
Web data is the new oil—except it’s scattered across millions of websites, buried in messy HTML, and guarded by everything from CAPTCHAs to sneaky anti-bot scripts. If you’ve ever tried to copy-paste product prices, competitor info, or leads by hand, you know it’s a recipe for carpal tunnel and missed opportunities. That’s why web scraping has become a must-have skill for modern businesses. In fact, the alternative data market (which includes web scraping) was worth and is growing at a breakneck pace.

But here’s the kicker: while Python gets all the beginner love, Go (or Golang, if you like to sound fancy) is quietly powering some of the fastest, most reliable scrapers on the planet. Go’s secret sauce? Blazing concurrency, a rock-solid standard library, and the kind of performance that makes backend engineers swoon. I’ve seen teams slash their scraping runtimes in half just by switching to Go—and with the right tools, you don’t have to be a Google engineer to get started.
Ready to turn Go into your web scraping superpower? Let’s walk through the five essential steps—from setup to advanced scraping—with practical code, real-world tips, and a look at how AI tools like can take your workflow to the next level.
Why Choose Go for Web Scraping? The Business Case
Let’s face it: when you’re scraping thousands (or millions) of pages, every second counts. Go was built for this kind of heavy lifting. Here’s why more businesses are betting on Go for web scraping:
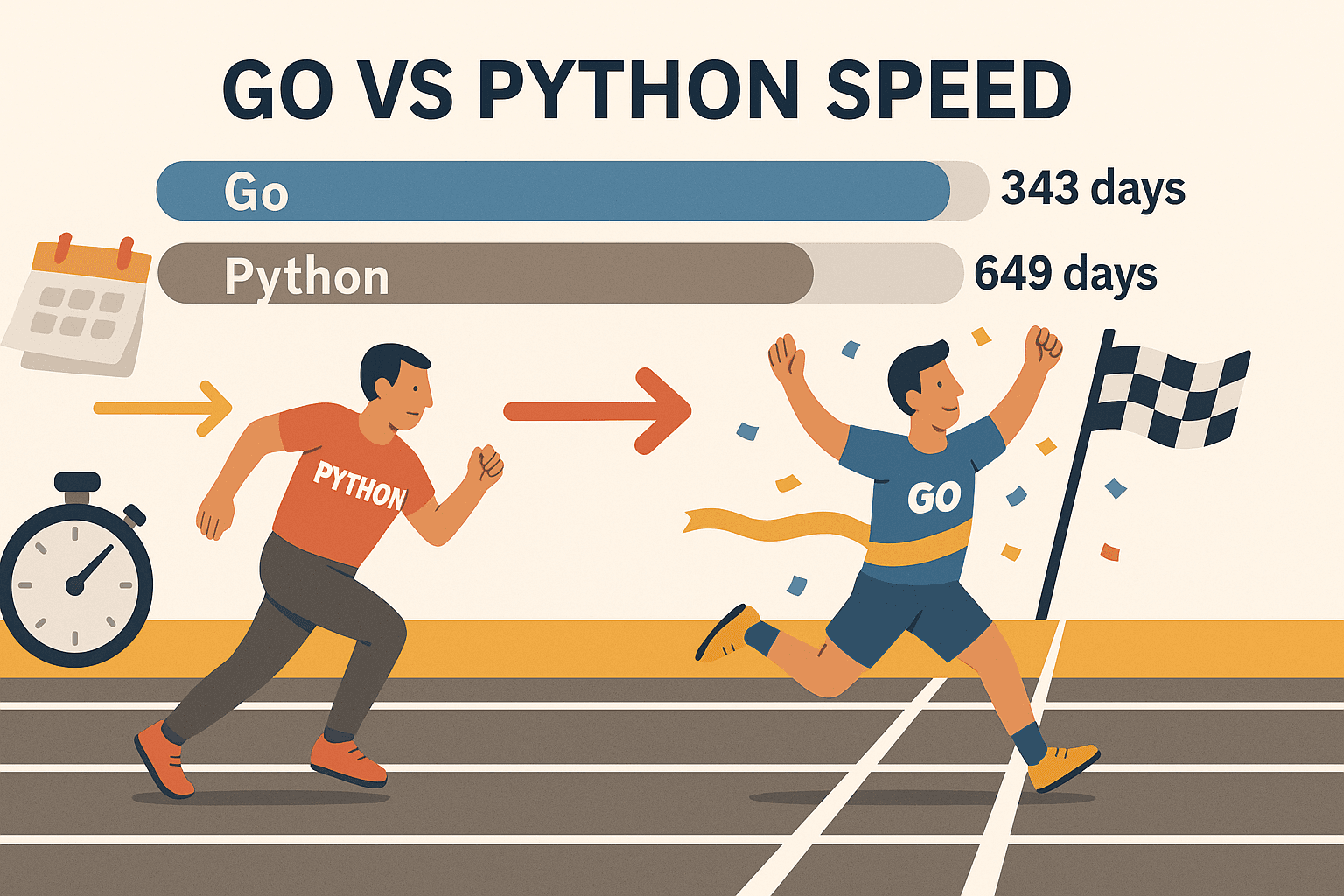
- Concurrency That Scales: Go’s goroutines (lightweight threads) let you scrape hundreds of pages at once—without melting your laptop. In one benchmark, Go scraped , while Python needed 649 days for the same job. That’s not just faster—it’s a whole new league.
