
Web data is exploding, and so is the pressure to keep up. I’ve seen firsthand how sales and operations teams spend more time wrangling spreadsheets and copy-pasting from websites than actually making decisions. According to Salesforce, sales reps now spend , and Asana reports that . That’s a lot of hours lost to manual data collection—hours that could be spent closing deals or launching campaigns.
But here’s the good news: web scraping has gone mainstream, and you don’t have to be a developer to harness its power. Ruby has long been a favorite for automating web data extraction, but when you combine it with modern AI web scrapers like , you get the best of both worlds—flexibility for coders, and no-code simplicity for everyone else. Whether you’re a marketer, an ecommerce manager, or just someone tired of endless copy-paste, this guide will show you how to master web scraping with Ruby and AI—no code required.
What is Web Scraping with Ruby? Your Gateway to Automated Data
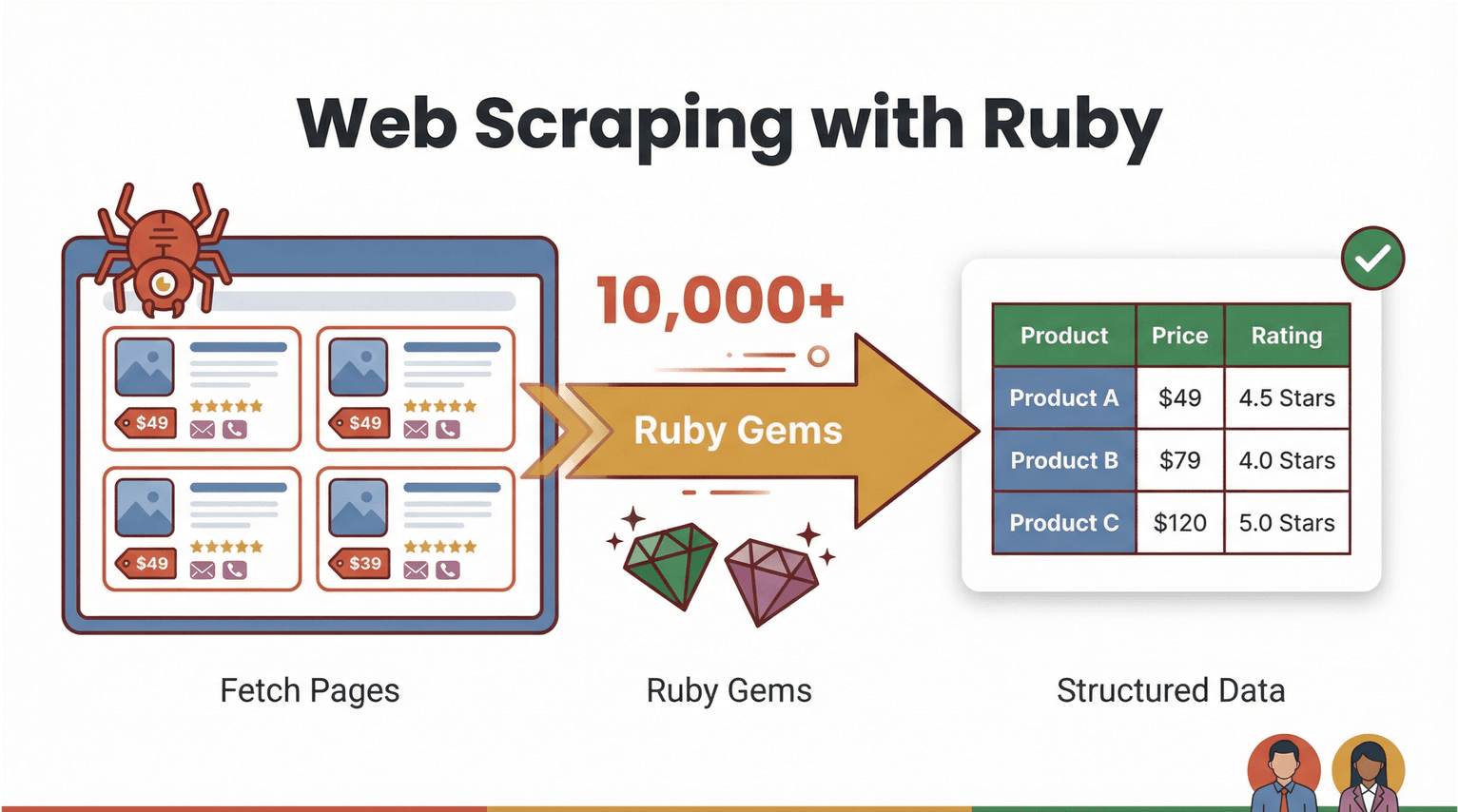
Let’s start with the basics. Web scraping is simply the process of using software to fetch web pages and extract specific information—like product prices, contact info, or reviews—into a structured format (think CSV or Excel). With Ruby, web scraping is both powerful and approachable. The language is known for its readable syntax and a massive ecosystem of “gems” (libraries) that make automation a breeze ().
