
Firecrawl has become one of the most hyped web scraping APIs in the AI developer world — , Y Combinator backing, and a client list that includes Shopify, Zapier, and Apple. But after digging through pricing docs, user complaints, independent benchmarks, and real-world cost models, the headline story and the actual experience are pretty far apart.
This Firecrawl review isn't another feature list. If you've signed up, run a few test scrapes, and are now wondering "what will this actually cost me at scale?" — or if you're trying to figure out whether Firecrawl is the right tool for your team in the first place — you're in the right place. I'm going to walk through the real costs (including the dual billing trap most reviews skip), where Firecrawl genuinely excels, where it falls flat (especially on bot-protected sites), and when a completely different tool — including no-code options like — is the smarter move. My goal: save you from the surprise credit card statement.
What Is Firecrawl and Who Is It Built For?
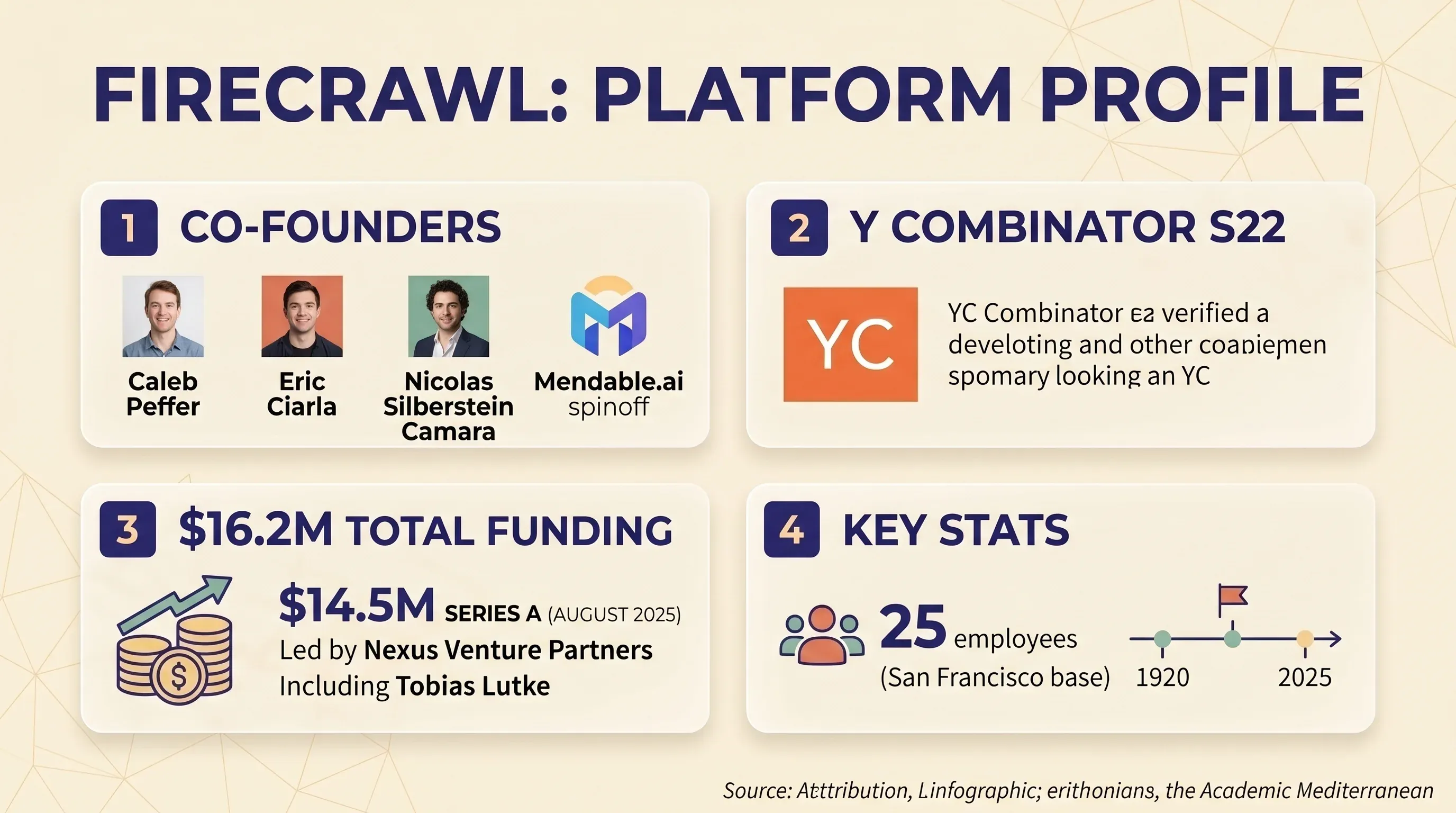
Firecrawl is an API-first web scraping and crawling platform that converts websites into clean markdown or structured JSON. It's designed primarily for developers building AI and LLM applications — think RAG pipelines, chatbot knowledge bases, and AI agent workflows. The company was founded by Caleb Peffer, Eric Ciarla, and Nicolas Silberstein Camara as a spinoff from Mendable.ai. They went through and raised a in August 2025 led by Nexus Venture Partners, with Shopify CEO Tobias Lutke participating. Total funding: $16.2M. The team is 25 people, based in San Francisco.
