
The world is swimming in data—actually, scratch that. We’re not just swimming; we’re trying to surf a tidal wave of information that’s growing by the second. By 2025, the global datasphere is projected to hit a mind-boggling a year. (For perspective, that’s a trillion gigabytes per zettabyte. I’ll let you do the math while I go find my calculator.) But here’s the kicker: about —think messy web pages, PDFs, images, emails, and social posts.
If you work in sales, marketing, or operations, you know the pain: you need answers, not haystacks. Yet say they struggle to find the information they need to do their jobs. That’s why extracting information—the art and science of pulling useful facts from the chaos—has become the secret sauce of modern business agility. And thanks to new AI-powered tools like , even non-technical teams can now extract, organize, and use information at a speed that would make your old copy-paste routine look like dial-up internet.
Let’s break down what extracting information really means, why it’s so critical, and how you can use the latest techniques (including Thunderbit’s AI web scraper) to turn data overload into business gold.
Extracting Information: A Simple Definition
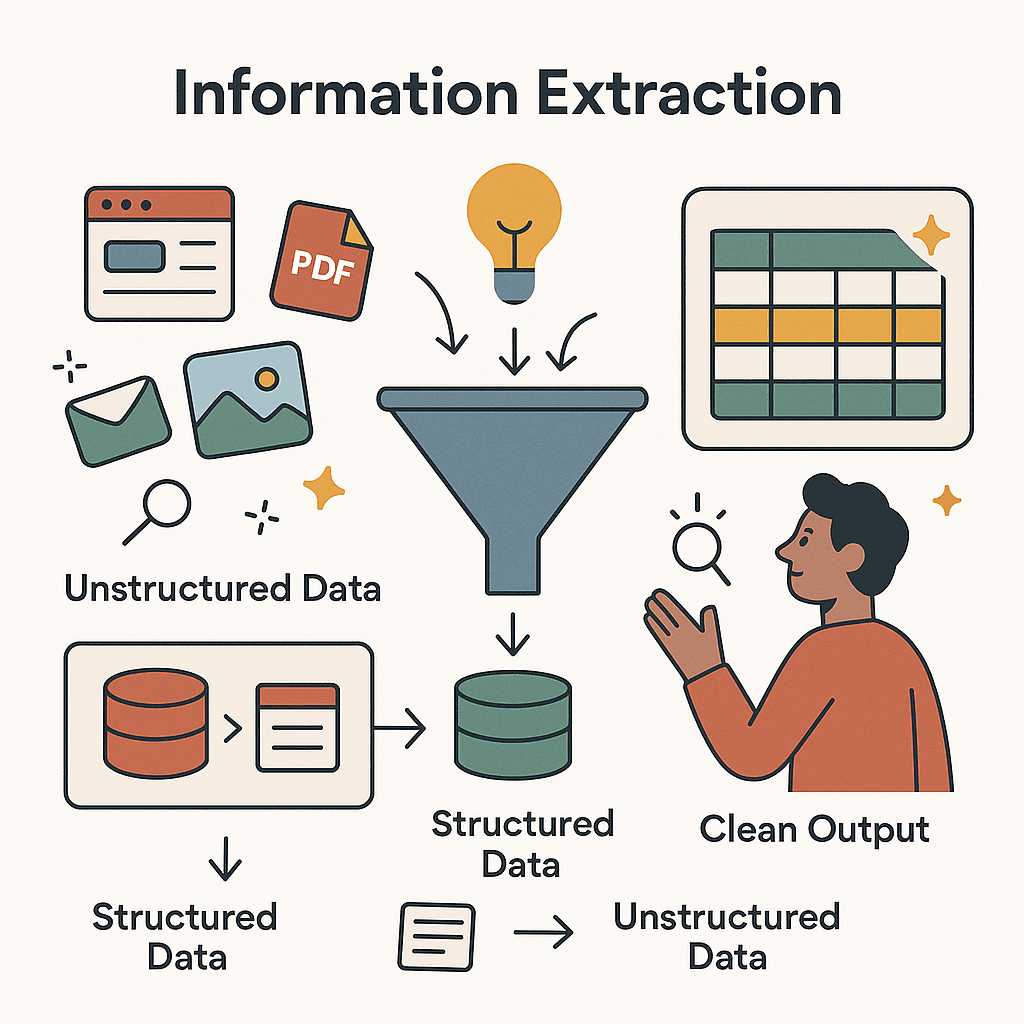
At its core, extracting information means pulling relevant data from various sources and turning it into a structured, usable format. Imagine you’re copying customer emails from a website into a spreadsheet—that’s the most basic form of information extraction. But in today’s world, it’s more like hiring a super-fast assistant who reads through messy web pages, PDFs, or even images, and hands you a neat table of the facts you care about.
