected savings across different usage profiles:
| User Profile | Estimated Monthly Spend (Default) | After Full Optimization | Monthly Savings |
|---|---|---|---|
| Light (~10 queries/day) | ~$100 | ~$12 | ~88% |
| Moderate (~50 queries/day) | ~$500 | ~$90 | ~82% |
| Heavy (~200+ queries/day) | ~$1,750 | ~$220 | ~87% |
These aren't hypothetical. One developer documented going from $600–750/month down to $3–4/day — a genuine 90% cut — by stacking model routing with the hidden-drain fixes covered later in this guide.
OpenClaw Token Usage Anatomy: Where Every Token Actually Goes
This is the part most optimization guides skip, and it's the part that matters most. You can't fix what you can't see.
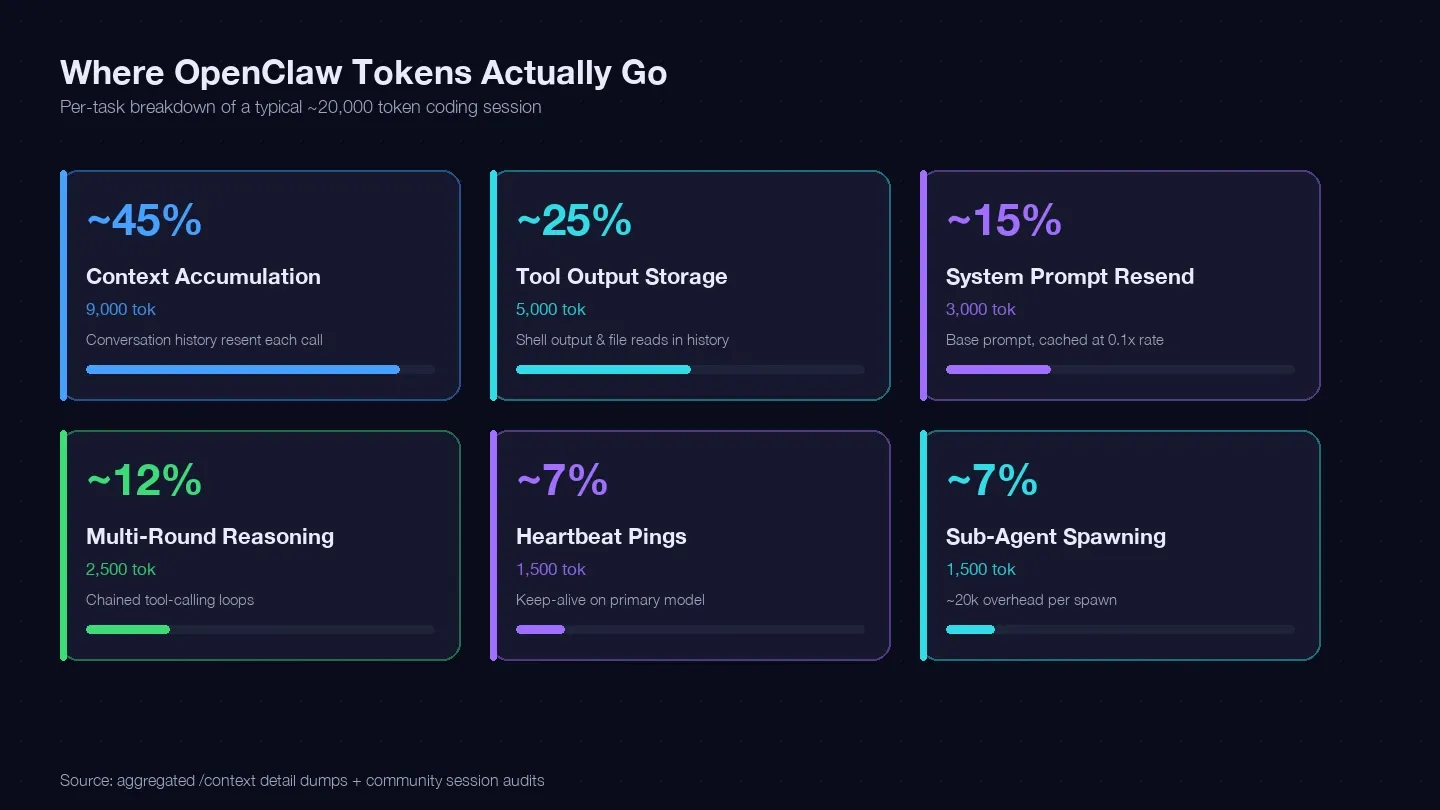
I audited several sessions and cross-referenced with the LaoZhang cost optimization guide and community /context dumps to build a token ledger for a typical single coding task. Here's where approximately 20,000 tokens actually went:
| Token Category | Typical % of Total | Example (1 coding task) | Can You Control It? |
|---|---|---|---|
| Context accumulation (conversation history resent each call) | ~40–50% | ~9,000 tokens | Yes — /clear, /compact, shorter sessions |
| Tool output storage (shell output, file reads kept in history) | ~20–30% | ~5,000 tokens | Yes — smaller reads, tighter tool scope |
| System prompt resend (~15K base) | ~10–15% | ~3,000 tokens | Partially — cache reads at 0.1x rate |
| Multi-round reasoning (chained tool-calling loops) | ~10–15% | ~2,500 tokens | Model choice + better prompts |
| Heartbeat / keep-alive pings | ~5–10% | ~1,500 tokens | Yes — config change |
| Sub-agent calls | ~5–10% | ~1,500 tokens | Yes — model routing |
The single biggest bucket — context accumulation — is your conversation history being resent with every API call. One real session dump showed 185,400 tokens in the Messages bucket alone, with the model not having responded yet. The system prompt and tools added another ~35,800 tokens of fixed overhead on top of that.
The takeaway: if you're not clearing sessions between unrelated tasks, you're paying to re-transmit your entire conversation history on every single turn.
How to Monitor OpenClaw Token Usage (You Can't Cut What You Can't See)
Before changing anything, get visibility into where your tokens are going. Jumping straight to "use a cheaper model" without monitoring is like trying to lose weight without ever stepping on a scale.
Check Your OpenRouter Dashboard