Firecrawl offers four core modes, plus two newer additions:
| Mode | What It Does |
|---|---|
| Scrape | Convert a single URL to markdown, JSON, or screenshot |
| Crawl | Crawl a URL and all its subpages |
| Map | Discover all URLs on a website in seconds (up to 100K URLs) |
| Search | Web search with full page content retrieval |
| Extract | AI-powered structured extraction via prompts or schemas |
| Agent (Research Preview) | Autonomous web research without specifying URLs |
I want to be upfront: Firecrawl is a developer tool. It requires API calls, coding knowledge, and technical setup. If you're a business user looking to grab data from a website without writing code, Firecrawl is not built for you (more on alternatives later). But for dev teams building AI apps, the promise is compelling — clean, LLM-ready web data with minimal infrastructure headaches.
Firecrawl Review: Pricing Tiers at a Glance
On the surface, Firecrawl's pricing looks straightforward. Here's what's listed on :
| Plan | Monthly Price | Credits/Month | Concurrency | Annual Price |
|---|---|---|---|---|
| Free | $0 | 500 (one-time, not monthly) | 2 | — |
| Hobby | $19/mo | 3,000 | 10 | $16/mo billed annually |
| Standard | $99/mo | 100,000 | 50 | $83/mo billed annually |
| Growth | $399/mo | 500,000 | 100 | $333/mo billed annually |
| Scale | $749/mo | 1,000,000 | 1,000 | $599/mo billed annually |
A couple of things jump out immediately. The free plan's 500 credits are one-time, not monthly — a detail many users miss until they've burned through them in a single test session. And those tiers look simple enough, but actual costs depend heavily on which features you use. The listed price is really just the starting point. The real bill? That's what the next section is about.
The Real Cost of Firecrawl: A Credit Calculator for Your Use Case
Pricing is the single biggest pain point among real Firecrawl users — "it is damn expensive," "I would need to be on the $99/mo plan for my usage level," and "egregiously expensive" are actual quotes from Hacker News and Reddit threads. The reason? There's a dual billing system that most Firecrawl reviews completely ignore.
Here's the trap: Firecrawl's credit plans cover Scrape, Crawl, Map, and Search. But Extract — the AI-powered structured extraction that's one of Firecrawl's main selling points — runs on a completely separate token-based subscription.
| Extract Plan | Monthly Price | Tokens/Year | Tokens/Month (approx.) |
|---|---|---|---|
| Starter | $89/mo | 18M | ~1.5M |
| Standard | $189/mo | 48M | ~4M |
| Growth | $389/mo | 108M | ~9M |
| Pro | $719/mo | 192M | ~16M |
So a startup on the Standard credit plan ($99/mo) that also needs extraction pays $99 + $89 = $188/mo minimum — before hitting any credit multipliers. This is the dual billing trap that catches people off guard.