There are two main flavors:
- Structured sources: Data that’s already organized, like databases or spreadsheets.
- Unstructured sources: Data in free-form text, web pages, PDFs, images, or emails—basically, anything that doesn’t fit into neat rows and columns.
Modern extracting information is all about turning raw info into usable data—the first step in any data-driven decision-making process (, ). In business, this might mean scraping product prices from competitor websites, summarizing customer feedback from online reviews, or pulling contact info from a PDF.
Think of extracting information as finding the needle of insight in a haystack of data. And with the right tools, you don’t need to be a coder to do it.
Why Extracting Information Matters for Modern Businesses
Why is extracting information such a big deal? Because in the age of data overload, the companies that can quickly find, organize, and act on the right information are the ones that win. Here’s how extracting information delivers real value across business teams:
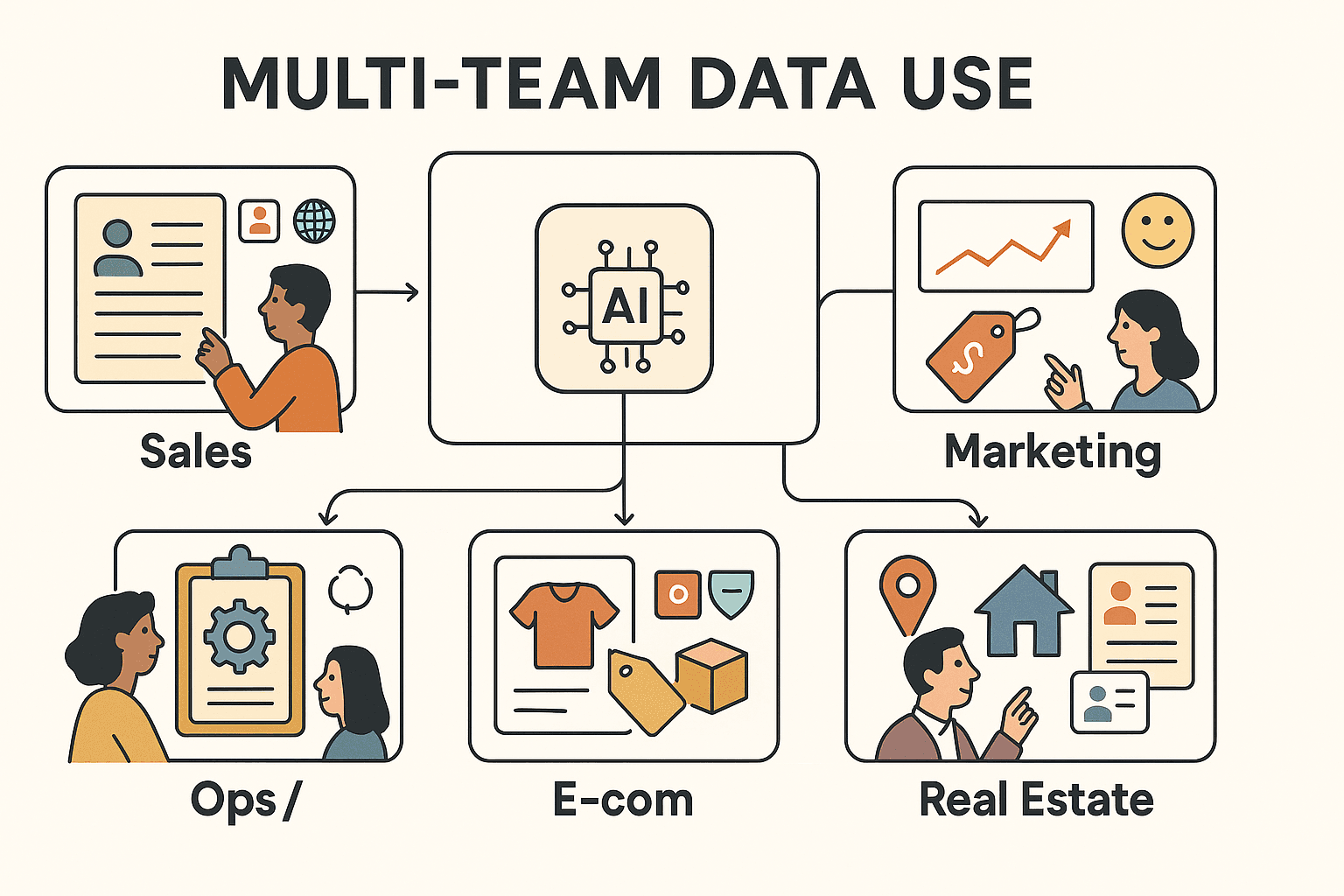
- Sales: Build targeted lead lists by scraping public directories, social media, or company sites—no more buying stale lists or spending hours on manual research. Automated extraction can boost prospecting output by up to and cut manual work by 80%.
- Marketing: Track competitor prices, monitor market trends, and analyze customer sentiment at scale. Retailers like John Lewis credited automated price scraping with a through smarter pricing.
- Operations & Research: Automate repetitive data collection for reports, dashboards, or supplier lists. Knowledge workers can reclaim up to previously lost to manual data wrangling.
- E-commerce: Monitor competitor stock and pricing, track MAP compliance, and optimize your own pricing strategy.
- Real Estate: Aggregate property listings, extract owner contact info, and track market trends automatically.
Here’s a quick snapshot of extracting information use cases by business function:
| Business Function | Use Case for Extraction | Value/Benefit |
|---|---|---|
