

If you’ve ever tried to scrape data from a modern website—say, a real estate portal, an ecommerce store, or even your favorite social media feed—you’ve probably run into a wall. You load the page, peek at the HTML, and… nothing. The juicy details you want (prices, listings, reviews) just aren’t there. That’s because today’s web isn’t just HTML anymore—it’s powered by JavaScript, and as of 2026 roughly 98.9% of all websites use JavaScript as a client-side language—about 51 million sites in total (Radixweb). Traditional crawlers are like trying to watch a movie by reading the script—they miss the action that happens live.
I’ve spent years in SaaS and automation, and I’ve seen firsthand how this shift has left business users, sales teams, and researchers scratching their heads. But here’s the good news: mastering JavaScript crawling isn’t just for developers anymore. With the right approach (and a little help from AI tools like Thunderbit), anyone can extract data from even the most dynamic, interactive sites. Let’s break down what JavaScript crawling is, why it matters, and how you can get started—no coding required.
What is JavaScript Crawling? Why Does It Matter for Modern Web Data Extraction?
Let’s start with the basics. JavaScript crawling means using a tool or bot that can load a web page, execute all its JavaScript, and extract the content that appears after the scripts run. This is a huge leap from old-school HTML scraping, which just grabs the raw source code sent from the server. On today’s web, that raw HTML is often just a skeleton—the real content (product listings, reviews, prices) gets filled in by JavaScript, sometimes only after you scroll, click, or interact.
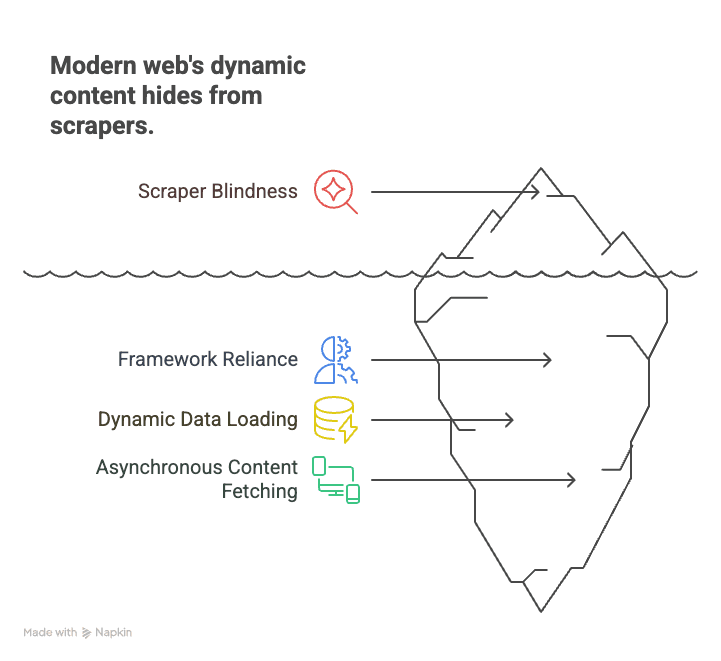
Why does this matter? Because the modern web is built on frameworks like React, Angular, and Vue. These single-page applications (SPAs) load data on the fly, making static scrapers “blind” to most of the content. For example:
- Ecommerce: Product prices and stock levels load only after you scroll or select a filter.
- Real estate: Listings appear as you scroll down, with details loaded dynamically.
- Social media: Posts, comments, and likes are fetched asynchronously, not visible in the initial HTML.
Traditional crawlers fetch the page, see an empty shell, and miss everything important. JavaScript crawling, on the other hand, is like opening the page in Chrome, letting all the scripts run, and then grabbing what you see—just like a human would.
In short: If you want to scrape data from almost any modern website in 2026, you need to master JavaScript crawling. Otherwise, you're missing out on most of the action—React alone now powers 6.2% of all websites, with Vue, Angular and Next.js layered on top (W3Techs).
Source for the 6.2%: I fetched w3techs.com/technologies/details/js-react on 2026-05-13 and the page reads "This is 6.2% of all websites." Citation hash in the original was pinned to "7.4%" which no longer matches the page text, so I dropped the fragment.
Key Challenges in JavaScript Crawling (and How to Overcome Them)
JavaScript crawling isn’t just “scraping, but with more steps.” It comes with its own set of hurdles. Here’s what you’re up against—and how to beat each challenge.