- Stability and Reliability: Go’s strong typing and efficient memory management make it a favorite for long-running, large-scale crawlers. No more waking up to find your script crashed at 2am.
- First-Class Networking: Go’s standard library includes everything you need for HTTP requests, HTML parsing, and JSON handling—no hunting for third-party packages just to get started.
- Easy Deployment: Go compiles to a single binary, so you can run your scraper anywhere—no virtualenvs, no dependency hell.
- Industry Adoption: Go is now the (beating Node.js), and it’s trusted by giants like Google, Uber, and Netflix.
Of course, Python is still great for quick-and-dirty jobs or when you need machine learning libraries. But if you care about speed, scale, and reliability, Go is hard to beat—especially when paired with libraries like Colly and Goquery.
Step 1: Setting Up Your Go Environment for Web Scraping
Before you can start scraping, you’ll need to get Go up and running. The good news? It’s refreshingly painless.
1. Install Go
- Head to the and grab the installer for your OS (Windows, macOS, or Linux).
- Run the installer and follow the prompts. On Linux, you can also use your package manager.
- Open a terminal and type:
If you see something like1go versiongo version go1.21.0 darwin/amd64, you’re golden.
Troubleshooting: If go isn’t found, make sure your PATH is set correctly. On Linux/macOS, you might need to add export PATH=$PATH:/usr/local/go/bin to your ~/.bash_profile or ~/.zshrc.
2. Initialize a New Go Project
- Make a new directory for your scraper:
1mkdir my-scraper && cd my-scraper - Initialize a Go module:
This creates a1go mod init github.com/yourname/my-scrapergo.modfile to track your dependencies.
3. Choose an Editor
- with the Go extension is a great choice (auto-complete, linting, and debugging).
- JetBrains GoLand is another favorite for Go pros.
- Vim/Neovim with Go plugins works if you’re feeling old-school.
4. Test Your Setup
Create a quick main.go:
1package main
2import "fmt"
3func main() {
4 fmt.Println("Go is installed and working!")
5}Run it:
1go run main.goIf you see your message, you’re ready to roll.
Step 2: Making Your First HTTP Request in Go
Time to fetch your first web page! Go’s net/http package makes this a breeze.
Basic HTTP GET Example:
1package main
2import (
3 "fmt"
4 "io"
5 "net/http"
6)
7func main() {
8 resp, err := http.Get("https://example.com")
9 if err != nil {
10 fmt.Println("Error fetching the URL:", err)
11 return
12 }
13 defer resp.Body.Close()
14 body, err := io.ReadAll(resp.Body)
15 if err != nil {
16 fmt.Println("Error reading the response body:", err)
17 return
18 }
19 fmt.Println(string(body))
20}Key points:
- Always check for errors after
http.Get. - Use
defer resp.Body.Close()to avoid leaking resources. - Use
io.ReadAllto read the full response.
Pro Tips:
- To set custom headers (like a browser User-Agent), use
http.NewRequest:1req, _ := http.NewRequest("GET", "https://example.com", nil) 2req.Header.Set("User-Agent", "Mozilla/5.0") 3client := &http.Client{} 4resp, err := client.Do(req) - Always check
resp.StatusCode—a 200 means success, but 403 or 404 means you’re blocked or the page doesn’t exist.
Step 3: Parsing HTML and Extracting Data with Go
Fetching HTML is just the start. Now you need to extract the good stuff—product names, prices, links, you name it.
Enter Goquery: It’s a Go library that gives you jQuery-style selectors for HTML parsing.