Hidden Credit Multipliers Most Users Miss
The "1 credit per page" headline is misleading. Here's what features actually cost:
| Feature | Credit Cost | Effective Multiplier |
|---|---|---|
| Basic Scrape/Crawl | 1 credit/page | 1x |
| Search | 2 credits/10 results | 2x per result set |
| JSON extraction (via Scrape) | +4 credits/page | 5x total |
| Enhanced Mode | +4 credits/page | 5x total |
| JSON + Enhanced Mode | +8 credits/page | 9x total |
| Browser interactions | 2 credits/minute | Variable |
| Agent mode (spark-1-mini) | Dynamic, ~100–500/query | 100–500x |
| Agent mode (spark-1-pro) | Dynamic, ~200–1,500+/query | 200–1,500x |
And a few more details that matter: credits do not roll over month-to-month. Failed requests still consume credits (users report 20–30% waste on flaky sites). Agent mode has no pre-run cost estimator — you set a maxCredits parameter, but you're basically guessing. The free plan's 500 lifetime credits translate to roughly 56 pages if you enable extraction. That's not a trial — it's a taste.
Sample Monthly Cost Table by User Profile
| User Profile | Monthly Pages | Features Used | Estimated Credit Burn | Estimated Monthly Cost |
|---|---|---|---|---|
| Hobbyist / Side Project | 500 | Basic scrape + crawl | ~500 credits | $19/mo (Hobby plan) |
| Hobbyist + JSON extraction | 500 | Scrape + Extract | ~2,500 credits + $89 Extract | $108/mo |
| Startup / AI App | 5,000 | Scrape + Extract + Search | ~30,000 credits + $89 Extract | $188/mo (Standard + Extract) |
| Enterprise / Data Pipeline | 50,000 | Full stack + Agent | ~250,000–450,000 credits + $389 Extract | $788–$1,138/mo |
One Hacker News developer paying $190/month called the experience "expensive and felt half baked" and replaced Firecrawl with 2,700 lines of custom Elixir code. That's a pretty strong signal.
Self-Hosted Firecrawl: What's Actually Free (and What's Cloud-Only)
"Can I just self-host Firecrawl for free?" is one of the most common questions I see. The answer is: sort of, but probably not in the way you're hoping.
Firecrawl has an open-source core (AGPL-3.0 license), but several important features are cloud-only. Here's the definitive breakdown:
| Capability | Self-Hosted (Free) | Cloud (Paid) |
|---|---|---|
| Basic Scrape/Crawl to Markdown | ✅ | ✅ |
| Map (URL discovery) | ✅ | ✅ |
| LLM-powered Extract | ⚠️ (bring your own LLM keys) | ✅ (managed) |
| Agent mode | ❌ | ✅ |
| Browser Sandbox | ❌ | ✅ |
| Actions/Interact | ❌ | ✅ |
| Anti-bot / proxy rotation (Fire-engine) | ❌ (uses your static IP) | ✅ |
| Batch processing | ❌ | ✅ |
| Dashboard / analytics | ❌ | ✅ |
| Managed infrastructure | ❌ (Docker + PostgreSQL + Redis required) | ✅ |
Fire-engine, Firecrawl's proprietary anti-bot system, is . Self-hosted users get zero anti-bot capabilities and must provide their own proxies.
Who Self-Hosting Still Makes Sense For
Self-hosting works if you're a developer who wants a basic crawl-to-markdown pipeline and you're comfortable managing Docker Compose with 5+ services. Minimum requirements: 4GB RAM, 2 CPU cores, plus LLM API keys for extraction ($0.01–$0.10/page) and proxy services if you need them. All-in, self-hosted costs run $90–$340/month — which is often comparable to the cloud plans at moderate volume.
Why Users Are Frustrated with the Self-Hosted Version
Real user feedback paints a rough picture. Multiple Reddit and GitHub threads describe the self-hosted version degrading over time as features migrate to cloud-only. One user summarized it bluntly: the company "tries to push all users to pay now and make self-host useless." The community even created a firecrawl-simple fork to address pain points. If you're counting on self-hosting as a long-term free solution, set your expectations accordingly — it's a good starting point for experimentation, but not a substitute for the paid cloud product at scale.