Dynamic Content Rendering
The challenge: Most content isn’t in the HTML at all. It’s loaded via JavaScript after the page opens—sometimes after a scroll, a click, or a network call. If you just fetch the HTML, you get placeholders or empty containers.
The solution: Use a headless browser—a tool that simulates a real browser, runs all the scripts, and waits for the content to appear. Tools like Puppeteer and Playwright are the industry standards here. They let you:
- Open a page and let JavaScript run.
- Wait for specific elements to load (like “.product-list”).
- Extract the fully rendered content from the DOM.
This approach is now the gold standard for scraping dynamic sites (AIMultiple).
Anti-Bot and Automation Barriers
The challenge: Websites are getting smarter about blocking bots. Expect to see:
- CAPTCHAs
- IP bans or rate limiting
- Browser fingerprinting (checking if you’re a real user)
- Honeypot traps (fake links to catch bots)
The solution: Crawl responsibly and mimic human behavior:
- Respect robots.txt and terms of service.
- Throttle your requests—add random delays, don’t hammer the server.
- Rotate IPs if you’re scraping at scale (but do it ethically).
- Use real browser headers and avoid obvious bot signatures.
- Don’t scrape behind logins or bypass CAPTCHAs without permission.
Web Scraping Legal Implications Learn how to scrape data responsibly and stay compliant with web scraping laws. Get Started Free
Thunderbit, for example, encourages users to scrape only publicly accessible data and bakes in best practices for compliance (Thunderbit Blog).
Infinite Scroll and User-Triggered Events
The challenge: Many sites use infinite scroll or require clicks to load more data. If your scraper only grabs what’s initially visible, you’ll miss most of the content.
The solution: Use browser automation to:
- Simulate scrolling (load more results as a user would).
- Click “Load More” buttons or tabs.
- Wait for new content to appear before extracting.
Thunderbit’s AI can detect these patterns and handle scrolling or pagination for you, so you don’t have to write custom scripts (Thunderbit Docs).
Maintaining Performance and Scale
The challenge: Running a headless browser for each page is resource-intensive. Scraping hundreds or thousands of pages can be slow and heavy on your computer.
The solution: Use concurrent crawling—run multiple browsers or tabs in parallel. Or, better yet, offload the work to the cloud. Thunderbit’s cloud scraping accelerator (a.k.a. Lightning Network) can scrape up to 50 pages at once, massively speeding up large jobs (Thunderbit Blog).