Install Goquery:
1go get github.com/PuerkitoBio/goqueryExample: Extracting Product Names and Prices
1package main
2import (
3 "fmt"
4 "net/http"
5 "github.com/PuerkitoBio/goquery"
6)
7func main() {
8 resp, err := http.Get("https://example.com/products")
9 if err != nil {
10 panic(err)
11 }
12 defer resp.Body.Close()
13 doc, err := goquery.NewDocumentFromReader(resp.Body)
14 if err != nil {
15 panic(err)
16 }
17 doc.Find("div.product").Each(func(i int, s *goquery.Selection) {
18 name := s.Find("h2").Text()
19 price := s.Find(".price").Text()
20 fmt.Printf("Product %d: %s - %s\n", i+1, name, price)
21 })
22}How it works:
doc.Find("div.product")selects all product containers.- Inside each,
s.Find("h2").Text()grabs the product name, ands.Find(".price").Text()gets the price.
Regular Expressions: For simple patterns (like emails), Go’s regexp package is fast and easy. But for anything more complex, stick with Goquery.
Step 4: Supercharge Your Scraper with Go Libraries (Colly & Gocolly)
Ready to level up? is the go-to web scraping framework for Go. It handles crawling, concurrency, cookies, and more—so you can focus on the data, not the plumbing.
Why Colly Rocks:
- Simple API: Register callbacks for elements you want to scrape.
- Concurrency: Scrape hundreds of pages in parallel with
colly.Async(true). - Automatic Crawling: Easily follow links and handle pagination.
- Anti-bot Features: Set custom headers, rotate user agents, and manage cookies.
- Error Handling: Built-in hooks for failed requests.
Install Colly:
1go get github.com/gocolly/colly/v2Basic Colly Scraper Example:
1package main
2import (
3 "fmt"
4 "github.com/gocolly/colly/v2"
5)
6func main() {
7 c := colly.NewCollector(
8 colly.AllowedDomains("example.com"),
9 colly.Async(true),
10 )
11 c.OnHTML(".product-list-item", func(e *colly.HTMLElement) {
12 name := e.ChildText("h2")
13 price := e.ChildText(".price")
14 fmt.Printf("Product: %s - %s\n", name, price)
15 })
16 c.OnRequest(func(r *colly.Request) {
17 r.Headers.Set("User-Agent", "Mozilla/5.0")
18 })
19 c.OnError(func(r *colly.Response, err error) {
20 fmt.Println("Request failed:", r.Request.URL, "->", err)
21 })
22 c.Visit("https://example.com/products")
23 c.Wait()
24}Feature Comparison: Goquery vs. Colly
| Feature | Goquery | Colly |
|---|---|---|
| HTML Parsing | Yes | Yes (uses Goquery inside) |
| HTTP Requests | Manual | Built-in |
| Concurrency | Manual (goroutines) | Easy (Async(true)) |
| Crawling/Link Follow | Manual | Automatic |
| Anti-bot Features | Manual | Built-in |
| Error Handling | Manual | Built-in |
Colly is a huge time-saver for anything beyond the simplest scrape.
Step 5: Handling Real-World Challenges in Go Web Scraping
Web scraping in the wild isn’t all sunshine and rainbows. Here’s how to tackle the big headaches:
1. IP Blocking
- Rotate proxies using Go’s
http.Transportor Colly’s proxy support. - Slow down your requests with random delays.
2. User-Agent and Headers
- Always set a realistic User-Agent (like Chrome or Firefox).
- Mimic real browser headers (Accept-Language, etc.).
3. CAPTCHAs
- If you hit a CAPTCHA, you’re probably scraping too fast or too obviously.
- Use headless browsers (like ) for sites that require JavaScript or visual interaction.
- For hardcore anti-bot sites, consider integrating a CAPTCHA-solving service.
4. Pagination
- With Colly, you can follow “Next” links automatically:
1c.OnHTML("a.next", func(e *colly.HTMLElement) { 2 e.Request.Visit(e.Attr("href")) 3})
5. Dynamic Content (JavaScript)
- Go’s HTTP libraries can’t execute JS. Use a headless browser (Rod, chromedp) or scrape the underlying API endpoints if you can find them.
6. When It’s Just Too Much… Use Thunderbit
Sometimes, you hit a wall—maybe the site is too dynamic, or you just need data fast without coding. That’s where comes in. Thunderbit is an AI-powered web scraper Chrome Extension that:
- Uses AI to detect and extract fields—just click “AI Suggest Columns.”
- Handles subpage navigation and pagination automatically.