Firecrawl Anti-Bot Performance: Where It Works and Where It Doesn't
This is the section that matters most if you're wondering: "Will Firecrawl actually work on the sites I need to scrape?"
The short answer: it depends entirely on how well those sites are protected.
The Benchmark Numbers
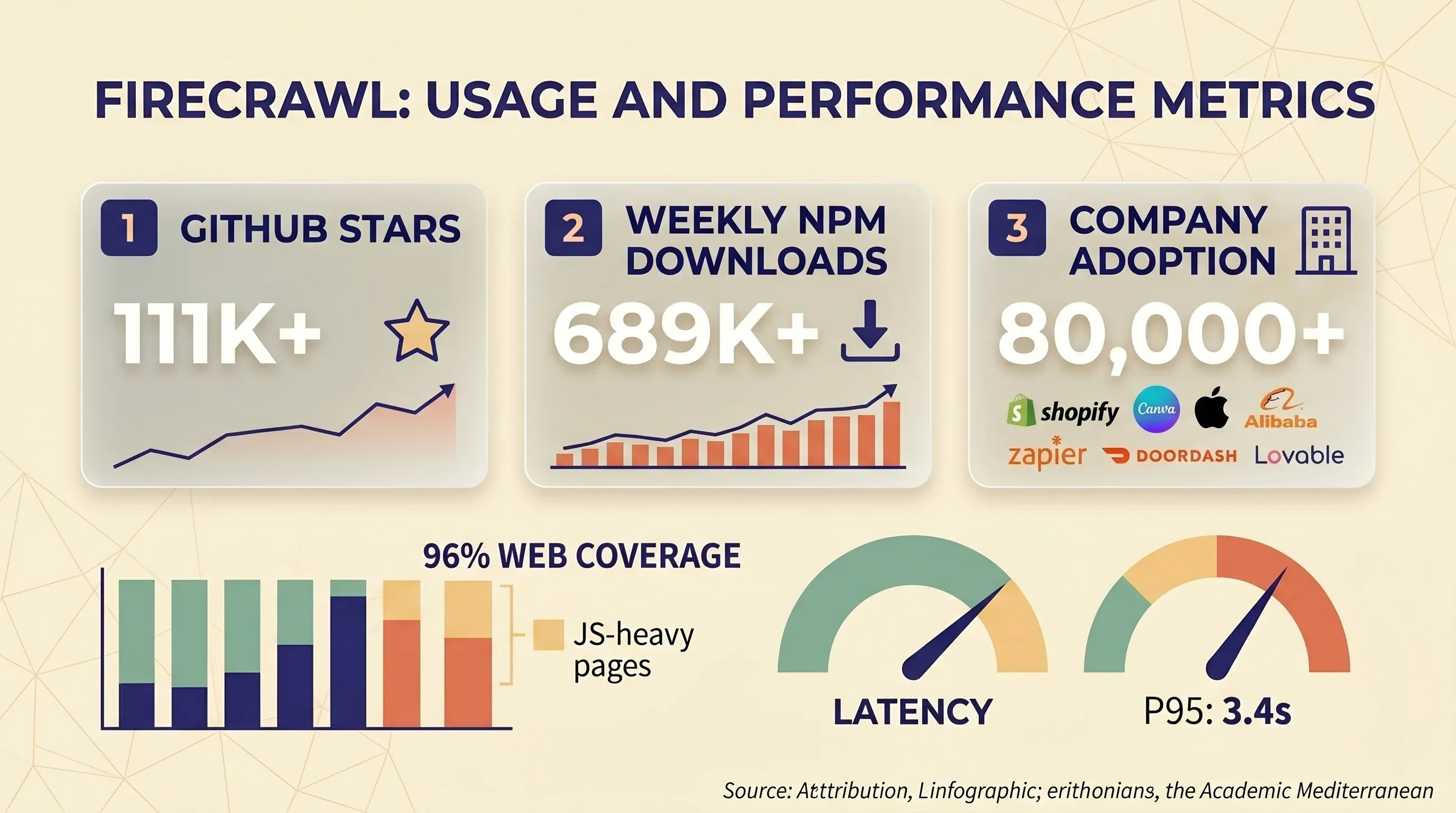
independently tested 10 web scraping APIs against 15 heavily bot-protected sites. Firecrawl's results:
| Provider | Success Rate (2 req/s) | Success Rate (10 req/s) |
|---|---|---|
| Zyte | 93.14% | 89.2% |
| ScrapFly | 91.8% | 88.5% |
| Bright Data | 88.7% | 84.9% |
| Firecrawl | 33.69% | 26.69% |
Firecrawl scored out of 10 providers on protected sites. Its fast response time (7.92 seconds average) is partly explained by a "fail fast" strategy — it returns failures quickly rather than retrying.