So what does “web scraping with Ruby” actually look like? Imagine you want to pull all the product names and prices from an ecommerce site. With Ruby, you can write a script that:
- Downloads the web page (using a library like )
- Parses the HTML to find the data you want (with )
- Exports it to a spreadsheet or database
But here’s where things get interesting: you don’t always need to write code. AI-powered, no-code web scrapers like can now handle the heavy lifting—reading web pages, detecting fields, and exporting clean data tables with just a couple of clicks. Ruby remains a fantastic “automation glue” for custom workflows, but AI web scrapers are opening the door for business users to get in on the action.
Why Web Scraping with Ruby Matters for Business Teams

Let’s be real: nobody wants to spend their day copying and pasting data. The demand for automated web data extraction is skyrocketing, and for good reason. Here’s how web scraping with Ruby (and AI tools) is transforming business operations:
- Lead Generation: Instantly pull contact info from directories or LinkedIn for your sales pipeline.
- Competitor Price Monitoring: Track pricing changes across hundreds of ecommerce SKUs—no more manual checks.
- Product Catalog Building: Aggregate product details and images for your own store or marketplace.
- Market Research: Collect reviews, ratings, or news articles for trend analysis.
The ROI is clear: teams that automate web data collection save hours per week, reduce errors, and get fresher, more reliable data. In manufacturing, for example, , even as the volume of data has doubled in just two years. That’s a huge opportunity for automation.
Here’s a quick summary of how web scraping with Ruby and AI tools delivers value:
| Use Case | Manual Pain Point | Benefit of Automation | Typical Outcome |
|---|---|---|---|
| Lead Generation | Copying emails one by one | Scrape thousands in minutes | 10x more leads, less grunt work |
| Price Monitoring | Daily site checks | Scheduled, automated price pulls | Real-time pricing intelligence |
| Catalog Building | Manual data entry | Bulk extraction & formatting | Faster launches, fewer errors |
| Market Research | Reading reviews by hand | Scrape and analyze at scale | Deeper, fresher insights |
And it’s not just about speed—automation means fewer mistakes and more consistent data, which is critical when .
Exploring Web Scraping Solutions: Ruby Scripts vs. AI Web Scraper Tools
So, should you write your own Ruby script or use an AI-powered, no-code web scraper? Let’s break down the options.
Ruby Scripting: Total Control, Higher Maintenance
Ruby’s ecosystem is packed with gems for every scraping need:
- : The go-to for parsing HTML and XML.
- : For fetching web pages and APIs.
- : For sites that require cookies, forms, and navigation.
- / : For automating real browsers (great for JavaScript-heavy sites).
With Ruby scripts, you get full flexibility—custom logic, data cleaning, and integration with your own systems. But you also take on the maintenance: when a website changes its layout, your script might break. And if you’re not comfortable with code, there’s a learning curve.
AI Web Scrapers & No-Code Tools: Fast, User-Friendly, and Adaptive
Modern no-code web scrapers like flip the script. Instead of writing code, you:
- Open the Chrome extension
- Click “AI Suggest Fields” to let the AI detect what to extract
- Hit “Scrape” and export your data
Thunderbit’s AI adapts to changing web layouts, handles subpages (like product details), and exports directly to Excel, Google Sheets, Airtable, or Notion. It’s perfect for business users who want results without the hassle.
Here’s a side-by-side comparison:
| Approach | Pros | Cons | Best For |
|---|---|---|---|
| Ruby Scripting | Full control, custom logic, flexible | Steeper learning curve, maintenance | Developers, advanced users |
| AI Web Scraper | No-code, fast setup, adapts to changes | Less granular control, some limits | Business users, ops teams |
The trend is clear: as websites get more complex (and defensive), AI web scrapers are becoming the go-to for most business workflows.
Getting Started: Setting Up Your Ruby Web Scraping Environment
If you’re ready to try Ruby scripting, let’s get your environment set up. The good news? Ruby is easy to install and works on Windows, macOS, and Linux.
Step 1: Install Ruby
- Windows: Download the and follow the prompts. Make sure to include MSYS2 for building native extensions (needed for gems like Nokogiri).
- macOS/Linux: Use for version management. In Terminal:
1brew install rbenv ruby-build
2rbenv install 4.0.1
3rbenv global 4.0.1(Check for the latest stable version.)