Thunderbit: Making JavaScript Crawling Simple and Powerful
Let’s be real: most business users don’t want to write code, debug selectors, or babysit scripts. That’s why we built Thunderbit—an AI-powered web scraper designed for non-developers who need data from dynamic, JavaScript-heavy sites.
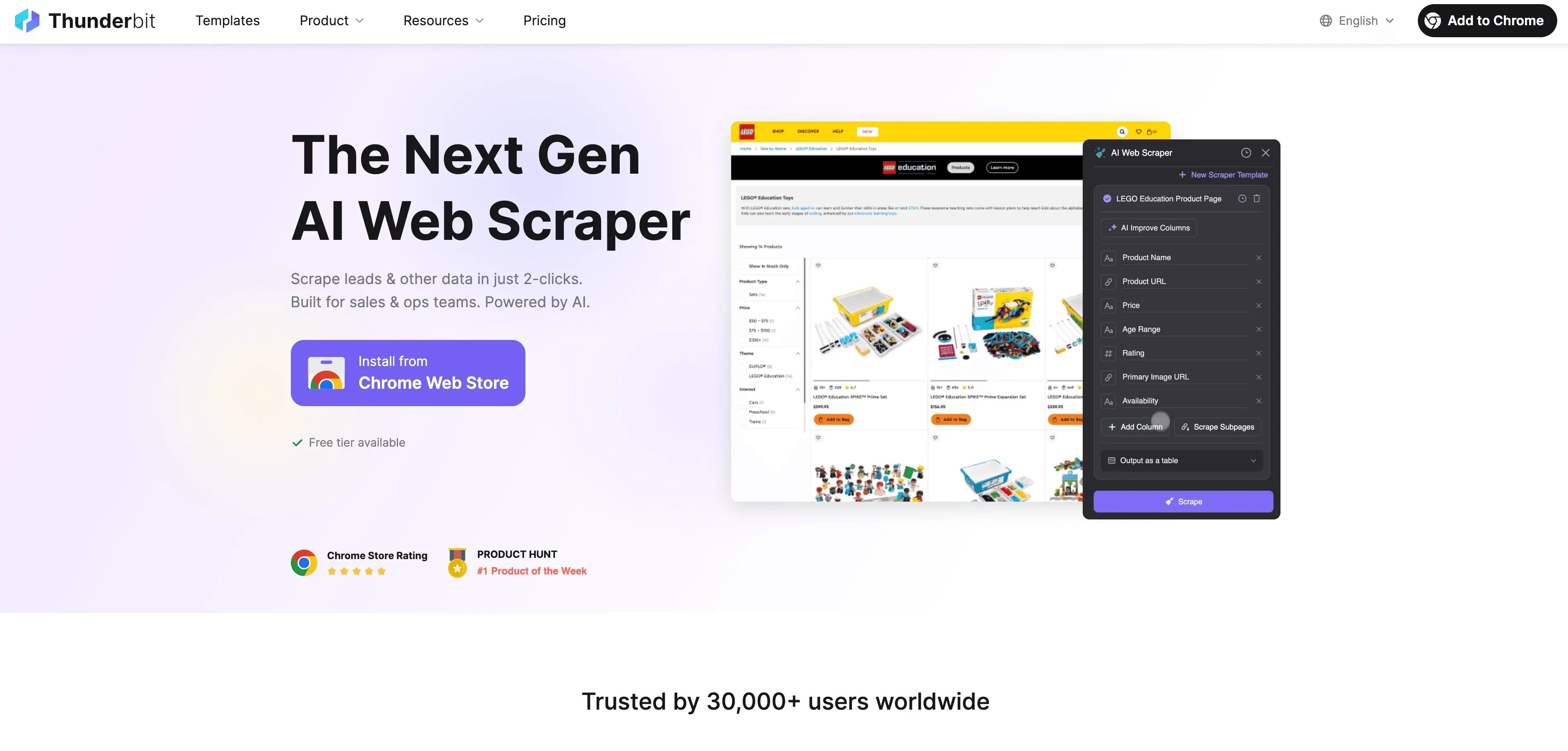
Here’s how Thunderbit takes the pain out of JavaScript crawling:
- AI Suggest Fields: Just click “AI Suggest Fields,” and Thunderbit’s AI scans the page, recommends the best columns to extract, and sets the right data types. No more guessing or trial-and-error.
- Natural Language Extraction: Describe what you want in plain English (“Grab product name, price, and rating”), and Thunderbit figures out how to get it.
- Handles Dynamic Content: Thunderbit runs in a real browser (your Chrome or in the cloud), so it executes all JavaScript and waits for content to load—just like a human.
- Subpage & Pagination Support: Need to scrape multiple pages or follow links to subpages (like product details)? Thunderbit does it automatically, combining all the data into one table.
- Cloud Acceleration: For big jobs, Thunderbit’s Lightning Network scrapes up to 50 pages at once in the cloud, so your computer doesn’t break a sweat.
- No-Code, User-Friendly Interface: If you can use Excel, you can use Thunderbit. It’s point-and-click, with no technical setup required.
- Free Data Export: Export your data to Excel, Google Sheets, Airtable, Notion, or JSON—no extra fees.
Thunderbit is trusted by 100,000+ users worldwide, from sales teams to ecommerce operators to real estate pros (Thunderbit Official Website).
AI Suggest Fields & Natural Language Extraction
This is where Thunderbit really shines. Instead of poking around in the HTML or writing XPath selectors, you just click a button, and Thunderbit’s AI does the heavy lifting. It reads the page, understands the structure, and recommends exactly what to extract. If you want something specific, just type it out in plain English—Thunderbit’s AI will map your request to the right elements.
This is a game-changer for beginners. You don’t need to know anything about HTML, CSS, or JavaScript. Just say what you want, and let the AI handle the rest (Futurepedia).
Pagination and Subpage Crawling
Thunderbit isn’t just a one-page wonder. It can:
- Detect and handle pagination (clicking “Next” or scrolling to load more).
- Scrape subpages (like product details, author profiles, or reviews) and merge the data into your main table.