| Sales | Scraping directories & social networks for leads; pulling contact info from websites, PDFs, or images | Automated lead generation—more leads, less manual work |
| Marketing | Monitoring competitor prices, collecting reviews & social data | Competitive intelligence, sentiment analysis, smarter campaigns |
| Operations/Research | Aggregating industry data, automating reports | Workflow automation, real-time insights, fewer errors |
| E-commerce | Price tracking, stock monitoring | Optimized pricing, revenue protection |
| Real Estate | Scraping listings, owner contacts | Comprehensive market view, faster outreach |
(, )
In short: extracting information is the force multiplier that lets non-technical teams harness big data for real business outcomes.
Key Techniques for Extracting Information
Let’s talk shop: how do people actually extract information? The techniques have evolved fast:
1. Manual Copy-Paste
The “old reliable” (or maybe “old painful”): open a web page, copy the info, paste it into Excel, repeat until your fingers go numb. It’s flexible, but slow, error-prone, and impossible to scale. Studies show knowledge workers waste just searching for and gathering information.
2. Traditional Web Scraping Tools
These are the “DIY power tools”—write scripts (like Python with BeautifulSoup or Scrapy) or use point-and-click software to set up extraction rules. They’re fast and efficient for structured sites, but require technical skills and constant maintenance. One small change to a website’s layout, and your scraper might break ().
3. AI-Powered Extraction (The Modern Way)
This is where things get exciting. AI-driven tools like use natural language processing and computer vision to “read” web pages, PDFs, or images—just like a human would. You tell the tool what you want (“extract product names and prices”), and the AI figures out the rest. No coding, no templates, no headaches. These tools are adaptive, resilient to website changes, and accessible to non-technical users ().
Bottom line: We’re moving from manual and technical bottlenecks to AI-driven, user-friendly extracting information—making it possible for anyone to turn web data into business value.