If you route through OpenRouter, the Activity page is the easiest no-setup dashboard. You can filter by model, provider, API key, and time period. The Usage Accounting view breaks down prompt, completion, reasoning, and cached tokens on every request. There's an Export button (CSV or PDF) for longer-range analysis.
What to look for: which model consumed the most tokens, and whether heartbeat or sub-agent requests are showing up as unexpectedly large line items.
Audit Your Local API Logs
OpenClaw stores session data in ~/.openclaw/agents.main/sessions/sessions.json, which includes totalTokens per session. You can also run openclaw logs --follow --json for real-time per-request logging.
One caveat worth knowing: sessions.json totalTokens is not updated after compaction, so the dashboard can show stale pre-compaction values. Trust /status and /context detail over the stored totals.
Use Third-Party Tracking (For Moderate-to-Heavy Users)
LiteLLM proxy gives you an OpenAI-compatible endpoint in front of 100+ providers and automatically logs spend per virtual key, model, user, and team. The killer feature: hard per-key budgets that survive /clear — a runaway sub-agent can't blow past a cap you set.
Helicone is even simpler — a one-line base-URL swap that gives you a Sessions view grouping related requests. A single "fix this bug" prompt that fans out to 8+ sub-agent calls shows up as one session row with the real total cost. Free tier: 10,000 requests/month.
Quick Spot-Checks Inside OpenClaw
For day-to-day monitoring, four in-session commands do the job:
/status— shows context usage, last input/output tokens, estimated cost/usage full— per-response usage footer/context detail— per-file, per-skill, per-tool token breakdown/compact [guidance]— force compaction with optional focus string
Run /context detail before and after making config changes. That's how you measure whether your optimizations actually worked.
The OpenClaw Cheapest Model Showdown: Which Budget LLMs Actually Handle Agentic Work
Most guides go wrong here. They show you a pricing table, point to the cheapest row, and call it a day. Benchmarks don't predict real-world agentic performance — a point the community has made loudly and repeatedly. As one user put it: "benchmarks aren't doing any justice to understand which one works best for agentic AI."
The critical insight: the cheapest model isn't always the cheapest outcome. A model that fails and retries four times costs more than a mid-tier model that succeeds on the first try. In production agent systems, plan for a 5–10% retry rate — and if five LLM calls are chained and step four fails, a naive retry re-runs all five steps.