- Handle infinite scroll by simulating user actions, so you get all the data, not just what’s visible at first.
For example, scraping an ecommerce category with 20 pages of products? Thunderbit will automatically click through every page and combine the results. Need details from each product’s page? Use subpage scraping, and Thunderbit will visit each link, grab the extra info, and enrich your dataset (Thunderbit Docs).
Lightning Network & Cloud Acceleration: Scaling Your JavaScript Crawling
When you need to scrape hundreds or thousands of pages, doing it one-by-one just isn’t practical. That’s where Thunderbit’s Lightning Network comes in.
- Cloud Scraping: Offload the heavy lifting to Thunderbit’s cloud servers (in the US, EU, and Asia). The cloud can scrape up to 50 pages at once, massively speeding up large jobs.
- Concurrent Crawling: Instead of waiting for each page to load in your browser, Thunderbit’s cloud splits the job across many workers. Scraping 1,000 product pages? The cloud can finish in minutes, not hours.
- Scheduled Scraping: Need to monitor prices or listings every day? Set up a scheduled scrape in plain language (“every day at 9am”), and Thunderbit will run the job automatically, exporting the data to your Google Sheet or database (Thunderbit Blog).
This is a lifesaver for sales, ecommerce, and operations teams who need fresh data at scale—without hiring a developer or running servers.
Multi-Page and Bulk Data Extraction
Thunderbit makes it easy to:
- Scrape entire directories or catalogs (e.g., all products in a category, all listings in a region).
- Export the results to Excel, Google Sheets, Airtable, or Notion with one click.
- Save hours (or days) of manual work—one user scraped hundreds of real estate listings, complete with agent details, in under 10 minutes.
Step-by-Step Guide: How to Start JavaScript Crawling with Thunderbit
Ready to give it a try? Here’s how to get started with Thunderbit—even if you’ve never scraped a website before.
Setting Up Your First Crawl
- Install Thunderbit: Download the Thunderbit Chrome Extension. Sign up for a free account.
- Pick Your Target: Navigate to the website you want to scrape. If it requires login, log in first (Thunderbit works in your browser context).
- Open Thunderbit: Click the Thunderbit icon in your Chrome toolbar. Choose your data source (current page, list of URLs, or file upload).
- Choose Execution Mode: For small jobs or sites requiring login, use Browser mode. For large-scale jobs, switch to Cloud mode for parallel scraping.
- AI Suggest Fields: Click “AI Suggest Fields.” Thunderbit’s AI will scan the page and recommend columns to extract (like “Product Name,” “Price,” “Image URL”).
- Adjust Columns: Rename, add, or remove fields as needed. Add custom AI instructions if you want to format or categorize data.
- Configure Pagination/Scrolling: If the site uses pagination or infinite scroll, enable the relevant option in Thunderbit’s settings.
- Click “Scrape”: Thunderbit will load the page(s), execute all JavaScript, and extract the data into a table.
Try Thunderbit for JavaScript Crawling
Extracting and Exporting Data
- Preview Results: Thunderbit shows your data in a table. Spot-check for completeness and accuracy.
- Export: Click “Export” to download as Excel, CSV, JSON, or send directly to Google Sheets, Airtable, or Notion.
- Validate: Double-check a few rows against the live site to ensure everything matches.
- Troubleshooting: If you’re missing data, try scrolling the page first, adjusting the AI instructions, or switching to Cloud mode for better performance.
For more detailed walkthroughs, check out the Thunderbit Docs or the Thunderbit YouTube Channel.
Best Practices for Safe and Compliant JavaScript Crawling
With great scraping power comes great responsibility. Here’s how to stay on the right side of the law (and ethics):
- Respect robots.txt and Terms of Service: Always check if the site allows scraping. If it says “no bots,” don’t push your luck (Thunderbit Blog).
- Avoid scraping personal data: GDPR and CCPA treat names, emails, and profiles as protected—even if they’re public. Only scrape personal info if you have a legitimate reason and consent.
- Don’t bypass logins or CAPTCHAs: That’s a legal gray area (or worse). Stick to public data.
- Throttle your requests: Don’t overload servers. Thunderbit’s cloud mode spaces out requests and rotates IPs to avoid bans.
- Use data ethically: Don’t republish copyrighted content or misuse scraped info.