broader ongoing benchmark gives Firecrawl a 65.4% overall success rate (above the 59.5% industry average), with strong results on easy targets but poor results on protected ones.
Site Difficulty Breakdown: Easy, Moderate, and Hard Targets
| Difficulty | Example Sites | Firecrawl Success Rate | Recommendation |
|---|---|---|---|
| Easy | Blogs, documentation, public SaaS pages | 85–98% | Use Firecrawl confidently |
| Moderate | Product catalogs, news sites with basic bot protection, Etsy, Realtor.com | 53–65% | Test carefully, expect failures |
| Hard | Amazon, LinkedIn, Instagram, Cloudflare-heavy pages | 0–33% | Don't rely on Firecrawl — use dedicated anti-bot providers |
Cloudflare-protected sites are the most reported failure point. Multiple GitHub issues document the problem: Cloudflare's fingerprint-based detection blocks Firecrawl even when IP rotation is used. Self-hosted users are hit hardest since they lack Fire-engine's proxy infrastructure.
What to Do When Firecrawl Isn't Enough
For heavily protected sites, users typically turn to dedicated proxy services like ScrapFly or Bright Data, or headless browser tooling with custom stealth configurations. If you're a business user who doesn't want to deal with proxy rotation or success rate math, no-code tools like handle anti-bot concerns behind the scenes — you just click and get your data.
Firecrawl Pros and Cons: An Honest Summary
What Firecrawl Does Well
- Clean, LLM-ready markdown output — consistently well-formatted with proper heading structure. This is genuinely Firecrawl's strongest selling point.
- Zero infrastructure overhead for cloud users — no browser setup, proxy management, or headless browser configuration.
- Broad framework integrations — LangChain, LlamaIndex, CrewAI, AutoGPT, Dify, , Flowise (7+ integrations for AI pipelines).
- Fast URL discovery via Map endpoint — 2–3 seconds for a full sitemap.
- Open-source core with — transparency and community contributions.
- MCP server support with FIRE-1 model for AI agent workflows.
- on JS-heavy pages (React, Vue, Angular SPAs).
Where Firecrawl Falls Short
- Dual pricing (credits + separate Extract token plan) creates billing surprises nobody expects.
- Credit multipliers inflate real costs 5–9x above headline pricing.
- Anti-bot performance: dead last in the Proxyway benchmark ( vs. top performer at 93.14%).
- Agent mode has unpredictable credit consumption with no pre-run cost estimator.
- Failed requests still consume credits — 20–30% waste on flaky sites.
- Self-hosted version missing Agent, Browser Sandbox, Fire-engine anti-bot, and dashboard.
- No native CAPTCHA solving — a significant gap vs. Bright Data and Zyte.
- Not accessible to non-technical users — requires coding and API knowledge.
- Free plan's 500 credits are lifetime, not monthly — insufficient for meaningful testing.
Beyond Developer Tools: No-Code Alternatives That Firecrawl Reviews Never Mention
Every Firecrawl review I've read compares it exclusively to other developer tools — Crawl4AI, Scrapy, Playwright, Apify. That makes sense if you're a developer. But a huge chunk of people searching for web scraping solutions are non-developers: sales teams building prospect lists, ecommerce ops monitoring competitor prices, marketers gathering content data, real estate agents tracking listings.
That's a gap worth filling.