Step 2: Install Bundler and Essential Gems
Bundler helps manage dependencies:
1gem install bundlerCreate a Gemfile for your project:
1source 'https://rubygems.org'
2gem 'nokogiri'
3gem 'httparty'Then run:
1bundle installThis ensures your environment is consistent and ready for scraping.
Step 3: Test Your Setup
Try this in IRB (Ruby’s interactive shell):
1require 'nokogiri'
2require 'httparty'
3puts Nokogiri::VERSIONIf you see a version number, you’re good to go!
Step-by-Step: Building Your First Ruby Web Scraper
Let’s walk through a real example—scraping product data from , a site designed for scraping practice.
Here’s a simple Ruby script to extract book titles, prices, and stock status:
1require "net/http"
2require "uri"
3require "nokogiri"
4require "csv"
5BASE_URL = "https://books.toscrape.com/"
6def fetch_html(url)
7 uri = URI.parse(url)
8 res = Net::HTTP.get_response(uri)
9 raise "HTTP #\{res.code\} for #\{url\}" unless res.is_a?(Net::HTTPSuccess)
10 res.body
11end
12def scrape_list_page(list_url)
13 html = fetch_html(list_url)
14 doc = Nokogiri::HTML(html)
15 products = doc.css("article.product_pod").map do |pod|
16 title = pod.css("h3 a").first["title"]
17 price = pod.css(".price_color").text.strip
18 stock = pod.css(".availability").text.strip.gsub(/\s+/, " ")
19 { title: title, price: price, stock: stock }
20 end
21 next_rel = doc.css("li.next a").first&.[]("href")
22 next_url = next_rel ? URI.join(list_url, next_rel).to_s : nil
23 [products, next_url]
24end
25rows = []
26url = "#\{BASE_URL\}catalogue/page-1.html"
27while url
28 products, url = scrape_list_page(url)
29 rows.concat(products)
30end
31CSV.open("books.csv", "w", write_headers: true, headers: %w[title price stock]) do |csv|
32 rows.each { |r| csv << [r[:title], r[:price], r[:stock]] }
33end
34puts "Wrote #\{rows.length\} rows to books.csv"This script fetches each page, parses the HTML, extracts the data, and writes it to a CSV file. You can open books.csv in Excel or Google Sheets.
Common pitfalls:
- If you get errors about missing gems, double-check your Gemfile and run
bundle install. - For sites that use JavaScript to load data, you’ll need a browser automation tool like Selenium or Watir.
Supercharging Ruby Scraping with Thunderbit: AI Web Scraper in Action
Now, let’s talk about how can take your scraping to the next level—no code required.
Thunderbit is an that lets you extract structured data from any website in just two clicks. Here’s how it works:
- Open the Thunderbit extension on the page you want to scrape.
- Click “AI Suggest Fields.” Thunderbit’s AI scans the page and suggests the best columns to extract (like “Product Name,” “Price,” “Stock”).
- Click “Scrape.” Thunderbit grabs the data, handles pagination, and even follows subpages if you need more details.
- Export your data directly to Excel, Google Sheets, Airtable, or Notion.
What makes Thunderbit unique is its ability to handle complex, dynamic web pages—no brittle selectors or code required. And if you want to blend workflows, you can use Thunderbit to extract the data, then process or enrich it further with a Ruby script.
Pro tip: Thunderbit’s subpage scraping is a lifesaver for ecommerce and real estate teams. Scrape a list of product links, then let Thunderbit visit each one to pull detailed specs, images, or reviews—automatically enriching your dataset.
Real-World Example: Scraping Ecommerce Product & Price Data with Ruby and Thunderbit
Let’s put it all together with a practical workflow for ecommerce teams.
Scenario: You want to monitor competitor prices and product details across hundreds of SKUs.
Step 1: Use Thunderbit to Scrape the Main Product List
- Open the competitor’s product listing page.
- Launch Thunderbit, click “AI Suggest Fields” (e.g., Product Name, Price, URL).
- Click “Scrape” and export the results to CSV.
Step 2: Enrich Data with Subpage Scraping
- In Thunderbit, use the “Scrape Subpages” feature to visit each product’s detail page and extract additional fields (like description, stock, or images).
- Export the enriched table.
Step 3: Process or Analyze with Ruby
- Use a Ruby script to further clean, transform, or analyze the data. For example, you might want to:
- Convert prices to a standard currency
- Filter out out-of-stock items
- Generate summary statistics
Here’s a simple Ruby snippet to filter for in-stock products:
1require 'csv'
2rows = CSV.read('products.csv', headers: true)
3in_stock = rows.select { |row| row['stock'].include?('In stock') }
4CSV.open('in_stock_products.csv', 'w', write_headers: true, headers: rows.headers) do |csv|
5 in_stock.each { |row| csv << row }
6endResult:
You go from raw web pages to a clean, actionable data table—ready for pricing analysis, inventory planning, or marketing campaigns. And you did it all without writing a single line of scraping code.