Thunderbit: Making Extracting Information Easy for Everyone
Now, let me put on my Thunderbit hat for a second (which, if you’re wondering, is a metaphorical hat with a lightning bolt). We built because we saw how much time and opportunity teams were losing to manual data work and clunky scraping tools.
Here’s what makes Thunderbit different:
- 2-Click AI Extraction: Just open the , click “AI Suggest Fields,” and our AI scans the page, suggests relevant columns, and sets up the extraction for you. No code, no templates, just results.
- Handles Complex Sources: Thunderbit isn’t just for web pages. It can extract from PDFs, images, and even messy, unstructured sources. Need to pull contact info from a PDF brochure or a screenshot? Thunderbit’s got your back ().
- Subpage and Pagination Scraping: Our AI can navigate subpages (like product details or profile links) and handle paginated lists, so you get all the data—not just what’s on the first page.
- Natural Language Prompts: You can describe what you want in plain English, and Thunderbit’s AI will figure out the extraction logic.
- Instant Export: Export your results directly to Google Sheets, Excel, Airtable, or Notion—no manual importing or data cleaning needed.
- No-Code, All Power: Thunderbit is designed for sales, marketing, and ops teams who want results without technical hurdles. (And yes, my mom can use it. She’s still working on her smartphone, but Thunderbit? No problem.)
Thunderbit is trusted by over , and we’re just getting started.
Overcoming the Challenges of Extracting Information from Unstructured Data
Here’s where things get tricky: most business-critical info lives in unstructured formats—web pages with weird layouts, PDFs, images, or dynamic content. Traditional scrapers struggle here. But Thunderbit’s AI web scraper is built for the mess:
- Contextual Understanding: Our AI reads the page like a human, recognizing context and patterns—not just HTML tags. If the “Price” field moves, Thunderbit still finds it.
- Subpage Navigation: Need to follow links to get more details? Thunderbit’s subpage scraping handles this automatically, merging all the info into one table.
- PDF and Image Extraction: Thunderbit uses OCR and AI to pull data from PDFs and images, so you can extract from scanned documents, screenshots, or even photos of business cards.
- Data Type Recognition: Thunderbit automatically assigns data types (text, number, date, email, phone, image), so your exports are clean and ready to use.
- Custom AI Prompts: Want to format, categorize, or summarize data as you extract it? Just add a prompt, and Thunderbit’s AI will handle it on the fly.
Real-world example: I’ve seen sales teams use Thunderbit to extract hundreds of leads from a PDF attendee list, marketing teams scrape competitor prices from e-commerce sites, and ops teams pull supplier data from directories—tasks that used to take days now take minutes.
Automating Extracting Information for Business Efficiency
Let’s talk about the real superpower: automation. With Thunderbit, you can set up extracting information workflows that run on autopilot:
- Scheduled Scraping: Describe your schedule in plain English (“every Monday at 9am”), and Thunderbit will run your extraction jobs automatically ().
- Cloud vs. Browser Scraping: Choose cloud mode for speed (scrape up to 50 pages at once) or browser mode for sites that require login.
- Instant Export: Send your data straight to Sheets, Notion, or Airtable—no more CSV wrangling.
- Error Reduction: Automation means fewer manual mistakes and more consistent, reliable data.
The impact? Teams save hours (or days) every week, make faster decisions, and keep their data pipelines fresh and accurate.
From Extracting Information to Building a Data Ecosystem
Extracting information is just the first step. The real magic happens when you turn extracted data into a living, breathing part of your business workflow:
- In-Platform Data Transformation: Thunderbit can summarize, categorize, translate, or format data as it extracts—so your output is analysis-ready.
- Integration with Business Apps: Export directly to your favorite tools (Excel, Google Sheets, Airtable, Notion), or connect via API for deeper integration.
- Data Labeling and Enrichment: Use AI prompts to label, clean, or enrich your data on the fly—no more manual post-processing.
- Knowledge Management: Store and share extracted data in collaborative databases, making it accessible to your whole team.