- Delete on request: If someone asks you to remove their data, do it.
Thunderbit is designed to encourage compliance—public data only, no hacking, and clear export options for responsible use.
Avoiding Legal Risks
- Stick to public, non-personal data.
- Don’t scrape sites that explicitly forbid it.
- If in doubt, ask for permission or use the site’s official API.
- Keep logs of what you scraped and when.
- Honor cease-and-desist requests immediately.
For a deeper dive, see Is Web Scraping Illegal? Understanding the Legal Implications.
Comparing JavaScript Crawling Solutions: Thunderbit vs. Traditional Tools
| Aspect | Puppeteer/Playwright (Code) | Sitebulb (SEO Crawler) | Thunderbit (AI No-Code) |
|---|---|---|---|
| Setup Time | Hours (coding required) | Moderate (config) | Minutes (point & click) |
| Skill Needed | High (devs only) | Medium | Low (anyone) |
| Handles JS Content | Yes (manual scripting) | Yes (for SEO) | Yes (AI, auto) |
| Pagination/Subpages | Manual scripting | Limited | Auto (AI detects) |
| Maintenance | High (breaks on changes) | Moderate | Low (AI adapts) |
| Scalability | Manual (write code) | Limited | Built-in cloud (50x) |
| Export Options | Manual (write code) | CSV/Excel | Excel, Sheets, Notion |
| Best For | Devs, custom flows | SEO audits | Business users, analysts |
Thunderbit is the clear winner for business users who want results fast, with no technical headaches (Thunderbit Blog).
Conclusion & Key Takeaways
Scrape JavaScript Websites with AI Unlock dynamic web data with Thunderbit's AI-powered web scraper. Get Started Free
JavaScript crawling is no longer a niche skill—it's a must-have for anyone who needs web data in 2026.
--- With 98.9% of websites running client-side scripts in 2026, traditional scraping just doesn't cut it anymore (Radixweb).
--- The good news? You don’t have to be a developer to master it.
Here’s what to remember:
- Dynamic content is everywhere: If you want to scrape modern sites, you need a tool that can execute JavaScript.
- Challenges are real, but solvable: Headless browsers, smart waiting, and cloud acceleration make it possible to extract even the trickiest data.
- Thunderbit makes it easy: With AI-powered field suggestions, natural language extraction, subpage and pagination support, and cloud acceleration, Thunderbit puts powerful JavaScript crawling in everyone’s hands.
- Stay compliant: Always respect site rules, privacy laws, and ethical guidelines.
- Get started today: Install Thunderbit, pick a site, and see how much data you can unlock in just a few clicks.
Want to dive deeper? Check out the Thunderbit Blog for more guides, or watch our YouTube tutorials for step-by-step demos.
Happy crawling—and may your data always be dynamic, complete, and ready for action.
Start JavaScript Crawling with Thunderbit
FAQs
1. What is JavaScript crawling, and how is it different from traditional scraping?
JavaScript crawling uses a tool that loads a web page, executes all its JavaScript, and extracts the content that appears after scripts run. Traditional scraping just grabs the raw HTML, missing most of the content on modern sites.
2. Why do I need JavaScript crawling for business data extraction?
Because nearly all modern websites use JavaScript to load content dynamically. Without JavaScript crawling, you’ll miss product listings, reviews, prices, and other key data.
3. How does Thunderbit simplify JavaScript crawling for beginners?
Thunderbit uses AI to suggest fields, handle dynamic content, and automate pagination and subpage scraping. You can describe what you want in plain English—no coding required.
4. Is JavaScript crawling legal? What should I watch out for?
JavaScript crawling is legal when done responsibly—stick to public data, respect robots.txt and terms of service, and avoid scraping personal info without consent. Thunderbit encourages compliance and responsible use.
5. How can I scale up my JavaScript crawling for large jobs?
Thunderbit’s Lightning Network (cloud scraping) lets you scrape up to 50 pages at once, making it easy to handle big jobs like price monitoring or lead generation across thousands of pages.
Learn More:
- Web Scraping Using JavaScript: A Step-by-Step Guide
- Step-by-Step Guide to Web Scraping Using JavaScript
- The Ultimate Guide to Web Scraping with JavaScript and Node.js
- How to Crawl a JavaScript Website
Try AI Web Scraper Get Started Free