Firecrawl Alternatives Comparison Table
| Tool | Best For | Code Required? | LLM-Ready Output | Starting Price |
|---|---|---|---|---|
| Firecrawl | Devs building AI apps | Yes (API) | ✅ Markdown/JSON | $19/mo |
| Crawl4AI | Devs wanting free/OSS | Yes (Python) | ✅ Markdown | Free |
| Apify | Devs needing scale + marketplace | Yes (SDK) | ⚠️ With setup | $39/mo |
| Thunderbit | Business users (no-code) | No (Chrome extension) | ✅ Structured data | Free tier available |
| ScrapingBee | Devs needing proxy | Yes (API) | ❌ Raw HTML | $49/mo |
| Bright Data | Enterprise data teams | Yes (API/SDK) | ⚠️ With setup | $500+/mo |
Why Thunderbit Is the Go-To for Non-Technical Teams
I work on the Thunderbit team, so I'll be transparent about that. Thunderbit belongs in this comparison because it solves a different problem than Firecrawl, for a different audience, without requiring any code.
Thunderbit's workflow is two clicks: open the , click "AI Suggest Fields," then click "Scrape." The AI reads the page, suggests the right columns, and extracts structured data into a table. No API keys, no selectors, no coding. You can export free to Excel, Google Sheets, Airtable, or Notion.
Key differentiators for business users:
- Subpage enrichment — click into detail pages and pull additional fields automatically
- AI that adapts to layout changes — no maintenance when a site redesigns
- Built-in data labeling and translation — useful for multilingual datasets
- Instant templates for popular sites (Amazon, Zillow, LinkedIn, etc.)
For developers who want an API alternative, Thunderbit also offers with simpler pricing than Firecrawl's dual credit/token system. It won't replace Firecrawl for LLM pipeline developers. But for sales, ecommerce, marketing, and operations teams who need structured data without writing code, it's the faster and cheaper path.
Build vs. Buy: When Firecrawl Pays for Itself (and When It Doesn't)
"I thought about writing my own web scraper… simpler than Firecrawl but at least cheaper." Multiple users raise this point. Rather than a subjective take, here's a structured decision framework.
Decision Framework Table
| Factor | Build Custom (Scrapy/Playwright) | Buy Firecrawl Cloud | Use Thunderbit (No-Code) |
|---|---|---|---|
| Setup time | 10–40+ hours | ~30 minutes | ~5 minutes |
| Ongoing maintenance | High (selectors break) | Near-zero (managed) | Zero (AI adapts) |
| Anti-bot handling | Manual (proxy, headers, retries) | Built-in (partial — weak on protected sites) | Built-in (browser + cloud modes) |
| Cost at 1K pages/mo | $50–150 (server + proxy) | $19–$108 (depends on features) | $0–$15 |
| Cost at 50K pages/mo | $500–$1,500 (infra) | $399–$1,138 | $39–$249 |
| LLM-ready output | Custom code required | Built-in (markdown/JSON) | Structured tables (exportable) |
| Best for | Full control, niche sites, DevOps teams | AI/LLM devs, RAG pipelines | Sales, ecommerce, marketing, ops |
Building custom runs than APIs over three years for most organizations. The crossover point where self-built becomes cheaper is approximately 10M+ pages/month — a scale very few teams actually reach.
The Honest Verdict: Which Path Fits You?