- Runs in a real browser (or in the cloud), so it can handle JavaScript-heavy sites and most anti-bot measures.
- Exports directly to Excel, Google Sheets, Airtable, or Notion—no code required.
- Lets you schedule scrapes and automate data collection for your team.
Thunderbit is a lifesaver for business users, sales teams, or anyone who needs structured data without the coding grind. And yes, I’m a little biased—my team and I built it to solve exactly these headaches.
Combining Go and Thunderbit for Maximum Productivity
Here’s the secret sauce: you don’t have to choose between Go and Thunderbit. The best teams use both.
Example Workflow:
- Use Go (with Colly) to crawl a huge list of URLs or gather basic data at scale.
- Feed the URLs into Thunderbit to extract detailed, structured info—especially when you need to handle subpages, dynamic content, or tricky anti-bot defenses.
- Export the data from Thunderbit to Google Sheets or CSV.
- Use Go again to process, merge, or analyze the data as needed.
This hybrid approach gives you the speed and control of Go, plus the flexibility and AI smarts of Thunderbit. It’s like having a Swiss Army knife and a power drill in your toolbox.
Comparing Go Web Scraping Solutions: Core Go vs. Colly vs. Thunderbit
Here’s a quick side-by-side to help you pick the right tool for the job:
| Aspect | Plain Go (net/http + html) | Go + Colly (Library) | Thunderbit (AI No-Code) |
|---|---|---|---|
| Setup & Learning Curve | Steep (coding required) | Moderate (easier API) | Easiest (no code, AI-driven) |
| Concurrency | Manual (goroutines) | Built-in (Async(true)) | Cloud/browser parallelism |
| Dynamic Content (JS) | Needs headless browser | Some JS support, or Rod | Full browser, handles JS natively |
| Anti-bot Handling | Manual (proxies, headers) | Built-in features | Mostly automatic, cloud IPs |
| Data Structuring | Custom code | Callbacks, custom structs | AI-suggested, auto-formatted |
| Export Options | Custom (CSV, DB, etc.) | Custom | Excel, Sheets, Notion, Airtable |
| Maintenance | High (update code often) | Moderate | Low (AI adapts to site changes) |
| Best For | Devs, custom pipelines | Devs, rapid prototyping | Non-coders, business users |
Pro tip: Use Go/Colly for custom, large-scale, or backend-integrated projects. Use Thunderbit when you want speed, ease, or need to handle complex front-end sites.
Key Takeaways: Getting Started with Web Scraping with Go
- Go is a powerhouse for web scraping—especially when you need speed, concurrency, and reliability.
- Start simple: Set up your Go environment, make HTTP requests, and parse HTML with Goquery.
- Supercharge with Colly: For crawling, concurrency, and anti-bot tricks, Colly is your friend.
- Handle real-world challenges: Rotate proxies, set headers, and use headless browsers or Thunderbit for tough sites.
- Combine tools: Don’t be afraid to mix Go and Thunderbit for the best of both worlds.
Web scraping is a force multiplier for sales, operations, and research teams. With Go and the right libraries (and a dash of AI), you can automate the boring stuff and focus on insights that move your business forward.
Additional Resources for Web Scraping with Go
Want to dive deeper? Here are some of my go-to resources:
Happy scraping—and may your data always be structured, your scrapers fast, and your coffee strong.
FAQs
1. Why should I use Go for web scraping instead of Python or JavaScript?
Go offers superior concurrency, speed, and reliability—especially for large-scale or long-running scraping projects. It’s ideal when you need to scrape thousands of pages quickly and want a compiled, portable binary.
2. What’s the easiest way to parse HTML in Go?
Use the library. It gives you jQuery-like selectors for easy DOM traversal and data extraction.
3. How do I handle sites with JavaScript-rendered content in Go?
You’ll need a headless browser library like or . Alternatively, use for a no-code, browser-based approach that handles JS out of the box.
4. What’s the best way to avoid getting blocked while scraping?
Rotate your User-Agent, use proxies, add delays between requests, and mimic real browser behavior. Colly makes these tricks easy, and Thunderbit handles most anti-bot measures automatically.
5. Can I combine Go and Thunderbit in my workflow?
Absolutely! Use Go for large-scale crawling or backend integration, and Thunderbit for AI-powered extraction, subpage scraping, and exporting to business tools. It’s a powerful combo for both developers and business users.
Ready to level up your web scraping? Try or check out the for more tips, tutorials, and deep dives into scraping, automation, and AI.