No-Code, No Problem: Automating Web Data Extraction for Everyone
One of my favorite things about Thunderbit is how it empowers non-technical users. You don’t need to know Ruby, HTML, or CSS—just open the extension, let the AI do its thing, and export your data.
Learning curve: With Ruby scripts, you’ll need to learn the basics of programming and web structure. With Thunderbit, the setup time is measured in minutes, not days.
Integration: Thunderbit exports directly to the tools business teams already use—Excel, Google Sheets, Airtable, Notion. You can even schedule recurring scrapes for ongoing monitoring.
User feedback: I’ve seen marketing teams, sales ops, and ecommerce managers use Thunderbit to automate everything from lead list building to price tracking—without ever calling IT.
Best Practices: Combining Ruby and AI Web Scraper for Scalable Automation
Want to build a robust, scalable scraping workflow? Here are my top tips:
- Handle website changes: AI web scrapers like Thunderbit adapt automatically, but if you’re using Ruby scripts, be ready to update selectors when sites change.
- Schedule your scrapes: Use Thunderbit’s scheduling feature for regular data pulls. For Ruby, set up a cron job or use a task scheduler.
- Batch processing: For large datasets, break your scraping into batches to avoid getting blocked or overloading your system.
- Data formatting: Always clean and validate your data before analysis—Thunderbit’s exports are structured, but custom Ruby scripts may need extra checks.
- Compliance: Only scrape publicly available data, respect
robots.txt, and be mindful of privacy laws (especially in the EU—). - Fallback strategies: If a site becomes too complex or blocks scraping, look for official APIs or alternative data sources.
When to use what?
- Use Ruby scripts when you need full control, custom logic, or integration with internal systems.
- Use Thunderbit when you want speed, ease of use, and adaptability—especially for one-off or recurring business tasks.
- Combine both for advanced workflows: let Thunderbit handle extraction, then use Ruby for enrichment, QA, or integration.
Conclusion & Key Takeaways
Web scraping with Ruby has always been a superpower for automating data collection—but now, with AI web scrapers like Thunderbit, that power is accessible to everyone. Whether you’re a developer looking for flexibility or a business user who just wants results, you can automate web data extraction, save hours of manual work, and make better, faster decisions.
Here’s what I hope you take away:
- Ruby is a fantastic tool for web scraping and automation—especially with gems like Nokogiri and HTTParty.
- AI web scrapers like Thunderbit make data extraction accessible to non-coders, with features like “AI Suggest Fields” and subpage scraping.
- Combining Ruby and Thunderbit gives you the best of both worlds: quick, no-code extraction plus custom automation and analysis.
- Automating web data collection is a game plan for sales, marketing, and ecommerce teams—cutting manual effort, boosting accuracy, and unlocking new insights.
Ready to get started? , try a simple Ruby script, and see how much time you can save. And if you want to dive deeper, check out the for more guides, tips, and real-world examples.
FAQs
1. Do I need to know how to code to use Thunderbit for web scraping?
No. Thunderbit is designed for non-technical users. Just open the extension, click “AI Suggest Fields,” and let the AI do the rest. You can export your data to Excel, Google Sheets, Airtable, or Notion—no coding required.
2. What are the main advantages of using Ruby for web scraping?
Ruby offers powerful libraries like Nokogiri and HTTParty for flexible, custom scraping workflows. It’s great for developers who want full control, custom logic, and integration with other systems.
3. How does Thunderbit’s “AI Suggest Fields” feature work?
Thunderbit’s AI scans the web page, detects the most relevant data fields (like product names, prices, emails), and suggests a structured table for you. You can adjust the columns as needed before scraping.
4. Can I combine Thunderbit with Ruby scripts for advanced workflows?
Absolutely. Many teams use Thunderbit to extract data (especially from complex or dynamic sites), then process or analyze it further with Ruby scripts. This hybrid approach is great for custom reporting or data enrichment.
5. Is web scraping legal and safe for business use?
Web scraping is legal when you collect publicly available data and respect website terms of service and privacy laws. Always check robots.txt and avoid scraping personal data without proper consent—especially for EU users under GDPR.
Curious to see how web scraping can transform your workflow? Try Thunderbit’s free tier or experiment with a Ruby script today. And if you get stuck, the and are packed with tutorials and tips to help you master web data automation—no code required.
Learn More