Firecrawl pays for itself when:
- Your team already codes in Python/JS and needs clean markdown for LLM/RAG pipelines
- You target mostly unprotected or lightly protected sites
- You want managed infrastructure without DevOps overhead
- Volume stays under ~50K pages/month
Firecrawl doesn't pay for itself when:
- You're a business user doing extractions without a dev team → Thunderbit is easier and faster
- You target heavily protected sites (Amazon, LinkedIn, Cloudflare-heavy) → Bright Data or Zyte
- You need predictable billing at scale → credit multipliers make costs unpredictable
- You want to self-host with full features → Agent, Browser Sandbox, Fire-engine are cloud-only
Building custom makes sense only when:
- Your team has dedicated DevOps capacity
- You're at massive scale (10M+ pages/month)
- You need full control over niche/quirky site handling
- You're comfortable with ongoing selector maintenance
Firecrawl Review: Side-by-Side Comparison Table
Here's everything side by side:
| Tool | Type | Best For | Code Required | Anti-Bot Handling | LLM-Ready Output | Self-Host Option | Starting Price |
|---|---|---|---|---|---|---|---|
| Firecrawl | API | AI/LLM devs | Yes | Weak on protected sites | ✅ Markdown/JSON | ✅ (limited) | $19/mo |
| Crawl4AI | Python library | OSS-first devs | Yes | None (DIY) | ✅ Markdown | ✅ | Free |
| Apify | Cloud platform | Scale + marketplace | Yes | Moderate | ⚠️ With setup | ✅ | $39/mo |
| Thunderbit | Chrome extension + API | Business users, no-code | No | Built-in | ✅ Structured data | ❌ | Free tier |
| ScrapingBee | API | Proxy-focused devs | Yes | Strong | ❌ Raw HTML | ❌ | $49/mo |
| Bright Data | API + proxy network | Enterprise data teams | Yes | Best (~99.9%) | ⚠️ With setup | ❌ | $500+/mo |
Final Verdict: Is Firecrawl Worth It?
Firecrawl is a solid tool for a specific use case: developer teams building LLM apps, RAG pipelines, or AI agents who need clean web data at moderate scale and are comfortable with API-based workflows. The markdown output quality is genuinely best-in-class, and the framework integrations (LangChain, LlamaIndex, CrewAI) are mature. If your team already lives in Python or JavaScript and your target sites aren't heavily bot-protected, Firecrawl can save you real engineering time.
The downsides are real, though. The dual pricing system (credits + separate Extract subscription) creates real billing surprises. The on protected sites means you can't rely on it for Amazon, LinkedIn, or Cloudflare-heavy targets. The self-hosted version is missing too many features to serve as a true free alternative. And if you're a non-technical user — someone in sales, ecommerce, or marketing — Firecrawl isn't built for you at all.
Test Firecrawl's free 500 credits to see if the output quality fits your pipeline. But model your real monthly costs using the calculator above before committing to a paid plan. If you're a business user who just needs structured data from websites without writing code, start with instead — you'll be extracting data in minutes, not hours. You can try the right now, or check out to see what scales for your team. For video walkthroughs, the has step-by-step demos.
FAQs
How much does Firecrawl cost per page scraped?
A basic scrape or crawl costs 1 credit per page. JSON extraction adds 4 credits/page (5 total). Enhanced Mode adds another 4 (up to 9 total). Search costs 2 credits per 10 results, and Agent mode can consume 100–1,500+ credits per query. On top of that, the Extract feature requires a separate token subscription starting at $89/month. See the cost calculator section above for realistic estimates by user profile.
Can you self-host Firecrawl for free?
Yes, the open-source core (AGPL-3.0) is free to self-host. But you lose Agent mode, Browser Sandbox, anti-bot/proxy rotation (Fire-engine is closed-source), batch processing, and the management dashboard. You'll need to bring your own LLM keys for extraction and manage Docker, PostgreSQL, and Redis yourself. Self-hosting works for basic crawl-to-markdown pipelines, but it's not a substitute for the cloud product at production scale.
Is Firecrawl good for scraping Amazon, LinkedIn, or other protected sites?
The shows Firecrawl achieving a 33.69% success rate on heavily bot-protected sites — dead last among 10 tested providers. It works well on unprotected pages (blogs, docs, SaaS sites — 85–98% success), but isn't reliable for major e-commerce or social platforms. For those targets, consider dedicated anti-bot providers like Bright Data or Zyte, or no-code tools like Thunderbit that handle anti-bot behind the scenes.
What's the best Firecrawl alternative for non-technical users?
is the top no-code alternative. It's a Chrome extension where you click "AI Suggest Fields" then "Scrape" — no API calls, no coding, no selectors. Data exports free to Excel, Google Sheets, Airtable, or Notion. It's built for sales, ecommerce, marketing, and operations teams who need structured web data without a developer.
Does Firecrawl offer a free trial?
Firecrawl gives with no credit card required. This is enough to test basic scrape/crawl functionality on a handful of pages, but not enough for production use — especially if you enable extraction (which burns 5 credits per page). Credits do not renew monthly on the free plan.
Learn More