Here's my capability matrix, with a "Real Agentic Score" based on actual user reports rather than synthetic benchmarks:
| Model | Input $/1M | Output $/1M | Tool-Calling Reliability | Multi-Step Reasoning | Real Agentic Score (1–5) | Best For |
|---|---|---|---|---|---|---|
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | Mixed — occasional loops | Basic | ⭐2.5 | Heartbeats, simple lookups |
| GPT-OSS-120B | $0.04 | $0.19 | Adequate | Adequate | ⭐3.0 | Budget experimentation, speed-critical |
| DeepSeek V3.2 | $0.26 | $0.38 | Inconsistent (6 open issues) | Good | ⭐3.0 | Reasoning-heavy, minimal tool calling |
| Kimi K2.5 | $0.38 | $1.72 | Good (via :exacto) | Adequate | ⭐3.5 | Simple-to-mid coding |
| MiniMax M2.5 / M2.7 | $0.28 | $1.10 | Good | Good | ⭐4.0 | General coding daily driver |
| Claude Haiku 4.5 | $1.00 | $5.00 | Excellent | Good | ⭐4.5 | Reliable mid-tier fallback |
| Claude Sonnet 4.6 | $3.00 | $15.00 | Excellent | Excellent | ⭐5.0 | Complex multi-step tasks |
| Claude Opus 4.5/4.6 | $5.00 | $15.00 | Excellent | Excellent | ⭐5.0 | Reserve for hardest problems only |
A Warning About DeepSeek and Gemini Flash for Tool Calling
DeepSeek V3.2 looks great on paper — 72–74% on SWE-Bench, 11–36x cheaper than Sonnet. In practice, six separate GitHub issues across Cline, Roo Code, Continue, and NVIDIA NIM document broken tool-calling behavior. Composio's head-to-head verdict: "DeepSeek V3.2 built parts of the app but stumbled on execution, speed, and reliability." Zvi Mowshowitz's one-liner: "okay and cheap, but."
Gemini 2.5 Flash has a similar gap. A Google AI Developers Forum thread titled "Very frustrating experience with Gemini 2.5 function calling performance" opens with: "the function calling behavior of Gemini models has become completely unreliable and unpredictable."
OpenRouter flagged a critical nuance: "the propensity of a model to call tools and the accuracy of those calls can vary dramatically across hosts of the same weights." If you route cheap models through OpenRouter, look for the :exacto tag — a silent provider swap can turn a reliable cheap model into an expensive retry loop overnight.
When to Use Each Model
- Gemini Flash-Lite: Heartbeats, keep-alive pings, simple Q&A. Never for multi-step tool calling.
- MiniMax M2.5/M2.7: Your daily driver for general coding tasks. SWE-Pro 56.22, Terminal-Bench 2 57.0% at a fraction of Sonnet's price.
- Claude Haiku 4.5: The reliable fallback when cheap models choke on tool calls. Excellent tool-calling reliability at ~3x cheaper than Sonnet.
- Claude Sonnet 4.6: Complex multi-step agentic work. This is where you get your money's worth.
- Claude Opus: Reserve for the hardest problems. Don't let it be your default for anything.
(Model pricing changes frequently — verify current rates on OpenRouter or direct provider pages before committing to a config.)
The Hidden Token Drains Most Guides Skip
Forum users report that disabling specific features drastically reduces costs, but no guide I've found provides a unified checklist of all hidden drains with their actual token impact. The full teardown:
| Hidden Drain | Token Cost per Occurrence | How to Fix | Config Key |
|---|---|---|---|
| Default heartbeat on Opus | ~100,000 tokens/run without isolation | Haiku override + isolatedSession | heartbeat.model, heartbeat.isolatedSession: true |
| Sub-agent spawning | ~20,000 tokens per spawn before any work | Route sub-agents to Haiku | subagents.model |
| Full codebase context loading | ~3,000–15,000 tokens per auto-explore | .clawignore for node_modules, dist, lockfiles | .clawrules + .clawignore |
| Memory auto-summarize | ~500–2,000 tokens/session | Disable or reduce frequency | memory: false or memory.max_context_tokens |
| Conversation history accumulation | ~500+ tokens/turn (cumulative) | Start new sessions between unrelated tasks | /clear discipline |
| MCP server tool overhead | ~7,000 tokens for 4 servers; 50,000+ for 5+ | Keep MCP minimal | Remove unused MCPs |
| Skill/plugin initialization | 200–1,000 tokens per loaded skill | Disable unused skills | skills.entries.<name>.enabled: false |
| Agent Teams (plan mode) | ~7x standard session cost | Use only for genuinely parallel work | Prefer sequential |
The heartbeat drain deserves its own callout. By default, heartbeats fire on the primary model (Opus) every 30 minutes. Setting isolatedSession: true drops that from ~100,000 tokens per run down to 2,000–5,000 tokens — a 95–98% reduction on that single bucket.