Imagine a sales team scraping new leads every week, automatically enriching them with company size and exporting to their CRM. Or a marketing team tracking competitor prices in real time, feeding the data into a dynamic pricing dashboard. That’s the power of a data ecosystem built on extracting information.
Extracting Information: Best Practices for Sales and Operations Teams
Ready to get started? Here are my top tips for non-technical teams:
- Set Clear Goals: Know what you want to extract and why. Don’t just scrape for the sake of it—focus on data that drives decisions.
- Choose Reliable Sources: Target authoritative, rich sources for your data needs. Always check if scraping is allowed and ethical.
- Leverage AI Suggestions: Use Thunderbit’s “AI Suggest Fields” and templates to speed up setup and catch all relevant info.
- Validate and Clean Data: Spot-check your results, use data types, and clean as you go to ensure quality.
- Respect Compliance: Only scrape publicly available data, respect privacy laws (like GDPR), and avoid overloading sites.
- Document Your Process: Keep track of what you’re extracting, from where, and how often. It helps with audits and team handoffs.
- Iterate and Improve: Start simple, then refine your extraction as you learn what works best for your team.
()
The Future of Extracting Information: Toward Integrated Data Solutions
Where’s all this headed? The future of extracting information is smarter, more integrated, and more accessible than ever:
- AI Everywhere: Expect AI parsing, natural language queries, and predictive extraction to become standard features in every data tool ().
- Unified Data Platforms: The line between internal and external data will blur—extraction tools will plug directly into BI dashboards, CRMs, and analytics stacks.
- Real-Time and Predictive Extraction: AI will anticipate your data needs, schedule scrapes proactively, and deliver insights in real time.
- Multi-Modal Extraction: Tools will extract not just text, but images, video, and audio—turning any data source into a business asset.
- Ethical and Compliant by Design: Expect more built-in compliance, privacy controls, and ethical scraping frameworks.
At Thunderbit, we’re building toward this future—making extracting information a seamless, everyday part of how business teams work.
Conclusion: Unlocking Business Value Through Extracting Information
Here’s the bottom line: extracting information isn’t just a technical task—it’s the foundation of modern, data-driven business. Whether you’re in sales, marketing, operations, or research, your ability to find, organize, and use information is what sets you apart.
With AI-powered tools like , extracting information is now accessible to everyone. No code, no templates, no IT bottlenecks—just results. Teams are saving hours, making smarter decisions, and building data ecosystems that drive real value.
So, take a look at your current processes. Where are you still stuck in manual mode? What could you automate or improve with modern extracting information tools? I encourage you to , experiment with extracting information from a source you care about, and see how much time and insight you can unlock.
Because in a world overflowing with data, the winners aren’t those who have the most information—they’re the ones who know how to extract, use, and act on it.
For more tips, deep dives, and tutorials, check out the .
FAQs
1. What does “extracting information” actually mean?
Extracting information is the process of pulling relevant data from various sources—like web pages, PDFs, or images—and turning it into a structured, usable format (think: neat tables instead of messy text). It’s the first step in making data actionable for business decisions.
2. Why is extracting information important for business teams?
Because the right information, at the right time, drives better decisions. Extracting information helps sales teams build lead lists, marketers track competitors, and operations teams automate reports—saving time and boosting results.
3. How does Thunderbit make extracting information easier?
Thunderbit uses AI to read web pages, PDFs, and images, then suggests what data to extract—all with no coding required. You can extract, label, and export data in just a couple of clicks, even from complex or unstructured sources.
4. What are the biggest challenges in extracting information from unstructured data?
Unstructured data (like web pages, PDFs, or images) is messy and inconsistent. Traditional tools struggle with layout changes, subpages, or dynamic content. Thunderbit’s AI web scraper overcomes these by understanding context, navigating subpages, and handling multiple data types.
5. What’s the future of extracting information?
The future is AI-driven, automated, and integrated. Tools like Thunderbit will become even smarter—anticipating data needs, extracting from any source (text, image, video), and plugging directly into business apps and analytics platforms. Extracting information will be as routine as sending an email.
Ready to unlock the power of extracting information? and start turning data into business value today.
Read More