Three Quick Wins That Save the Most Tokens in Under Two Minutes
All three are zero-risk and take under two minutes:
-
/clearbetween unrelated tasks (5 seconds). This is the single biggest token saver. Forum consensus puts it at 50–70% reduction just from clearing session history before starting new work. Remember that 185k-token Messages bucket from the /context dump?/clearwipes it. -
/model haiku-4.5for grunt work (10 seconds). Tactical model switching yields 60–80% cost reduction on routine tasks. Haiku handles most straightforward coding, file lookups, and commit messages perfectly well. -
Shrink
.clawrulesto <200 lines + add.clawignore(90 seconds). Your rules file loads on every single message. At 200 lines that's ~1,500–2,000 tokens per turn; at 1,000 lines it's 8,000–10,000 tokens permanently taxing every request. Combined with a.clawignoreexcludingnode_modules/,dist/, lockfiles, and generated code, one developer claims a 92% token reduction from this discipline alone.
Step-by-Step: Three Ready-to-Copy Configs to Slash OpenClaw Token Usage

Three complete, annotated openclaw.json configurations follow — ranging from "just get started" to "full optimization stack." Each includes inline comments and monthly cost estimates.
Before You Start:
- Difficulty: Beginner (Config A) → Intermediate (Config B) → Advanced (Config C)
- Time Required: ~5 minutes for Config A, ~15 minutes for Config C
- What You'll Need: OpenClaw installed, a text editor, access to
~/.openclaw/openclaw.json
Config A: Beginner — Just Save Money
Five lines. Zero complexity. Swaps the default model from Opus to Sonnet, disables memory overhead, and isolates heartbeats to Haiku.
// ~/.openclaw/openclaw.json
{
"agents": {
"defaults": {
"model": { "primary": "anthropic/claude-sonnet-4-6" }, // was Opus — instant 3-5x savings
"heartbeat": {
"every": "55m", // align with 1h cache TTL for max cache hits
"model": "anthropic/claude-haiku-4-5", // Haiku for pings, not Opus
"isolatedSession": true // ~100k → 2-5k tokens per run
}
}
},
"memory": { "enabled": false } // saves ~500-2k tokens/session
}
What you should see after applying this: Run /status before and after. Your per-request cost should drop noticeably, and heartbeat entries in your OpenRouter Activity page should show Haiku instead of Opus.
| Usage Tier | Default (Opus) | Config A (Sonnet + Haiku heartbeats) | Savings |
|---|---|---|---|
| Light (~10 q/day) | ~$100 | ~$35 | 65% |
| Moderate (~50 q/day) | ~$500 | ~$250 | 50% |
| Heavy (~200 q/day) | ~$1,750 | ~$900 | 49% |
Config B: Intermediate — Smart Three-Tier Routing
Primary Sonnet for real work. Haiku for sub-agents and compaction. Gemini Flash-Lite as a budget fallback when Claude is throttled. Fallback chains handle provider outages automatically.
{
"agents": {
"defaults": {
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"anthropic/claude-haiku-4-5", // if Sonnet is throttled
"google/gemini-2.5-flash-lite" // ultra-cheap last resort
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m", // 55min < 1h cache TTL = cache hits
"model": "google/gemini-2.5-flash-lite", // pennies per ping
"isolatedSession": true,
"lightContext": true // minimal context in heartbeat calls
},
"subagents": {
"maxConcurrent": 4, // down from default 8
"model": "anthropic/claude-haiku-4-5" // sub-agents don't need Sonnet
},
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5", // compaction summaries via Haiku
"memoryFlush": { "enabled": true }
}
}
}
}
Expected result: Sub-agent entries in your logs should now show Haiku pricing. Heartbeats should be near-zero cost. Your fallback chain means a Claude outage doesn't stall your session — it degrades gracefully to Gemini.
| Usage Tier | Default | Config B | Savings |
|---|---|---|---|
| Light | ~$100 | ~$20 | 80% |
| Moderate | ~$500 | ~$150 | 70% |
| Heavy | ~$1,750 | ~$500 | 71% |
Config C: Power User — Full Optimization Stack
Per-sub-agent model assignment, context compaction pinned to Haiku, vision routing to Gemini Flash, tight .clawrules + .clawignore, disabled unused skills. This is the config that gets you to the 85–90% savings range.
{
"agents": {
"defaults": {
"workspace": "~/clawd",
"model": {
"primary": "anthropic/claude-sonnet-4-6",
"fallbacks": [
"openrouter/anthropic/claude-sonnet-4-6", // different provider as backup
"minimax/minimax-m2-7", // cheap daily-driver fallback
"anthropic/claude-haiku-4-5" // last resort
]
},
"models": {
"anthropic/claude-sonnet-4-6": {
"params": { "cacheControlTtl": "1h", "maxTokens": 8192 }
},
"minimax/minimax-m2-7": {
"params": { "maxTokens": 8192 }
}
},
"heartbeat": {
"every": "55m",
"model": "google/gemini-2.5-flash-lite",
"isolatedSession": true,
"lightContext": true,
"activeHours": "09:00-19:00" // no heartbeats overnight
},
"subagents": {
"maxConcurrent": 4,
"model": "anthropic/claude-haiku-4-5"
},
"contextPruning": { "mode": "cache-ttl", "ttl": "1h" },
"compaction": {
"mode": "safeguard",
"model": "anthropic/claude-haiku-4-5",
"identifierPolicy": "strict",
"memoryFlush": { "enabled": true }
},
"bootstrapMaxChars": 12000, // down from default 20000
"imageModel": "google/gemini-3-flash" // vision tasks via cheap model
}
},
"memory": { "enabled": true, "max_context_tokens": 800 }, // minimal memory
"skills": {
"entries": {
"web-search": { "enabled": false },
"image-generation": { "enabled": false },
"audio-transcribe": { "enabled": false }
}
}
}
Per-subagent override example — paste into ~/.openclaw/agents/lint-runner/SOUL.md:
---
name: lint-runner
description: Runs lint/format checks and applies trivial fixes
tools: [Bash, Read, Edit]
model: anthropic/claude-haiku-4-5
---
Minimum-viable .clawignore — this alone cuts typical bootstraps from 150k characters toward 30–50k:
node_modules/
dist/
build/
.next/
coverage/
.venv/
vendor/
*.lock
package-lock.json
yarn.lock
pnpm-lock.yaml
*.min.js
*.min.css
**/__snapshots__/
**/*.snap
| Usage Tier | Default | Config C | Savings |
|---|---|---|---|
| Light | ~$100 | ~$12 | 88% |
| Moderate | ~$500 | ~$90 | 82% |
| Heavy | ~$1,750 | ~$220 | 87% |
These numbers align with two independent real-user reports: Praney Behl's documented $600–750/mo → $3–4/day (90% cut), and the LaoZhang case studies showing $943 → $347 (63%), $1,750 → $1,000 (64%), $200 → $70 (65%) with partial optimization.
Using the /model Command to Control OpenClaw Token Usage On-the-Fly
The /model command switches the active model for the next turn while preserving your conversation context — no reset, no lost history. This is the daily habit that compounds savings over time.
Practical workflow:
- Working on a gnarly multi-file refactor? Stay on Sonnet.
- Quick "what does this regex do?" question?
/model haiku, ask, then/model sonnetto switch back. - Commit message or doc polish?
/model flash-lite, done.
You can set up aliases in openclaw.json under commands.aliases to map short names (haiku, sonnet, opus, flash) to full provider strings. Saves a few keystrokes on every switch.
The math: 50 queries/day at Sonnet is roughly $3/day. The same 50 queries split 70/20/10 across Haiku/Sonnet/Opus is about $1.10/day. Over a month, that's $90 → $33 — 63% cheaper without changing tools, just habits.
Bonus: Tracking OpenClaw Model Pricing Across Providers with Thunderbit
Track model pricing across providers with AI Get Started Free
With so many models and providers — OpenRouter, direct Anthropic API, Google AI Studio, DeepSeek, MiniMax — pricing changes often. Anthropic cut Opus output pricing by ~67% overnight. Google trimmed Gemini free-tier limits 50–80% in December 2025. Keeping a static pricing spreadsheet current by hand is a losing battle.
Thunderbit solves this without any scraping code. It's an AI web scraper Chrome extension built for exactly this kind of structured data extraction.
The workflow I use:
- Open the OpenRouter models page in Chrome and click Thunderbit's "AI Suggest Fields." It reads the page and proposes columns — model name, input price, output price, context window, provider.
- Hit Scrape, then export directly to Google Sheets.
- Set up a scheduled scrape in plain English — "every Monday at 9am, re-scrape the OpenRouter model list" — and it runs in the cloud automatically.
From then on, your personal pricing tracker updates itself. Any model that suddenly cheapens by 30% — or any provider that gets an Exacto tag — shows up in your Monday morning spreadsheet without you lifting a finger. We've written more about AI data extraction for business use cases on our blog.
Comparing pricing across direct provider pages (Anthropic, Google, DeepSeek)? Thunderbit's subpage scraping follows each model link into its detail page and pulls per-provider rates — useful when you want to know whether routing Kimi K2.5 through OpenRouter is cheaper than going direct through NVIDIA Build. Check Thunderbit pricing for free tier and plan details.
Key Takeaways for Cutting OpenClaw Token Usage
The framework: Understand → Monitor → Route → Optimize.
Biggest-impact actions, ranked:
- Don't default to Opus. Swap your primary model to Sonnet or MiniMax M2.7. This alone is a 3–5x cost reduction.
- Isolate heartbeats. Set
isolatedSession: trueand route heartbeats to Gemini Flash-Lite. This turns a ~100k token drain into ~2–5k. - Route sub-agents to Haiku. Each spawn loads ~20k tokens of context before doing any work. Don't let that happen on Opus.
- Use
/clearreligiously. Free, takes 5 seconds, and community consensus is it saves more than any other single action. - Add
.clawignore. Excludingnode_modules, lockfiles, and build artifacts cuts bootstrap context dramatically. - Monitor with
/context detailbefore and after changes. If you can't measure it, you can't improve it.
The cheapest model depends on the task. Gemini Flash-Lite for heartbeats. MiniMax M2.7 for daily coding. Haiku for reliable tool calling. Sonnet for complex multi-step work. Opus for the genuinely hardest problems — and nothing else.
Most readers can see 50–70% savings in a single afternoon with Config A or B. The full 85–90% requires stacking all of the above — model routing, hidden drain fixes, .clawignore, session discipline — but it's achievable, and it sticks.
FAQs
1. How much does OpenClaw cost per month?
It depends entirely on your configuration, usage volume, and model choices. Light users (~10 queries/day) typically spend $5–30/month with optimization, or $100+ on defaults. Moderate users (~50 queries/day) range from $90–400/month. Heavy users can hit $600–2,000+/month on defaults — one documented extreme was $5,623 in a single month. Anthropic's own internal telemetry suggests a median of $13/developer/active-day.
2. What is the cheapest OpenClaw model that still works well for coding?
MiniMax M2.5/M2.7 is the best general daily driver — good tool-calling reliability, SWE-Pro 56.22, at roughly $0.28/$1.10 per million tokens. For heartbeats and simple lookups, Gemini 2.5 Flash-Lite at $0.10/$0.40 is hard to beat. Claude Haiku 4.5 at $1/$5 is the reliable mid-tier fallback when you need excellent tool-calling without paying Sonnet prices.
3. Can I use free-tier models with OpenClaw?
Technically yes. GPT-OSS-120B is free on OpenRouter's :free tag and NVIDIA Build. Gemini Flash-Lite has a free tier (15 RPM, 1,000 requests/day). DeepSeek gives 5M free tokens on signup. But free tiers have aggressive rate limits, slower speeds, and unreliable availability. Cheap paid models — pennies per million tokens — are far more dependable for regular use.
4. Does switching models mid-conversation with /model lose my context?
No. /model preserves your full session context — the next turn routes to the new model with complete history intact. This is verified in OpenClaw's concepts documentation and works the same way in Claude Code. You can freely bounce between Haiku for quick questions and Sonnet for complex work without losing anything.
5. What's the single fastest way to reduce my OpenClaw bill today?
Type /clear between unrelated tasks. It's free, takes five seconds, and wipes the conversation history that gets resent on every API call. One real session showed 185,000 tokens of accumulated message history — all of which was being re-transmitted and re-billed on every single turn. Clearing that before starting new work is the highest-ROI habit you can build.
Try Thunderbit for AI Web Scraping Get Started Free




